全栈项目部署实战指南:Java / Python / Vue / React 一站式搞定
从本地开发到生产上线,覆盖 Spring Boot、FastAPI/Flask、Vue、React 四大技术栈的完整部署方案,结合 Docker 容器化 + Nginx 反向代理 + CI/CD 自动化,帮你打通项目上线的"最后一公里"。
本文中的所有部署方式,均来自我日常工作中维护的多个生产项目,以及个人开源项目的实战经验。如果对你有帮助,希望给我的开源项目点赞支持一下吧,你们的点赞和收藏都是我的动力! github.com/DevYangJC
🧪 实战推荐: 如果你想找一个前后端分离的真实项目来练手部署,推荐试试我的开源项目 ------ DataLoom ,把在线表格(类似 Excel)像零件一样装进你的项目里。它的架构和本文完全对应:前端是独立 SPA(Vue 3 + Luckysheet)、后端是独立微服务(Spring Boot)、前后端之间只有 REST API 通信。读完本文后,用它来实操一遍"前端 Nginx 托管 + 后端脚本部署 + Nginx 反向代理"的完整流程,体会会更深刻。
目录
- 一、部署前置:服务器环境准备
- 二、Java(Spring Boot)项目部署
- 三、Python(FastAPI / Flask)项目部署
- 四、前端(Vue / React)项目部署
- 五、Nginx 反向代理与域名配置
- 六、Docker Compose 一键编排
- 七、CI/CD 自动化部署
- 八、生产环境最佳实践
- 九、常见问题排查
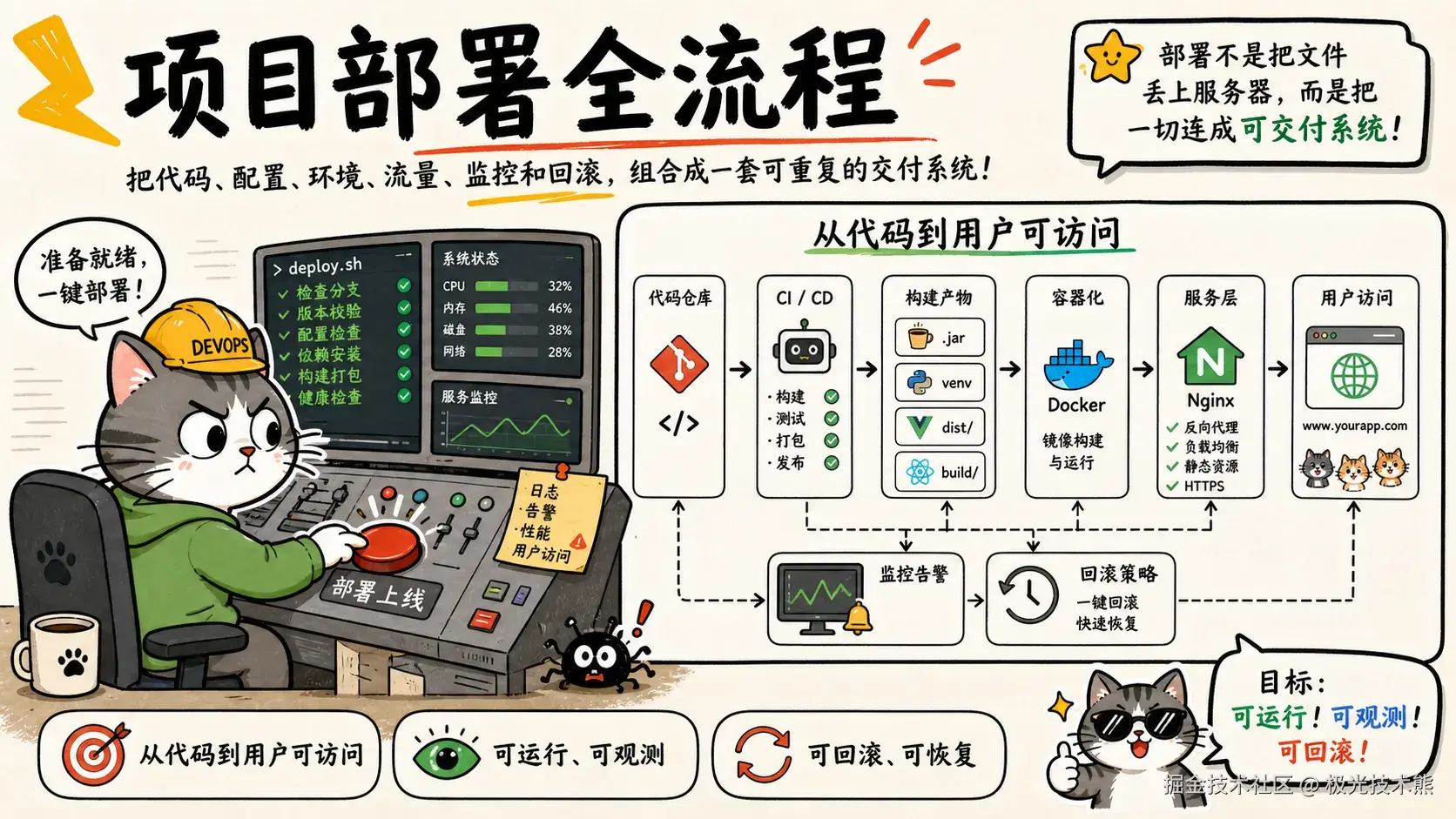
一、部署前置:服务器环境准备
1.1 服务器选型建议
| 场景 | 推荐配置 | 适用项目 |
|---|---|---|
| 个人项目/测试 | 2C4G | 单体应用、静态前端 |
| 中小型生产 | 4C8G | Spring Boot + 前端 |
| 中大型生产 | 8C16G+ | 微服务、多容器编排 |
云服务商选择:国内推荐阿里云、腾讯云、华为云;海外推荐 AWS、DigitalOcean。学生和开发者可关注各厂商的优惠活动,通常首年价格极低。
1.2 基础环境安装
在开始安装之前,先想清楚一个问题:你部署的项目用到了哪些技术? 不同的项目需要不同的运行环境,没必要一股脑全装上。下面这张表帮你快速判断:
| 你要部署什么 | 必装环境 | 可选环境 |
|---|---|---|
| Spring Boot 项目 | JDK 17+ | Maven(服务器构建时需要) |
| FastAPI / Flask 项目 | Python 3.10+、pip | Nginx(生产环境反向代理) |
| Vue / React 前端项目 | Node.js 20+(构建时需要) | Nginx(托管静态文件) |
| 使用 Docker 部署 | Docker、Docker Compose | --- |
| 需要数据库 | MySQL / PostgreSQL | Redis(缓存) |
安装顺序建议:先装基础工具(curl、git 等)→ 再装运行环境(JDK、Python、Node)→ 最后装基础设施(Docker、Nginx、数据库)。因为后面的软件可能依赖前面的工具来下载和安装。
以 CentOS 7/8 为例,下面按步骤安装:
bash
# ========================================
# 第一步:系统更新(装任何东西之前先更新)
# ========================================
# CentOS 7
sudo yum update -y
# CentOS 8 / Rocky Linux / AlmaLinux
sudo dnf update -y
# ========================================
# 第二步:基础工具(必须装,后面都会用到)
# ========================================
sudo yum install -y curl wget git vim unzip net-tools lsof
# curl - 下载文件用(装 Docker、Node 都靠它)
# wget - 另一个下载工具,某些脚本只支持 wget
# git - 拉代码用
# vim - 编辑配置文件
# unzip - 解压 zip 包
# net-tools - netstat 等网络排查工具
# lsof - 查看端口占用(服务启动失败时排查用)
# ========================================
# 第三步:Docker 和 Docker Compose
# ========================================
# 安装 Docker
curl -fsSL https://get.docker.com | sh
sudo systemctl start docker
sudo systemctl enable docker
# 把当前用户加入 docker 组,这样不用每次都 sudo
sudo usermod -aG docker $USER
# ⚠️ 执行上面这条后需要重新登录 SSH 才能生效
# 安装 Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" \
-o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# 验证
docker --version
docker-compose --version
# ========================================
# 第四步:Nginx(前端托管 + 反向代理)
# ========================================
# CentOS 必须先装 epel-release 源,不然找不到 nginx 包
sudo yum install -y epel-release
sudo yum install -y nginx
sudo systemctl start nginx
sudo systemctl enable nginx
# ========================================
# 第五步:JDK 17(Java 项目必装)
# ========================================
sudo yum install -y java-17-openjdk java-17-openjdk-devel
# 验证
java -version
# javac -version # 验证开发工具包(服务器构建时需要)
# 如果你的项目还在用 JDK 8 或 11,装对应版本:
# sudo yum install -y java-11-openjdk # JDK 11
# sudo yum install -y java-1.8.0-openjdk # JDK 8
# 多版本 JDK 共存时,用 alternatives 切换默认版本:
# sudo alternatives --config java
# ========================================
# 第六步:Python 3(FastAPI / Flask 项目必装)
# ========================================
# CentOS 7(系统自带 Python 2,需要额外装 Python 3)
sudo yum install -y https://repo.ius.io/ius-release-el7.rpm
sudo yum install -y python3u python3u-pip python3u-venv
# CentOS 8+ 自带 Python 3
sudo dnf install -y python3 python3-pip
# 验证
python3 --version
pip3 --version
# 设置 pip 国内镜像(加速下载,默认源在国外很慢)
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# ========================================
# 第七步:Node.js 20+(前端构建时需要)
# ========================================
# 注意:Node.js 只在"服务器上直接构建"时才需要
# 如果你在本地构建好 dist/ 再上传服务器,可以不装
curl -fsSL https://rpm.nodesource.com/setup_20.x | sudo bash -
sudo yum install -y nodejs
# 验证
node --version
npm --version
# 设置 npm 国内镜像(加速下载)
npm config set registry https://registry.npmmirror.com
# ========================================
# 第八步:Git(如果需要在服务器上拉代码)
# ========================================
sudo yum install -y git
# 配置 Git 用户信息(首次使用需要)
git config --global user.name "你的名字"
git config --global user.email "your@email.com"
# 如果需要从私有仓库拉代码,配置 SSH 密钥:
# ssh-keygen -t ed25519 -C "your@email.com"
# 然后把 ~/.ssh/id_ed25519.pub 的内容添加到 Git 平台的 SSH Keys 设置中安装后验证清单 :装完跑一遍,确保每个工具都正常工作。如果某个命令报
command not found,说明没装上或者环境变量没配好:
bashjava -version # ✅ 应该输出 openjdk version "17.x.x" python3 --version # ✅ 应该输出 Python 3.x.x node --version # ✅ 应该输出 v20.x.x docker --version # ✅ 应该输出 Docker 2x.x.x nginx -v # ✅ 应该输出 nginx version: nginx/1.x.x git --version # ✅ 应该输出 git version 2.x.x
1.3 部署前检查清单
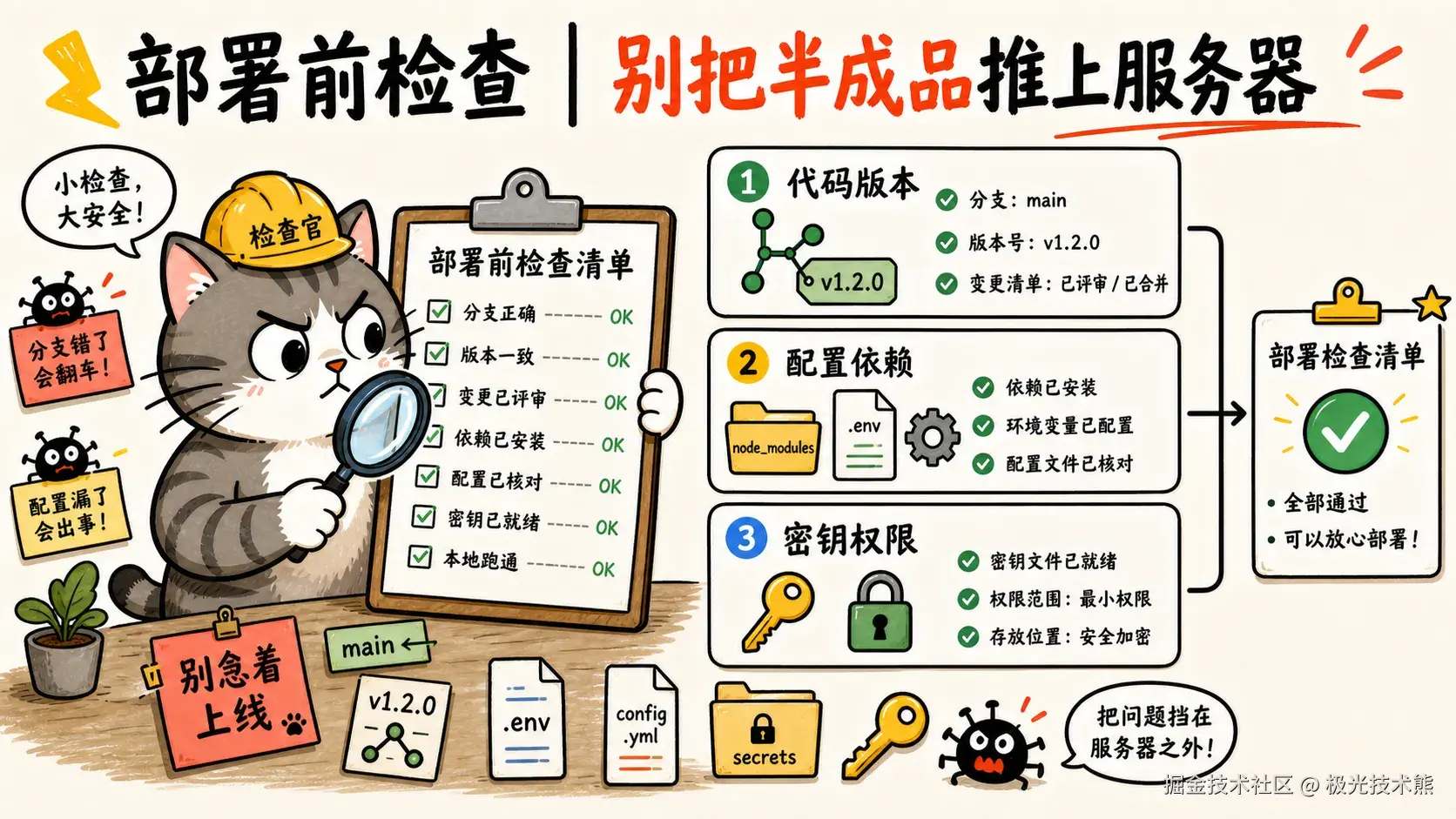 很多新手拿到一台服务器就急着装软件、传代码、启动服务,结果到处报错------端口被占了、数据库连不上、文件权限不对、 配置文件 少写了逗号......这些问题如果在部署前花 10 分钟检查一遍,能省下好几个小时的排错时间。
很多新手拿到一台服务器就急着装软件、传代码、启动服务,结果到处报错------端口被占了、数据库连不上、文件权限不对、 配置文件 少写了逗号......这些问题如果在部署前花 10 分钟检查一遍,能省下好几个小时的排错时间。
部署前的检查就像出门旅行前的"伸手要钱"(身份证、手机、钥匙、钱包)------看似啰嗦,但少一样都走不了。
1️⃣ 代码与版本检查
| 检查项 | 怎么检查 | 为什么重要 |
|---|---|---|
| 代码是否已提交并推送到远程 | git status 看有没有未提交的改动 |
你部署的应该是远程仓库的代码,而不是本地改了一半的版本 |
| 部署的版本号是否正确 | git tag 或 git log --oneline -5 确认当前版本 |
避免部署了错误的分支或旧的提交 |
| 分支是否正确 | git branch 确认是 release/main 分支 |
部署了开发分支的代码上生产,后果你懂的 |
| JAR 包 / 构建产物是否最新 | 对比构建时间和代码提交时间 | 避免用了缓存的旧包,新代码没打进去 |
bash
# 在本地或 CI 环境中执行
git status # 确认没有未提交的改动
git log --oneline -5 # 确认最新提交是你期望的版本
git tag -l "v*" # 查看所有版本标签
# 打一个版本标签(发布时建议打 tag)
git tag -a v1.2.0 -m "发布 v1.2.0"
git push origin v1.2.02️⃣ 配置与依赖检查
| 检查项 | 怎么检查 | 为什么重要 |
|---|---|---|
| 配置文件是否齐全 | 确认 application-prod.yml / .env 等文件存在 |
缺了配置文件,服务启动后连不上数据库、读不到参数 |
| 数据库连接信息是否正确 | 检查 host、port、用户名、数据库名 | 配置写错了或者指向了测试库,生产数据就乱套了 |
| 第三方服务密钥是否配置 | 检查短信、支付、OSS 等的 API Key | 缺了密钥,相关功能全部不可用 |
| 依赖版本是否匹配 | 对比开发环境和生产环境的 JDK/Python/Node 版本 | "在我电脑上能跑"最常见的原因就是版本不一致 |
| 环境变量是否设置 | 检查 .env 文件或 export 的变量 |
密码、密钥等敏感配置通常通过环境变量注入 |
bash
# 检查配置文件是否存在且内容完整
ls -la /opt/app/user-service/config/
cat /opt/app/user-service/config/application-prod.yml
# 检查关键配置项
grep -E "datasource|redis|port" /opt/app/user-service/config/application-prod.yml
# 测试数据库是否可连接(在服务器上执行)
mysql -h 10.0.0.100 -u appuser -p -e "SELECT 1" # MySQL
# python3 -c "import redis; r=redis.Redis(host='10.0.0.100',port=6379,password='xxx'); print(r.ping())" # Redis
# 检查 Python 依赖是否安装
pip3 list | grep -E "fastapi|flask|gunicorn|uvicorn"
# 检查 Node.js 依赖是否安装(前端项目)
ls node_modules/ | head # 确认依赖已安装3️⃣ 权限与密钥检查
| 检查项 | 怎么检查 | 为什么重要 |
|---|---|---|
| SSH 密钥是否配置 | ssh -T git@github.com 测试连通性 |
没有密钥就没法从私有仓库拉代码 |
| 文件目录权限是否正确 | ls -la /opt/app/ 查看权限 |
权限不对会导致应用无法读取配置或写入日志 |
| 应用是否以非 root 用户运行 | 检查启动脚本中的用户身份 | root 运行应用一旦被攻破,整个服务器都沦陷 |
| SSL 证书是否有效 | openssl x509 -enddate 检查过期时间 |
证书过期用户访问会提示"不安全",直接流失用户 |
| 数据库用户权限是否最小化 | 检查应用用的数据库账号是否只有必要的权限 | 给应用 root 权限 = 给小偷配了万能钥匙 |
bash
# ---- SSH 密钥检查 ----
# 测试 GitHub SSH 连通性
ssh -T git@github.com
# ✅ 看到 "Hi xxx! You've successfully authenticated" 说明密钥配置正确
# 生成新的 SSH 密钥(如果没有的话)
ssh-keygen -t ed25519 -C "deploy@myapp"
# 把公钥添加到 Git 平台:cat ~/.ssh/id_ed25519.pub 复制内容
# ---- 文件权限检查 ----
# 应用目录权限:所有者可读写执行,组和其他用户只读
ls -la /opt/app/user-service/
# ✅ 正确:drwxr-xr-x appuser appgroup ...
# ❌ 危险:drwxrwxrwx (777,任何人都能改)
# 修正权限
chown -R appuser:appgroup /opt/app/user-service/
chmod 755 /opt/app/user-service/bin/
chmod 600 /opt/app/user-service/config/application-prod.yml # 配置文件只有所有者可读写
# ---- SSL 证书有效期检查 ----
# Let's Encrypt 证书有效期 90 天,务必设置自动续期
openssl x509 -enddate -noout -in /etc/letsencrypt/live/example.com/fullchain.pem
# 检查自动续期定时任务
sudo crontab -l | grep certbot
# 如果没有,添加一个:
# echo "0 3 * * * certbot renew --quiet" | sudo crontab -4️⃣ 网络与端口检查
| 检查项 | 怎么检查 | 为什么重要 |
|---|---|---|
| 应用端口是否被占用 | lsof -i :8080 或 `netstat -tlnp |
grep 8080` |
| 服务器能否访问外部网络 | curl -I https://www.baidu.com |
服务器出不了外网,npm install / pip install 就会失败 |
| 数据库服务器是否可达 | telnet 10.0.0.100 3306 或 nc -zv 10.0.0.100 3306 |
连不上数据库,应用启动就报错 |
| 防火墙是否放通了必要端口 | sudo firewall-cmd --list-ports |
端口没开,外部请求根本进不来 |
| DNS 解析是否正常 | nslookup your-domain.com 或 dig your-domain.com |
域名没解析到服务器 IP,用户访问不了 |
bash
# 检查端口占用(部署前务必检查!)
lsof -i :8080 # 检查 8080 端口
lsof -i :80 # 检查 80 端口
netstat -tlnp | grep -E "8080|80|443|3306"
# 如果端口被占用,找到并停掉占用的进程
kill -15 <PID> # 先礼貌退出
# kill -9 <PID> # 实在不停再强制杀
# 测试服务器网络连通性
curl -I https://www.baidu.com # 测试外网
ping 10.0.0.100 # 测试内网数据库服务器
nc -zv 10.0.0.100 3306 # 测试数据库端口是否可连
nc -zv 10.0.0.100 6379 # 测试 Redis 端口是否可连
# DNS 解析检查
nslookup your-domain.com
# 如果域名还没解析,可以先在本地 hosts 文件中临时配置:
# echo "你的服务器IP your-domain.com" | sudo tee -a /etc/hosts5️⃣ 磁盘与资源检查
| 检查项 | 怎么检查 | 为什么重要 |
|---|---|---|
| 磁盘剩余空间 | df -h |
磁盘满了日志写不进去、数据库崩溃,问题一个比一个大 |
| 内存是否充足 | free -h |
内存不够 Java 直接 OOM 崩掉 |
| CPU 负载是否正常 | `top -bn1 | head -5` |
| 日志清理策略是否设置 | du -sh /var/log/ 检查日志大小 |
日志无限增长是磁盘爆满的头号原因 |
bash
# 磁盘空间(使用率超过 80% 就要警惕了)
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/vda1 40G 15G 23G 40% / ← ✅ 正常
# /dev/vda1 40G 35G 3G 93% / ← ⚠️ 危险!赶紧清理
# 内存(关注 available 列,这是实际可用内存)
free -h
# total used free available
# Mem: 7.6G 3.2G 1.1G 4.0G ← ✅ 充裕
# Mem: 7.6G 6.8G 128M 500M ← ⚠️ 偏紧,考虑加内存或减少 JVM 分配
# CPU 负载(load average 三个数分别代表 1/5/15 分钟的平均负载)
# 数值超过 CPU 核心数说明过载了
top -bn1 | head -5
# 大文件排查(找出占空间最多的目录)
du -sh /* | sort -rh | head -10一键检查脚本 :如果你觉得上面逐项检查太麻烦,可以把所有检查项写成一个脚本,部署前跑一次就行。把下面的脚本保存为
pre-deploy-check.sh,每次部署前执行bash pre-deploy-check.sh:
bash#!/bin/bash # 部署前一键检查脚本 # 用法: bash pre-deploy-check.sh PASS=0; FAIL=0 check() { local desc="$1" cmd="$2" echo -n "[$(echo $desc | cut -c1-20)] ... " if eval "$cmd" &>/dev/null; then echo "✅ 通过"; ((PASS++)) else echo "❌ 未通过"; ((FAIL++)) fi } echo "========== 部署前检查 ==========" echo "" echo "--- 环境 ---" check "Java 安装" "java -version" check "Python 安装" "python3 --version" check "Node.js 安装" "node --version" check "Docker 安装" "docker --version" check "Nginx 安装" "nginx -v" check "Git 安装" "git --version" echo "" echo "--- 网络 ---" check "外网连通" "curl -sI https://www.baidu.com" check "DNS 解析" "nslookup baidu.com" echo "" echo "--- 资源 ---" check "磁盘 > 20%" "test $(df / | tail -1 | awk '{print $5}' | tr -d '%') -lt 80" check "内存 > 500M" "test $(free -m | awk '/Mem/{print $7}') -gt 500" echo "" echo "========== 结果: ✅ ${PASS} 通过, ❌ ${FAIL} 未通过 ==========" if [ $FAIL -gt 0 ]; then echo "⚠️ 请先修复未通过的项目再进行部署!" exit 1 fi
1.4 防火墙与安全组
bash
# CentOS 7/8 使用 firewalld
sudo systemctl start firewalld
sudo systemctl enable firewalld
# 开放常用端口
sudo firewall-cmd --permanent --add-port=22/tcp # SSH
sudo firewall-cmd --permanent --add-port=80/tcp # HTTP
sudo firewall-cmd --permanent --add-port=443/tcp # HTTPS
sudo firewall-cmd --permanent --add-port=8080/tcp # Spring Boot 默认端口
# sudo firewall-cmd --permanent --add-port=3306/tcp # MySQL(仅内网访问,不建议公网开放)
# 重载防火墙使规则生效
sudo firewall-cmd --reload
# 查看已开放端口
sudo firewall-cmd --list-ports安全提醒:数据库端口(3306、5432、6379 等)务必不要直接暴露在公网,应通过安全组限制为内网访问。
二、Java(Spring Boot)项目部署
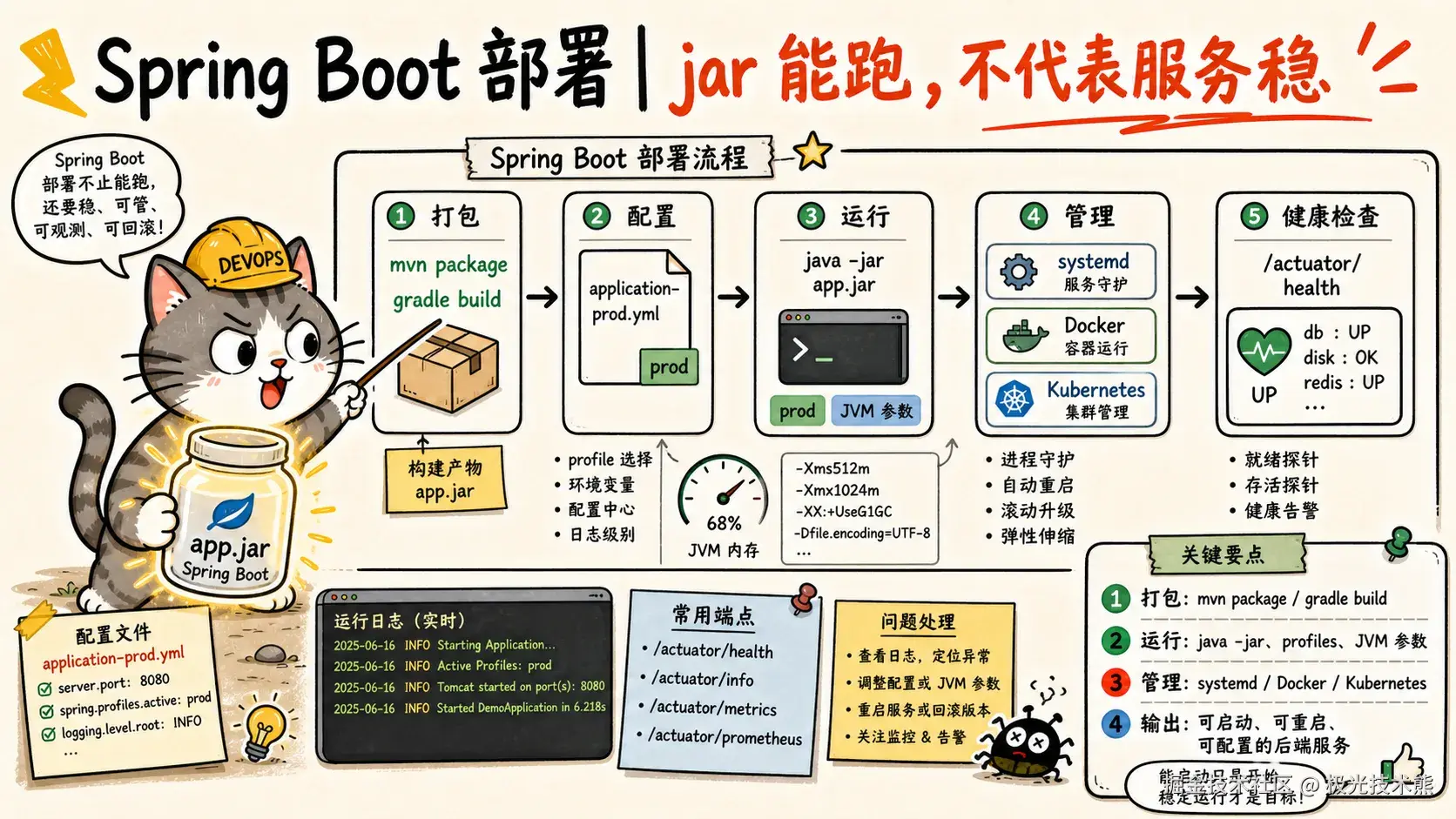
2.1 项目打包
Spring Boot 项目内嵌 Tomcat,直接打成可执行 JAR 即可:
bash
# Maven 项目
mvn clean package -DskipTests
# Gradle 项目
gradle clean build -x test构建产物在 target/ 目录下,类似 user-service-1.0.0.jar。
2.2 方式一:脚本化部署(推荐,多服务运维首选)
为什么要用脚本部署?
你可能想问:Java 项目直接一条 java -jar xxx.jar 不就能跑了吗?确实能跑,但问题来了------你的服务器重启了怎么办?服务挂了怎么办?你要更新 JAR 包怎么办?每次都手动敲命令,时间长了自己都忘了怎么操作,换个人来接手更是两眼一抹黑。
脚本化部署就是把日常操作"录"下来,变成一条命令就能搞定的事情。就像微波炉的"一键热牛奶"按钮,你不需要知道微波炉内部怎么运作,按一下就行。同样的道理:
- 服务没启动,运行脚本 → 自动启动
- 服务已经在跑,运行同一个脚本 → 自动重启(先停再启)
- 要更新版本,运行备份脚本 → 旧版本安全保存,出问题随时回退
这种方式最大的好处就是简单可靠------不需要学 Docker、不需要懂容器网络、不需要额外的运维工具,一台装了 Java 的 Linux 服务器就能跑。对于大多数中小项目来说,这就够了。
目录结构设计
在开始之前,先说清楚文件放在哪里。一个好的目录结构就像一个整理好的工具箱------扳手在哪、螺丝刀在哪,一目了然,不用每次都翻箱倒柜。
我们规定所有服务都放在 /opt/app/ 下面,每个服务一个独立的文件夹,里面的子目录各有各的用处:
bash
/opt/app/
├── user-service/ # 用户服务
│ ├── app/
│ │ └── user-service.jar # JAR 包(应用本体)
│ ├── config/
│ │ └── application-prod.yml # 外部配置文件
│ ├── logs/ # 运行日志
│ ├── tmp/ # 临时文件(存放 PID 文件等)
│ └── bin/
│ ├── restart.sh # 重启/启动脚本(核心,就这一个)
│ └── backup.sh # 备份脚本
│
├── api-gateway/ # API 网关
│ ├── app/
│ │ └── api-gateway.jar
│ ├── config/
│ │ └── application-prod.yml
│ ├── logs/
│ ├── tmp/
│ └── bin/
│ ├── restart.sh
│ └── backup.sh
│
└── backup/ # 发布备份(回滚用)
├── user-service/
└── api-gateway/这些目录都是什么用?用大白话给你解释一下:
| 目录 | 里面放什么 | 为什么要单独放 |
|---|---|---|
app/ |
JAR 包,你的应用本体 | 和配置文件分开,更新时只需替换这里面的 JAR 包,配置不受影响 |
config/ |
application-prod.yml 外部配置 |
改数据库密码、调端口号,直接编辑这个文件就行,不用重新打包 |
logs/ |
运行产生的日志文件 | 日志会越来越大,单独放方便定期清理,不会撑爆磁盘 |
tmp/ |
PID 文件(记录进程号) | 脚本靠这个文件判断服务是否在运行,就像门上挂的"有人/无人"牌子 |
bin/ |
管理脚本 | 所有运维操作都在这里,一条命令搞定 |
backup/ |
旧版本 JAR 包备份 | 更新前自动备份,万一新版本有问题,把旧的换回来就行 |
一键初始化目录结构
每新增一个服务都要手动建这么多文件夹?当然不用。下面这个初始化脚本帮你一键创建好所有目录,新项目部署时跑一次就行:
bash
#!/bin/bash
#===================================================
# 初始化服务目录结构
# 用法: ./init-structure.sh <服务名>
# 示例: ./init-structure.sh user-service
#===================================================
APP_HOME="/opt/app"
SVC_NAME=$1
# 检查参数
if [ -z "$SVC_NAME" ]; then
echo "❌ 请提供服务名称!"
echo "用法: $0 <服务名>"
echo "示例: $0 user-service"
exit 1
fi
SVC_DIR="$APP_HOME/$SVC_NAME"
# 检查是否已存在
if [ -d "$SVC_DIR" ]; then
echo "⚠️ 目录已存在: $SVC_DIR"
read -p "是否继续?(会跳过已存在的目录)[y/N] " confirm
if [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; then
echo "已取消"
exit 0
fi
fi
echo "🔧 正在初始化服务目录: $SVC_DIR"
# 创建各子目录
mkdir -p "$SVC_DIR/app"
mkdir -p "$SVC_DIR/config"
mkdir -p "$SVC_DIR/logs"
mkdir -p "$SVC_DIR/tmp"
mkdir -p "$SVC_DIR/bin"
mkdir -p "$APP_HOME/backup/$SVC_NAME"
# 创建重启脚本
cat > "$SVC_DIR/bin/restart.sh" << 'SCRIPT'
#!/bin/bash
#===================================================
# 服务重启/启动脚本
# 逻辑:服务没启动 → 启动;已经在跑 → 重启
# 用法: ./restart.sh [prod|dev]
#===================================================
# ---- 基础配置(按实际项目修改这三行)----
APP_NAME="这里改成你的服务名"
JAR_NAME="这里改成你的jar包名.jar"
ACTIVE_PROFILE=${1:-prod}
# ---- 以下不用改 ----
APP_DIR=$(cd "$(dirname "$0")/.." && pwd)
JAR_PATH="$APP_DIR/app/$JAR_NAME"
CONFIG_DIR="$APP_DIR/config"
LOG_DIR="$APP_DIR/logs"
PID_FILE="$APP_DIR/tmp/app.pid"
# JVM 参数
JVM_OPTS="-Xms512m -Xmx1024m"
JVM_OPTS="$JVM_OPTS -XX:+UseG1GC"
JVM_OPTS="$JVM_OPTS -XX:+HeapDumpOnOutOfMemoryError"
JVM_OPTS="$JVM_OPTS -XX:HeapDumpPath=$LOG_DIR/heapdump.hprof"
JVM_OPTS="$JVM_OPTS -Djava.security.egd=file:/dev/./urandom"
JVM_OPTS="$JVM_OPTS -Dfile.encoding=UTF-8"
# 颜色输出
RED='\033[0;31m'; GREEN='\033[0;32m'; YELLOW='\033[1;33m'; NC='\033[0m'
info() { echo -e "${GREEN}[INFO]${NC} $1"; }
warn() { echo -e "${YELLOW}[WARN]${NC} $1"; }
error() { echo -e "${RED}[ERROR]${NC} $1"; }
# 获取 PID
get_pid() {
if [ -f "$PID_FILE" ]; then
cat "$PID_FILE" 2>/dev/null
fi
}
# 检查是否在运行
is_running() {
local pid=$(get_pid)
[ -z "$pid" ] && return 1
if ps -p "$pid" > /dev/null 2>&1; then
return 0
else
rm -f "$PID_FILE"
return 1
fi
}
# 停止服务
do_stop() {
if ! is_running; then
warn "$APP_NAME 未在运行"
return 0
fi
local pid=$(get_pid)
info "正在停止 $APP_NAME (PID: $pid) ..."
# 先发 SIGTERM,让应用优雅关闭(保存数据、释放连接)
kill -15 "$pid"
# 等最多 30 秒
for i in $(seq 1 30); do
if ! ps -p "$pid" > /dev/null 2>&1; then
info "$APP_NAME 已优雅停止"
rm -f "$PID_FILE"
return 0
fi
sleep 1
done
# 超时了还没停,强制杀掉
warn "优雅关闭超时,强制终止 ..."
kill -9 "$pid"
rm -f "$PID_FILE"
info "$APP_NAME 已强制停止"
}
# 启动服务
do_start() {
if is_running; then
warn "$APP_NAME 已在运行 (PID: $(get_pid)),将重启 ..."
do_stop
sleep 2
fi
if [ ! -f "$JAR_PATH" ]; then
error "找不到 JAR 文件: $JAR_PATH"
exit 1
fi
mkdir -p "$LOG_DIR" "$APP_DIR/tmp"
info "正在启动 $APP_NAME ..."
info " 环境 : $ACTIVE_PROFILE"
info " JAR : $JAR_PATH"
info " 配置 : $CONFIG_DIR/"
nohup java $JVM_OPTS \
-jar "$JAR_PATH" \
--spring.profiles.active="$ACTIVE_PROFILE" \
--spring.config.location="$CONFIG_DIR/" \
>> "$LOG_DIR/console-$(date '+%Y%m%d%H%M').log" 2>&1 &
echo $! > "$PID_FILE"
sleep 5
if is_running; then
info "✅ $APP_NAME 启动成功 (PID: $(get_pid))"
else
error "❌ $APP_NAME 启动失败!请查看日志: $LOG_DIR/"
exit 1
fi
}
# 主逻辑:运行就是重启/启动
do_start
SCRIPT
# 创建备份脚本
cat > "$SVC_DIR/bin/backup.sh" << 'SCRIPT'
#!/bin/bash
#===================================================
# 服务备份脚本
# 用法: ./backup.sh
# 功能: 把当前 JAR 包复制到 backup 目录,带时间戳
#===================================================
APP_NAME="这里改成你的服务名"
JAR_NAME="这里改成你的jar包名.jar"
APP_DIR=$(cd "$(dirname "$0")/.." && pwd)
JAR_PATH="$APP_DIR/app/$JAR_NAME"
BACKUP_DIR="/opt/app/backup/$APP_NAME"
RED='\033[0;31m'; GREEN='\033[0;32m'; NC='\033[0m'
info() { echo -e "${GREEN}[INFO]${NC} $1"; }
error() { echo -e "${RED}[ERROR]${NC} $1"; }
if [ ! -f "$JAR_PATH" ]; then
error "找不到 JAR 文件: $JAR_PATH"
exit 1
fi
mkdir -p "$BACKUP_DIR"
# 备份文件名加上时间戳,方便识别
BACKUP_NAME="${JAR_NAME}.bak_$(date '+%Y%m%d%H%M%S')"
cp "$JAR_PATH" "$BACKUP_DIR/$BACKUP_NAME"
info "✅ 备份完成: $BACKUP_DIR/$BACKUP_NAME"
# 只保留最近 5 个备份,旧的自动清理
ls -t "$BACKUP_DIR"/*.bak_* 2>/dev/null | tail -n +6 | xargs -r rm -f
info "已清理旧备份(保留最近 5 个)"
SCRIPT
# 设置执行权限
chmod +x "$SVC_DIR/bin/restart.sh"
chmod +x "$SVC_DIR/bin/backup.sh"
echo ""
echo "✅ 目录结构初始化完成!"
echo ""
echo "📁 $SVC_DIR/"
echo " ├── app/ ← 把 JAR 包放这里"
echo " ├── config/ ← 把 application-prod.yml 放这里"
echo " ├── logs/ ← 日志会自动写到这里"
echo " ├── tmp/ ← PID 文件自动管理"
echo " └── bin/"
echo " ├── restart.sh ← 启动/重启脚本"
echo " └── backup.sh ← 备份脚本"
echo ""
echo "⚡ 下一步:"
echo " 1. 把 JAR 包上传到 $SVC_DIR/app/"
echo " 2. 把配置文件放到 $SVC_DIR/config/"
echo " 3. 修改 restart.sh 和 backup.sh 顶部的 APP_NAME 和 JAR_NAME"
echo " 4. 运行 $SVC_DIR/bin/restart.sh 启动服务"使用方式非常简单:
bash
# 初始化一个新服务的目录结构
./init-structure.sh user-service
# 再初始化另一个服务
./init-structure.sh api-gateway核心脚本详解
初始化完成后,每个服务的 bin/ 目录下会有两个脚本。这两个脚本就是日常运维的全部武器,不需要记复杂的命令,会这两个就够了。
脚本一:restart.sh ------ 启动/重启服务
这是最核心的脚本,日常 90% 的操作都用它。它的工作逻辑很简单:服务没启动就启动,已经在跑就先停再启。你不需要关心服务当前是什么状态,运行就完了。
几个你可能好奇的设计细节,用大白话解释一下:
为什么要 PID 文件? PID 文件就是记录"当前运行的进程号"的小文件,放在 tmp/app.pid 里。脚本靠它判断服务是否在运行------有 PID 文件且对应进程还活着,说明服务在跑;没有 PID 文件或进程已经死了,说明服务停了。这比每次都 ps -ef | grep xxx 去查要快得多、准得多。
为什么先 kill -15 再 kill -9? kill -15(SIGTERM)相当于"礼貌地请应用退出",Spring Boot 收到这个信号后会执行清理工作------关闭数据库连接、保存 缓存 、写完日志------然后优雅退出。kill -9(SIGKILL)相当于"直接拔电源",进程立刻消失,什么清理都来不及做。所以我们的策略是:先礼貌请退,等 30 秒,如果还不走再强制拖走。
为什么用 nohup? nohup 的意思是"不要因为终端关闭就停掉程序"。如果没有 nohup,你 SSH 登录服务器启动 Java 进程,关掉 SSH 窗口后进程就跟着死了。加了 nohup,即使你关掉终端、断开 SSH,服务依然在后台运行。
为什么 sleep 5 秒再检查? Java 应用启动需要时间------加载类、初始化 Spring 容器、连接数据库......这些不是瞬间完成的。等 5 秒再检查进程是否还活着,可以过滤掉"刚启动就崩了"的情况。如果 5 秒后进程还活着,基本可以认为启动成功了。
脚本二:backup.sh ------ 备份当前版本
更新版本之前先备份,这是运维的基本素养。万一新版本有 bug,把备份的旧 JAR 包换回来就能恢复,比重新构建快得多。
备份文件名带时间戳,这样你能清楚地知道每个备份是什么时候做的。自动保留最近 5 个备份,太老的自动清理,防止备份目录无限膨胀。
日常运维------就这两条命令
| 场景 | 命令 | 效果 |
|---|---|---|
| 首次启动服务 | ./restart.sh |
检测到没在运行,直接启动 |
| 重启服务 | ./restart.sh |
检测到在运行,先停再启 |
| 切换到开发环境 | ./restart.sh dev |
以 dev 环境启动(默认是 prod) |
| 更新版本前备份 | ./backup.sh |
当前 JAR 包安全保存到 backup 目录 |
就这些,没有复杂的参数,没有多余的子命令。
发布更新完整流程
下面这张图展示了从"开发完成"到"上线运行"的完整操作流程,每一步都配有对应的命令:
对应的命令操作:
bash
# 1. 先备份(防止翻车)
cd /opt/app/user-service/bin
./backup.sh
# 2. 上传新 JAR 包到 app 目录(从你本地电脑上传到服务器)
scp target/user-service-1.0.1.jar user@server:/opt/app/user-service/app/user-service.jar
# 3. 运行 restart.sh,自动停旧版本、启新版本
./restart.sh
# 4. 看一眼日志,确认启动正常
tail -f ../logs/console-*.log
# 5. 万一新版本有问题,从备份恢复
cp /opt/app/backup/user-service/user-service.jar.bak_20260616103000 \
/opt/app/user-service/app/user-service.jar
./restart.sh外部配置文件说明
你可能注意到,启动命令里有一行 --spring.config.location=../config/。这是什么意思?
Spring Boot 项目打包时,配置文件(application.yml)会被打进 JAR 包里。但生产环境的数据库地址、密码跟开发环境肯定不一样,你不可能为每台服务器单独打一个 JAR 包。--spring.config.location 就是告诉 Spring Boot:"别用 JAR 包里面的配置了,用我指定目录下的配置文件。" 这样 JAR 包只打一次,不同服务器放不同的 application-prod.yml 就行。
bash
# /opt/app/user-service/config/application-prod.yml
server:
port: 8081
spring:
datasource:
url: jdbc:mysql://10.0.0.100:3306/user_db?useSSL=true
username: ${DB_USER} # 也可通过环境变量注入,避免密码明文写在文件里
password: ${DB_PASSWORD}
hikari:
maximum-pool-size: 20
logging:
file:
name: logs/application.log
logback:
rollingpolicy:
max-file-size: 50MB
max-history: 30这种方式的好处用三句话总结:
- 改配置不需要重新打包 --- 直接编辑 yml 文件,运行
./restart.sh就生效 - 不同服务器可以有不同配置 --- JAR 包保持一致,配置各管各的
- 敏感信息不入代码仓库 --- 数据库密码、API 密钥只存在于服务器上,不会泄露到 Git
2.3 方式二:systemd 服务管理(适合需要开机自启的场景)
如果你的服务需要开机自启或与系统服务统一管理,可以将脚本注册为 systemd 服务:
bash
# /etc/systemd/system/user-service.service
[Unit]
Description=User Service (Spring Boot)
After=network.target
[Service]
Type=forking
User=deploy
WorkingDirectory=/opt/app/user-service
ExecStart=/opt/app/user-service/bin/app.sh start
ExecStop=/opt/app/user-service/bin/app.sh stop
ExecReload=/opt/app/user-service/bin/app.sh restart
PIDFile=/opt/app/user-service/tmp/app.pid
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target
bash
# 注册并启动
sudo systemctl daemon-reload
sudo systemctl start user-service
sudo systemctl enable user-service # 开机自启
# 查看状态和日志
sudo systemctl status user-service
sudo journalctl -u user-service -f提示 :使用
Type=forking配合脚本中的后台启动(nohup &),systemd 能通过 PIDFile 正确追踪进程状态。
2.4 方式三:Docker 容器化部署
什么是 Docker?为什么要用 Docker?
先说一个很多人都会遇到的痛点:"在我电脑上明明能跑啊!"------你本地开发得好好的,一部署到服务器就各种报错,JDK 版本不对、系统依赖缺失、文件路径写死......这些问题说到底都是"环境不一致"造成的。
Docker 就是来解决这个问题的。它的核心思路很简单:把你的应用和它需要的所有依赖(JDK、系统库、配置文件)一起打包成一个"镜像",这个 镜像 就像一个密封的集装箱------不管你把它搬到哪台机器上,只要装了 Docker,打开就能跑,环境一模一样,不会再有"在我电脑上能跑"的尴尬。
用大白话来打几个比方:
- 镜像(Image) = 装好软件的系统盘。比如
mysql:8.0这个镜像,就是一个已经装好了 MySQL 8.0 的"系统盘",你拿过来直接用就行,不用自己安装配置。 - 容器(Container) = 用系统盘装好的、正在运行的电脑。一个镜像可以"装"出多个容器,就像一张系统盘可以装多台电脑。
- Dockerfile = 安装说明书。告诉 Docker 怎么一步步打包你的应用------先装 JDK,再复制代码,再编译打包......每一步都写清楚。
- Docker Compose = 批量启动器。你的项目通常不只是一个应用,还有数据库、缓存、Nginx......Docker Compose 让你用一个 YAML 文件定义所有服务,一条命令全部拉起来。
Docker vs 传统部署的直观对比:传统部署就像自己买砖、买水泥、雇工人盖房子,每换一块地就得重新来;Docker 部署就像买了一个移动板房,里面水电齐全,搬到哪里都能直接住。
本节将分两部分讲解:第一部分是测试环境单节点部署 (入门友好,快速上手),第二部分是生产级多节点集群部署(正式上线用,高可用保障)。
第一部分:测试环境单节点部署
什么是单节点部署?
单节点部署就是把所有服务------应用、数据库、缓存、Nginx------都装在同一台服务器上,各自跑在独立的 Docker 容器里。就像把厨房、卧室、客厅都放在一个房间,虽然挤了点,但一个人住完全够用。
适合场景:自己开发测试、功能验证、给客户做演示。
不适合场景:正式对外提供服务。因为一旦这台机器宕机(断电、硬件故障、网络中断),所有服务全挂,用户完全无法访问。生产环境必须用多节点,后面会讲。
部署架构
下面这张图展示了单节点部署时,各容器之间的关系和调用链路。用户的请求先到 Nginx(门面),Nginx 根据请求路径把请求转发给对应的应用容器,应用容器再去连接数据库和缓存。
数据流解读:用户访问网站 → 请求先到 Nginx(统一入口)→ Nginx 把 API 请求转发给 Spring Boot 容器 → Spring Boot 从 Redis 读缓存,缓存没有就去 MySQL 查 → 查到后返回给用户,同时写入 Redis 缓存。
前置准备
在开始部署之前,需要先在服务器上安装 Docker 和 Docker Compose。就像做饭之前要先把灶台和锅碗瓢盆准备好一样,这些是后续所有操作的基础。
| 步骤 | 命令 | 大白话解释 |
|---|---|---|
| 安装 Docker | `curl -fsSL get.docker.com | bash` |
| 安装 Docker Compose | sudo yum install docker-compose -y |
Docker Compose 是 Docker 的"批量管家",让你用一个配置文件同时管理多个容器。没有它你就得一个一个手动启动 |
| 验证安装 | docker --version |
看一眼版本号,确认安装成功了。如果报 command not found,说明没装上,回头检查 |
| 启动 Docker 服务 | sudo systemctl start docker |
Docker 装好了但还没运行,这条命令相当于"开灶" |
| 设置开机自启 | sudo systemctl enable docker |
服务器重启后 Docker 自动启动,不用你每次手动开。生产环境必须设置,不然机器重启后服务就断了 |
Docker Compose 配置文件详解
这是整个部署的核心------docker-compose.yml。它就像一张"施工图纸",告诉 Docker 要启动哪些服务、每个服务怎么配置、服务之间怎么关联。下面逐段讲解,每一行都配上大白话解释。
bash
# version 表示 Compose 文件格式的版本号
# 不同版本支持的功能不同,3.8 是目前最常用的稳定版本
version: '3.8'
# services 下面定义所有需要运行的容器
# 每一个 service 就是一个独立的容器,可以理解为"一台虚拟小电脑"
services:
# ---- MySQL 数据库服务 ----
# 数据库是整个应用的数据仓库,所有业务数据都存在这里
mysql:
# image 指定使用哪个"系统盘"来创建容器
# mysql:8.0 就是一个已经装好 MySQL 8.0 的系统盘,拿来即用
image: mysql:8.0
# container_name 给容器起个名字,方便后续管理
# 不指定的话 Docker 会自动生成一个随机名字(如 mystifying_tesla),不好记
container_name: test-mysql
# restart: always ------ 容器挂了自动重启
# 比如数据库进程崩了,Docker 会自动把它拉起来,不用你半夜爬起来手动重启
restart: always
# environment 设置容器内部的环境变量
# 这些变量在 MySQL 首次启动时生效,帮你自动完成初始化配置
environment:
MYSQL_ROOT_PASSWORD: root123456 # root 超级用户的密码,权力最大
MYSQL_DATABASE: myapp # 首次启动自动创建这个数据库,省得你手动建
MYSQL_USER: appuser # 创建一个普通用户,日常操作用这个,不用 root
MYSQL_PASSWORD: apppass123 # 普通用户的密码
# ports 端口映射:把容器内部的端口"暴露"到宿主机
# 格式是 "宿主机端口:容器端口"
# "3306:3306" 意思是:访问服务器的 3306 端口,就等于访问容器内的 3306 端口
ports:
- "3306:3306"
# volumes 目录挂载:把宿主机的目录"绑定"到容器内部
# 这是数据持久化的关键------默认情况下,容器删除后内部数据就没了
# 挂载后,数据实际存在宿主机上,容器删了重建,数据还在
volumes:
# 数据库文件存到宿主机 ./data/mysql 目录
# 容器内 /var/lib/mysql 是 MySQL 存数据的地方,映射出来就不怕丢了
- ./data/mysql:/var/lib/mysql
# 把初始化 SQL 脚本挂载进去
# MySQL 首次启动时会自动执行这个目录下的 .sql 文件,帮你建表、灌初始数据
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
# ---- Redis 缓存服务 ----
# Redis 是内存数据库,用来缓存热点数据,减轻数据库压力
# 就像你把常用文件放在桌面,不用每次都去文件柜翻
redis:
image: redis:7-alpine # alpine 版本基于 Alpine Linux,体积只有正常版的 1/5
container_name: test-redis
restart: always
ports:
- "6379:6379"
# command 覆盖容器默认的启动命令
# 默认 Redis 启动是不设密码的,这里加上密码防止被人白嫖
command: redis-server --requirepass redis123
volumes:
- ./data/redis:/data # 把 Redis 的持久化文件也挂出来,防止丢失
# ---- 应用服务(Spring Boot 后端)----
# 这是你的核心业务应用,处理用户的请求、执行业务逻辑
app:
# build 表示不从仓库拉镜像,而是根据 Dockerfile 自己构建
# 就像不买现成的家具,而是按图纸自己打
build:
context: . # Dockerfile 在当前目录下
dockerfile: Dockerfile # 指定 Dockerfile 文件名
container_name: test-app
restart: always
ports:
- "8080:8080"
# depends_on 定义启动顺序
# 意思是:先启动 mysql 和 redis,再启动 app
# 不然应用启动时连不上数据库就报错了
# 注意:depends_on 只保证启动顺序,不保证 mysql 已经"准备好接受连接"
# 如果应用启动太快连不上数据库,可以在应用里加重试逻辑
depends_on:
- mysql
- redis
# environment 注入环境变量
# 这些变量会覆盖 Spring Boot 配置文件中的对应项
# 好处:不用改代码和配置文件,只需改环境变量就能切换数据库连接等配置
environment:
SPRING_DATASOURCE_URL: jdbc:mysql://mysql:3306/myapp?useSSL=false&serverTimezone=Asia/Shanghai
# 注意这里的 host 写的是 "mysql" 而不是 IP
# 因为 Docker Compose 会自动创建一个内部网络,服务名就是域名
# 应用容器访问 "mysql:3306" 就能连到 MySQL 容器,不用管 IP
SPRING_DATASOURCE_USERNAME: appuser
SPRING_DATASOURCE_PASSWORD: apppass123
SPRING_REDIS_HOST: redis # 同理,"redis" 就是 Redis 容器的域名
SPRING_REDIS_PASSWORD: redis123
# ---- Nginx 反向代理 ----
# Nginx 是整个系统的"前台门面",用户只跟它打交道
# 它负责:1. 接收用户请求 2. 转发给后端应用 3. 返回结果给用户
# 这样用户只需要访问 80 端口,不用记住后端各种端口号
nginx:
image: nginx:alpine
container_name: test-nginx
restart: always
ports:
- "80:80" # HTTP 端口,用户访问的就是这个
- "443:443" # HTTPS 端口,配置 SSL 后使用
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro # :ro = read-only 只读挂载
# Nginx 配置文件挂进来,修改后 nginx -s reload 即可生效
# :ro 防止容器内的进程意外修改配置文件
depends_on:
- app # 等应用启动后再启动 Nginx关键概念说明:
- 端口映射 (ports):容器是一个封闭的小世界,外部默认访问不到。端口映射就是在容器上"开一扇窗",让外部流量能进来。
"8080:8080"就是把容器的 8080 端口暴露到宿主机的 8080 端口。- 目录挂载(volumes):容器内部的数据默认是临时的,容器一删就没了。挂载就是把宿主机的目录"绑定"到容器内,这样数据实际存在宿主机上,容器重建后数据还在。
- 服务名即域名 :Docker Compose 自动创建内部网络,服务名就是域名。比如
mysql:3306就能访问 MySQL 容器,不用写 IP。
应用 Dockerfile 详解
Dockerfile 是打包应用的"菜谱",告诉 Docker 怎么把你的源代码变成一个可运行的镜像。这里用的是多阶段构建------先在一个"厨房"里编译代码,再把编译好的"成品菜"端到另一个干净的"盘子"里。这样做的好处是最终镜像很小,不会把编译工具链也带进去。
bash
# ============ 阶段1:构建 ============
# 这个阶段就像一个"专用厨房",里面有 Maven 和 JDK,专门用来编译代码
# 构建完成后这个"厨房"就被丢弃了,不会出现在最终镜像里
FROM maven:3.9-eclipse-temurin-17 AS builder
WORKDIR /app
# 先复制 pom.xml 并下载依赖
# 这一步单独写,是为了利用 Docker 的缓存机制:
# 只要 pom.xml 没变,下次构建就会跳过依赖下载,节省大量时间
COPY pom.xml .
RUN mvn dependency:go-offline -B # 把所有依赖下载到本地缓存
# 再复制源代码并编译
COPY src ./src
RUN mvn clean package -DskipTests -B # 打包成 JAR,跳过测试(测试在 CI 阶段已经跑过了)
# ============ 阶段2:运行 ============
# 这是最终镜像,只包含运行应用所需的最小环境
# 用 JRE 而不是 JDK,因为运行时不需要编译器,体积小很多
FROM eclipse-temurin:17-jre-alpine
WORKDIR /app
# 安全最佳实践:在容器内创建一个普通用户来运行应用
# 默认容器以 root 用户运行,一旦被攻破,攻击者就拥有了 root 权限
# 用普通用户运行,即使被攻破,危害也有限
RUN addgroup -S appgroup && adduser -S appuser -G appgroup
USER appuser
# 从 builder 阶段把编译好的 JAR 包复制过来
# --from=builder 表示从名为 builder 的阶段复制
COPY --from=builder /app/target/*.jar app.jar
# 健康检查:Docker 每 30 秒访问一次 /actuator/health 端点
# 连续 3 次失败就认为容器不健康,触发重启策略
# 就像定时给容器"量体温",发烧了就送医院
HEALTHCHECK --interval=30s --timeout=3s --retries=3 \
CMD wget -qO- http://localhost:8080/actuator/health || exit 1
# EXPOSE 声明容器对外提供服务的端口
# 这只是一个"文档说明",并不会实际发布端口,真正的端口映射在 docker-compose.yml 中
EXPOSE 8080
# ENTRYPOINT 容器启动时执行的命令
# 这里启动 Java 应用,配置了基本 JVM 参数
ENTRYPOINT ["java", \
"-Xms512m", "-Xmx1024m", \ # 初始/最大堆内存
"-Djava.security.egd=file:/dev/./urandom", \ # 加速 SecureRandom 初始化
"-jar", "app.jar"]启动与运维
万事俱备,只欠东风。配置文件写好后,按照下面的流程图操作即可:
| 命令 | 大白话解释 |
|---|---|
docker-compose up -d |
"一键开火"------根据配置文件启动所有容器。-d 是后台运行的意思,不加的话当前终端会被占满,关掉终端服务就停了 |
docker-compose ps |
"点名"------看看哪些容器在跑、哪些挂了,以及各自的端口映射 |
docker-compose logs -f 服务名 |
"监听"------实时查看某个服务的日志输出,-f 表示持续跟踪(跟 tail -f 一个意思),按 Ctrl+C 退出 |
docker-compose restart 服务名 |
"重启"------某个服务改了配置文件后,重启让新配置生效 |
docker-compose down |
"收工"------停掉并删除所有容器和网络。注意:数据卷(volumes 挂载的目录)不会删,数据库数据还在 |
docker-compose down -v |
"连根拔起"------连数据卷一起删!数据库数据永久丢失,慎用! |
docker exec -it test-mysql bash |
"进入容器内部"------像远程登录一样进入 MySQL 容器的命令行,可以直接执行 SQL |
第二部分:生产级多节点集群部署
为什么需要多节点?
单节点部署有一个致命问题:单点故障。那台机器一旦宕机------不管是断电、硬盘坏了、还是网络中断------你的整个系统就瘫痪了。用户访问不了,订单下不了,数据查不到,损失可能按分钟计算。
生产环境必须做到高可用:多台机器协同工作,任何一台挂了,其他机器自动接管,用户完全感知不到。这就好比你开了一家店,只有一个收银员,他请假了店就得关门;但如果你有三个收银员,谁请假都不影响营业。
多节点集群要解决的问题有三个:
- 应用层高可用:部署多个应用实例,一个挂了其他还在
- 数据库高可用:主库挂了,从库自动升级为主库,数据不丢
- 入口层高可用:负载均衡器也要做双机热备,不能它自己成了单点
多节点集群架构
下面这张图展示了生产环境的完整集群架构。从上往下看:用户请求先到负载均衡层,再分发到应用集群,应用集群再去访问缓存和数据库。每一层都做了高可用设计,不存在单点故障。
集群组件职责说明(大白话版)
| 组件 | 官方说法 | 大白话理解 |
|---|---|---|
| Docker Swarm | 容器集群编排工具 | 工地的总调度:决定哪个工人(节点)干什么活,有人请假自动找人顶上 |
| Keepalived + VIP | 负载均衡高可用方案 | 公司的总机号码:对外只有一个号码(VIP),背后两台机器一主一备。主机正常时它接电话,主机挂了备机无缝接替,客户完全不知道换人了 |
| Nginx 集群 | 七层反向代理与负载均衡 | 前台接待员:把来访的客户请求均匀分配给后台的工作人员(应用实例),谁闲就分给谁 |
| Redis 主从 + Sentinel | 缓存高可用与自动故障转移 | 记性好的团队:主节点负责记东西(读写),从节点抄一份备份。Sentinel 是"监工",盯梢主节点,一发现它倒下了立马提拔一个从节点上位 |
| MySQL 主从复制 | 数据库高可用与读写分离 | 档案室:主库存原件(写),从库存复印件(只读)。写操作只找主库,读操作分摊给从库,既安全又快 |
| Prometheus + Grafana | 指标采集、可视化与告警 | 体检中心:Prometheus 定时给每台机器量体温、测血压(采集指标),Grafana 把数据画成图表,体温超标自动发短信告警 |
第一步:初始化 Docker Swarm 集群
Docker Swarm 是 Docker 自带的集群管理工具,装了 Docker 就自带,不用额外安装。它的工作方式很简单:选一台机器当"管理者"(Manager),其他机器当"打工人"(Worker),管理者负责分配任务,打工人负责执行。
下面的时序图展示了从零搭建集群的完整过程:
命令详解(每条都讲清楚执行时机和效果):
| 命令 | 在哪台机器执行 | 大白话解释 |
|---|---|---|
docker swarm init --advertise-addr 192.168.1.10 |
Manager 节点 | "我来当老大"------初始化集群。--advertise-addr 告诉其他节点"来找我报到"。执行后会输出一个 docker swarm join 命令,里面带着 Token,复制下来给其他机器用 |
docker swarm join --token SWMTKN-xxx 192.168.1.10:2377 |
Worker 节点 | "我来打工"------拿着通行证加入集群。2377 是 Swarm 管理通信的端口,Token 是安全凭证,防止随便什么机器都来加入 |
docker node ls |
Manager 节点 | "点名"------查看所有节点的状态。能看到每个节点是 Manager 还是 Worker、是正常(Ready)还是掉线(Down) |
docker node promote 节点名 |
Manager 节点 | "提拔"------把 Worker 提升为 Manager,增加管理节点的冗余度。推荐至少 3 个 Manager 节点 |
docker node update --availability drain 节点名 |
Manager 节点 | "休假"------把节点标记为"排空"模式,上面的容器会自动迁移到其他节点。常用于给机器做维护升级 |
第二步:部署服务栈
集群搭好了,接下来要把应用部署上去。这里用 Docker Compose 文件配合 Swarm 的 deploy 配置来实现多节点编排。和单节点的 docker-compose.yml 相比,最大的区别是多了 deploy 块------它告诉 Swarm 怎么在多台机器上分配容器。
bash
version: '3.8'
services:
app:
image: registry.example.com/myapp:latest # 从私有镜像仓库拉取镜像
# deploy 块是 Swarm 模式专用配置
# 在普通 docker-compose up 中不生效,必须用 docker stack deploy 部署
deploy:
# replicas 副本数量:同时运行几个应用实例
# 3 个副本分布在 3 台机器上,任何一台挂了,另外两台还能继续服务
replicas: 3
# update_config 滚动更新策略:怎么安全地更新到新版本
update_config:
parallelism: 1 # 每次只更新 1 个副本,不会一口气全换
delay: 10s # 更新一个后等 10 秒,确认没问题再更新下一个
failure_action: rollback # 如果更新失败(新版本起不来),自动回滚到旧版本
# restart_policy 重启策略:容器挂了怎么处理
restart_policy:
condition: on-failure # 只有异常退出才重启(正常退出不重启)
max_attempts: 3 # 最多重试 3 次,避免无限重启(可能代码本身有问题)
# placement 部署约束:容器应该放在哪种节点上
placement:
constraints:
- node.role == worker # 应用容器只部署在 Worker 节点上
# Manager 节点专注于管理工作,不跑业务,避免影响集群稳定性
environment:
SPRING_PROFILES_ACTIVE: prod
networks:
- app-network
nginx:
image: nginx:alpine
deploy:
replicas: 2 # 2 个 Nginx 实例,互为备份
placement:
constraints:
- node.role == manager # Nginx 部署在 Manager 节点,作为统一入口
ports:
- "80:80"
- "443:443"
configs:
- source: nginx_config
target: /etc/nginx/nginx.conf
# configs 是 Swarm 专用的配置管理方式
# 比 volumes 更适合存储配置文件:可以版本化、可以滚动更新
configs:
nginx_config:
file: ./nginx-prod.conf
# overlay 网络:允许不同机器上的容器互相通信
# 就像给分布在各楼层的员工配了对讲机,不用走公网
networks:
app-network:
driver: overlay第三步:服务部署与运维命令
| 命令 | 大白话解释 |
|---|---|
docker stack deploy -c docker-compose.yml myapp |
"全员上阵"------把配置文件中定义的所有服务部署到集群上。Swarm 会自动把容器分配到各个节点。myapp 是这个技术栈的名字,后续操作都靠它 |
docker stack ls |
"看看部署了什么"------列出集群中所有的技术栈 |
docker stack services myapp |
"看看各服务状态"------显示每个服务需要几个副本、当前跑了几个。如果 REPLICAS 显示 3/3 说明全在跑,2/3 说明有一个挂了 |
docker stack ps myapp |
"细看每个副本"------显示每个副本具体跑在哪台机器上、运行了多久、是否正常 |
docker service logs -f myapp_app |
"看聚合日志"------把分布在多台机器上的应用日志汇总显示,不用一台一台登录看 |
docker service scale myapp_app=5 |
"紧急加人"------把应用副本从 3 个扩到 5 个,应对流量突增。Swarm 自动在可用节点上启动新容器 |
docker service update --image registry.example.com/myapp:v2.0 myapp_app |
"升级装备"------把应用镜像更新到 v2.0 版本。Swarm 会按 update_config 中的策略逐个替换,保证服务不中断 |
docker stack rm myapp |
"收队"------移除整个技术栈,所有容器停止并删除 |
第四步:多节点日常运维
集群部署不是一锤子买卖,日常巡检和及时处理问题同样重要。下面这张图展示了一个典型的日常运维流程:
关键概念深入讲解:
节点故障自动恢复:当某个 Worker 节点宕机,Swarm 不需要你做任何事------它会自动发现该节点失联,然后在该节点上运行的容器迁移到其他健康节点。整个过程通常在几十秒内完成。这得益于 Swarm 的"期望状态协调"机制:你声明"我要 3 个应用副本",Swarm 会持续监控,发现只有 2 个在跑,就自动补上 1 个。就像你跟管家说"家里要常备 3 瓶牛奶",管家发现只剩 2 瓶了就自动去超市补货。
滚动更新的原理:更新时绝对不能把旧版本全停了再启动新版本(那叫"停机更新",用户会看到 502 错误)。滚动更新是逐个替换:先启动 1 个新版本容器 → 等健康检查通过 → 停掉 1 个旧版本容器 → 再启动第 2 个新版本容器......如此循环,直到全部替换完毕。用户在这个过程中完全感知不到服务中断。
日志聚合 :在多节点集群中,同一个服务的 3 个副本可能分布在 3 台不同的机器上。docker service logs 会自动把所有副本的日志汇总到一起显示,不用你逐台 SSH 登录去看。
监控告警:推荐用 Prometheus 定时采集各节点的 CPU、内存、磁盘、网络指标,Grafana 以漂亮的图表展示。当某个指标超过阈值(比如内存使用率超过 90%),Alertmanager 会自动通过钉钉、邮件或短信发送告警。运维人员不需要一直盯着屏幕,有问题系统会主动通知你。
测试环境 vs 生产环境对比总结
| 维度 | 测试环境单节点 | 生产环境多节点集群 |
|---|---|---|
| 服务器数量 | 1 台 | 至少 3 台(推荐 5 台以上) |
| 容器编排 | Docker Compose | Docker Swarm |
| 高可用 | 无,单点故障 | 多副本自动故障转移 |
| 数据持久化 | 本地目录挂载 | NFS/分布式存储 |
| 负载均衡 | 无或单 Nginx | Nginx + Keepalived 双活 |
| 数据库 | 单实例 | 主从复制 + 读写分离 |
| 缓存 | 单 Redis | Redis 主从 + Sentinel |
| 监控告警 | 手动查看日志 | Prometheus + Grafana 自动告警 |
| 日志管理 | docker logs | ELK/Loki 集中日志平台 |
| 适用场景 | 开发调试、功能验证 | 正式对外提供服务 |
选型建议:如果你的项目是内部系统、用户量不大,单节点就够用了,别过度设计。等流量上来了、业务重要了,再升级到多节点也不迟。架构是演出来的,不是一步到位的。
2.5 JVM 调优参考
| 参数 | 说明 | 推荐值 |
|---|---|---|
-Xms |
初始堆内存 | 物理内存的 1/4 |
-Xmx |
最大堆内存 | 物理内存的 1/2,不超过 4G |
-XX:+UseG1GC |
使用 G1 垃圾回收器 | JDK 9+ 默认,低延迟场景推荐 |
-XX:MaxRAMPercentage=75.0 |
容器内按比例分配堆内存 | Docker 环境推荐 |
-XX:+HeapDumpOnOutOfMemoryError |
OOM 时自动 dump 堆 | 生产必开,排查内存问题 |
-XX:HeapDumpPath |
dump 文件路径 | 指向 logs 目录 |
bash
# 脚本部署中的推荐 JVM 参数(已在 app.sh 中配置)
JVM_OPTS="-Xms512m -Xmx1024m"
JVM_OPTS="$JVM_OPTS -XX:+UseG1GC"
JVM_OPTS="$JVM_OPTS -XX:+HeapDumpOnOutOfMemoryError"
JVM_OPTS="$JVM_OPTS -XX:HeapDumpPath=$LOG_DIR/heapdump.hprof"
bash
# Docker 环境下的推荐启动参数
java -XX:MaxRAMPercentage=75.0 \
-XX:+UseG1GC \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/app/logs/heapdump.hprof \
-jar app.jar三、Python(FastAPI / Flask)项目部署
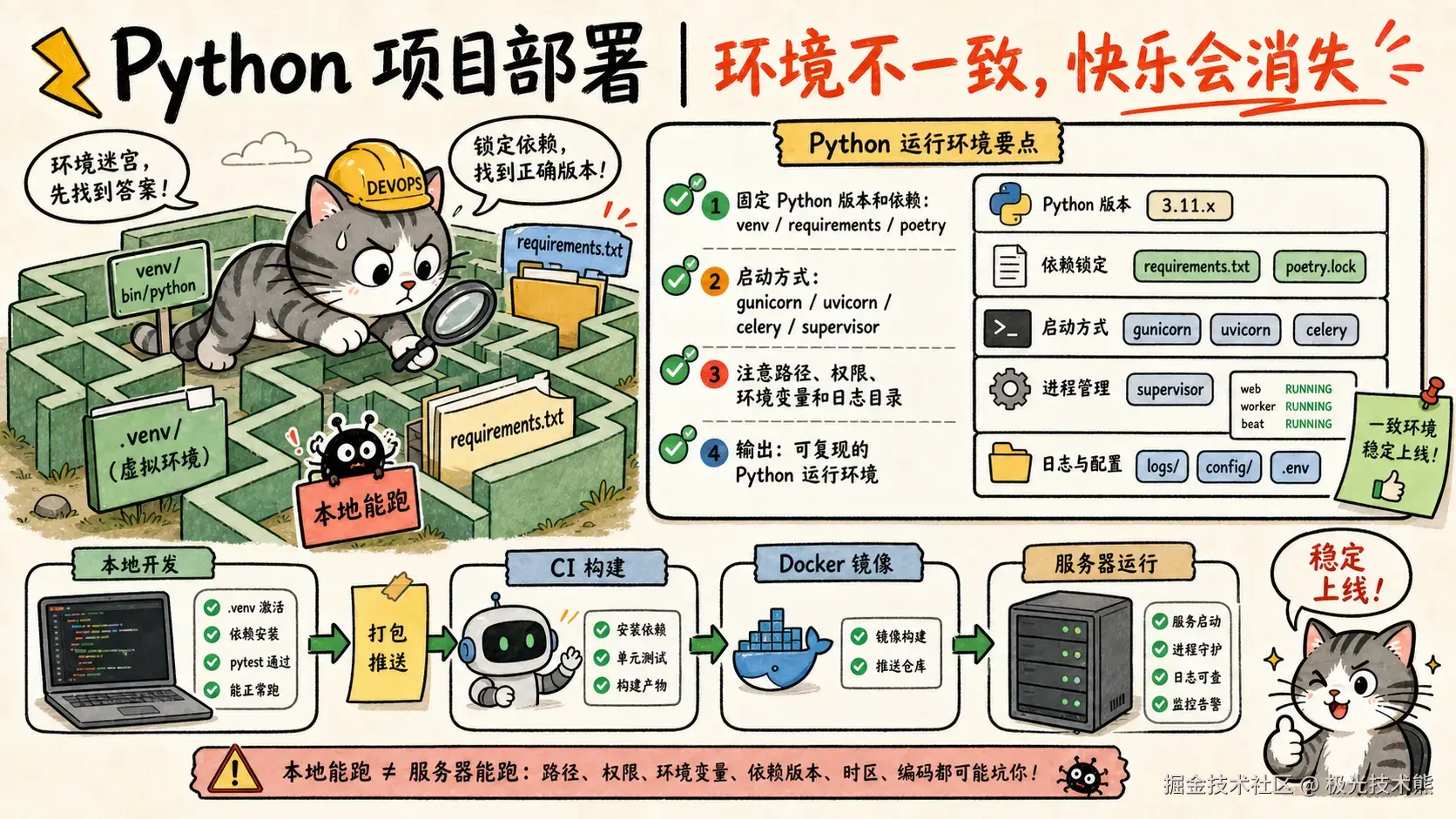
先说大白话:Python 项目部署和 Java 有什么不同?
很多学 Java 出身的同学第一次部署 Python 项目会懵:"Python 没有 main 方法、没有内置 Web 服务器,我到底在跑什么?"
先把这个困惑讲清楚 ------ Java Spring Boot 自带 Tomcat ,打个 JAR 包直接 java -jar 就能跑;但 Python 不是这样,它是解释型语言,没有"自带服务器"这个概念。要跑一个 HTTP API 服务,你需要自己搭一个 Web 服务器来"托管"你的 Python 代码。
这就引出了一整套工具和概念,我们用一张图来讲清楚:
各层解释:
| 层级 | 是什么 | 大白话理解 | 为什么需要 |
|---|---|---|---|
| Nginx | HTTP 反向代理服务器 | "前台接待员"------负责接客、分发请求、返回结果 | 直接把 Python 服务暴露到公网不安全,Nginx 做了一层缓冲和统一入口 |
| Gunicorn | WSGI HTTP 服务器 | "包工头"------负责启动和管理多个 Python 工作进程(Worker) | Python 代码自己跑不稳,需要个"包工头"来管理进程,挂了自动重启 |
| Uvicorn | ASGI 服务器(FastAPI 专用) | "技术工"------真正执行你的 async/await 代码的服务器 | FastAPI 基于 async/await,必须用支持 ASGI 的服务器才能发挥性能 |
| FastAPI/Flask | 你的业务代码 | "干活的程序员"------写接口、写业务逻辑的地方 | 这是你真正要部署的东西 |
一句话总结:部署 Python 项目 = 让你的代码跑在一个"包工头(Gunicorn)"管理下的"技术工(Uvicorn/Flask)"进程里,前面再挡一个"前台(Nginx)"。
3.1 项目结构示例
一个标准的 Python API 项目长这样,每个目录和文件都有明确分工:
bash
my-python-api/
├── app/
│ ├── __init__.py # 包初始化文件(Python 包必须有这个)
│ ├── main.py # 应用入口:FastAPI() 或 Flask() 实例创建的地方
│ ├── routers/ # 路由模块(接口定义放这里)
│ │ └── user.py
│ ├── models/ # 数据模型(Pydantic / SQLAlchemy 模型)
│ │ └── user.py
│ └── dependencies.py # 依赖注入(认证、数据库会话等)
├── requirements.txt # 依赖清单(pip install -r 安装的包列表)
├── gunicorn.conf.py # Gunicorn 配置文件(Worker 数、超时等)
├── Dockerfile # Docker 构建文件
└── .env # 环境变量(数据库密码、API Key 等,不要提交到 Git!)为什么要这样组织?
app/是一个 Python 包,所有业务代码都在里面requirements.txt是 Python 项目的"购物清单"------列出所有需要安装的第三方库(类似 Java 的pom.xml)gunicorn.conf.py控制 Gunicorn 怎么跑你的应用:几个进程、超时多久、日志在哪.env存敏感信息,通过python-dotenv库加载,切记加入.gitignore,不要提交到代码仓库
3.2 方式一:虚拟环境直接部署
"虚拟环境"是 Python 的生态特色------它解决了"全局 Python 被不同项目互相污染"的问题。比如项目 A 需要 requests==2.28,项目 B 需要 requests==2.31,装在一起会冲突。虚拟环境就是给每个项目建一个独立的 Python 小房间,互不干扰。
部署步骤详解
跟着下面这张流程图操作,每一步都有大白话解释:
第一步:上传代码到服务器
bash
# 方式 A:从 Git 仓库拉取(推荐,版本可控)
git clone https://github.com/yourname/my-python-api.git /opt/myapi
cd /opt/myapi
git checkout prod # 切换到生产分支
# 方式 B:用 scp 从本地上传(适合没用 Git 的项目)
# 在本地机器执行:
scp -r ./my-python-api user@your-server:/opt/myapi第二步:创建虚拟环境
bash
cd /opt/myapi
# venv 是 Python 内置的虚拟环境工具,会在当前目录创建一个 venv/ 文件夹
# 里面是一个独立的 Python 解释器 + pip,跟系统 Python 完全隔离
python3 -m venv venv
# 验证:激活后命令行提示符前面会出现 (venv) 字样
source venv/bin/activate
which python # 应该显示 /opt/myapi/venv/bin/python(不是 /usr/bin/python)大白话 :
venv就像给这个项目单独配了一台"虚拟机",里面的 Python 是独立的,跟系统 Python 各装各的包,互不干扰。
第三步:安装依赖
bash
# 激活虚拟环境后,pip 会自动把包装到 venv/ 里(不是装到系统)
source venv/bin/activate
pip install -r requirements.txt
# 安装完成后,确认关键包都在
pip list | grep -E "fastapi|flask|gunicorn|uvicorn"注意 :FastAPI 生产环境需要额外装
gunicorn和uvicorn[standard]
bashpip install gunicorn "uvicorn[standard]"
第四步:先测试启动,确认能跑起来
bash
# ---------- FastAPI 项目 ----------
# uvicorn 是 FastAPI 的开发服务器,先用它测一下能不能跑
# --reload 表示代码改了自动重启(仅开发用,生产不要用!)
uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# 如果看到 "Uvicorn running on http://0.0.0.0:8000" 说明成功了
# 按 Ctrl+C 停掉,准备用 Gunicorn 正式跑
# ---------- Flask 项目 ----------
# Flask 内置的开发服务器(app.run)不能用于生产!只用来测试
flask --app app.main run --host 0.0.0.0 --port 8000为什么开发服务器不能用于生产? 因为
uvicorn --reload或flask run是单线程、单进程的,只能同时处理一个请求,并发能力几乎为零,而且没有进程守护,挂了就是真挂了。
第五步:用 Gunicorn 正式启动(生产方式)
现在要用 Gunicorn("包工头")来管理你的应用进程了:
bash
# ========== FastAPI 项目 ==========
gunicorn app.main:app \
-w 4 \ # 启动 4 个 Worker 进程(具体几个看下面说明)
-k uvicorn.workers.UvicornWorker \ # Worker 类型:FastAPI 必须用 UvicornWorker
--bind 0.0.0.0:8000 \ # 监听所有网卡的 8000 端口
--timeout 120 \ # Worker 处理请求超过 120 秒就被强制杀掉重启
--access-logfile - \ # 访问日志输出到 stdout(Docker 场景推荐)
--error-logfile - # 错误日志输出到 stdout
# ========== Flask 项目 ==========
gunicorn app.main:app \
-w 4 \ # 4 个 Worker 进程
-k gthread \ # Worker 类型:Flask 推荐用线程模式
--bind 0.0.0.0:8000 \
--timeout 120-w 4 是什么意思?Worker 数量怎么定?
这是最容易困惑的地方,用大白话讲:gunicorn 启动后是这样的:
bash
Gunicorn(主进程,包工头)
├── Worker 1(干活的程序员)
├── Worker 2(干活的程序员)
├── Worker 3(干活的程序员)
└── Worker 4(干活的程序员)每个 Worker 是一个独立的 Python 进程,能同时处理请求。Worker 越多 = 并发能力越强,但也不是越多越好(内存有限)。
推荐公式 :Worker 数 = (2 × CPU核心数) + 1
比如你的服务器是 2 核 CPU,就设 2 × 2 + 1 = 5 个 Worker。4 核就设 9 个。
Gunicorn 配置文件(推荐用文件代替命令行)
每次启动敲一大串参数太麻烦,也容易出错。推荐把配置写入 gunicorn.conf.py 文件:
bash
# gunicorn.conf.py
# Gunicorn 会自动读取当前目录下的这个文件,不需要在命令行指定 -c
import multiprocessing
import os
# ==================== 核心配置 ====================
# Worker 数量:公式 (2 × CPU核心数) + 1
# multiprocessing.cpu_count() 自动获取 CPU 核心数,不用硬编码
workers = multiprocessing.cpu_count() * 2 + 1
# 每个 Worker 的线程数(Flask 的 gthread 模式会用到,FastAPI 一般设 1)
# FastAPI 是 async 的,一个进程就能处理大量并发,不需要多线程
# Flask 是同步的,一个请求占用一个线程,所以线程数可以设大一点(如 4)
threads = 1 # FastAPI 用 1;Flask 用 4
# Worker 类型(非常重要!决定了你的应用怎么运行)
# FastAPI → 必须用 "uvicorn.workers.UvicornWorker"(支持 async/await)
# Flask → 推荐用 "gthread"(多线程模式,能更好利用 CPU)
worker_class = "uvicorn.workers.UvicornWorker" # FastAPI 用这行
# worker_class = "gthread" # Flask 用这行(取消注释,注释掉上一行)
# ==================== 网络配置 ====================
# 绑定地址:0.0.0.0 表示监听所有网卡(外网能访问)
# 127.0.0.1 表示只监听本机(外网访问不了,一般不用)
bind = "0.0.0.0:8000"
# ==================== 超时配置 ====================
# Worker 处理请求的超时时间(秒)
# 超过这个时间 Worker 还没处理完,Gunicorn 会强制 KILL 掉这个 Worker 并重启
# 设置太短:正常请求被误杀;设置太长:慢请求卡住 Worker 不释放
# 一般 API 接口 30-60 秒,有文件处理/导出的可以设 120-300 秒
timeout = 120
# 优雅重启超时(秒)
# 当你 reload Gunicorn 时,旧 Worker 有这么多秒时间处理完手上的请求再退出
# 设为 0 表示立即强制退出(可能丢请求);设为 30 表示给 30 秒优雅收尾
graceful_timeout = 30
# ==================== 内存保护 ====================
# 每个 Worker 处理满 N 个请求后,自动重启自己
# 目的:防止代码里内存泄漏累积(Python 的 GC 不是万能的)
# 比如设为 5000:每处理 5000 个请求,这个 Worker 就"自杀"重启,释放内存
max_requests = 5000
max_requests_jitter = 500 # 加一点随机抖动,避免所有 Worker 同时重启
# ==================== 日志配置 ====================
# 访问日志:记录每个请求的 URL、状态码、耗时
# "-" 表示输出到 stdout(Docker / systemd 场景推荐,日志由 Docker/systemd 统一管理)
# 也可以写成文件路径:"/var/log/myapi/access.log"
accesslog = "-"
# 错误日志:记录异常、报错信息
errorlog = "-"
# 日志级别:debug / info / warning / error / critical
# 生产环境推荐 info 或 warning;debug 会打印太多日志影响性能
loglevel = "info"
# ==================== 应用配置 ====================
# 预加载应用(True = 在 Worker fork 之前就把应用代码加载好)
# 好处:多个 Worker 共享同一份代码内存,节省内存
# 坏处:代码里的全局变量在 fork 后不共享(每个 Worker 有自己的副本)
# 一般设为 True;如果你的应用有全局状态且依赖共享内存,设为 False
preload_app = True
# 进程名称(方便用 ps 命令识别)
proc_name = "myapi-gunicorn"配置 systemd 服务(开机自启 + 崩溃重启)
直接 gunicorn ... 启动的进程,服务器重启后就停了,而且进程挂了不会自动重启。用 systemd 来管理就能解决这两个问题:
bash
# /etc/systemd/system/myapi.service
# systemd 是 Linux 的系统服务管理器,用来管理开机自启和进程守护
[Unit]
Description=My Python API Service
# After=network.target 表示:等网络服务就绪后再启动本服务(不然端口绑定会失败)
After=network.target
[Service]
Type=notify
# User / Group:用普通用户运行,不要用 root(安全!)
User=www-data
Group=www-data
# WorkingDirectory:进程的工作目录(gunicorn.conf.py 要放在这个目录下)
WorkingDirectory=/opt/myapi
# Environment:设置环境变量,重点是让 systemd 知道去哪找 venv 里的 python/gunicorn
Environment="PATH=/opt/myapi/venv/bin"
# 如果有 .env 文件,可以通过 EnvironmentFile 加载:
# EnvironmentFile=/opt/myapi/.env
# ExecStart:启动命令(不需要 -c gunicorn.conf.py,因为 Gunicorn 会自动找同目录下的)
ExecStart=/opt/myapi/venv/bin/gunicorn app.main:app
# Restart=always:进程挂了就自动重启(always = 任何原因退出都重启)
# RestartSec=5:重启前等 5 秒(避免频繁重启刷日志)
Restart=always
RestartSec=5
# 限制资源(防止内存泄漏拖垮整台服务器)
# MemoryMax=1G:这个服务最多用 1GB 内存,超了会被系统杀掉
MemoryMax=1G
[Install]
# WantedBy=multi-user.target:多用户模式下自动启动(即正常的服务器运行级别)
WantedBy=multi-user.target启用并启动服务:
bash
# 重新加载 systemd 配置(每次改了 .service 文件都要执行)
sudo systemctl daemon-reload
# 启动服务
sudo systemctl start myapi
# 设置开机自启
sudo systemctl enable myapi
# 查看状态(看是否 Active (running))
sudo systemctl status myapi
# 查看日志(代替 tail -f /var/log/xxx.log)
sudo journalctl -u myapi -f3.3 方式二:Docker 容器化部署(推荐)
如果你的团队已经用 Docker 管理 Java/前端项目,Python 项目也用 Docker 部署是最省心的------环境完全一致,不会再有"我本地能跑"的问题。
FastAPI 项目的 Dockerfile(逐行大白话注释)
bash
# ==================== 阶段 1:安装依赖("厨房"阶段)====================
# 用 python:3.12-slim 作为构建环境
# slim 版本比 full 版本体积小很多(约 50MB vs 800MB),生产推荐
FROM python:3.12-slim AS builder
# WORKDIR:设置工作目录为 /app(类似 cd /app,后面的命令都在这个目录下执行)
WORKDIR /app
# 先只复制 requirements.txt,再执行 pip install
# 目的:利用 Docker 的缓存机制
# requirements.txt 不常变,这样依赖装好后,下次构建会直接用缓存,不用重新下载
COPY requirements.txt .
# --no-cache-dir:不缓存下载的安装包(减小镜像体积)
# --prefix=/install:把包装到 /install 目录下(方便下一阶段复制)
RUN pip install --no-cache-dir --prefix=/install -r requirements.txt
# ==================== 阶段 2:运行("上菜"阶段)====================
# 这个阶段是最终镜像,只保留运行所需的最小文件
FROM python:3.12-slim
WORKDIR /app
# 安全:创建非 root 用户来运行应用
# 默认用 root 跑容器,一旦被攻破,攻击者就有 root 权限,很危险
RUN groupadd -r appgroup && useradd -r -g appgroup appuser
# 从 builder 阶段把安装好的依赖复制过来
# /install 目录下的所有文件会被复制到新镜像的 /usr/local 下
COPY --from=builder /install /usr/local
# 复制应用代码到容器
COPY . .
# 切换到普通用户(安全最佳实践)
USER appuser
# 健康检查:Docker 每隔一段时间访问一次 /health 接口
# 连续失败 3 次,Docker 就认为这个容器"不健康",触发重启策略
HEALTHCHECK --interval=30s --timeout=3s --retries=3 \
CMD python -c "import urllib.request; urllib.request.urlopen('http://localhost:8000/health')"
# 声明容器对外暴露 8000 端口(文档作用,实际映射在 docker run -p 时指定)
EXPOSE 8000
# 容器启动命令:用 Gunicorn 跑应用
# -w 4:4 个 Worker(容器内 CPU 核心数就是容器被分配的核数,可以用 os.cpu_count() 获取)
# --bind 0.0.0.0:监听所有网卡(容器内必须写 0.0.0.0,写 127.0.0.1 外网访问不了)
CMD ["gunicorn", "app.main:app", \
"-k", "uvicorn.workers.UvicornWorker", \
"-w", "4", \
"--bind", "0.0.0.0:8000", \
"--timeout", "120"]Flask 项目的 Dockerfile(只改 CMD)
Flask 项目唯一区别是 Worker 类型不同,Gunicorn 用 gthread 模式:
bash
# ... 前面的 FROM / WORKDIR / COPY 都和 FastAPI 完全一样 ...
CMD ["gunicorn", "app.main:app", \
"-w", "4", \
"--bind", "0.0.0.0:8000", \
"--timeout", "120"]
# 注意:Flask 不需要 -k 参数,默认就是 sync worker
# 如果想用多线程模式,加:-k gthread -t 4构建与运行
bash
# 构建镜像(在项目根目录执行,确保 Dockerfile 在当前目录)
docker build -t myapi:latest .
# 运行容器
docker run -d \
--name myapi \
-p 8000:8000 \
# 注入环境变量(覆盖代码中的配置,比改代码灵活)
-e DATABASE_URL=postgresql://user:pass@db:5432/mydb \
-e REDIS_URL=redis://redis:6379/0 \
-e TZ=Asia/Shanghai \
# 挂载 .env 文件(适合不方便用 -e 注入的大量环境变量)
-v /opt/myapi/.env:/app/.env:ro \
# 自动重启策略:除非手动停止,否则一直重启
--restart unless-stopped \
myapi:latest
# 查看日志
docker logs -f myapi
# 进入容器内部调试
docker exec -it myapi bash四、前端(Vue / React)项目部署
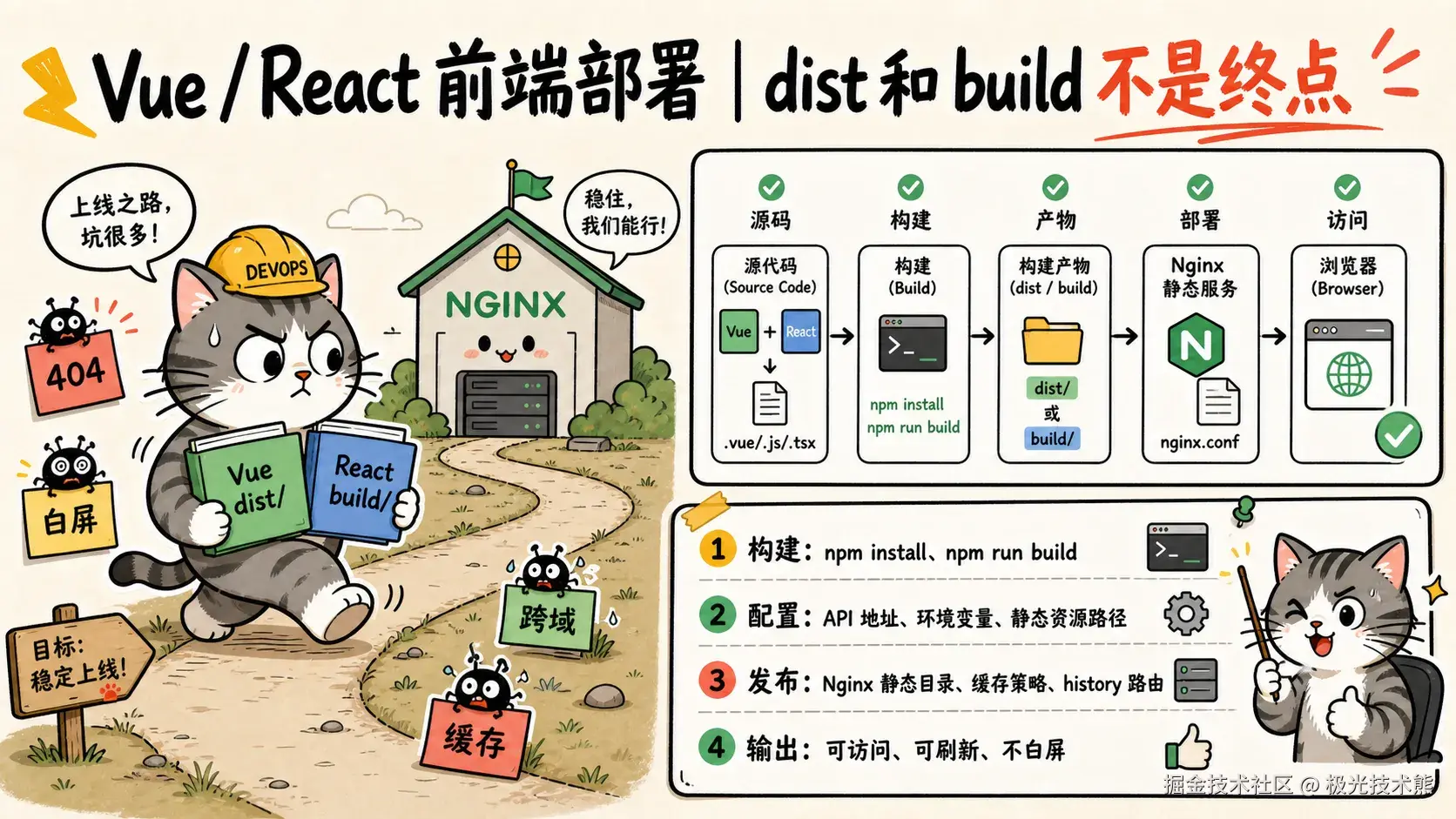
4.1 核心认知
前端部署的本质:把源码构建成静态文件(HTML/CSS/JS),然后交给 Web 服务器(Nginx)对外提供服务。前端项目本身不需要运行时环境,Nginx 托管静态文件即可。
4.2 项目构建
bash
# ---- Vue 项目(Vite 构建)----
npm install
npm run build # 产物在 dist/ 目录
# ---- React 项目(Vite / CRA)----
npm install
npm run build # 产物在 build/ 或 dist/ 目录构建完成后,核心产物是 index.html + JS/CSS 静态资源文件。
4.3 方式一:Nginx 直接托管(最常用)
前端打包后到底生成了什么?
很多小白搞不清楚"构建"到底做了什么。用大白话来说:
构建 = 把你能看懂的 Vue/React 源码,翻译成浏览器能直接运行的 HTML + CSS + JS 文件
构建完成后,dist/ 文件夹里就是这些"翻译好"的文件:
bash
dist/
├── index.html ← 入口页面,浏览器第一个加载的文件
├── assets/
│ ├── index-abc123.js ← 你的业务代码(登录、下单等功能),带 hash 防缓存
│ ├── vendor-def.js ← 第三方库(Vue、React 等)
│ └── style-xyz789.css ← 样式文件
└── favicon.ico核心认知:Nginx 的工作就是"把这些文件发给浏览器",它不需要懂 Vue 或 React,它只负责"递文件"。
第一步:把 dist 上传到服务器,放在哪里?
推荐放在 /var/www/项目名/ 或 /opt/项目名/frontend/,两个方案对比:
| 方案 | 路径示例 | 适用场景 | 优点 |
|---|---|---|---|
/var/www/ |
/var/www/myapp/ |
纯前端项目,Nginx 直接托管 | 符合 Linux 规范,权限清晰 |
/opt/项目名/ |
/opt/myapp/frontend/dist/ |
前后端在同一台机器 | 前后端文件在一起,方便管理 |
推荐用 /var/www/ 方案,命令如下:
bash
# 在本地构建(你的电脑上)
npm run build
# 构建完成后,dist/ 目录就生成了
# 把 dist/ 里的所有文件上传到服务器的 /var/www/myapp/
# scp 是 SSH 文件传输命令,把本地文件复制到远程服务器
scp -r dist/* user@your-server-ip:/var/www/myapp/
# ---- 或者,在服务器上直接构建(推荐) ----
ssh user@your-server-ip
cd /var/www/myapp
git pull origin main # 拉最新代码
npm install # 安装依赖
npm run build # 构建,产物在 dist/小贴士 :如果
npm run build时提示npm: command not found,说明服务器上还没装 Node.js,参考"一、部署前置"的 1.2 节安装。
第二步:Nginx 配置托管------逐行大白话解释
Nginx 要做的只有一件事:当用户访问你的网站时,把 dist/ 里的文件发给浏览器。
下面是完整配置,每一行都配有"大白话解释":
bash
# /etc/nginx/conf.d/myapp.conf
# 这是 Nginx 的"虚拟主机"配置文件
# 一个文件对应一个网站,可以有多个网站同时跑在 80 端口
server {
# listen 80:监听 80 端口(HTTP 默认端口)
# 用户访问 http://你的域名 或 http://服务器IP,Nginx 就会收到请求
listen 80;
# server_name:这个配置响应哪个域名的请求
# 比如 server_name www.example.com,只有访问 www.example.com 才会走这个配置
# 如果写 _(下划线),表示"匹配所有域名",适合临时测试
server_name www.example.com;
# root:指定"网站根目录"
# Nginx 收到请求后,会去这个目录下找文件
# 比如用户访问 /logo.png,Nginx 就去 /var/www/myapp/logo.png 找
root /var/www/myapp;
# index:指定"默认首页"
# 用户访问 / 时,Nginx 自动返回 index.html
index index.html;
# ---- 最关键配置:SPA 路由支持 ----
# 问题:Vue/React 是单页应用,路由是前端控制的
# 比如用户直接访问 /user/123,Nginx 会去找 /var/www/myapp/user/123 这个文件
# 但这个文件不存在!因为是前端路由,实际只有一个 index.html
#
# try_files 的作用:
# 1. 先找 $uri(比如 /user/123 这个文件)------找不到
# 2. 再找 $uri/(比如 /user/123/ 目录)------找不到
# 3. 最后返回 /index.html(交给前端路由处理)
#
# 这一步是前端部署最容易出错的地方!配错了就会出现"刷新页面 404"
location / {
try_files $uri $uri/ /index.html;
}
# ---- 静态资源缓存策略 ----
# 带 hash 的 JS/CSS 文件(比如 index-abc123.js)内容不会变
# 浏览器可以缓存 1 年,下次直接读本地,不用再下载
location /assets/ {
# expires 1y:告诉浏览器"这个文件 1 年内不用再来问我有没有更新"
expires 1y;
# Cache-Control "public, immutable":公开缓存,且内容不可变(因为有 hash)
add_header Cache-Control "public, immutable";
}
# ---- index.html 不缓存 ----
# index.html 是入口文件,每次发版都可能变
# 必须让浏览器每次都来问服务器"有没有新版本"
location = /index.html {
# expires -1:过期时间是"过去"(立即过期),浏览器每次都重新请求
expires -1;
add_header Cache-Control "no-cache, no-store, must-revalidate";
}
# ---- Gzip 压缩 ----
# 把 JS/CSS 文件压缩后再发给浏览器,传输速度快 3-5 倍
gzip on;
# gzip_types:指定哪些类型的文件需要压缩
# text/plain text/css application/javascript 是前端最常用的
gzip_types text/plain text/css application/json application/javascript text/xml;
# gzip_min_length:小于 1024 字节的文件不压缩(压缩收益太低)
gzip_min_length 1024;
# ---- 安全头(可选但推荐)----
# 防止被嵌入 iframe 钓鱼
add_header X-Frame-Options "SAMEORIGIN" always;
# 防止浏览器猜测 MIME 类型(安全加固)
add_header X-Content-Type-Options "nosniff" always;
}配置文件写完后,让 Nginx 重新加载配置:
bash
# 先检查配置文件语法是否正确(很重要!写错了 Nginx 会启动失败)
sudo nginx -t
# 语法 OK 后,平滑重载配置(不会中断正在处理的请求)
sudo nginx -s reload部署后验证 Checklist
| 现象 | 原因 | 解决办法 |
|---|---|---|
| 访问 IP 白屏 | Nginx 没启动 / root 路径写错 | sudo systemctl status nginx 检查状态 |
| 刷新页面 404 | try_files 配置缺失或写错 |
确认 location / 块里有 try_files $uri $uri/ /index.html; |
| 样式错乱/JS 报错 | dist/ 上传不完整 |
重新 scp -r dist/* 上传,或服务器上重新 npm run build |
| 能访问但很慢 | 没开 Gzip / 图片没压缩 | 检查 gzip on; 是否配置,用浏览器 DevTools Network 面板看传输大小 |
4.4 方式二:Docker 容器化部署(推荐生产环境)
这种方式本质是什么?
用 Docker 跑一个 Nginx 容器,把前端打包好的 HTML/CSS/JS 文件"塞"进去,让容器里的 Nginx 对外提供服务。
和"方式一"的核心区别:
- 方式一:Nginx 直接装在服务器上,dist 文件放在服务器的目录里
- 方式二:Nginx 跑在 Docker 容器里,dist 文件要么"打包进镜像",要么"挂载到容器里"
两种子方案对比:
| 子方案 | 做法 | 适用场景 |
|---|---|---|
| A. 打包进镜像(推荐) | dist/ 在构建镜像时就复制进去 |
CI/CD 自动化部署,版本可追溯 |
| B. 挂载数据卷 | 容器启动后,把宿主机 dist/ 挂载到容器里 |
快速调试,改了代码不用重新构建镜像 |
子方案 A:打包进镜像(生产推荐)
完整 Dockerfile(逐行大白话注释):
bash
# ============ 阶段1:构建前端代码 ============
# 用一个装好 Node.js 的"厨房"来构建项目
FROM node:20-alpine AS builder
WORKDIR /app
# 先复制 package*.json,再 npm ci
# 目的:利用 Docker 缓存,package.json 没变就不重新下载依赖
COPY package*.json ./
RUN npm ci --registry=https://registry.npmmirror.com
# 复制所有源代码,然后构建
COPY . .
RUN npm run build
# 构建完成后,产物在 /app/dist 目录
# ============ 阶段2:用 Nginx 托管 ============
# 换一个"干净盘子":只装 Nginx,不装 Node.js(镜像更小)
FROM nginx:1.25-alpine
# 删除 Nginx 默认配置(我们不想要那个 "Welcome to nginx!" 页面)
RUN rm /etc/nginx/conf.d/default.conf
# 把我们写好的 Nginx 配置文件复制进去
# nginx.conf 需要和 Dockerfile 在同一个目录
COPY nginx.conf /etc/nginx/conf.d/default.conf
# 把阶段1构建好的 dist/ 复制进 Nginx 的默认网站目录
# /usr/share/nginx/html 是 Nginx 容器的默认 root 路径
COPY --from=builder /app/dist /usr/share/nginx/html
# 暴露 80 端口(这只是"文档说明",真正映射端口在 docker run 时指定)
EXPOSE 80
# 启动 Nginx(daemon off 表示"前台运行",Docker 容器需要一个前台进程才不会退出)
CMD ["nginx", "-g", "daemon off;"]配套的 Nginx 配置文件(nginx.conf):
bash
# 这个文件和"方式一"的 Nginx 配置几乎一样
# 唯一的区别:root 路径变成了容器内的 /usr/share/nginx/html
server {
listen 80;
server_name _; # _ 表示匹配所有域名(容器内不需要特定域名)
root /usr/share/nginx/html;
index index.html;
# SPA 路由支持(和方式一完全一样,这个必须配!)
location / {
try_files $uri $uri/ /index.html;
}
# 静态资源长缓存
location /assets/ {
expires 1y;
add_header Cache-Control "public, immutable";
}
# index.html 不缓存
location = /index.html {
add_header Cache-Control "no-cache, no-store, must-revalidate";
}
# Gzip 压缩
gzip on;
gzip_types text/plain text/css application/json application/javascript text/xml;
gzip_min_length 1024;
}构建和运行命令:
bash
# 构建镜像(在 Dockerfile 所在目录执行)
docker build -t myapp-web:v1.0.0 .
# 运行容器
docker run -d \
--name myapp-web \
-p 80:80 \ # 把容器的 80 端口映射到宿主机的 80 端口
--restart unless-stopped \ # 容器挂了自动重启
myapp-web:v1.0.0
# 查看日志(确认 Nginx 正常启动)
docker logs -f myapp-web子方案 B:挂载数据卷(调试/快速迭代用)
场景 :你在调试前端样式,每次改一点都要重新 docker build,太慢了!
解决 :把宿主机的 dist/ 目录"挂载"到容器里,改完代码重新构建后,刷新浏览器就能看到效果,不用重建镜像。
目录结构规划:
bash
/opt/myapp/frontend/ ← 前端项目根目录
├── dist/ ← 构建产物(npm run build 生成)
├── nginx.conf ← Nginx 配置文件
└── docker-compose.yml ← 容器编排文件docker-compose.yml(关键配置说明):
bash
version: '3.8'
services:
frontend:
image: nginx:1.25-alpine
container_name: myapp-frontend
restart: always
# ports:端口映射,格式"宿主机端口:容器端口"
# 访问 http://服务器IP:8080 就能看到前端页面
ports:
- "8080:80"
# volumes(数据卷挂载):这是本方案的核心!
# 格式:"宿主机路径:容器路径[:权限]"
volumes:
# 挂载1:把宿主机 dist/ 挂到 Nginx 的网站目录
# 这样 dist/ 里的文件变了,容器里立刻生效(不用重启容器)
- ./dist:/usr/share/nginx/html:ro
# ↑ :ro = read-only 只读
# 防止容器内的进程意外修改你的文件
# 挂载2:把宿主机的 nginx.conf 挂进去
# 这样你改了 nginx.conf,执行 nginx -s reload 就能生效
- ./nginx.conf:/etc/nginx/conf.d/default.conf:ro
# command:容器启动后执行的命令
# nginx -g "daemon off;" 是前台运行(Docker 容器必须前台运行)
command: nginx -g "daemon off;"完整工作流(大白话版):
关键命令速查:
| 命令 | 大白话解释 |
|---|---|
docker-compose up -d |
"启动容器",-d 是后台运行 |
docker-compose down |
"停掉并删除容器",卷挂载的数据不会丢 |
docker exec myapp-frontend nginx -s reload |
"让 Nginx 重新加载配置",修改 nginx.conf 后必执行 |
docker logs -f myapp-frontend |
"看容器日志",Nginx 报错信息在这里 |
两种子方案怎么选?
bash
你在做 ↓
开发调试 / 快速迭代
│
▼
用【子方案 B:挂载数据卷】
→ 改代码 → build → 刷新浏览器,秒级见效
→ 改 Nginx 配置 → docker exec ... nginx -s reload,秒级见效
│
发版上线 / CI/CD 自动化
│
▼
用【子方案 A:打包进镜像】
→ docker build 构建镜像 → docker push 推到镜像仓库
→ 服务器 docker pull 拉取 → docker run 启动
→ 版本可追溯(v1.0.0、v1.0.1...),出问题秒回滚4.5 环境变量处理技巧
前端项目在构建时注入环境变量,而非运行时:
bash
# Vue / Vite 项目:使用 .env 文件
# .env.production
VITE_API_BASE_URL=https://api.example.com
VITE_APP_TITLE=My App
# React / CRA 项目
# .env.production
REACT_APP_API_URL=https://api.example.com
bash
# Dockerfile 中注入构建时变量
ARG VITE_API_BASE_URL=https://api.example.com
ENV VITE_API_BASE_URL=$VITE_API_BASE_URL
RUN npm run build
bash
# 构建时动态指定
docker build --build-arg VITE_API_BASE_URL=https://api.prod.com -t myapp-web .注意 :如果需要运行时动态修改 API 地址,可在
index.html中注入window.__CONFIG__,通过 Nginx 的sub_filter在启动时替换。
五、Nginx 反向代理与域名配置
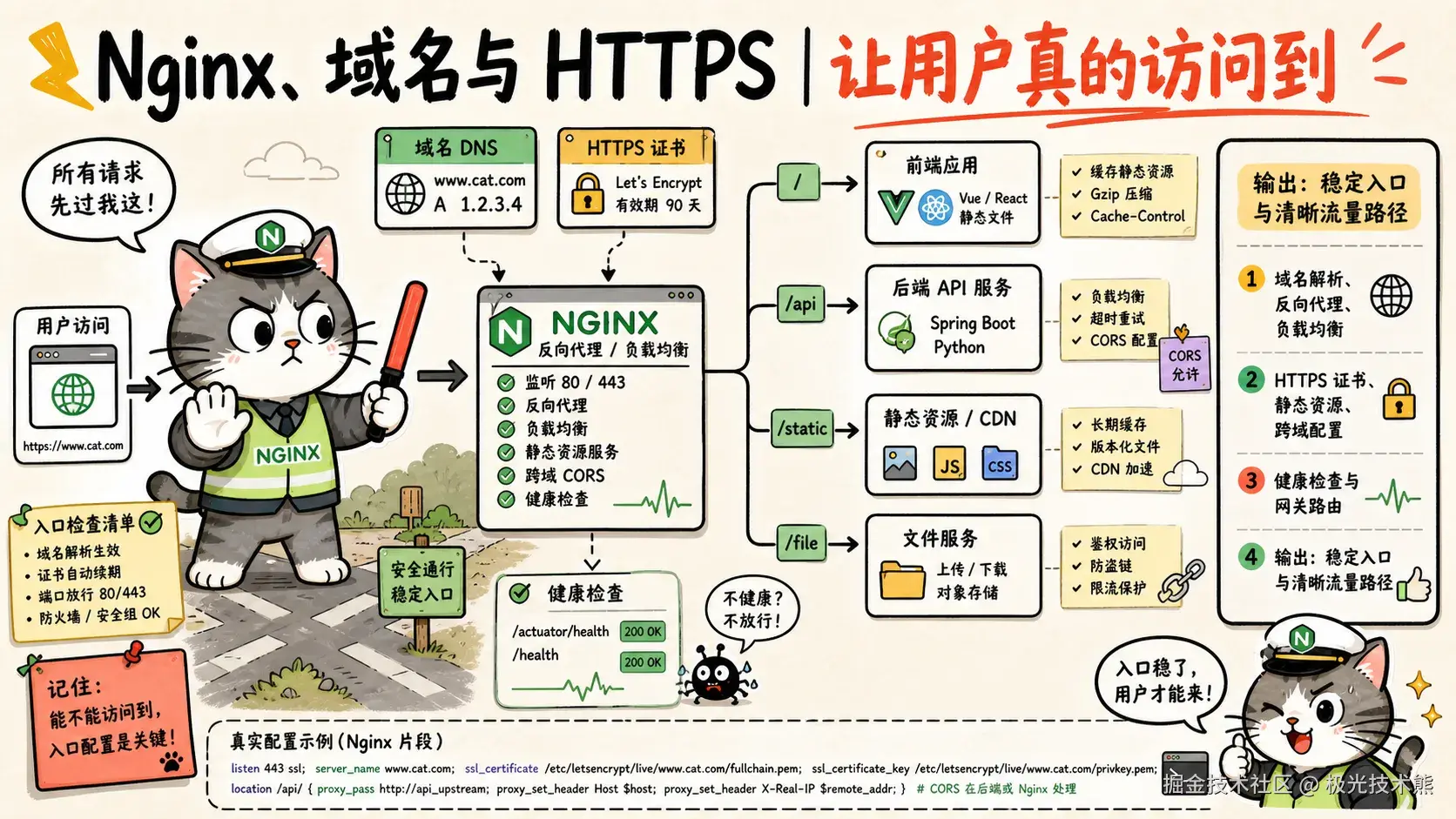
5.1 反向代理:统一入口
将前端 + 后端 API 统一到同一域名下,避免跨域问题:
bash
# /etc/nginx/conf.d/myapp.conf
# HTTP -> HTTPS 重定向
server {
listen 80;
server_name www.example.com;
return 301 https://$host$request_uri;
}
# HTTPS 主配置
server {
listen 443 ssl http2;
server_name www.example.com;
# SSL 证书(Let's Encrypt 免费获取)
ssl_certificate /etc/letsencrypt/live/www.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/www.example.com/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
# ---- 前端静态文件 ----
location / {
root /var/www/myapp;
index index.html;
try_files $uri $uri/ /index.html;
}
# ---- 后端 API 代理 ----
location /api/ {
proxy_pass http://127.0.0.1:8080/; # Spring Boot
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket 支持
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
# 超时设置
proxy_connect_timeout 60s;
proxy_read_timeout 120s;
proxy_send_timeout 60s;
}
# ---- Python API 代理(如有) ----
location /pyapi/ {
proxy_pass http://127.0.0.1:8000/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# 静态资源缓存
location /assets/ {
expires 1y;
add_header Cache-Control "public, immutable";
}
}5.2 SSL 证书配置(Let's Encrypt)
bash
# 安装 Certbot
sudo yum install -y certbot python3-certbot-nginx
# 获取证书(自动修改 Nginx 配置)
sudo certbot --nginx -d www.example.com
# 自动续期(Certbot 会自动添加 cron)
sudo certbot renew --dry-run六、Docker Compose 一键编排
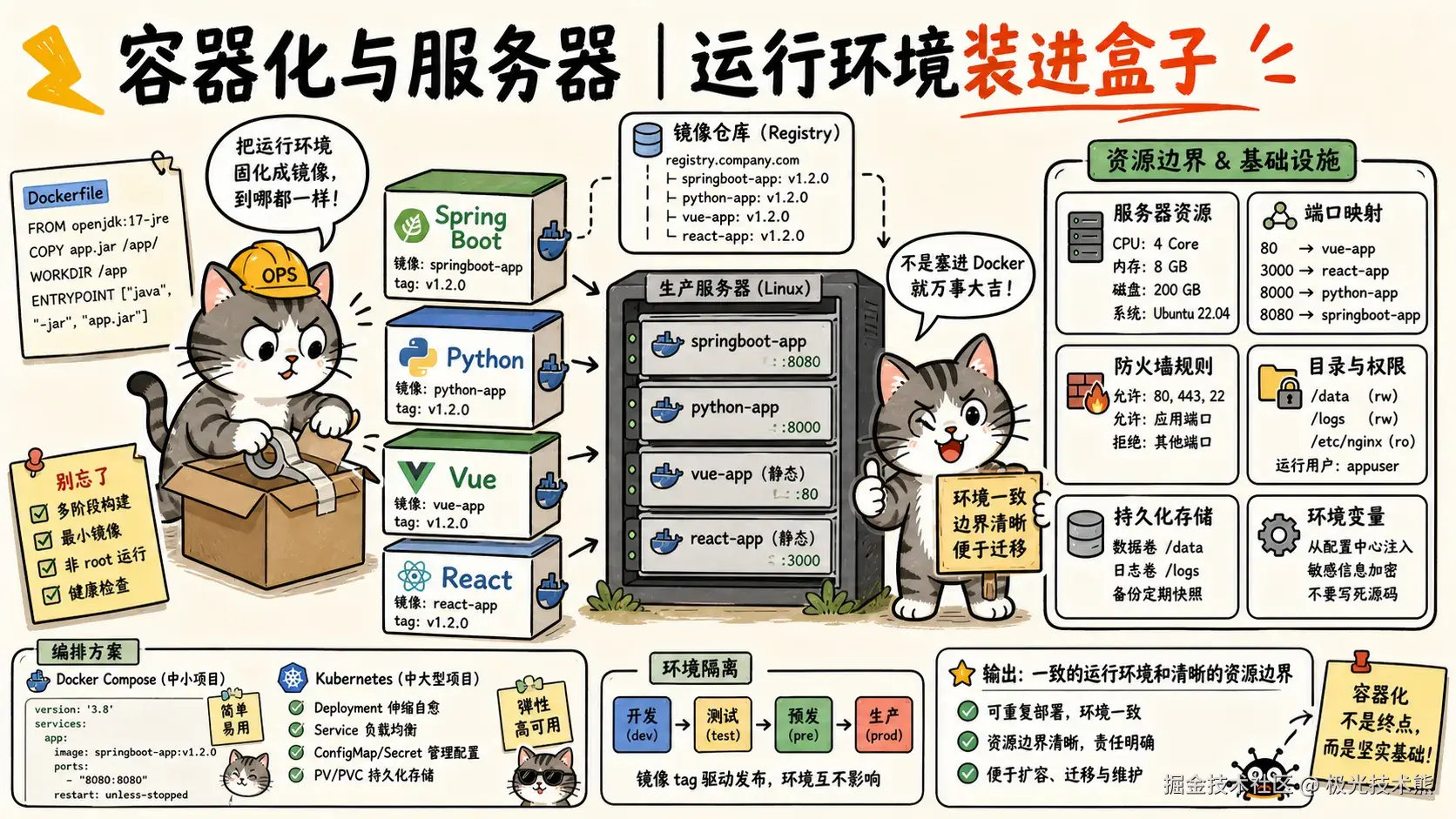
当项目包含前端、后端、数据库等多个服务时,用 Docker Compose 统一管理。
6.1 完整的 docker-compose.yml
bash
# docker-compose.yml
version: "3.9"
services:
# ---- Nginx 网关 ----
nginx:
image: nginx:1.25-alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx/conf.d:/etc/nginx/conf.d
- ./nginx/ssl:/etc/letsencrypt
- frontend-dist:/usr/share/nginx/html
depends_on:
- java-api
- python-api
restart: unless-stopped
networks:
- app-network
# ---- Java Spring Boot 后端 ----
java-api:
build:
context: ./java-backend
dockerfile: Dockerfile
environment:
- SPRING_PROFILES_ACTIVE=prod
- SPRING_DATASOURCE_URL=jdbc:postgresql://db:5432/mydb
- SPRING_DATASOURCE_USERNAME=${DB_USER}
- SPRING_DATASOURCE_PASSWORD=${DB_PASSWORD}
- TZ=Asia/Shanghai
ports:
- "8080:8080" # 仅调试用,生产可去掉
depends_on:
db:
condition: service_healthy
restart: unless-stopped
networks:
- app-network
# ---- Python FastAPI 后端 ----
python-api:
build:
context: ./python-backend
dockerfile: Dockerfile
environment:
- DATABASE_URL=postgresql://${DB_USER}:${DB_PASSWORD}@db:5432/mydb
- TZ=Asia/Shanghai
ports:
- "8000:8000" # 仅调试用
depends_on:
db:
condition: service_healthy
restart: unless-stopped
networks:
- app-network
# ---- PostgreSQL 数据库 ----
db:
image: postgres:16-alpine
environment:
- POSTGRES_DB=mydb
- POSTGRES_USER=${DB_USER}
- POSTGRES_PASSWORD=${DB_PASSWORD}
- TZ=Asia/Shanghai
volumes:
- pgdata:/var/lib/postgresql/data
# 不暴露端口到公网!
# ports:
# - "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${DB_USER}"]
interval: 10s
timeout: 5s
retries: 5
restart: unless-stopped
networks:
- app-network
# ---- Redis 缓存 ----
redis:
image: redis:7-alpine
command: redis-server --requirepass ${REDIS_PASSWORD}
volumes:
- redisdata:/data
restart: unless-stopped
networks:
- app-network
volumes:
pgdata:
redisdata:
frontend-dist:
networks:
app-network:
driver: bridge6.2 环境变量管理
bash
# .env 文件(不要提交到 Git!)
DB_USER=myuser
DB_PASSWORD=your_strong_password_here
REDIS_PASSWORD=your_redis_password_here
bash
# .gitignore 中添加
.env6.3 一键启停
bash
# 启动所有服务
docker-compose up -d
# 查看运行状态
docker-compose ps
# 查看日志
docker-compose logs -f java-api
# 重启单个服务
docker-compose restart java-api
# 停止并删除容器(数据卷保留)
docker-compose down
# 重新构建并启动
docker-compose up -d --build七、CI/CD 自动化部署
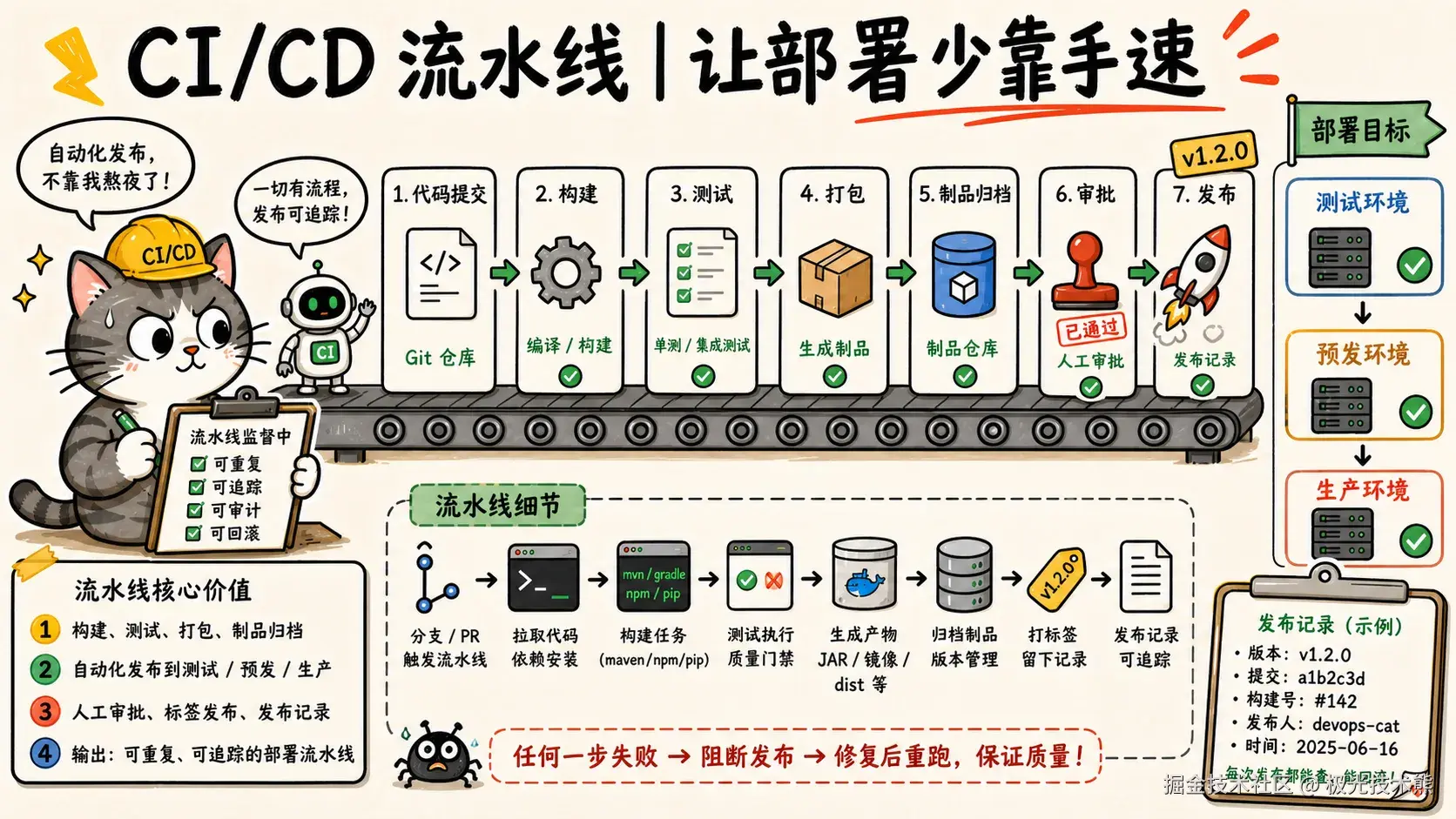
7.1 GitHub Actions 示例
Java Spring Boot + Docker 自动部署:
bash
# .github/workflows/deploy-java.yml
name: Deploy Java API
on:
push:
branches: [main]
paths:
- 'java-backend/**'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Set up JDK 17
uses: actions/setup-java@v4
with:
java-version: '17'
distribution: 'temurin'
- name: Build with Maven
run: |
cd java-backend
mvn clean package -DskipTests
- name: Build Docker Image
run: |
cd java-backend
docker build -t myapp-java:${{ github.sha }} .
- name: Deploy to Server
uses: appleboy/ssh-action@v1
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SERVER_USER }}
key: ${{ secrets.SSH_PRIVATE_KEY }}
script: |
cd /opt/myapp
docker pull myregistry/myapp-java:${{ github.sha }}
docker-compose up -d java-api
docker image prune -f前端 Vue/React 自动部署:
bash
# .github/workflows/deploy-frontend.yml
name: Deploy Frontend
on:
push:
branches: [main]
paths:
- 'frontend/**'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
cache-dependency-path: frontend/package-lock.json
- name: Install & Build
run: |
cd frontend
npm ci
npm run build
- name: Deploy to Server
uses: appleboy/scp-action@v0.1.7
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SERVER_USER }}
key: ${{ secrets.SSH_PRIVATE_KEY }}
source: "frontend/dist/*"
target: "/var/www/myapp"
strip_components: 2
- name: Reload Nginx
uses: appleboy/ssh-action@v1
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SERVER_USER }}
key: ${{ secrets.SSH_PRIVATE_KEY }}
script: sudo nginx -s reload7.2 GitLab CI 示例
bash
# .gitlab-ci.yml
stages:
- build
- deploy
variables:
DOCKER_IMAGE: registry.example.com/myapp
build-java:
stage: build
image: maven:3.9-eclipse-temurin-17
script:
- cd java-backend
- mvn clean package -DskipTests
- docker build -t $DOCKER_IMAGE/java:$CI_COMMIT_SHA .
- docker push $DOCKER_IMAGE/java:$CI_COMMIT_SHA
only:
changes:
- java-backend/**/*
deploy:
stage: deploy
script:
- ssh deploy@server "cd /opt/myapp && docker-compose pull && docker-compose up -d"
only:
- main
when: manual # 需手动触发部署八、生产环境最佳实践
8.1 安全清单
- 不使用 root 运行应用:Docker 容器内创建专用用户
- 数据库不暴露公网:通过安全组/防火墙限制为内网访问
- 敏感信息使用环境变量:密码、密钥不硬编码,不提交 Git
- 启用 HTTPS:Let's Encrypt 免费 SSL
- 设置安全响应头:X-Frame-Options、CSP、HSTS
- 定期更新依赖:关注安全漏洞公告
- SSH 密钥登录:禁用密码登录
8.2 日志管理
bash
# Docker 日志限制
# /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "50m",
"max-file": "3"
}
}
bash
# Spring Boot 日志配置(application-prod.yml)
logging:
file:
name: /app/logs/application.log
logback:
rollingpolicy:
max-file-size: 50MB
max-history: 30
total-size-cap: 1GB8.3 监控告警
| 工具 | 用途 | 推荐场景 |
|---|---|---|
| Prometheus + Grafana | 指标采集与可视化 | 中大型项目 |
| Uptime Kuma | 站点可用性监控 | 个人/小团队 |
| Sentry | 错误追踪 | 所有项目 |
| Portainer | Docker 可视化管理 | 容器化项目 |
8.4 备份策略
bash
#!/bin/bash
# backup.sh - 数据库定时备份脚本
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_DIR="/opt/backups"
# PostgreSQL 备份
docker exec db pg_dump -U myuser mydb | gzip > "$BACKUP_DIR/db_$DATE.sql.gz"
# 保留最近 7 天备份
find $BACKUP_DIR -name "*.sql.gz" -mtime +7 -delete
echo "Backup completed: db_$DATE.sql.gz"
bash
# 添加 crontab 定时任务(每天凌晨 3 点执行)
crontab -e
0 3 * * * /opt/scripts/backup.sh >> /opt/backups/backup.log 2>&18.5 性能优化速查
| 项目类型 | 优化点 | 具体措施 |
|---|---|---|
| Java | JVM 调优 | G1GC、容器感知内存、连接池 |
| Python | 并发模型 | Gunicorn 多 worker、异步 IO |
| 前端 | 资源优化 | Gzip/Brotli 压缩、CDN、懒加载 |
| Nginx | 连接优化 | keepalive、upstream 缓存、限流 |
| 数据库 | 查询优化 | 索引、连接池、读写分离 |
九、常见问题排查
9.1 Java 项目
| 问题 | 原因 | 解决方案 |
|---|---|---|
OutOfMemoryError |
堆内存不足 | 调大 -Xmx,查看 logs/heapdump.hprof 分析内存 |
| 启动慢 | 依赖多、扫描路径大 | 开启懒加载 spring.main.lazy-initialization=true |
| 连接数据库超时 | 网络或连接池配置 | 检查安全组,调整 spring.datasource.hikari |
| Docker 容器时区不对 | 默认 UTC | 设置 TZ=Asia/Shanghai |
| 脚本 stop 后进程仍在 | 优雅停机超时 | 检查应用是否注册了 shutdown hook,脚本会在 30 秒后自动 kill -9 |
| 外部配置不生效 | --spring.config.location 路径错误 |
确认以 / 结尾,如 ../config/,文件名须为 application-prod.yml |
| 脚本提示 JAR not found | JAR 文件名与脚本配置不一致 | 检查 app.sh 中的 JAR_NAME 变量是否与实际文件名匹配 |
| 日志目录不存在 | 首次部署未创建目录 | 脚本会自动创建;如手动启动需 mkdir -p logs tmp |
kill -9 后端口仍占用 |
进程残留 | 等待 1-2 分钟释放,或 `ss -tlnp |
| 回滚后配置不匹配 | 备份的 JAR 与现有 config 不兼容 | 同时备份 config 目录,或确保配置向后兼容 |
9.2 Python 项目
| 问题 | 原因 | 解决方案 |
|---|---|---|
ModuleNotFoundError |
依赖未安装 | 检查 requirements.txt,确认 venv 激活 |
| 502 Bad Gateway | Gunicorn 挂了 | 查看日志 docker logs,增加 worker/超时 |
| 静态文件 404 | 路径配置错误 | 检查 STATIC_URL 和 Nginx alias |
| 并发上不去 | GIL 限制 | 增加 worker 数,考虑异步框架(FastAPI) |
9.3 前端项目
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 刷新页面 404 | Nginx 未配置 SPA 回退 | 添加 try_files $uri $uri/ /index.html |
| 接口跨域 | 前后端不同端口/域名 | Nginx 反向代理统一域名 |
| 更新后白屏 | 浏览器缓存旧文件 | index.html 设 no-cache,静态资源加 hash |
| 环境变量不生效 | Vite/CRA 构建时注入 | 检查 .env.production,确认 VITE_/REACT_APP_ 前缀 |
| Docker 镜像太大 | 未用多阶段构建 | 使用 builder 阶段,最终镜像仅含 Nginx + 静态文件 |
9.4 通用排查命令
bash
# 检查端口占用
ss -tlnp | grep :8080
# 检查 Docker 容器状态
docker ps -a
# 查看容器日志(最后 100 行)
docker logs --tail 100 -f myapp
# 检查 Nginx 配置语法
sudo nginx -t
# 测试接口连通性
curl -v http://localhost:8080/actuator/health
curl -v http://localhost:8000/health
# 查看磁盘空间
df -h
# 查看内存使用
free -h
# 查看系统负载
uptime快速部署速查表
| 技术栈 | 构建命令 | 部署方式 | 默认端口 |
|---|---|---|---|
| Spring Boot | mvn clean package |
脚本 / Docker Compose / Swarm | 8080 |
| FastAPI | - | Gunicorn + Uvicorn / Docker | 8000 |
| Flask | - | Gunicorn / Docker | 8000 |
| Vue (Vite) | npm run build |
Nginx / Docker | 80 |
| React (Vite/CRA) | npm run build |
Nginx / Docker | 80 |
写在最后:部署没有银弹,适合自己的才是最好的。小型项目用 JAR/venv + systemd 就够了,中大型项目上 Docker Compose + CI/CD,微服务架构考虑 Kubernetes。先跑起来,再优化。遇到问题别慌,看日志,查端口,99% 的问题都能定位。