
核心结论
模型剪枝不是把一些参数设成 0 这么简单,而是把训练好的模型改造成更小、更快或更省显存的部署形态。真正的收益取决于四件事:剪掉的结构是否能从计算图中删除,稀疏模式是否适合目标硬件,推理框架是否调用了对应 kernel,以及剪枝后的质量能否通过回归评估。
更准确的一句话是:
text
剪枝收益 = 可删除结构 × 稀疏模式 × 推理后端支持 × 质量回归可控原稿里"模型缩小 50-90%、推理速度提升 2-5 倍、精度损失 <1%"不能作为通用结论。某些模型、数据集和硬件上确实可能达到类似效果,但参数变少、理论 FLOPs 变少和真实端到端延迟下降是三件不同的事。非结构化稀疏如果仍然走普通 dense Conv/Linear kernel,通常不会自动加速;结构化剪枝更容易变成更小的 dense 模型,因此更容易在 CPU、移动端、NPU 和普通 GPU 后端上获得稳定收益。
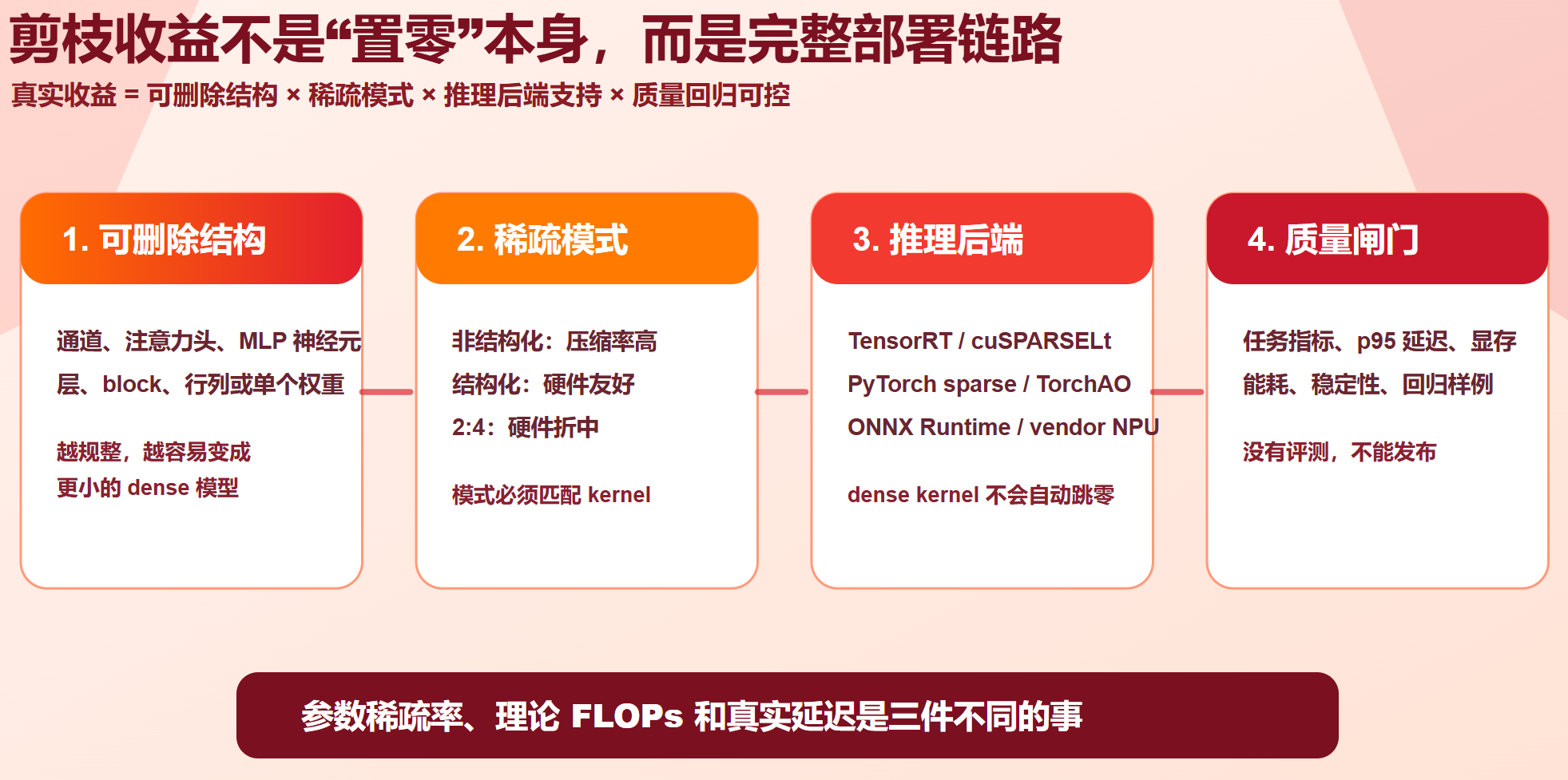
第 0 层:30 秒理解
模型像一座工厂,剪枝是在不明显影响产出的前提下关掉低价值设备。
| 方法 | 可以怎么理解 | 部署含义 |
|---|---|---|
| 非结构化剪枝 | 关掉单个螺丝级别的零件 | 压缩率高,但需要稀疏 kernel 才可能加速 |
| 结构化剪枝 | 拆掉整条产线、整组机器或整层模块 | 更容易变成小模型,硬件友好 |
| 2:4 半结构化稀疏 | 每 4 个零件固定保留 2 个 | 压缩率受限,但适合特定 GPU 稀疏加速 |
| 稀疏推理 | 运行时真的跳过被剪掉的计算 | 依赖格式、kernel、编译器和硬件 |
核心判断式:
text
如果剪枝结果仍走 dense kernel:可能只省 checkpoint,不一定省延迟
如果剪枝结果改变模型结构:更可能获得通用加速
如果稀疏模式匹配硬件:才有机会把非结构化/半结构化稀疏转成真实加速第 1 层:基础概念
1.1 为什么需要剪枝
剪枝主要解决四类部署问题:
| 问题 | 表现 | 剪枝可能带来的收益 |
|---|---|---|
| 模型太大 | checkpoint、显存、内存占用高 | 权重减少,加载和存储成本下降 |
| 推理太慢 | Conv、GEMM、attention 或 MLP 计算重 | 删除通道、头、层或使用稀疏 kernel |
| 能耗太高 | 端侧电池消耗、服务器功耗 | 降低内存访问和计算量 |
| 端侧部署困难 | CPU/NPU/移动端后端限制多 | 结构化剪枝后导出更小 dense 图 |
剪枝的本质是一个受约束优化问题:
text
在质量下降不超过阈值的前提下,最大化模型压缩、延迟下降和能耗下降1.2 四种常见稀疏形态
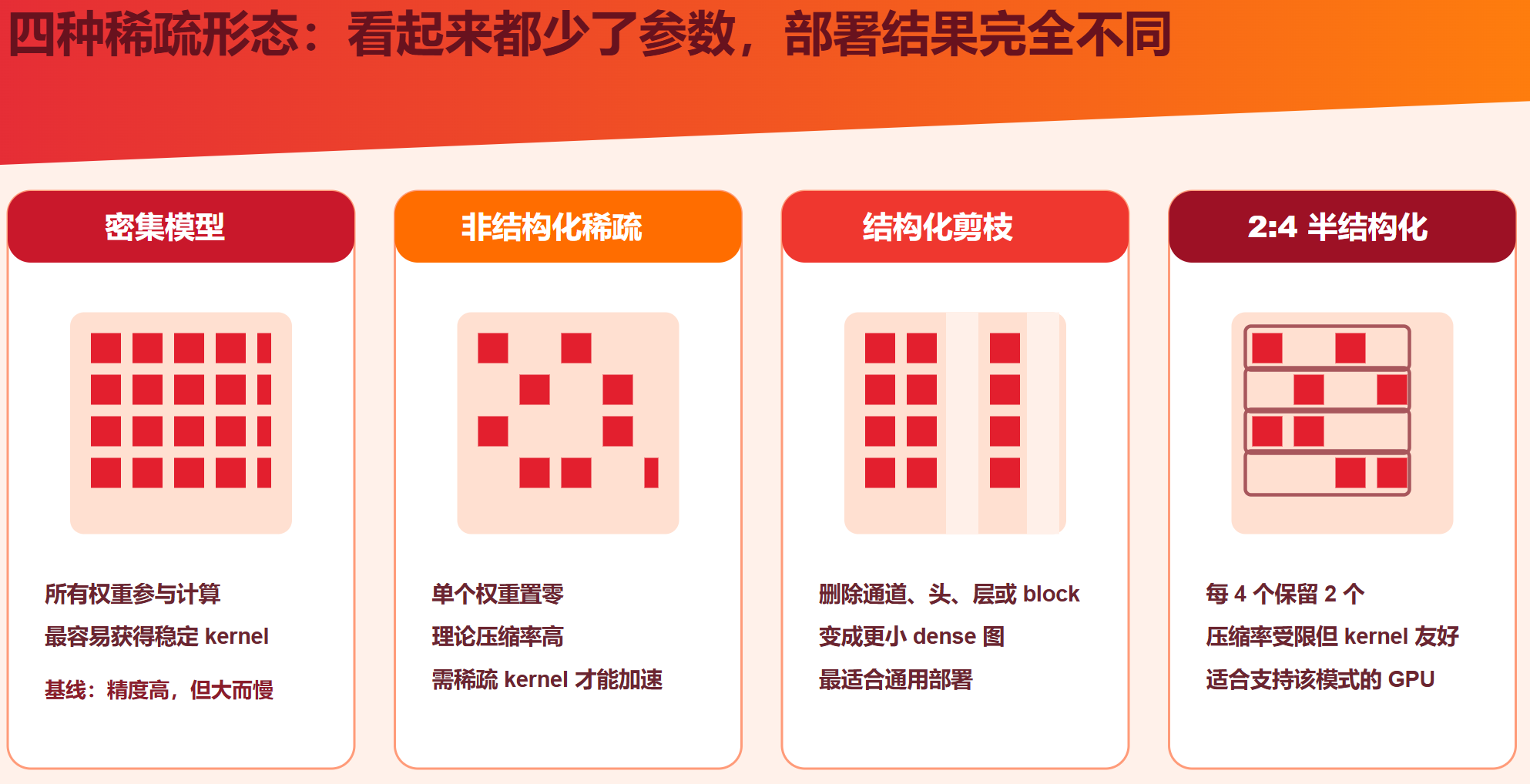
| 类型 | 剪什么 | 优点 | 风险 | 典型场景 |
|---|---|---|---|---|
| 非结构化剪枝 | 单个权重 | 最高自由度,通常压缩率高 | 不规则稀疏难加速,元数据开销高 | checkpoint 压缩、支持稀疏 kernel 的 GPU |
| 结构化剪枝 | 通道、filter、head、层、block | 生成更小 dense 模型,通用硬件友好 | 粒度粗,精度更容易受影响 | CPU、移动端、边缘设备、NPU |
| 半结构化剪枝 | 2:4、N:M、block sparse | 在压缩率和硬件友好之间折中 | 必须满足固定模式,训练和导出受约束 | NVIDIA Ampere+ GPU、部分专用加速器 |
| 动态稀疏 | 输入不同,激活或路由不同 | 计算可随样本变化 | 控制流、负载均衡和延迟稳定性复杂 | MoE、token pruning、early exit |
1.3 剪枝流程
一个可靠的剪枝流程通常是:
text
训练好模型
-> 选目标:体积、延迟、显存、能耗或吞吐
-> 选剪枝粒度:权重、通道、头、层、block、2:4
-> 用校准数据评估重要性
-> 剪枝并修复计算图
-> 微调、蒸馏或短期恢复训练
-> 导出到目标后端
-> 端到端评估质量和延迟注意最后两步非常关键。只在 Python 里看到参数为 0,不代表部署模型已经变快。
第 2 层:剪枝重要性怎么判断
2.1 幅度剪枝
幅度剪枝认为绝对值小的权重更不重要:
text
importance(w_i) = |w_i|它简单、便宜、常作为基线。Han 等人的早期剪枝工作、后续大量 CNN 和 Transformer 压缩实验都把幅度作为重要参考。但幅度只看权重本身,不直接看任务损失、激活分布和硬件约束。
2.2 激活与通道统计
结构化剪枝常看通道输出是否活跃:
text
importance(channel c) = ||activation_c|| 或 ||weight_filter_c||如果某个通道在代表性数据上长期输出很小,删除它通常更安全。问题是激活统计依赖校准数据,校准集若不覆盖真实分布,剪枝会对长尾样本造成损害。
2.3 梯度与 Taylor 准则
更贴近任务损失的做法是估计删除参数后的损失变化。对参数 w_i 做一阶近似:
text
ΔL_i ≈ |g_i · w_i|其中 g_i 是损失对权重的梯度。通道剪枝也可以用激活和激活梯度估计:
text
importance(channel c) ≈ |∂L/∂y_c · y_c|Taylor 方法比纯幅度更关注任务影响,但需要反向传播和代表性数据,成本更高。
2.4 二阶信息:OBD、OBS 到 SparseGPT
经典的 Optimal Brain Damage 和 Optimal Brain Surgeon 用 Hessian 二阶信息估计删除权重造成的损失变化。二阶方法理论上更精细,但完整 Hessian 太贵,所以实际会使用对角近似、块近似或近似逆 Hessian。
LLM 场景中的 SparseGPT 继承了这种思路:用少量校准数据和近似二阶信息,对大模型权重做一次性剪枝,并在每层内补偿误差。它说明了一点:大模型剪枝不能只按"权重小就删"理解,校准数据和误差补偿非常重要。
2.5 Movement Pruning 与训练中稀疏
Movement Pruning 不只看权重大小,而看权重在微调过程中朝向 0 还是远离 0。RigL 等动态稀疏训练方法则在训练中周期性删除低价值连接、重新生长可能有用的连接。
这类方法适合有训练预算的场景;如果只能拿到已训练 checkpoint 并且没有大规模数据,通常会优先考虑 PTQ 式的一次性剪枝、少量校准数据剪枝或短微调恢复。
第 3 层:结构化剪枝
3.1 结构化剪枝剪什么
结构化剪枝的目标是让模型结构真的变小。
| 模型 | 常见剪枝对象 | 需要同步处理 |
|---|---|---|
| CNN | filter、输出通道、stage、block | BatchNorm、残差分支、concat、depthwise/group conv |
| ViT | attention head、MLP hidden dimension、token、block | LayerNorm、残差、投影矩阵、位置编码 |
| Transformer LLM | attention head、KV head、MLP neuron、层、行列 | RoPE、GQA/MQA、残差、权重 tying、导出格式 |
| 检测/分割模型 | backbone、neck、head 通道 | FPN/PAN 多尺度连接、anchor/head shape |
结构化剪枝的难点不是"切掉一个张量维度",而是保持整张计算图一致。比如 ResNet 的一个残差 block,如果主分支剪了通道,shortcut 分支、BatchNorm 和后续卷积都必须一致;YOLO 类网络还要处理 neck 中的 concat 和多尺度 head。
3.2 通道剪枝的工程要点
通道剪枝应至少做四件事:
- 用代表性数据计算通道重要性。
- 根据全局或分层约束选择要删除的通道。
- 通过图级依赖分析同步修改相邻层。
- 导出后重新评估 shape、精度和延迟。
不建议在真实项目里使用"遍历 Conv2d 然后直接切 module.weight"的玩具代码作为结构化剪枝实现。它很容易漏掉 BatchNorm、残差、分组卷积和多分支连接。工程中更适合使用已有压缩框架、模型库内置剪枝工具,或在明确掌握模型拓扑后写专用转换脚本。
3.3 层剪枝、头剪枝与 block 剪枝
结构化剪枝不只剪通道。
| 方法 | 含义 | 优点 | 风险 |
|---|---|---|---|
| 层剪枝 | 删除整个层或 Transformer block | 延迟收益直接,图更简单 | 对深度和表示能力影响大 |
| attention head 剪枝 | 删除低价值注意力头 | 适合 Transformer | 多头之间存在冗余,但不是所有任务都稳 |
| MLP neuron 剪枝 | 删除 FFN 中间维度 | LLM/ViT 参数量大头常在 MLP | 需同步 up/down/gate 投影 |
| block 剪枝 | 删除成块权重或结构 | 更适合硬件和缓存 | 粒度粗,压缩率受限 |
对 LLM 来说,MLP 中间维度、attention heads 和层深度往往是结构化剪枝重点。剪掉后模型可以变成更小的 dense Transformer,这比不规则稀疏更容易被通用推理引擎接受。
第 4 层:非结构化剪枝与稀疏训练
4.1 非结构化剪枝的价值
非结构化剪枝的优点是自由度高,可以在较高稀疏率下保持模型质量。早期 Deep Compression 就把剪枝、量化和 Huffman 编码组合起来,大幅压缩模型存储。
但部署时要分清三种收益:
| 收益 | 是否容易获得 | 说明 |
|---|---|---|
| checkpoint 变小 | 比较容易 | 稀疏存储或压缩编码可减少文件体积 |
| 显存下降 | 取决于运行时 | 如果加载后变回 dense tensor,显存不一定下降 |
| 延迟下降 | 最难 | 必须有适合稀疏模式的 kernel 和硬件 |
4.2 迭代幅度剪枝
迭代幅度剪枝通常比一次性高比例剪枝更稳:
text
训练好的模型
-> 剪掉一小部分低幅度权重
-> 短微调恢复
-> 提高稀疏率
-> 重复直到目标稀疏率它的优势是每轮扰动较小,模型有机会恢复;代价是训练预算更高。
4.3 彩票假设
彩票假设认为,在一个随机初始化的 dense 网络中,存在某个稀疏子网络,在合适初始化下可以训练到接近原网络的效果。这个方向对理解"为什么稀疏子网络可行"很重要,但在大规模 LLM 部署中,更多时候我们面对的是已经训练好的 checkpoint,需要做 post-training pruning 或短微调恢复,而不是从头寻找中奖彩票。
4.4 动态稀疏训练
RigL 等方法让稀疏连接在训练过程中动态更新:删掉低价值连接,同时重新激活可能有用的位置。这类方法能在训练阶段节省部分计算,但需要训练框架、稀疏 kernel 和优化器支持。对于只做部署压缩的团队,结构化剪枝、2:4 稀疏和量化组合往往更直接。
第 5 层:2:4 半结构化稀疏
2:4 稀疏是一种硬件友好的稀疏模式:在指定方向上,每 4 个连续元素中保留 2 个非零值,另外 2 个为 0。
text
[a, b, c, d] -> 保留其中 2 个,例如 [a, 0, c, 0]它的意义在于:完全不规则稀疏很难让 GPU 高效执行,而固定模式的半结构化稀疏可以让硬件提前知道跳零规则。NVIDIA Ampere 架构引入 Sparse Tensor Cores 后,2:4 结构化稀疏成为 GPU 推理和训练优化中的重要路线;cuSPARSELt、TensorRT 等后端也围绕这类模式提供支持。
2:4 的优点和限制都很清楚:
| 方面 | 说明 |
|---|---|
| 优点 | 模式规则,元数据少,更容易被 Sparse Tensor Core 利用 |
| 限制 | 理论稀疏率固定在 50% 左右,不能像非结构化剪枝那样随意达到 80-90% |
| 训练要求 | 通常需要稀疏感知训练、蒸馏或恢复微调 |
| 部署要求 | 必须确认导出后的 GEMM/Conv 真的走了 2:4 sparse kernel |
PyTorch 也提供了半结构化稀疏相关能力,但这类能力的可用算子、dtype、形状和后端路径会随版本变化。工程上不能只看 API 存在,要在目标环境实测。
第 6 层:稀疏推理栈

稀疏推理要解决两个问题:怎么存,以及怎么算。
6.1 稀疏存储格式
| 格式 | 适合什么 | 风险 |
|---|---|---|
| COO | 简单坐标存储,便于构造 | 索引冗余,计算效率通常不高 |
| CSR | 按行压缩,适合稀疏矩阵乘 | 列访问不友好,动态 shape 复杂 |
| CSC | 按列压缩 | 行访问不友好 |
| BSR/Blocked | 分块稀疏,硬件和缓存更友好 | 需要块级稀疏,灵活性低 |
| 2:4/N:M | 固定局部模式 | 依赖特定 kernel 和硬件 |
非结构化稀疏在数学上可以把 MACs 降到 dense_macs × (1 - sparsity),但这只是理论上限。真实推理还要读取索引、解码元数据、处理不规则访存,并且受 batch size 和算子融合影响。
6.2 dense kernel 与 sparse kernel
如果一个 Linear 层的权重有 80% 为 0,但仍然以普通 dense GEMM 执行,那么计算单元会照常处理这些 0。只有当模型转换成稀疏张量、图编译器保留稀疏算子、运行时调用稀疏 kernel,并且硬件适合这种稀疏模式时,才可能获得真实延迟收益。
因此剪枝报告必须写清楚:
| 必填项 | 为什么重要 |
|---|---|
| 稀疏率 | 说明参数层面的压缩程度 |
| 稀疏模式 | 非结构化、block、2:4、通道等决定 kernel 可用性 |
| 导出后端 | PyTorch、ONNX Runtime、TensorRT、cuSPARSELt、ExecuTorch、NPU SDK 等 |
| kernel path | 确认是否走了 sparse kernel |
| 端到端延迟 | 反映真实用户体验 |
第 7 层:大模型剪枝的新重点
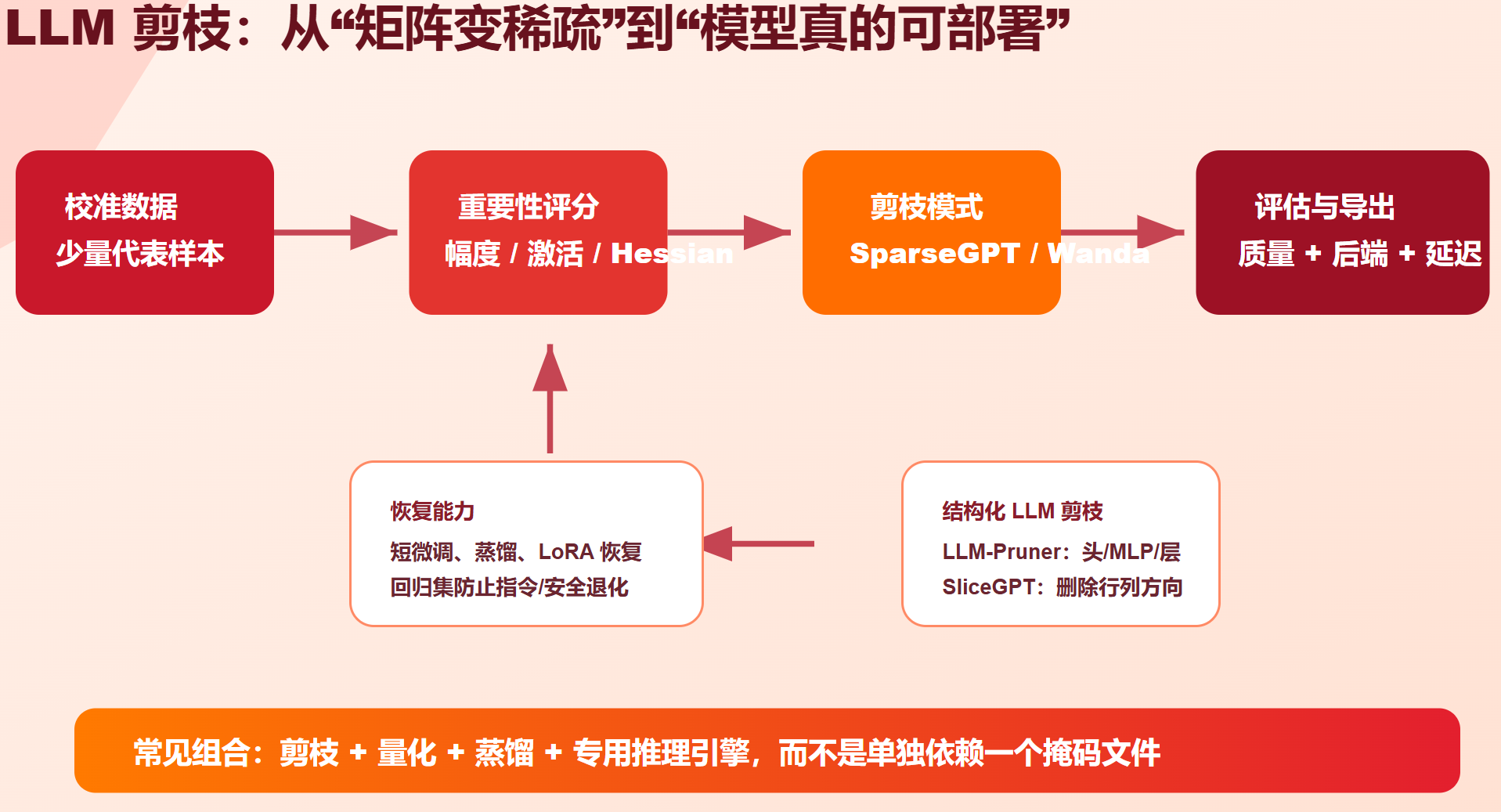
2023 年以后,LLM 剪枝形成了几条重要路线。
7.1 SparseGPT
SparseGPT 使用少量校准数据和近似二阶信息,对大语言模型做一次性剪枝,并在层内做误差补偿。它适合解释为什么"post-training pruning"在大模型上可行:大模型有冗余,但剪枝需要考虑输入激活和误差传播。
7.2 Wanda
Wanda 的核心思路更简单:结合权重大小和输入激活大小进行剪枝评分。它不需要反向传播,适合低成本 LLM 剪枝基线。它提醒我们,大模型权重重要性不应只看 |w|,还要看该权重对应输入通道在真实数据中的活跃程度。
7.3 LLM-Pruner
LLM-Pruner 关注结构化剪枝:删除注意力头、MLP 维度等结构,让 LLM 变成更小的 dense 模型。它更贴近通用部署需求,因为很多推理引擎对小 dense 模型的支持比不规则稀疏更成熟。
7.4 SliceGPT
SliceGPT 通过删除 Transformer 权重矩阵中的行列方向来压缩模型,并保持结构可部署。它代表了一类"让压缩后的模型仍像一个普通 dense Transformer"的思路。
7.5 LLM 剪枝与量化要一起考虑
LLM 推理常见瓶颈包括权重带宽、KV cache、attention 复杂度、batch 调度和长上下文。剪枝只解决其中一部分问题。因此实际部署常把剪枝与以下技术组合:
| 技术 | 解决什么 |
|---|---|
| INT8/INT4 权重量化 | 降低权重存储和带宽 |
| FP8/INT8 激活或 GEMM | 提升低精度计算效率 |
| KV cache 量化 | 降低长上下文显存 |
| 蒸馏或 LoRA 恢复 | 弥补剪枝后的质量下降 |
| speculative decoding | 改善生成吞吐 |
| continuous batching | 提升服务端利用率 |
剪枝不是 LLM 推理优化的唯一按钮。一个剪枝模型如果让困惑度下降不多,但破坏了指令遵循、安全拒答或长上下文稳定性,也不应上线。
第 8 层:策略选择
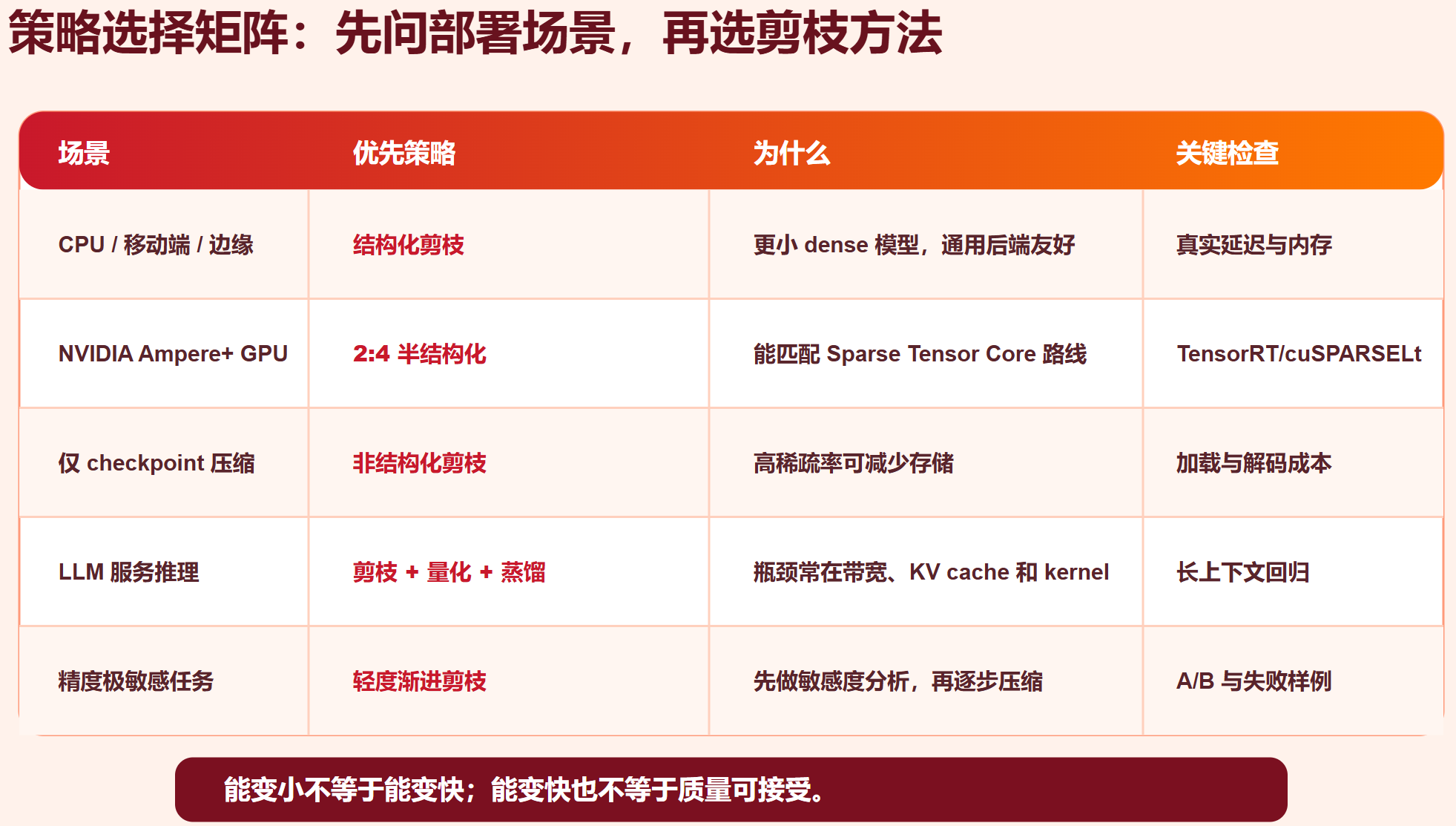
8.1 按部署场景选方法
| 场景 | 推荐优先级 | 说明 |
|---|---|---|
| CPU、移动端、边缘设备 | 结构化剪枝 > 量化 > 非结构化稀疏 | 通用后端更容易跑小 dense 模型 |
| NVIDIA Ampere/Hopper/Blackwell GPU | 2:4 半结构化、稀疏 GEMM、量化组合 | 需要 TensorRT、cuSPARSELt 或相应 kernel 支持 |
| 服务器 LLM 服务 | 结构化 LLM 剪枝 + 权重量化 + KV cache 优化 | 真瓶颈常在带宽、KV 和调度 |
| 只想压缩文件 | 非结构化剪枝 + 稀疏存储/编码 | 可减少 checkpoint,但不保证推理变快 |
| 精度极敏感任务 | 轻度剪枝、渐进剪枝、蒸馏恢复 | 先做层敏感度分析 |
| 检测/分割/多分支模型 | 框架化结构化剪枝 | 需要处理 FPN、concat、head shape |
8.2 参数建议不是固定答案
可以把下面当作起点,而不是结论:
| 参数 | 起点 | 调整方向 |
|---|---|---|
| 结构化剪枝率 | 20-50% 通道或维度 | 精度稳定后再提高 |
| 非结构化稀疏率 | 50-80% | 超过 80% 要更谨慎验证 |
| 2:4 稀疏 | 固定 50% 局部稀疏 | 重点验证后端是否利用 |
| 微调预算 | 从短微调开始 | 质量下降大时增加数据、蒸馏或降低剪枝率 |
| 校准数据 | 覆盖真实输入分布 | 长尾、长上下文、多语言/多领域要覆盖 |
如果目标是端到端加速,建议先用 10-20% 的轻度结构化剪枝建立可复现评估,再逐步增加压缩率,而不是直接追求 80-90% 稀疏。
第 9 层:评估与代码骨架

9.1 稀疏率报告
下面的代码只能报告权重中有多少 0,不能证明模型会加速。
python
def tensor_sparsity(x):
return (x == 0).sum().item() / max(1, x.numel())
def module_sparsity_report(model):
report = {}
for name, module in model.named_modules():
weight = getattr(module, "weight", None)
if weight is not None:
w = weight.detach()
report[name] = {
"shape": tuple(w.shape),
"sparsity": tensor_sparsity(w),
}
return report9.2 理论 MACs 不是真实延迟
python
def theoretical_sparse_macs(dense_macs, sparsity):
return dense_macs * (1.0 - sparsity)这只能估计"如果每个 0 都能被免费跳过"的理想上限。实际延迟必须用目标硬件、目标 batch、目标输入长度和目标推理引擎实测。
9.3 发布闸门
python
def pass_pruning_gate(metrics, limits):
return (
metrics["quality_drop"] <= limits["max_quality_drop"]
and metrics["p95_latency_ms"] <= limits["max_p95_latency_ms"]
and metrics["peak_memory_gb"] <= limits["max_peak_memory_gb"]
and metrics["kernel_path_verified"]
)推荐至少记录:
| 指标 | 说明 |
|---|---|
| quality_drop | 分类精度、mAP、困惑度、BLEU、人工偏好、任务成功率等 |
| p50/p95 latency | 端到端延迟,不只算单层 |
| throughput | images/s、tokens/s、requests/s |
| peak memory | 权重、激活、KV cache、workspace |
| energy | 端侧或服务器能耗 |
| kernel_path_verified | 是否真的走了 sparse/2:4/低精度 kernel |
| regression_cases | 长尾样例、安全样例、长上下文样例 |
9.4 延迟评估注意事项
评估剪枝模型时要固定:
- 硬件型号、驱动、CUDA/cuDNN/TensorRT/PyTorch 版本。
- batch size、输入分辨率或序列长度分布。
- warmup 次数和重复次数。
- 是否开启编译、算子融合、量化、稀疏 kernel。
- 是否测端到端,包括数据搬运、tokenizer、后处理和调度。
第 10 层:落地工作流
10.1 CNN/检测模型
text
确定部署端和延迟目标
-> 分析模型拓扑和多分支依赖
-> 做轻度通道剪枝
-> 同步 BN、shortcut、concat 和 head
-> 微调或蒸馏
-> 导出 ONNX/TensorRT/NPU 格式
-> 实测 mAP、p95 延迟和显存检测模型尤其要小心 neck 和 head。只剪 backbone 往往收益有限;剪 neck/head 又容易破坏多尺度特征和输出 shape。
10.2 Transformer/LLM
text
选校准集
-> 选择剪枝目标:head、MLP、层、行列、2:4 或非结构化
-> 剪枝并做短恢复训练
-> 与量化组合评估
-> 检查困惑度、下游任务、指令遵循、安全和长上下文
-> 导出到目标推理引擎LLM 剪枝一定要避免只看困惑度。指令模型还要看对话格式、工具调用、安全拒答、多语言、代码和长上下文稳定性。
10.3 推荐路线
| 目标 | 推荐路线 |
|---|---|
| 快速减小端侧视觉模型 | 结构化通道剪枝 + QAT/PTQ INT8 |
| 降低 LLM 显存 | INT4/INT8 权重量化优先,再评估结构化剪枝 |
| 利用 NVIDIA 稀疏硬件 | 2:4 稀疏训练/微调 + TensorRT/cuSPARSELt 验证 |
| 压缩 checkpoint 文件 | 非结构化剪枝 + 稀疏编码,但要说明不保证加速 |
| 极限压缩 | 剪枝 + 量化 + 蒸馏 + 架构搜索,但成本高 |
常见误区
| 误区 | 更准确的说法 |
|---|---|
| 稀疏率越高越好 | 高稀疏率可能让质量突然崩溃,也可能因稀疏 kernel 开销导致不加速 |
| 非结构化剪枝一定优于结构化剪枝 | 非结构化更灵活,结构化更容易部署 |
| 剪枝后只要微调几轮就行 | 微调预算必须由质量回归决定 |
| 理论 FLOPs 下降就是推理加速 | 真实延迟取决于 kernel、内存访问、batch 和编译器 |
| LLM 剪枝只看困惑度 | 还要看指令遵循、安全、代码、数学、长上下文和工具调用 |
| 结构化剪枝代码很简单 | 真实模型需要图级依赖处理和导出验证 |
总结
模型剪枝与稀疏推理的关键不是追求一个漂亮的稀疏率,而是把剪枝结果变成目标硬件上真的更小、更快、更省、质量仍然可控的模型。
最稳的判断顺序是:
text
先定部署目标
-> 再选剪枝粒度
-> 再确认后端支持
-> 最后用真实任务和真实硬件验收结构化剪枝适合追求通用部署收益;非结构化剪枝适合高压缩率和有稀疏后端的场景;2:4 半结构化稀疏是硬件友好的折中;LLM 剪枝则必须与量化、蒸馏、KV cache 和推理引擎一起看。真正成熟的剪枝不是"少了多少参数",而是"上线后是否更快、更稳、更便宜"。
参考资料
- Yann LeCun, John Denker, Sara Solla, "Optimal Brain Damage," NeurIPS 1989.
- Babak Hassibi, David Stork, "Second Order Derivatives for Network Pruning: Optimal Brain Surgeon," NeurIPS 1993.
- Song Han, Jeff Pool, John Tran, William Dally, "Learning both Weights and Connections for Efficient Neural Networks," NeurIPS 2015.
- Song Han, Huizi Mao, William Dally, "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding," ICLR 2016.
- Jonathan Frankle, Michael Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks," ICLR 2019.
- Namhoon Lee, Thalaiyasingam Ajanthan, Philip Torr, "SNIP: Single-shot Network Pruning based on Connection Sensitivity," ICLR 2019.
- Trevor Gale, Erich Elsen, Sara Hooker, "The State of Sparsity in Deep Neural Networks," 2019.
- Utku Evci et al., "Rigging the Lottery: Making All Tickets Winners," ICML 2020.
- Victor Sanh, Thomas Wolf, Alexander Rush, "Movement Pruning: Adaptive Sparsity by Fine-Tuning," NeurIPS 2020.
- Elias Frantar, Dan Alistarh, "SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot," ICML 2023.
- Mingjie Sun et al., "A Simple and Effective Pruning Approach for Large Language Models" (Wanda), 2023.
- Xinyin Ma et al., "LLM-Pruner: On the Structural Pruning of Large Language Models," NeurIPS 2023.
- Saleh Ashkboos et al., "SliceGPT: Compress Large Language Models by Deleting Rows and Columns," ICLR 2024.
- NVIDIA, "NVIDIA Ampere Architecture In-Depth," Sparse Tensor Cores and 2:4 structured sparsity.
- NVIDIA, cuSPARSELt Documentation, structured sparsity and sparse matrix multiplication.
- NVIDIA, TensorRT Documentation, structured sparsity and inference optimization.
- PyTorch, Sparse Tensors Documentation, sparse tensors and semi-structured sparsity.