
适合对象:会用 Python、装过 PyCharm,但没接触过爬虫/自动化的同学
一、核心原理(先搞懂再动手)
普通爬虫 vs Playwright
对比项 requests 爬虫 Playwright
能执行 JS ❌ 不能 ✅ 能
能模拟点击 ❌ 不能 ✅ 能
动态渲染页面 ❌ 拿不到 ✅ 拿得到
需要分析接口 ✅ 必须 ❌ 不需要
上手难度 中 低
Playwright 的本质:用代码控制一个真实的浏览器
你的 Python 脚本
↓ 发指令
Playwright
↓ 控制
Chromium 浏览器(真实浏览器,不是假的)
↓ 访问
12306 网站
↓ 返回数据
Python 脚本解析打印12306 这类网站数据是 JavaScript 动态渲染的,用普通 requests 只能拿到空页面,Playwright 则是"让浏览器真正渲染完再截取数据"。
二、环境安装(只需做一次)
第一步:安装 Python 库
打开 PyCharm 底部 Terminal,依次执行:
pip install playwright第二步:安装浏览器内核
playwright install chromium⚠️ 注意:这一步必须单独执行,不能用 pip install chromium,那是无效的。
下载约 100MB,需要等一会儿。
验证安装成功
python -c "from playwright.sync_api import sync_playwright; print('安装成功')"看到"安装成功"就可以了。
三、完整代码(直接可运行)
新建 main.py,把以下代码完整粘贴进去:
"""
12306 余票查询自动化脚本
定位:Web UI 自动化测试实战案例
"""
from playwright.sync_api import sync_playwright, TimeoutError as PWTimeout
import time
import random
from datetime import datetime
# ══════════════════════════════════════════
# 【配置区】只需改这里
# ══════════════════════════════════════════
CONFIG = {
"from_city": "武汉", # 出发城市
"to_city": "上海", # 到达城市
"date": "2026-06-20", # 出发日期 格式:YYYY-MM-DD
"train_types": ["G", "D"], # 只看高铁/动车,留空=全部
"monitor_interval": 0, # 0=查一次;60=每60秒自动刷新
"headless": False, # False=看得到浏览器操作过程
}
# 城市名 → 12306 站码(查询 URL 用)
STATION_CODE = {
"北京":"BJP", "上海":"SHH", "广州":"GZQ", "深圳":"SZQ",
"武汉":"WHN", "成都":"CDW", "杭州":"HZH", "南京":"NJH",
"西安":"XAY", "重庆":"CQW", "长沙":"CSQ", "郑州":"ZZF",
"济南":"JNA", "沈阳":"SYT", "哈尔滨":"HBB", "天津":"TJP",
"青岛":"QDK", "厦门":"XMS", "昆明":"KMG", "贵阳":"GYK",
}
# ══════════════════════════════════════════
# 工具函数
# ══════════════════════════════════════════
def human_delay(min_s=1.0, max_s=2.5):
"""随机等待,模拟真人操作节奏(反爬核心技巧)"""
time.sleep(random.uniform(min_s, max_s))
def force_close_dropdown(page):
"""用 JS 强制关闭城市下拉框,防止它遮挡其他元素"""
page.evaluate("""() => {
var sd = document.getElementById('search_div');
if (sd) sd.style.display = 'none';
var tc = document.getElementById('top_cities');
if (tc) tc.style.display = 'none';
}""")
human_delay(0.3, 0.5)
def js_set_value(page, element_id, value):
"""
直接用 JS 设置输入框的值
原理:找到 DOM 元素 → 设置 value 属性
比 Playwright 的 fill() 更稳定,不触发下拉框
"""
page.evaluate(
"([eid, val]) => { var el = document.getElementById(eid); if(el) el.value = val; }",
[element_id, value]
)
def fill_station(page, selector, city_name):
"""
填写出发地/到达地
策略:直接用 JS 同时写入显示框(文字)和隐藏字段(站码)
这样完全绕开下拉框,避免下拉框残留遮挡问题
"""
force_close_dropdown(page)
human_delay(0.3, 0.5)
is_from = "from" in selector
text_id = "fromStationText" if is_from else "toStationText" # 显示的文字框
hidden_id = "fromStation" if is_from else "toStation" # 隐藏的站码字段
code = STATION_CODE.get(city_name, "")
if code:
js_set_value(page, text_id, city_name) # 写入城市名(显示用)
js_set_value(page, hidden_id, code) # 写入站码(查询用)
print(" [JS写入] {} = {} ({})".format(text_id, city_name, code))
human_delay(0.5, 0.8)
else:
print(" [警告] 城市 {} 不在站码表里,请手动添加".format(city_name))
def set_date(page, date_str):
"""用 JS 设置日期,触发 change/blur 事件让页面感知变化"""
page.evaluate(
"(date) => { var el = document.getElementById('train_date'); "
"if(el){ el.value = date; "
"el.dispatchEvent(new Event('change', {bubbles:true})); "
"el.dispatchEvent(new Event('blur', {bubbles:true})); } }",
date_str
)
def get_td_text(row, selector):
"""安全取元素文本,找不到返回 --"""
el = row.query_selector(selector)
return el.text_content().strip() if el else "--"
# ══════════════════════════════════════════
# 核心:提取余票数据
# ══════════════════════════════════════════
def parse_ticket_table(page):
"""
从结果页提取余票数据
选择器说明(DevTools 实测):
#queryLeftTable tr → 每一行车次
.number → 车次号(如 G2368)
.start-s / .end-s → 出发站 / 到达站
.start-t → 出发时间
.ls strong → 历时
td[id^="ZY_"] → 一等座余票(id 前缀匹配)
td[id^="ZE_"] → 二等座余票
td[id^="SWZ_"] → 商务座余票
"""
results = []
# 等待表格出现(显式等待是 UI 自动化测试的核心技巧)
try:
page.wait_for_selector("#queryLeftTable tr", timeout=20000)
except PWTimeout:
print(" [!] 等待超时,URL:", page.url)
return results
rows = page.query_selector_all("#queryLeftTable tr")
print(" [调试] 共找到 {} 行数据".format(len(rows)))
for row in rows:
try:
# 1. 找车次号,找不到说明这行不是数据行(跳过)
train_el = row.query_selector(".number")
if not train_el:
continue
train_no = train_el.text_content().strip()
if not train_no:
continue
# 2. 按车次类型过滤(G/D 字头)
if CONFIG["train_types"]:
if not any(train_no.startswith(t) for t in CONFIG["train_types"]):
continue
# 3. 提取站点和时间
start_station = get_td_text(row, ".start-s")
end_station = get_td_text(row, ".end-s")
start_time = get_td_text(row, ".start-t")
end_time_el = row.query_selector("div.cds strong:last-child")
end_time = end_time_el.text_content().strip() if end_time_el else "--"
duration = get_td_text(row, ".ls strong")
# 4. 用 ID 前缀精准定位各席别余票
# 格式:td[id^="ZY_"] 表示匹配 id 以 ZY_ 开头的 td
swz = get_td_text(row, 'td[id^="SWZ_"]') # 商务座
zy = get_td_text(row, 'td[id^="ZY_"]') # 一等座
ze = get_td_text(row, 'td[id^="ZE_"]') # 二等座
wz = get_td_text(row, 'td[id^="WZ_"]') # 无座
results.append({
"train_no": train_no,
"start_station": start_station,
"end_station": end_station,
"depart": start_time,
"arrive": end_time,
"duration": duration,
"商务座": swz, "一等座": zy,
"二等座": ze, "无座": wz,
})
except Exception:
continue # 单行解析失败不影响其他行
return results
# ══════════════════════════════════════════
# 打印报告
# ══════════════════════════════════════════
def print_report(results, cfg):
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
sep = "=" * 80
print("\n" + sep)
print(" 12306 余票查询报告 [{}]".format(now))
print(" {} → {} 出发日期:{}".format(cfg["from_city"], cfg["to_city"], cfg["date"]))
print(sep)
if not results:
print(" 未查询到符合条件的车次")
else:
fmt = " {:<8} {:<7} {:<7} {:<8} {:<7} {:<7} {:<7} {:<5}"
print(fmt.format("车次", "出发", "到达", "历时", "商务座", "一等座", "二等座", "无座"))
print(" " + "-" * 72)
for r in results:
print(fmt.format(
r["train_no"], r["depart"], r["arrive"], r["duration"],
r["商务座"], r["一等座"], r["二等座"], r["无座"]
))
print("\n 出发站:{} 到达站:{}".format(
results[0]["start_station"], results[0]["end_station"]))
print(sep)
# ══════════════════════════════════════════
# 主流程
# ══════════════════════════════════════════
def run_query(cfg):
with sync_playwright() as p:
# ── 启动浏览器(反爬配置)────────────────────────────
browser = p.chromium.launch(headless=cfg["headless"])
context = browser.new_context(
# 设置真实 User-Agent,让服务器认为是普通用户
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
viewport={"width": 1366, "height": 768},
locale="zh-CN",
)
page = context.new_page()
# 屏蔽 webdriver 特征(防止被识别为自动化工具)
page.add_init_script(
"Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"
)
# ── 第一步:打开首页(建立正常 Cookie)────────────────
print("[1] 打开 12306 首页...")
page.goto("https://www.12306.cn/index/", timeout=30000, wait_until="domcontentloaded")
human_delay(2, 3)
# ── 第二步:填写出发地 ─────────────────────────────────
print("[2] 填写出发地:{}".format(cfg["from_city"]))
fill_station(page, "input#fromStationText", cfg["from_city"])
# ── 第三步:填写到达地 ─────────────────────────────────
print("[3] 填写到达地:{}".format(cfg["to_city"]))
fill_station(page, "input#toStationText", cfg["to_city"])
# ── 第四步:设置日期 ───────────────────────────────────
print("[4] 设置日期:{}".format(cfg["date"]))
set_date(page, cfg["date"])
human_delay(0.8, 1.2)
# ── 第五步:点击查询按钮,捕获新标签页 ────────────────
# 原理:12306 点查询会新开标签页
# expect_popup() 专门用来等待新标签页出现
print("[5] 点击查询按钮...")
with page.expect_popup() as popup_info:
page.locator("a#search_one").click()
new_page = popup_info.value # 拿到新标签页对象
print("[5] 新标签页打开,等待数据加载...")
new_page.wait_for_load_state("domcontentloaded")
human_delay(3, 5)
print("[5] 结果页 URL: {}".format(new_page.url))
# ── 第六步:提取数据(在新标签页操作)────────────────
print("[6] 提取余票数据...")
results = parse_ticket_table(new_page)
# 断言:验证返回类型正确(自动化测试核心)
assert isinstance(results, list), "数据提取返回类型异常"
print("[√] 断言通过,共提取 {} 条车次".format(len(results)))
print_report(results, cfg)
input("\n【按回车键关闭浏览器】")
browser.close()
def main():
cfg = CONFIG
if cfg["monitor_interval"] == 0:
run_query(cfg)
else:
print("[*] 监控模式:每 {} 秒查询一次,Ctrl+C 退出".format(cfg["monitor_interval"]))
n = 0
while True:
n += 1
print("\n第 {} 次查询".format(n))
try:
run_query(cfg)
except Exception as e:
print("[!] 异常:{}".format(e))
time.sleep(cfg["monitor_interval"])
if __name__ == "__main__":
main()四、运行步骤
第一次运行前,确认安装完成(见第二节)。
直接点 PyCharm 右上角绿色 ▶ 按钮,或 Terminal 执行:
python main.py正常运行你会看到:
[1] 打开 12306 首页...
[2] 填写出发地:武汉
[JS写入] fromStationText = 武汉 (WHN)
[3] 填写到达地:上海
[JS写入] toStationText = 上海 (SHH)
[4] 设置日期:2026-06-20
[5] 点击查询按钮...
[5] 新标签页打开,等待数据加载...
[6] 提取余票数据...
[调试] 共找到 127 行数据
[√] 断言通过,共提取 60 条车次
================================================================
12306 余票查询报告 [2026-06-15 21:15:41]
武汉 → 上海 出发日期:2026-06-20
================================================================
车次 出发 到达 历时 商务座 一等座 二等座 无座
...五、配置修改说明
只需改文件顶部的 CONFIG,其他不动:
CONFIG = {
"from_city": "武汉", # 改这里换出发城市
"to_city": "北京", # 改这里换目的地
"date": "2026-07-01", # 改这里换日期
"train_types": ["G"], # 只看高铁;["G","D"] 高铁+动车;[] 全部
"monitor_interval": 0, # 改成 60 开启监控模式(每60秒刷新)
"headless": False, # 改成 True 不弹出浏览器窗口(后台静默运行)
}支持的城市在 STATION_CODE 字典里,需要新城市就往里加一行:
"武昌": "WCN", # 格式:城市名 → 12306 三字站码六、遇到错误怎么排查
常见错误速查表
错误信息 原因 解决方法
No module named 'playwright' 库没装 执行 pip install playwright
Executable doesn't exist 浏览器内核没装 执行 playwright install chromium
listdict 语法错误 Python 版本 < 3.9 把 listdict 改成 list
等待超时 0 条数据 页面结构可能变化 开 DevTools 检查选择器
页面跳转到 error.html 被反爬拦截 先手动访问首页再运行
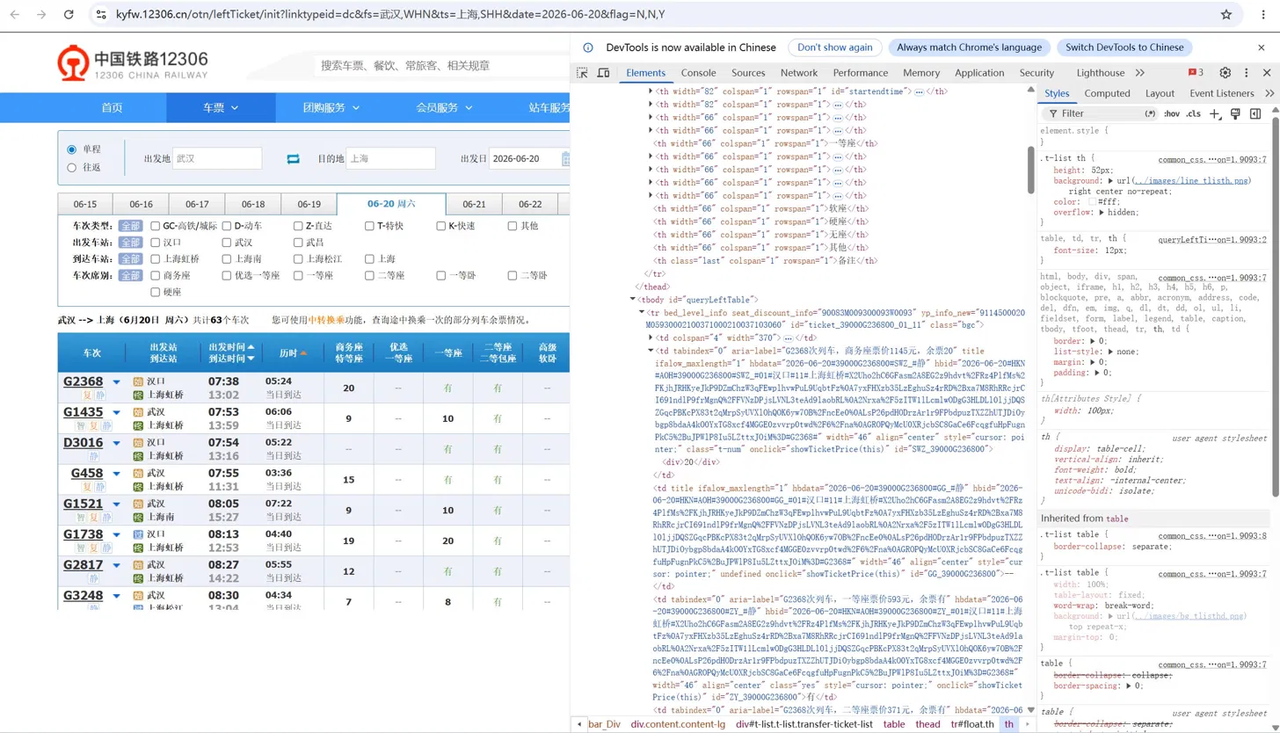
怎么用 DevTools 检查选择器
当程序提取不到数据时:
- 在弹出的浏览器中按 F12 打开 DevTools
- 点左上角箭头图标(元素选择器)
- 点击页面中的车次或余票数字
- 右侧 Elements 面板会高亮对应的 HTML
- 看这个元素的 id、class 是什么,对应更新代码里的选择器
七、核心 API 速查
这是本项目用到的所有 Playwright 关键方法,理解这些就掌握了 80% 的用法:
# 启动浏览器
browser = p.chromium.launch(headless=False)
# 新建页面(标签页)
page = browser.new_page()
# 跳转到某个 URL
page.goto("https://www.example.com")
# 等待某个元素出现(最重要!)
page.wait_for_selector("#queryLeftTable tr", timeout=20000)
# 用 CSS 选择器找单个元素
el = page.query_selector(".train-number")
# 用 CSS 选择器找多个元素(返回列表)
rows = page.query_selector_all("#queryLeftTable tr")
# 获取元素的文本内容
text = el.text_content().strip()
# 点击元素
page.locator("a#search_one").click()
# 捕获新标签页(12306 点查询会新开标签页)
with page.expect_popup() as popup_info:
page.locator("a#search_one").click()
new_page = popup_info.value
# 在页面里执行 JavaScript
page.evaluate("() => { document.getElementById('xxx').value = '123'; }")
# 等待页面加载完成
page.wait_for_load_state("domcontentloaded")八、扩展思路(学有余力)
完成基础版之后,可以挑战以下扩展:
扩展 1:发现有票自动提醒
# 在 print_report 里加:
for r in results:
if r["二等座"] not in ["--", "无", "候补"]:
print("★★★ {} 有二等座:{} ★★★".format(r["train_no"], r["二等座"]))
# 进阶:调用微信推送 API 发通知扩展 2:结果保存为 CSV
import csv
with open("tickets.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)扩展 3:把 headless 改成 True
静默后台运行,配合 monitor_interval=60,就是一个真正在后台工作的余票监控器。
九、本项目踩过的坑(调试记录)
这是从零到跑通经历的所有问题,整理出来帮助理解:
序号 问题 原因 解决方案
1 页面跳 error.html 直接访问查询 URL 被拦截 改为先访问首页再操作
2 下拉框显示北京不是武汉 输入汉字触发历史记录而非搜索 改用 JS 直接写入值
3 下拉框遮住日期框 下拉框没关闭 JS 强制 display:none
4 triple_click 报错 旧版 Playwright 无此方法 改用 Control+a + Delete
5 evaluate() 参数错误 不能传多个参数 打包成数组 a,b 传入
6 arguments 未定义 Playwright 不支持 arguments 改用箭头函数 (arg) => {}
7 查询按钮点不到 按钮是 不是 DevTools 查真实 id:a#search_one
8 提取 0 条数据 选择器 .bgc 不存在 改为直接等 #queryLeftTable tr
9 页面没跳转 12306 查询在新标签页打开 用 expect_popup() 捕获新页
文档版本:2026-06-15 | 基于实测调试整理