Agent Harness 工程详解:大模型之外,决定 Agent 生死的十一个组件
真正难的不是模型能不能答,而是 Harness 能不能把上下文、工具、状态、权限、沙箱、记忆、观测、验证、评测、交付这十一件事做扎实

一、背景:Agent 系统的真实瓶颈
1.1 一个常见的误判
2026 年,很多人对 Agent 的理解还停留在"选一个大模型 → 写一段 Prompt → 就能干活"的阶段。但任何一个真正在生产环境跑过 Agent 的工程师都会告诉你:
模型只是大脑,Harness 才是整个神经系统。
Harness 这个词在英文中意为"马具"或"线束"------它的作用是连接和控制。在 Agent 系统里,Harness 包裹在大模型周围,决定模型看到什么、能调用什么工具、结果如何存储、什么时候返回控制权、以及对话如何在时间中存活下去。
OpenAI 的 Lilian Weng 给出了 Agent 的经典定义:
ini
Agent = LLM + 规划(Planning)+ 记忆(Memory)+ 工具使用(Tool Use)这个公式里,LLM 只占了 1/4。剩下的 3/4,全都是 Harness 的活儿。
1.2 Harness 到底是什么?
用冯诺依曼架构做类比:
| 冯诺依曼组件 | Agent 对应 | 属于 Harness? |
|---|---|---|
| 运算器 | LLM 大模型 | ❌ 不是 |
| 控制器 | 编排(Orchestration) | ✅ 是 |
| 存储器 | 记忆系统 | ✅ 是 |
| 总线 | MCP / A2A 协议 | ✅ 是 |
| I/O 设备 | Tools / Skills | ✅ 是 |
| 安全边界 | 沙箱 / 权限控制 | ✅ 是 |
| 监控面板 | 观测追踪 | ✅ 是 |
| 测试门禁 | 评测验证 | ✅ 是 |
| 交付管道 | CI/CD | ✅ 是 |
一句话:除了模型之外的任何事情,都是 Harness 的职责。
二、Harness 的八层架构

javascript
第1层:模型与推理层 ──── GPT / Claude / Gemini / Qwen / DeepSeek
第2层:Agent 编排层 ──── LangGraph(图引擎)→ Deep Agents(完整Harness)
第3层:工具与协议层 ──── MCP / A2A / Function Calling
第4层:上下文与记忆层 ── 工作记忆 + 会话记忆 + 长期记忆
第5层:执行环境与沙箱层 ─ 容器隔离 / 权限控制 / 回滚
第6层:观测与追踪层 ──── LangSmith / Braintrust / OpenTelemetry
第7层:评测与验证层 ──── Inspect AI / DeepEval / SWE-bench
第8层:CI/CD 与交付层 ── 灰度 / 回滚 / 审计为什么每层都不能少?
- 缺编排:模型无限循环,不知道该停
- 缺工具协议:每次接入新能力都要手写胶水代码
- 缺记忆:对话一长就"失忆",中间遗忘效应严重
- 缺沙箱 :模型真的可能
rm -rf / - 缺观测:出错后不知道怎么调试
- 缺评测:改了一行 Prompt 不知道变好还是变坏
- 缺 CI/CD:Agent 上线流程和传统软件脱节
三、Deep Agents:完整的 Harness 实现
在讲各种 Harness 组件之前,先看一个具体实现。这比抽象描述一百遍"中间件是什么"都更有用。
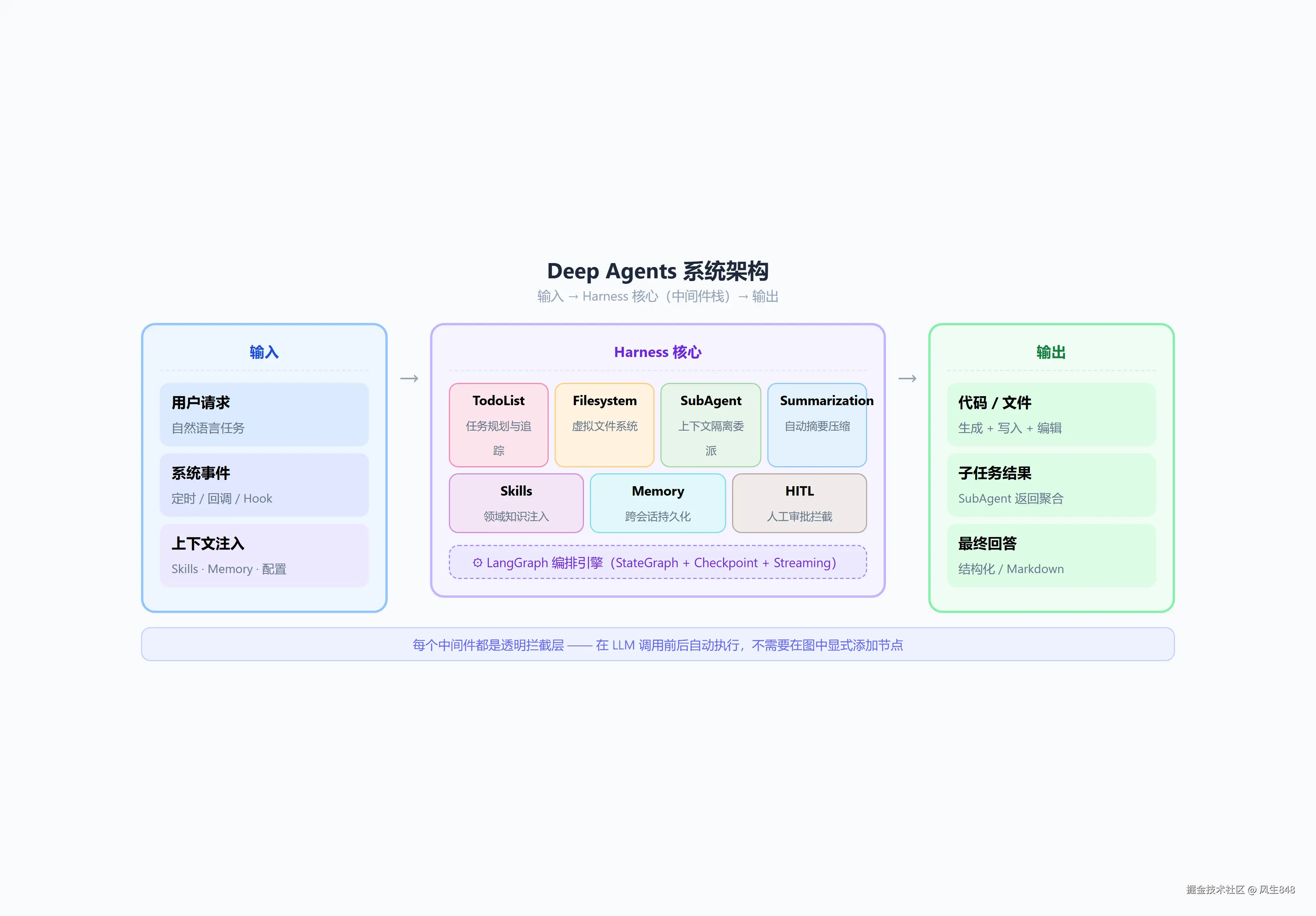
3.1 定位
Deep Agents 是 LangChain 团队在 2025-2026 年重点打造的开源 Agent Harness,GitHub 地址:langchain-ai/deepagents。
它不是"又一个 Agent 框架",而是一个 "电池已含"(batteries-included)的完整运行时:在 LangGraph 编排引擎之上,叠加了文件系统、子Agent 委派、上下文压缩、技能挂载、人工审批等全套中间件。开发者不需要从头拼装这些组件。
3.2 三个项目的演进与关系
要理解这三个项目,得先分开两个维度:历史演进 和架构依赖。很多人把这俩混在一起,就容易困惑。

历史演进
LangChain(2022)──→ LangGraph(2024)──→ Deep Agents(2025)
早期 Agent 尝试 引入图编排引擎 叠加完整中间件栈- LangChain 最早(2022 年):最先尝试把 LLM 和工具、记忆、Prompt 模板串联起来。但早期的 Agent 实现是自己写的编排逻辑,随着场景变复杂,线性编排不够用了。
- LangGraph 后来(2024 年):团队意识到编排这件事需要一个专门的引擎------支持循环、分支、检查点、人机协同------于是从 LangChain 中抽象出了独立的图编排运行时。
- Deep Agents 最新(2025 年):团队进一步发现,光有编排引擎还不够,开发者每次都要手搭文件系统、子Agent、上下文压缩、记忆持久化......于是把所有这些"标配电池"打包成 Deep Agents。
当前架构依赖
从底层到上层:
| 层级 | 项目 | 角色 |
|---|---|---|
| 第1层 | LangGraph | 图编排引擎------StateGraph、Checkpoint、Streaming。不是 Agent 框架,是通用编排运行时。 |
| 第2层 | LangChain create_agent() |
LangGraph 之上的最小化 Agent 封装------ReAct 循环 + 工具调用,没有额外中间件。 |
| 第3层 | Deep Agents | 在 create_agent() 之上叠加 TodoList / Filesystem / SubAgent / Summarization / Skills / Memory / HITL 全套中间件。 |
一句话总结两者的关系:
LangChain 先做出了 Agent,然后拆出 LangGraph 专门做编排,最后把编排能力 + 中间件经验打包成 Deep Agents。架构上 LangGraph 在最底层驱动一切,但历史上 LangChain 是先来的那个。
3.3 默认中间件栈
调用 create_deep_agent() 时自动组装以下中间件,每个都是透明的拦截层------不需要在图里显式添加节点:
| 中间件 | 挂载的工具 | 做了什么 |
|---|---|---|
| TodoListMiddleware | write_todos |
任务规划:pending → in_progress → completed |
| FilesystemMiddleware | ls, read_file, write_file, edit_file, glob, grep |
虚拟文件系统,可插拔后端(内存/本地/Store/沙箱) |
| SubAgentMiddleware | task |
上下文隔离的子 Agent 委派 |
| SummarizationMiddleware | 无(自动触发) | 上下文接近窗口限制时自动摘要压缩 |
| SkillsMiddleware | 无(注入知识) | 加载可复用的领域 Skill,注入 System Prompt |
| MemoryMiddleware | 无(注入上下文) | 跨会话记忆持久化,下次对话自动加载 |
| HumanInTheLoopMiddleware | 无(拦截审批) | 指定工具调用需要人工点击确认才能执行 |
3.4 执行循环
Deep Agents 的核心是模型-工具循环,由 LangGraph 驱动:
用户输入 → LLM 推理 → 发出工具调用 → ToolNode 批量执行 → 结果追加到状态 → LLM 再次推理 → ... → 最终回答每一步之间 LangGraph 自动写入检查点(Checkpoint),这意味着:
- 可以在任意步骤中断和恢复
- 出错了可以回滚到上一个检查点
- 可以注入人工审批
3.5 上下文管理:两种核心策略
这是 Deep Agents 区别于其他框架的关键设计:
| 策略 | 触发条件 | 怎么做的 |
|---|---|---|
| Offloading | 单次工具输出 > 20,000 tokens | 写入文件系统,消息中只保留路径引用 |
| Summarization | 总上下文达到窗口 85% | LLM 生成结构化摘要,完整历史保留在文件系统供检索 |
效果:让 Agent 可以在不触发上下文溢出错误的前提下完成非常长的任务。
3.6 v0.6 的四个关键突破
① 代码解释器(Code Interpreter) 内置 QuickJS 运行时,Agent 可以写代码来编排工具。这带来了 PTC(程序化工具调用)------模型一次写代码批量调用工具,避免多次 LLM 往返,大幅减少 token 消耗。
② Harness 配置文件 为开源模型(Kimi、Qwen、DeepSeek、GLM)提供按模型调优的配置。实测:仅靠 Harness 调优,gpt-5.2-codex 在 Terminal-Bench 2.0 上从 52.8% 提升到 66.5%。开源模型以 1/20 的成本接近前沿 API 水平。
③ Delta Channels 检查点存储从全量快照改为增量差异。实测:200 轮编程会话从 5.27 GB 降到 129 MB,压缩 40 倍。
④ Streaming v3 类型化事件流(消息/工具调用/子Agent/自定义),前后端统一的流式协议。
四、工具调用:Agent 与外部世界的"USB 接口"
4.1 Function Calling 的真实流程
很多人以为 LLM 在"调用函数",实际上 LLM 只是按概率输出了一段 JSON:
javascript
用户输入 → LLM 输出 JSON → 编排层解析 → 调用真正函数 → 结果返回 LLM → 决策下一步关键认知:LLM 不执行任何代码。它是决策者,不是执行者。执行、校验、错误处理------全是 Harness 的活。
4.2 MCP 协议:统一接口
MCP(Model Context Protocol)是 Anthropic 提出的标准协议,类比 USB-C------任何实现了 MCP 的工具,就能被任何支持 MCP 的 Agent 调用。
MCP 规定三件事:发现 有哪些工具 → 请求 执行某个工具 → 返回结果。
Google 的 A2A(Agent-to-Agent)也在快速推进,两者的分工:
| 协议 | 方向 | 类比 |
|---|---|---|
| MCP | Agent → 工具 | USB 接口(设备连接) |
| A2A | Agent → Agent | 蓝牙/WiFi(设备间通信) |
4.3 工具接口设计原则
"工具接口要为 Agent 设计,不是简单把人类接口暴露给模型。"
好的工具返回:
json
{
"success": false,
"error_type": "permission_denied",
"cause": "缺少 production 环境的部署权限",
"suggestion": "提交审批工单到 Release Manager"
}差的工具返回 :Error: exit code 1
拿到第二种返回,Agent 不知道该怎么办,大概率乱试其他工具直到上下文耗尽。
五、记忆系统:从两层到四层的演进
5.1 为什么不能全塞进上下文窗口?
| 问题 | 说明 |
|---|---|
| 成本 O(n²) | 注意力计算量随上下文长度平方级增长 |
| 中间遗忘 | 模型对上下文中间部分理解最弱 |
| 推理变慢 | 窗口越大,首 token 延迟越高 |
5.2 工业级四层记忆架构
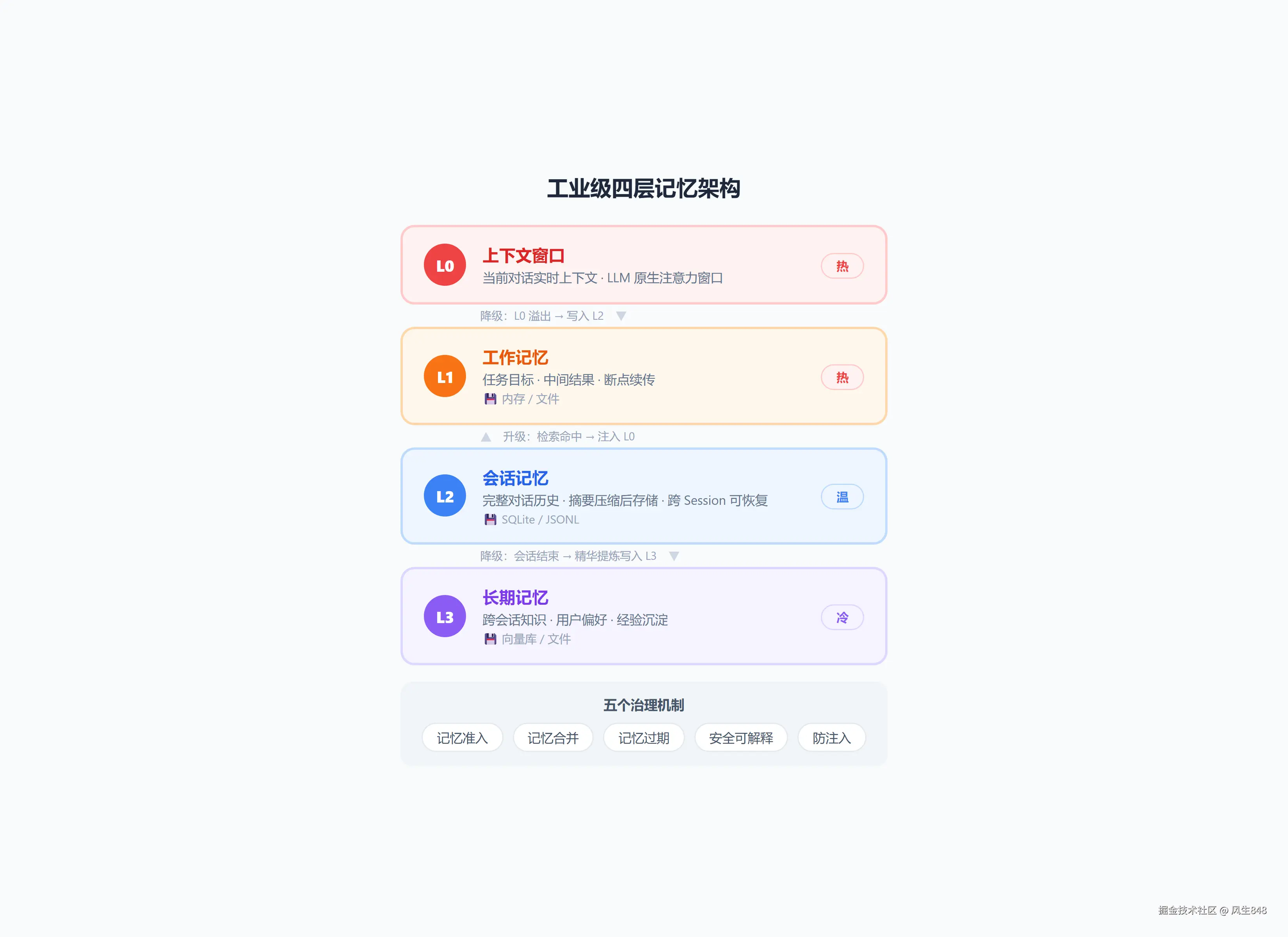
| 层级 | 名称 | 存储 | 职责 |
|---|---|---|---|
| L0 | 上下文窗口 | LLM 原生 | 当前对话实时上下文 |
| L1 | 工作记忆 | 内存/文件 | 任务目标、中间结果、断点续传 |
| L2 | 会话记忆 | SQLite/JSONL | 完整对话历史,摘要压缩后存储 |
| L3 | 长期记忆 | 向量库/文件 | 跨会话知识:用户偏好、经验沉淀 |
5.3 记忆升降级
降级(热 → 冷):
L0 溢出 → 写入 L2(会话记忆)
会话结束 → 精华提炼写入 L3(长期记忆)
升级(冷 → 热):
检索命中 → L3 注入 L0(重新进入 LLM 上下文)5.4 五个治理机制
- 记忆准入 :写入前重要性打分 + 去重。宁可少存,也别乱存
- 记忆合并:同一实体多条记忆归一化
- 记忆过期:时间衰减 + 访问频率衰减 + 定期清理
- 安全可解释:用户可查看、可编辑、可删除
- 防注入:Agent 不能篡改记忆
六、执行循环与编排

6.1 ReAct:Agent 的心跳
python
while not task_done:
# 1. 观察
context = harness.select_context(state, task)
# 2. 推理
plan = model.reason(context, task)
# 3. 行动
result = harness.dispatch_tool(plan.next_action)
# 4. 评估
if outcome.needs_retry:
harness.add_error_trace(outcome.error)
continue
if outcome.needs_human:
harness.escalate(outcome)
break
harness.checkpoint(result)6.2 四种运行范式
| 范式 | 控制逻辑 | 适用场景 |
|---|---|---|
| ReAct | Thought → Action → Observation 循环 | 通用任务 |
| Plan-Execute | 先规划 Step 1-3,再线性执行 | 步骤确定 |
| Reflexion | 执行后自查,不合格重来 | 代码/内容生成 |
| Multi-Agent | 多 Agent 分工协作 | 复杂系统拆解 |
6.3 编排的核心不是"选哪个框架"
而是能不能表达循环 + 条件分支 + 人工审批。真实场景中的 Agent 几乎从不是线性的------需要重试、需要分支、需要跳回上一步、需要等人点确认。这就是为什么 Deep Agents 选择基于 LangGraph(图引擎)来构建:Graph 模式天然支持这些控制流。
七、Skills:比 Tool 更上一层的可复用知识
| 维度 | Tool | Skill |
|---|---|---|
| 编码什么 | "调用什么函数" | "怎么做 + 为什么这么做" |
| 包含什么 | 函数签名 + Schema | 领域知识 + 操作流程 + 踩坑经验 |
| 类比 | 螺丝刀 | 操作手册 + 螺丝刀 |
Skill 的定位:在 Prompt 之上(可复用持久)、在微调之下(轻量可迭代)、比 RAG 更主动(主动注入知识而非被动检索)。
一份典型的 Skill 就是一份 Markdown 文件,包含领域概念、标准流程、已知最佳实践和常见踩坑记录。
八、观测与安全:让 Agent 不再是"黑盒"

8.1 全链路可观测
Agent 出问题时,你需要三样东西:
| 需要 | 工具 | 说明 |
|---|---|---|
| Trace | LangSmith / Braintrust | 每一步调了哪个工具、花了多少时间、I/O 是什么 |
| Log | OpenTelemetry | 结构化日志,可搜索可聚合 |
| Eval | DeepEval / Inspect AI | 改 Prompt 后自动跑评测,知道变好还是变坏 |
8.2 错误恢复层级
markdown
1. 重试(带上下文) → 模型看到错误,自行调整
2. 回滚到检查点 → 回到上一步重新尝试
3. 拆分子任务 → 大任务变小任务逐个击破
4. 升级到人工 → 清晰总结已尝试内容,交给人处理8.3 沙箱与权限
- 容器隔离:每个 Agent 跑在独立容器
- 命令白名单:只能执行预定义的工具
- 人工审批门:高风险操作(部署、删库、改数据库)需人工确认
- 只读文件系统:Agent 不能直接改生产配置
九、Agent 成熟度模型
| 级别 | 特征 | 能做什么 |
|---|---|---|
| H0 脚本式 | 一次 prompt,无状态无 trace | 个人临时工具 |
| H1 工具调用 | function calling + 基本日志 | 查询助手、轻量自动化 |
| H2 工程化 | 状态机 + 持久化 + 审批 + trace + 验证 | 代码修改、工作流自动化 |
| H3 企业级 | 完整权限 + 评测 + CI/CD + 灰度回滚 | 生产级 Agent 平台 |
大多数团队应从 H1/H2 起步,选一个场景把 Harness 做扎实,再向上演进。
十、总结
markdown
Agent = LLM(运算器)
+ 编排层(图引擎 + 中间件栈)
+ 记忆系统(L0 上下文 + L1 工作 + L2 会话 + L3 长期)
+ MCP 总线(标准化工具连接协议)
+ Tools / Skills(与外部世界交互)
+ 沙箱(安全边界)
+ 观测追踪(全链路可观测)
+ 评测验证(自动质量门禁)
+ CI/CD 交付(工程化上线)核心判断
2026 年及以后,Agent 工程的竞争重心从**"谁的模型更强"转向"谁的 Harness 更扎实"**。
模型层在快速同质化------GPT、Claude、Gemini、DeepSeek 的能力差距持续缩小。但 Harness 层的差距在拉大:谁能把上下文组织好、工具设计好、权限收敛好、trace 做好、eval 做好,谁的 Agent 才能从 Demo 走向 Production。
Meta 收购 Manus 花了约 20 亿美元------买的不是模型,是 Harness。
在实践层面,Deep Agents 是目前最强的"电池已含"Harness 实现。它证明了:一个好的 Harness 能让不同模型(包括开源模型)都达到生产级水平;而一个差的 Harness 能让最强的模型也翻车。
延伸阅读 :Deep Agents GitHub · Deep Agents 官方文档 · Improving Deep Agents with Harness Engineering · Morphllm - Agent Engineering · MCP 协议