6.1
1 实验目的
本实验基于之前实验加工完成的用户画像统计表(user_profile_stats),完成浏览器用户画像分析大屏的静态布局设计。
通过本实验,学生应掌握:
- 根据用户画像分析需求,合理设计大屏的信息结构与叙事逻辑
- 理解不同图表类型在用户画像分析中的适用场景与分析价值
- 将数据结果转化为可直观理解、可支撑决策的用户洞察
- 站在"数据产品"角度,思考大屏如何向不同受众传递价值
2 实验环境
- 实验平台:助睿在线实验平台 https://lab.guilian.cn/
本次实验使用助睿数智(Uniplore)作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。
助睿数智官网为 https://www.uniplore.com//
- 可视化工具:助睿Max(数据大屏)
助睿Max 是低代码数据可视化平台,支持拖拽搭建、多种图表组件、地图可视化、交互筛选、低代码开发等能力,适用于业务监控、用户洞察、营销战报等场景。
助睿Max核心优势:
- 组件丰富:覆盖所有常见图表和交互控件,满足企业级可视化需求
- 图层管理:支持图层堆叠、锁定、隐藏、排序,复杂布局轻松实现
- 低代码操作:拖拽式搭建 + 蓝图编辑器,无需复杂编程即可完成大屏布局与数据交互配置
- 工业级数据处理能力:支持海量数据实时接入与渲染,千万级数据点秒级响应,满足企业级生产环境要求
- 支持数字孪生:支持3D场景、GIS地图、实时物联数据接入,可快速构建数字孪生可视化系统
3 实验数据
本实验使用上一阶段加工完成的 user_profile_stats 表,该表按浏览器维度,统计了用户在各人口属性上的分布,包括:
- 基本信息:性别、年龄、学历、职业、收入
- 地域信息:居住地类型(城市/城郊/乡村)、省份
- 维度:按浏览器名称分组,支持整体分析与分浏览器对比
4 整体分析框架
4.1 业务问题
在开始搭建大屏之前,先明确:这张大屏要帮助谁、看懂什么?
| 业务问题 | 对应的分析维度 |
|---|---|
| 目标用户是谁?(年龄、性别、职业) | 明确核心目标人群,指导产品设计与营销沟通 |
| 用户的教育与收入水平如何? | 影响产品复杂度设计、定价策略与商业化路径 |
| 用户分布在哪里? | 指导区域市场投放与本地化运营 |
| 不同浏览器的用户画像是否存在差异? | 识别差异化人群特征,制定针对性竞争策略 |
用户画像大屏的核心价值不是"罗列统计数字",而是回答"谁在用我们的产品",并将抽象的人口属性转化为可行动的人群认知。
4.2 大屏设计方案
| 分析目标 | 推荐图表 | 为什么 |
|---|---|---|
| 展示男女比例、城市/城郊/乡村占比 | 饼图 / 环形图 | 直观反映部分与整体的关系,适合占比类指标 |
| 对比各年龄段、各学历、各职业的用户数量 | 柱状图 / 条形图 | 便于横向比较不同类别的数量差异,条形图尤其适合类别较多的场景 |
| 展示省份分布 | 中国地图 | 空间信息的最佳载体,一眼看出热点区域与空白区域 |
| 展示关键数值(总用户、平均年龄等) | 指标卡 / 翻牌器 | 突出核心结论,视觉聚焦,适合大屏"第一眼信息" |
| 支持查看不同浏览器的用户画像差异 | 筛选器(如下拉多选) | 提供交互能力,让大屏从"静态展示"变为"可探索的分析工具" |
助睿Max支持以上所有图表类型,且每个图表组件都有丰富的样式自定义选项(颜色、标签、图例、提示框、动画等),满足企业级UI要求。
最终整理用户画像大屏的具体方案如下:
| 模块 | 子模块 | 指标项 | 组件 | 关联数据表 | 备注 |
|---|---|---|---|---|---|
| 数据概览 | 用户概况 | 覆盖用户数 | 指标卡 | user_profile_stats | 满足筛选条件的用户总数 |
| 性别比例 | 指标卡 | user_profile_stats | 用户年龄均值 | ||
| 本科以上占比 | 指标卡 | user_profile_stats | 学历本科及以上的用户比例 | ||
| 中高收入占比 | 指标卡 | user_profile_stats | 月收入>5k的用户比例 | ||
| 基本信息 | 性别分布 | 饼图 | user_profile_stats | 男/女用户占比 | |
| 年龄分布 | 柱状图 | user_profile_stats | 按年龄段统计用户数 | ||
| 学历分布 | 条形图 | user_profile_stats | 按学历层次统计用户数 | ||
| 职业分布 | 柱状图 | user_profile_stats | 按职业类别统计用户数 | ||
| 收入分布 | 柱状图 | user_profile_stats | 按收入段统计用户数 | ||
| 地域分布 | 城市 vs 乡镇分布 | 饼图 | user_profile_stats | 城市/城郊/乡村用户占比 | |
| 用户省份分布 | 中国地图 | user_profile_stats | 展示各省份用户数量分布 | ||
| 省份用户数TOP5 | 轮播列表 | user_profile_stats | 展示用户数量top5省份 | ||
| 筛选器 | 浏览器选择 | 下拉多选 | - | 支持选择单个、多个或全部浏览器,默认全部 |
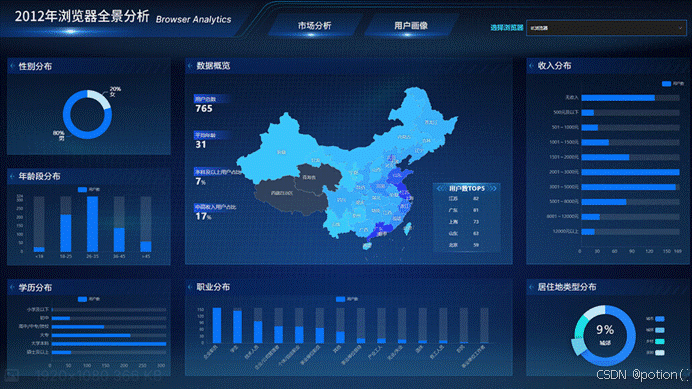
4.3 参考图
++1920×1080 416 KB++
4.4 项目整体说明
本次大屏项目包含"市场分析"和"用户画像"两个大屏,通过顶部导航按钮切换。市场分析大屏已在上一个实验中完成,本次实验只制作用户画像大屏。因此,在开始布局前,需要先将上一个实验已制作的市场分析图表全部隐藏,避免与当前用户画像内容重叠干扰。
助睿Max的图层管理功能:在大屏编辑界面右侧"图层"面板中,可以查看所有组件的堆叠顺序,支持拖拽调整图层上下关系、锁定组件防止误操作、隐藏组件临时不显示。本次实验中,我们可以将市场分析大屏的组件所在的"市场分析"组整体复制、隐藏,复制的组重命名为"用户画像",用户画像大屏的组件正常显示。这样两个大屏可以共存于同一个大屏文件中,通过图层可见性切换,便于统一管理。两个大屏的点击切换交互将在后续实验中专门讲解,本次暂不涉及。
5 各模块设计思路与步骤
5.1 用户省份分布(中国地图)
设计思路:
分析省份分布,是为了识别区域市场的"热点"与"空白":
- 哪些省份用户最多?
- 这些省份是否连片(如沿海高活跃带)?
- 哪些省份是"灯下黑"?
这些信息直接指导区域运营资源的投放优先级,以及本地化推广的策略选择。同时,省份分布也是向投资人展示市场覆盖范围的直观方式。
布局位置:
在大屏布局中,我们把省份分布地图放在最醒目的主视觉位置(通常是大屏的中上部或右侧核心区)。因为地图的空间表现力最强,能够一眼传递"用户从哪来"的直观印象,适合作为大屏的视觉焦点。
图表选择理由:
省份分布必须用地图组件来展示。 地理空间数据的核心信息是"邻近关系"和"空间聚集模式"------柱状图可以告诉你广东用户最多,但它回答不了"华东地区整体表现如何"这类问题。地图保留了省份之间的实际位置关系,观众可以一眼发现热点区域和空白区域。所以地图在这个场景下是不可替代的。
助睿Max地图能力:
助睿Max的"基础平面地图"组件支持多种子图层:区域热力层(按省份颜色深浅)、散点层(城市级别标记)、飞线层(展示流向关系)、迁徙层(动态流动效果)。本实验使用区域热力层即可满足需求,也可以根据实际数据复杂度叠加多个图层,实现更丰富的地理洞察。对于需要数字孪生的场景,助睿Max还支持三维地图、倾斜摄影模型、实时物联数据叠加,可直接构建智慧城市、工业仿真等数字孪生应用。
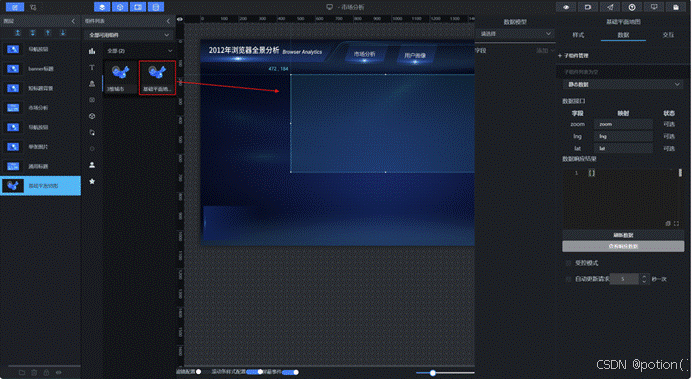
实验步骤:
(1)根据参考图布局,添加"基础平面地图"组件,设置好大小、位置后,添加"区域热力层"子组件
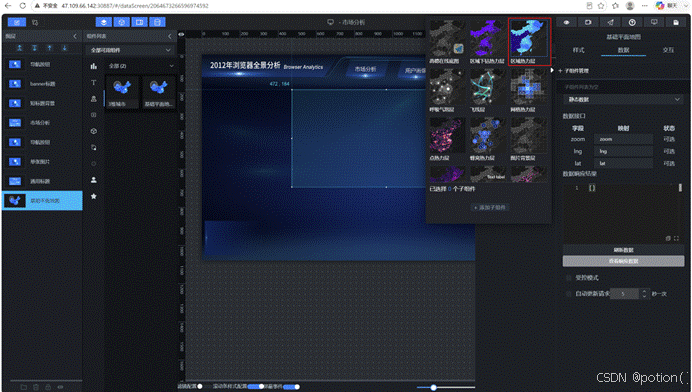
(2)点击"区域热力层"进入子组件配置页面,可根据自身需求配置颜色渐变、边界线宽、高亮样式等属性。助睿Max的地图组件支持自定义地图样式(如深色模式、清新模式),可匹配大屏整体风格。
5.2 核心指标
设计思路:
分析用户画像,需要一个快速获取整体印象的概览区。 在大屏布局中,核心指标卡通常放置在地图的上方、下方或左侧,与地图形成"数据总览+空间分布"的呼应关系。决策者关心四个问题:
- 用户规模有多大?
- 用户偏年轻还是成熟?
- 用户的教育水平如何?
- 有没有消费潜力?
因此,我们在主视觉区域设计了4个核心指标:
| 业务问题 | 对应指标 |
|---|---|
| 用户规模有多大? | 用户总数 |
| 用户偏年轻还是成熟? | 平均年龄 |
| 用户的教育水平如何? | 本科及以上用户占比 |
| 有没有消费潜力? | 中高收入用户(月收入≥5k)占比 |
这4个指标覆盖了用户的"规模、年龄、教育、收入"四个层面,足以快速勾勒出用户群的基本轮廓。
图表选择理由:
核心指标通常用指标卡(数字翻牌器)来呈现。 指标卡的优势是:数字大而醒目,标题简洁,没有任何冗余的图表元素,观众的目光会直接落在数值上。这就是我们选择指标卡的原因------在信息层级中,最重要的数字必须最先被看到。
助睿Max翻牌器能力:
助睿Max的"数字翻牌器"组件支持动态数值变化动画、千分位分隔符、小数位数控制、前后缀自定义(如"万人"、"%"、"¥"),以及背景、边框、字体阴影等样式,使核心指标更加突出。同时,其工业级数据处理能力确保了即使底层数据达到千万级,翻牌器的数值更新依然流畅无延迟。
实验步骤:
(1)根据参考图,添加4个"数字翻牌器"纵向排列,设置标题和数值样式
(2)每个"数字翻牌器"的标题,使用"单张图片"组件设置背景,背景图链接:https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/practice/browser-analysis/mbg.png

5.3 用户数TOP5省份排行榜
设计思路:
地图虽然展示了全国分布,但观众很难精确读出每个省份的具体数值。排行榜以列表形式直接给出用户数最高的几个省份及其数值,与地图形成互补:
- 地图看趋势和空间关系,排行榜看具体排名和数值。
- 帮助运营团队快速定位核心区域,优先在这些省份加大投放或开展线下活动。
- 观察TOP省份排名变化,识别新兴增长区域。
图表选择理由:
排行榜通常用表格或横向条形图来展示。表格的优点是信息密度高、精确,适合展示排名、省份名称、用户数三列信息,这里,我们采用表格形式,简洁明了。
助睿Max表格组件:
助睿Max提供了多种列表组件:轮播列表、折叠指标表格、键值表格、进度条表格。其中轮播列表支持各行各列的样式和内容的自定义配置,支持列表内容的超链接配置,同时支持图片格式的列表内容,能够使用轮播动画的方式,将数据信息以列表的形式清晰地展示在可视化应用上。本实验选择轮播列表,既美观又节省空间。
实验步骤:
(1)根据参考图,添加"单张图片"组件,作为排行榜区域背景,背景图链接:https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/enrollment-data/top-list-bg.png
(2)添加"通用标题"组件,调整好样式
(3)添加"轮播列表"组件,调整好样式(行高、列宽、字体、交替行背景色等)

5.4 性别分布
设计思路:
了解浏览器用户的性别构成,是认识用户画像的第一步。不同性别的用户在使用浏览器的内容和偏好上存在显著差异------男性用户通常对科技、财经、体育等内容关注度更高,而女性用户则更偏娱乐、育儿、时尚等。这种内容偏好差异直接影响广告投放策略和信息流推荐逻辑。
基于上述信息,我们着重分析本浏览器用户的性别分布:
- 男女比例如何? 当前用户群是男性居多、女性居多,还是接近均衡?
- 内容推荐依据:根据性别比例,可以推测用户可能更偏好哪些内容,指导运营团队调整推荐策略。
- 异常监控:观察性别比例是否出现异常波动(如某月从7:3突变为5:5),这可能是市场或产品策略变化的信号。
图表选择理由:
性别分布用饼图来展示,因为性别只有两三个类别(男、女、未知)。饼图的扇形角度能被大脑瞬间识别为比例关系------看到半圆就知道50%,看到三分之一就知道33%,这种直觉反应是柱状图做不到的。所以我们用饼图,让观众不需要阅读数值就能感知男女比例。
助睿Max饼图家族:
助睿Max支持多种饼图:基础款饼图、基础饼图、标注对比图、目标占比图、多维度饼图、指标占比图、指标对比饼图、单值百分比饼图、轮播饼图。这里只有男、女、未知三个类别,使用基础饼图即可。同时,饼图支持内圈半径、外圈半径、标签位置、引导线等精细调节。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)添加"基础饼图"组件,调整大小和位置
5.5 年龄段分布
设计思路:
浏览器用户的年龄结构,是洞察用户需求的切入点。通过分析不同年龄段的占比,我们可以推断出不同年龄段的用户对浏览器的核心诉求和消费潜力。
基于上述信息,我们着重分析本浏览器用户的年龄结构:
- 哪个年龄段最多? 主力用户是学生群体(<18岁),还是青年职场人群(18-35岁),或是年龄更大的用户?
- 功能设计决策:如果用户偏年轻,可以加强个性化、社交分享功能;如果用户偏成熟,则需要强调稳定性、安全性和办公协同能力。
- 风险预警:如果用户年龄结构持续老化,意味着产品对新用户的吸引力可能正在下降,需要警惕品牌老化风险。
图表选择理由:
年龄分布用柱状图来呈现,因为年龄是多个有序区间(如<18、18-25、26-35、>35),柱状图能直观展示分布形态(哪段最高?趋势是上升还是下降?)。饼图处理4个以上类别时会变得难以比较,而柱状图完全没有这个问题。
助睿Max柱状图家族:
助睿Max支持多种柱状图:基础柱图、弧形柱图、水平基础柱图、水平胶囊柱图、垂直胶囊柱图、垂直基本柱图(堆叠柱状图)。这里使用基础柱图即可。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)助睿Max 支持多种柱状图:基础柱图、弧形柱图、水平基础柱图、水平胶囊柱图、垂直胶囊柱图、垂直基本柱图(堆叠柱状图),这里我们使用基础柱图:
5.6 学历分布
设计思路:
浏览器用户的学历分布可以帮助我们从侧面了解用户群体的"特征画像"。不同教育背景的用户,在获取信息的习惯、对专业内容的接受度以及对新功能的探索意愿上可能存在差异。
基于上述信息,我们着重分析浏览器用户的学历结构:
- 高学历用户占比如何? 产品是否吸引了更多拥有高等教育背景的用户?
- 产品复杂度设计:如果高学历(本科及以上)用户占比较高,说明用户群体对新功能、专业工具的接受度更高,产品可以考虑增加高级自定义设置或开发者工具。
图表选择理由:
学历分布用条形图(横向柱状图)来展示,因为学历类别名称通常较长(如"初中及以下""高中/中专""大专""本科""硕士及以上"),条形图让类别名称自然左对齐,阅读流畅度明显更好。
助睿Max条形图:
这里使用水平基础柱图,它是横向条形图,尤其适合类别名称较长的场景。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max 的水平基础柱图:
5.7 职业分布
设计思路:
了解浏览器用户的职业分布,可以帮助我们理解用户的"生活背景",从而推断其典型的使用场景:
- 判断用户群体:他们可能是学生、IT从业者、企业白领,还是自由职业者?
- 场景化功能设计:学生用户多,可推出学习辅助功能;职场人士多,工作日活跃度高,可强化密码管理、云同步等办公属性功能。
- 挖掘增长机会:如果某一职业群体占比较低,也许是未来定向推广或功能拓展的机会点。
图表选择理由:
职业分布用柱状图来展示。职业类别名称一般不长(如"学生""IT从业者""白领"等),柱状图可以清晰地进行横向对比。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max的基础柱图:
5.8 收入分布
设计思路:
浏览器用户的收入数据直接服务于商业化策略。用户的收入水平是衡量其付费能力与消费意愿的核心指标之一,直接关系到产品商业化的天花板。
- 挖掘高潜用户:分析收入分布,可以帮助找到更具价值的用户群体。
- 指导变现策略:如果10k以上用户占比较高,可以考虑订阅制、云服务会员等高端增值服务。反之,如果用户收入集中在中等水平,则免费增值模式(如去广告付费)可能更合适。
图表选择理由:
收入分布用柱状图来展示。收入分段是有序变量(如<3k、3-5k、5-10k、>10k),柱状图能直观展示用户收入水平的集中趋势。
同时,在这个柱状图中展示绝对用户数,与顶部指标卡中的"中高收入用户占比"形成互补:占比给结构结论,绝对值给执行规模。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max 的水平基础柱图:
5.9 居住地类型分布
设计思路:
用户居住地类型(城市/城郊/乡村)反映了用户所处环境的数字化程度和消费习惯差异。城市用户通常网络基础设施更好、线上消费更活跃;城郊和乡村用户可能对某些本地化服务或轻量级应用有独特需求。了解这一分布有助于制定差异化的市场策略和产品功能适配。
图表选择理由:
居住地类型只有三个类别,适合用饼图展示结构占比
助睿Max特色饼图:
为了使大屏可视化效果更丰富,这里使用助睿Max的轮播饼图组件。轮播饼图可以在饼图基础上增加轮播动画,依次高亮每个扇区并显示详细数值,在有限空间内增强了信息传达的动态效果。
实验步骤:
(1)使用"单张图片"组件设置区域背景,并设置好标题
(2)为了使大屏可视化效果更丰富,这里我们使用助睿Max 的轮播饼图:

5.10 筛选器
设计思路:
用户画像分析大屏的核心价值之一,是支持按不同浏览器进行对比分析。通过筛选器,用户可以:
- 查看全部浏览器用户的整体画像(默认视图),了解产品大盘用户特征;
- 选择单个浏览器(如 Chrome、IE、360 等),聚焦该浏览器用户的画像,回答"使用 Chrome 的用户与其他用户有什么不同?";
- 选择多个浏览器进行对比,直观比较不同浏览器用户的年龄、职业、地域等分布差异,为产品定位和竞争策略提供数据依据。
图表选择理由:
筛选器应满足多选、可清空、支持全选/默认全选的交互需求,同时要贴合大屏整体风格。助睿Max的下拉多选组件是最常用的筛选器类型:占用空间小、选项清晰、支持搜索,适合浏览器数量不多(6个)但需要灵活选择的场景。另外也可以使用选项卡组件,但下拉框更节省空间,适合放在大屏顶部或侧边栏。
助睿Max筛选器组件:
助睿Max 提供了下拉框、下拉多选、单选框、时间选择器、选项卡等多种交互组件,均支持自定义选项、默认值、样式(边框、背景、字体颜色等),并可与多个图表联动,实现筛选后所有图表数据自动刷新。本实验使用下拉多选组件,默认选中"全部浏览器"。
实验步骤:
(1)在大屏顶部右侧合适位置,添加"下拉选择"组件(位于"交互"组件分类中),重命名为"浏览器筛选",调整组件位置和大小
(2)在组件右侧属性面板中,调整样式如下:
6 预览与总结
最后,点击"保存"并"预览",检查整体布局是否协调、组件是否对齐、颜色是否一致。助睿Max支持一键全屏预览:
至此,浏览器用户画像分析大屏的静态布局已全部完成。本实验充分利用了助睿Max的丰富组件、图层堆叠管理、丰富的样式配置、以及地图、翻牌器、轮播饼图等特色组件,实现了专业级的数据大屏设计。下一实验我们将进入蓝图编辑器,为这些静态组件绑定真实数据,让大屏"活"起来。
6.2
1 实验目的
本实验基于上一实验《浏览器用户画像分析-大屏静态布局制作》完成的大屏布局,使用助睿Max的蓝图编辑器,将之前实验加工好的用户画像数据表接入到大屏的各个图表组件中,并配置筛选器实现多浏览器联动。
通过本实验,学生应掌握:
- 理解蓝图编辑器的基本概念(数据源、触发器、动作、并行数据处理)
- 使用并行数据处理节点接收筛选器参数并分发给多个SQL请求节点
- 为不同图表组件编写带参数的SQL查询语句
- 配置筛选器与图表的联动交互
2 实验环境
- 实验平台:助睿在线实验平台 https://lab.guilian.cn/
本次实验使用助睿数智(Uniplore)作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。
助睿数智官网为 https://www.uniplore.com//
- 可视化工具:助睿Max(数据大屏)
助睿Max 是低代码数据可视化平台,支持零代码拖拽搭建、多种图表组件、地图可视化、交互筛选等能力,适用于业务监控、用户洞察、营销战报等场景。
助睿Max核心优势:
- 组件丰富:覆盖所有常见图表和交互控件,满足企业级可视化需求
- 图层管理:支持图层堆叠、锁定、隐藏、排序,复杂布局轻松实现
- 低代码操作:拖拽式搭建 + 蓝图编辑器,无需复杂编程即可完成大屏布局与数据交互配置
- 工业级数据处理能力:支持海量数据实时接入与渲染,千万级数据点秒级响应,满足企业级生产环境要求
- 支持数字孪生:支持3D场景、GIS地图、实时物联数据接入,可快速构建数字孪生可视化系统
- 数据来源:团队私有数据库(MySQL)
本实验将重点使用蓝图编辑器完成数据接入与筛选器联动配置。
3 实验数据
本实验使用上一阶段加工完成的 user_profile_stats 表,该表结构如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| browser_name | VARCHAR(50) | 浏览器名称 |
| gender | VARCHAR(10) | 性别 |
| age_group | VARCHAR(10) | 年龄段 |
| edu | VARCHAR(50) | 学历 |
| job | VARCHAR(50) | 职业 |
| income | VARCHAR(50) | 收入 |
| city_type | VARCHAR(10) | 居住地类型 |
| province | VARCHAR(50) | 省份 |
| user_count | INT | 用户数 |
4 整体蓝图逻辑说明
4.1 什么是蓝图编辑器?
蓝图编辑器是助睿Max中用于配置数据流和交互逻辑的可视化编程工具。它采用"节点-连线"的方式,帮助您自由管理可视化应用中多个组件之间的交互关系。
蓝图编辑器的优势:
- 蓝图编辑器可以保证交互和数据的实时性和同步性。
- 蓝图编辑器支持数据请求合并和数据分发的功能。
- 蓝图编辑器可模块化拆分,只需要专注于业务规则和交互需求即可。
4.2 核心概念
| 概念 | 说明 |
|---|---|
| 数据源 | 数据库连接配置,定义数据从哪里来 |
| 查询 | SQL语句,定义取什么数据 |
| 触发器 | 触发数据加载的事件(如页面加载、组件点击、定时刷新等) |
| 动作 | 触发器执行后的操作(如查询数据、刷新图表) |
| 变量 | 用于在查询之间传递参数(如筛选器选中的浏览器名称) |
4.3 核心流程
- 页面加载或用户选择浏览器 → 触发两个SQL请求:
- 维度数据SQL:查询性别、年龄、学历、职业、收入、居住地类型、省份分布。
- 核心指标SQL:查询总用户数、平均年龄、本科及以上占比、中高收入占比。
- 浏览器筛选器 → 将选中的浏览器值传递给两个SQL请求节点。
- 维度数据分发:通过一个并行数据处理节点,按 dimension_type 分发到各个图表。
- 核心指标分发:通过另一个并行数据处理节点,将单行多列的指标数据拆分为四个独立数值,分别发送给四个指标卡。
- 各图表组件接收数据并展示。
4.4 各节点职责
| 节点 | 职责 |
|---|---|
| 页面加载 | 大屏打开时自动触发一次数据加载 |
| 浏览器筛选器 | 用户选择浏览器后,触发数据刷新,并将选中的浏览器值传递给下游 |
| 浏览器参数接收 | 并行数据处理节点,接收筛选器参数,存储到全局变量 |
| 维度数据SQL请求 | 一次性查询所有维度数据(性别、年龄、学历、职业、收入、居住地类型、省份),输出格式 (dimension_type, name, value) |
| 核心指标SQL请求 | 查询四个核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比),输出单行多列格式 |
| 维度数据分发 | 并行数据处理节点,按 dimension_type 过滤,格式化后分发给7个图表 |
| 核心指标分发 | 并行数据处理节点,将单行多列数据拆分为四个独立数值,分发给四个指标卡 |
| 各图表组件 | 接收数据并渲染 |
4.5 本实验范围说明
本次实验只做全国范围的数据展示,包括:
- 全国省份地图(各省份用户数分布)
- 全国核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比)
- 全国各维度分布(性别、年龄、学历、职业、收入、居住地类型)
点击省份查看该省份核心指标数据将在下一实验中完成。
4.6 完整蓝图连接示意图
助睿Max蓝图编辑器亮点:通过拖拽节点、连线即可完成复杂的交互逻辑,无需编写复杂代码。并行数据处理节点支持一个数据源同时分发到多个图表,实现高效的数据复用。
节点连线说明:
| 起点节点 | 终点节点 | 连线含义 |
|---|---|---|
| 页面加载(页面初始化完成) | 浏览器参数接收(输入) | 大屏打开时触发参数初始化 |
| 浏览器筛选器(下拉框内容被选中) | 浏览器参数接收(输入) | 用户选择浏览器后触发 |
| 浏览器参数接收(输出) | 维度数据SQL请求(执行SQL) | 传递浏览器参数 |
| 浏览器参数接收(输出) | 核心指标SQL请求(执行SQL) | 传递浏览器参数 |
| 维度数据SQL请求(执行成功) | 维度数据分发(输入) | 将维度数据传给分发节点 |
| 核心指标SQL请求(执行成功) | 核心指标分发(输入) | 将核心指标数据传给分发节点 |
| 维度数据分发(分支1-7) | 各维度图表(导入数据接口) | 性别、年龄、学历等数据 |
| 核心指标分发(分支1-4) | 四个指标卡(导入数据接口) | 总用户数、平均年龄等 |
5 实验步骤
5.1 前置准备:添加年龄字段
在用户画像大屏中,我们需要展示平均年龄这一核心指标。原有的 user_profile_stats 表中只有年龄段(age_group)字段,没有精确年龄。如果使用年龄段中值估算平均年龄(如 26-35 岁取 30.5 岁),会存在一定误差。
为了更准确地计算平均年龄,我们需要在 user_profile_stats 表中增加一个 age 字段。
修改目标表:
在团队私有数据库中执行以下SQL:
DROP TABLE IF EXISTS `user_profile_stats`;
CREATE TABLE `user_profile_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`gender` VARCHAR(10) COMMENT '性别',
`age` INT NOT NULL COMMENT '年龄',
`age_group` VARCHAR(10) COMMENT '年龄段',
`edu` VARCHAR(50) COMMENT '学历',
`job` VARCHAR(50) COMMENT '职业',
`income` VARCHAR(50) COMMENT '收入',
`city_type` VARCHAR(10) COMMENT '居住地类型',
`province` VARCHAR(50) COMMENT '省份',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
修改转换流,在分组聚合中保留 age 字段:
打开"用户画像表加工"转换流,做以下修改:
① 修改排序记录组件,增加 age 字段的升序排序
② 修改分组组件,分组字段更加 age
③ 执行转换流
5.2 组件导出到蓝图编辑器
上周的实验【浏览器市场分析-大屏数据接入】已经介绍了如何连接数据源,本实验不再教学。
只有当组件导入到蓝图编辑器后,才可以为该组件配置交互。
打开上一实验制作的"用户画像"数据大屏,在画布编辑器内,右键单击左侧图层栏或中间画布区的组件,选择导出到蓝图编辑器,即可将对应组件导出到蓝图编辑器中。
将以下组件依次导出到蓝图编辑器:
- 浏览器筛选器(下拉多选)
- 性别分布饼图
- 年龄段分布柱状图
- 学历分布条形图
- 职业分布柱状图
- 收入分布柱状图
- 居住地类型饼图
- 用户省份分布地图
- 省份排行榜(轮播列表)
- 核心指标卡(总用户数、平均年龄、中高收入占比)
导出成功后,单击"蓝图编辑器"图标切换到蓝图编辑器 页面,可在导入节点列表中查看对应的节点。列表内所有节点都可供后续配置交互使用。
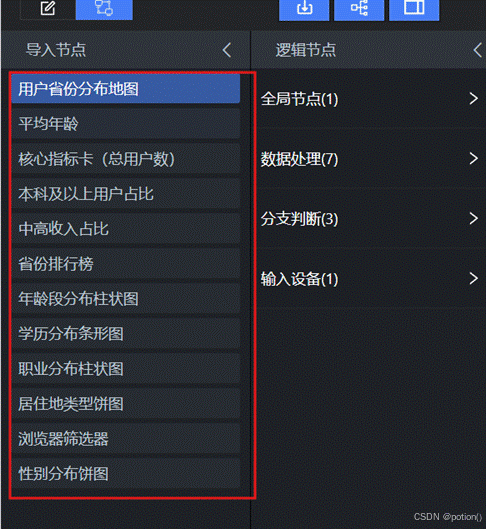
5.3 添加浏览器参数接收节点(并行数据处理)
大屏上的浏览器筛选器让用户可以选择某个具体的浏览器。当用户切换选择时,地图、饼图、柱状图等所有图表的数据都需要跟着变。
怎么实现这种联动呢?筛选器本身只能输出"我选中了哪个值",它不知道接下来要干什么。所以需要一个中间节点来做两件事:记住用户选中的浏览器,然后告诉SQL请求去查新数据。
这个节点就是"浏览器参数接收",它用"并行数据处理"组件来实现。
双击节点,添加两个处理方法:
方法一(页面加载时执行一次,设置基础URL)
const BASE_URL = 'https://lab.guilian.cn';
window.GLOBAL_BASE_URL = BASE_URL;
return data;
这个方法主要是为后续可能用到的外部API预留一个基础地址,本实验用不上,但保留结构。
方法二(每次筛选器变化时执行,接收浏览器参数)
const SELECTED_BROWSER = data.value;
window.GLOBAL_SELECTED_BROWSER = SELECTED_BROWSER;
return { value: SELECTED_BROWSER };
这个方法把用户选中的浏览器存到 window.GLOBAL_SELECTED_BROWSER 这个全局变量里。后面的SQL请求节点只要读取这个变量,就知道该查哪个浏览器的数据了。
连好线之后,整个流程是这样的:
- 大屏打开 → 页面加载触发 → 节点初始化
- 用户切换浏览器 → 筛选器输出新值 → 节点更新全局变量 → SQL重新执行 → 所有图表刷新
其中,浏览器的选项我们可以直接使用静态数据(因为个数不多):title为前端显示内容,value为实际查询内容,即数据库中存储的对应 browser_name,如:
{
"title": "IE浏览器",
"value": "IE浏览器"
}
我们需要填写6个浏览器的对应内容,并刷新数据,同时,输入框中默认选中设置为"IE浏览器"
这样,一个筛选器就同时控制了所有图表。
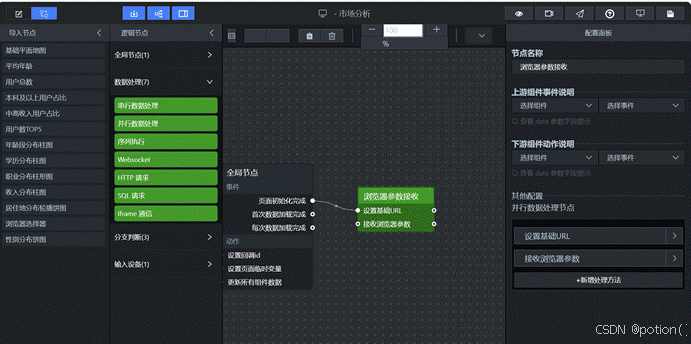
5.4 添加SQL请求节点(一次除指标外所有维度数据)
这个节点负责查询性别、年龄、学历、职业、收入、居住地类型、省份等维度数据,使用 UNION ALL 合并,输出格式为 (dimension_type, name, value)。
添加"SQL请求"节点,重命名为"维度数据SQL请求",查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 性别分布
select
'gender' as dimension_type,
gender as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by gender
union all
-- 年龄段分布
select
'age' as dimension_type,
age_group as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by age_group
union all
-- 学历分布
select
'edu' as dimension_type,
edu as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by edu
union all
-- 职业分布
select
'job' as dimension_type,
job as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by job
union all
-- 收入分布
select
'income' as dimension_type,
income as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by income
union all
-- 居住地类型分布
select
'city_type' as dimension_type,
city_type as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by city_type
union all
-- 省份分布
select
'province' as dimension_type,
province as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by province
`;
return sql
这个 SQL 用了 UNION ALL 把所有属性维度的数据一次性查出来,每条记录都带一个 dimension_type 字段来标记它属于哪个维度。这样一次查询就能拿到所有图表需要的数据,不用每个图表单独发请求。
由于筛选器只能选单个浏览器,SQL 中直接用 where browser_name = '${selectedBrowser}' 即可,不需要处理"全部浏览器"的情况。
5.5 添加核心指标SQL请求节点(单独查询四个指标)
这个节点只查询四个核心指标,输出单行多列格式(一行包含四个字段),不需要 UNION ALL,取值更简单。
添加"SQL请求"节点,重命名为"核心指标SQL请求",查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比)
select
'total_users' as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
`;
return sql
5.6 添加维度数据分发节点(并行数据处理)
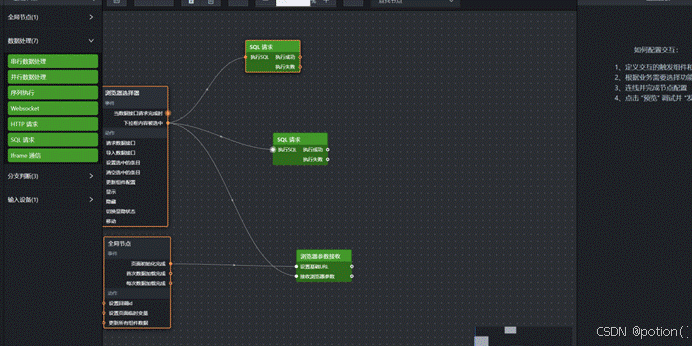
上一步SQL查出来的是一张包含所有维度数据的大表,但每个图表只需要其中一部分:性别饼图只看 dimension_type='gender' 的数据,年龄柱状图只看 dimension_type='age' 的数据,以此类推。
所以需要一个分发节点,把数据按 dimension_type 拆开,分别送给对应的图表。这个节点也用"并行数据处理"来实现。
添加"并行数据处理"节点,重命名为"数据分发"。将SQL请求节点的"执行成功"连接到该节点。
双击节点,为每个图表添加一个处理方法:
分支1:性别分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'gender');
return filtered.map(item => ({
name: item.name,
value: item.value
}));
分支2:年龄段分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'age');
var order = '\<18', '18-25', '26-35', '36-45', '\>45';
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));
分支3:学历分布(条形图)
var filtered = data.filter(item => item.dimension_type === 'edu');
var order = '小学及以下', '初中', '高中/中专/技校', '大专', '大学本科', '硕士及以上';
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '学历'
}));
分支4:职业分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'job');
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '职业'
}));
分支5:收入分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'income');
// 按收入金额升序排序(提取数字进行比较)
filtered.sort((a, b) => {
// 提取收入段中的最小金额
var getMinIncome = (incomeStr) => {
// 处理 "无收入"、"500元及以下" 等特殊情况
if (incomeStr === '无收入') return -1;
if (incomeStr === '500元及以下') return 0;
// 提取数字,如 "1501~2000元" 提取 1501
var match = incomeStr.match(/(\d+)/);
return match ? parseInt(match1) : 999999;
};
return getMinIncome(a.name) - getMinIncome(b.name);
});
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '收入'
}));
分支6:居住地类型分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'city_type');
return filtered.map(item => ({
name: item.name === 'unknown' ? '未知' : item.name,
value: item.value
}));
分支7:省份排行榜TOP5
这里需要注意,轮播列表的映射字段是通过"数据系列"中的系列1、系列2来决定的
/ 过滤出省份数据
var filtered = data.filter(item => item.dimension_type === 'province');
// 按用户数降序排序
filtered.sort((a, b) => b.value - a.value);
// 取前5条
var top5 = filtered.slice(0, 5);
// 直接返回组件需要的字段名
return top5.map(item => ({
province: item.name,
user_count: item.value
}));
以上的输出结果不正确的话,可以在最终输出结果的节点的处理方法代码中添加以下代码,查看返回的数据:
// console.log("返回的数据",data)
5.7 添加核心指标分发节点(并行数据处理)
添加另一个"并行数据处理"节点,重命名为"核心指标分发"。将"核心指标SQL请求"节点的"执行成功"连接到该节点。
SQL 返回的是四行数据,而四个指标卡每个只需要一个数值。通过"并行数据处理"节点,我们按 name 字段过滤,将每个指标单独输出给对应的指标卡。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');
return { value: item ? item.value : 0 };
其他分支类似,只需修改 item.name === 'total_users'的条件即可
5.8 连接节点
按照4.6节的蓝图连接示意图,依次连接所有节点:
- 页面加载 → 浏览器参数接收(输入)
- 浏览器筛选器 → 浏览器参数接收(输入)
- 浏览器筛选器 → 维度数据SQL请求(执行SQL)
- 浏览器筛选器 → 核心指标SQL请求(执行SQL)
- 维度数据SQL请求(执行成功) → 维度数据分发(输入)
- 核心指标SQL请求(执行成功) → 核心指标分发(输入)
- 维度数据分发(分支1-8) → 各维度图表组件(导入数据接口)
- 核心指标分发(分支1-4) → 四个核心指标卡(导入数据接口)
++1912×966 142 KB++
5.9 保存与预览
点击蓝图编辑器右上角的"保存"按钮,然后返回大屏,点击"预览"。
测试功能:
- 大屏打开时,默认显示第一个浏览器的用户画像数据(如下拉框默认选中的浏览器)
- 选择其他浏览器,所有图表应刷新为新浏览器的数据
- 观察地图、饼图、柱状图是否都随筛选器变化
++1920×1080 372 KB++
1 实验目的
本实验基于上一实验《浏览器用户画像分析-大屏静态布局制作》完成的大屏布局,使用助睿Max的蓝图编辑器,将之前实验加工好的用户画像数据表接入到大屏的各个图表组件中,并配置筛选器实现多浏览器联动。
通过本实验,学生应掌握:
- 理解蓝图编辑器的基本概念(数据源、触发器、动作、并行数据处理)
- 使用并行数据处理节点接收筛选器参数并分发给多个SQL请求节点
- 为不同图表组件编写带参数的SQL查询语句
- 配置筛选器与图表的联动交互
2 实验环境
- 实验平台:助睿在线实验平台 https://lab.guilian.cn/
本次实验使用助睿数智(Uniplore)作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。
助睿数智官网为 https://www.uniplore.com//
- 可视化工具:助睿Max(数据大屏)
助睿Max 是低代码数据可视化平台,支持零代码拖拽搭建、多种图表组件、地图可视化、交互筛选等能力,适用于业务监控、用户洞察、营销战报等场景。
助睿Max核心优势:
- 组件丰富:覆盖所有常见图表和交互控件,满足企业级可视化需求
- 图层管理:支持图层堆叠、锁定、隐藏、排序,复杂布局轻松实现
- 低代码操作:拖拽式搭建 + 蓝图编辑器,无需复杂编程即可完成大屏布局与数据交互配置
- 工业级数据处理能力:支持海量数据实时接入与渲染,千万级数据点秒级响应,满足企业级生产环境要求
- 支持数字孪生:支持3D场景、GIS地图、实时物联数据接入,可快速构建数字孪生可视化系统
- 数据来源:团队私有数据库(MySQL)
本实验将重点使用蓝图编辑器完成数据接入与筛选器联动配置。
3 实验数据
本实验使用上一阶段加工完成的 user_profile_stats 表,该表结构如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| browser_name | VARCHAR(50) | 浏览器名称 |
| gender | VARCHAR(10) | 性别 |
| age_group | VARCHAR(10) | 年龄段 |
| edu | VARCHAR(50) | 学历 |
| job | VARCHAR(50) | 职业 |
| income | VARCHAR(50) | 收入 |
| city_type | VARCHAR(10) | 居住地类型 |
| province | VARCHAR(50) | 省份 |
| user_count | INT | 用户数 |
4 整体蓝图逻辑说明
4.1 什么是蓝图编辑器?
蓝图编辑器是助睿Max中用于配置数据流和交互逻辑的可视化编程工具。它采用"节点-连线"的方式,帮助您自由管理可视化应用中多个组件之间的交互关系。
蓝图编辑器的优势:
- 蓝图编辑器可以保证交互和数据的实时性和同步性。
- 蓝图编辑器支持数据请求合并和数据分发的功能。
- 蓝图编辑器可模块化拆分,只需要专注于业务规则和交互需求即可。
4.2 核心概念
| 概念 | 说明 |
|---|---|
| 数据源 | 数据库连接配置,定义数据从哪里来 |
| 查询 | SQL语句,定义取什么数据 |
| 触发器 | 触发数据加载的事件(如页面加载、组件点击、定时刷新等) |
| 动作 | 触发器执行后的操作(如查询数据、刷新图表) |
| 变量 | 用于在查询之间传递参数(如筛选器选中的浏览器名称) |
4.3 核心流程
- 页面加载或用户选择浏览器 → 触发两个SQL请求:
- 维度数据SQL:查询性别、年龄、学历、职业、收入、居住地类型、省份分布。
- 核心指标SQL:查询总用户数、平均年龄、本科及以上占比、中高收入占比。
- 浏览器筛选器 → 将选中的浏览器值传递给两个SQL请求节点。
- 维度数据分发:通过一个并行数据处理节点,按 dimension_type 分发到各个图表。
- 核心指标分发:通过另一个并行数据处理节点,将单行多列的指标数据拆分为四个独立数值,分别发送给四个指标卡。
- 各图表组件接收数据并展示。
4.4 各节点职责
| 节点 | 职责 |
|---|---|
| 页面加载 | 大屏打开时自动触发一次数据加载 |
| 浏览器筛选器 | 用户选择浏览器后,触发数据刷新,并将选中的浏览器值传递给下游 |
| 浏览器参数接收 | 并行数据处理节点,接收筛选器参数,存储到全局变量 |
| 维度数据SQL请求 | 一次性查询所有维度数据(性别、年龄、学历、职业、收入、居住地类型、省份),输出格式 (dimension_type, name, value) |
| 核心指标SQL请求 | 查询四个核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比),输出单行多列格式 |
| 维度数据分发 | 并行数据处理节点,按 dimension_type 过滤,格式化后分发给7个图表 |
| 核心指标分发 | 并行数据处理节点,将单行多列数据拆分为四个独立数值,分发给四个指标卡 |
| 各图表组件 | 接收数据并渲染 |
4.5 本实验范围说明
本次实验只做全国范围的数据展示,包括:
- 全国省份地图(各省份用户数分布)
- 全国核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比)
- 全国各维度分布(性别、年龄、学历、职业、收入、居住地类型)
点击省份查看该省份核心指标数据将在下一实验中完成。
4.6 完整蓝图连接示意图
助睿Max蓝图编辑器亮点:通过拖拽节点、连线即可完成复杂的交互逻辑,无需编写复杂代码。并行数据处理节点支持一个数据源同时分发到多个图表,实现高效的数据复用。
节点连线说明:
| 起点节点 | 终点节点 | 连线含义 |
|---|---|---|
| 页面加载(页面初始化完成) | 浏览器参数接收(输入) | 大屏打开时触发参数初始化 |
| 浏览器筛选器(下拉框内容被选中) | 浏览器参数接收(输入) | 用户选择浏览器后触发 |
| 浏览器参数接收(输出) | 维度数据SQL请求(执行SQL) | 传递浏览器参数 |
| 浏览器参数接收(输出) | 核心指标SQL请求(执行SQL) | 传递浏览器参数 |
| 维度数据SQL请求(执行成功) | 维度数据分发(输入) | 将维度数据传给分发节点 |
| 核心指标SQL请求(执行成功) | 核心指标分发(输入) | 将核心指标数据传给分发节点 |
| 维度数据分发(分支1-7) | 各维度图表(导入数据接口) | 性别、年龄、学历等数据 |
| 核心指标分发(分支1-4) | 四个指标卡(导入数据接口) | 总用户数、平均年龄等 |
5 实验步骤
5.1 前置准备:添加年龄字段
在用户画像大屏中,我们需要展示平均年龄这一核心指标。原有的 user_profile_stats 表中只有年龄段(age_group)字段,没有精确年龄。如果使用年龄段中值估算平均年龄(如 26-35 岁取 30.5 岁),会存在一定误差。
为了更准确地计算平均年龄,我们需要在 user_profile_stats 表中增加一个 age 字段。
修改目标表:
在团队私有数据库中执行以下SQL:
DROP TABLE IF EXISTS `user_profile_stats`;
CREATE TABLE `user_profile_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`gender` VARCHAR(10) COMMENT '性别',
`age` INT NOT NULL COMMENT '年龄',
`age_group` VARCHAR(10) COMMENT '年龄段',
`edu` VARCHAR(50) COMMENT '学历',
`job` VARCHAR(50) COMMENT '职业',
`income` VARCHAR(50) COMMENT '收入',
`city_type` VARCHAR(10) COMMENT '居住地类型',
`province` VARCHAR(50) COMMENT '省份',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
修改转换流,在分组聚合中保留 age 字段:
打开"用户画像表加工"转换流,做以下修改:
① 修改排序记录组件,增加 age 字段的升序排序
② 修改分组组件,分组字段更加 age
③ 执行转换流
5.2 组件导出到蓝图编辑器
上周的实验【浏览器市场分析-大屏数据接入】已经介绍了如何连接数据源,本实验不再教学。
只有当组件导入到蓝图编辑器后,才可以为该组件配置交互。
打开上一实验制作的"用户画像"数据大屏,在画布编辑器内,右键单击左侧图层栏或中间画布区的组件,选择导出到蓝图编辑器,即可将对应组件导出到蓝图编辑器中。
将以下组件依次导出到蓝图编辑器:
- 浏览器筛选器(下拉多选)
- 性别分布饼图
- 年龄段分布柱状图
- 学历分布条形图
- 职业分布柱状图
- 收入分布柱状图
- 居住地类型饼图
- 用户省份分布地图
- 省份排行榜(轮播列表)
- 核心指标卡(总用户数、平均年龄、中高收入占比)
导出成功后,单击"蓝图编辑器"图标切换到蓝图编辑器 页面,可在导入节点列表中查看对应的节点。列表内所有节点都可供后续配置交互使用。
++1920×945 122 KB++
5.3 添加浏览器参数接收节点(并行数据处理)
大屏上的浏览器筛选器让用户可以选择某个具体的浏览器。当用户切换选择时,地图、饼图、柱状图等所有图表的数据都需要跟着变。
怎么实现这种联动呢?筛选器本身只能输出"我选中了哪个值",它不知道接下来要干什么。所以需要一个中间节点来做两件事:记住用户选中的浏览器,然后告诉SQL请求去查新数据。
这个节点就是"浏览器参数接收",它用"并行数据处理"组件来实现。
双击节点,添加两个处理方法:
方法一(页面加载时执行一次,设置基础URL)
const BASE_URL = 'https://lab.guilian.cn';
window.GLOBAL_BASE_URL = BASE_URL;
return data;
这个方法主要是为后续可能用到的外部API预留一个基础地址,本实验用不上,但保留结构。
方法二(每次筛选器变化时执行,接收浏览器参数)
const SELECTED_BROWSER = data.value;
window.GLOBAL_SELECTED_BROWSER = SELECTED_BROWSER;
return { value: SELECTED_BROWSER };
这个方法把用户选中的浏览器存到 window.GLOBAL_SELECTED_BROWSER 这个全局变量里。后面的SQL请求节点只要读取这个变量,就知道该查哪个浏览器的数据了。
连好线之后,整个流程是这样的:
- 大屏打开 → 页面加载触发 → 节点初始化
- 用户切换浏览器 → 筛选器输出新值 → 节点更新全局变量 → SQL重新执行 → 所有图表刷新
其中,浏览器的选项我们可以直接使用静态数据(因为个数不多):title为前端显示内容,value为实际查询内容,即数据库中存储的对应 browser_name,如:
{
"title": "IE浏览器",
"value": "IE浏览器"
}
我们需要填写6个浏览器的对应内容,并刷新数据,同时,输入框中默认选中设置为"IE浏览器"
++324×449 6.35 KB++
++325×487 9.05 KB++
这样,一个筛选器就同时控制了所有图表。
++1920×945 128 KB++
5.4 添加SQL请求节点(一次除指标外所有维度数据)
这个节点负责查询性别、年龄、学历、职业、收入、居住地类型、省份等维度数据,使用 UNION ALL 合并,输出格式为 (dimension_type, name, value)。
添加"SQL请求"节点,重命名为"维度数据SQL请求",查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 性别分布
select
'gender' as dimension_type,
gender as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by gender
union all
-- 年龄段分布
select
'age' as dimension_type,
age_group as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by age_group
union all
-- 学历分布
select
'edu' as dimension_type,
edu as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by edu
union all
-- 职业分布
select
'job' as dimension_type,
job as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by job
union all
-- 收入分布
select
'income' as dimension_type,
income as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by income
union all
-- 居住地类型分布
select
'city_type' as dimension_type,
city_type as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by city_type
union all
-- 省份分布
select
'province' as dimension_type,
province as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by province
`;
return sql
这个 SQL 用了 UNION ALL 把所有属性维度的数据一次性查出来,每条记录都带一个 dimension_type 字段来标记它属于哪个维度。这样一次查询就能拿到所有图表需要的数据,不用每个图表单独发请求。
由于筛选器只能选单个浏览器,SQL 中直接用 where browser_name = '${selectedBrowser}' 即可,不需要处理"全部浏览器"的情况。
++318×434 9.14 KB++
5.5 添加核心指标SQL请求节点(单独查询四个指标)
这个节点只查询四个核心指标,输出单行多列格式(一行包含四个字段),不需要 UNION ALL,取值更简单。
添加"SQL请求"节点,重命名为"核心指标SQL请求",查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比)
select
'total_users' as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
`;
return sql
5.6 添加维度数据分发节点(并行数据处理)
上一步SQL查出来的是一张包含所有维度数据的大表,但每个图表只需要其中一部分:性别饼图只看 dimension_type='gender' 的数据,年龄柱状图只看 dimension_type='age' 的数据,以此类推。
所以需要一个分发节点,把数据按 dimension_type 拆开,分别送给对应的图表。这个节点也用"并行数据处理"来实现。
添加"并行数据处理"节点,重命名为"数据分发"。将SQL请求节点的"执行成功"连接到该节点。
双击节点,为每个图表添加一个处理方法:
分支1:性别分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'gender');
return filtered.map(item => ({
name: item.name,
value: item.value
}));
分支2:年龄段分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'age');
var order = '\<18', '18-25', '26-35', '36-45', '\>45';
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));
分支3:学历分布(条形图)
var filtered = data.filter(item => item.dimension_type === 'edu');
var order = '小学及以下', '初中', '高中/中专/技校', '大专', '大学本科', '硕士及以上';
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '学历'
}));
分支4:职业分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'job');
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '职业'
}));
分支5:收入分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'income');
// 按收入金额升序排序(提取数字进行比较)
filtered.sort((a, b) => {
// 提取收入段中的最小金额
var getMinIncome = (incomeStr) => {
// 处理 "无收入"、"500元及以下" 等特殊情况
if (incomeStr === '无收入') return -1;
if (incomeStr === '500元及以下') return 0;
// 提取数字,如 "1501~2000元" 提取 1501
var match = incomeStr.match(/(\d+)/);
return match ? parseInt(match1) : 999999;
};
return getMinIncome(a.name) - getMinIncome(b.name);
});
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '收入'
}));
分支6:居住地类型分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'city_type');
return filtered.map(item => ({
name: item.name === 'unknown' ? '未知' : item.name,
value: item.value
}));
分支7:省份排行榜TOP5
这里需要注意,轮播列表的映射字段是通过"数据系列"中的系列1、系列2来决定的
/ 过滤出省份数据
var filtered = data.filter(item => item.dimension_type === 'province');
// 按用户数降序排序
filtered.sort((a, b) => b.value - a.value);
// 取前5条
var top5 = filtered.slice(0, 5);
// 直接返回组件需要的字段名
return top5.map(item => ({
province: item.name,
user_count: item.value
}));
以上的输出结果不正确的话,可以在最终输出结果的节点的处理方法代码中添加以下代码,查看返回的数据:
// console.log("返回的数据",data)
5.7 添加核心指标分发节点(并行数据处理)
添加另一个"并行数据处理"节点,重命名为"核心指标分发"。将"核心指标SQL请求"节点的"执行成功"连接到该节点。
SQL 返回的是四行数据,而四个指标卡每个只需要一个数值。通过"并行数据处理"节点,我们按 name 字段过滤,将每个指标单独输出给对应的指标卡。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');
return { value: item ? item.value : 0 };
其他分支类似,只需修改 item.name === 'total_users'的条件即可
5.8 连接节点
按照4.6节的蓝图连接示意图,依次连接所有节点:
- 页面加载 → 浏览器参数接收(输入)
- 浏览器筛选器 → 浏览器参数接收(输入)
- 浏览器筛选器 → 维度数据SQL请求(执行SQL)
- 浏览器筛选器 → 核心指标SQL请求(执行SQL)
- 维度数据SQL请求(执行成功) → 维度数据分发(输入)
- 核心指标SQL请求(执行成功) → 核心指标分发(输入)
- 维度数据分发(分支1-8) → 各维度图表组件(导入数据接口)
- 核心指标分发(分支1-4) → 四个核心指标卡(导入数据接口)
++1912×966 142 KB++
5.9 保存与预览
点击蓝图编辑器右上角的"保存"按钮,然后返回大屏,点击"预览"。
测试功能:
- 大屏打开时,默认显示第一个浏览器的用户画像数据(如下拉框默认选中的浏览器)
- 选择其他浏览器,所有图表应刷新为新浏览器的数据
- 观察地图、饼图、柱状图是否都随筛选器变化
6.3
1 实验目的
本实验基于前两个实验完成的市场分析大屏和用户画像大屏,使用助睿Max的蓝图编辑器,配置两个大屏之间的切换交互,以及地图省份点击联动指标卡的功能。
通过本实验,学生应掌握:
- 使用图层可见性控制实现大屏内容切换
- 使用按钮组件配置页面跳转或内容显示/隐藏
- 使用地图组件的交互事件,实现省份下钻联动
- 配置指标卡组件根据地图点击动态更新数据
2 实验环境
实验平台:助睿在线实验平台 https://lab.guilian.cn/
可视化工具:助睿Max(数据大屏)
数据来源:团队私有数据库(MySQL)
3 整体交互逻辑说明
3.1 大屏切换逻辑
市场分析和用户画像两个大屏实际上是在同一个大屏文件中,通过控制图层的可见性来实现切换。
实现原理:通过 tab列表组件实现。将市场分析的所有组件放入"市场分析组",用户画像的所有组件放入"用户画像组"。tab列表组件设置2列("市场分析"和"用户画像"),每列设置不同的ID(如 "id": 1 和 "id": 2),背景设为透明以融合导航栏样式。点击某列时,根据ID控制两个组的可见性:显示对应组,隐藏另一组。
助睿Max图层管理优势:通过"图层"面板可以轻松控制组件的显示/隐藏,无需编写代码。配合蓝图编辑器,可以实现按钮与图层可见性的联动。
3.2 地图省份点击联动逻辑
在用户画像大屏中,点击地图上的某个省份时,右侧的四个核心指标卡(总用户数、平均年龄、本科及以上占比、中高收入占比)需要更新为该省份的数据。
用户点击省份 → 地图组件触发"点击区域"事件 → 蓝图接收省份名称 → SQL请求查询该省份的核心指标 → 指标卡刷新数据
4 整体蓝图逻辑说明
4.1 什么是蓝图编辑器?
蓝图编辑器是助睿Max中用于配置数据流和交互逻辑的可视化编程工具。它采用"节点-连线"的方式,帮助您自由管理可视化应用中多个组件之间的交互关系。
蓝图编辑器的优势:
- 蓝图编辑器可以保证交互和数据的实时性和同步性。
- 蓝图编辑器支持数据请求合并和数据分发的功能。
- 蓝图编辑器可模块化拆分,专注单个的交互链路,不需要考虑代码的整理和规范,只需要专注于业务规则和交互需求即可。
4.2 核心概念

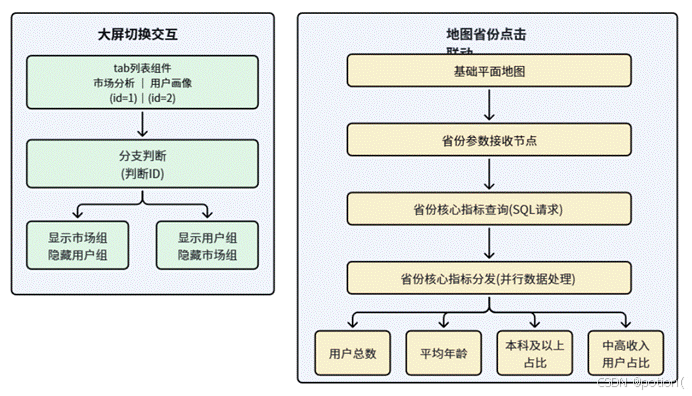
4.3 核心流程(大屏切换)
- 用户点击tab列表中的"市场分析"列 → 触发点击事件,输出ID 1
- 蓝图接收ID → 设置"市场分析组"可见,设置"用户画像组"隐藏
- 用户点击tab列表中的"用户画像"列 → 触发点击事件,输出ID 2
- 蓝图接收ID → 设置"市场分析组"隐藏,设置"用户画像组"可见
4.4 核心流程(地图点击联动)
- 用户点击地图上的省份区域 → 触发"点击区域"事件
- 地图组件 → 输出被点击的省份名称
- 省份参数接收节点 → 接收省份名称,存储到全局变量
- 省份核心指标查询节点 → 读取省份名称和当前浏览器,查询该省份的核心指标
- 省份核心指标分发节点 → 将查询结果拆分为4个独立数值
- 四个核心指标卡 → 接收新数据并刷新显示
4.5 各节点职责

4.5 完整蓝图连接示意图
助睿Max蓝图编辑器亮点:通过拖拽节点、连线即可完成复杂的交互逻辑,无需编写复杂代码。并行数据处理节点支持一个数据源同时分发到多个图表,实现高效的数据复用。
5 实验步骤
5.1 配置大屏切换
实现原理:
Tab列表组件是一个可自定义选项的交互组件。助睿Max的Tab列表组件内置了丰富的样式自定义选项(背景色、字体、选中态颜色等),无需额外CSS即可实现美观的导航栏。Tab列表组件点击时会触发"当Tab点击时"事件,并输出被点击项的ID。通过分支判断节点判断ID,然后分别执行"设置图层可见性"动作,即可实现两组内容的切换。
本实验将Tab列表组件设置为2列,与两个导航按钮的大小、位置重合,分别代表"市场分析"和"用户画像"。通过为每列设置唯一的ID,点击时即可区分用户的选择,从而实现不同内容的切换。
操作步骤:
- 添加Tab列表组件,调整大小、位置,两个导航按钮重合
- Tab列表组件的基本设置中,设置行数为1,列数为2,再标签默认配置中,将"背景颜色"、"选中背景色"、"悬浮背景色"的透明度设置为0,这样就看不见Tab列表组件,给用户的感觉就是只有2个按钮
(3)设置Tab列表组件每个选项的id:在数据中,保留2列数据,id分别为1、2,content为空,设置后记得刷新数据
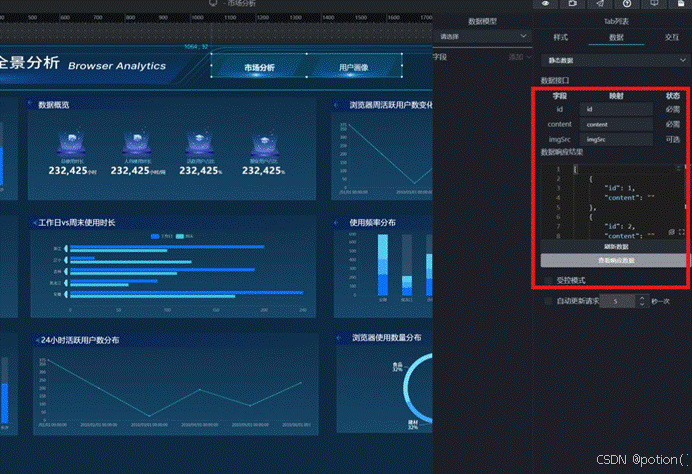
(4)将"市场分析"组、"用户画像"组、Tab列表组件导出到蓝图编辑器
(5)在蓝图编辑器中,将"市场分析"组、"用户画像"组、Tab列表组件添加到蓝图编辑器画布中,通过"分支判断"节点来做"当Tab点击时"的id判断,处理刚发为:
return data.id == 1;
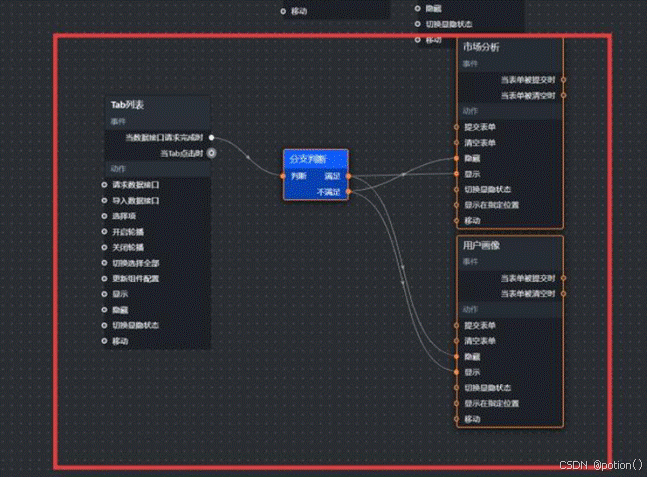
(6)在"分支判断"的 满足 分支上,添加两个"设置图层可见性"动作:
目标图层:市场分析组 → 显示
目标图层:用户画像组 → 隐藏
(7)在"判断选项卡"的 不满足 分支上,添加两个"设置图层可见性"动作:
目标图层:市场分析组 → 隐藏
目标图层:用户画像组 → 显示
5.2 配置地图省份点击联动
5.2.1 设计思路与原理
在用户画像大屏中,我们希望通过点击地图上的任意省份,右侧的核心指标卡(总用户数、平均年龄、本科及以上占比、中高收入占比)能立即切换为该省份的数据。这是一种典型的地理下钻分析,也是数据大屏的核心交互之一。
助睿Max 的蓝图编辑器让这种交互无需编写后端代码,只需通过"事件-动作"的连线即可实现。整个数据流如下:
地图点击(事件) → 提取省份名称(并行数据处理) → 动态SQL查询(SQL请求) → 数据分发(并行数据处理) → 四个指标卡刷新
核心知识点:
- 事件驱动:地图组件的"点击区域时"事件是起点,它会输出被点击区域的地理信息(如省份名称),前提是需要开启组件的交互事件。
- 变量传递:通过 window.globalProvinceName 全局变量,可以将省份名称在不同节点间共享,避免重复连线。
- 动态SQL:SQL请求节点可以接收外部变量,实现"根据用户点击的省份查询不同数据"。
- 并行数据处理:将一次查询返回的多行数据(每个指标一行)拆分、过滤,分别发送给不同的目标组件。
5.2.2 核心组件配置
(1)提取地区名称(并行数据处理)
地图组件点击后返回的省份名称是全称(如"江苏省"、"广西壮族自治区"),但我们的数据表中存储的是简称("江苏"、"广西")。因此需要先做一个名称映射。
作用:接收地图点击事件输出的 data 对象,从中提取 name 字段,并通过映射表转换为数据表中的简称,最后存入全局变量 window.globalProvinceName。
代码(已提供完整映射表,支持省、自治区、直辖市、特别行政区):
// 省份特殊映射(直辖市、自治区、特别行政区)
const specialMap = {
'北京市': '北京', '天津市': '天津', '上海市': '上海', '重庆市': '重庆',
'广西壮族自治区': '广西', '内蒙古自治区': '内蒙古', '西藏自治区': '西藏',
'宁夏回族自治区': '宁夏', '新疆维吾尔自治区': '新疆',
'香港特别行政区': '香港', '澳门特别行政区': '澳门'
};
let provinceName = data.name;
// 优先使用特殊映射
if (specialMapprovinceName) {
provinceName = specialMapprovinceName;
} else {
// 通用处理:去除末尾的"省"、"自治区"、"市"
provinceName = provinceName.replace(/(省|自治区|市)$/, '');
}
window.globalProvinceName = provinceName;
return provinceName;
(2)省份核心指标查询(SQL请求节点)
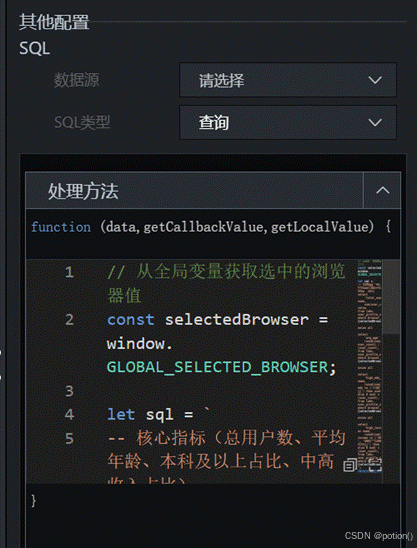
根据当前选中的浏览器(window.GLOBAL_SELECTED_BROWSER)和点击的省份(window.globalProvinceName),从 user_profile_stats 表中查询四个核心指标。为了便于后续分发,使用 UNION ALL 将四个指标输出为多行,每行包含 name(指标名)和 value(数值)。
SQL 如下:
const selectedProvince = window.globalProvinceName;
console.log("点击的省份名称(处理后):", selectedProvince);
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
const sql = `
select 'total_users' as name, sum(user_count) as value
from labs.user_profile_stats
where browser_name = '{selectedBrowser}' and province = '{selectedProvince}'
union all
select 'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 0) as value
from labs.user_profile_stats
where browser_name = '{selectedBrowser}' and province = '{selectedProvince}'
union all
select 'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '{selectedBrowser}' and province = '{selectedProvince}'
union all
select 'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '{selectedBrowser}' and province = '{selectedProvince}'
`;
console.log("生成的省份核心指标SQL:", sql);
return sql;
(3)省份核心指标分发(并行数据处理)
SQL 返回的是四行数据,而四个指标卡每个只需要一个数值。通过"并行数据处理"节点,我们按 name 字段过滤,将每个指标单独输出给对应的指标卡。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');
return { value: item ? item.value : 0 };
其他分支类似,只需修改 item.name === 'total_users'的条件即可
5.2.3 蓝图连线与数据流
- 区域热力层的"点击区域时"事件 → 连接到 "提取地区名称" 节点。
- "提取地区名称" 的"执行成功"输出 → 连接到 "省份核心指标查询" 节点的"执行SQL"输入。
- "省份核心指标查询" 的"执行成功"输出 → 连接到 "省份核心指标分发" 节点的输入。
- "省份核心指标分发" 的四个输出分支 → 分别连接到四个核心指标卡的"导入数据接口"。
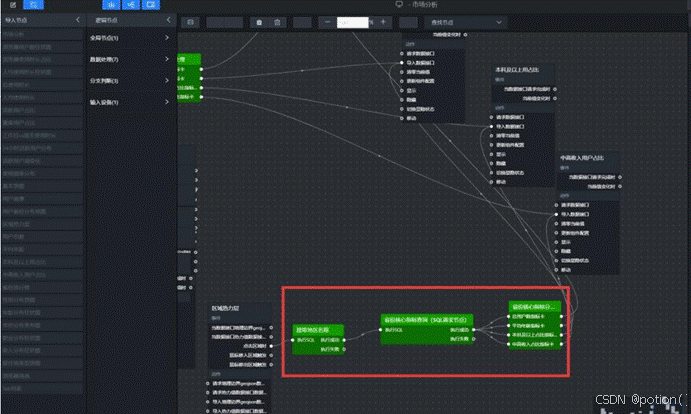
5.3 地图热力层根据用户数渲染颜色
5.3.1 设计思路与原理
为了直观展示全国各省份的用户分布,我们需要在地图上用颜色深浅来表示每个省份的用户数(用户数越多,颜色越深)。这是数据大屏中常见的热力图效果。
助睿Max 的地图组件支持通过"区域热力层"子组件接收自定义数据。数据格式要求为 { name, value, area_id },其中 name 为省份名称,value 为用户数,area_id 为行政区划代码(adcode)。因此,我们需要完成以下步骤:
- 提取地理数据中的 adcode 和 name:地图组件内部包含全国各省份的 GeoJSON 边界数据,其中包含 adcode(行政区划代码)和标准名称。我们需要提取并建立一个"省份名称 → adcode"的映射表,存储在全局变量中。
- 查询所有省份的用户数:根据当前选中的浏览器,从 user_profile_stats 表中统计每个省份的用户总数。
- 数据映射与格式化:将查询结果中的省份名称与 adcode 映射表匹配,输出格式 { name, value, area_id }。
- 导入热力值数据:将格式化后的数据导入地图的"区域热力层"子组件,即可自动渲染颜色深浅。
传统开发中,实现地图热力层需要前端加载 GeoJSON、手动计算颜色映射、绑定事件等。而助睿Max 只需配置子组件的数据接口,平台自动完成渲染,极大降低了地理可视化的门槛。
5.3.2 核心组件配置
(1)提取 adcode 映射表(并行数据处理)
此节点只需执行一次,在页面加载时运行,从地图组件内置的 GeoJSON 中提取每个省份的 adcode 和标准名称,建立映射表 globalProvinceAdcode。
操作步骤:
- 在蓝图中添加"并行数据处理"节点,命名为"提取adcode映射表"。
- 将区域热力层的"当数据接口地理边界geojson数据加载完成时"事件连接到该节点(确保地图数据加载后执行)。
- 提取 adcode 映射表的处理方法中输入以下代码:
/**
* 提取地理数据中的 adcode 和 name,建立名称→adcode 映射
* @param {Object} data - 地理数据对象(包含 features 数组)
* @returns {Object} 名称到 adcode 的映射表
*/
function extractAdcodeAndName�data) {
if (!data || !Array.isArray�data.features)) {
console.error�'无效的地图数据格式');
return {};
}
const nameToAdcode = {};
data.features.forEach�feature => {
const props = feature.properties;
if (props && props.adcode && props.name) {
nameToAdcodeprops.name = props.adcode;
}
});
return nameToAdcode;
}
const mapping = extractAdcodeAndName�data);
window.globalProvinceAdcode = mapping;
console.log�"省份adcode映射表已加载", Object.keys�mapping).length);
return mapping;
(2)查询所有省份的用户数(SQL请求节点)
根据当前选中的浏览器(window.GLOBAL_SELECTED_BROWSER),统计每个省份的用户总数,并按用户数降序排列。
操作步骤:
- 添加"SQL请求"节点,命名为"各省份用户数查询"。
- 处理方法中输入以下代码:
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER; // 当前选中的浏览器
const sql = `
SELECT
province AS name,
SUM(user_count) AS value
FROM labs.user_profile_stats
WHERE browser_name = '${selectedBrowser}'
AND province IS NOT NULL
AND province != ''
GROUP BY province
ORDER BY value DESC
`;
console.log�"生成的所有省份用户数SQL:", sql);
return sql;
(3)地图数据映射(并行数据处理节点)
将 SQL 查询结果中的省份名称与 window.globalProvinceAdcode 匹配,生成 { name, value, area_id } 格式的数据,供地图热力层使用。
操作步骤:
- 添加"并行数据处理"节点,重命名为"地图数据与用户数映射"。
- 处理方法中输入以下代码:
function convertToMapData�data) {
if (!Array.isArray�data) || data.length === 0) {
return \[\];
}
return data.map�item => {
const provinceName = item.name; // 注意:SQL 返回字段名为 name
let area_id = globalProvinceAdcodeprovinceName;
// 如果直接匹配失败,尝试简化名称(案例中已实现)
if (!area_id) {
const simplifiedName = provinceName.replace(/省|市|自治区|特别行政区|回族|壮族|维吾尔|藏族|苗族/g, '');
for (const fullName in globalProvinceAdcode) {
if (fullName.includes�simplifiedName)) {
area_id = globalProvinceAdcodefullName;
break;
}
}
}
if (!area_id) {
// console.warn(`未找到省份 "${provinceName}" 的匹配 adcode`);
area_id = "000000";
}
return {
name: provinceName,
value: parseFloat�item.value) || 0,
area_id: Number�area_id)
};
});
}
const result = convertToMapData�data);
// console.log("最终返回的地图热力数据:", result);
return result;
(4)导入地图热力层
在地图组件(基础平面地图)中,已经添加了子组件"区域热力层"。我们需要将映射后的数据导入该子组件。
操作步骤:
- 将"地图数据与用户数映射"节点的输出端口连接到"区域热力层"的"导入热力值数据接口"。
助睿Max的地图组件及其子组件的事件和动作非常丰富。通过"导入热力值数据接口"动态更新数据,可以实现浏览器切换时热力图自动刷新。
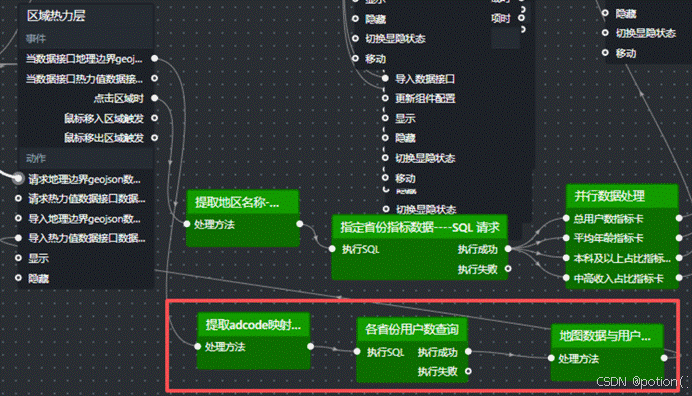
5.3.3 蓝图连线与数据流
完整的蓝图数据流如下(热力渲染部分独立于点击联动):
5.4 预览与发布
完成上述所有配置后,大屏应具备三个核心交互功能:
- 大屏切换:点击 tab 列表的"市场分析"/"用户画像",正确显示对应大屏内容。
- 地图热力层:地图上各省份颜色深浅反映该省份在当前浏览器下的用户数(用户数越多颜色越深)。
- 省份点击联动:点击地图上的省份,右侧四个核心指标卡自动更新为该省份的数据。
保存预览,对以上功能进行验证,确保三个核心交互功能均正常工作。
最后点击"发布"按钮,在弹出的发布对话框中打开发布分享开关,复制分享链接,打开浏览器,将复制的链接粘贴到地址栏中,即可在线观看