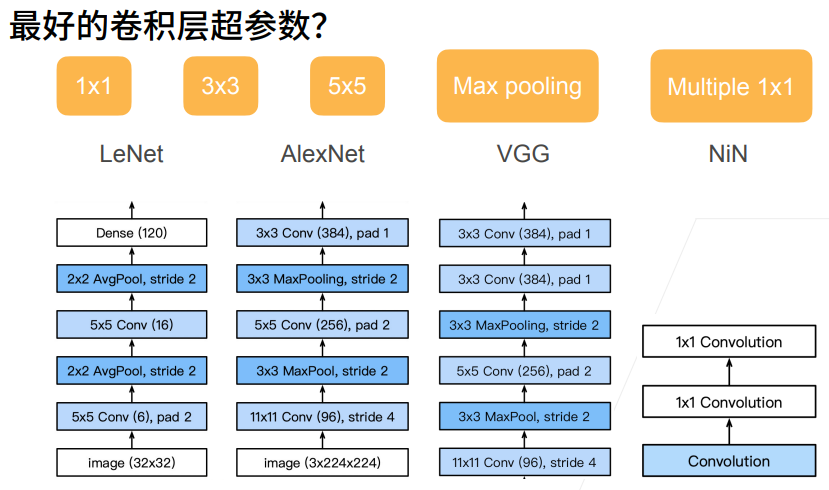
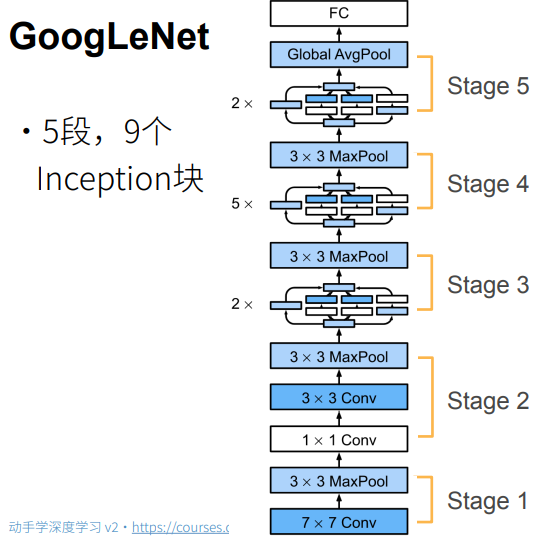
1. GoogLeNet
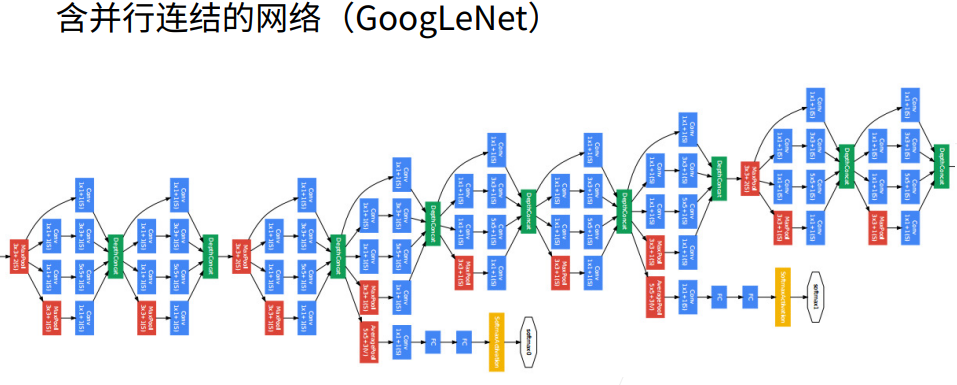
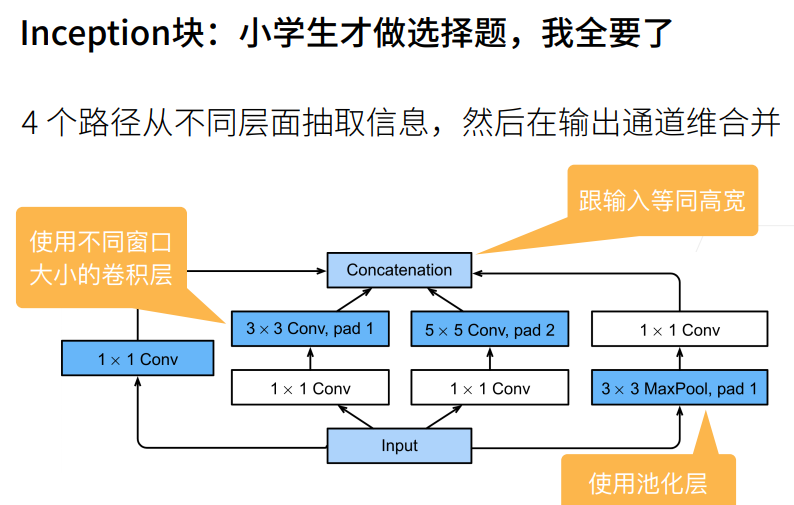
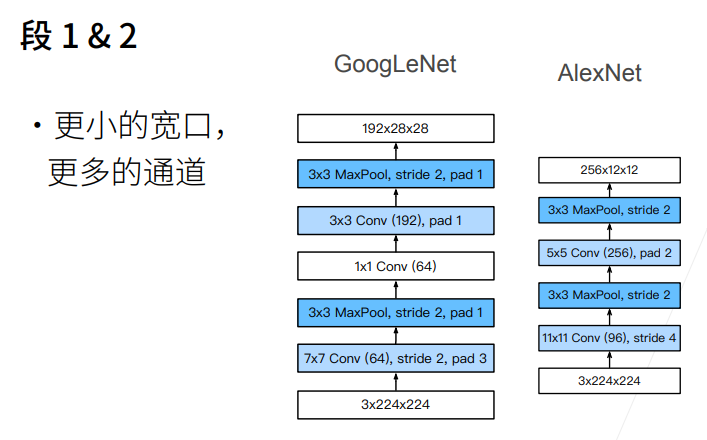
① 白色的卷积用来改变通道数,蓝色的卷积用来抽取信息。
② 最左边一条1X1卷积是用来抽取通道信息,其他的3X3卷积用来抽取空间信息。
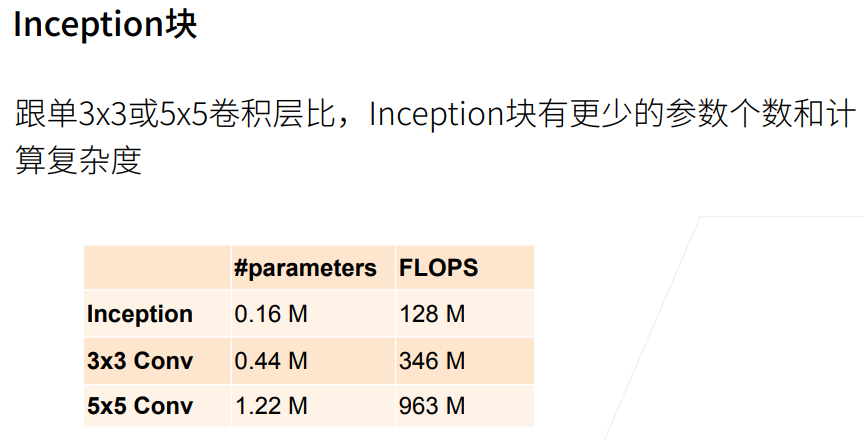
① 输出相同的通道数,5X5比3X3的卷积层参数个数多,3X3比1X1卷积层的参数个数多。
② Inception块使用了大量1X1卷积层,使得参数相对单3X3、5X5卷积层更少。
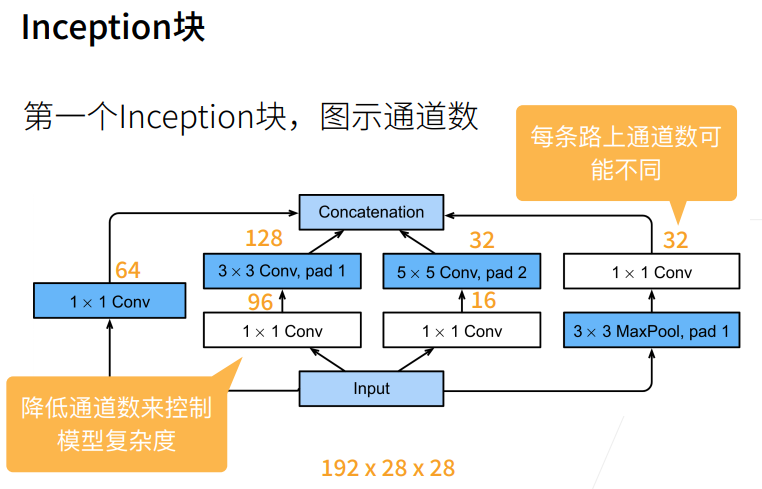
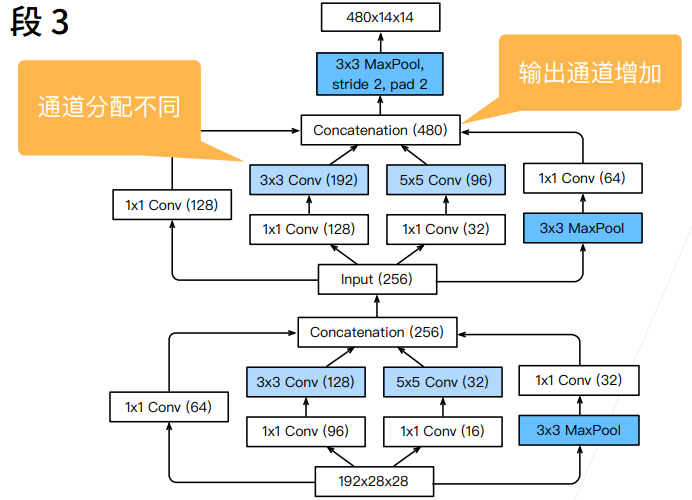
3×3 卷积路线(输出 128 通道):3×3 是卷积里性价比最高的尺寸 ------ 既能提取中等范围的局部特征,计算量又不算夸张。它是整个模块的 "主力输出",所以给最多的通道数,承担主要的特征提取任务。 它前面的 1×1 降维给 96 通道,也是平衡后的结果:先把通道降下来控制 3×3 的计算量,又不能降太低导致 3×3 没足够特征可学习。
1×1 卷积分支(输出 64 通道):1×1 卷积计算成本极低,专门做通道维度的特征混合,作为补充特征,所以给中等规模的通道数。
5×5 卷积路线(输出 32 通道):5×5 卷积感受野更大,但计算量是 3×3 的近 3 倍(5²/3²≈2.78),属于 "贵但有用" 的选项,负责提取大范围的全局特征。 因为计算成本高,所以给的通道数最少;前面的 1×1 降维也压得最狠(只留 16 通道),严格控制它的计算开销,这就是图里说的 "降低通道数来控制模型复杂度"。
池化分支(输出 32 通道):池化本身不改变通道数,后面加 1×1 卷积是为了调整通道维度,补充池化后的结构特征,同样给少量通道做辅助。
① 1X7卷积层是看行一下空间信息,列信息不看,7X1是列看一下空间信息,行信息不看。

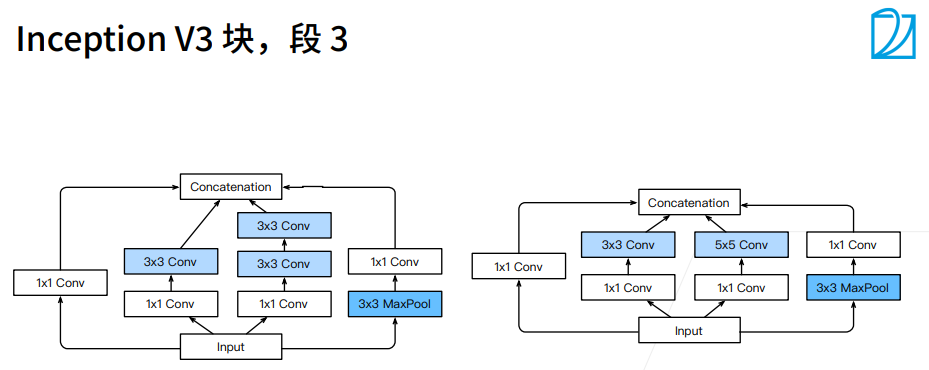
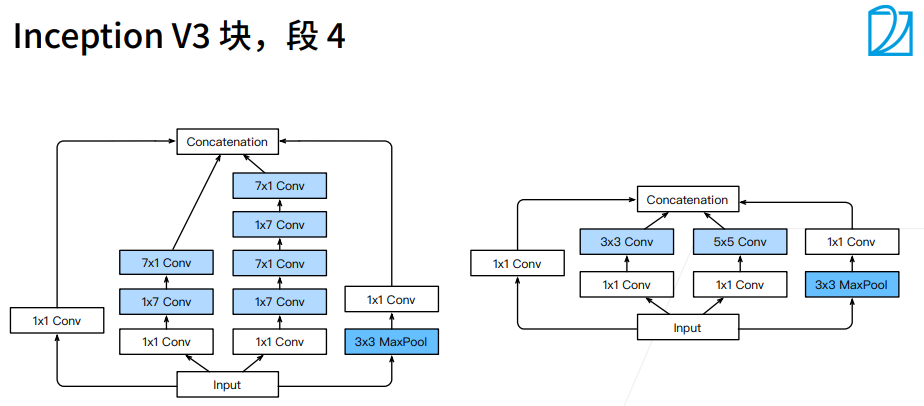
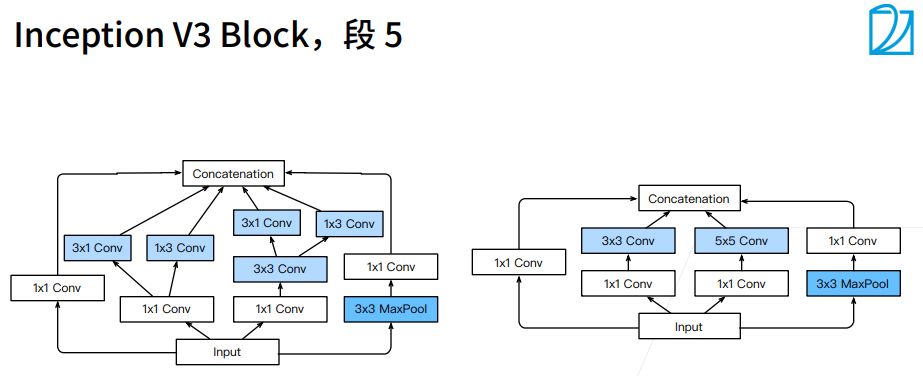
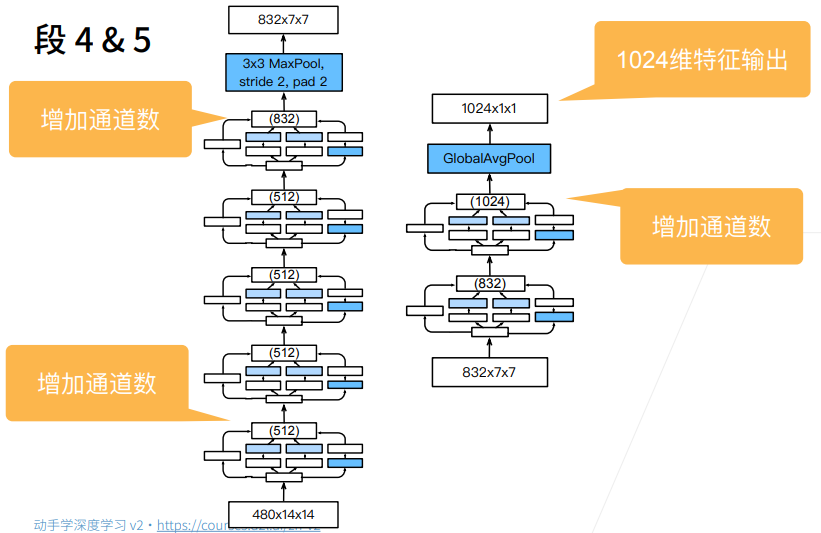
① 圈的大小表示耗内存的大小。
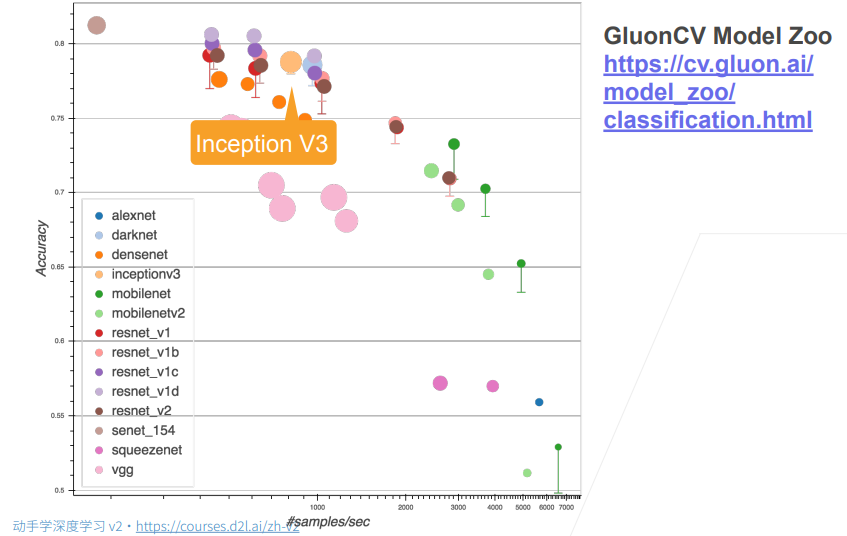
2. 总结

1. GoogLeNet(使用自定义)
python
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs): # c1为第一条路的输出通道数、c2为第二条路的输出通道数
super(Inception, self).__init__(**kwargs) # python中*vars代表解包元组,**vars代表解包字典,通过这种语法可以传递不定参数。**kwage是将除了前面显式列出的参数外的其他参数, 以dict结构进行接收.
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=2)
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels,c4,kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x)) # 第一条路的输出
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x)))) # 第二条路的输出
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 批量大小的dim为0,通道数的dim为1,以通道数维度进行合并
b1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
b2 = nn.Sequential(nn.Conv2d(64,64,kernel_size=1),nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
b3 = nn.Sequential(Inception(192,64,(96,128),(18,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
b4 = nn.Sequential(Inception(480,192,(96,208),(16,48),64),
Inception(512,160,(112,224),(24,64),64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112,(144,288),(32,64),64),
Inception(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
b5 = nn.Sequential(Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
nn.AdaptiveAvgPool2d((1,1)),nn.Flatten())
net = nn.Sequential(b1,b2,b3,b4,b5,nn.Linear(1024,10))① 在实际的项目当中,我们往往预先只知道的是输入数据和输出数据的大小,而不知道核与步长的大小。
② 我们可以手动计算核的大小和步长的值。而自适应(Adaptive)能让我们从这样的计算当中解脱出来,只要我们给定输入数据和输出数据的大小,自适应算法能够自动帮助我们计算核的大小和每次移动的步长。
③ 相当于我们对核说,我已经给你输入和输出的数据了,你自己适应去吧。你要长多大,你每次要走多远,都由你自己决定,总之最后你的输出符合我的要求就行了。
④ 比如我们给定输入数据的尺寸是9, 输出数据的尺寸是3,那么自适应算法就能自动帮我们计算出,核的大小是3,每次移动的步长也是3,然后依据这些数据,帮我们创建好池化层。
help(nn.AdaptiveAvgPool2d) # 对输入应用自适应平均池化,将feature map改为我们需要大小的输出。只需要给定输出特征图的大小就好,其中通道数前后不发生变化。 Help on class AdaptiveAvgPool2d in module torch.nn.modules.pooling:
class AdaptiveAvgPool2d(_AdaptiveAvgPoolNd)
| Applies a 2D adaptive average pooling over an input signal composed of several input planes.
|
| The output is of size H x W, for any input size.
| The number of output features is equal to the number of input planes.
|
| Args:
| output_size: the target output size of the image of the form H x W.
| Can be a tuple (H, W) or a single H for a square image H x H.
| H and W can be either a ``int``, or ``None`` which means the size will
| be the same as that of the input.
|
| Shape:
| - Input: :math:`(N, C, H_{in}, W_{in})` or :math:`(C, H_{in}, W_{in})`.
| - Output: :math:`(N, C, S_{0}, S_{1})` or :math:`(C, S_{0}, S_{1})`, where
| :math:`S=\text{output\_size}`.
|
| Examples:
| >>> # target output size of 5x7
| >>> m = nn.AdaptiveAvgPool2d((5,7))
| >>> input = torch.randn(1, 64, 8, 9)
| >>> output = m(input)
| >>> # target output size of 7x7 (square)
| >>> m = nn.AdaptiveAvgPool2d(7)
| >>> input = torch.randn(1, 64, 10, 9)
| >>> output = m(input)
| >>> # target output size of 10x7
| >>> m = nn.AdaptiveAvgPool2d((None, 7))
| >>> input = torch.randn(1, 64, 10, 9)
| >>> output = m(input)
|
| Method resolution order:
| AdaptiveAvgPool2d
| _AdaptiveAvgPoolNd
| torch.nn.modules.module.Module
| builtins.object
|
| Methods defined here:
|
| forward(self, input:torch.Tensor) -> torch.Tensor
| Defines the computation performed at every call.
|
| Should be overridden by all subclasses.
|
| .. note::
| Although the recipe for forward pass needs to be defined within
| this function, one should call the :class:`Module` instance afterwards
| instead of this since the former takes care of running the
| registered hooks while the latter silently ignores them.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __annotations__ = {'output_size': typing.Union[int, NoneType, typing.T...
|
| ----------------------------------------------------------------------
| Methods inherited from _AdaptiveAvgPoolNd:
|
| __init__(self, output_size:Union[int, NoneType, Tuple[Union[int, NoneType], ...]]) -> None
| Initializes internal Module state, shared by both nn.Module and ScriptModule.
|
| extra_repr(self) -> str
| Set the extra representation of the module
|
| To print customized extra information, you should re-implement
| this method in your own modules. Both single-line and multi-line
| strings are acceptable.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from _AdaptiveAvgPoolNd:
|
| __constants__ = ['output_size']
|
| ----------------------------------------------------------------------
| Methods inherited from torch.nn.modules.module.Module:
|
| __call__ = _call_impl(self, *input, **kwargs)
|
| __delattr__(self, name)
| Implement delattr(self, name).
|
| __dir__(self)
| __dir__() -> list
| default dir() implementation
|
| __getattr__(self, name:str) -> Union[torch.Tensor, _ForwardRef('Module')]
|
| __repr__(self)
| Return repr(self).
|
| __setattr__(self, name:str, value:Union[torch.Tensor, _ForwardRef('Module')]) -> None
| Implement setattr(self, name, value).
|
| __setstate__(self, state)
|
| add_module(self, name:str, module:Union[_ForwardRef('Module'), NoneType]) -> None
| Adds a child module to the current module.
|
| The module can be accessed as an attribute using the given name.
|
| Args:
| name (string): name of the child module. The child module can be
| accessed from this module using the given name
| module (Module): child module to be added to the module.
|
| apply(self:~T, fn:Callable[[_ForwardRef('Module')], NoneType]) -> ~T
| Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
| as well as self. Typical use includes initializing the parameters of a model
| (see also :ref:`nn-init-doc`).
|
| Args:
| fn (:class:`Module` -> None): function to be applied to each submodule
|
| Returns:
| Module: self
|
| Example::
|
| >>> @torch.no_grad()
| >>> def init_weights(m):
| >>> print(m)
| >>> if type(m) == nn.Linear:
| >>> m.weight.fill_(1.0)
| >>> print(m.weight)
| >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
| >>> net.apply(init_weights)
| Linear(in_features=2, out_features=2, bias=True)
| Parameter containing:
| tensor([[ 1., 1.],
| [ 1., 1.]])
| Linear(in_features=2, out_features=2, bias=True)
| Parameter containing:
| tensor([[ 1., 1.],
| [ 1., 1.]])
| Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
| Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
|
| bfloat16(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``bfloat16`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| buffers(self, recurse:bool=True) -> Iterator[torch.Tensor]
| Returns an iterator over module buffers.
|
| Args:
| recurse (bool): if True, then yields buffers of this module
| and all submodules. Otherwise, yields only buffers that
| are direct members of this module.
|
| Yields:
| torch.Tensor: module buffer
|
| Example::
|
| >>> for buf in model.buffers():
| >>> print(type(buf), buf.size())
| <class 'torch.Tensor'> (20L,)
| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
|
| children(self) -> Iterator[_ForwardRef('Module')]
| Returns an iterator over immediate children modules.
|
| Yields:
| Module: a child module
|
| cpu(self:~T) -> ~T
| Moves all model parameters and buffers to the CPU.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| cuda(self:~T, device:Union[int, torch.device, NoneType]=None) -> ~T
| Moves all model parameters and buffers to the GPU.
|
| This also makes associated parameters and buffers different objects. So
| it should be called before constructing optimizer if the module will
| live on GPU while being optimized.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| device (int, optional): if specified, all parameters will be
| copied to that device
|
| Returns:
| Module: self
|
| double(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``double`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| eval(self:~T) -> ~T
| Sets the module in evaluation mode.
|
| This has any effect only on certain modules. See documentations of
| particular modules for details of their behaviors in training/evaluation
| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
| etc.
|
| This is equivalent with :meth:`self.train(False) <torch.nn.Module.train>`.
|
| See :ref:`locally-disable-grad-doc` for a comparison between
| `.eval()` and several similar mechanisms that may be confused with it.
|
| Returns:
| Module: self
|
| float(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``float`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| get_buffer(self, target:str) -> 'Tensor'
| Returns the buffer given by ``target`` if it exists,
| otherwise throws an error.
|
| See the docstring for ``get_submodule`` for a more detailed
| explanation of this method's functionality as well as how to
| correctly specify ``target``.
|
| Args:
| target: The fully-qualified string name of the buffer
| to look for. (See ``get_submodule`` for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.Tensor: The buffer referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not a
| buffer
|
| get_extra_state(self) -> Any
| Returns any extra state to include in the module's state_dict.
| Implement this and a corresponding :func:`set_extra_state` for your module
| if you need to store extra state. This function is called when building the
| module's `state_dict()`.
|
| Note that extra state should be pickleable to ensure working serialization
| of the state_dict. We only provide provide backwards compatibility guarantees
| for serializing Tensors; other objects may break backwards compatibility if
| their serialized pickled form changes.
|
| Returns:
| object: Any extra state to store in the module's state_dict
|
| get_parameter(self, target:str) -> 'Parameter'
| Returns the parameter given by ``target`` if it exists,
| otherwise throws an error.
|
| See the docstring for ``get_submodule`` for a more detailed
| explanation of this method's functionality as well as how to
| correctly specify ``target``.
|
| Args:
| target: The fully-qualified string name of the Parameter
| to look for. (See ``get_submodule`` for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.nn.Parameter: The Parameter referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not an
| ``nn.Parameter``
|
| get_submodule(self, target:str) -> 'Module'
| Returns the submodule given by ``target`` if it exists,
| otherwise throws an error.
|
| For example, let's say you have an ``nn.Module`` ``A`` that
| looks like this:
|
| .. code-block::text
|
| A(
| (net_b): Module(
| (net_c): Module(
| (conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2))
| )
| (linear): Linear(in_features=100, out_features=200, bias=True)
| )
| )
|
| (The diagram shows an ``nn.Module`` ``A``. ``A`` has a nested
| submodule ``net_b``, which itself has two submodules ``net_c``
| and ``linear``. ``net_c`` then has a submodule ``conv``.)
|
| To check whether or not we have the ``linear`` submodule, we
| would call ``get_submodule("net_b.linear")``. To check whether
| we have the ``conv`` submodule, we would call
| ``get_submodule("net_b.net_c.conv")``.
|
| The runtime of ``get_submodule`` is bounded by the degree
| of module nesting in ``target``. A query against
| ``named_modules`` achieves the same result, but it is O(N) in
| the number of transitive modules. So, for a simple check to see
| if some submodule exists, ``get_submodule`` should always be
| used.
|
| Args:
| target: The fully-qualified string name of the submodule
| to look for. (See above example for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.nn.Module: The submodule referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not an
| ``nn.Module``
|
| half(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``half`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| load_state_dict(self, state_dict:'OrderedDict[str, Tensor]', strict:bool=True)
| Copies parameters and buffers from :attr:`state_dict` into
| this module and its descendants. If :attr:`strict` is ``True``, then
| the keys of :attr:`state_dict` must exactly match the keys returned
| by this module's :meth:`~torch.nn.Module.state_dict` function.
|
| Args:
| state_dict (dict): a dict containing parameters and
| persistent buffers.
| strict (bool, optional): whether to strictly enforce that the keys
| in :attr:`state_dict` match the keys returned by this module's
| :meth:`~torch.nn.Module.state_dict` function. Default: ``True``
|
| Returns:
| ``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
| * **missing_keys** is a list of str containing the missing keys
| * **unexpected_keys** is a list of str containing the unexpected keys
|
| Note:
| If a parameter or buffer is registered as ``None`` and its corresponding key
| exists in :attr:`state_dict`, :meth:`load_state_dict` will raise a
| ``RuntimeError``.
|
| modules(self) -> Iterator[_ForwardRef('Module')]
| Returns an iterator over all modules in the network.
|
| Yields:
| Module: a module in the network
|
| Note:
| Duplicate modules are returned only once. In the following
| example, ``l`` will be returned only once.
|
| Example::
|
| >>> l = nn.Linear(2, 2)
| >>> net = nn.Sequential(l, l)
| >>> for idx, m in enumerate(net.modules()):
| print(idx, '->', m)
|
| 0 -> Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
| 1 -> Linear(in_features=2, out_features=2, bias=True)
|
| named_buffers(self, prefix:str='', recurse:bool=True) -> Iterator[Tuple[str, torch.Tensor]]
| Returns an iterator over module buffers, yielding both the
| name of the buffer as well as the buffer itself.
|
| Args:
| prefix (str): prefix to prepend to all buffer names.
| recurse (bool): if True, then yields buffers of this module
| and all submodules. Otherwise, yields only buffers that
| are direct members of this module.
|
| Yields:
| (string, torch.Tensor): Tuple containing the name and buffer
|
| Example::
|
| >>> for name, buf in self.named_buffers():
| >>> if name in ['running_var']:
| >>> print(buf.size())
|
| named_children(self) -> Iterator[Tuple[str, _ForwardRef('Module')]]
| Returns an iterator over immediate children modules, yielding both
| the name of the module as well as the module itself.
|
| Yields:
| (string, Module): Tuple containing a name and child module
|
| Example::
|
| >>> for name, module in model.named_children():
| >>> if name in ['conv4', 'conv5']:
| >>> print(module)
|
| named_modules(self, memo:Union[Set[_ForwardRef('Module')], NoneType]=None, prefix:str='', remove_duplicate:bool=True)
| Returns an iterator over all modules in the network, yielding
| both the name of the module as well as the module itself.
|
| Args:
| memo: a memo to store the set of modules already added to the result
| prefix: a prefix that will be added to the name of the module
| remove_duplicate: whether to remove the duplicated module instances in the result
| or not
|
| Yields:
| (string, Module): Tuple of name and module
|
| Note:
| Duplicate modules are returned only once. In the following
| example, ``l`` will be returned only once.
|
| Example::
|
| >>> l = nn.Linear(2, 2)
| >>> net = nn.Sequential(l, l)
| >>> for idx, m in enumerate(net.named_modules()):
| print(idx, '->', m)
|
| 0 -> ('', Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| ))
| 1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
|
| named_parameters(self, prefix:str='', recurse:bool=True) -> Iterator[Tuple[str, torch.nn.parameter.Parameter]]
| Returns an iterator over module parameters, yielding both the
| name of the parameter as well as the parameter itself.
|
| Args:
| prefix (str): prefix to prepend to all parameter names.
| recurse (bool): if True, then yields parameters of this module
| and all submodules. Otherwise, yields only parameters that
| are direct members of this module.
|
| Yields:
| (string, Parameter): Tuple containing the name and parameter
|
| Example::
|
| >>> for name, param in self.named_parameters():
| >>> if name in ['bias']:
| >>> print(param.size())
|
| parameters(self, recurse:bool=True) -> Iterator[torch.nn.parameter.Parameter]
| Returns an iterator over module parameters.
|
| This is typically passed to an optimizer.
|
| Args:
| recurse (bool): if True, then yields parameters of this module
| and all submodules. Otherwise, yields only parameters that
| are direct members of this module.
|
| Yields:
| Parameter: module parameter
|
| Example::
|
| >>> for param in model.parameters():
| >>> print(type(param), param.size())
| <class 'torch.Tensor'> (20L,)
| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
|
| register_backward_hook(self, hook:Callable[[_ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle
| Registers a backward hook on the module.
|
| This function is deprecated in favor of :meth:`~torch.nn.Module.register_full_backward_hook` and
| the behavior of this function will change in future versions.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_buffer(self, name:str, tensor:Union[torch.Tensor, NoneType], persistent:bool=True) -> None
| Adds a buffer to the module.
|
| This is typically used to register a buffer that should not to be
| considered a model parameter. For example, BatchNorm's ``running_mean``
| is not a parameter, but is part of the module's state. Buffers, by
| default, are persistent and will be saved alongside parameters. This
| behavior can be changed by setting :attr:`persistent` to ``False``. The
| only difference between a persistent buffer and a non-persistent buffer
| is that the latter will not be a part of this module's
| :attr:`state_dict`.
|
| Buffers can be accessed as attributes using given names.
|
| Args:
| name (string): name of the buffer. The buffer can be accessed
| from this module using the given name
| tensor (Tensor or None): buffer to be registered. If ``None``, then operations
| that run on buffers, such as :attr:`cuda`, are ignored. If ``None``,
| the buffer is **not** included in the module's :attr:`state_dict`.
| persistent (bool): whether the buffer is part of this module's
| :attr:`state_dict`.
|
| Example::
|
| >>> self.register_buffer('running_mean', torch.zeros(num_features))
|
| register_forward_hook(self, hook:Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle
| Registers a forward hook on the module.
|
| The hook will be called every time after :func:`forward` has computed an output.
| It should have the following signature::
|
| hook(module, input, output) -> None or modified output
|
| The input contains only the positional arguments given to the module.
| Keyword arguments won't be passed to the hooks and only to the ``forward``.
| The hook can modify the output. It can modify the input inplace but
| it will not have effect on forward since this is called after
| :func:`forward` is called.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_forward_pre_hook(self, hook:Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle
| Registers a forward pre-hook on the module.
|
| The hook will be called every time before :func:`forward` is invoked.
| It should have the following signature::
|
| hook(module, input) -> None or modified input
|
| The input contains only the positional arguments given to the module.
| Keyword arguments won't be passed to the hooks and only to the ``forward``.
| The hook can modify the input. User can either return a tuple or a
| single modified value in the hook. We will wrap the value into a tuple
| if a single value is returned(unless that value is already a tuple).
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_full_backward_hook(self, hook:Callable[[_ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle
| Registers a backward hook on the module.
|
| The hook will be called every time the gradients with respect to module
| inputs are computed. The hook should have the following signature::
|
| hook(module, grad_input, grad_output) -> tuple(Tensor) or None
|
| The :attr:`grad_input` and :attr:`grad_output` are tuples that contain the gradients
| with respect to the inputs and outputs respectively. The hook should
| not modify its arguments, but it can optionally return a new gradient with
| respect to the input that will be used in place of :attr:`grad_input` in
| subsequent computations. :attr:`grad_input` will only correspond to the inputs given
| as positional arguments and all kwarg arguments are ignored. Entries
| in :attr:`grad_input` and :attr:`grad_output` will be ``None`` for all non-Tensor
| arguments.
|
| For technical reasons, when this hook is applied to a Module, its forward function will
| receive a view of each Tensor passed to the Module. Similarly the caller will receive a view
| of each Tensor returned by the Module's forward function.
|
| .. warning ::
| Modifying inputs or outputs inplace is not allowed when using backward hooks and
| will raise an error.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_parameter(self, name:str, param:Union[torch.nn.parameter.Parameter, NoneType]) -> None
| Adds a parameter to the module.
|
| The parameter can be accessed as an attribute using given name.
|
| Args:
| name (string): name of the parameter. The parameter can be accessed
| from this module using the given name
| param (Parameter or None): parameter to be added to the module. If
| ``None``, then operations that run on parameters, such as :attr:`cuda`,
| are ignored. If ``None``, the parameter is **not** included in the
| module's :attr:`state_dict`.
|
| requires_grad_(self:~T, requires_grad:bool=True) -> ~T
| Change if autograd should record operations on parameters in this
| module.
|
| This method sets the parameters' :attr:`requires_grad` attributes
| in-place.
|
| This method is helpful for freezing part of the module for finetuning
| or training parts of a model individually (e.g., GAN training).
|
| See :ref:`locally-disable-grad-doc` for a comparison between
| `.requires_grad_()` and several similar mechanisms that may be confused with it.
|
| Args:
| requires_grad (bool): whether autograd should record operations on
| parameters in this module. Default: ``True``.
|
| Returns:
| Module: self
|
| set_extra_state(self, state:Any)
| This function is called from :func:`load_state_dict` to handle any extra state
| found within the `state_dict`. Implement this function and a corresponding
| :func:`get_extra_state` for your module if you need to store extra state within its
| `state_dict`.
|
| Args:
| state (dict): Extra state from the `state_dict`
|
| share_memory(self:~T) -> ~T
| See :meth:`torch.Tensor.share_memory_`
|
| state_dict(self, destination=None, prefix='', keep_vars=False)
| Returns a dictionary containing a whole state of the module.
|
| Both parameters and persistent buffers (e.g. running averages) are
| included. Keys are corresponding parameter and buffer names.
| Parameters and buffers set to ``None`` are not included.
|
| Returns:
| dict:
| a dictionary containing a whole state of the module
|
| Example::
|
| >>> module.state_dict().keys()
| ['bias', 'weight']
|
| to(self, *args, **kwargs)
| Moves and/or casts the parameters and buffers.
|
| This can be called as
|
| .. function:: to(device=None, dtype=None, non_blocking=False)
| :noindex:
|
| .. function:: to(dtype, non_blocking=False)
| :noindex:
|
| .. function:: to(tensor, non_blocking=False)
| :noindex:
|
| .. function:: to(memory_format=torch.channels_last)
| :noindex:
|
| Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
| floating point or complex :attr:`dtype`\ s. In addition, this method will
| only cast the floating point or complex parameters and buffers to :attr:`dtype`
| (if given). The integral parameters and buffers will be moved
| :attr:`device`, if that is given, but with dtypes unchanged. When
| :attr:`non_blocking` is set, it tries to convert/move asynchronously
| with respect to the host if possible, e.g., moving CPU Tensors with
| pinned memory to CUDA devices.
|
| See below for examples.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| device (:class:`torch.device`): the desired device of the parameters
| and buffers in this module
| dtype (:class:`torch.dtype`): the desired floating point or complex dtype of
| the parameters and buffers in this module
| tensor (torch.Tensor): Tensor whose dtype and device are the desired
| dtype and device for all parameters and buffers in this module
| memory_format (:class:`torch.memory_format`): the desired memory
| format for 4D parameters and buffers in this module (keyword
| only argument)
|
| Returns:
| Module: self
|
| Examples::
|
| >>> linear = nn.Linear(2, 2)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1913, -0.3420],
| [-0.5113, -0.2325]])
| >>> linear.to(torch.double)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1913, -0.3420],
| [-0.5113, -0.2325]], dtype=torch.float64)
| >>> gpu1 = torch.device("cuda:1")
| >>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1914, -0.3420],
| [-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
| >>> cpu = torch.device("cpu")
| >>> linear.to(cpu)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1914, -0.3420],
| [-0.5112, -0.2324]], dtype=torch.float16)
|
| >>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.3741+0.j, 0.2382+0.j],
| [ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)
| >>> linear(torch.ones(3, 2, dtype=torch.cdouble))
| tensor([[0.6122+0.j, 0.1150+0.j],
| [0.6122+0.j, 0.1150+0.j],
| [0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
|
| to_empty(self:~T, *, device:Union[str, torch.device]) -> ~T
| Moves the parameters and buffers to the specified device without copying storage.
|
| Args:
| device (:class:`torch.device`): The desired device of the parameters
| and buffers in this module.
|
| Returns:
| Module: self
|
| train(self:~T, mode:bool=True) -> ~T
| Sets the module in training mode.
|
| This has any effect only on certain modules. See documentations of
| particular modules for details of their behaviors in training/evaluation
| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
| etc.
|
| Args:
| mode (bool): whether to set training mode (``True``) or evaluation
| mode (``False``). Default: ``True``.
|
| Returns:
| Module: self
|
| type(self:~T, dst_type:Union[torch.dtype, str]) -> ~T
| Casts all parameters and buffers to :attr:`dst_type`.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| dst_type (type or string): the desired type
|
| Returns:
| Module: self
|
| xpu(self:~T, device:Union[int, torch.device, NoneType]=None) -> ~T
| Moves all model parameters and buffers to the XPU.
|
| This also makes associated parameters and buffers different objects. So
| it should be called before constructing optimizer if the module will
| live on XPU while being optimized.
|
| .. note::
| This method modifies the module in-place.
|
| Arguments:
| device (int, optional): if specified, all parameters will be
| copied to that device
|
| Returns:
| Module: self
|
| zero_grad(self, set_to_none:bool=False) -> None
| Sets gradients of all model parameters to zero. See similar function
| under :class:`torch.optim.Optimizer` for more context.
|
| Args:
| set_to_none (bool): instead of setting to zero, set the grads to None.
| See :meth:`torch.optim.Optimizer.zero_grad` for details.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from torch.nn.modules.module.Module:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from torch.nn.modules.module.Module:
|
| T_destination = ~T_destination
| Type variable.
|
| Usage::
|
| T = TypeVar('T') # Can be anything
| A = TypeVar('A', str, bytes) # Must be str or bytes
|
| Type variables exist primarily for the benefit of static type
| checkers. They serve as the parameters for generic types as well
| as for generic function definitions. See class Generic for more
| information on generic types. Generic functions work as follows:
|
| def repeat(x: T, n: int) -> List[T]:
| '''Return a list containing n references to x.'''
| return [x]*n
|
| def longest(x: A, y: A) -> A:
| '''Return the longest of two strings.'''
| return x if len(x) >= len(y) else y
|
| The latter example's signature is essentially the overloading
| of (str, str) -> str and (bytes, bytes) -> bytes. Also note
| that if the arguments are instances of some subclass of str,
| the return type is still plain str.
|
| At runtime, isinstance(x, T) and issubclass(C, T) will raise TypeError.
|
| Type variables defined with covariant=True or contravariant=True
| can be used do declare covariant or contravariant generic types.
| See PEP 484 for more details. By default generic types are invariant
| in all type variables.
|
| Type variables can be introspected. e.g.:
|
| T.__name__ == 'T'
| T.__constraints__ == ()
| T.__covariant__ == False
| T.__contravariant__ = False
| A.__constraints__ == (str, bytes)
|
| dump_patches = False
python
# 为了使Fashion-MNIST上的训练短小精悍,我们将输入的高和宽从224降到96
X = torch.rand(size=(1,1,96,96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)Sequential output shape: torch.Size([1, 64, 24, 24])
Sequential output shape: torch.Size([1, 192, 12, 12])
Sequential output shape: torch.Size([1, 480, 6, 6])
Sequential output shape: torch.Size([1, 832, 3, 3])
Sequential output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 10])
python
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2,
padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
python
lr, num_epochs, batch_size =0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,resize=96)
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())loss 0.252, train acc 0.903, test acc 0.889
1518.0 examples/sec on cuda:0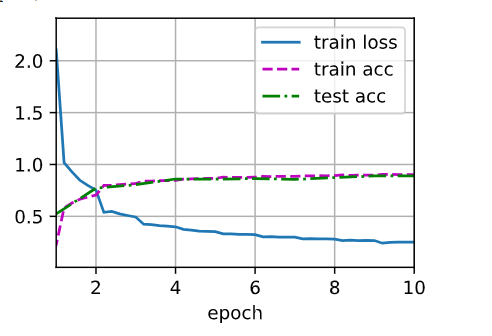
2.数学归一化
1. 正态分布
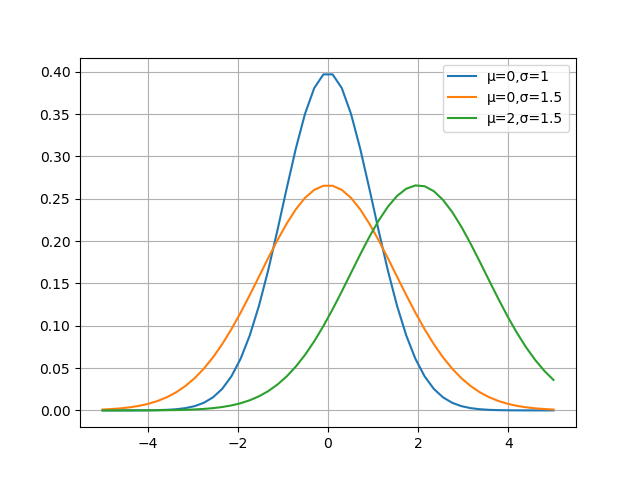
① 正态分布,又叫做高斯分布。
② 若随机变量,服从一个位置参数为、尺度参数为的概率分布,且其概率密度函数为:
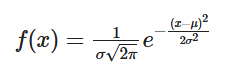
③ 则这个随机变量就称为正态随机变量,正态随机变量服从的分布就称为正态分布,记作:
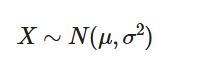
④ 当μ=0,σ=1时,称为标准正态分布: 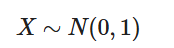
⑤ 此时公式简化为: 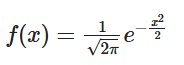
⑥ 下图是三种()组合的函数图像。 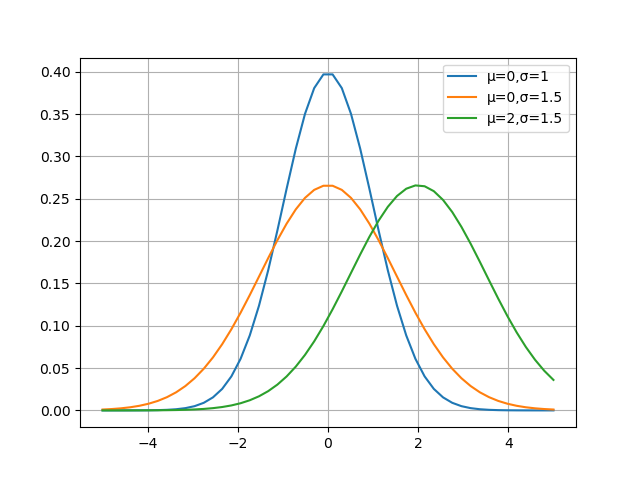
2. 每层数据分布
① 机器学习领域有个很重要的假设:I.I.D.(独立同分布)假设,就是假设训练数据和测试数据是满足相同分布的,这样就能做到通过训练数据获得的模型能够在测试集获得好的效果。
② 在深度神经网络中,我们可以将每一层视为对输入的信号做了一次变换: 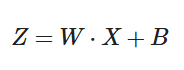
③ 输入层的数据如果不做归一化,很多时候甚至网络不会收敛,可见归一化的重要性。
④ 随后的网络的每一层的输入数据在经过公式5的运算后,其分布一直在发生变化,前面层训练参数的更新将导致后面层输入数据分布的变化,必然会引起后面每一层输入数据分布的改变,不再是输入的原始数据所适应的分布了。
⑤ 而且,网络前面几层微小的改变,后面几层就会逐步把这种改变累积放大。训练过程中网络中间层数据分布的改变称之为内部协变量偏移(Internal Covariate Shift)。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。
① 比如,在上图中,假设X是服从蓝色或红色曲线的分布,经过公式5后,有可能变成了绿色曲线的分布。
② 标准正态分布的数值密度占比如下图所示。
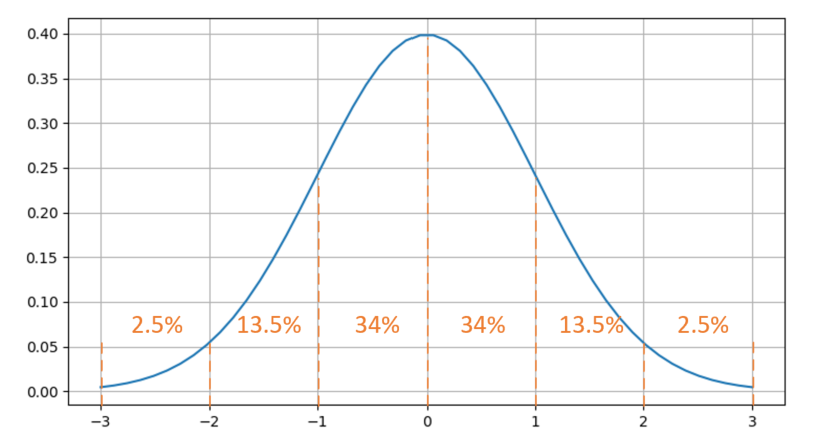
③ 有68%的值落在-1,1之间,有95%的值落在-2,2之间。
① 比较一下偏移后的数据分布区域和Sigmoid激活函数的图像,如下图所示。
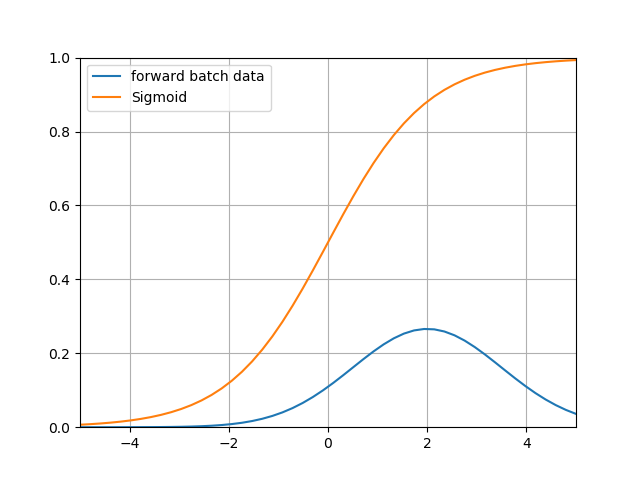
② 可以看到带来的问题是:
- 在大于2的区域,激活后的值基本接近1了,饱和输出。如果蓝色曲线表示的数据更偏向右侧的话,激活函数就会失去了作用,因为所有的输出值都是0.94、0.95、0.98这样子的数值,区别不大;
- 导数数值小,只有不到0.1甚至更小,反向传播的力度很小,网络很难收敛。
① 我们在深度学习中不是都用ReLU激活函数吗?那么BN对于ReLU有用吗?下面我们看看ReLU函数的图像,如下图所示。 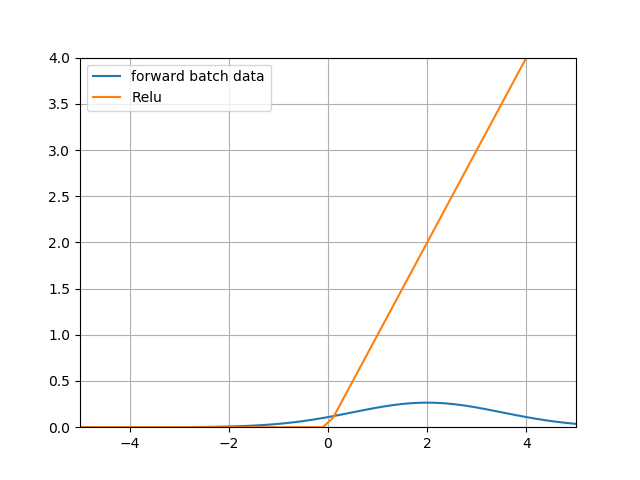
② 上图中蓝色为数据分布,已经从0点向右偏移了,黄色为ReLU的激活值,可以看到95%以上的数据都在大于0的区域,从而被Relu激活函数原封不动第传到了下一层网络中,而没有被小于0的部分剪裁,那么这个网络和线性网络也差不多了,失去了深层网络的能力。
3. 批量归一化
① 既然可以把原始训练样本做归一化,那么如果在深度神经网络的每一层,都可以有类似的手段,也就是说把层之间传递的数据移到0点附近,那么训练效果就应该会很理想。这就是批归一化BN的想法的来源。
② 深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢,这是个在DL领域很接近本质的问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network。BN本质上也是解释并从某个不同的角度来解决这个问题的。
③ BN就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同的分布,致力于将每一层的输入数据正则化成的分布。因次,每次训练的数据必须是mini-batch形式,一般取32,64等数值。
④ 具体的数据处理过程如下图所示。 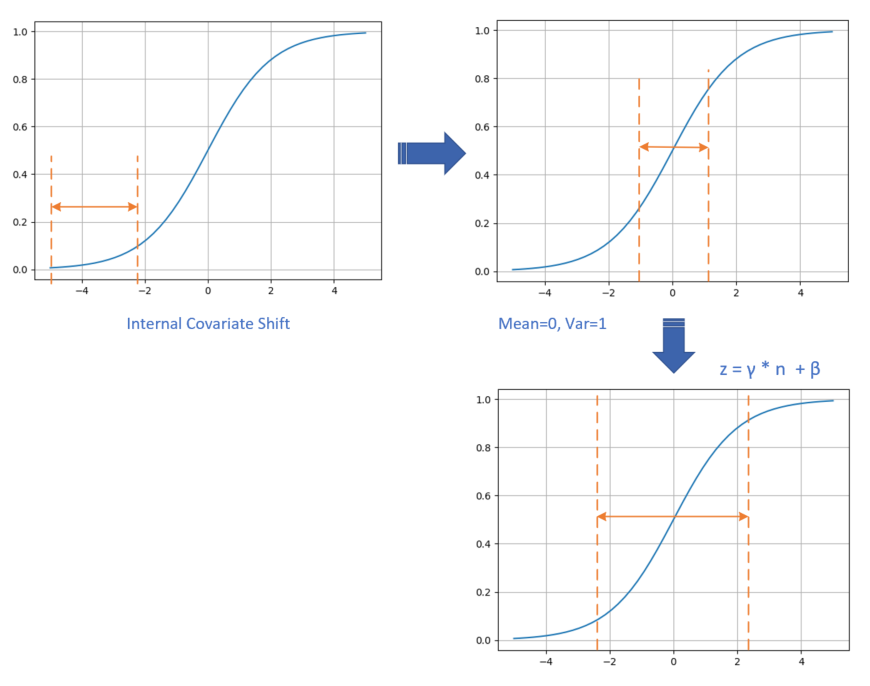
① 数据在训练过程中,在网络的某一层会发生Internal Covariate Shift,导致将数据处于激活函数的饱和区;
② 经过均值为0、方差为1的变换后,位移到了0点附近。但是只做到这一步的话,会带来两个问题:
- 在-1,1这个区域,Sigmoid激活函数是近似线性的,造成激活函数失去非线性的作用;
- 在二分类问题中我们学习过,神经网络把正类样本点推向了右侧,把负类样本点推向了左侧,如果再把它们强行向中间集中的话,那么前面学习到的成果就会被破坏;
③ 经过的线性变换后,把数据区域拉宽,则激活函数的输出既有线性的部分,也有非线性的部分,这就解决了问题a;而且由于也是通过网络进行学习的,所以以前学到的成果也会保持,这就解决了问题b。
④ 在实际的工程中,我们把BN当作一个层来看待,一般架设在全连接层(或卷积层)与激活函数层之间。
1. 批量归一化


① 在每个批量里,1个像素是1个样本。与像素(样本)对应的通道维,就是特征维。
② 所以不是对单个通道的特征图做均值方差,是对单个像素的不同通道做均值方差。
③ 输入9个像素(3x3), 输出3通道,以通道作为列分量,每个像素都对应3列(输出通道=3),可以列出表格,按列求均值和方差,其实和全连接层一样的。即像素为样本,通道为特征。

① 这个小批量数据实随机的,算出来的统计量也可以说是随机的。
② 因为每个batch的均值和方差都不太一样。
③ 因为每次取得batch中的数据都是不同的,所以在batch中计算的均值和方差也是不同的,所以引入了随机性。

2. 总结
① 当每一个层的均值和方差都固定后,学习率太大的话,靠近loss上面的梯度太大,就梯度爆炸了,学习率太小的话,靠近数据的梯度太小了,就算不动(梯度消失)。
② 将每一层的输入放在一个差不多的分布里,就可以用一个比较大的精度了,就可以加速收敛速度。
③ 归一化不会影响数据分布,它一点都不会影响精度,变好变坏都不会。

1. 批量归一化(使用自定义)
python
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum): # X为输入,gamma、beta为学的参数。moving_mean、moving_var为全局的均值、方差。eps为避免除0的参数。momentum为更新moving_mean、moving_var的。
if not torch.is_grad_enabled(): # 'is_grad_enabled' 来判断当前模式是训练模式还是预测模式。就是在做推理的时候,推理不需要反向传播,所以不需要计算梯度
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) # 做推理时,可能只有一个图片进来,没有一个批量进来,因此这里用的全局的均值、方差。在预测中,一般用整个预测数据集的均值和方差。加eps为了避免方差为0,除以0了。
else: # 训练模式
assert len(X.shape) in (2,4) # 批量数+通道数+图片高+图片宽=4
if len(X.shape) == 2: # 2 表示2表示有两个维度,样本和特征,表示全连接层应该是:2 代表全连接层 (batch_size, feature)
mean = X.mean(dim=0) # 按行求均值,即对每一列求一个均值出来。mean为1Xn的行向量
var = ((X-mean)**2).mean(dim=0) # 方差也是行向量
else: # 4 表示卷积层
mean = X.mean(dim=(0,2,3),keepdim=True) # 0为批量大小,1为输出通道,2、3为高宽。这里是沿着通道维度求均值,0->batch内不同样本,2 3 ->同一通道层的所有值求均值,获得一个1xnx1x1的4D向量。
var = ((X-mean)**2).mean(dim=(0,2,3),keepdim=True) # 同样对批量维度、高宽取方差。每个通道的每个像素位置 计算均值方差。
X_hat = (X-mean) / torch.sqrt(var + eps) # 训练用的计算出来的均值、方差,推理用的全局的均值、方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean # 累加,将计算的均值累积到全局的均值上,更新moving_mean
moving_var = momentum * moving_var + (1.0 - momentum) * var # 当前全局的方差与当前算的方差做加权平均,最后会无限逼近真实的方差。仅训练时更新,推理时不更新。
Y = gamma * X_hat + beta # Y 为归一化后的输出
return Y, moving_mean.data, moving_var.data
python
# 创建一个正确的BatchNorm图层
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features) # num_features 为 feature map 的多少,即通道数的多少
else:
shape = (1, num_features,1,1)
self.gamma = nn.Parameter(torch.ones(shape)) # 伽马初始化为全1,贝塔初始化为全0
self.beta = nn.Parameter(torch.zeros(shape)) # 伽马为要拟合的均值,贝塔为要拟合的方差
self.moving_mean = torch.zeros(shape) # 伽马、贝塔需要在反向传播时更新,所以放在nn.Parameter里面,moving_mean、moving_var不需要迭代,所以不放在里面
self.moving_var = torch.ones(shape)
def forward(self, X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device) #
self.moving_var = self.moving_var.to(X.device)
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta,self.moving_mean,self.moving_var,
eps=1e-5,momentum=0.9)
return Y
python
# 应用BatchNorm于LeNet模型
net = nn.Sequential(nn.Conv2d(1,6,kernel_size=5),BatchNorm(6,num_dims=4), # 在第一个卷积后面加了BatchNorm
nn.Sigmoid(),nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),BatchNorm(16,num_dims=4), # BatchNorm的feature map为卷积层的输出通道数。这里BatchNorm加在激活函数前面。
nn.Sigmoid(),nn.MaxPool2d(kernel_size=2,stride=2),
nn.Flatten(),nn.Linear(16*4*4,120),
BatchNorm(120,num_dims=2),nn.Sigmoid(),
nn.Linear(120,84),BatchNorm(84,num_dims=2),
nn.Sigmoid(),nn.Linear(84,10))
python
# 在Fashion-MNIST数据集上训练网络
lr,num_epochs,batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) # 变快是指收敛所需的迭代步数变少了,但每次迭代计算量更大了呀,所以从时间上来讲跑得慢了 loss 0.249, train acc 0.909, test acc 0.846
30358.2 examples/sec on cuda:0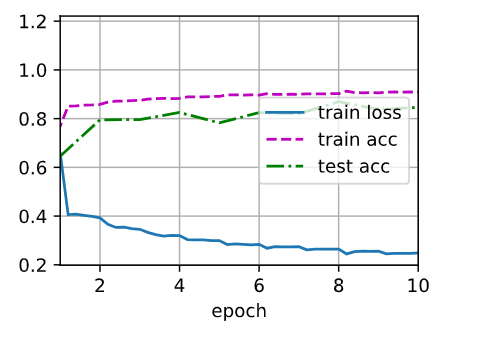
python
# 拉伸参数gamma和偏移参数beta
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))(tensor([2.0168, 1.5084, 2.6115, 2.2617, 1.2831, 1.7600], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>),
tensor([-2.1202, 0.0205, -0.1117, 1.1191, -1.5594, 0.1140], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>))2. 批量归一化(使用框架)
python
# 简洁使用
net = nn.Sequential(nn.Conv2d(1,6,kernel_size=5),nn.BatchNorm2d(6),
nn.Sigmoid(),nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.BatchNorm2d(16),
nn.Sigmoid(),nn.MaxPool2d(kernel_size=2,stride=2),
nn.Flatten(),nn.Linear(256,120),nn.BatchNorm1d(120),
nn.Sigmoid(),nn.Linear(120,84),nn.BatchNorm1d(84),
nn.Sigmoid(),nn.Linear(84,10))
python
# 使用相同超参数来训练模型
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.253, train acc 0.908, test acc 0.861
56499.2 examples/sec on cuda:0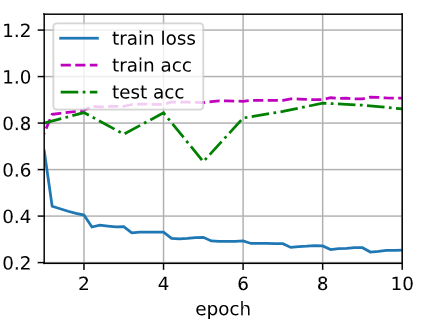
先搞懂:BatchNorm 到底是干啥的?
简单说:深度神经网络一层叠一层,前面层的参数一变,输出数据的「分布」(大概就是数据的平均大小、波动幅度)就会跟着变,后面的层就得不停适应新的数据尺度,训练起来又慢又容易崩。
BatchNorm 就是给每一层的输入「掰正一下」:先把数据拉到平均值为 0、波动幅度为 1的标准尺度,再给网络两个可调节的旋钮,让它自己微调回去。这样每一层的输入分布都很稳定,训练又快又稳。
打个比方:就像每次考试完,老师先把全班分数调成平均分 0、分差 1 的标准分,再根据难度整体加分 / 减分、调整分数拉开的程度,让每次考试的分数都在差不多的范围里,方便后续排名和教学。
先认清楚函数的每个参数
python
运行
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
X:当前这一层的输入数据,就是要被「掰正」的原始数据gamma、beta:网络要学习的两个可调旋钮
gamma:缩放旋钮,控制归一化后数据的波动幅度beta:偏移旋钮,控制归一化后数据的整体平均值moving_mean、moving_var:全局累计的平均值和方差,是训练过程中慢慢攒出来的「全数据集统计值」,预测 / 推理的时候用eps:一个特别小的数(一般是 1e-5),纯保底用的,防止方差是 0 的时候除以 0 出错momentum:动量系数,控制全局统计值的更新速度,越大更新越慢、越平稳
核心逻辑:分「训练模式」和「推理模式」两套玩法
BatchNorm 最关键的点就是:训练和预测用的均值、方差不一样。代码里第一个判断就是干这个的。
1. 推理 / 预测模式:用全局统计值
python
运行
if not torch.is_grad_enabled(): X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
torch.is_grad_enabled()是判断当前开没开梯度计算。推理的时候不需要反向传播,梯度是关着的,就会走进这个分支。- 推理时直接用训练时攒好的全局平均值 moving_mean 和 全局方差 moving_var 来归一化。
为什么不用当前输入自己算均值? 因为推理的时候可能只进来 1 张图片,单张图算出来的均值方差毫无代表性。用训练时攒的整个数据集的统计值,结果才稳定、才符合训练时的逻辑。 就像你不能拿一个人的分数来算标准分,得用全年级平时累计的平均分才算数。
2. 训练模式:用当前批次(batch)的统计值
走进
else分支就是训练模式,这时候用当前这一批数据自己算均值和方差。第一步:先判断输入是全连接层还是卷积层
python
运行
assert len(X.shape) in (2,4)断言输入的维度要么是 2 维(全连接层),要么是 4 维(卷积层),别的维度直接报错。
- 2 维形状:
[批次大小, 特征数量],比如 32 个样本,每个样本 128 个特征 →[32, 128]- 4 维形状:
[批次大小, 通道数, 高度, 宽度],比如 32 张图,16 个通道,28×28 像素 →[32, 16, 28, 28]第二步:分情况算当前批次的均值和方差
情况 A:全连接层(2 维)
python
运行
if len(X.shape) == 2: mean = X.mean(dim=0) var = ((X-mean)**2).mean(dim=0)
dim=0就是沿着「批次」这个维度求平均。- 大白话:每一个特征,在整个批次里算平均值和方差。 比如 32 个学生、10 道题,就会算出 10 个均值、10 个方差,每道题对应一个全班的平均分和分数波动。
情况 B:卷积层(4 维)
python
运行
else: mean = X.mean(dim=(0,2,3), keepdim=True) var = ((X-mean)**2).mean(dim=(0,2,3), keepdim=True)
dim=(0,2,3)就是把「批次维度 0、高度维度 2、宽度维度 3」这三个维度都求平均,只保留「通道维度 1」。- 大白话:每一个通道,把整个批次里、所有像素位置的值都拉出来,算一个总的平均值和方差。 比如 32 张图、16 个通道、28×28 像素,就会算出 16 个均值、16 个方差,每个通道对应一个。 你可以理解成:16 个通道相当于 16 种不同的「特征滤镜」,每个滤镜单独算自己的平均分,和像素位置、哪张图都没关系。
keepdim=True是保持 4 维的形状,方便后面和原始 X 做广播计算。第三步:用当前批次的均值方差做归一化
python
运行
X_hat = (X-mean) / torch.sqrt(var + eps)原始数据减去均值,再除以标准差(方差开根号),拉成均值 0、方差 1 的标准分布。加 eps 就是怕方差是 0,除以 0 报错。
第四步:更新全局统计值
python
运行
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean moving_var = momentum * moving_var + (1.0 - momentum) * var这就是「滑动平均更新」,大白话就是: 新的全局均值 = 大部分保留旧的全局均值,小部分掺入当前批次的均值。 比如
momentum=0.9,那就是 90% 旧值 + 10% 新值,慢慢滚雪球,越攒越接近整个数据集的真实均值。 训练的时候每进来一个 batch 就更新一次,推理的时候就不动这俩值了。
最后一步:缩放 + 偏移,给网络留调整空间
python
运行
Y = gamma * X_hat + beta return Y, moving_mean.data, moving_var.data归一化之后,不是直接输出,而是用
gamma乘一下(缩放),再加beta(偏移)。为什么要多这一步? 如果硬把所有数据都强制拉成均值 0、方差 1,可能会把网络好不容易学到的特征给抹掉了。比如某一层的特征本来偏移一点效果更好,归一化就给掰没了。
所以给网络两个可学习的参数
gamma和beta,让它自己决定:要不要缩放、要不要偏移。如果归一化不好,它可以学成gamma=1、beta=0,就等于没做归一化;如果需要调整,它自己学合适的数值。 相当于:我先给你掰正了,但给你留了反悔 / 微调的权利。最后返回三个东西:
- 归一化 + 缩放偏移后的最终结果
Y- 更新后的全局均值、方差(给下一个 batch 继续用) 用
.data是因为这俩值不需要算梯度,就是纯统计值。
几个最容易懵的点,一句话说透
为什么训练和推理要用不同的均值方差? 训练的时候一个 batch 一个 batch 来,用当前 batch 的统计值,既能归一化,还能带点噪声,相当于轻微的正则化,防止过拟合。 推理的时候要结果稳定,不能输入 1 张图和输入 10 张图结果不一样,所以用训练攒好的全局统计值。
gamma 和 beta 是必须的吗? 必须有。没有的话,每一层的输出都被强制成均值 0 方差 1,网络的表达能力会大幅下降。这俩参数让 BN 既能稳定分布,又不丢失网络的特征表达能力。
momentum 动量是干嘛的? 控制全局统计值的更新速度。越大,旧值占比越高,更新越慢,结果越平稳;越小,新 batch 的影响越大,更新越快。一般默认 0.9 左右。
3.残差神经网络ResNet
1. ResNet网络
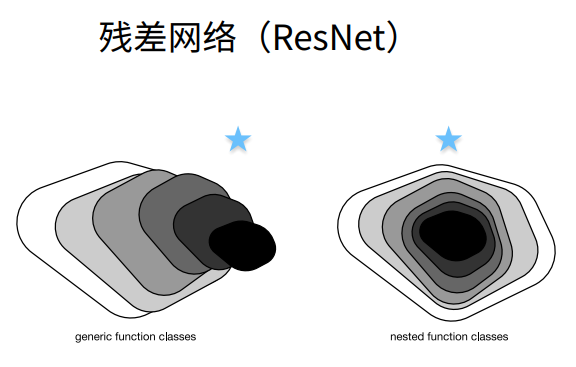
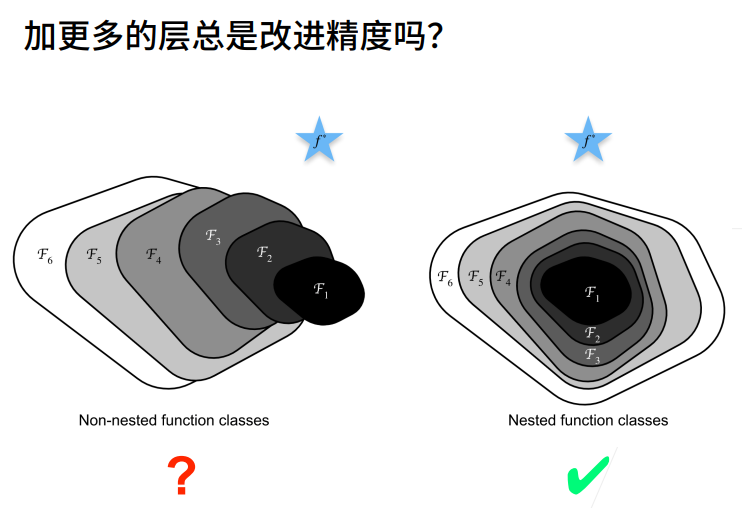
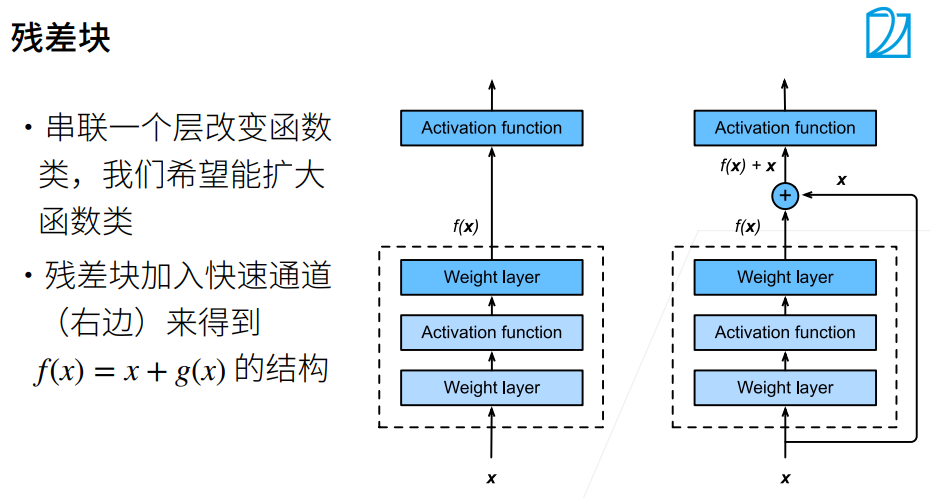
① 这样直接加保证了最优解"至少不会变差",g(x)=0是和以前一样的。假设没有学到任何东西,则g(x)为0。
② 这个x实际上是f0(x),就是上幅图小的部分,f(x)是f1(x),新函数包含原函数。
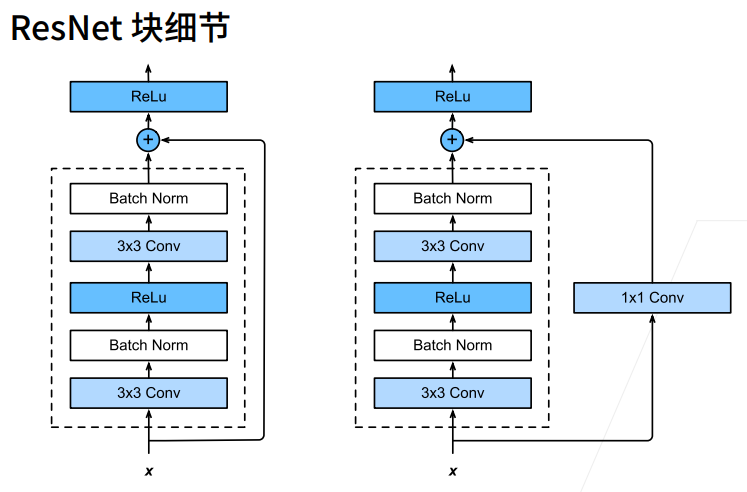
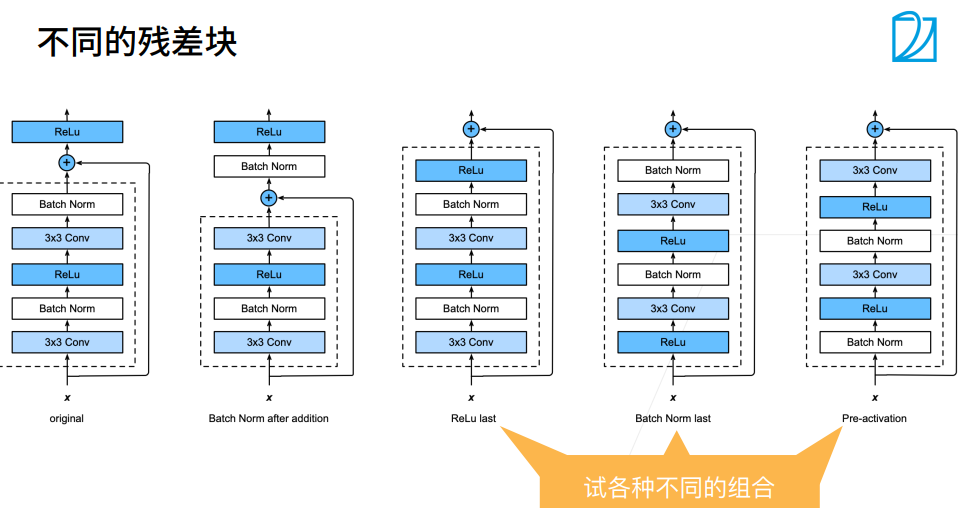
① g(x)高宽减半的同时,1x1 conv的strides=2,也把x高宽减半了。
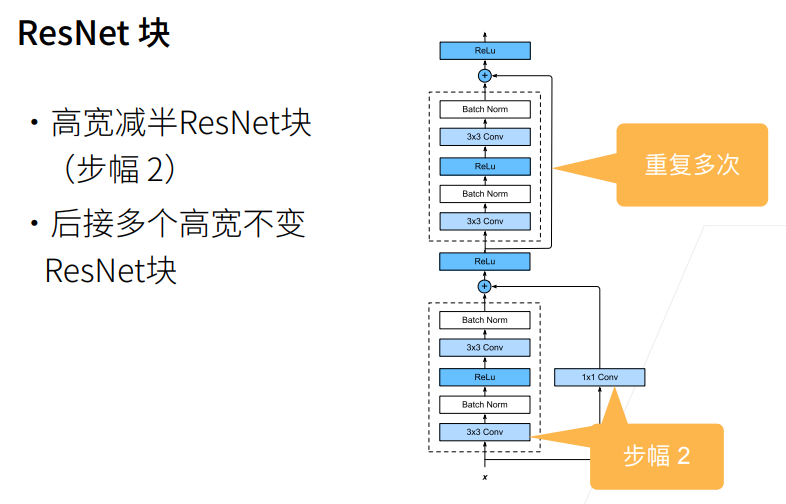
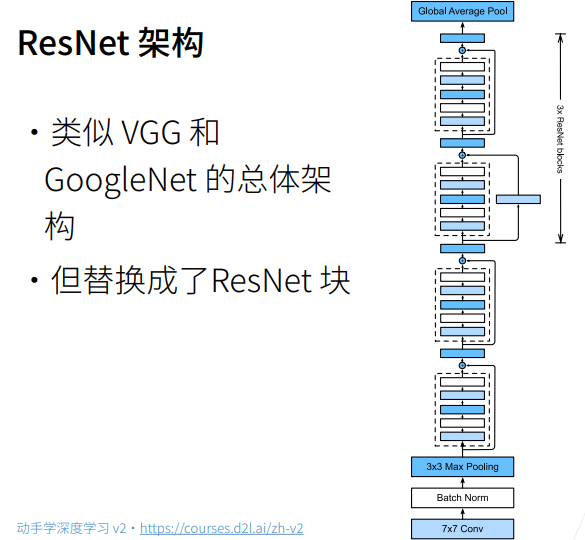
2. 总结

1. ResNet网络(使用自定义)
python
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual (nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,strides=1): # num_channels为输出channel数
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides) # 可以使用传入进来的strides
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) # 使用nn.Conv2d默认的strides=1
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True) # inplace原地操作,不创建新变量,对原变量操作,节约内存
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
python
# 输入和输出形状一致
blk = Residual(3,3) # 输入三通道,输出三通道
X = torch.rand(4,3,6,6)
Y = blk(X) # stride用的默认的1,所以宽高没有变化。如果strides用2,则宽高减半
Y.shapetorch.Size([4, 3, 6, 6])
python
# 增加输出通道数的同时,减半输出的高和宽
blk = Residual(3,6,use_1x1conv=True,strides=2) # 由3变为6,通道数加倍
blk(X).shapetorch.Size([4, 6, 3, 3])
python
# ResNet的第一个stage
b1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
# class Residual为小block,resnet_block 为大block,为Resnet网络的一个stage
def resnet_block(input_channels,num_channels,num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block: # stage中不是第一个block则高宽减半
blk.append(Residual(input_channels, num_channels, use_1x1conv=True,strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True)) # 因为b1做了两次宽高减半,nn.Conv2d、nn.MaxPool2d,所以b2中的首次就不减半了
b3 = nn.Sequential(*resnet_block(64,128,2)) # b3、b4、b5的首次卷积层都减半
b4 = nn.Sequential(*resnet_block(128,256,2))
b5 = nn.Sequential(*resnet_block(256,512,2))
net = nn.Sequential(b1,b2,b3,b4,b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(),nn.Linear(512,10))
python
# 观察一下ReNet中不同模块的输入形状是如何变化的
X = torch.rand(size=(1,1,224,224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape) # 通道数翻倍、模型减半Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
python
# 训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.009, train acc 0.998, test acc 0.921
2166.7 examples/sec on cuda:0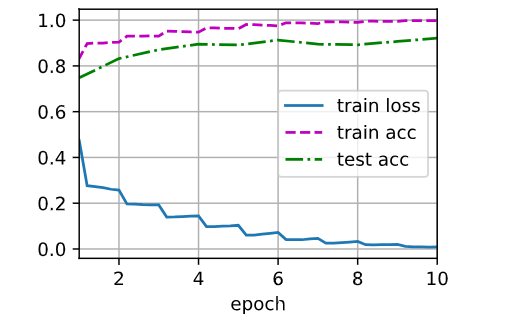
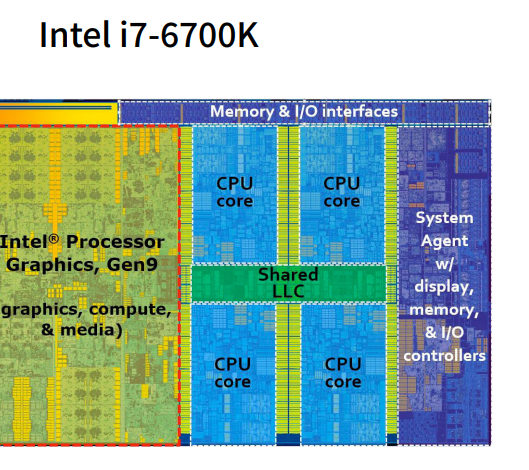
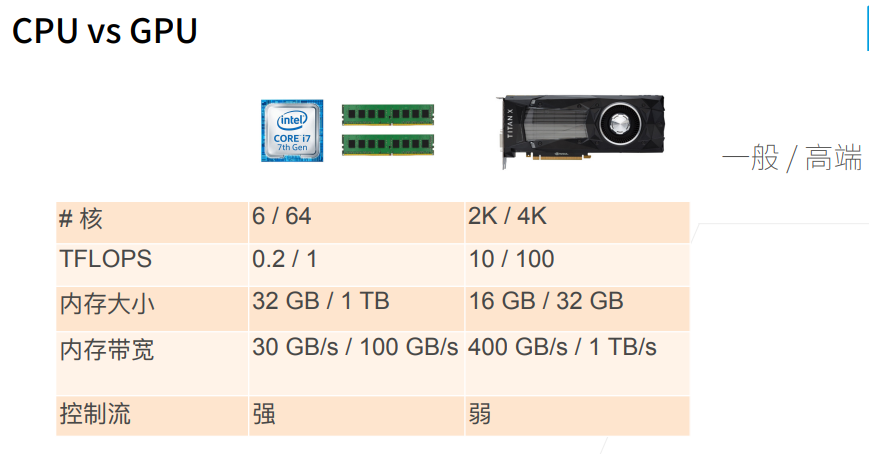
4. CPU和GPU










2. 总结

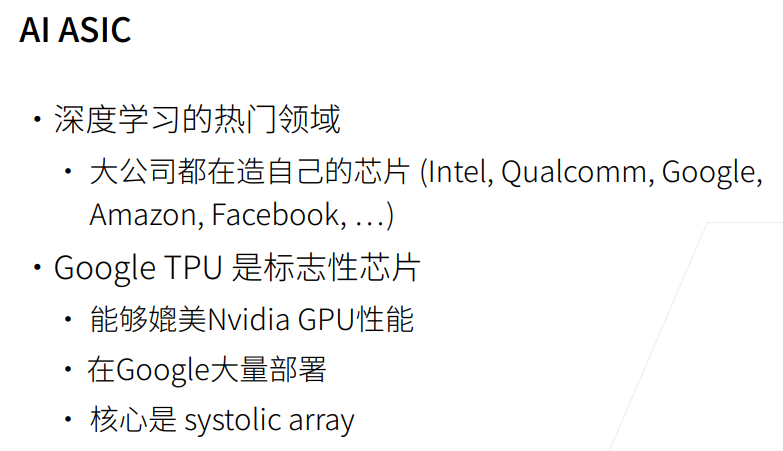
5. 深度学习硬件TPU和其他




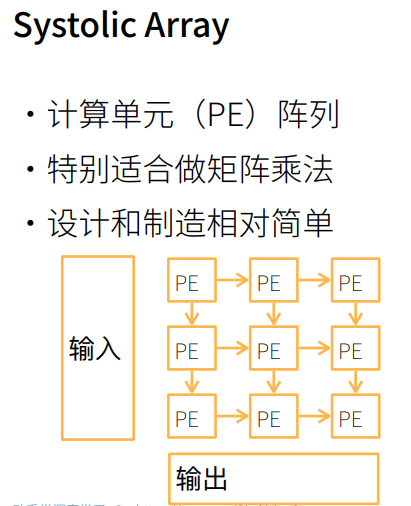
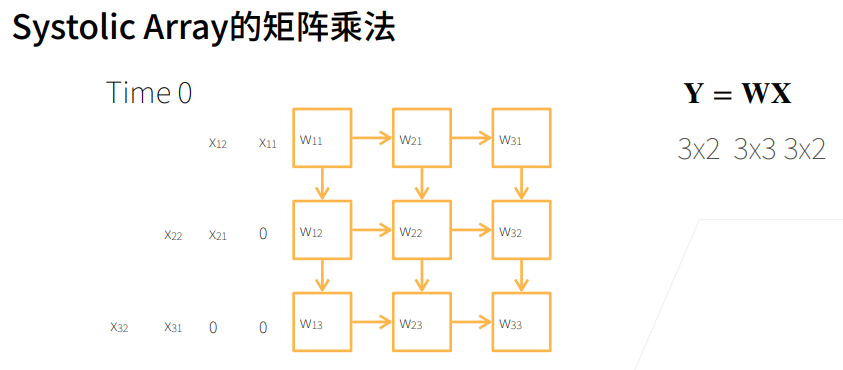
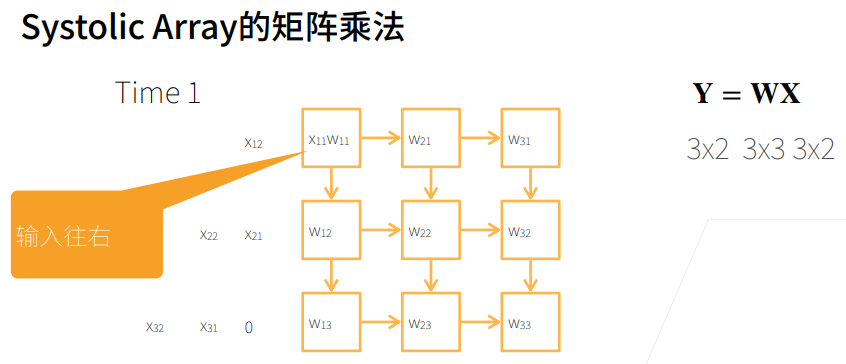
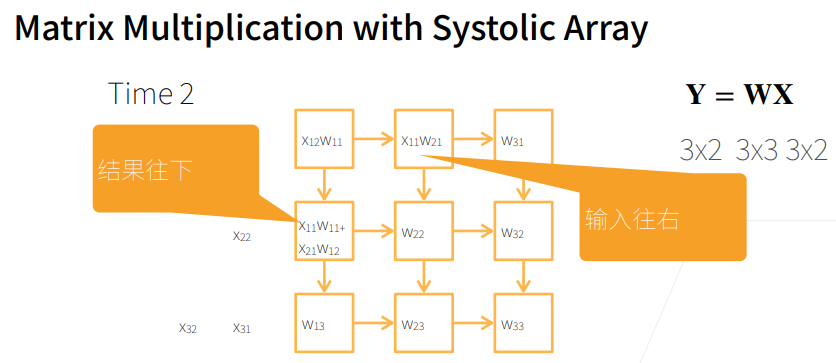

2. 总结

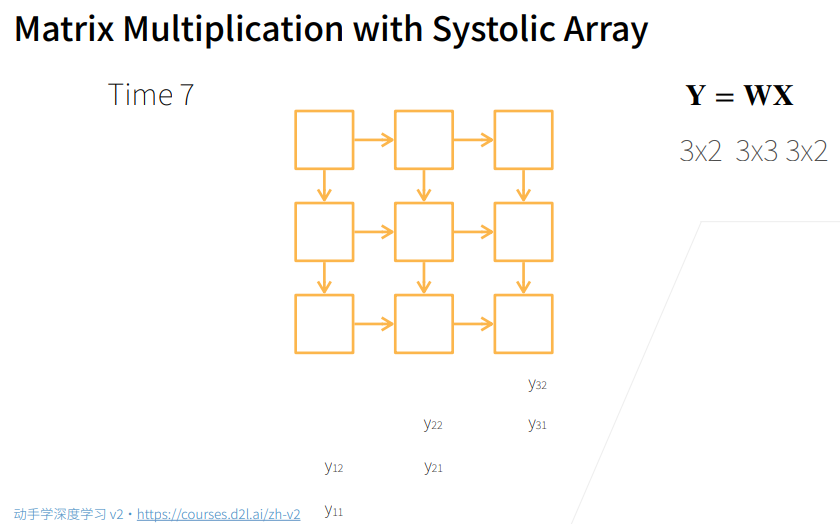
6. 单机多卡并行


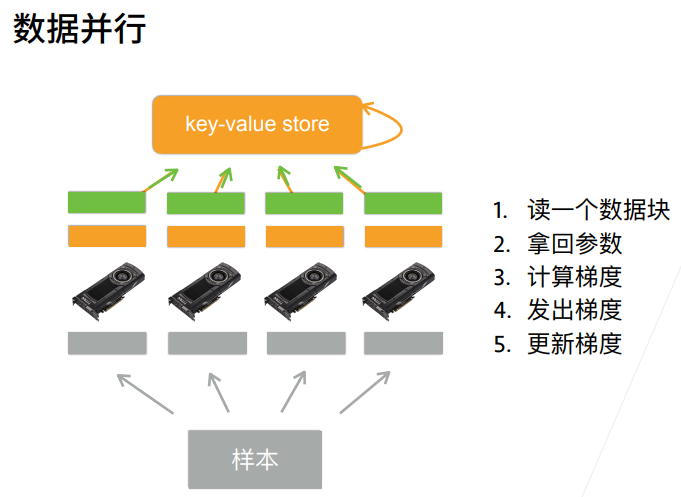
2. 总结

7. 多GPU训练
python
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
W = torch.randn(size=(3,4)) # 从标准正态分布(均值为0,方差为1)中抽取的一组随机数。
scale = 0.01
print(W * scale)
tensor([[-0.0241, -0.0077, 0.0035, 0.0003],
[-0.0109, 0.0084, 0.0114, 0.0123],
[ 0.0036, -0.0087, 0.0080, 0.0018]])
# 简单网络
scale = 0.01
W1 = torch.randn(size=(20,1,3,3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50,20,5,5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800,128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128,10)) * scale
b4 = torch.zeros(10)
params = [W1,b1,W2,b2,W3,b3,W4,b4]
def lenet(X, params):
h1_conv = F.conv2d(input=X, weight=params[0],bias=params[1])
h1_activation = F.relu(h1_conv)
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2,2), stride=(2,2))
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
h2_activation = F.relu(h2_conv)
h2 = F.avg_pool2d(input=h2_activation,kernel_size=(2,2),stride=(2,2))
h2 = h2.reshape(h2.shape[0],-1)
h3_linear = torch.mm(h2, params[4]) + params[5]
h3 = F.relu(h3_linear)
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
loss = nn.CrossEntropyLoss(reduction='none')
python
# 向多个设备分发参数
def get_params(params, device):
new_params = [p.clone().to(device) for p in params] # 把params中所有参数挪到GPU上
for p in new_params:
p.requires_grad_() # 每一个参数都要计算梯度
return new_params
python
new_params = get_params(params, d2l.try_gpu(0))
print('b1 weight:', new_params[1])
print('b1 grad:', new_params[1].grad)b1 weight: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', requires_grad=True)
b1 grad: None
python
# allreduce函数将所有向量相加,并将结果广播给所有GPU
def allreduce(data): # 如果有四个GPU的话,data这个list里面就有四个元素
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device) # 把其余三个GPU上元素,拷贝到0号GPU上
for i in range(1, len(data)):
data[i] = data[0].to(data[i].device) # 把相加后的结果复制回所有GPU上
data = [torch.ones((1,2),device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('before allreduce:\n', data[0], '\n', data[1])
allreduce(data) # allreduce函数可以用于各个GPU的梯度加起来,然后各个GPU拿到合梯度
print('before allreduce:\n', data[0], '\n', data[1])before allreduce:
tensor([[1., 1.]], device='cuda:0')
tensor([[2., 2.]])
before allreduce:
tensor([[3., 3.]], device='cuda:0')
tensor([[3., 3.]])
python
# 将一个小批量数据均匀地分布在多个GPU上
data = torch.arange(20).reshape(4,5)
devices = [torch.device('cuda:0'),torch.device('cuda:1')]
print('input:',data)
print('load into',devices)
split = nn.parallel.scatter(data,devices) # 将data均匀的切开,放到不同的GPU上
print('output:',split)input: tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
load into [device(type='cuda', index=0), device(type='cuda', index=1)]---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-6-67c72ea6039f> in <module>
4 print('input:',data)
5 print('load into',devices)
----> 6 split = nn.parallel.scatter(data,devices) # 将data均匀的切开,放到不同的GPU上
7 print('output:',split)
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\scatter_gather.py in scatter(inputs, target_gpus, dim)
34 # None, clearing the cell
35 try:
---> 36 res = scatter_map(inputs)
37 finally:
38 scatter_map = None
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\scatter_gather.py in scatter_map(obj)
17 def scatter_map(obj):
18 if isinstance(obj, torch.Tensor):
---> 19 return Scatter.apply(target_gpus, None, dim, obj)
20 if is_namedtuple(obj):
21 return [type(obj)(*args) for args in zip(*map(scatter_map, obj))]
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\_functions.py in forward(ctx, target_gpus, chunk_sizes, dim, input)
93 if torch.cuda.is_available() and ctx.input_device == -1:
94 # Perform CPU to GPU copies in a background stream
---> 95 streams = [_get_stream(device) for device in target_gpus]
96 outputs = comm.scatter(input, target_gpus, chunk_sizes, ctx.dim, streams)
97 # Synchronize with the copy stream
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\_functions.py in <listcomp>(.0)
93 if torch.cuda.is_available() and ctx.input_device == -1:
94 # Perform CPU to GPU copies in a background stream
---> 95 streams = [_get_stream(device) for device in target_gpus]
96 outputs = comm.scatter(input, target_gpus, chunk_sizes, ctx.dim, streams)
97 # Synchronize with the copy stream
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\_functions.py in _get_stream(device)
120 if _streams is None:
121 _streams = [None] * torch.cuda.device_count()
--> 122 if _streams[device] is None:
123 _streams[device] = torch.cuda.Stream(device)
124 return _streams[device]
IndexError: list index out of range
python
def split_batch(X, y, devices):
"""将X和y拆分到多个设备上"""
assert X.shape[0] == y.shape[0] # 确定样本数与标号数是一样的
return (nn.parallel.scatter(X, devices), nn.parallel.scatter(y, devices)) # 样本与标号都均匀分布到不同GPU上
python
# 在一个小批量上实现多GPU训练
def train_batch(X, y, device_params, devices, lr):
X_shards, y_shards = split_batch(X, y, devices) # 把X,y分到不同GPU上
# 拿到每一个GPU上的X_shard、y_shard以及对应的device_W
# sum是对每一个GPU上所有样本的损失求和
# ls返回的是每一个GPU上对应的损失
ls = [loss(lenet(X_shard, device_W),y_shard).sum()
for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]
for l in ls:
l.backward() # 对每一个GPU的loss做负反馈,算梯度
with torch.no_grad():
for i in range(len(device_params[0])):
# i是层,c是GPU
allreduce([device_params[c][i].grad for c in range(len(devices))])
for param in device_params: # 拿到所有梯度后,对每一个GPU做SGD
d2l.sgd(param, lr, X.shape[0])
python
# 训练
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)] # 创建多少个GPU
device_params = [get_params(params, d) for d in devices] # 初始化的params复制到每个GPU上
num_epochs = 10
animator = d2l.Animator('epoch','test acc',xlim=[1,num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize() # 等待所有的GPU算完
timer.stop()
animator.add(epoch+1,(d2l.evaluate_accuracy_gpu(
lambda x: lenet(x,device_params[0]),test_iter,devices[0]),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch'
f'on {str(devices)}')
python
help(torch.cuda.synchronize)Help on function synchronize in module torch.cuda:
synchronize(device:Union[torch.device, str, int, NoneType]=None) -> None
Waits for all kernels in all streams on a CUDA device to complete.
Args:
device (torch.device or int, optional): device for which to synchronize.
It uses the current device, given by :func:`~torch.cuda.current_device`,
if :attr:`device` is ``None`` (default).
python
# 在单个GPU上运行
train(num_gpus=1, batch_size=256, lr=0.2)test acc: 0.84, 3.7 sec/epochon [device(type='cuda', index=0)]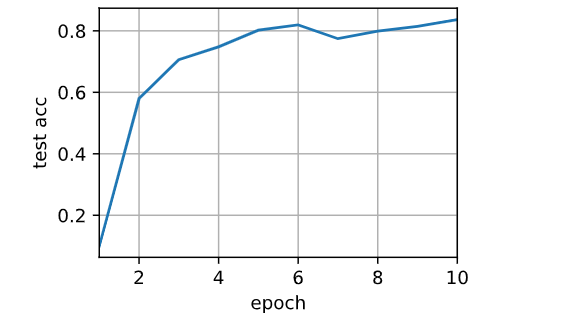
python
# 增加为2个GPU
train(num_gpus=2, batch_size=256, lr=0.2) # 本电脑只有一个GPU,呜呜呜呜---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-12-ef7689592cb4> in <module>
1 # 增加为2个GPU
----> 2 train(num_gpus=2, batch_size=256, lr=0.2) # 本电脑只有一个GPU,呜呜呜呜
<ipython-input-9-ddae8883987e> in train(num_gpus, batch_size, lr)
10 timer.start()
11 for X, y in train_iter:
---> 12 train_batch(X, y, device_params, devices, lr)
13 torch.cuda.synchronize() # 等待所有的GPU算完
14 timer.stop()
<ipython-input-8-055fd69e9627> in train_batch(X, y, device_params, devices, lr)
1 # 在一个小批量上实现多GPU训练
2 def train_batch(X, y, device_params, devices, lr):
----> 3 X_shards, y_shards = split_batch(X, y, devices) # 把X,y分到不同GPU上
4 # 拿到每一个GPU上的X_shard、y_shard以及对应的device_W
5 # sum是对每一个GPU上所有样本的损失求和
<ipython-input-7-82122d5c5691> in split_batch(X, y, devices)
2 """将X和y拆分到多个设备上"""
3 assert X.shape[0] == y.shape[0] # 确定样本数与标号数是一样的
----> 4 return (nn.parallel.scatter(X, devices), nn.parallel.scatter(y, devices)) # 样本与标号都均匀分布到不同GPU上
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\scatter_gather.py in scatter(inputs, target_gpus, dim)
34 # None, clearing the cell
35 try:
---> 36 res = scatter_map(inputs)
37 finally:
38 scatter_map = None
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\scatter_gather.py in scatter_map(obj)
17 def scatter_map(obj):
18 if isinstance(obj, torch.Tensor):
---> 19 return Scatter.apply(target_gpus, None, dim, obj)
20 if is_namedtuple(obj):
21 return [type(obj)(*args) for args in zip(*map(scatter_map, obj))]
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\_functions.py in forward(ctx, target_gpus, chunk_sizes, dim, input)
87 @staticmethod
88 def forward(ctx, target_gpus, chunk_sizes, dim, input):
---> 89 target_gpus = [_get_device_index(x, True) for x in target_gpus]
90 ctx.dim = dim
91 ctx.input_device = input.get_device() if input.device.type != "cpu" else -1
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\_functions.py in <listcomp>(.0)
87 @staticmethod
88 def forward(ctx, target_gpus, chunk_sizes, dim, input):
---> 89 target_gpus = [_get_device_index(x, True) for x in target_gpus]
90 ctx.dim = dim
91 ctx.input_device = input.get_device() if input.device.type != "cpu" else -1
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\_utils.py in _get_device_index(device, optional, allow_cpu)
495 if isinstance(device, torch.device):
496 if not allow_cpu and device.type == 'cpu':
--> 497 raise ValueError('Expected a non cpu device, but got: {}'.format(device))
498 device_idx = -1 if device.type == 'cpu' else device.index
499 if isinstance(device, int):
ValueError: Expected a non cpu device, but got: cpub'\r\n\r\n\r\n
2. 多GPU的简洁实现
python
import torch
from torch import nn
from d2l import torch as d2l
python
def resnet18(num_classes, in_channels=1):
"""稍加修改的ResNet-18模型"""
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(d2l.Residual(in_channels, out_channels, use_1x1conv=True,strides=2))
else:
blk.append(d2l.Residual(out_channels,out_channels))
return nn.Sequential(*blk)
net = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU())
net.add_module("resnet_block1", resnet_block(64,64,2,first_block=True))
net.add_module("resnet_block2", resnet_block(64,128,2))
net.add_module("resnet_block3", resnet_block(128,256,2))
net.add_module("resnet_block4", resnet_block(256,512,2))
net.add_module("resnet_avg_pool", nn.AdaptiveAvgPool2d((1,1)))
net.add_module("fc", nn.Sequential(nn.Flatten(), nn.Linear(512, num_classes)))
return net
net = resnet18(10)
devices = d2l.try_all_gpus()
python
# 训练
def train(net, num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# nn.DataParallel会的是X切开并行到各个GPU上,并行算梯度,然后loss加起来,它重新定义了net的forward函数
net = nn.DataParallel(net, device_ids=devices) # net会复制到每一个GPU上
trainer = torch.optim.SGD(net.parameters(),lr)
loss = nn.CrossEntropyLoss()
timer, num_epochs = d2l.Timer(), 10
animator = d2l.Animator('epoch','test acc', xlim=[1, num_epochs])
for epoch in range(num_epochs):
net.train()
timer.start()
for X, y in train_iter:
trainer.zero_grad()
X, y = X.to(devices[0]), y.to(devices[0])
l = loss(net(X), y)
l.backward()
trainer.step()
timer.stop()
animator.add(epoch+1, (d2l.evaluate_accuracy_gpu(net, test_iter),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch'
f'on {str(devices)}')
python
help(nn.DataParallel)Help on class DataParallel in module torch.nn.parallel.data_parallel:
class DataParallel(torch.nn.modules.module.Module)
| Implements data parallelism at the module level.
|
| This container parallelizes the application of the given :attr:`module` by
| splitting the input across the specified devices by chunking in the batch
| dimension (other objects will be copied once per device). In the forward
| pass, the module is replicated on each device, and each replica handles a
| portion of the input. During the backwards pass, gradients from each replica
| are summed into the original module.
|
| The batch size should be larger than the number of GPUs used.
|
| .. warning::
| It is recommended to use :class:`~torch.nn.parallel.DistributedDataParallel`,
| instead of this class, to do multi-GPU training, even if there is only a single
| node. See: :ref:`cuda-nn-ddp-instead` and :ref:`ddp`.
|
| Arbitrary positional and keyword inputs are allowed to be passed into
| DataParallel but some types are specially handled. tensors will be
| **scattered** on dim specified (default 0). tuple, list and dict types will
| be shallow copied. The other types will be shared among different threads
| and can be corrupted if written to in the model's forward pass.
|
| The parallelized :attr:`module` must have its parameters and buffers on
| ``device_ids[0]`` before running this :class:`~torch.nn.DataParallel`
| module.
|
| .. warning::
| In each forward, :attr:`module` is **replicated** on each device, so any
| updates to the running module in ``forward`` will be lost. For example,
| if :attr:`module` has a counter attribute that is incremented in each
| ``forward``, it will always stay at the initial value because the update
| is done on the replicas which are destroyed after ``forward``. However,
| :class:`~torch.nn.DataParallel` guarantees that the replica on
| ``device[0]`` will have its parameters and buffers sharing storage with
| the base parallelized :attr:`module`. So **in-place** updates to the
| parameters or buffers on ``device[0]`` will be recorded. E.g.,
| :class:`~torch.nn.BatchNorm2d` and :func:`~torch.nn.utils.spectral_norm`
| rely on this behavior to update the buffers.
|
| .. warning::
| Forward and backward hooks defined on :attr:`module` and its submodules
| will be invoked ``len(device_ids)`` times, each with inputs located on
| a particular device. Particularly, the hooks are only guaranteed to be
| executed in correct order with respect to operations on corresponding
| devices. For example, it is not guaranteed that hooks set via
| :meth:`~torch.nn.Module.register_forward_pre_hook` be executed before
| `all` ``len(device_ids)`` :meth:`~torch.nn.Module.forward` calls, but
| that each such hook be executed before the corresponding
| :meth:`~torch.nn.Module.forward` call of that device.
|
| .. warning::
| When :attr:`module` returns a scalar (i.e., 0-dimensional tensor) in
| :func:`forward`, this wrapper will return a vector of length equal to
| number of devices used in data parallelism, containing the result from
| each device.
|
| .. note::
| There is a subtlety in using the
| ``pack sequence -> recurrent network -> unpack sequence`` pattern in a
| :class:`~torch.nn.Module` wrapped in :class:`~torch.nn.DataParallel`.
| See :ref:`pack-rnn-unpack-with-data-parallelism` section in FAQ for
| details.
|
|
| Args:
| module (Module): module to be parallelized
| device_ids (list of int or torch.device): CUDA devices (default: all devices)
| output_device (int or torch.device): device location of output (default: device_ids[0])
|
| Attributes:
| module (Module): the module to be parallelized
|
| Example::
|
| >>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
| >>> output = net(input_var) # input_var can be on any device, including CPU
|
| Method resolution order:
| DataParallel
| torch.nn.modules.module.Module
| builtins.object
|
| Methods defined here:
|
| __init__(self, module, device_ids=None, output_device=None, dim=0)
| Initializes internal Module state, shared by both nn.Module and ScriptModule.
|
| forward(self, *inputs, **kwargs)
| Defines the computation performed at every call.
|
| Should be overridden by all subclasses.
|
| .. note::
| Although the recipe for forward pass needs to be defined within
| this function, one should call the :class:`Module` instance afterwards
| instead of this since the former takes care of running the
| registered hooks while the latter silently ignores them.
|
| gather(self, outputs, output_device)
|
| parallel_apply(self, replicas, inputs, kwargs)
|
| replicate(self, module, device_ids)
|
| scatter(self, inputs, kwargs, device_ids)
|
| ----------------------------------------------------------------------
| Methods inherited from torch.nn.modules.module.Module:
|
| __call__ = _call_impl(self, *input, **kwargs)
|
| __delattr__(self, name)
| Implement delattr(self, name).
|
| __dir__(self)
| __dir__() -> list
| default dir() implementation
|
| __getattr__(self, name:str) -> Union[torch.Tensor, _ForwardRef('Module')]
|
| __repr__(self)
| Return repr(self).
|
| __setattr__(self, name:str, value:Union[torch.Tensor, _ForwardRef('Module')]) -> None
| Implement setattr(self, name, value).
|
| __setstate__(self, state)
|
| add_module(self, name:str, module:Union[_ForwardRef('Module'), NoneType]) -> None
| Adds a child module to the current module.
|
| The module can be accessed as an attribute using the given name.
|
| Args:
| name (string): name of the child module. The child module can be
| accessed from this module using the given name
| module (Module): child module to be added to the module.
|
| apply(self:~T, fn:Callable[[_ForwardRef('Module')], NoneType]) -> ~T
| Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
| as well as self. Typical use includes initializing the parameters of a model
| (see also :ref:`nn-init-doc`).
|
| Args:
| fn (:class:`Module` -> None): function to be applied to each submodule
|
| Returns:
| Module: self
|
| Example::
|
| >>> @torch.no_grad()
| >>> def init_weights(m):
| >>> print(m)
| >>> if type(m) == nn.Linear:
| >>> m.weight.fill_(1.0)
| >>> print(m.weight)
| >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
| >>> net.apply(init_weights)
| Linear(in_features=2, out_features=2, bias=True)
| Parameter containing:
| tensor([[ 1., 1.],
| [ 1., 1.]])
| Linear(in_features=2, out_features=2, bias=True)
| Parameter containing:
| tensor([[ 1., 1.],
| [ 1., 1.]])
| Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
| Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
|
| bfloat16(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``bfloat16`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| buffers(self, recurse:bool=True) -> Iterator[torch.Tensor]
| Returns an iterator over module buffers.
|
| Args:
| recurse (bool): if True, then yields buffers of this module
| and all submodules. Otherwise, yields only buffers that
| are direct members of this module.
|
| Yields:
| torch.Tensor: module buffer
|
| Example::
|
| >>> for buf in model.buffers():
| >>> print(type(buf), buf.size())
| <class 'torch.Tensor'> (20L,)
| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
|
| children(self) -> Iterator[_ForwardRef('Module')]
| Returns an iterator over immediate children modules.
|
| Yields:
| Module: a child module
|
| cpu(self:~T) -> ~T
| Moves all model parameters and buffers to the CPU.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| cuda(self:~T, device:Union[int, torch.device, NoneType]=None) -> ~T
| Moves all model parameters and buffers to the GPU.
|
| This also makes associated parameters and buffers different objects. So
| it should be called before constructing optimizer if the module will
| live on GPU while being optimized.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| device (int, optional): if specified, all parameters will be
| copied to that device
|
| Returns:
| Module: self
|
| double(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``double`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| eval(self:~T) -> ~T
| Sets the module in evaluation mode.
|
| This has any effect only on certain modules. See documentations of
| particular modules for details of their behaviors in training/evaluation
| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
| etc.
|
| This is equivalent with :meth:`self.train(False) <torch.nn.Module.train>`.
|
| See :ref:`locally-disable-grad-doc` for a comparison between
| `.eval()` and several similar mechanisms that may be confused with it.
|
| Returns:
| Module: self
|
| extra_repr(self) -> str
| Set the extra representation of the module
|
| To print customized extra information, you should re-implement
| this method in your own modules. Both single-line and multi-line
| strings are acceptable.
|
| float(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``float`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| get_buffer(self, target:str) -> 'Tensor'
| Returns the buffer given by ``target`` if it exists,
| otherwise throws an error.
|
| See the docstring for ``get_submodule`` for a more detailed
| explanation of this method's functionality as well as how to
| correctly specify ``target``.
|
| Args:
| target: The fully-qualified string name of the buffer
| to look for. (See ``get_submodule`` for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.Tensor: The buffer referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not a
| buffer
|
| get_extra_state(self) -> Any
| Returns any extra state to include in the module's state_dict.
| Implement this and a corresponding :func:`set_extra_state` for your module
| if you need to store extra state. This function is called when building the
| module's `state_dict()`.
|
| Note that extra state should be pickleable to ensure working serialization
| of the state_dict. We only provide provide backwards compatibility guarantees
| for serializing Tensors; other objects may break backwards compatibility if
| their serialized pickled form changes.
|
| Returns:
| object: Any extra state to store in the module's state_dict
|
| get_parameter(self, target:str) -> 'Parameter'
| Returns the parameter given by ``target`` if it exists,
| otherwise throws an error.
|
| See the docstring for ``get_submodule`` for a more detailed
| explanation of this method's functionality as well as how to
| correctly specify ``target``.
|
| Args:
| target: The fully-qualified string name of the Parameter
| to look for. (See ``get_submodule`` for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.nn.Parameter: The Parameter referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not an
| ``nn.Parameter``
|
| get_submodule(self, target:str) -> 'Module'
| Returns the submodule given by ``target`` if it exists,
| otherwise throws an error.
|
| For example, let's say you have an ``nn.Module`` ``A`` that
| looks like this:
|
| .. code-block::text
|
| A(
| (net_b): Module(
| (net_c): Module(
| (conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2))
| )
| (linear): Linear(in_features=100, out_features=200, bias=True)
| )
| )
|
| (The diagram shows an ``nn.Module`` ``A``. ``A`` has a nested
| submodule ``net_b``, which itself has two submodules ``net_c``
| and ``linear``. ``net_c`` then has a submodule ``conv``.)
|
| To check whether or not we have the ``linear`` submodule, we
| would call ``get_submodule("net_b.linear")``. To check whether
| we have the ``conv`` submodule, we would call
| ``get_submodule("net_b.net_c.conv")``.
|
| The runtime of ``get_submodule`` is bounded by the degree
| of module nesting in ``target``. A query against
| ``named_modules`` achieves the same result, but it is O(N) in
| the number of transitive modules. So, for a simple check to see
| if some submodule exists, ``get_submodule`` should always be
| used.
|
| Args:
| target: The fully-qualified string name of the submodule
| to look for. (See above example for how to specify a
| fully-qualified string.)
|
| Returns:
| torch.nn.Module: The submodule referenced by ``target``
|
| Raises:
| AttributeError: If the target string references an invalid
| path or resolves to something that is not an
| ``nn.Module``
|
| half(self:~T) -> ~T
| Casts all floating point parameters and buffers to ``half`` datatype.
|
| .. note::
| This method modifies the module in-place.
|
| Returns:
| Module: self
|
| load_state_dict(self, state_dict:'OrderedDict[str, Tensor]', strict:bool=True)
| Copies parameters and buffers from :attr:`state_dict` into
| this module and its descendants. If :attr:`strict` is ``True``, then
| the keys of :attr:`state_dict` must exactly match the keys returned
| by this module's :meth:`~torch.nn.Module.state_dict` function.
|
| Args:
| state_dict (dict): a dict containing parameters and
| persistent buffers.
| strict (bool, optional): whether to strictly enforce that the keys
| in :attr:`state_dict` match the keys returned by this module's
| :meth:`~torch.nn.Module.state_dict` function. Default: ``True``
|
| Returns:
| ``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
| * **missing_keys** is a list of str containing the missing keys
| * **unexpected_keys** is a list of str containing the unexpected keys
|
| Note:
| If a parameter or buffer is registered as ``None`` and its corresponding key
| exists in :attr:`state_dict`, :meth:`load_state_dict` will raise a
| ``RuntimeError``.
|
| modules(self) -> Iterator[_ForwardRef('Module')]
| Returns an iterator over all modules in the network.
|
| Yields:
| Module: a module in the network
|
| Note:
| Duplicate modules are returned only once. In the following
| example, ``l`` will be returned only once.
|
| Example::
|
| >>> l = nn.Linear(2, 2)
| >>> net = nn.Sequential(l, l)
| >>> for idx, m in enumerate(net.modules()):
| print(idx, '->', m)
|
| 0 -> Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| )
| 1 -> Linear(in_features=2, out_features=2, bias=True)
|
| named_buffers(self, prefix:str='', recurse:bool=True) -> Iterator[Tuple[str, torch.Tensor]]
| Returns an iterator over module buffers, yielding both the
| name of the buffer as well as the buffer itself.
|
| Args:
| prefix (str): prefix to prepend to all buffer names.
| recurse (bool): if True, then yields buffers of this module
| and all submodules. Otherwise, yields only buffers that
| are direct members of this module.
|
| Yields:
| (string, torch.Tensor): Tuple containing the name and buffer
|
| Example::
|
| >>> for name, buf in self.named_buffers():
| >>> if name in ['running_var']:
| >>> print(buf.size())
|
| named_children(self) -> Iterator[Tuple[str, _ForwardRef('Module')]]
| Returns an iterator over immediate children modules, yielding both
| the name of the module as well as the module itself.
|
| Yields:
| (string, Module): Tuple containing a name and child module
|
| Example::
|
| >>> for name, module in model.named_children():
| >>> if name in ['conv4', 'conv5']:
| >>> print(module)
|
| named_modules(self, memo:Union[Set[_ForwardRef('Module')], NoneType]=None, prefix:str='', remove_duplicate:bool=True)
| Returns an iterator over all modules in the network, yielding
| both the name of the module as well as the module itself.
|
| Args:
| memo: a memo to store the set of modules already added to the result
| prefix: a prefix that will be added to the name of the module
| remove_duplicate: whether to remove the duplicated module instances in the result
| or not
|
| Yields:
| (string, Module): Tuple of name and module
|
| Note:
| Duplicate modules are returned only once. In the following
| example, ``l`` will be returned only once.
|
| Example::
|
| >>> l = nn.Linear(2, 2)
| >>> net = nn.Sequential(l, l)
| >>> for idx, m in enumerate(net.named_modules()):
| print(idx, '->', m)
|
| 0 -> ('', Sequential(
| (0): Linear(in_features=2, out_features=2, bias=True)
| (1): Linear(in_features=2, out_features=2, bias=True)
| ))
| 1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
|
| named_parameters(self, prefix:str='', recurse:bool=True) -> Iterator[Tuple[str, torch.nn.parameter.Parameter]]
| Returns an iterator over module parameters, yielding both the
| name of the parameter as well as the parameter itself.
|
| Args:
| prefix (str): prefix to prepend to all parameter names.
| recurse (bool): if True, then yields parameters of this module
| and all submodules. Otherwise, yields only parameters that
| are direct members of this module.
|
| Yields:
| (string, Parameter): Tuple containing the name and parameter
|
| Example::
|
| >>> for name, param in self.named_parameters():
| >>> if name in ['bias']:
| >>> print(param.size())
|
| parameters(self, recurse:bool=True) -> Iterator[torch.nn.parameter.Parameter]
| Returns an iterator over module parameters.
|
| This is typically passed to an optimizer.
|
| Args:
| recurse (bool): if True, then yields parameters of this module
| and all submodules. Otherwise, yields only parameters that
| are direct members of this module.
|
| Yields:
| Parameter: module parameter
|
| Example::
|
| >>> for param in model.parameters():
| >>> print(type(param), param.size())
| <class 'torch.Tensor'> (20L,)
| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
|
| register_backward_hook(self, hook:Callable[[_ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle
| Registers a backward hook on the module.
|
| This function is deprecated in favor of :meth:`~torch.nn.Module.register_full_backward_hook` and
| the behavior of this function will change in future versions.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_buffer(self, name:str, tensor:Union[torch.Tensor, NoneType], persistent:bool=True) -> None
| Adds a buffer to the module.
|
| This is typically used to register a buffer that should not to be
| considered a model parameter. For example, BatchNorm's ``running_mean``
| is not a parameter, but is part of the module's state. Buffers, by
| default, are persistent and will be saved alongside parameters. This
| behavior can be changed by setting :attr:`persistent` to ``False``. The
| only difference between a persistent buffer and a non-persistent buffer
| is that the latter will not be a part of this module's
| :attr:`state_dict`.
|
| Buffers can be accessed as attributes using given names.
|
| Args:
| name (string): name of the buffer. The buffer can be accessed
| from this module using the given name
| tensor (Tensor or None): buffer to be registered. If ``None``, then operations
| that run on buffers, such as :attr:`cuda`, are ignored. If ``None``,
| the buffer is **not** included in the module's :attr:`state_dict`.
| persistent (bool): whether the buffer is part of this module's
| :attr:`state_dict`.
|
| Example::
|
| >>> self.register_buffer('running_mean', torch.zeros(num_features))
|
| register_forward_hook(self, hook:Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle
| Registers a forward hook on the module.
|
| The hook will be called every time after :func:`forward` has computed an output.
| It should have the following signature::
|
| hook(module, input, output) -> None or modified output
|
| The input contains only the positional arguments given to the module.
| Keyword arguments won't be passed to the hooks and only to the ``forward``.
| The hook can modify the output. It can modify the input inplace but
| it will not have effect on forward since this is called after
| :func:`forward` is called.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_forward_pre_hook(self, hook:Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle
| Registers a forward pre-hook on the module.
|
| The hook will be called every time before :func:`forward` is invoked.
| It should have the following signature::
|
| hook(module, input) -> None or modified input
|
| The input contains only the positional arguments given to the module.
| Keyword arguments won't be passed to the hooks and only to the ``forward``.
| The hook can modify the input. User can either return a tuple or a
| single modified value in the hook. We will wrap the value into a tuple
| if a single value is returned(unless that value is already a tuple).
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_full_backward_hook(self, hook:Callable[[_ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle
| Registers a backward hook on the module.
|
| The hook will be called every time the gradients with respect to module
| inputs are computed. The hook should have the following signature::
|
| hook(module, grad_input, grad_output) -> tuple(Tensor) or None
|
| The :attr:`grad_input` and :attr:`grad_output` are tuples that contain the gradients
| with respect to the inputs and outputs respectively. The hook should
| not modify its arguments, but it can optionally return a new gradient with
| respect to the input that will be used in place of :attr:`grad_input` in
| subsequent computations. :attr:`grad_input` will only correspond to the inputs given
| as positional arguments and all kwarg arguments are ignored. Entries
| in :attr:`grad_input` and :attr:`grad_output` will be ``None`` for all non-Tensor
| arguments.
|
| For technical reasons, when this hook is applied to a Module, its forward function will
| receive a view of each Tensor passed to the Module. Similarly the caller will receive a view
| of each Tensor returned by the Module's forward function.
|
| .. warning ::
| Modifying inputs or outputs inplace is not allowed when using backward hooks and
| will raise an error.
|
| Returns:
| :class:`torch.utils.hooks.RemovableHandle`:
| a handle that can be used to remove the added hook by calling
| ``handle.remove()``
|
| register_parameter(self, name:str, param:Union[torch.nn.parameter.Parameter, NoneType]) -> None
| Adds a parameter to the module.
|
| The parameter can be accessed as an attribute using given name.
|
| Args:
| name (string): name of the parameter. The parameter can be accessed
| from this module using the given name
| param (Parameter or None): parameter to be added to the module. If
| ``None``, then operations that run on parameters, such as :attr:`cuda`,
| are ignored. If ``None``, the parameter is **not** included in the
| module's :attr:`state_dict`.
|
| requires_grad_(self:~T, requires_grad:bool=True) -> ~T
| Change if autograd should record operations on parameters in this
| module.
|
| This method sets the parameters' :attr:`requires_grad` attributes
| in-place.
|
| This method is helpful for freezing part of the module for finetuning
| or training parts of a model individually (e.g., GAN training).
|
| See :ref:`locally-disable-grad-doc` for a comparison between
| `.requires_grad_()` and several similar mechanisms that may be confused with it.
|
| Args:
| requires_grad (bool): whether autograd should record operations on
| parameters in this module. Default: ``True``.
|
| Returns:
| Module: self
|
| set_extra_state(self, state:Any)
| This function is called from :func:`load_state_dict` to handle any extra state
| found within the `state_dict`. Implement this function and a corresponding
| :func:`get_extra_state` for your module if you need to store extra state within its
| `state_dict`.
|
| Args:
| state (dict): Extra state from the `state_dict`
|
| share_memory(self:~T) -> ~T
| See :meth:`torch.Tensor.share_memory_`
|
| state_dict(self, destination=None, prefix='', keep_vars=False)
| Returns a dictionary containing a whole state of the module.
|
| Both parameters and persistent buffers (e.g. running averages) are
| included. Keys are corresponding parameter and buffer names.
| Parameters and buffers set to ``None`` are not included.
|
| Returns:
| dict:
| a dictionary containing a whole state of the module
|
| Example::
|
| >>> module.state_dict().keys()
| ['bias', 'weight']
|
| to(self, *args, **kwargs)
| Moves and/or casts the parameters and buffers.
|
| This can be called as
|
| .. function:: to(device=None, dtype=None, non_blocking=False)
| :noindex:
|
| .. function:: to(dtype, non_blocking=False)
| :noindex:
|
| .. function:: to(tensor, non_blocking=False)
| :noindex:
|
| .. function:: to(memory_format=torch.channels_last)
| :noindex:
|
| Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
| floating point or complex :attr:`dtype`\ s. In addition, this method will
| only cast the floating point or complex parameters and buffers to :attr:`dtype`
| (if given). The integral parameters and buffers will be moved
| :attr:`device`, if that is given, but with dtypes unchanged. When
| :attr:`non_blocking` is set, it tries to convert/move asynchronously
| with respect to the host if possible, e.g., moving CPU Tensors with
| pinned memory to CUDA devices.
|
| See below for examples.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| device (:class:`torch.device`): the desired device of the parameters
| and buffers in this module
| dtype (:class:`torch.dtype`): the desired floating point or complex dtype of
| the parameters and buffers in this module
| tensor (torch.Tensor): Tensor whose dtype and device are the desired
| dtype and device for all parameters and buffers in this module
| memory_format (:class:`torch.memory_format`): the desired memory
| format for 4D parameters and buffers in this module (keyword
| only argument)
|
| Returns:
| Module: self
|
| Examples::
|
| >>> linear = nn.Linear(2, 2)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1913, -0.3420],
| [-0.5113, -0.2325]])
| >>> linear.to(torch.double)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1913, -0.3420],
| [-0.5113, -0.2325]], dtype=torch.float64)
| >>> gpu1 = torch.device("cuda:1")
| >>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1914, -0.3420],
| [-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
| >>> cpu = torch.device("cpu")
| >>> linear.to(cpu)
| Linear(in_features=2, out_features=2, bias=True)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.1914, -0.3420],
| [-0.5112, -0.2324]], dtype=torch.float16)
|
| >>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)
| >>> linear.weight
| Parameter containing:
| tensor([[ 0.3741+0.j, 0.2382+0.j],
| [ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)
| >>> linear(torch.ones(3, 2, dtype=torch.cdouble))
| tensor([[0.6122+0.j, 0.1150+0.j],
| [0.6122+0.j, 0.1150+0.j],
| [0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
|
| to_empty(self:~T, *, device:Union[str, torch.device]) -> ~T
| Moves the parameters and buffers to the specified device without copying storage.
|
| Args:
| device (:class:`torch.device`): The desired device of the parameters
| and buffers in this module.
|
| Returns:
| Module: self
|
| train(self:~T, mode:bool=True) -> ~T
| Sets the module in training mode.
|
| This has any effect only on certain modules. See documentations of
| particular modules for details of their behaviors in training/evaluation
| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
| etc.
|
| Args:
| mode (bool): whether to set training mode (``True``) or evaluation
| mode (``False``). Default: ``True``.
|
| Returns:
| Module: self
|
| type(self:~T, dst_type:Union[torch.dtype, str]) -> ~T
| Casts all parameters and buffers to :attr:`dst_type`.
|
| .. note::
| This method modifies the module in-place.
|
| Args:
| dst_type (type or string): the desired type
|
| Returns:
| Module: self
|
| xpu(self:~T, device:Union[int, torch.device, NoneType]=None) -> ~T
| Moves all model parameters and buffers to the XPU.
|
| This also makes associated parameters and buffers different objects. So
| it should be called before constructing optimizer if the module will
| live on XPU while being optimized.
|
| .. note::
| This method modifies the module in-place.
|
| Arguments:
| device (int, optional): if specified, all parameters will be
| copied to that device
|
| Returns:
| Module: self
|
| zero_grad(self, set_to_none:bool=False) -> None
| Sets gradients of all model parameters to zero. See similar function
| under :class:`torch.optim.Optimizer` for more context.
|
| Args:
| set_to_none (bool): instead of setting to zero, set the grads to None.
| See :meth:`torch.optim.Optimizer.zero_grad` for details.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from torch.nn.modules.module.Module:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from torch.nn.modules.module.Module:
|
| T_destination = ~T_destination
| Type variable.
|
| Usage::
|
| T = TypeVar('T') # Can be anything
| A = TypeVar('A', str, bytes) # Must be str or bytes
|
| Type variables exist primarily for the benefit of static type
| checkers. They serve as the parameters for generic types as well
| as for generic function definitions. See class Generic for more
| information on generic types. Generic functions work as follows:
|
| def repeat(x: T, n: int) -> List[T]:
| '''Return a list containing n references to x.'''
| return [x]*n
|
| def longest(x: A, y: A) -> A:
| '''Return the longest of two strings.'''
| return x if len(x) >= len(y) else y
|
| The latter example's signature is essentially the overloading
| of (str, str) -> str and (bytes, bytes) -> bytes. Also note
| that if the arguments are instances of some subclass of str,
| the return type is still plain str.
|
| At runtime, isinstance(x, T) and issubclass(C, T) will raise TypeError.
|
| Type variables defined with covariant=True or contravariant=True
| can be used do declare covariant or contravariant generic types.
| See PEP 484 for more details. By default generic types are invariant
| in all type variables.
|
| Type variables can be introspected. e.g.:
|
| T.__name__ == 'T'
| T.__constraints__ == ()
| T.__covariant__ == False
| T.__contravariant__ = False
| A.__constraints__ == (str, bytes)
|
| __annotations__ = {'__call__': typing.Callable[..., typing.Any], '_is_...
|
| dump_patches = False
python
# 在单个GPU上训练网络
train(net, num_gpus=1, batch_size=256, lr=0.1)test acc: 0.92, 27.5 sec/epochon [device(type='cuda', index=0)]
python
# 使用2个GPU进行训练
train(net, num_gpus=2, batch_size=512, lr=0.2)---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-18-767446712b65> in <module>
1 # 使用2个GPU进行训练
----> 2 train(net, num_gpus=2, batch_size=512, lr=0.2)
<ipython-input-15-d7b4a8ff7033> in train(net, num_gpus, batch_size, lr)
10 net.apply(init_weights)
11 # nn.DataParallel会的是X切开并行到各个GPU上,并行算梯度,然后loss加起来,它重新定义了net的forward函数
---> 12 net = nn.DataParallel(net, device_ids=devices) # net会复制到每一个GPU上
13 trainer = torch.optim.SGD(net.parameters(),lr)
14 loss = nn.CrossEntropyLoss()
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\data_parallel.py in __init__(self, module, device_ids, output_device, dim)
136 self.dim = dim
137 self.module = module
--> 138 self.device_ids = [_get_device_index(x, True) for x in device_ids]
139 self.output_device = _get_device_index(output_device, True)
140 self.src_device_obj = torch.device(device_type, self.device_ids[0])
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\nn\parallel\data_parallel.py in <listcomp>(.0)
136 self.dim = dim
137 self.module = module
--> 138 self.device_ids = [_get_device_index(x, True) for x in device_ids]
139 self.output_device = _get_device_index(output_device, True)
140 self.src_device_obj = torch.device(device_type, self.device_ids[0])
D:\11_Anaconda\envs\py3.6.3\lib\site-packages\torch\_utils.py in _get_device_index(device, optional, allow_cpu)
495 if isinstance(device, torch.device):
496 if not allow_cpu and device.type == 'cpu':
--> 497 raise ValueError('Expected a non cpu device, but got: {}'.format(device))
498 device_idx = -1 if device.type == 'cpu' else device.index
499 if isinstance(device, int):
ValueError: Expected a non cpu device, but got: cpu8. 分布式训练
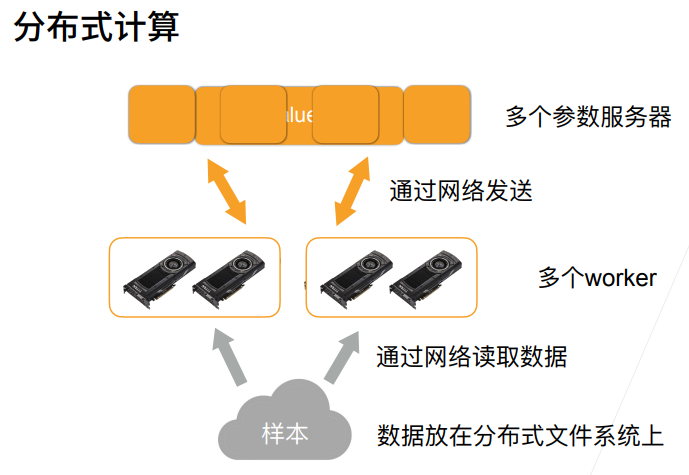
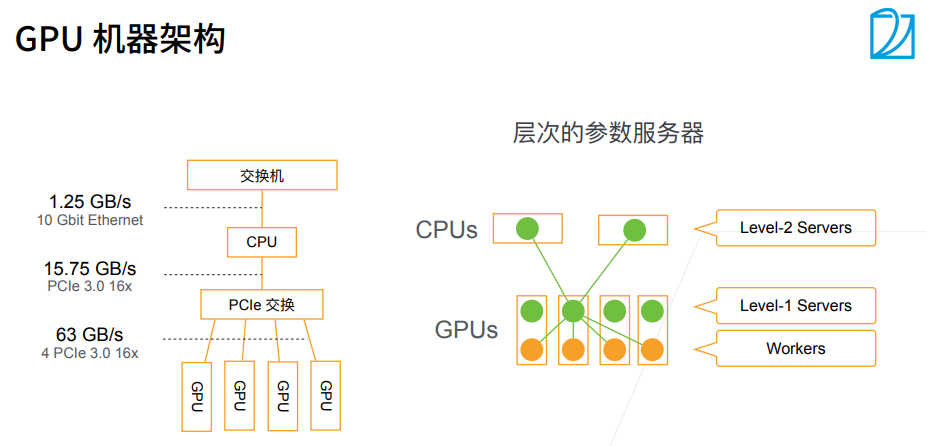
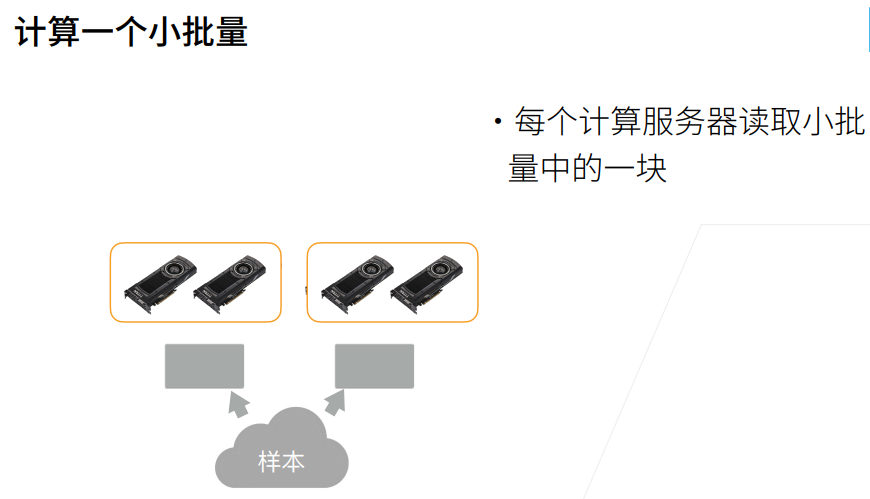
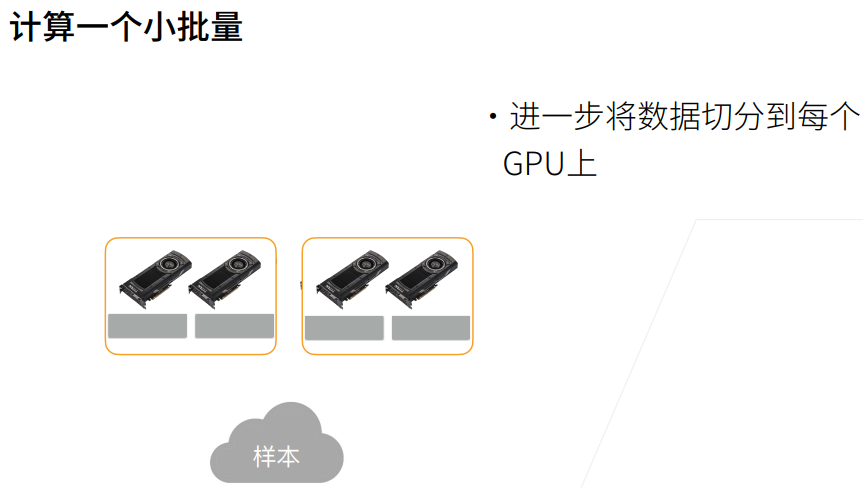
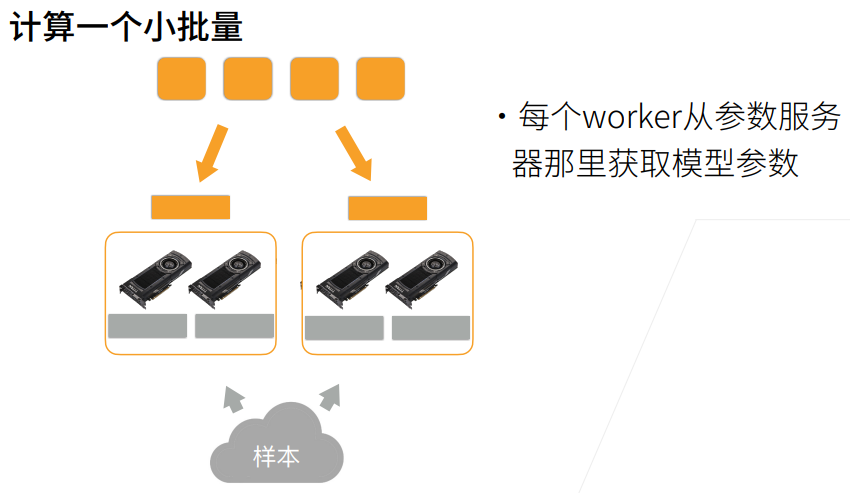
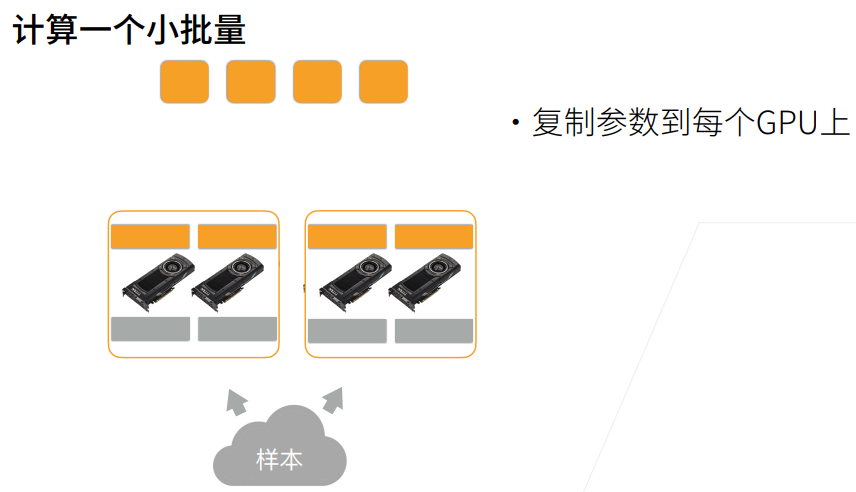
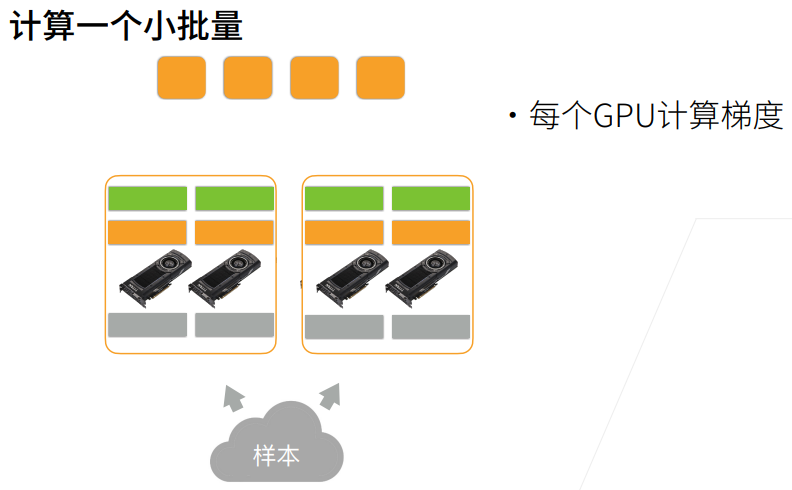
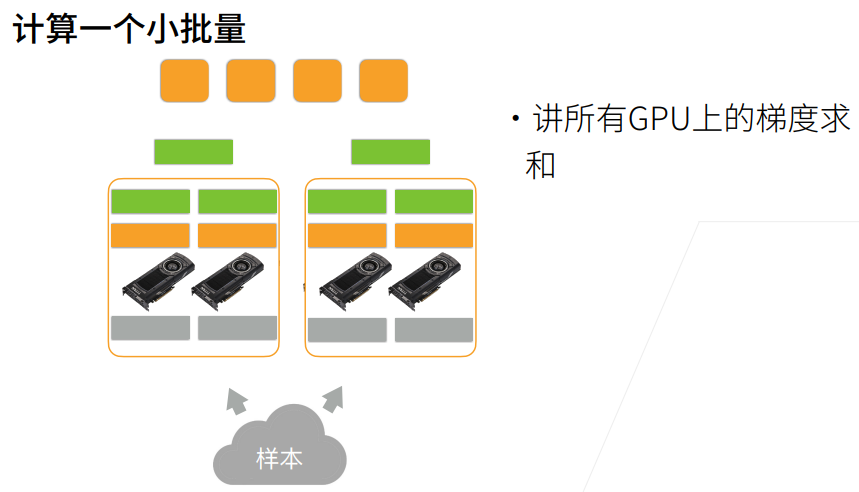
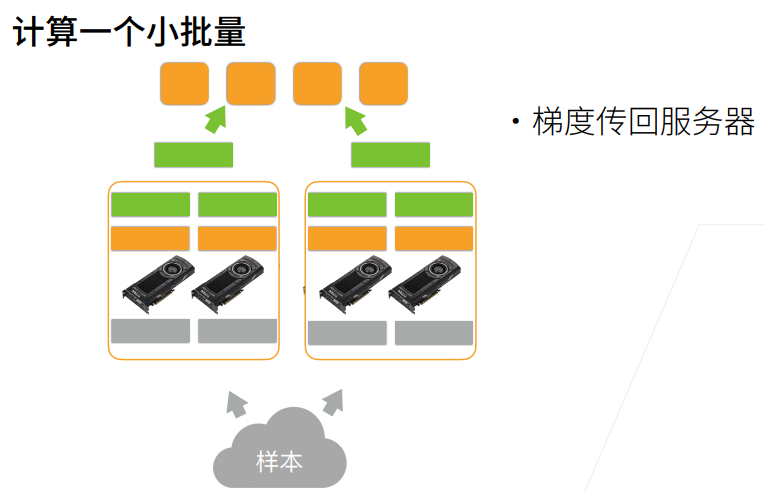
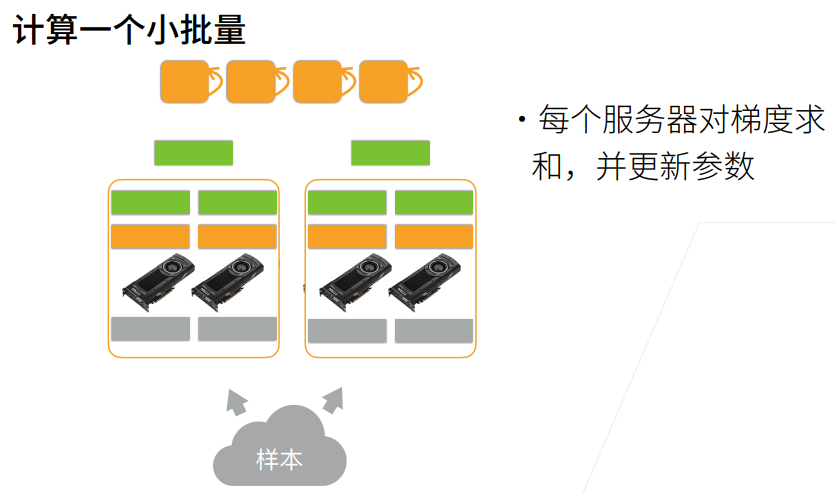


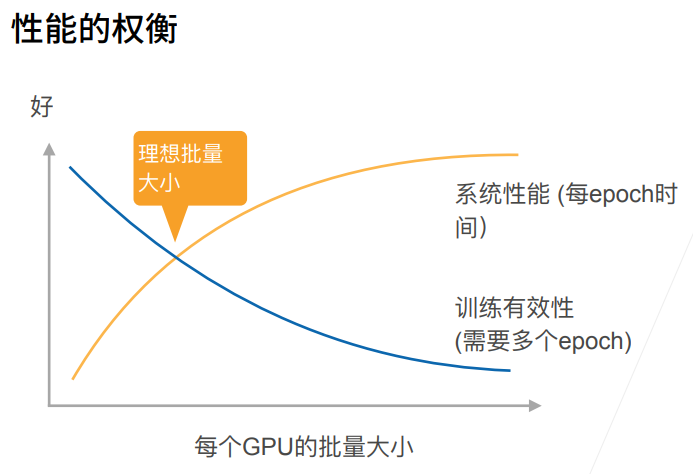

2. 总结
