写在前面:不是每个人都想先学 Docker 和命令行
Ollama 很适合让你第一次把大模型跑在自己电脑里,Open WebUI 很适合把本地模型变成网页 AI 助手。
但对很多普通用户来说,还有一个更直接的需求:
text
我不想先学 Docker;
我不想打开终端敲命令;
我只想下载一个桌面应用;
像打开 ChatGPT 一样打开它;
模型尽量跑在我自己的电脑里。Jan 的价值就在这里。
它的官方定位很直白:Jan 是一个开源的 ChatGPT 替代品,可以 100% 离线运行在你的电脑上。官网也强调可以运行本地开源模型,或者连接 GPT、Claude 等云端模型。
换成人话:
Jan 想把"本地大模型"做成普通人能安装、能打开、能直接聊天的桌面软件。
这个立意很强,因为它不是让读者感觉"我又学了一个框架",而是让读者感觉:
text
我也能拥有一个真正属于自己电脑的 AI 助手。截至 2026-06-15,公开页面可见的项目信息大致如下:
| 指标 | 数据 |
|---|---|
| GitHub Star | 约 40k+ |
| Fork | 约 2.5k+ |
| 主要语言 | TypeScript |
| 核心定位 | Open-source ChatGPT alternative |
| 本地服务 | OpenAI-compatible API at localhost:1337 |
| 关键能力 | 本地模型、云端模型、自定义助手、MCP、隐私优先 |
一句话总结:
如果 Ollama 是"把大模型装进电脑",Jan 更像是"把本地 AI 做成一个普通人能直接打开的桌面应用"。
本文实战口径
这篇不写成模型评测,也不写成桌面软件介绍,而是按新手最关心的路径来:
| 阶段 | 要解决的问题 |
|---|---|
| 理解 | Jan 和 Ollama、Open WebUI 的区别 |
| 安装 | Windows / macOS / Linux 怎么开始 |
| 模型 | 怎么下载和运行本地模型 |
| 聊天 | 怎么像 ChatGPT 一样使用本地 AI |
| API | 怎么把 Jan 当成本地 OpenAI-compatible 服务 |
| 扩展 | 怎么连接云端模型和 MCP 工具 |
| 边界 | 离线、本地、隐私分别意味着什么 |
目标很简单:
text
让一个不熟悉命令行的人,也能在自己的电脑上跑起一个 AI 助手。一、Jan 到底解决什么问题
很多本地 AI 工具默认用户是开发者。
它们会让你接触:
text
命令行;
模型路径;
Docker;
端口;
环境变量;
API 调用;
GPU / CPU 推理参数。这些对开发者没问题,但对普通用户来说门槛很高。
Jan 试图把这些复杂度封装成桌面应用。
你可以把它理解成:
text
Jan = 桌面 ChatGPT 界面 + 本地模型运行 + 云端模型连接 + 本地 API + 助手管理1.1 它和 Ollama 有什么区别
| 对比项 | Ollama | Jan |
|---|---|---|
| 主要入口 | CLI / 本地 API | 桌面应用 |
| 目标体验 | 把模型跑起来 | 把 AI 用起来 |
| 适合人群 | 开发者、新手进阶 | 普通用户、隐私敏感用户、轻量开发者 |
| 图形界面 | 需要接 Open WebUI 等 | 自带桌面聊天界面 |
| API | localhost:11434 |
OpenAI-compatible API,常见为 localhost:1337 |
两者不是互相替代。
更准确的理解是:
text
Ollama 更像本地模型运行器;
Jan 更像本地 AI 桌面工作站。1.2 它和 Open WebUI 有什么区别
Open WebUI 更适合:
text
浏览器访问;
团队共享;
Docker 部署;
连接多模型;
做私有 ChatGPT 网页入口。Jan 更适合:
text
个人电脑;
桌面应用;
离线使用;
轻量本地模型体验;
不想先配置 Docker 的用户。如果你想给自己电脑装一个 AI 助手,Jan 很顺手。
如果你想给一个小团队提供网页入口,Open WebUI 更合适。
二、本地安装:先把桌面端跑起来
打开官网:
text
https://jan.ai/选择对应系统下载安装包。
常见平台包括:
text
Windows;
macOS;
Linux。下载安装完成后,像普通桌面软件一样打开。
2.1 新手第一次打开要看什么
先不要急着研究所有设置。
重点看 3 个地方:
text
模型列表:能不能下载或选择本地模型;
聊天窗口:能不能像 ChatGPT 一样输入问题;
设置页面:是否能看到本地 API、模型路径、云端 Provider。第一次使用建议选小模型。
比如:
text
3B 到 8B 量级模型;
Qwen、Gemma、Llama 等常见开源模型;
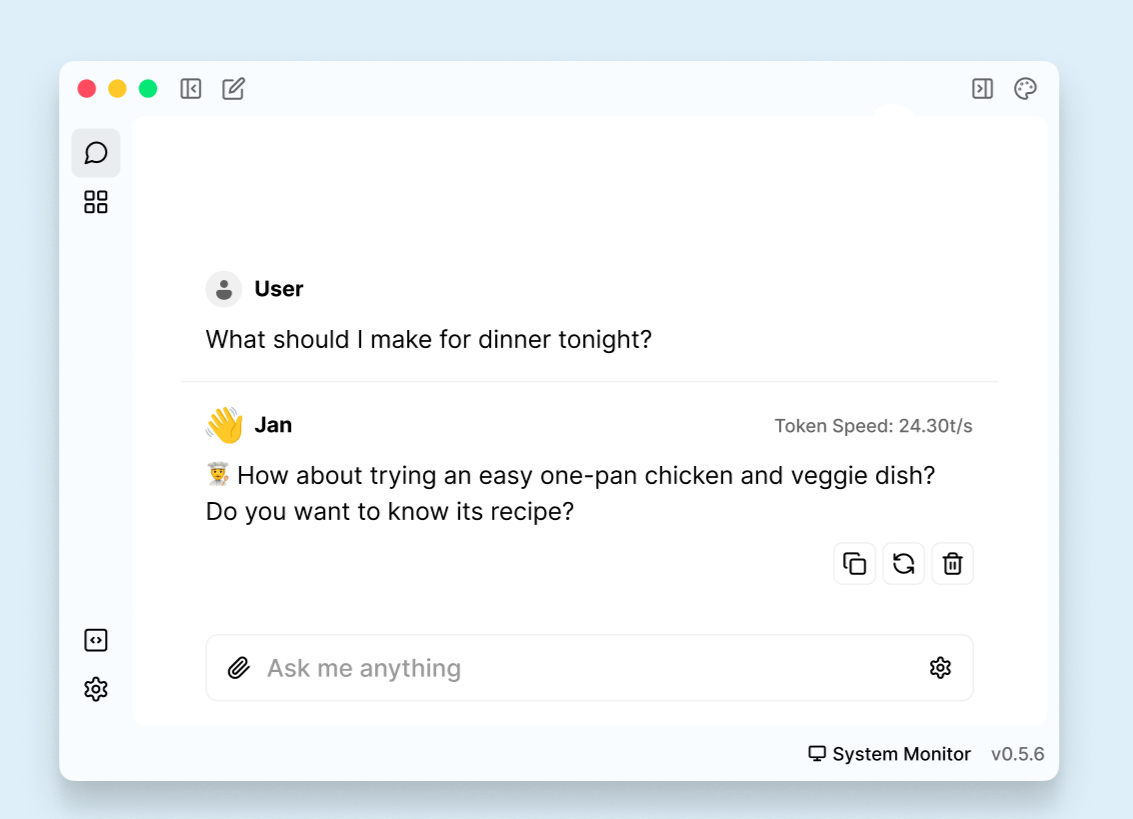
不要一上来就追求 70B。三、第一个任务:下载一个本地模型并聊天
Jan 的核心体验是:你可以在应用里下载和运行本地模型。
建议第一个测试问题不要太复杂:
text
用三句话解释什么是本地大模型。如果模型能正常回答,说明你已经完成了:
text
桌面应用打开;
本地模型加载;
本地推理运行;
聊天界面可用。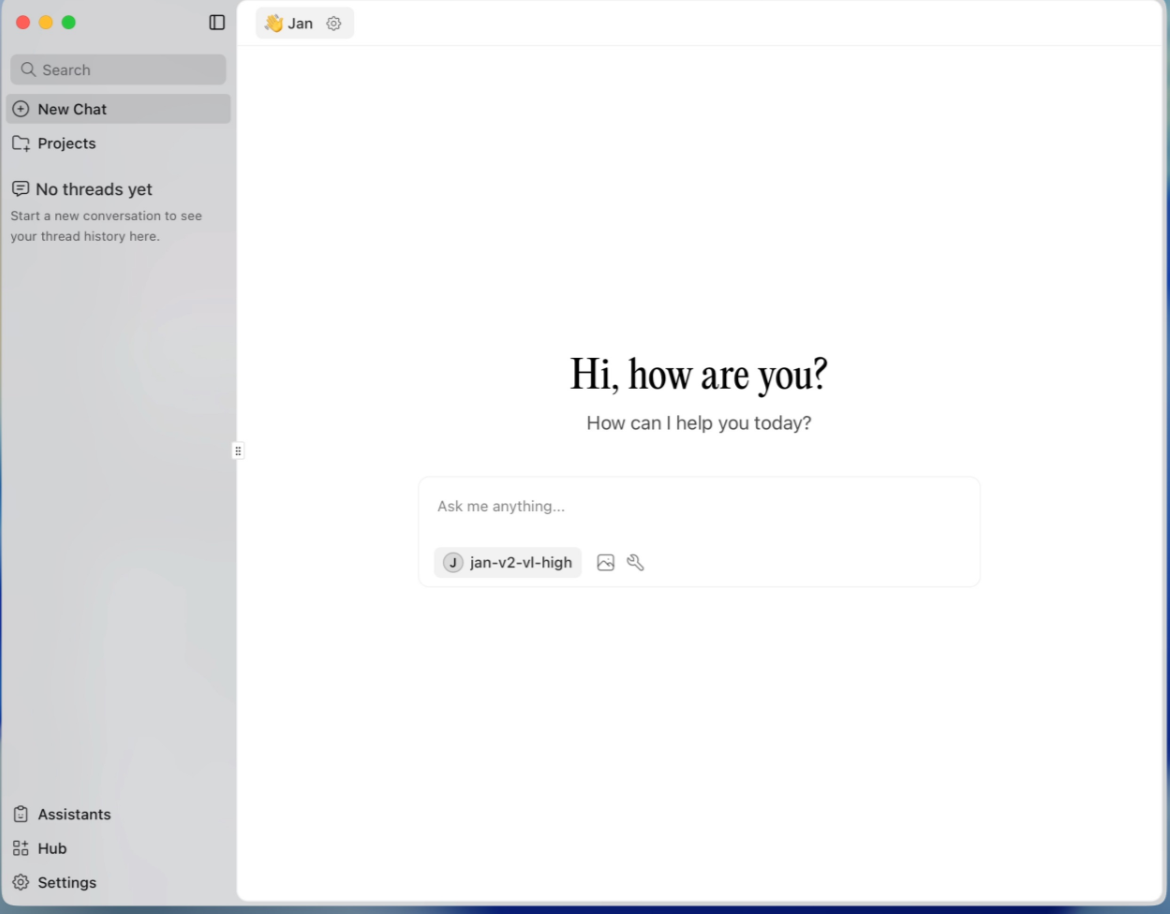
3.1 电脑配置怎么选模型
粗略建议:
| 机器情况 | 建议 |
|---|---|
| 普通办公本,16GB 内存 | 先试 3B / 4B 小模型 |
| 32GB 内存或有入门显卡 | 可以试 7B / 8B |
| 高端显卡或工作站 | 再考虑 14B 以上 |
| 不确定配置 | 先从小模型开始,不要硬跑大模型 |
本地 AI 的第一目标不是"立刻最强",而是:
text
先跑起来;
先能用;
先建立直觉;
再慢慢换更强模型。四、把 Jan 当成本地 API 服务
Jan 不只是一个聊天界面。
它还可以提供 OpenAI-compatible API,常见本地地址是:
text
http://localhost:1337这意味着其他应用可以把 Jan 当成本地模型服务调用。
例如:
text
你自己的 Python 脚本;
本地知识库工具;
自动化工作流;
某些支持 OpenAI-compatible API 的客户端。这一步很关键。
因为 Jan 从"聊天软件"变成了"本地 AI 能力入口"。
4.1 OpenAI-compatible 的意义
很多 AI 应用默认支持 OpenAI API 格式。
如果 Jan 提供兼容接口,你就可以把:
text
base_url改成本地 Jan 服务地址。
这样上层应用不用大改。
五、连接云端模型:不是只能离线
Jan 的卖点是本地和隐私,但它不是只能用本地模型。
官方说明里也提到可以连接 OpenAI、Anthropic、Mistral、Groq、MiniMax 等云端模型。
这对真实使用很重要。
因为本地小模型适合:
text
日常问答;
简单总结;
隐私资料处理;
离线环境;
低成本学习。云端强模型适合:
text
复杂推理;
长文写作;
高质量代码;
多轮复杂任务;
对准确率要求更高的场景。所以一个合理策略是:
text
隐私内容走本地模型;
高难任务走云端强模型;
同一个桌面应用里统一管理。六、MCP:让桌面 AI 不只会聊天
Jan 支持 Model Context Protocol,也就是 MCP。
你可以把 MCP 理解成:
text
给 AI 接外部工具和数据源的标准接口。有了 MCP,AI 不只是回答文本,还可能连接:
text
本地文件;
数据库;
GitHub;
搜索;
任务系统;
自定义工具。对 Jan 来说,这意味着它有机会从"桌面聊天软件"进一步变成"桌面 AI 工作台"。
不过新手阶段不要一上来就装一堆 MCP。
建议路径:
text
先跑本地模型;
再测试本地 API;
最后只接一个低风险 MCP,比如只读文件或只读 GitHub。七、常见问题和排查
| 问题 | 可能原因 | 处理方式 |
|---|---|---|
| 模型下载慢 | 网络或镜像问题 | 换网络,先选小模型 |
| 回答很慢 | 模型太大或 CPU 推理 | 换小模型,检查 GPU |
| 应用启动失败 | 系统权限或安装包异常 | 重装,查看官方 issue |
| API 调不通 | 本地服务未启动或端口不对 | 检查 localhost:1337 |
| 本地模型效果一般 | 模型太小或任务太难 | 换更强模型或接云端模型 |
| 风扇狂转 | 本地推理负载高 | 降低模型大小,避免长时间高负载 |
八、安全和隐私边界
Jan 强调隐私和本地运行,但你仍然要分清楚几件事:
text
本地模型回答:数据主要留在本机;
云端模型调用:数据会发给对应模型服务商;
MCP 工具调用:取决于工具连接了什么系统;
本地 API:如果暴露到局域网或公网,也需要访问控制。建议:
text
处理敏感资料时确认当前使用的是本地模型;
不要把 API Key 截图发出去;
不要把本地 API 直接暴露到公网;
MCP 工具先从只读权限开始;
涉及公司资料时,先看内部合规要求。九、适合落地的 5 类场景
9.1 个人离线 AI 助手
适合写作、总结、翻译、学习、简单代码解释。
9.2 隐私资料处理
适合不想把草稿、笔记、文档片段发到云端的用户。
9.3 本地模型体验入口
适合测试不同开源模型的回答风格。
9.4 开发者本地 API
适合把 Jan 当成本地 OpenAI-compatible 服务,接自己的脚本。
9.5 AI 教学和演示
桌面应用比终端更容易让非技术同学理解。
十、最终评价
Jan 的价值不是"比所有模型都强",而是它把本地 AI 的使用门槛进一步降低了。
适合使用 Jan 的人:
text
想要桌面版 AI 助手;
想离线运行开源模型;
不想先学 Docker 和命令行;
希望本地模型和云端模型放在一个应用里;
想要一个本地 OpenAI-compatible API。不太适合:
text
需要多人协作后台;
需要复杂知识库权限;
需要生产级模型服务;
需要强工作流编排;
只想部署给整个团队网页访问。我的建议:
text
个人使用:Jan 很适合作为第一站;
团队共享:Open WebUI 更合适;
复杂业务:再看 Dify、RAGFlow、n8n;
高并发推理:再看 vLLM。一句话总结:
Jan 把"本地大模型"从命令行和服务器里拉回了普通人的桌面。它最适合做你的第一台个人 AI 工作站。