uv pip uninstall torchvision torchaudio跑完整个 Notebook,相当于你已经独立完成了一次完整的模型微调。具体来说,你手上会多出这样几样成果:
- 一个保存好的 LoRA adapter 目录 ------这就是你这次训练的核心产物,模型新学到的"情绪识别本领"都浓缩在这里。
- 一张微调前后的指标对比表 ------把训练前、训练后的成绩并排放在一起,让你一眼看出微调到底有没有效果。
- 几个 CSV 结果文件 ------保存了详细的评估数据,方便你之后写实验报告时引用。
- 一个微调后的模型 ------它现在能读懂一句英文,并给出对应的情绪标签,从"通用聊天模型"变成了"情绪分类专家"。
关机前的"安全撤退"两步走
- 把核心成果下载到本地(最重要!) --- 代码、训练过程和结果
- 因为教程只是带你微体验下整体流程,因此本次的成果不需要下载,你直接进行下一步正式关闭环境即可(前提:确保你已经截好了任务要求要打卡的截图---具体详见每个任务打卡表单的要求)。
正式关闭环境 确认代码文件下载到你本地电脑后,回到网页的 Profile(个人主页) ,找到 Active Instance 区域,点击红色的 Destroy Instance 按钮。
微调(Fine-tuning)

微调的真实威力,看下例子就懂:耶鲁大学用微调后的 Gemma 4 探索癌症治疗的新方向;保加利亚的团队把它微调成了"保加利亚语优先"的大模型 BgGPT。
同一个通用模型,喂不同的专门数据,就能变成不同领域的专家 ------这就是微调的价值所在。
1️⃣ 数据集(模型的"教材")
微调效果好不好,数据是头号关键。
数据集就是你喂给模型的"教材"。本教程的教材,是一条条"英文句子 + 它对应的情绪标签",情绪一共 6 类:悲伤 / 喜悦 / 爱 / 愤怒 / 恐惧 / 惊讶。教材越贴合任务、质量越高,微调出来越好(质量往往比数量更重要)。
2️⃣ LoRA(省显存的微调办法)
全量微调要把大模型的几十亿参数全部重调,单张显卡根本扛不住。LoRA 换了个聪明办法:把原来的大模型参数全"冻住"不动,只额外加一小撮新参数来训练,所以单卡一小时就能跑完。
- 它的产物不是一个完整的新模型,而是那一小撮参数,专业上叫 adapter(适配器) 。
- 敲黑板 :平时使用时,我们可以把"原模型 + adapter"一起加载; 但实际上,这个 adapter 是可以直接"融合(Merge)"到原模型里的! 融合之后就变成了一个纯净、完整的新模型,以后直接加载这一个就行,不需要每次都费事带上这个"补丁包"一起加载了。
3️⃣ epoch(训练轮数)
把整套教材完整学一遍,叫一个 epoch(一轮)。
- 本教程为了让你快速跑通,只训练了 1 轮,所以提升有限是正常的------这一阶段的目标是先把流程走通,而不是冲最高分。
- 危险警告 :想要更好的效果,之后可以加大数据、多训几轮。 但 epoch 绝不是设置得越高越好!如果轮数太高,模型就会变成"死记硬背"的呆子(专业叫"过拟合 / Overfitting") ------它把教材里的每一句话都背得滚瓜烂熟,但在现实中遇到没见过的新句子时,反而考试交白卷。
4️⃣ 评估指标(怎么判断有没有效果) 怎么知道微调到底有没有用?靠"微调前 vs 微调后"的成绩对比。主要看三个:
- 准确率(accuracy) :答对的比例,越高越好。
- F1 :综合各类情绪表现的得分,越高越好。
- 无效预测(invalid predictions) :模型答非所问、没给出 6 个标签之一的次数,越低越好。
(1)工具库:transformers 、 datasets 、 trl 、 peft 、 modelscope 。
它们分别负责 下载模型、读取数据、加载大模型、执行 LoRA 微调 这几件事,相当于开工前先把工具都备齐。
modelscope:从魔搭下载模型和数据集(snapshot_download 拉模型 + dataset_snapshot_download 拉数据集仓库)。
transformers:加载 Gemma 模型和 tokenizer。
datasets:用 load_dataset("parquet", ...) 从本地 parquet 加载数据,并提供 DatasetDict / ClassLabel 等数据结构。
trl:使用 SFTTrainer 做指令微调。
peft:配置 LoRA。
scikit-learn:计算 accuracy、F1、classification report、confusion matrix。
from tqdm.auto import tqdm
from datasets import Dataset, DatasetDict, ClassLabel, load_dataset
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, f1_score
from modelscope import snapshot_download
from modelscope.hub.snapshot_download import dataset_snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
from peft import LoraConfig, PeftModel
from trl import SFTConfig, SFTTrainer(2)查显卡:确认 GPU 能用------和任务三第一步一个道理,地基先确认
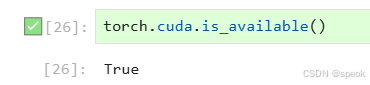
训练大模型需要显卡(GPU)来出力,所以代码会先确认显卡是否就位:
torch.cuda.is_available()

重要函数
下载模型
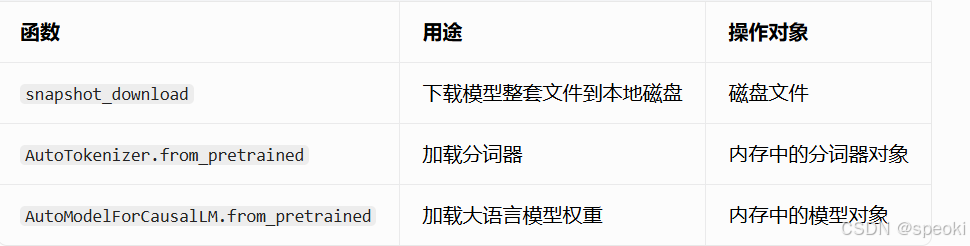
snapshot_download(ModelScope)
一句话:把整个模型仓库从远端完整下载到本地磁盘。
下载哪些文件(全部)
- 模型权重:
- pytorch_model.bin(老格式)
- model-*.safetensors(分片、安全格式,现在主流)
- 模型配置:
- config.json(层数、维度、激活函数等)
- 分词器全套:
- tokenizer.json(词表 + BPE 合并规则)
- tokenizer_config.json(特殊 token、max_length 等)
- special_tokens_map.json(特殊 token 映射)
- 其他:
- generation_config.json(生成参数)
- README.md、LICENSE、.py(自定义代码)等文档与脚本
AutoTokenizer.from_pretrained
从本地磁盘读取分词器文件,在 CPU 内存里造出 tokenizer 对象。
- 只加载这几个文件(小文件)
- tokenizer.json → 核心词表与分词规则
- tokenizer_config.json → 特殊 token、长度限制等
- special_tokens_map.json → 特殊 token 映射
- 不加载
- 模型权重(.bin/.safetensors)完全不碰。
- 加载位置
CPU 内存(很小,几 MB)。 - 角色
负责:文本 → token id(给模型输入)、decode:token id → 文本。
snapshot_download 是下载模型文件到本地,AutoTokenizer.from_pretrained 是从本地目录加载分词器,分工完全不同。
python
base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)AutoModelForCausalLM.from_pretrained
加载的文件(大文件为主)
- config.json → 构建模型结构(必须)
- 权重文件(二选一):
- 多个分片:model-00001-of-00004.safetensors...
- 单个:pytorch_model.bin
- 可选:generation_config.json → 生成默认参数
先在 CPU 内存 加载(用 low_cpu_mem_usage=True 减少峰值)。
随后一般手动搬到 GPU 显存(.cuda() / .to('cuda'))。
来自 transformers 库,作用是:从本地模型目录,加载因果语言模型(大模型权重)到内存,用于文本生成、对话、续写等任务。
和 AutoTokenizer.from_pretrained 逻辑一致:都是读取本地已下载好的模型文件,实例化对象,区别只是一个加载分词器,一个加载模型权重。
python
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"
print("Downloading model from ModelScope...")
print("ModelScope model id:", MODELSCOPE_MODEL_ID)
model_dir = snapshot_download(
MODELSCOPE_MODEL_ID,
cache_dir="./models",
)
python
print("Loading tokenizer from:", LOCAL_MODEL_DIR)
tokenizer = AutoTokenizer.from_pretrained(
LOCAL_MODEL_DIR,
use_fast=True,
trust_remote_code=True,
)modelscope.hub.snapshot_download.dataset_snapshot_download() 把数据集仓库整体拉到本地(包含 data/*.parquet 文件),然后用 datasets.load_dataset("parquet", data_files=...) 从本地 parquet 加载。这样做不依赖 MsDataset 内部对 datasets 库的桥接代码,可以避开类似 as_dataset() got an unexpected keyword argument 'verification_mode' 的版本兼容报错。
实现细节:从 parquet 文件加载时,label 字段类型会退化成普通 int64。
这里显式 cast_column("label", ClassLabel(names=...)),让 features"label".names 可以直接拿到标签名,与原始 HF 版本接口完全一致,后续 prompt 构造、评估、混淆矩阵等下游代码一字未改。
python
EMOTION_LABEL_NAMES = ["sadness", "joy", "love", "anger", "fear", "surprise"]
# 直接把魔搭上的数据集仓库(parquet 文件)整体下载到本地,然后用 datasets 库从本地 parquet 加载。
# 不走 MsDataset.load -> datasets.load_dataset 的桥接路径,可以规避 modelscope 与 datasets 之间
# `as_dataset() got an unexpected keyword argument 'verification_mode'` 这类版本错配错误。
print("Downloading dataset from ModelScope...")
print("ModelScope dataset id:", MODELSCOPE_DATASET_ID)
dataset_dir = dataset_snapshot_download(
MODELSCOPE_DATASET_ID,
cache_dir="./datasets",
)
print("Downloaded dataset dir:", dataset_dir)
dataset = DatasetDict({
"train": maybe_limit(raw_dataset["train"], TRAIN_LIMIT),
"validation": maybe_limit(raw_dataset["validation"], VALIDATION_LIMIT),
"test": maybe_limit(raw_dataset["test"], TEST_LIMIT),
})这里有个容易误会的点:在 AMD 显卡的 ROCm 环境里,这行代码依然写着 cuda 。 cuda 本来是 NVIDIA 的叫法,PyTorch 沿用了这个老名字,所以 看到 cuda 不代表你在用 NVIDIA 显卡 ,不用担心。
只要这行返回 True ,并且后面打印出来的设备信息里能看到 AMD GPU 的名字,就说明显卡已经准备好了,可以继续。
python
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
){'prompt': [{'role': 'system', 'content': "You are an emotion classification assistant.\nRead the user's text and answer with exactly one label.\nOnly choose from: sadness, joy, love, anger, fear, surprise.\nReturn only the label and nothing else."}, {'role': 'user', 'content': 'Classify the emotion of this text:\n\nwhile cycling in the country'}], 'completion': [{'role': 'assistant', 'content': 'fear'}]}
python
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)
print(sft_dataset)
print(sft_dataset["train"][0])remove_columns 的作用:映射转换后,删掉原数据集里没用的旧字段,只保留新生成的 prompt、completion。
python
TEMPLATE_SOURCE_MODEL_ID = "google/gemma-4-E4B-it"
def _load_official_gemma_chat_template() -> str:
"""从 gemma-4-E4B-it 仓库下载官方 chat_template.jinja 并返回字符串。
主路径:modelscope.snapshot_download(allow_file_pattern=["chat_template.jinja"])
兜底:ModelScope raw file API 直接 HTTP GET
"""
try:
template_dir = snapshot_download(
TEMPLATE_SOURCE_MODEL_ID,
cache_dir="./models",
allow_file_pattern=["chat_template.jinja"],
)
path = os.path.join(template_dir, "chat_template.jinja")
if os.path.exists(path):
with open(path, "r", encoding="utf-8") as f:
return f.read()
except Exception as e:
print("snapshot_download(allow_file_pattern) failed, fallback to HTTP. err =", e)
import urllib.request
url = (
"https://www.modelscope.cn/api/v1/models/"
f"{TEMPLATE_SOURCE_MODEL_ID}/repo?Revision=master&FilePath=chat_template.jinja"
)
with urllib.request.urlopen(url, timeout=60) as resp:
return resp.read().decode("utf-8")
if not getattr(tokenizer, "chat_template", None):
print(f"Loading official chat_template.jinja from {TEMPLATE_SOURCE_MODEL_ID} ...")
tokenizer.chat_template = _load_official_gemma_chat_template()
print("Loaded official chat_template, length =", len(tokenizer.chat_template))
else:
print("tokenizer.chat_template already set, leaving as-is.")
# 自检:跑一次 apply_chat_template,确保模板可用。
_probe = tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
],
tokenize=False,
add_generation_prompt=True,
)评估函数
评估指标包括:
- accuracy
- macro_f1
- invalid_predictions
- classification_report
- confusion_matrix
由于生成式评估比较慢,默认只评估 EVAL_LIMIT=400 条测试样本。
配置 LoRA
LoRA 只训练一小部分低秩适配器参数,不直接全量更新大模型权重。
这里使用:
target_modules="all-linear"
表示尽量给模型中的线性层加 LoRA,适合先快速跑通。如果你后面想进一步控制显存和训练速度,可以改成指定模块名。
python
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)定义训练参数
单卡版本默认:
- per_device_train_batch_size=4
- gradient_accumulation_steps=4
- 等效 batch size 为 16
- 使用 adamw_torch,避免 AMD ROCm 下 bitsandbytes 优化器兼容问题
显存不够的话,可以把 per_device_train_batch_size 改成 1 或 2。
python
training_args = SFTConfig(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="linear",
warmup_steps=50,
num_train_epochs=1,
logging_steps=5,
eval_strategy="steps",
eval_steps=25,
save_strategy="steps",
save_steps=25,
save_total_limit=2,
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_checkpointing=True,
bf16=BF16,
fp16=FP16,
tf32=False,
max_length=256,
packing=False,
completion_only_loss=True,
remove_unused_columns=False,
dataloader_num_workers=2,
optim="adamw_torch",
report_to="none",
seed=SEED,
data_seed=SEED,
)开始 LoRA 微调
这里会创建 SFTTrainer 并开始训练。
训练前会检查 LoRA 参数是否真的被挂上。如果 Trainable LoRA parameters 为 0,说明 target_modules 没匹配成功,需要调整 LoRA 配置。
python
trainer = SFTTrainer(
model=base_model,
train_dataset=sft_dataset["train"],
eval_dataset=sft_dataset["validation"],
peft_config=lora_config,
args=training_args,
processing_class=tokenizer,
)
trainable_params = 0
total_params = 0
trainable_param_names = []
for name, param in trainer.model.named_parameters():
total_params += param.numel()
if param.requires_grad:
trainable_params += param.numel()
trainable_param_names.append(name)
train_result = trainer.train()
trainer.model.eval()
trainer.model.config.use_cache = True
train_resultnumel函数:返回张量中所有元素的总个数
python
import torch
# 1. 二维张量 [2行, 3列]
t1 = torch.randn(2, 3)
print(t1.numel()) # 2*3 = 6
# 2. 三维张量 [4,5,2]
t2 = torch.rand(4, 5, 2)
print(t2.numel()) # 4*5*2 = 40
# 3. 标量(0维张量)
t3 = torch.tensor(10)
print(t3.numel()) # 1保存 LoRA adapter 和 tokenizer
保存的是 LoRA adapter,不是完整大模型权重。
目录中通常包括:
- adapter_model.safetensors
- adapter_config.json
- tokenizer 相关文件
- training checkpoints
python
trainer.model.save_pretrained(OUTPUT_DIR) # 把训练后的模型权重、配置文件保存到 OUTPUT_DIR 文件夹。
tokenizer.save_pretrained(OUTPUT_DIR)
#把分词器全套配置、词表保存到同一个输出目录,和模型放在一起,方便后续推理直接读取。
with open(os.path.join(OUTPUT_DIR, "train_metrics.json"), "w", encoding="utf-8") as f:
json.dump(train_result.metrics, f, ensure_ascii=False, indent=2)
#train_result.metrics:Trainer 训练结束后自动统计的指标,包含训练 loss、epoch、学习率、训练耗时等数据;
# 写入 train_metrics.json 文件存档,方便后续复盘、绘图、对比实验效果;
# ensure_ascii=False:中文不转义,indent=2 格式化 JSON,方便人阅读。
print("Saved adapter and tokenizer to:", OUTPUT_DIR)Saved adapter and tokenizer to: ./gemma4-it-emotion-lora-ms-single-gpu
微调后评估
训练后直接复用内存里的模型评估,避免重新加载导致显存碎片或 OOM。
python
ft_model = trainer.model
# trainer 是 transformers 的 Trainer 训练器,内部绑定了训练完成后的模型;
# 把训练好的微调模型赋值给 ft_model(ft = fine-tune 微调模型),后续评估统一用这个变量,代码更简洁。
ft_model.eval()
#关闭 dropout、batch norm 等训练时才用的随机正则层,保证每次预测结果稳定;
#不计算梯度,节省显存、提速;
#评估、推理必须加这一行,否则指标会严重失真。
#训练阶段用:model.train(),评估 / 推理用:model.eval()
ft_model.config.use_cache = True
#开启KV Cache 缓存
#大模型文本生成时,会缓存每一步的注意力键值,不用重复计算,大幅加速推理;
#训练阶段一般设 use_cache=False(节省显存、兼容梯度计算);
#评估测试、上线推理必须打开,提升生成速度。
# 执行测试集评估函数
post_metrics, post_report, post_preds = evaluate_model(ft_model, tokenizer, split="test", limit=EVAL_LIMIT)
post_metrics
# ft_model:微调完毕、已切 eval 模式的模型
# tokenizer:配套分词器,用来把文本转模型输入 token
# split="test":指定用测试集做评估(区分 train/val 验证集)
# limit=EVAL_LIMIT:限制评估样本数量,比如只测前 1000 条,加快评估速度
pd.DataFrame(post_report).transpose()手动测试微调后的模型
python
def predict_emotion_ft(user_text: str) -> str:
return generate_label(ft_model, tokenizer, user_text, SYSTEM_PROMPT)
test_texts = [
"I feel completely heartbroken and alone.",
"This is the best day of my life!",
"I am really scared about what might happen tomorrow.",
"I can't believe they remembered my birthday!",
"I am so angry that nobody listened to me.",
"I really love spending time with my family.",
]
for text in test_texts:
print(text, "=>", predict_emotion_ft(text))保存评估结果
python
comparison_df.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_before_after_metrics.csv"), index=False)
merged_examples.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_prediction_examples.csv"), index=False)
changed_predictions.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_changed_predictions.csv"), index=False)
pre_preds.to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_predictions.csv"), index=False)
post_preds.to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_predictions.csv"), index=False)
pd.DataFrame(pre_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_classification_report.csv"))
pd.DataFrame(post_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_classification_report.csv"))
confusion_matrix_df(pre_preds).to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_confusion_matrix.csv"))
confusion_matrix_df(post_preds).to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_confusion_matrix.csv"))
print("Saved all outputs to:", OUTPUT_DIR)可选:重新加载本地 LoRA adapter 推理
python
# 保存的代码
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
with open(os.path.join(OUTPUT_DIR, "train_metrics.json"), "w", encoding="utf-8") as f:
json.dump(train_result.metrics, f, ensure_ascii=False, indent=2)
print("Saved adapter and tokenizer to:", OUTPUT_DIR)以后不想重新训练,可以用下面代码重新加载:
- 从魔搭下载的本地基础模型目录加载 base model。
- 从 OUTPUT_DIR 加载 LoRA adapter。
- 使用同一个 generate_label() 做推理。
python
# 可选运行:重新加载 LoRA adapter
# 为避免当前 notebook 占用显存,建议重启 kernel 后单独运行本节。
RUN_RELOAD_TEST = False
if RUN_RELOAD_TEST:
reload_tokenizer = AutoTokenizer.from_pretrained(
OUTPUT_DIR,
use_fast=True,
trust_remote_code=True,
)
if reload_tokenizer.pad_token is None:
reload_tokenizer.pad_token = reload_tokenizer.eos_token
reload_base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
reload_model = PeftModel.from_pretrained(
reload_base_model,
OUTPUT_DIR,
)
reload_model.eval()
print(generate_label(reload_model, reload_tokenizer, "I feel completely heartbroken and alone."))显存不够怎么办?
优先调整:
TRAIN_LIMIT = 1000
EVAL_LIMIT = 50
per_device_train_batch_size = 1
max_length = 128想用全量数据怎么办?
把数据限制改为:
TRAIN_LIMIT = None
VALIDATION_LIMIT = None
TEST_LIMIT = None
EVAL_LIMIT = 1000