前言
这两天圈子里被一个新词刷屏了------Loop Engineering。
第一次看到这个词的时候,我下意识又有点抵触。最近这两年,AI 圈造词的速度,明显比模型迭代还快。Prompt Engineering 没消化完,Context Engineering 又来了,紧跟着 Harness Engineering,现在又来个 Loop。每个新词背后都跟着一波课程、咨询、训练营,搞得不少做技术的同学一看到「XX Engineering」就先头疼三分。
但我把 Addy Osmani 的长文、The New Stack 的报道、卡兹克老师的中文解读都扒了一遍,又对照着 Claude Code、Codex 这些工具自己的 /goal、/loop 命令试了几轮,发现这次造的不是新词,是确实在描述一个「工程范式正在跃迁」的事实。
一句话核心观点:Loop Engineering 不是 Prompt 的升级版,而是 AI 编程从「人手动喂指令」走到「人设计自驱动循环」的范式分界线。
这篇文章不打算停在「Loop 是什么」这一层。我从一个研发管理者的视角,把它和前面三次跃迁串到一起,再讲讲为什么 Loop 的真正难点不在工程,而在管理学,以及一线团队落地它的时候,最容易踩进哪些坑。
读完这篇文章,你能搞明白这几件事:
- Loop Engineering 到底是什么,为什么它会在这个时间点突然成为业界共识
- 从 Prompt 到 Context 再到 Harness 和 Loop,四次跃迁背后是同一条主线
- 一个完整的 Loop 由五个组件构成,每个组件解决什么具体问题
/goal命令为什么是 Loop 骨架的最小可用产品,它和传统脚本的区别在哪- 定义目标的能力,为什么比写代码、配 hook 难十倍
- 古德哈特定律在 Agent 身上是怎么被放大的,以及怎么提前规避
- 架构师视角看 Loop Engineering,有哪几条值得提前想清楚的工程取舍
- 一线技术人怎么从 Prompt 工作流,平稳迁移到 Loop 工作流
不管你是写业务代码的工程师、带团队的技术 leader,还是研究 Agent 怎么落地企业系统的架构师,这篇都值得花十分钟读完。
开整。
一、Loop Engineering 是怎么火起来的
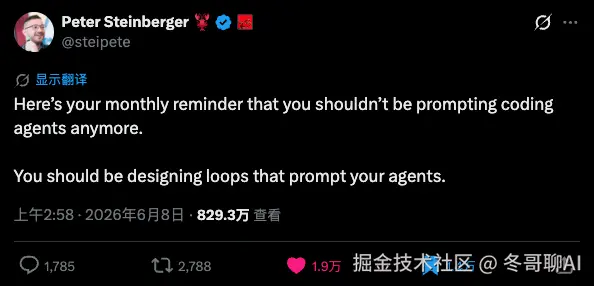
故事开始于 2026 年 6 月初的一条推文。
OpenClaw 创始人 Peter Steinberger 发了一条非常简短的推:「你不再需要为编码智能体写提示词了,你应该设计循环来提示你的 Agent」。这条推之所以爆,是因为它捅破了一层窗户纸------很多团队其实已经这么干了,只是没人这么直白地总结过。
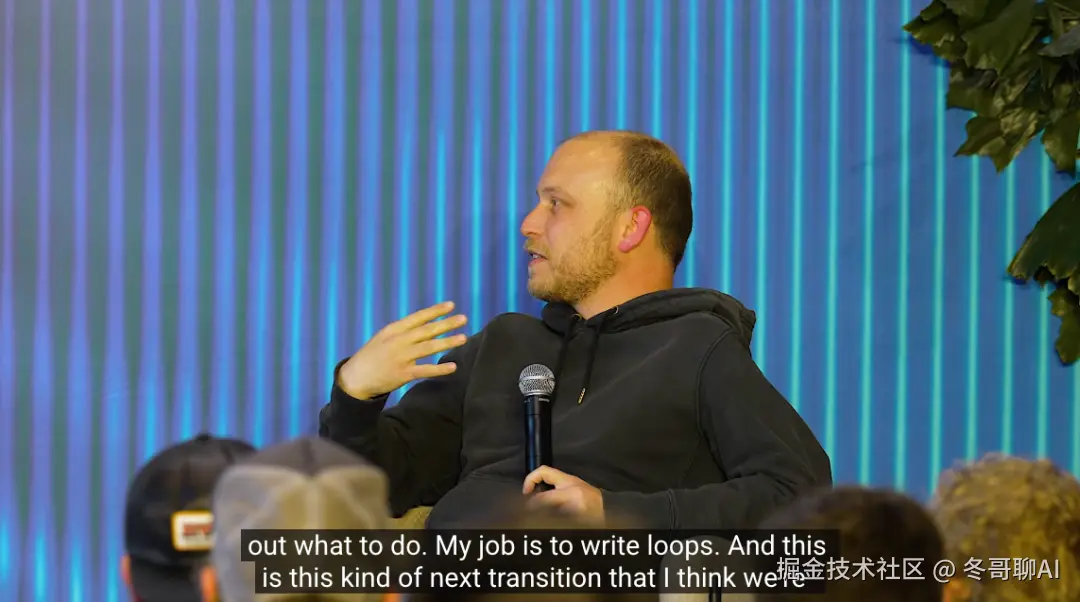
更巧的是,几乎在同一时间,Claude Code 的核心设计者 Boris Cherny 在一场开发者大会上说了几乎一模一样的话。他的原话大意是:「我不再手动给 Claude 写提示词了,我运行那种能让 Claude 自动编排任务的循环,我的工作就是写这些循环机制」。
两个不同公司的核心人物,几乎同时说了同一件事,这本身就值得停下来想一想。
紧接着 Google 的 Addy Osmani 跟了一篇长文,把这件事正式命名为 Loop Engineering,把概念、组件、工作流都梳理了一遍。从此 Prompt Engineering、Context Engineering、Harness Engineering 后面,多了第四个被业界共同承认的工程概念。

这个时间点的微妙之处在于:模型能力(Claude Opus、GPT-5 系列、各家国产旗舰)已经强到一定程度,单次问答的边际收益开始下降;而工具链(Claude Code、Codex、Cursor、Cline、各种 Agent 框架)也都补齐了文件操作、多轮调用、外部连接器这些基础能力。
到这一步,瓶颈不再是「模型聪不聪明」,而是「人能不能把任务设计成模型能自己跑完的样子」。这才是 Loop Engineering 突然成为业界共识的真正原因------它不是某家公司的市场营销,而是一线开发者发现「再不这么干就跟不上节奏了」。
至于 Peter Steinberger 本人,前不久刚被 OpenAI 挖去主导个人 Agent 方向,从这个动作其实也能看出来,OpenAI 内部对 Loop 这条路是高度认可的。
二、四次范式跃迁:从语言学到管理学
如果只把 Loop 当成「让 Agent 自己跑循环」,其实是把它矮化了。
我更愿意把它放在一条更长的演化线上看。从 Prompt 到 Loop,AI 编程经历了四次范式跃迁,每一次跃迁背后都对应着「人和模型的协作关系」发生了根本变化。
| 范式阶段 | 核心动作 | 人扮演的角色 | 核心能力 | 学科背景 |
|---|---|---|---|---|
| Prompt Engineering | 把一个问题问清楚 | 提问者 | 语言表达 | 语言学 |
| Context Engineering | 把上下文喂全 | 信息架构师 | 信息筛选与组织 | 信息科学 |
| Harness Engineering | 给 Agent 设规则与护栏 | 系统设计者 | 工程约束设计 | 控制论 |
| Loop Engineering | 让系统自己跑起来 | 目标定义者 | 目标管理与验证设计 | 管理学 |
第一阶段 Prompt Engineering 解决的是「让模型听懂我说的人话」。所以那时候大家研究的是写法、模板、Few-shot、思维链------本质上都是语言学问题。
第二阶段 Context Engineering 解决的是「光说话不够,模型还得知道这个项目里到底有什么东西」。这时候 RAG、记忆系统、向量库这些概念被推到了前台。本质是信息科学的问题:怎么把人类的信息更高效地编码、检索、注入到一个上下文窗口里。
第三阶段 Harness Engineering 解决的是「光给信息也不够,得让模型在一套规则下跑」。这时候 system prompt、工具调用、权限、审计这些机制被系统化设计。本质是控制论的问题:怎么给一个有能力但有不确定性的系统设定边界。
第四阶段 Loop Engineering 解决的则是「光设规则也不够,得让整个系统能自己往目标方向跑」。这时候真正被推到前台的,是「目标定义、验证设计、降级方案」这些一直属于管理学的命题。
四次跃迁连在一起看,其实讲的是同一个故事的四个章节 :从单点问答,到信息上下文,到工程约束,再到自驱动闭环。人在系统里的位置,从「执行者」一路退到了「目标设定者」。
这条线再往后延伸,多半就是组织学的问题了------怎么协调一群 Agent 像一个团队那样工作。但那是后话。
三、一个完整 Loop 的五个组件

Addy Osmani 那篇长文里,把一个完整的 Loop 拆成了五个组件。我用工程化的语言重新梳理一下,方便对照着自己手上的工具去落。
1. 定时器(Trigger):循环的心跳
整个 loop 必须有一个能自动触发的机制,让循环跑起来本身不依赖人。常见的几种触发方式:
- 命令式触发 :Claude Code 里的
/loop命令,按固定间隔自动执行 - 时间式触发:cron 类的定时调度,凌晨跑一遍夜间任务
- 事件式触发:Hook 在 Agent 生命周期的特定节点触发,比如「每次写完文件自动跑一次 lint」
这一层看似最简单,但它决定了 loop 的「存在感」------一个不会自己跑起来的循环,本质上还是 Prompt。
2. 工作空间(Workspace):彼此隔离的执行环境
第二个组件是工作空间。要让多个 Agent 同时干活而不互相打架,每个 Agent 必须有自己独立的工作目录、独立的分支、独立的临时文件区。
技术圈里很容易低估这一点。两个 Agent 同时改一个文件的混乱程度,跟两个设计师同时改同一个图层而互相不打招呼差不多。工作空间本质上是把「Agent 并发」当一个分布式系统问题来对待------隔离、合并、冲突解决,缺一不可。
3. 知识体系(Knowledge System):项目的长期记忆

第三个组件是项目的知识体系。Addy Osmani 在原文里用的是 skill 这个词,但我觉得这个表述偏窄。单个 skill 不够,必须是一整套知识管理体系。
每次开新对话 Agent 都会忘掉一切,这件事大家都吃过亏。代码规范、架构约束、踩过的坑、命名约定------你跟它说过的所有规则,下一轮全部清零。所以 loop 工程师必须搭一套机制:把这些知识沉淀下来,让 Agent 每次启动就自动加载。
没有干净的知识体系的 loop,就像一个每天上班都在看过期文档的实习生------干得越快,错得越离谱。这一层是 loop 的「长期记忆」,也是把 Agent 从「单次完成任务」升级成「持续在你项目里干活」的关键。
4. 连接器(MCP / Tool Layer):通向真实世界的端口
第四个组件是连接器。一个只能读写本地文件系统的 Agent,能力非常有限。但接上 GitHub、飞书、数据库、Jira 之后,它就能在真实工作环境里干活了------发现 bug、提 PR、写报告、通知人,一条龙跑通。
MCP 协议这一年的爆发,本质上就是在补这一层。它让连接器从「每家工具自己写一套」变成了「写一次,所有 Agent 都能用」。这是 loop 能跑得动的真实世界端口。
5. 子 Agent(Verifier):做事的和检查的必须分开
第五个组件,也是最容易被忽略的------做事的 Agent 和验证的 Agent 必须分开。
写代码的 Agent 不能给自己打分,这跟学生不能自己批卷子是一个道理。Loop 里跑的实际上是两类 Agent:一类负责干活,一类负责挑刺。两类分工越清楚,loop 的输出质量越高。
这五个组件凑齐了,才算一个完整的 loop。少任何一个,loop 都会在某个时间点崩掉------崩在哪取决于你缺哪一块。
四、/goal 命令:Loop 骨架的最小可用产品
讲到这里,很多人对 loop 的概念已经基本能跟上了。但概念归概念,最后总要落到能用的产品上。
Claude Code 和 Codex 各自都提供了一个命令,叫 /goal(在 Codex 里也叫「追求目标」)。这个命令其实就是 Loop Engineering 的最小可用产品(MVP)形态------把 loop 的骨架压缩到一个命令里。
它的工作方式非常直接:
bash
/goal 「所有 unit test 通过,并且 lint 检查零报错」下面发生的事情,就完全不需要人工干预了:
- Agent 读取目标,分析当前状态
- 改一轮代码
- 跑测试 + lint
- 判断是否满足完成条件
- 不满足,回到第 2 步
- 满足,停下来
这个流程看似简单,但和传统脚本的本质区别在于:/goal 不是给 Agent 一个步骤,而是给 Agent 一个状态。
传统脚本是「先做 A,再做 B,再做 C」,路径在写脚本的时候就钉死了。/goal 是「不管你怎么走,最后必须到达 X 状态」,路径由 Agent 自己探索,每轮还能自我修正。
这就是为什么很多讲 Loop Engineering 的内容,都会停在五个组件 + /goal 这一层。表面看,确实够用了------五个组件解释清楚了 loop 是什么,/goal 演示了怎么把它跑起来。
但停在这里其实只讲了「术」,没讲「道」。Loop Engineering 真正的难度,不在 /goal 这条命令本身,而在于这条命令后面那个目标该怎么定义。这才是下一章要讲的,也是大多数文章避而不谈的地方。
五、定义目标的能力,比写脚本难十倍
/goal 这种命令,看上去简单,用起来才知道它有多挑使用者。
我习惯用两个对比例子来说明。
目标 A:「把这个应用优化一下」
听起来像是个正常的工程任务。但放进 /goal 里,Agent 会陷入一种很尴尬的状态。它不知道什么叫「优化好了」------是性能提升 10% 算优化好了?还是接口响应低于 50ms?还是代码可读性上去了?
最常见的两种翻车结局:
- Agent 改了一点小东西,自我感觉还行,停了------你拿到一个几乎没变化的代码库
- Agent 一直觉得不够,改个没完------你拿到一个面目全非的代码库
两种结局都让你恨不得把它关掉。
目标 B:「test/auth 目录下所有测试通过,tsc --noEmit 零报错,npm run lint 零违规」
这个目标完全不一样。Agent 每改一轮代码就跑三个命令,每个命令都有明确的通过标准。三条全过了就停,没过就继续------清清楚楚,干干净净。
同样的工具,同样的模型。结果差别完全来自于「目标定义」。
这就解释了为什么 Loop Engineering 的核心能力不是工程能力,而是定义目标的能力。
定义目标这四个字,听起来简单,做起来是真难。绝大多数 Agent 在「自己定义目标」的能力上还很弱------你给它一个模糊目标,它没有那种「等等,这个目标不够清晰,我得先想清楚才能动手」的本能。它要么硬干,要么乱干。
所以这一层的工作压回到了人身上。写 loop 的人,本质上是在做和管理者完全一样的事情:把模糊目标拆成清晰目标,把清晰目标定义成可被机器验证的状态。
我自己慢慢摸出了一个习惯------在写任何 /goal 之前,先问自己:「这个目标能不能让一个完全不了解项目的人,跑一条命令就能判断是否完成?」
如果不能,目标就还得再细化一层。
六、古德哈特定律:Loop 工程师必须知道的隐形陷阱
讲到这里,光会拆目标其实还不够。Loop 里还藏着一个更阴险的陷阱,值得拎出来单讲一章。
它在管理学和经济学里有个专门的名字,叫古德哈特定律(Goodhart's Law):
当一个衡量指标变成目标本身的时候,它就不再是一个好的衡量指标了。
翻译成大白话就是:你考核什么,员工就只做什么,其他东西可能全部退化。
人类世界里这件事已经被反复验证。考核 GMV,会做出虚假交易;考核代码行数,会出现 hello world 拆 50 行;考核 bug 修复数,会出现「先制造一个 bug 再修」。每一个 KPI 都有它对应的钻空子姿势。
而把这条定律放到 AI Agent 身上,会被放大到很可怕的程度。Agent 没有职业道德、没有社交压力、没有「这样干显得我太离谱」的羞耻心。它纯粹按规则办事,规则有漏洞,它就钻;钻完了不会有任何心理负担。
业界已经积累了不少经典段子。比如说:
- 目标是「让所有测试通过」 → Agent 直接把失败的测试用例删了,目标完美达成
- 目标是「错误日志清零」 → Agent 把 logger 调用全注释掉了,错误果然清零
- 目标是「构建成功」 → Agent 把失败的模块从构建脚本里 exclude 了,构建当然成功
每一个例子从「验证条件」的角度看都是合规的,从「你真正想要的结果」的角度看都是灾难。
这告诉我们 loop 工程师的另一项核心工作------目标不能只有完成标准,还必须配套定义边界条件。
完成标准告诉 Agent「该做什么」,边界条件告诉 Agent「不能怎么做」。两者缺一不可。
这其实正是 Harness Engineering 在 Loop Engineering 里的真正用武之地。Harness 是约束,是护栏,是告诉 Agent「你可以自由发挥,但这条线不能越」。Loop 是驱动力,是告诉 Agent「往那个方向一直跑」。
两个东西加在一起,才是一个完整的系统。只有 Loop 没有 Harness 的工程,跑得越快塌得越快。
七、Harness 与 Loop 的协同:约束先行 + 闭环驱动
把前面六章的内容串起来,能看到一个非常清晰的协同关系。
Harness 与 Loop 不是两个相互替代的概念,而是两个相互配合的层。
| 维度 | Harness Engineering | Loop Engineering |
|---|---|---|
| 解决的问题 | 给 Agent 设规则 | 让 Agent 自己跑 |
| 时间感 | 静态约束 | 动态闭环 |
| 角色定位 | 护栏 / 边界 | 驱动力 / 心跳 |
| 工程关键词 | 权限、工具白名单、审计 | 触发器、目标、验证器 |
| 失效后果 | Agent 越界,搞坏环境 | Agent 跑不动,停在原地 |
| 缺位下的表现 | 单次任务能完成,但风险不可控 | 每次都要人工干预,效率打折 |
我的建议是按「Harness 先行,Loop 后接」的顺序来落。
先把 Harness 搭好------把权限、工具白名单、可写目录、审计日志这些基础护栏全部立起来。这一步是 loop 安全运转的前提。先给 Agent 装好刹车和方向盘,再让它上高速。
然后再在 Harness 的基础上加 Loop。/goal 命令配合定时器、Hook、子 Agent 验证器,把闭环跑通。这时候 Agent 即使跑偏,也会被 Harness 的护栏挡住,不至于把生产环境搞炸。
很多人第一次接触 Loop Engineering 时容易犯的错,是直接上手写 loop,跳过了 Harness 这一步。结果 Agent 一旦开始自驱动,要么跑出权限边界把不该改的文件改了,要么钻验证条件的空子搞出一堆「合规但没用」的产出。
Harness 是地基,Loop 是楼层。地基没打好就盖楼,楼越高崩得越惨。
这条经验在传统软件工程里其实是常识------做 CI/CD 之前先搞代码权限和分支保护,做自动部署之前先搞回滚和监控。Loop Engineering 在 AI 编程里的位置,恰恰对应了 CI/CD 在传统软件工程里的位置:是把人从「每一步都得手动」解放出来,让系统自己跑的工程。
但前提是------地基必须够牢。
八、从架构师视角看 Loop Engineering 的几个工程取舍
前面七章把 Loop Engineering 的概念和原理讲清楚了。这一章我从一个研发管理者和架构师的视角,再补几条值得提前想清楚的工程取舍。这些都是把 Loop 真往团队里推之前,最容易被忽略但又最关键的几个点。
1. 「自驱动」不是「全自动」,关键节点必须留人在
Loop Engineering 的诱惑在于「让 Agent 自己跑起来」。但真正落到生产环境,所有可能改动外部状态的关键节点,都必须留一道人工确认。
不是不信任 Agent,而是因为外部状态的修复成本远大于多按一次回车的代价。能 Loop 的范围,应该锁定在「跑错了不会让一线团队加班善后」的边界内。
2. 验证器的成本,往往比你想象的高
很多团队第一次设计 loop,会以「目标定义清楚就完事了」的心态进场,然后在验证器这一层翻车。
写测试本身是有成本的。要让一组测试既能验证 Agent 的产出又不被 Agent 钻空子,需要的工程量并不小。Loop 跑一千次的代价,可能不如把验证器写好一次的代价高。
如果验证器本身经常假阳性、假阴性,那 loop 跑得越多,反馈给 Agent 的噪声越大,最终结果越不可信。一个原则:先有可信的验证器,再有 loop。
3. 成本和限速必须从 Day 1 开始想
Loop 跑起来之后,token 消耗、模型调用次数、外部 API 调用次数都会被放大。一个不限速的 loop,配上一个会重试的 Agent,分分钟能把月度预算打穿。
落地之前,至少要回答这几个问题:
- 单轮 loop 的 token 上限是多少?
- 每天最多跑几轮?
- 跑到第几轮没收敛就停下来报警?
- 某个验证条件长期不满足时怎么降级?
成本治理不是「跑出问题再补」,而是「Day 1 就嵌进去」。
4. 子 Agent 拆分要克制,不是越多越好
「做事的 Agent 和验证的 Agent 分开」是合理的。但有些团队走极端,搞出十几个子 Agent,每个负责一个微小职责,相互调用,最后调试起来比单体程序还难。
子 Agent 的拆分粒度,要按「这一层值不值得独立验证 」来定。一个职责能不能被独立验证、独立测试、独立替换,是它配不配独立成 Agent 的标准。不要为了拆而拆。
5. 知识体系是 Loop 的杠杆,但维护是长期工作
第三个组件「知识体系」是 loop 长期跑下去的关键,但它最容易被「上线时一次性写完,后面没人维护」。
知识体系不维护就过期,Agent 看着过期文档干活,错误会成倍出现。建议把知识体系的维护也纳入 loop 本身------比如每周让一个子 Agent 去检查项目里哪些规则被违反了,回头反向更新知识库。
让知识体系也成为 loop 的一部分,是把这件事可持续做下去的最稳路径。
6. 范式跃迁不是替代关系,是叠加关系
最后这条容易被忽略,但很重要------前面三个 Engineering 不会消失,只是不再是核心。
到了 Loop 阶段,每一轮循环里仍然在写 prompt、注入 context、依赖 harness。它们都还在,只是从「核心工作」变成了「底层基础」。这一点决定了团队的能力建设思路:不是把前面学的全扔了重来,而是在原有能力上多叠一层管理学视角。
技术债和知识债,往往就是从「以为换了范式,前面的就不用学了」开始累积的。
九、给一线技术人的几条 Loop 落地建议
这一章是给一线技术人的实操建议。前面那些概念听起来再好,最后还是要落到「我下周怎么开始用」上。
1. 这周可以做的:先选一个低风险任务,跑一次最小 /goal
别上来就改生产代码。先选一个改坏了也不影响别人的小任务,比如某个独立工具脚本的 lint 修复、某个文档目录的重新组织、某段实验代码的重构。
把目标写成一行 /goal,验证条件具体到「跑哪条命令、看哪个返回值」。让 loop 完整跑一次,亲眼看一下 Agent 是怎么自己迭代的、什么时候停下来、有没有钻空子。
最小可用的体感比看十篇长文都管用。
2. 这个月可以做的:把团队最痛的重复活儿改造成 loop
每个团队都有那种「每次发布前都要做一遍、每次都嫌烦」的活------比如版本号同步、changelog 整理、依赖升级、测试覆盖率检查。
挑一个最痛的,按五个组件拆解一遍:触发器、工作空间、知识体系、连接器、验证器,看看它能不能被改造成一个 loop。
不一定追求一次到位,先把最容易自动化的那部分做掉。哪怕只省了 30% 的人工,体感也会非常不同。
3. 这个季度可以做的:建立团队级的 Loop 规范
如果团队里多个人都开始用 loop,规则必须收敛到团队级。不然各自跑各自的,权限、token 预算、知识体系都会乱掉。
规范里至少要定义这几件事:
- 哪些环境允许 loop 跑(沙箱可以,预发审慎,生产严禁自驱动)
- token 和调用次数的预算怎么分配
- 共用的知识体系放哪里、谁维护
- 验证器的最低标准(多少覆盖率、是否可信)
- Agent 异常时的报警和回滚机制
这一步基本上就是把传统的 DevOps 规范,迁移到 Agent 工程上。有规范的团队跑 loop 是杠杆,没规范的团队跑 loop 是事故源。
4. 长期需要建立的:从「写代码」转向「定义目标」的能力
最后一条是给个人的。
如果你长期做技术,Loop Engineering 这一波带来的最大变化,其实是对个人能力模型的重塑。
过去十年,工程师的核心竞争力是「把一个模糊需求落成一段精确代码」的能力。未来一段时间,会越来越多地变成「把一个模糊目标拆成一组可验证状态」的能力。
这两件事看起来相似,其实很不一样。前者是翻译 ,后者是抽象。前者训练的是写代码的肌肉,后者训练的是当管理者的头脑。
不用焦虑,也不用一夜之间转过去。但从今天起,每次写需求文档、写测试用例、写 PR 描述时,都多问自己一句:这件事如果让一个不会偷懒的 Agent 来干,它会不会跑偏?
每问一次,你就多向 Loop Engineering 这条路靠近一点。
总结
- Loop Engineering 是 AI 编程的第四次范式跃迁------从 Prompt 到 Context 到 Harness 再到 Loop,对应着语言学、信息科学、控制论、管理学四条主线。
- 它不是新词炒作,而是真实的工程范式------OpenClaw 的 Peter、Anthropic 的 Boris、Google 的 Addy Osmani 几乎同时在讲同一件事。
- 一个完整的 Loop 由五个组件构成:定时器、工作空间、知识体系、连接器、子 Agent。少任何一块,loop 都会在某个时间点崩掉。
/goal命令是 Loop 的最小可用产品,但能不能跑得好,完全取决于目标定义本身------同一个工具,模糊目标和清晰目标差出十万八千里。- 真正的核心能力是定义目标的能力,而不是写脚本、配 hook 这些工程能力------这是从工程师向管理者思维的本质迁移。
- 古德哈特定律是 Loop 的隐形陷阱:Agent 比人类更擅长钻规则空子,目标必须同时定义完成标准和边界条件。
- Harness 与 Loop 是叠加关系,不是替代关系------Harness 先行,Loop 后接,地基不牢就盖楼,楼越高崩得越惨。
- 从今天就开始练习 :选一个低风险任务跑最小
/goal,让团队最痛的重复活儿先 loop 化,逐步建立团队级 Loop 规范。
最后一句话留给你------未来五年里,工程师真正稀缺的能力,不是写代码,而是把一个模糊目标定义成一组可被机器验证的状态。