背景
不管是学习还是娱乐,看视频时,难免会遇到一些没有中文字幕而自己又比较好奇讲了什么的英文视频,怎么办呢?今天教你一招,如何利用VideoLingo, 将没有字幕的英文视频转换成中文视频。先展示一下成果:
你肯定比较好奇,怎么不直接插入视频内容呢?因为现在西瓜视频和抖音视频合并成了抖音视频,而平台插入视频时校验的链接还是只认西瓜视频,没法上传视频,只好退而求其次。
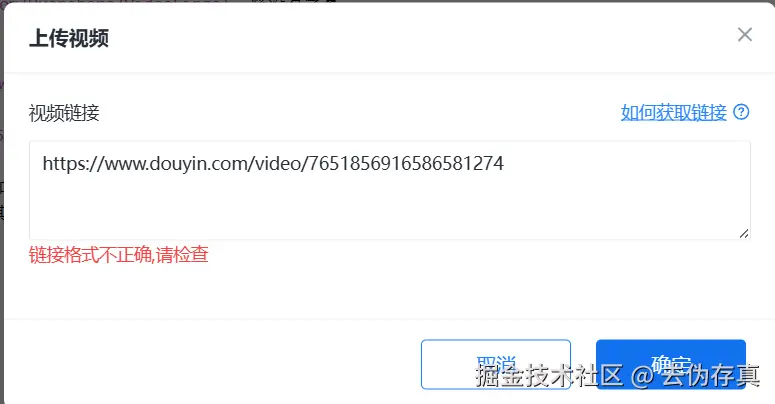
工作原理
第一步 下载视频
下载视频的核心流程可以概括为以下三步:
- 前端输入:用户在 Streamlit 网页端输入视频链接并选择分辨率
- 自动更新 :后台下载前会自动执行
pip install --upgrade yt-dlp,确保下载工具yt-dlp是最新版以防接口失效 - 后台下载 :调用
yt-dlp库,结合FFmpeg将视频和音频以指定画质下载并合并为安全命名的.mp4文件
第二步 翻译并生成字幕
翻译并生成字幕 是整个项目的核心工作流,它将原本粗糙的语音识别文本加工成符合人类阅读习惯、排版优美且时间戳精准的双语硬字幕。分为6
2.1 WhisperX词级转录
- 视频转音频:首先使用 FFmpeg 提取原视频的音频流。
- 人声背景声分离 (可选):调用
Demucs提取出纯人声,并自动进行音量归一化,大幅消除背景音乐或噪音对识别的干扰。 - 分段与识别 :为了防止长视频转录超时,先将音频切片,再通过 WhisperX(本地模型)提取出带有单词级(Word-level)时间戳的原始转录数据。也就是说,音频中每一个词在第几分第几秒被说出,都会被精确记录下来。
2.2 使用NLP和LLM进行句子分段
- NLP结构拆分 (初步):利用
spaCyNLP 库进行语法解析,在标点符号、逗号或长句子的语法谓语/连接词处进行初步断句。 - LLM语义切分 (精细):若初步拆分后的单句长度仍超过设定的阈值,则调用大语言模型(LLM)。LLM 会根据句子的实际含义 ,在最自然的停顿处插入换行符
[br]。 - 文本还原映射 :为了防止 LLM 翻译时"胡说八道"或增删单词,系统使用
SequenceMatcher(字符相似度匹配算法)将 LLM 建议的切分位置强行映射回原始转录文本上,确保转录文本内容绝对不改变。
2.3 摘要和多步翻译
- 生成全局摘要与术语表 :首先用 LLM 阅读全视频的文本片段,归纳视频主题,并自动提取出人名、地名、专业技术词汇(结合用户提供的
custom_terms.xlsx自定义术语表),生成专属术语表。 - 滑动窗口上下文翻译 :在翻译时,系统不会孤立地一句一句翻,而是以 600 字符为一个文本块,并同时把前 3 句和后 2 句作为上下文 连同视频全局摘要、术语对照表一起提交给 LLM。这样能极大减少"机翻感",确保代词指代(如 he/she/it)和专业语境逻辑连贯。
- 行数与字数校验 :翻译完成后,系统会对译文与原文进行句数对齐校验,防止 LLM 合并或漏掉某行翻译。对于翻译后过长(导致屏幕放不下或说话速度跟不上)的句子,会调用
check_len_then_trim进行适当的缩减和修饰
2.4 切割和对齐长字幕
- 字幕字数检测:针对翻译后的译文进行长度加权计算(例如:中日文字符权重为1.75,英文半角为1),找出那些翻译后过长、会超出屏幕边缘的字幕行。
- 中英同步切分对齐:对于过长的行,系统将长句的原英文和中文翻译一起提交给 LLM,由 LLM 完成**"英文切分成两行,且中文翻译也同步切分成对应的两行"**的操作,实现双语字幕的精准断句对齐。
- 多轮迭代:此过程最多循环 3 轮,直到确保所有字幕都能在屏幕内舒适地显示。
2.5 生成时间轴和字幕
- 重新对齐时间戳 :由于字幕在第二步和第四步经历了大刀阔斧的切分,原本的时间轴需要重新计算。程序通过字符匹配算法,找到分割后短句子的首尾单词,对照第一步中 WhisperX 的单词级时间戳,重新赋予每个切分后字幕精准的
start_time和end_time。 - 消除时间轴空隙(Gap Removal) :当两条相邻字幕的间隔极短(如小于1秒)时,系统会自动将前一条字幕的结束时间拉长到后一条字幕的开始时间,以减少字幕在屏幕上频繁闪烁和消失的不良观感。
- 生成 SRT 格式 :转换为标准的字幕文件格式,并在
output/目录下生成多种排列组合字幕:仅原文src.srt、仅译文trans.srt、双语字幕src_trans.srt/trans_src.srt等。
2.6 将字幕合并到视频中
- 检测视频与系统环境:用 OpenCV 检查原视频的分辨率,同时检测系统是否支持 NVIDIA GPU 硬件加速。
- 配置字幕样式滤镜 :配置 FFmpeg 的
subtitles滤镜,设定原文字幕和翻译字幕各自的字体(如 Arial 或 Noto Sans CJK)、字号大小、字体颜色、描边以及边距(MarginV),确保两行双语字幕在画面底部排版美观且互不重叠。 - FFmpeg 渲染输出 :通过启动 FFmpeg 子进程,将字幕文件作为硬字幕(Hard Subtitles)直接烧录进原视频的画面帧中,最后输出渲染完成的成品视频
output/output_sub.mp4。
第三步 配音
配音(Dubbing) 阶段旨在利用 AI 语音合成(TTS)技术生成目标语言(如中文)的配音,并将其与原视频的背景音乐/音效进行融合,生成音色和节奏都高度匹配的配音版视频。此阶段包含以下步骤:
3.1 生成音频任务和分块
-
文本清洗 :读取中英文本,过滤掉破折号以及括号内的注释内容(如
(laughter)),防止 TTS 引擎把它们直接生硬地念出来。 -
极短字幕平滑:如果某句字幕显示时间太短(例如低于设定值),会自动将其与下一句合并,或适当拉长其时间,确保配音时不会因字数过多而导致语速快到听不清。
-
计算语速与分块(Merge Chunks) :利用 TTS 长度估算器预估每句话在正常语速下合成所需的时长。如果某句话的预估时长超出了视频留给它的时间:
- 系统不会强行将单句调得极快,而是会计算它与前后句之间的空隙时间(Gap)。
- 将相邻几句可能需要"抢时间"的字幕合并为一个大配音分块(Dub Chunk) ,共享时间上限,让说话的人能在连续播放多句字幕时以更自然的节奏和速度发音。
-
标记停顿点:确定每一个分块在何处切断(Cutoff),最终生成一份详细的音频配音任务表(存入 Excel 中)。
3.2 提取参考音频
- 调用人声分离 :如果之前未进行人声分离,系统会先通过
Demucs算法从原视频中剥离出纯净的、无背景音乐和杂音的原作人声。 - 音频切片 :读取刚才生成的音频配音任务表中的原片起止时间戳,将原作者发音的各个时间段裁剪成单独的
.wav语音碎片。 - 提供克隆模板 :保存为
output/audio/refers/<序号>.wav。这些小片段将作为"音色参考",在下一步被送往 zero-shot TTS 克隆模型(如 GPT-SoVITS 或 CosyVoice),使得生成的中文配音拥有和视频原作者极为相似的音质与语调。
3.3 生成和合并音频文件
-
TTS 语音合成 (在
_10_gen_audio.py中):调用配置好的 TTS 模块(如 GPT-SoVITS、EdgeTTS 等),输入第二步提取的参考音色和翻译后的字幕文本,生成原始的中文配音片段。 -
变速与对齐(Speed Adjustment) :计算每段新合成的语音时长,使用 FFmpeg 的
atempo过滤器调节音频播放速度(加速或减速),使其严格对齐画面中对应的动作时长,并避免最后一句话超频。 -
静音填充与整轨拼接 (在
_11_merge_audio.py中):- 在每一句中文配音之间,根据新的时间戳(
new_sub_times)自动填充对应宽度的"静音段(Silence segment)"。 - 将成百上千个"配音句 + 静音空隙"拼接成一条与视频总长度完全一致的完整长音频轨道。
- 同时,生成适配新音频时间轴的配音专用字幕
dub.srt,最后导出为output/dub.mp3。
- 在每一句中文配音之间,根据新的时间戳(
3.4 将最终音频合并到视频中
-
音量标准化 :将第三步生成的
output/dub.mp3整合并归一化音量,以防止合成后的人声过小或失真。 -
多音轨混音(FFmpeg amix) :
- 音轨一:原视频画面(进行尺寸对齐)。
- 音轨二 :第一步分离出来的纯背景音乐/音效声轨(保留了视频的背景氛围、现场声和特效声)。
- 音轨三 :新生成的纯人声中文配音轨。
- 使用 FFmpeg 的
amix过滤器将音轨二和音轨三完美混合在一起,使成片在播放清晰中文配音的同时,还能听到原片的背景音乐与声效。
-
硬字幕烧录与最终输出 :使用 FFmpeg 视频滤镜将配音时间轴对应的
dub.srt字幕烧录至视频画面底层,并输出最终配音版视频文件output/output_dub.mp4。
环境准备
首先要安装 CUDA Toolkit和cuDNN,这两个工具是让你的英伟达显卡(GPU)能够用来跑 AI 算法(而不仅仅是打游戏)的底层软件桥梁。
我们可以用一个通俗的比喻来理解它们:
- 你的 显卡(GPU) 是一个计算能力极强的"超级工厂",里面有上万名计算工人(CUDA 核心)。
- CPU(中央处理器)则是一个"全能经理",什么都会,但人手有限。
1. CUDA Toolkit (CUDA 工具包)
- 作用:英伟达官方提供的并行计算平台和编程接口。
- 通俗理解:它是连接"软件(Python/PyTorch)"与"显卡工厂(GPU)"的通用通道。
- 扮演的角色:没有 CUDA,大模型和 AI 软件就无法直接命令显卡去干活,只能排队让 CPU 去算。安装了 CUDA 之后,软件就能把复杂的数学矩阵计算直接分发给显卡里的上万个计算工人,实现上百倍的加速。
2. cuDNN (CUDA 深度神经网络库)
- 作用:专门针对深度学习(Deep Neural Network)定制的加速算法库。
- 通俗理解:它是显卡工厂里的高级专家指导手册。
- 扮演的角色:cuDNN 运行在 CUDA 之上。它里面预先写好了很多被英伟达工程师极致优化过的深度学习标准算法(比如卷积、池化、激活函数等)。AI 软件(如 PyTorch)在运行 AI 模型时,直接对照 cuDNN 这个"专家手册"来指挥工人,可以让显卡的效率再翻几倍。
3. 既然大模型使用的是云端 API,为什么本地还需要英伟达的显卡加速?
虽然翻译(大模型)使用的是云端 API,但视频处理的完整工作流中,翻译只是其中的一个环节,其他非常消耗性能的环节依然默认在你的本地电脑运行:
1. 语音识别(ASR)
- 为什么在本地:虽然可以用 OpenAI 的云端 Whisper API,但云端接口对视频长度有限制,且需要按分钟收费。
- 本地运行情况 :为了省钱和处理大文件,VideoLingo 默认是在你本地电脑运行 WhisperX 模型来听写音频。这是一个部署在本地的深度学习模型,它非常吃配置。如果本地没有 CUDA,你的电脑就会用 CPU 去硬扛,听写速度会非常慢。
2. 声音克隆与配音(TTS)
- 为什么在本地 :如果你希望用小哥原本的声音来说中文,这就需要运行本地的语音克隆模型(如 GPT-SoVITS )。
- 本地运行情况 :声音克隆属于极其复杂的深度学习任务,必须依赖本地 GPU 的 CUDA/cuDNN 加速。如果用 CPU 跑,克隆一句话可能需要几分钟,根本无法实用。
3. 口型对齐(Lip-Sync)
- 为什么在本地:将新配好的中文音频与视频画面重新对齐口型(例如使用 Wav2Lip 模型),这一步是纯粹的本地视频帧像素级计算,不经过任何云端。没有本地显卡加速,你的电脑几乎会卡死在这步。
VideoLingo 是一个"云端 + 本地的混合架构系统:
-
云端:只负责需要逻辑推理的大模型(LLM 翻译)。
-
本地 :负责处理本地多媒体文件(Whisper 听写、本地声音克隆、视频剪辑与口型对齐)。 因此,即使翻译不花本地的算力,处理音视频的本地 AI 模型依然需要你本地 of CUDA 和 cuDNN 来提供强劲的动力。
4. 怎么看我的电脑上有没有安装 CUDA Toolkit 和 cuDNN?
1. 检查 CUDA 是否安装及版本
打开终端(PowerShell 或 CMD),运行以下命令:
cmd
nvcc -V- 已安装 :会输出类似
Cuda compilation tools, release 12.x...的版本信息。 - 未安装/未配置 :会提示
'nvcc' 不是内部或外部命令,也不是可运行的程序...。
此外,也可以通过查看系统环境变量中是否存在 CUDA_PATH(如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.x)来判断。
2. 检查 cuDNN 是否安装
由于 cuDNN 是一组动态链接库,没有直接查看版本的快捷命令。其常规检查方式为:
- 检查
C:\Program Files\NVIDIA\CUDNN目录下是否有对应版本号(如v12.x或v9.x)的文件夹。 - 或者是查看系统环境变量中的
PATH是否包含 cuDNN 的bin路径。
3. Windows上CUDA Toolkit和CUDNN 安装方法
- 安装 CUDA Toolkit 12.6
- 安装 CUDNN 9.3.0
- 将 C:\Program Files\NVIDIA\CUDNN\v9.3\bin\12.6 添加到系统环境变量 PATH 中
- 重启电脑
5. FFmpeg 的功能是什么?
FFmpeg 是一个开源的、跨平台的音视频处理多媒体框架。它几乎是目前所有音视频处理软件和项目的"幕后核心功臣"(如格式工厂、VLC、各类视频剪辑软件乃至 VideoLingo 项目本身,都在底层高度依赖它)。
它的核心功能可以归纳为以下几个方面,同时结合 VideoLingo 项目中的实际应用进行说明:
1. 格式转换与编解码(Transcoding)
- 基本功能:支持几乎所有音视频格式(如 MP4、MKV、AVI、MP3、WAV、FLAC、M4A 等)的互相转换。它能将视频文件解码为原始数据,再通过不同的编码器(如 H.264、H.265、AAC)重新打包。
- 项目中应用 :把用户上传的多格式音视频(如
wav,m4a)统一转码为项目所需的标准格式(如mp3或mp4)。
2. 视频与音频流提取(Demuxing)
-
基本功能:可以把视频文件中的视频画面和音频声音剥离开来,或者提取多音轨视频中的特定轨道。
-
项目中应用:第一步在进行语音识别(ASR)前,使用 FFmpeg 快速提取视频中的音频轨道
3. 字幕烧录(Subtitling)
- 基本功能 :将外挂字幕文件(如
.srt,.ass)以指定的字体、大小、颜色等格式渲染,并永久"烧录"(Burn-in)进视频画面中,生成硬字幕视频。
项目中应用 :FFmpeg 通过 subtitles 滤镜将翻译好的字幕压制到最终视频的指定位置。
4. 多路音视频混音与合成(Muxing & Mixing)
-
基本功能:将不同的视频流、音频流合并到同一个容器中。不仅可以把声音和画面对齐,还可以将多路声音(如人声 + 伴奏)按比例混合。
-
项目中应用 :在配音最后一步 使用
filter_complex的amix滤镜,把 "剥离出的原片背景音/音乐" 与 "AI 合成的中文配音" 混合,并与原视频轨道合并输出。
5. 音视频滤镜处理(Filters)
-
基本功能:对画面进行裁剪、缩放、加水印、调色;对音频进行变速、降噪、改变采样率、调节音量等。
-
项目中应用:
-
音频变速 :调用
atempo滤镜在不改变音调的前提下,对配音进行精确的加速或减速,使配音时长契合视频画面 -
尺寸对齐 :使用
scale和pad滤镜对不同分辨率的视频进行缩放和黑边填充,确保输出分辨率统一。
-
6. 硬件加速(Hardware Acceleration)
- 基本功能:支持调用 NVIDIA GPU (CUDA/NVENC)、AMD (AMF)、Intel (QSV) 或 Apple (VideoToolbox) 的显卡硬件对音视频进行极速编解码,减轻 CPU 负担。
- 项目中应用 :检测系统是否支持 NVIDIA 显卡加速,如果支持,在 FFmpeg 命令中添加
-c:v h264_nvenc参数以开启显卡硬编码,极大缩短成片渲染时间。
7. win系统上ffmpeg安装方法
打开一个powershell终端,执行
winget install Gyan.FFmpeg 装完之后,新开一个powershell终端,输入
装完之后,新开一个powershell终端,输入
js
ffmpeg -version有版本号显示的话说明安装的没问题
主角登场
VideoLingo 是一站式视频翻译本地化配音工具,能够一键生成 Netflix 级别的高质量字幕,告别生硬机翻,告别多行字幕,还能加上高质量的克隆配音,让全世界的知识能够跨越语言的障碍共享。
第一步 克隆仓库
js
git clone https://github.com/Huanshere/VideoLingo.git
cd VideoLingo第二步 安装项目Python依赖包
js
python setup_env.py
有两个包都比较大(torch和whisper),下载很缓慢,要耐心等 
2.1. torch 到底是什么包,为什么这么大(约 3.5GB)?
安装脚本检测到 NVIDIA GPU 时,会自动下载名为 torch-xxx+cu129... 的文件,其体积高达约 3.5 GB。
1. 什么是 torch
torch代表 PyTorch,是目前全球最主流的开源深度学习/神经网络框架。- 它是本地运行所有 AI 算法的心脏。无论是语音听写(Whisper)、声音克隆还是口型对齐,底层全都是依靠 PyTorch 在本地进行模型加载和运算。
2. 为什么体积这么大
- 内置了显卡计算库 :为了实现一键免配置的 GPU 显卡加速,GPU 版本的 PyTorch 内部打包了英伟达官方大量的底层 C++ 运算动态库(
.dll)和 CUDA 核心加速模块。 - 支持大模型推理:作为工业级框架,它需要支持各种张量计算与自动求导,代码和算法实现体积极为庞大。但它是本地 AI 运行必不可少的基础环境。
2.2 whisper包的作用是什么,为什么体积那么大
1.Whisper 包在 VideoLingo 中的作用
Whisper 是由 OpenAI 开源的通用语音识别(ASR)模型。它的作用是:
- 语音转文字(Transcription) :把视频中的英文/外语对白,自动且极其精准地听写并转换为文字。
- 生成精确的时间戳(Timestamping) :不仅听写出内容,还能精确定位到每一个单词是在第几分第几秒说出来的。这对于字幕对齐和后续的"根据口型给配音加速减速"是绝对不可或缺的数据支持。
- 多语种识别:Whisper 能够自动识别几十种主流国家语言并支持直接翻译/听写。
2.为什么它的体积会那么大?
Whisper 相关的安装包和缓存文件夹加起来往往有好几个 GB 甚至十几个 GB,这主要是由于以下三点原因:
- 庞大的模型权重文件(Model Weights)
Whisper 是一个基于 Transformer 架构的深度学习大模型,其内部包含了数以亿计的浮点数参数(权重)。
- VideoLingo 默认使用的
large-v3模型是 Whisper 中精度最高、体积也是最大的模型。 - 单单是这一个模型的权重参数文件,大小就高达 3 GB 左右(保存在您项目根目录的
_model_cache目录中)。
- 深度学习底层框架极其臃肿(PyTorch & CUDA)
要在你电脑上本地运行这个大模型,Python 环境中必须安装底层计算框架:
- PyTorch (torch) :这是主流的深度学习运行库,由于包含了各种复杂的张量运算代码,其安装包体积通常在 2 GB ~ 3 GB。
- CUDA / cuDNN 依赖 :为了让显卡(GPU)能加速运行 Whisper,包内打包了英伟达庞大的 CUDA 加速库(各种
.dll文件),这些静态和动态链接库体积非常惊人。
- 包含了"多语言"和"对齐"模型
除了主识别模型外,VideoLingo 为了实现单词级别的精准时间对齐,还使用了 WhisperX 框架中的音素对齐模型(Wav2Vec 2.0 等)。这些模型也会各自下载并缓存几百 MB 的模型文件。
第三步 启动应用
js
.venv\Scripts\streamlit run st.py # Windows1. 设置web界面显示语言
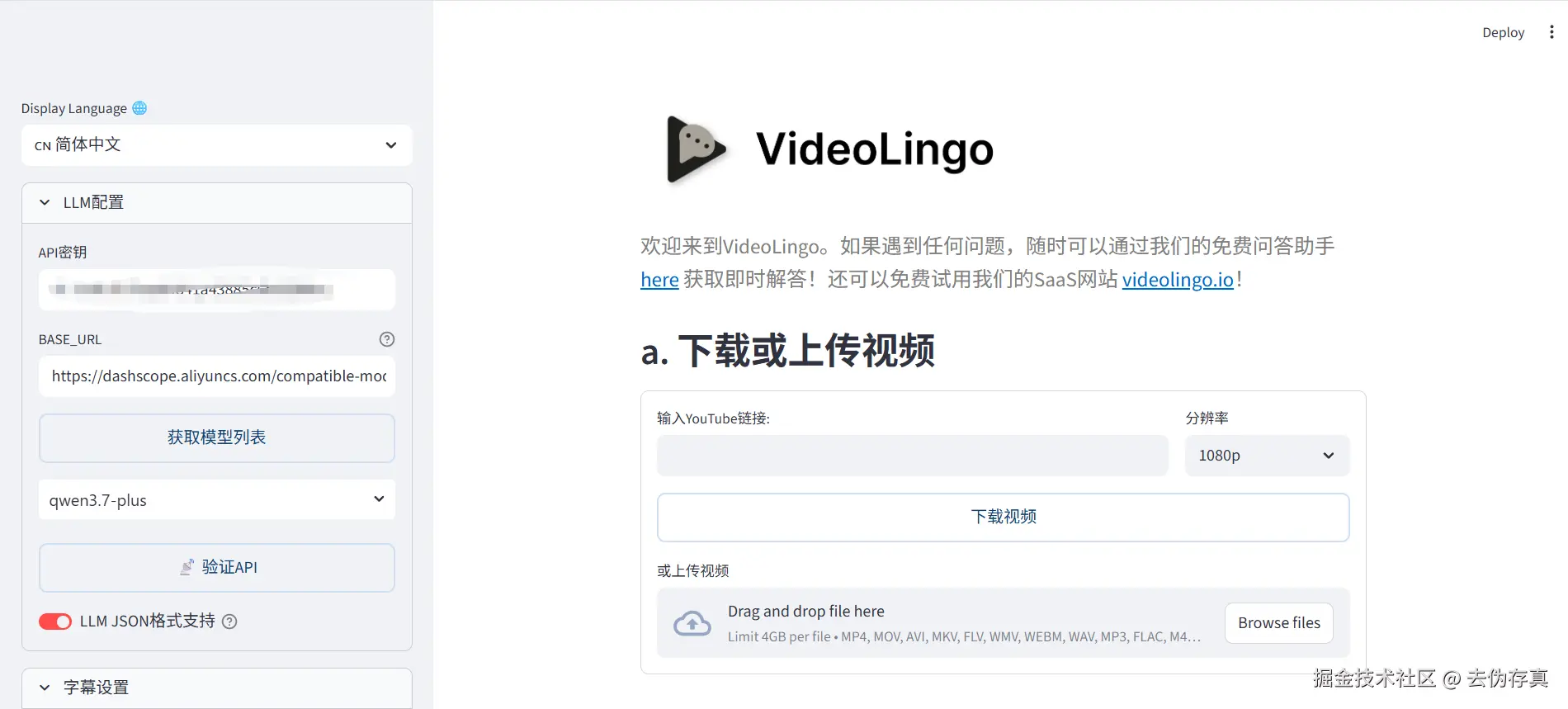
2. 配置翻译模型
Whisper识别出来语音,先转换成文字,接着要调用LLM对这些文字进行翻译,LLM模型有两种选择:
- 使用ollama,在本地安装一个LLM,这对本地机器的性能有一定要求
- 使用云端的LLM,本文使用的是阿里百炼平台的qwen3.7-plus大模型
3. 设置目标语言,以及Whisper的运行环境
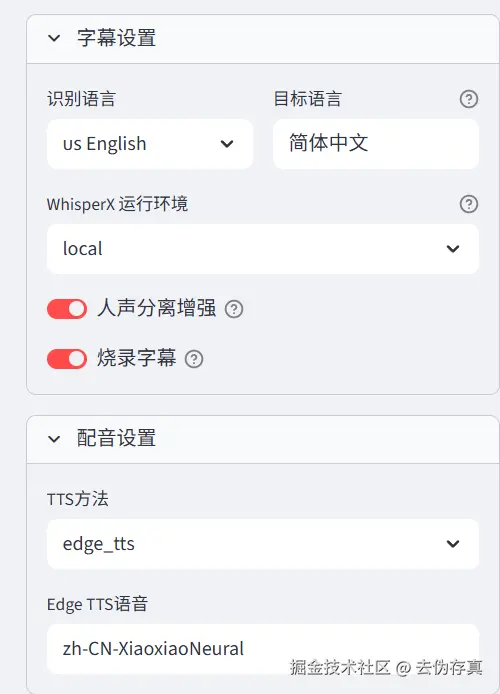
4. 配置文本转语语音引擎
VideoLingo 支持多种云端和本地的语音合成服务,提供的选项有:
1. azure_tts (微软 Azure 语音 - 302.ai 转发)
- 介绍:微软的 Azure Cognitive Services 语音合成,业内公认的商业级标杆,声音极度自然,情感丰富。
- 门槛 :需要 302.ai 的 API Key (付费,需要去 302.ai 申请并在
config.yaml中配置)。 - 音色 :默认使用
zh-CN-YunfengNeural(云枫),声音温暖且非常像真人。 - 适用场景:对配音音质和自然度要求极高,且愿意付一点点 API 费用的用户。
2. openai_tts (OpenAI TTS)
- 介绍 :使用 OpenAI 的 TTS 接口(包含
alloy,echo,fable,onyx,nova,shimmer等音色)。 - 门槛 :需要 302.ai 接口转发的 API Key(付费)。
- 音色:富有现代感、音质清晰,英文极其地道,中文听起来稍微带有一点点 ABC 腔调。
- 适用场景:翻译成英文、法文等多国语言视频,或喜欢 OpenAI 现代感音色的用户。
3. fish_tts (Fish Audio 语音 - 302.ai 转发)
- 介绍:由国内顶尖个性化语音合成平台 Fish Audio 提供的服务,常用于高度逼真的声音合成和克隆。
- 门槛 :需要 302.ai 的 API Key(付费)。
- 音色 :内置如
AD学姐、丁真等极具个性和中文表现力的音色。 - 适用场景:想要中文配音极具特色和网络真人感的用户。
4. sf_fish_tts (硅基流动 Fish TTS)
- 介绍 :将 Fish Audio 的 TTS 模型部署在硅基流动 (SiliconFlow) 算力平台上的接口。
- 门槛 :需要 硅基流动 的 API Key(硅基流动目前注册赠送免费额度)。
- 音色:同 Fish TTS,包含多款预设高逼真度音色。
- 适用场景:已有硅基流动账号或想薅免费算力额度,同时想要高品质配音的用户。
5. edge_tts (微软 Edge 浏览器免费大声朗读)
- 介绍:利用微软 Edge 浏览器内置的"大声朗读"接口。
- 门槛 :完全免费,无需任何 API Key,开箱即用。
- 音色 :音质依然相当高(采用微软最新的神经网络音色,如
zh-CN-XiaoxiaoNeural),但对比付费的 Azure 接口,其情感起伏和语气词表现力会稍微单一一些。 - 适用场景 :白嫖首选!不想折腾任何 API 秘钥或不想付费的用户。
6. gpt_sovits (GPT-SoVITS 本地或自建克隆)
- 介绍 :目前开源社区最强大的少样本声音克隆模型,只需提供 3-5 秒的目标声音样本(比如视频原作者的声音),就能完美克隆出对方说中文的效果。
- 门槛 :需要本地或服务器部署 GPT-SoVITS WebUI 服务。
- 音色:取决于你投喂的参考音频,能实现高仿的"原视频作者讲中文"效果。
- 适用场景:极客用户,追求完美的"声线一致性",有本地独立显卡并愿意折腾部署。
7. custom_tts (自定义 TTS 接口)
- 介绍:VideoLingo 提供的开放接口标准,允许代码能力较强的朋友接入自己的本地 TTS 引擎或第三方未内置的 TTS 平台。
- 门槛 :需要自己编写或配置 API 对接逻辑。
- 适用场景:开发者或有特殊本地语音合成引擎对接需求的用户。
8. sf_cosyvoice2 (硅基流动 CosyVoice2 克隆)
- 介绍 :阿里巴巴开源的 CosyVoice2(极高质量声音克隆模型)在硅基流动平台上的托管接口。
- 门槛 :需要 硅基流动的 API Key(付费或扣除免费赠送额度)。
- 音色:几乎能 100% 还原并克隆目标音色,并支持中英双语的精细语调控制。
- 适用场景:希望能通过简单配置实现高质量声音克隆,但不想本地部署显卡的用户。
9. f5tts (F5-TTS 302.ai 转发)
- 介绍:一种新型的非自回归语音合成模型,表现力非常自然,且能够模仿原句的呼吸声和情绪起伏。
- 门槛 :需要 302.ai 的 API Key(付费)。
- 适用场景:想要更加生活化、带有一些真实呼吸停顿音效果的配音。
总结建议
- 最省心、零成本:选 edge_tts。本文选的就是这个
- 效果最好(普通中文配音):选 azure_tts(需去 302.ai 充值配置 Key)。
- 效果最惊艳(想克隆原作者声线):选 sf_cosyvoice2(需硅基流动 Key)或本地折腾 gpt_sovits。
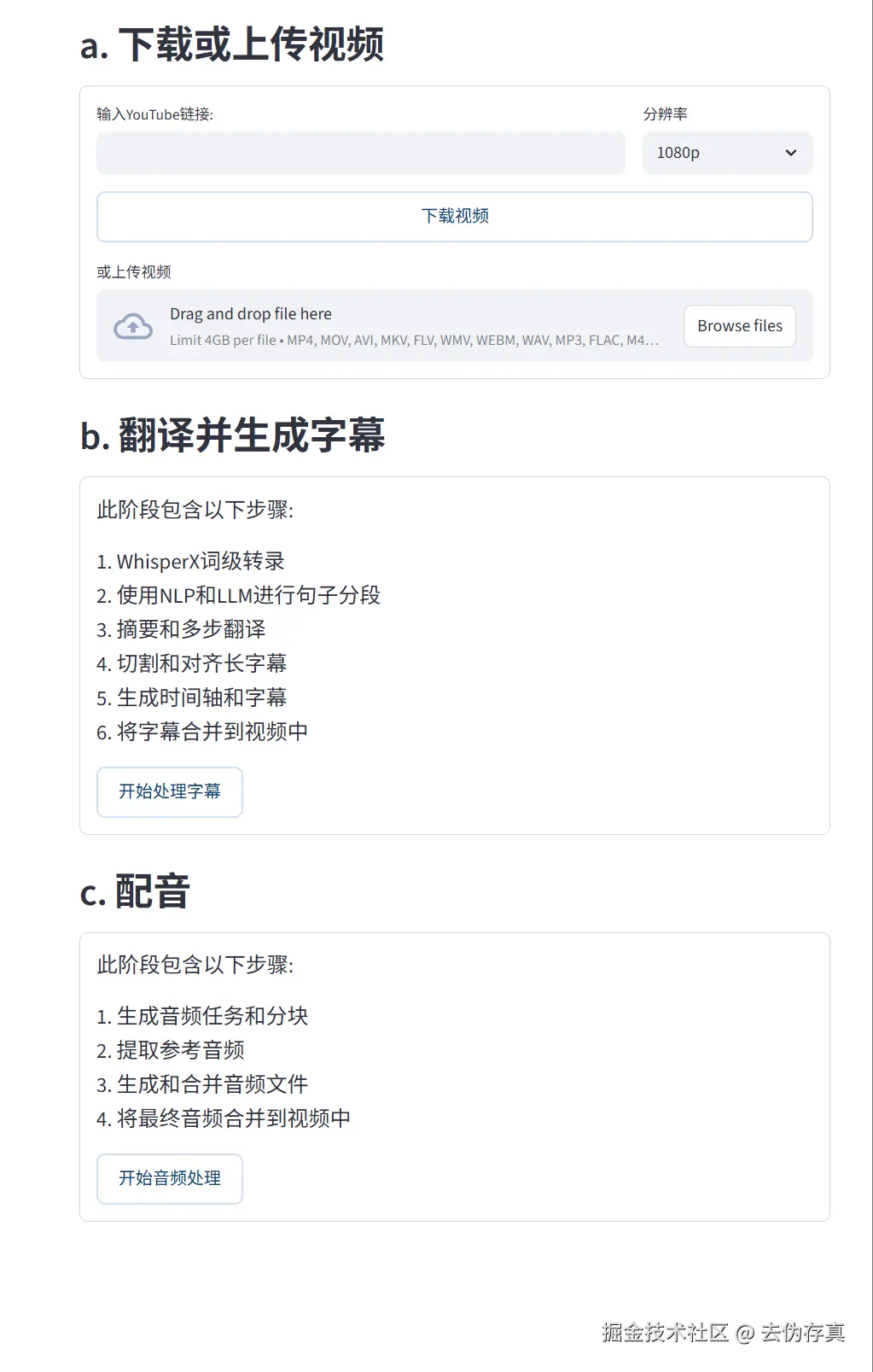
5. 上传视频进行转换
分为三步:
- 上传或者下载视频
- 识别视频中的语音,转换成文字,翻译成目标语言文本
- 将目标语言文本转换成语音,合成原视频内容和目标语言语音
第二步和第三步,执行的时间都比较长,要耐心等待,做LLM方面的开发,真是心急吃不了热豆腐,下载模型及其依赖的工具包很耗时,程序运行很耗时,性子急,沉不住气,非常容易半途而废,在实现这个功能的功能中,发现好几处源码报错,得亏有AI辅助编程,排查修复了一下,不然肯定无果而终。但也好指挥得好才行,不然在大方向上会走偏,比如说第一版转换出来的视频,声音很微弱,几乎听不到,AI认为视频和音频合成时出了问题,一直在去除背景噪声和增强音量上下大力气修改,可是改了好几次,还是改不好,我就听了一下转换的音频文件,发现没声音,让AI往这个方面排查,才定位到了真正的原因,所以AI时代,程序员还有没有价值,我感觉还是有的,只要AI需要人来驱动,人来指挥,人就有存在的价值。本文完。