最近,antirez(Salvatore Sanfilippo,Redis 作者)发布了一些内容,核心就是反驳一个言论: "中国模型之所以强,主要是因为通过 API 蒸馏了美国模型。"
他认为这种说法在机器学习原理上站不住脚,甚至是 "marketing from US labs" 或对 ML 的误解。
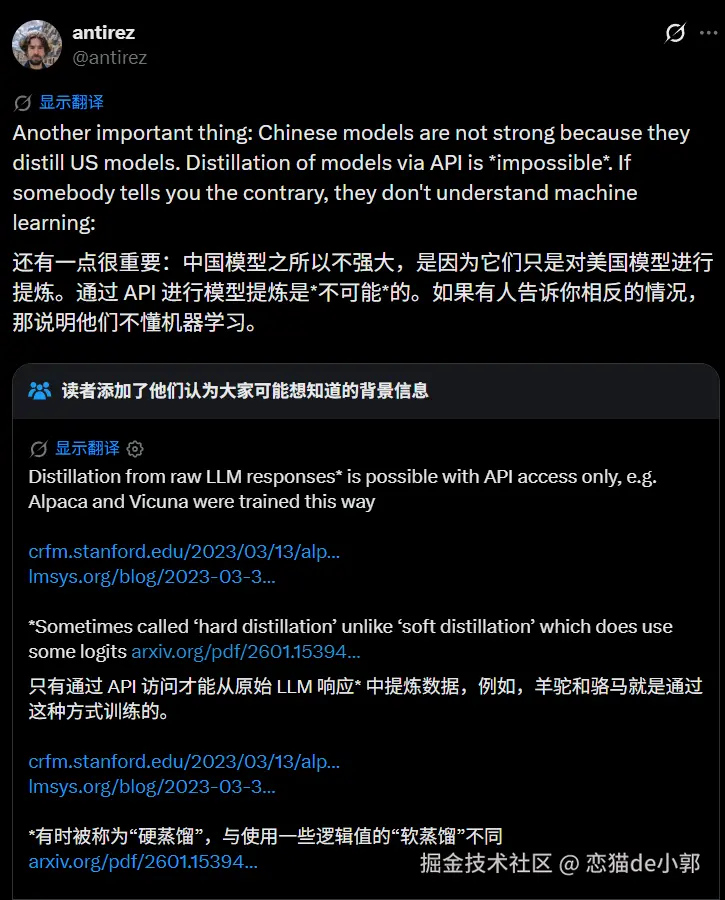
antirez 的意思是:有些人把中国开源/闭源模型的进步,简单归因于"偷偷用 GPT/Claude API 生成数据来蒸馏",这在严格的机器学习意义上是不成立的。
实际上也是大家对于定于的不一致,这个后面就可以理解。
在他看来,API 蒸馏在严格意义上不可能(白盒/软蒸馏),因为:
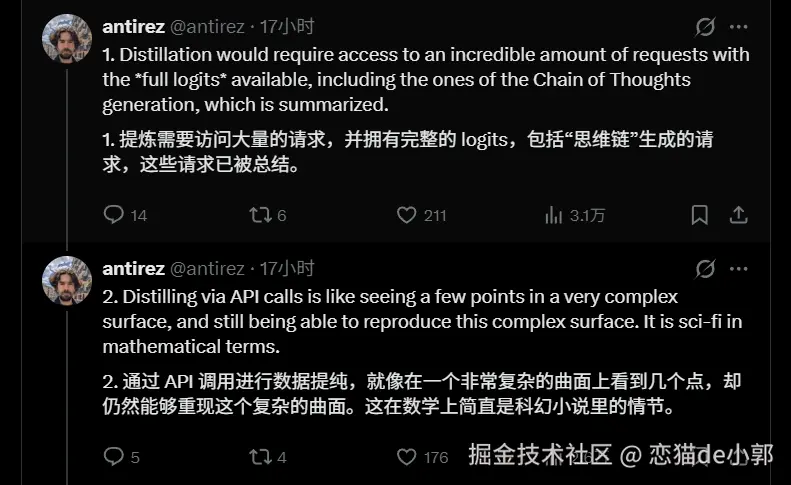
- 真正的蒸馏需要大量访问 teacher 的完整 logits(概率分布)、Chain-of-Thought 推理轨迹、内部表示等
- 商业 API 只返回最终文本,完全拿不到这些内部信息
- 他把 API 蒸馏比作「只看到复杂曲面上的几个点,就想复刻整个曲面」,这在在数学上接近科幻
所以白盒蒸馏闭源项目基本是不可能的,记住,是白盒(软的),因为白盒蒸需要让 student 不仅输出一样,还要内部"思考过程"和知识表示尽量接近 teacher。
其次是,黑盒 (硬蒸)能做,但作用有限 :
- 用 API 生成数据做 SFT(Alpaca/Vicuna 那类),确实可以改善「回复风格」、填补狭窄知识 gap、或者让模型更会 follow 特定格式
- 但是无法创造 frontier-level 的通用能力,真正强大的底层能力来自海量 pretraining(万亿 token 级别的数据 + 巨大 compute)
- 他明确说,即使你有 teacher 生成的 trace,没有 CoT 等内部信息,也只是 "tuning the style or filling very small knowledge gaps at best"
除非你只是用来刷基准,刷榜单,这就可以蒸得榜单数据好看,但是实战还是拉跨。
再者,即使有完整模型访问,蒸馏 frontier 模型也极难:
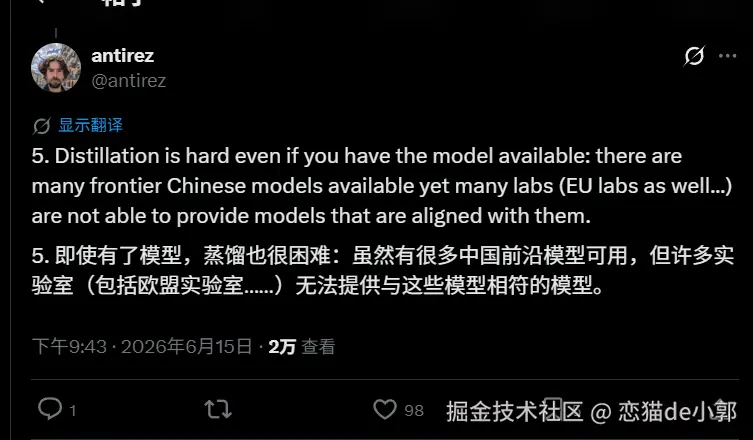
- 很多 frontier 中国模型已经开源,但包括欧洲实验室在内的很多团队,依然很难训练出对齐它们水平的模型
- 这说明蒸馏/复刻不是"有数据就能轻松复制"
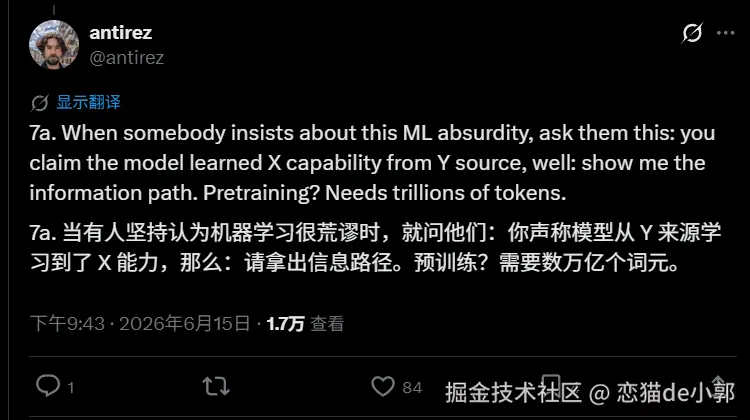
所以他觉得,中国模型比美国模型落后的原因,真正的差距更多来自 compute deficit (算力获取限制),而不是单纯的技术抄袭或蒸馏,他不否认中国模型目前的实际能力差距,但坚决反对把这种实力主要归因于"蒸馏美国模型" 。
不过,实际上现在黑盒蒸馏可以规模化,也能有效迁移部分任务能力、输出风格、格式遵循和一定程度的推理模式,所以被用的其实还是挺多的,但确实没办法真的复制 teacher 的能力 。
当然,也有说反对的说 "用原始 LLM responses 做 distillation 是完全可以的,只需要 API 访问权限",并举例 Alpaca 和 Vicuna 就是这么训练出来的 。
这种方式不需要 teacher 暴露任何内部 logits 或 hidden states,只需要 teacher 生成的最终文本 responses ,但是效果肯定好不到哪里去。
说回蒸馏,其实 antirez 想表达的意思里,有部分是想说 "蒸馏"这个词目前有点被严重滥用和误解了,大家口头说的"蒸馏",但是经常把两种完全不同的技术混在一起说:
- Hard Distillation(硬蒸馏 /黑盒) :只用 teacher 生成的离散 token 序列(responses)训练 student,用标准交叉熵损失, 类似前面说的 Alpaca 和 Vicuna 采用的方式
- Soft Distillation(软蒸馏/白盒) :需要 teacher 的完整概率分布(logits),通过 KL 散度让 student 模仿 teacher 的软标签,这需要白盒访问或 API 暴露 logits,目前主流商业 API 基本不提供
实际上苹果这次发布 Apple Foundation Models 就是一个 distillation-based refinement ,但是更接近硬蒸馏(不完全) ,因为苹果说的是,在 post-training / refinement 阶段,使用了 Gemini frontier models 的 outputs 进行精炼,也就是用 Gemini frontier model 生成的 outputs(responses)来精炼/对齐自己的模型 。
另外 2026 年的论文《Memorization Dynamics in Knowledge Distillation for Language Models 》(arxiv.org/pdf/2601.15394)也明确区分了这两个的不同,也提到了目前 hard distillation 在黑盒 API 场景下是可行的常用方法,只是会比 soft distillation 继承更多 teacher 特有的记忆样本。
所以如果要说硬蒸馏行不行?肯定是可以的,只是他的可控程度,成本和效果肯定差很多。
姚顺宇大佬在访谈里也提到过 "硬蒸/ 聪明的蒸"在实践策略层面的差异,在工程视角上:
-
简单粗暴:直接让 Claude/GPT 大量生成 token,然后一股脑塞进自己模型里强制训练,大佬的评价是 "商业上也不是很道德,治理上来说也比较愚蠢" ,说明公司"没有想明白也没有方向",因为没有数据筛选、没有策略、没有把 teacher 当成工具,只是当成"数据打印机"
-
聪明的蒸:把强模型当成辅助工具和评价者,有策略、有目的性地融入自己的训练系统,比如
- 数据筛选高质量 synthetic data、用 teacher 做 reward model / verifier、multi-agent 协作生成数据、真实数据 ,配合 synthetic 数据混合、迭代式 self-improvement 等
简单来说就是:
- 粗暴硬蒸 = 低水平重复(just dump data)
- 聪明的蒸 = 高水平工程(build a smart data flywheel + training system)
当时 antirez 认为不行大部分基于白盒/软蒸馏,他觉得中国模型的真实进步主要来自自己的算力投入、数据工程和研究工作,而不是通过 API 就能轻松"蒸馏"出 frontier 能力,如果把后者当成主要解释,既违反机器学习基本原理,也低估了真正构建强模型的难度。
所以讨论出现分歧的原因也在这里,虽然都叫"蒸馏",但是白盒/软蒸馏被技术圈认为才是真正的蒸馏,而黑盒/硬蒸馏这种只用 teacher 生成的文本 outputs 做 SFT 的做法叫做 Response Distillation 。
所以蒸馏也分专业领域和大众领域,所以这也是存在分歧的原因,大概区别就是:
-
Soft Distillation(软蒸馏 / 白盒)
- 让 student 去模仿 teacher 的完整概率分布(logits),不只是学最终答案
- Teacher 输出不是硬标签(one-hot),而是经过 temperature scaling 的软概率分布
- 学生能学到"暗知识"(dark knowledge):为什么 teacher 认为 A 的概率是 0.7、B 是 0.2、C 是 0.1,而不是简单告诉它是 A
当然,严格的说,soft distillation 的"软"主要是概率分布,不是自然语言思考过程,老师不是真的告诉学生"因为......",而是告诉学生:"在所有候选 token/class 里,我对 A、B、C 的概率分别是多少。"
-
Hard Distillation(硬蒸馏 / 黑盒)
- 只用 teacher 生成的离散 token 序列(最终输出文本),用标准交叉熵训练 student
- 相当于把 teacher 当成"老师傅"生成 pseudo-label,然后 student 像正常 SFT 一样学这些数据
说人话就是:
- Soft Distillation(软蒸馏 / 白盒)老师不仅写答案,还说出思考过程和信心:"我算出来17的概率85%,因为......",学生学到深层思考和暗知识,更聪明
- Hard Distillation(硬蒸馏 / 黑盒) 老师只在黑板上写最终答案:"10+7=17",学生反复抄答案,学会最终结果和格式,但不知道老师是怎么算的。
也就是一个抄思考过程,一个抄答案.
不过日常里大家其实也不会理解那么多,也不会区分那么多,所以反正我说蒸馏的时候,也不怎么区分这个,所以很多时候也会被怼被阴阳,不过不重要,重要的是你怎么看?
只是我也是同意的,纯硬蒸是做不出来 DeepSeek 的,这一点 antirez 毫无争议是对的。