最近发现个好玩的大模型 DiffusionGemma-26B-A4B-it,这个模型有什么特别的呢?可以先看下下面这张图。
可以看到,这个大模型生成的文字不是从左到右一个字一个字冒出来的,而是直接输出了所有的 token(图中的白色方块),接下来对所有噪声 token 进行迭代替换,直到得到最终答案。
这正是 DiffusionGemma 模型的技术特点,它没有使用传统大模型的 "自回归" 技术,而是使用了图像领域常用的 "扩散" 技术。
Google 发了个"异类"模型
6 月 10 日,Google DeepMind 发布了 DiffusionGemma-26B-A4B-it。26B 总参数,4B 激活参数,MoE 架构,Apache 2.0 开源。
这些数字看起来平平无奇,但真正有意思的是藏在它后半截名字里的 "Diffusion"。
目前几乎所有主流大语言模型,从 GPT-4o 到 Llama 4,从 Claude 到 DeepSeek,都是自回归(Autoregressive)模型。它们的工作方式是:给我前面的文字,我预测下一个字。像打字机,一个字接一个字。
DiffusionGemma 不是,它用了一套从图像生成领域搬过来的技术,叫扩散模型(Diffusion Model)。生成文字的方式跟生成图片的方式一样,先铺一层噪声,再一轮一轮去噪,直到文字浮现出来。
Google 自己也说了,这是一个实验性模型,虽然整体输出质量还不如同架构的标准 Gemma 4,但它的推理速度比 Gemma 4 整整快了 4 倍。单块 H100 上,每秒生成超过 1000 个 token。
这样一个 "异类" 模型,仅仅是快吗?有哪些是自回归模型做不到的呢?
扩散模型:CV领域的技术迁移
扩散模型并不是新技术。2022 年 Stable Diffusion 横空出世的时候,背后就是扩散模型。包括 DALL-E、Midjourney,全是这个路线。在过去几年里,扩散模型几乎垄断了图像生成的技术选型。
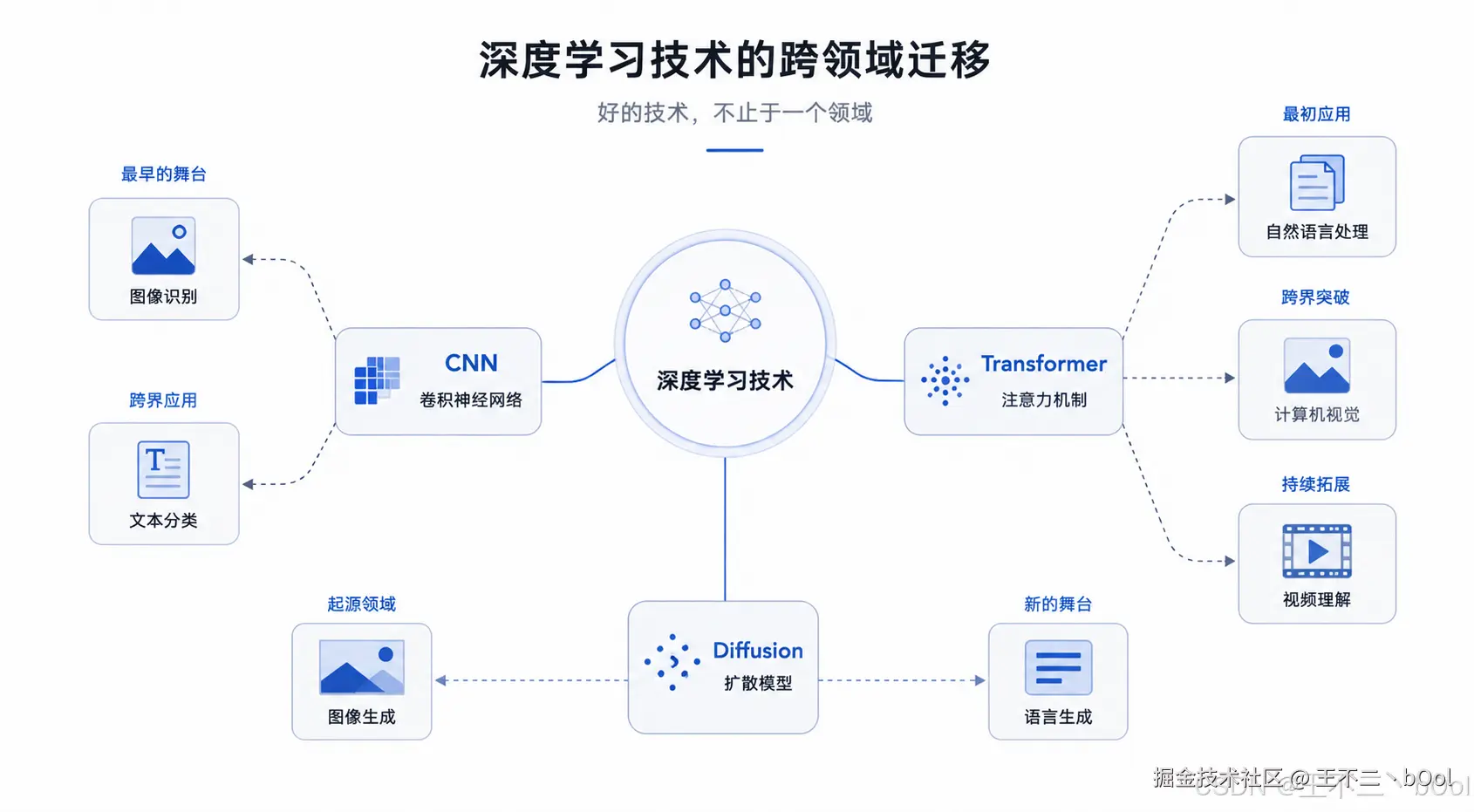
深度学习分领域(NLP、CV),深度学习技术可不分领域,从来不是 "哪个领域生,就只在哪个领域用"。技术是会迁移的,而且经常跨领域迁移。
CNN(卷积神经网络)最早是为图像设计的。Yann LeCun 在 1998 年用 LeNet 做手写数字识别。但 2014 年 Yoon Kim 搞出了 textCNN,拿CNN 做文本分类,效果同样很好。卷积的局部感受野天然适合抓文本的 n-gram 特征。
同样,2017 年 Attention Is All You Need 论文出来的时候,transformer 做的是机器翻译,纯 NLP 任务。但 2020 年 ViT(Vision Transformer)一出,Transformer 也能做图像理解了。现在图像、视频、语音、蛋白质结构预测,全在用 Transformer。
GAN(生成对抗网络)也有跨领域的历史。2014 年 Ian Goodfellow 拿它生成图像,后来也有人拿 GAN 生成文本,只是效果不如图像领域那么亮眼。
所以扩散模型从图像迁移到文本,不是什么意外。它遵循的是同一个规律:好的生成框架不挑领域,只挑合适的离散化或连续化方案。图像的噪声是连续的(高斯噪声),文本的 "噪声" 是离散的(掩码),但 "逐步去噪、渐进生成" 这个核心思想是一样的。
文本扩散模型怎么工作
推理:先出整体再细化
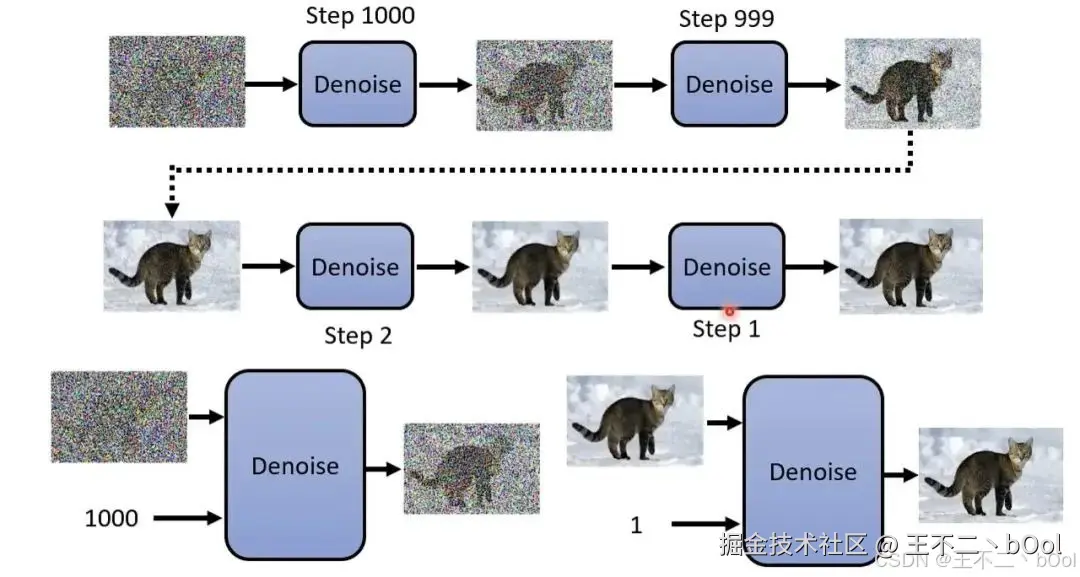
自回归模型推理,输入 prompt,预测第 1 个 token,将第一个输出 token 加入输入,预测第 2 个 token,继续加入输入,预测第 3 个,如此往复......每个 token 只能看到左边的上下文,看不到右边还没生成的东西(所以叫因果注意力)。一次前向传播只能推导出一个 token。
文本扩散模型推理可以分为三步:
第一步,铺空画布。 在 prompt 后面放一串占位符 [M][M][M]...[M]([M] 表示 <mask>),长度是预设的 gen_length。这就像一张画布的轮廓线。
第二步,整体预测。 把 prompt 和这些 [M] 一起扔给模型。模型同时预测所有 [M] 位置应该填什么 token。注意,模型用的是双向注意力,每个位置能看到左边和右边的全部上下文。
第三步,置信度筛选,迭代替换。 模型给每个位置的预测打了分(置信度)。只有高置信度的位置被保留,低置信度的重新盖回 [M]。下一轮再预测,再筛选,直到所有 [M] 都消除。
举个直观的例子,假设要生成"人工智能正在改变世界",这个生成过程如下:
scss
第1轮:[M] [M] [M] [M] [M] [M] [M] [M]
模型预测:人类 智能 在 改变 [M] [M] [M] [M]
保留高置信度:位置2"智能"(0.9)、位置4"改变"(0.85)
第1轮结果:[M] [智能] [M] [改变] [M] [M] [M] [M]
第2轮:[M] [智能] [M] [改变] [M] [M] [M] [M]
模型预测:人工 智能 正在 改变 世界 。 [M] [M]
保留高置信度:位置1"人工"(0.85)、位置3"正在"(0.8)、位置5"世界"(0.9)、位置6"。"(0.85)
第2轮结果:[人工] [智能] [正在] [改变] [世界] [。] [M] [M]
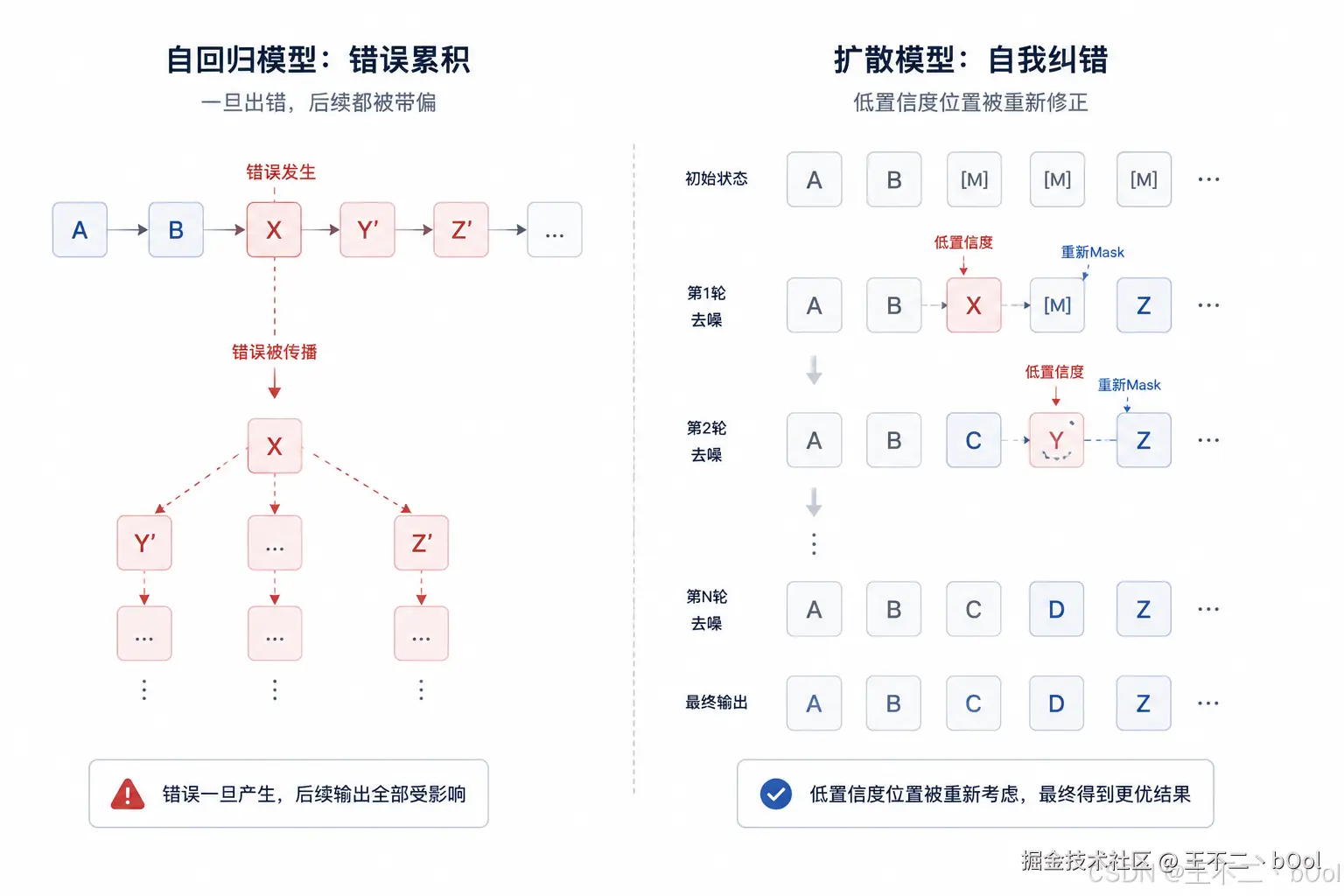
...继续直到所有 [M] 消除这个 "低置信度重掩码" 的机制给了扩散模型一个自回归模型没有的能力:自我纠错。
自回归模型,一旦在生成过程中,选取到某个低置信度 token,那么后面的 token 都会基于这个低置信度的 token 继续生成。错误会累积。扩散模型不一样,在每一轮降噪的过程中,低置信度 token 会被重新掩盖回 [M],优先保留高置信度的 token。等到下一轮的时候,基于双向注意力机制通盘考虑后,再次尝试修改这个位置的 token。
就像是做选词填空,自回归上来就从第一题开始按顺序作答,一旦第一题选错,后续题目都会基于错误答案继续推导,偏差不断累积。而扩散模型不拘泥于做题顺序,先把有把握的空填好,再回头攻克拿不准的位置,大幅降低了错误传导的概率。这套答题思路想必大家都深有体会😏。
训练
训练过程跟 BERT 的掩码语言模型(MLM)很像,但有一个关键区别。
BERT 训练时,固定掩码 15% 的 token,让模型预测。文本扩散模型训练时,掩码比例是随机的。每次采样一个比例 t ∈ (0, 1],然后以概率 t 独立掩码每个 token。t 可能是 0.1(只掩一点点),也可能是 0.9(几乎全掩了),也可能是 1.0(全部掩掉)。
之所以采用随机比例,是因为推理时你不知道要面对什么情况。有时候只要补几个字(t 小),有时候要从头生成一段话(t 大)。模型必须保证在所有掩码程度下都能工作。
因为掩码比例 t 是随机的,所以需要考虑不同掩码比例下的样本情况。例如一轮训练恰好 t=0.1,只掩了 10% 的token,那这一轮参与损失计算的 token 很少,产生的梯度信号就很弱,如果不去管它,低掩码比例的训练样本就会被忽略掉。
为了解决这个问题,会在损失函数里加一个 1/t 的权重。t 越小(掩得少),权重就越大,把 "信号弱" 的样本损失提起来。如果t比较大(掩码多),那么相对权重就会小一点,让这类样本的损失占比得到一定的平衡(因为掩掉的token多,所以此类样本本身token叠加的损失就挺大,乘一个小权重反而平衡了)。损失函数如下:
L(θ)=−Et,xtt1∑i1{xi 被掩码}logpθ(x0,i∣xt)
其中, 1{xi 被掩码} 是指示函数,被掩码的位置是 1,没被掩的位置是 0,意思就是只对被掩的位置算损失。 logpθ(x0,i∣xt) 是指从掩掉的 token xt 预测出正常的 token 的概率,概率越高,损失越小,模型就越准。
扩散模型的这种随机掩码还带来了一个好处,数据利用效率高 。同样一个样本,掩 10% 是一个训练样本,掩 50% 是另一个,掩 90% 又是一个。一条数据被随机掩码 "变" 出了很多不同版本,天然就有数据增强。
中国人民大学高瓴人工智能学院(GSAI)与蚂蚁集团联合研发的 LLaDA-8B 就是典型案例。该模型仅使用 2.3 万亿 token 的训练数据,综合性能便追平了 Meta 同量级的 LLaMA3-8B,而后者的训练数据量达到 15 万亿 token,二者相差 6 倍以上。
绕不开的工程问题:流式输出和停止机制
先说流式输出。扩散模型不支持 token-by-token 的流式,因为生成过程不是从左至右的,无法流式输出。但是可以通过 block-by-block 的方式块状流式输出。以 block 为单位依次生成,block 内部并行去噪,block 之间串行拼接。
跟自回归的逻辑几乎一样,只不过自回归是逐 token 串行,这里是逐 block 串行。第一个 block 根据 prompt 做迭代去噪,完成后锁定;第二个 block 把 prompt 加上第一个 block 的输出作为前缀,再做迭代去噪;以此类推。block 内部用双向注意力,token 可以"看到"同 block 内左右邻居,所以有自回归没有的纠错能力。
流式输出这一块很多开发商的做法是一样的,比如 LLaDA 和 DiffusionGemma 都是采用上面的方式。但是关于停止机制,各家的做法就有一定出入了。
LLaDA 的做法是"一刀切",推理前必须设定 gen_length,模型就只生成这么多位置。比如设了 256,那从头到尾就是 256 个位置,跑完整轮去噪再找 EOS 在哪。如果回答只需要 30 个 token,剩下 226 个位置全是 padding。gen_length 一旦设定就是天花板,不会多也不会少。
DiffusionGemma 不一样。它的源码里有一个关键变量 canvas_length,固定为 256。生成时,先算需要几个 canvas(ceil(max_new_tokens / canvas_length)),然后逐个 canvas 做去噪。每做完一个 canvas,就检查有没有出现 EOS。找到了,EOS 之后的 token 替换成 padding,生成结束;没找到,就再开一个 canvas 继续做。
DiffusionGemma 的停止机制看起来更高明一点,是真正的动态扩展。DiffusionGemma 不需要提前赌 "输出到底多长",它一个 canvas 一个 canvas 地往后走,碰到 EOS 就收工,跟自回归 "碰到 EOS 就停" 的逻辑只有颗粒度的区别,没有本质的区别。
| 模型 | 停止方式 | 最小浪费单位 |
|---|---|---|
| 自回归 | 逐 token 检查 EOS,碰到就停 | 0(精确停止) |
| DiffusionGemma | 逐 canvas 检查 EOS,一个 canvas 内全做完再判断 | 1 个 canvas(256 token) |
| LLaDA | 预设 gen_length,全部做完再找 EOS | gen_length - len(有效输出) |
扩散模型的其他特点
快,快,快,真的快 :扩散模型的推理速度要比自回归的快很多,毕竟是并行计算的,不同于自回归的串行执行。这里有一个在线体验地址,大家可以自己尝试下,确实是不一样的体验(chat.inceptionlabs.ai/ 非 DiffusionGemma 模型,但可以用来感受下扩散模型的生成速度)。
同样生成1000字的小说,自回归模型和扩散模型的速度差距一目了然。虽然其中也会有一些参数量和算力的差距干扰,但是从下面的图中的效果可以看出,两种模型的生成速度确实不在一个量级。


反转推理: LLaDA 论文里有个实验,给出一句古诗,让模型生成它的前一句。比如给出 "不拘一格降人才",问上一句是什么。自回归模型因为从左到右的生成惯性,做 "往前推" 这种反向任务表现比较差,扩散模型因为没有方向性约束,正向反向一视同仁,在反转诗歌任务上超过了 GPT-4o。
长逻辑推理是硬伤:GPQA(研究生级别科学推理)和 BIG-Bench Extra Hard 上,扩散模型成绩明显低于同参数量的自回归模型。原因也直白,全局并行优化不保证因果推理链的完整性。数学证明需要 A 推 B 推 C,但扩散模型可能在某一轮同时把 A、B、C 都预测了,跳过了中间的推理步骤。
扩散 vs 自回归:总结对比
| 维度 | 自回归模型 | 扩散模型 |
|---|---|---|
| 生成方式 | 从左到右,一次一个 token | 全局并行,迭代精炼 |
| 注意力 | 因果掩码,只看左边 | 双向,同时看左右 |
| 流式输出 | 原生支持(token 级) | block 级流式,单 block 内不可流式 |
| 停止机制 | 逐 token 检查 EOS | DiffusionGemma:逐 canvas 动态扩展(256 token 粒度);LLaDA:预设 gen_length 一刀切 |
| 推理速度 | 受限于逐 token 串行 | 并行生成,单请求快 |
| 自我纠错 | 无,错误累积 | 有,后续轮次可修正 |
| 长逻辑推理 | 强 | BBEH 明显落后(差 17 个百分点);GPQA 差距小 |
| 反转/非线性任务 | 受从左到右限制 | 天然适合 |
| 数据效率 | 需要大量数据 | 掩码即增强,数据效率高 |
| 高并发吞吐 | 成熟优化 | 单请求快但高 QPS 优势小 |
| 生态成熟度 | vLLM/llama.cpp 等完善 | 刚起步 |
谈谈我的看法:扩散文本模型的前景
DiffusionGemma 不是一个"干翻 XXX" 的模型。Google 自己也说了,整体质量不如标准 Gemma 4。
但是这个模型证明了一件事,文本扩散模型不是玩具。从 2024 年 MDLM 的理论奠基,到 2025 年 LLaDA 首次在大规模上追平自回归模型,再到 2026 年 Google 把这条路线放进 Gemma 家族,三年时间,扩散文本模型从学术论文走到了可用的开源产品。
它目前的短板是结构性的,没法优雅地停止,没法流式输出,长推理链薄弱。这些都不是调参能解决的,需要全新的架构变化或者架构调整。
但它的长项也是结构性的,并行生成速度快,双向注意力天然能纠错,非线性任务天然适合。这些能力同样不是工程优化就能赋予自回归模型的。
将来两种设计思路的模型大概率会长期共存,各自有各自的地盘。代码补全、工具调用、固定长度生成,扩散模型有机会翻盘。聊天助手、长链条推理、自回归模型大概率还是得加冕。