文章目录
引言
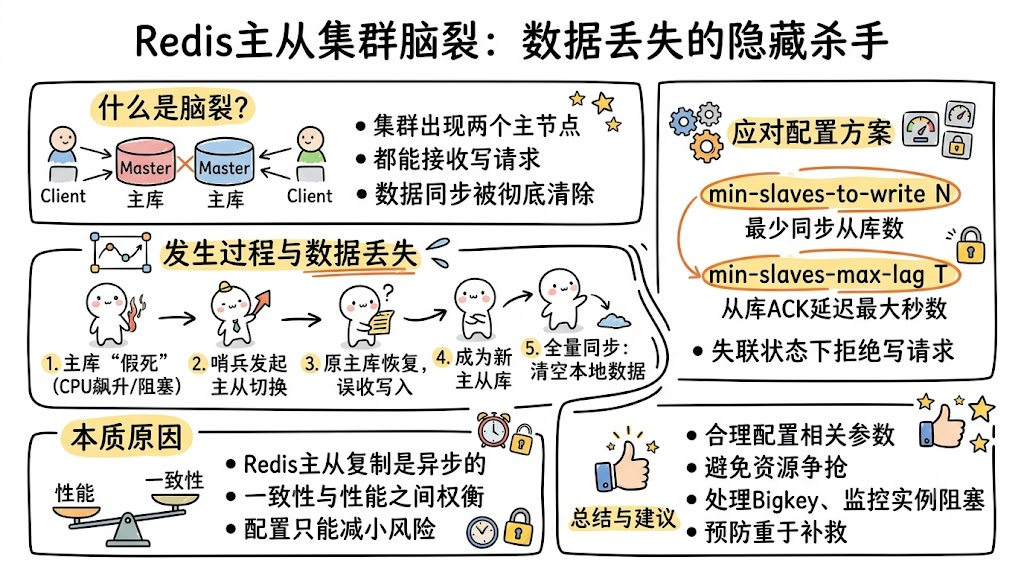
在Redis主从集群的运维过程中,有一类问题特别隐蔽------客户端写入的数据莫名其妙地丢失了。排查主从复制进度,发现offset完全一致;检查实例状态,一切看似正常。这种"幽灵般"的数据丢失,往往指向一个令人头疼的问题:脑裂(Split-Brain)。
脑裂的本质是主从集群中同时出现了两个主节点,它们都能接收写请求。当哨兵完成切换后,原主库被降级为从库并执行全量同步,切换期间写入原主库的数据就会被彻底清除。
脑裂的发生过程
从一次真实故障说起
假设我们有一个1主5从3哨兵的集群,某天发现客户端写入的部分数据丢失了。按照常规思路排查:
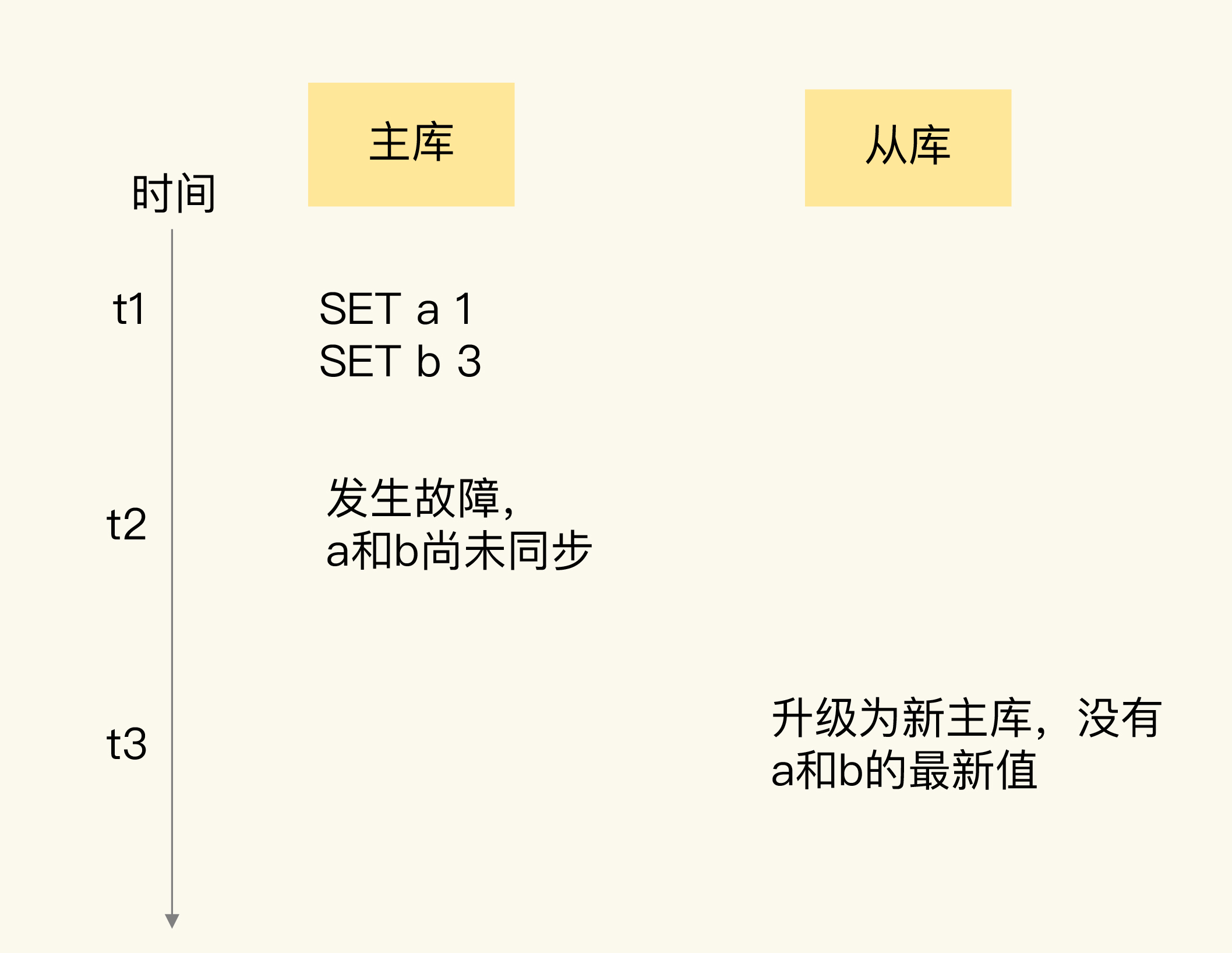
第一步:检查主从复制进度
数据丢失最常见的原因是主库故障前数据未同步到从库。我们可以对比 master_repl_offset 和 slave_repl_offset 的差值来判断。但如果发现新主库升级前的offset与原主库完全一致,说明数据同步没有问题,需要另寻原因。
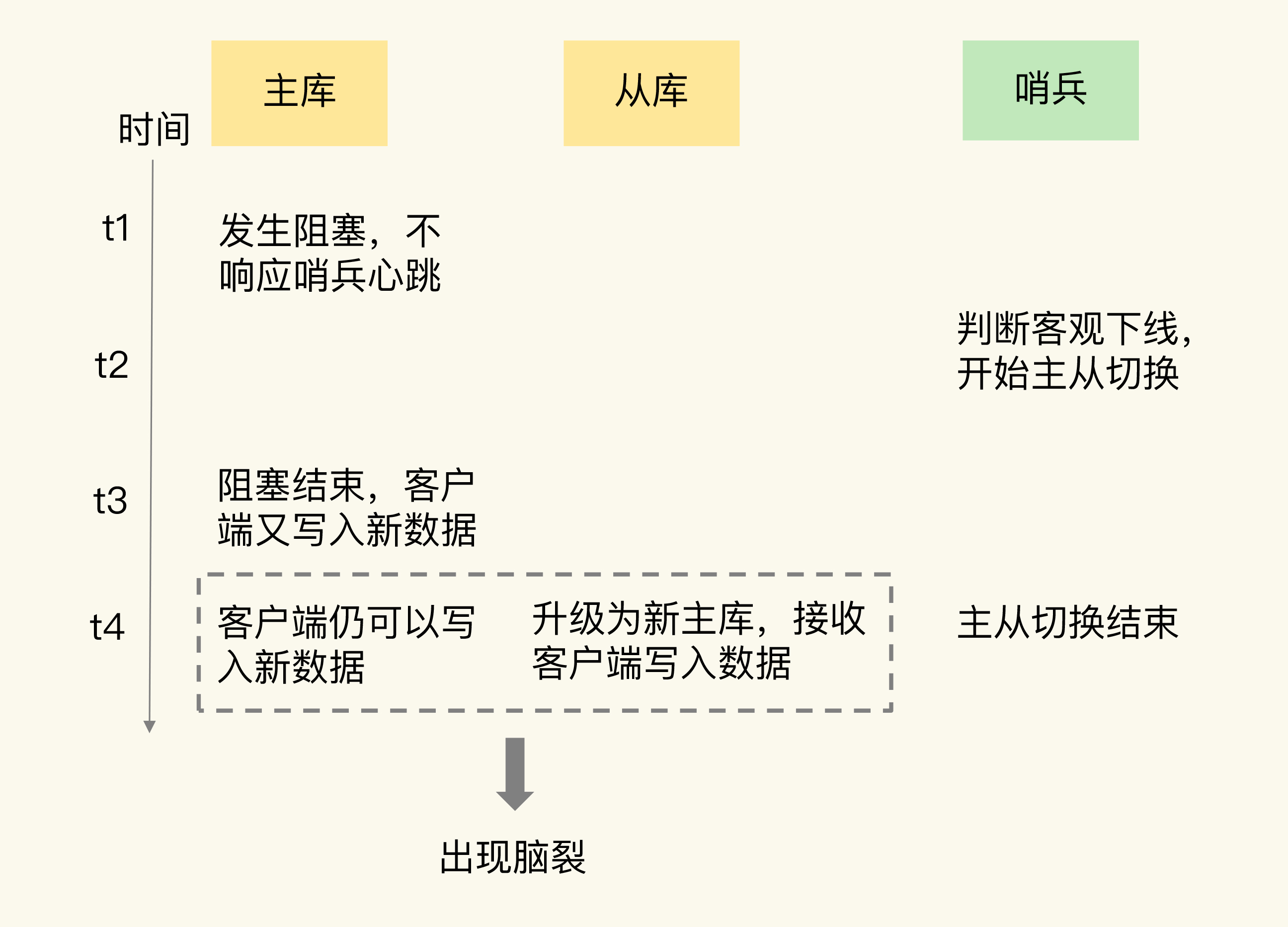
第二步:排查客户端操作日志
在客户端日志中发现,主从切换后的一段时间内,有客户端仍然在和原主库通信。这意味着集群中同时存在两个主库------脑裂已经发生。
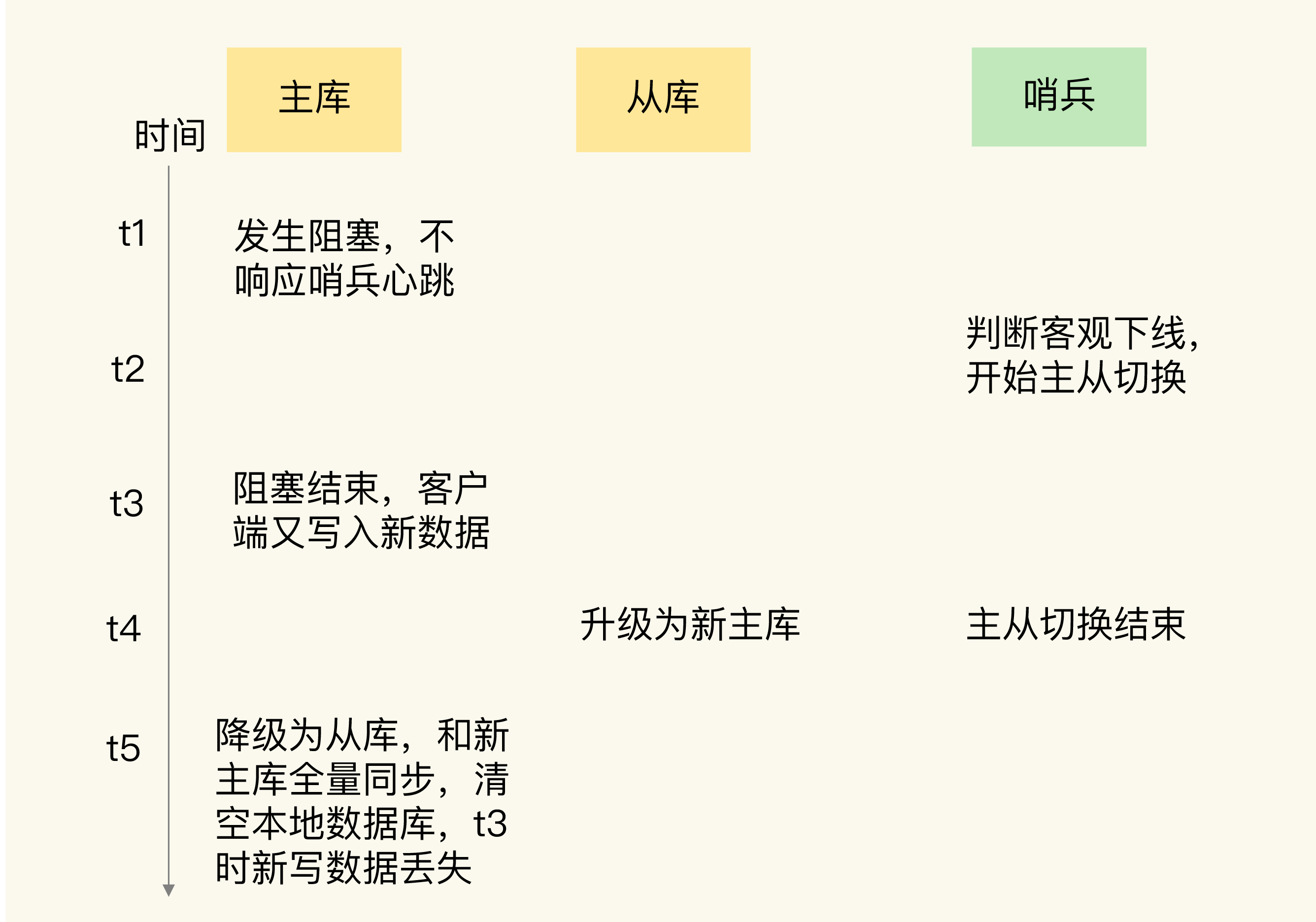
第三步:定位假故障根因
既然哨兵触发了切换,说明主库的心跳超时了。但客户端又能和原主库通信,说明主库并没有真正宕机。检查服务器监控发现,原主库所在机器的CPU利用率曾短暂飙升(被同机部署的数据采集程序占满),导致Redis无法响应哨兵心跳。CPU恢复后,原主库又开始正常服务。
脑裂导致数据丢失的机制
脑裂本身只是让两个主库同时存在,但数据丢失发生在后续的全量同步阶段:
- 原主库假故障期间,哨兵判定其客观下线,开始主从切换
- 原主库恢复后继续接收客户端写请求(此时新主库可能还未完全就绪)
- 哨兵切换完成后,让原主库执行
SLAVEOF命令,成为新主库的从库 - 全量同步的最后阶段,原主库清空本地数据,加载新主库的RDB文件
- 切换期间写入原主库的数据被彻底丢失
假故障的常见原因
导致主库"假死"的场景主要有两类:
-
资源争抢:与主库部署在同一台服务器上的其他程序临时占用大量CPU、内存或网络资源,导致Redis短时间内无法响应心跳。资源释放后主库恢复正常。
-
实例阻塞:主库自身遇到阻塞,比如处理bigkey、发生内存swap、执行耗时的AOF重写等。阻塞解除后恢复正常请求处理。
这两种情况的共同特点是:主库并没有真正挂掉,只是暂时"失联"。
应对脑裂的配置方案
Redis提供了两个配置项来限制主库在"失联"状态下接收请求:
bash
min-slaves-to-write 1
min-slaves-max-lag 12这两个参数的含义是:
min-slaves-to-write:主库能进行数据同步的最少从库数量min-slaves-max-lag:从库给主库发送ACK消息的最大延迟(秒)
组合使用的逻辑是:主库连接的从库中,至少有N个从库的ACK延迟不超过T秒,否则主库拒绝接收客户端写请求。
为什么这个方案有效
当原主库发生假故障时:
- 无法响应哨兵心跳
- 同样无法和从库进行正常的数据同步
- 从库的ACK消息自然会超时
min-slaves-to-write和min-slaves-max-lag的条件无法满足- 原主库自动拒绝客户端写请求
这样即使原主库从假故障中恢复,也不会接收新的写入,避免了数据丢失。
参数设置建议
假设从库有K个:
bash
# min-slaves-to-write 设置为 K/2+1(K=1时设为1)
min-slaves-to-write 3 # 假设5个从库
# min-slaves-max-lag 设置为10~20秒
min-slaves-max-lag 12
# 哨兵的 down-after-milliseconds 应小于 min-slaves-max-lag
sentinel down-after-milliseconds mymaster 10000关键原则:min-slaves-max-lag 要大于 down-after-milliseconds,这样在哨兵判定主库下线时,主库已经因为ACK超时而拒绝写入了。
方案的局限性
需要注意的是,这个方案并不能100%防止数据丢失。考虑以下场景:
min-slaves-max-lag= 15sdown-after-milliseconds= 10s- 哨兵切换耗时 = 5s
- 主库卡住时间 = 12s
主库卡住12s后恢复,此时哨兵已判定其下线但切换尚未完成(还需3s)。由于卡住时间12s < min-slaves-max-lag 15s,原主库恢复后仍可接收写请求。这3秒窗口期内的写入,在切换完成后仍会丢失。
本质原因与思考
脑裂问题的根本原因在于:Redis主从集群内部没有通过共识算法来维护数据的强一致性。不同于ZooKeeper每次写请求必须大多数节点确认才算成功,Redis的主从复制是异步的,这是性能与一致性之间的权衡。
min-slaves-to-write 和 min-slaves-max-lag 只能尽量减少数据丢失,无法完全杜绝。在对数据一致性要求极高的场景下,需要在应用层做额外的保障措施。
总结
脑裂是Redis主从集群中一个需要重点关注的问题。通过合理配置 min-slaves-to-write 和 min-slaves-max-lag,可以在大多数场景下有效预防脑裂导致的数据丢失。同时,在运维层面也要注意:避免在Redis主库所在服务器上部署资源密集型程序,及时处理bigkey,监控实例的阻塞情况。预防永远比事后补救更重要。
