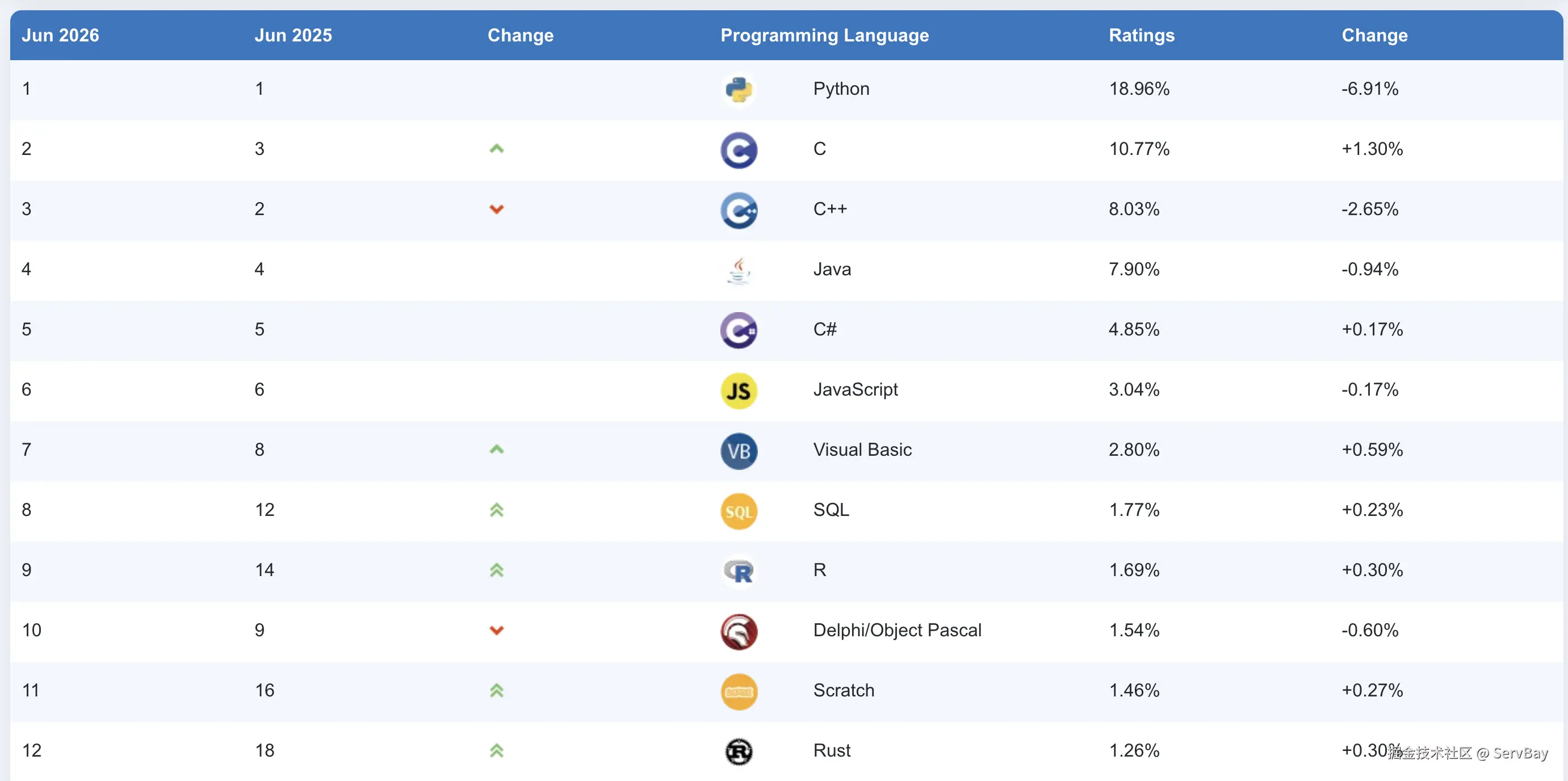
Rust可以说是进入了主流系统编程核心位置,在6月份,Rust 首次进入 TIOBE 编程语言排行榜全球前 12 名 。
Rust 后端开发对系统性能和内存安全有着很高的标准。审查一段代码的细节,就能反映出开发者的经验沉淀。初级工程师常为了快速通过编译器的所有权检查而妥协,高级工程师则更倾向于利用类型系统和内存管理特性,写出地道的 Rust(Idiomatic Rust)代码。

本文提炼了 8 种高频率使用的 Rust 编程模式。这些模式能切实减少系统开销,降低业务逻辑出错的概率。
内存与性能优化策略
在处理高并发网络请求时,不当的数据拷贝会急剧增加垃圾回收或堆内存分配的压力。做好 Rust 性能优化,第一步就是审视数据的传递方式。
少用无脑克隆,学会借用与共享
为了避开生命周期报错,初级写法常在多线程闭包中使用 .clone() 复制字符串。遇到大量并发请求时,这种做法会引发频繁的堆内存分配。
通过引入共享指针或借用机制,可以大幅度降低内存分配压力。
常规写法
rust
use std::thread;
fn process_configs(configs: Vec<String>) {
for cfg in configs {
let cfg_clone = cfg.clone();
thread::spawn(move || {
println!("Processing config: {}", cfg_clone);
});
}
}建议写法
rust
use std::sync::Arc;
use std::thread;
fn process_configs(configs: Vec<String>) {
let shared_configs: Vec<Arc<str>> = configs
.into_iter()
.map(Arc::<str>::from)
.collect();
for cfg in shared_configs {
thread::spawn(move || {
println!("Processing config: {}", cfg);
});
}
}将 String 转换为 Arc<str> 后,多个线程可以共享同一块底层文本数据。除了增加极少的引用计数开销外,整体堆内存分配次数锐减。
提升函数参数的宽容度
设计通用函数时,强制要求传入 String 或 &Vec<T> 会让调用方感到僵硬,迫使外部代码进行多余的类型转换。合理的做法是借助切片或特征(Trait)来放宽参数约束。
常规写法
rust
fn read_config_file(path: &String) {
// 只能接收绑定了 String 类型的引用
}建议写法
rust
use std::path::Path;
fn read_config_file(path: impl AsRef<Path>) {
let actual_path = path.as_ref();
// 可以无缝接收 &str, String, Path, PathBuf 等多种类型
}这种模式减少了调用方的心理负担。接口变得更具弹性,同时没有引入任何运行时性能损耗。
健壮的类型系统设计
编译器不仅能防范内存泄漏,还能被用来防御业务逻辑漏洞。初级与高级 Rust 开发者对比中,最明显的一点就是对类型系统(Type System)的利用深度。
引入新类型模式防范传参错误
过度使用基础类型(Primitive Obsession)是常见的代码坏味道。例如把所有的业务主键都定义为 u64,极易在函数调用时将用户 ID 与商品 ID 填反。
建议写法
rust
pub struct UserId(pub u64);
pub struct ProductId(pub u64);
fn create_order(user: UserId, product: ProductId) {
// 业务逻辑
}新类型模式(Newtype Pattern)在编译期具有零成本抽象的特性。运行时的内存表现完全等同于一个普通的 u64,却能在编译阶段彻底阻绝参数错位的问题。
状态机模式编码业务规则
带有复杂流转状态的业务对象(如订单、文章审核)如果使用多个布尔值和 Option 来记录状态,代码中会堆积大量运行时判断。Rust 状态机模式(Typestate Pattern)提倡将状态编码进类型本身。
建议写法
rust
struct DraftPost { content: String }
struct PublishedPost { content: String, url: String }
impl DraftPost {
fn publish(self, url: String) -> PublishedPost {
PublishedPost {
content: self.content,
url,
}
}
}旧状态实例在调用 publish 后被消耗(所有权转移),返回新状态实例。开发者无法对已发布的文章重复执行发布操作,非法状态在编译层面被彻底消除。
API 工程学与扩展性
优雅的 API 设计能提高团队的协同效率,降低代码库的维护成本。
扩展特征模式增强现有类型
当需要为标准库或其他第三方库的类型增加特定业务方法时,创建一堆零散的工具函数会让代码逻辑产生割裂感。利用扩展特征模式(Extension Traits)能获得流畅的链式调用体验。
建议写法
rust
pub trait StringExt {
fn to_slug(&self) -> String;
}
impl StringExt for str {
fn to_slug(&self) -> String {
self.to_lowercase().replace(" ", "-")
}
}
// 业务调用侧
let title = "Rust API Design";
let slug = title.to_slug();阅读顺序从左至右自然顺畅,代码结构更加内聚。
建造者模式构建复杂对象
当结构体包含大量具有默认值的配置项时,直接使用 new 方法会暴露出一个极其臃肿的参数列表。通过建造者模式可以按需配置属性。
建议写法
rust
pub struct DbClient {
host: String,
port: u16,
timeout_ms: u64,
}
pub struct DbClientBuilder {
host: String,
port: u16,
timeout_ms: Option<u64>,
}
impl DbClientBuilder {
pub fn timeout(mut self, ms: u64) -> Self {
self.timeout_ms = Some(ms);
self
}
pub fn build(self) -> DbClient {
DbClient {
host: self.host,
port: self.port,
timeout_ms: self.timeout_ms.unwrap_or(3000),
}
}
}未来业务需要增加诸如连接池大小等配置项时,旧有的构建逻辑依然能够正常编译,具备极强的向前兼容性。
错误与非内存资源管理
系统工程中,除了内存外,网络连接、文件句柄和错误信号的处理同样考验开发者的功底。
采用结构化的错误处理机制
频繁在业务分支中通过 format! 拼接字符串作为错误反馈,不仅会白白消耗 CPU 时钟周期,也不利于运维系统提取监控指标。Rust 错误处理最佳实践推荐使用专用的枚举类型。
建议写法
rust
use thiserror::Error;
#[derive(Error, Debug)]
pub enum AuthError {
#[error("Database failure: {0}")]
Database(#[from] std::io::Error),
#[error("Token expired at {0}")]
TokenExpired(u64),
}
fn verify_token() -> Result<(), AuthError> {
// 使用 ? 操作符优雅向外冒泡错误
Ok(())
}错误变为了清晰的结构化数据。只有在最终写入日志时才会发生字符串序列化操作,在系统的热点路径上省去了不必要的性能开销。
借助 RAII 实现资源自动回收
业务代码经常会遇到提早返回(Early Return)的情景。如果依靠手动清理临时目录或释放数据库锁,极易引发遗漏。Rust RAII 资源管理的核心在于利用 Drop 特征。
建议写法
rust
use std::fs;
use std::path::PathBuf;
struct TempDir(PathBuf);
impl TempDir {
fn new(path: PathBuf) -> Self {
fs::create_dir_all(&path).unwrap();
TempDir(path)
}
}
impl Drop for TempDir {
fn drop(&mut self) {
let _ = fs::remove_dir_all(&self.0);
}
}无论后续的业务代码发生 Panic 还是正常退出,当 TempDir 实例脱离作用域时,目录清理逻辑必定会严格执行。这种机制规避了几乎所有的非内存资源泄露问题。
高效构建 Rust 本地开发环境
为避开繁琐的底层环境搭建,开发者可以使用本地 Web 开发环境管理工具。针对 Rust 后端开发需求,ServBay 支持一键安装 Rust 环境。
配合其内置的各类数据库与网络服务组件,开发者无需反复排查环境变量冲突或库文件缺失问题,真正做到开箱即用。
依托自动化工具扫清前置环境障碍后,研发团队便能将工作重心完全转移到业务架构规划与深度的 Rust 代码优化上。
结语
高阶 Rust 工程师与初级开发者的分水岭,并不在于掌握了多少奇技淫巧,而在于对底层内存分配的克制以及对类型系统的深度发掘。上文探讨的 8 个编程模式,本质上都是将防御性审查的压力转移给编译器。
在日常的业务迭代中,刻意练习这些地道的编程范式,持续审视代码中的数据拷贝操作与资源生命周期,是提升整体架构稳定性的必经之路。拥抱高效的开发与环境搭建方案,把精力倾注于更高级别的系统抽象与逻辑校验,方能真正发挥 Rust 在后端开发领域的全部潜能。