学完本节之前,你已经学习了如何加载数据、切分文本、生成 embedding vectors,并将这些向量存储到 vector database 中,从而成功构建出一个高效的知识库。接下来,我们将探索检索前处理技术,揭示在执行检索之前如何构造合适的查询,以及如何优化这些查询,从而提升系统整体执行效率和准确性。
为什么检索前处理很重要
在查看具体技术之前,先理解为什么 RAG 系统需要检索前处理,是很有帮助的。
Alex:Lewis,为什么我们需要做检索前处理?
Lewis :我用一个类比来解释。我非常推荐《高效能人士的七个习惯》这门课程。课程中的一个核心原则是:人的反应并不是简单由刺激驱动的;相反,在"刺激"和"回应"之间,存在一个自主选择的空间。这个概念类似于 Viktor Frankl 在《活出生命的意义》中提出的思想,也被 Stephen Covey 等人强调和推广为高级智能体的选择自由。我把它称为回应前的预处理。
下图展示了 Lewis 用来解释"接收刺激"和"产生回应"之间空间的类比。
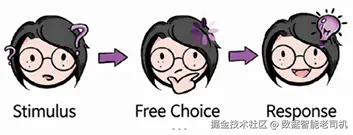
图 5.1:刺激---选择---回应序列,展示外部刺激如何通过自由选择被处理,并产生行为回应。
当 RAG 系统收到用户最初的查询请求时,它可以通过预设规则,相对固定,或者使用大模型,相对灵活,引入一种回应前预处理 。这个过程允许查询在检索和内容生成之前被优化和过滤。该机制为系统提供了一个检索前思考空间,使系统能够更智能地筛选信息、优化查询,或者决定下一步行动。这不仅提升了系统的灵活性和检索效率,也增强了输出质量和准确性。
在 RAG 系统中,同样的思想表现为检索前的预处理阶段。下面的工作流展示了 query construction、query routing、query translation 和 evaluation 如何融入这一阶段。
Alex:Lewis,我注意到检索前处理包括多个方面,例如 query construction、query translation 和 query routing。
检索前处理包含的技术
检索前处理并不是一种单一技术。它包含若干方法,用于在系统执行检索之前,对用户查询进行准备。
Lewis:确实,检索前处理覆盖以下三类技术。
Query construction:Query construction 指的是将用户提出的自然语言问题转换成适合检索系统的数据查询形式。这包括从关系型数据库中读取数据,以及自动将自然语言问题转换成 SQL 查询,这被称为 Text-to-SQL,也常写作 Text2SQL。此外,还有一些场景会将自然语言问题转换成图数据库查询语言,用于查询复杂实体关系,即 Text-to-Cypher。对于向量数据库来说,虽然可以直接对自然语言执行 embedding 查询,但本节也会介绍一种从查询中构建 metadata filters 的方式,它类似于简化版的 Text-to-SQL。
Query translation:Query translation,也称为 query rewriting 或 query optimization,是系统重构用户输入问题以增强检索效果的阶段。具体方法包括对原始问题进行替换、分解、抽象或扩展,将其转换成多个子查询,甚至转换成假设性问题等。
Query routing:Query routing 决定系统选择哪种类型的数据库或检索路径来执行查询。它主要分为 logical routing 和 semantic routing。
上述三类技术的核心目标,是将用户问题准确转换成更适合系统检索的形式,并选择最优检索路径,从而使后续检索和生成过程更加准确、全面、高效且顺畅。
Query construction:用自然语言提问
Query construction 是检索前处理中使用的主要技术之一。它是将用户自然语言问题转换成检索系统可以执行或直接应用的形式的过程。系统不再只依赖语义相似度,而是可以将问题转换成面向关系型数据库的 SQL、面向图数据库的 Cypher,或者面向向量存储的 metadata filters。这样,query construction 就在人的语言和不同数据源所需的结构化或半结构化查询格式之间,充当了一座桥梁。
现代企业知识库是庞大而复杂的系统。企业和个人的最终目标,是以更便捷的方式访问和检索信息。这些信息可能以非结构化向量形式存储,也可能以结构化格式存储在传统数据库中,甚至存储在图数据库中。
无论是 SQL 还是 Cypher,都有各自特定的语法和查询逻辑。直接编写这些查询通常需要对数据库结构和语法有一定了解。Query construction,也就是 Text-to-Query 技术,通过允许学习者使用自然语言提问,并让系统自动生成对应的数据库查询或向量搜索,极大降低了这一过程的技术门槛。
下面三种技术展示了自然语言问题如何被转换,以适配不同类型的数据源:
Text-to-SQL:负责将自然语言问题转换成适合关系型数据库,例如 MySQL、PostgreSQL、SQL Server 等的 SQL 查询。例如,将问题"Find the best-selling product"转换成下面的 SQL 查询:
sql
SELECT product_name FROM sales ORDER BY total_sold DESC LIMIT 1Text-to-Cypher:用于将自然语言问题翻译成图数据库,例如 Neo4j 的 Cypher 查询语言。例如,将问题"Find the management relationship of employees"转换成下面的 Cypher 查询:
less
MATCH (e:Employee)-[:MANAGES]->(m:Manager) RETURN e, mSelf-query retriever:LangChain 提供的一种检索前工具,可以在检索步骤之前,根据用户查询自动生成 metadata filter conditions。这样,在基于学习者问题生成 embedding vectors 并执行检索时,可以通过指定条件进一步过滤结果。这是一种高级 query construction 和 retrieval 技术。例如,对于查询"Find videos with more than 100,000 views",可以生成如下过滤条件:
json
"filter": "gt("view_count", "100000")"Text-to-SQL:将自然语言转换成 SQL
第一种 query construction 技术是 Text-to-SQL,当目标数据存储在关系型数据库中时会使用它。
Text-to-SQL 是 query construction 最常见的形式之一。它允许用户用自然语言提问,而系统在后台生成对应的 SQL 查询。在需要从关系型数据库中检索信息的 RAG 系统中,这尤其有用,因为答案往往不仅依赖语义相似度,还依赖结构化字段、表关系、过滤、排序和聚合。
为什么 Text-to-SQL 在 RAG 中很重要
在多数关于 RAG 系统的讨论中,重点通常放在非结构化数据的检索上,例如文本、图像等。然而,企业往往拥有各种类型的数据资产:一方面有非结构化文档;另一方面也有各种关系型数据库,例如 MySQL、PostgreSQL、SQL Server,数据仓库等。
因此,RAG 系统在对非结构化数据执行向量检索的同时,也需要为结构化数据提供解决方案。通过将 Text-to-SQL 纳入 RAG 工作流,用户可以用自然语言表达需求,系统自动执行查询,并将结果与非结构化知识整合后生成答案。这使检索和计算逻辑可以在结构化数据源中执行,从而把结构化数据集纳入整体 RAG 工作流。这有助于构建一个同时整合非结构化数据和结构化数据的统一问答与推理平台------这也是智能信息系统未来发展的方向之一。
事实上,Text-to-SQL 并不是随着 RAG 系统出现才诞生的新概念。早在深度学习兴起之前,与对话式数据库接口、基于模板的 NL2SQL,即自然语言到 SQL 系统相关的研究和应用就已经存在。不过,随着近年来大模型和 RAG 越来越流行并被广泛采用,Text-to-SQL 功能在统一 RAG 框架中重新受到关注,并借助新技术取得了显著性能提升。
Lewis:Text-to-SQL 是一个专业领域,拥有 WikiSQL 这样的评估数据集,其中包含大量单表查询示例。由于它相对简单,因此常用于初步实验。相比之下,由耶鲁大学团队发布的 Spider 数据集覆盖了涉及多表、多数据库和多关系的复杂查询。它目前是最具挑战性的开源数据集之一,也更真实地反映了实际数据库环境的难度和多样性。目前,研究人员通常使用 Spider 作为 Text-to-SQL 的主要评估基准。
传统 Text-to-SQL 实现
传统 Text-to-SQL 系统使用基于规则或模板匹配的方法,处理相对固定或受限领域中的查询。这类系统通常包含以下关键步骤。
自然语言理解,NLU:对用户的自然语言问题执行分词、命名实体识别、依存句法分析等操作,以提取用户意图,例如"query sales revenue"、返回 Product Names,或者按某个指标排序。
数据库 schema 映射 :将数据库表名和字段名映射到自然语言中提到的概念。例如,product 对应 product_name 字段,而 sales revenue 可能对应 sales 或 total_sold 字段。
SQL 结构生成:根据用户意图和数据库 schema,生成 SELECT、FROM、WHERE、GROUP BY、ORDER BY 和 LIMIT 等相关子句。如果涉及多表查询,则需要生成 JOIN 条件或子查询。
SQL 语句验证和执行:系统可能会在生成后选择执行简单的语法或逻辑检查,也可能直接将 SQL 提交给数据库引擎运行并返回查询结果。
传统 Text-to-SQL 方法高度依赖人工配置,尤其是在将自然语言匹配到数据库 schema 的过程中。例如,对于问题"Among the sales records, which product has the highest sales volume?",系统需要判断 sales volume 是对应 sales_table.total_sold 字段,还是 sales_table.sales_amount 字段,以及是否需要从 orders_table 中查询数据。这个匹配过程主要依赖命名实体识别,NER,然后通过计算词向量或字典条目之间的余弦相似度确定最佳映射。这种方法缺乏深层上下文理解,容易出错,也很难适应复杂数据库结构或多变的用户查询。
深度学习时代的 Text-to-SQL
随着深度学习技术的发展,基于 Transformer 的神经网络方法逐渐成为 Text-to-SQL 任务的主流解决方案。早期基于神经网络的系统通常采用 Seq2Seq 或 encoder-decoder 架构,将自然语言输入编码成向量表示,然后直接解码成 SQL token 序列。
后来,研究更多关注通过 embeddings 表示自然语言描述和字段名,并引入注意力机制优化这一过程。这种方法在一定程度上改善了自然语言和数据库 schema 之间的映射。不过,它仍然涉及大量人工特征工程,在处理复杂查询或跨领域应用场景时仍然受限。
为了进一步提升模型性能,研究人员会在特定领域的 Text-to-SQL 数据集,例如 Spider 和 WikiSQL 上微调模型,使模型更好适应不同数据库的结构特征和查询模式。微调后的模型能够更精确理解领域术语以及表字段之间的关系,从而生成更符合现实需求的 SQL 语句。这使模型在处理复杂多表查询或嵌套查询问题时尤其有效。
基于大语言模型的 Text-to-SQL 实现
ChatGPT 和 GPT-4 等大语言模型的出现,彻底重塑了 Text-to-SQL 的实现方式。通过大规模预训练,这些模型已经学习了自然语言和 SQL 之间的复杂映射,即使没有专门微调,也可以生成高质量 SQL 语句。
与传统"分步骤"方法相比------它需要手动实现自然语言理解、schema 映射、SQL 结构生成等流程------大模型时代的 few-shot learning 和 in-context learning 为 Text-to-SQL 提供了新的可能。只要在 prompt 中提供数据库 schema、解释信息和对应 SQL 查询示例,大模型就可以快速适应新的数据库结构和查询类型。
示例:构建一个简单的 Text-to-SQL 工作流
假设我们有两张表,其结构如下:
| Field Name | Data type | Description | Example value |
|---|---|---|---|
scenic_id |
INT | 主键,景点唯一标识 | 1 |
scenic_name |
VARCHAR | 景点名称 | Jinci |
city |
VARCHAR | 所在城市 | Taiyuan City |
level |
VARCHAR | 景区等级 | AAAAA level |
monthly_visitors |
INT | 当月游客数量 | 50000 |
表 5.1:scenic_spots 表结构,包括景点标识、名称、位置、等级和月游客量。
| Field name | Data type | Description | Example value |
|---|---|---|---|
city_id |
INT | 主键,城市唯一标识 | 1 |
city_name |
VARCHAR | 城市名称 | Taiyuan City |
annual_tourism_income |
INT | 年度文旅收入,单位:元 | 200000000 |
表 5.2:city_info 表结构,包括城市标识、城市名称和年度旅游收入。
famous_dish |
Type | Category | Example |
|---|---|---|---|
| VARCHAR | Local Specialty/Snack | Knife-cut Noodles |
表 5.3:famous_dish 字段说明,表示某个城市关联的地方特产或小吃。
首先,使用下面的代码创建这两张数据库表:
python
## 连接 SQLite 数据库
import sqlite3
conn = sqlite3.connect('data/tourism.db')
cursor = conn.cursor()
## 创建景点表
cursor.execute('''
CREATE TABLE IF NOT EXISTS scenic_spots (
scenic_id INTEGER PRIMARY KEY,
scenic_name VARCHAR(100) NOT NULL,
city VARCHAR(50) NOT NULL,
level VARCHAR(20),
monthly_visitors INTEGER
)''')
## 创建城市信息表
cursor.execute('''
CREATE TABLE IF NOT EXISTS city_info (
city_id INTEGER PRIMARY KEY,
city_name VARCHAR(50) NOT NULL,
annual_tourism_income INTEGER,
famous_dish VARCHAR(100)
)''')
## 向景点表插入示例数据
sample_scenic_spots = [
(1, 'Jinci Temple', 'Taiyuan City', 'AAAAA', 50000),
(2, 'Mount Wutai', 'Xinzhou City', 'AAAAA', 80000),
(3, 'Yungang Grottoes', 'Datong City', 'AAAAA', 70000),
(4, 'Pingyao Ancient City', 'Jinzhong City', 'AAAAA', 90000),
(5, 'Qiao Family Compound', 'Jinzhong City', 'AAAAA', 45000)
]
cursor.executemany(
'INSERT OR REPLACE INTO scenic_spots VALUES (?, ?, ?, ?, ?)',
sample_scenic_spots)
## 向城市信息表插入示例数据
sample_city_info = [
(1, 'Taiyuan City', 200000000, 'Knife-cut Noodles'),
(2, 'Datong City', 180000000, 'Datong Vinegar'),
(3, 'Jinzhong City', 150000000, 'Daozi Noodles'),
(4, 'Xinzhou City', 120000000, 'Youmian Kaolao Lao'),
(5, 'Yuncheng City', 130000000, 'Yuncheng Boiled Cake')
]
cursor.executemany('INSERT OR REPLACE INTO city_info VALUES (?, ?, ?, ?)',
sample_city_info)
## 提交更改并关闭连接
conn.commit()
conn.close()
print("Database tables created and sample data inserted.")数据库表准备好之后,现在就可以相应构建 Text-to-SQL 程序。完整代码可参考 github.com/PacktPublis...
ini
## 连接 SQLite 数据库
import sqlite3
conn = sqlite3.connect('data/tourism.db')
cursor = conn.cursor()
## 准备 Schema 描述
schema_description = """
You are accessing a database containing two tables:
1. scenic_spots (Scenic Spot Information Table)
- scenic_id (INT): Primary key, unique identifier for the scenic spot
- scenic_name (VARCHAR): Name of the scenic spot
- city (VARCHAR): City where it is located
- level (VARCHAR): Scenic spot rating
- monthly_visitors (INT): Number of visitors this month
2. city_info (City Information Table)
- city_id (INT): Primary key, unique identifier for the city
- city_name (VARCHAR): Name of the city
- annual_tourism_income (INT): Annual tourism income (unit: RMB)
- famous_dish (VARCHAR): Local famous dish/special snack
"""
## 初始化 OpenAI Client
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY")
)
## 设置查询
user_query = "Query the AAAAA-rated scenic spots in Taiyuan City and their monthly visitors"
## 准备 SQL 生成 Prompt
prompt = f"""
The following is the structural description of the database:
{schema_description}
The user's natural language question is as follows:
"{user_query}"
Please note:
1. The 'city' field in the scenic_spots table stores the city name, corresponding to the city_name field in the city_info table
2. The association between the two tables should use city_name and city for matching
3. Please return SQL query statement only, do not include any explanation, comments, or formatting marks (such as ```sql)
"""
## 调用大模型生成 SQL 语句
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "Only return the SQL statement, do not include any Markdown formatting or other notes."},
{"role": "user", "content": prompt}
],
temperature=0
)
## 清理 SQL 语句,移除可能出现的 Markdown 标签
sql = response.choices[0].message.content.strip()
sql = sql.replace('```sql', '').replace('```', '').strip()
print(f"\nGenerated SQL query statement:\n{sql}")生成结果如下:
ini
SELECT scenic_name, monthly_visitors
FROM scenic_spots
WHERE city = 'Taiyuan' AND level = 'AAAAA';接下来,执行大模型生成的 SQL 语句并获取结果。
scss
## 执行 SQL 语句并获取结果
cursor.execute(sql)
results = cursor.fetchall()
print(f"Query results: {results}")
conn.close()
## Query Results
Query results: [('Jinci Temple', 50000)]然后,我们再将这些数据传回大模型,让它以自然语言形式输出。
ini
## 生成自然语言描述
if results:
# 获取列名
column_names = [description[0] for description in cursor.description]
# 将结果转换成字典列表
results_with_columns = [dict(zip(column_names, row)) for row in results]
nl_prompt = f"""
Query results are as follows:
{results_with_columns}
Please convert these data into a natural language description that is easy to understand.
The original question is: {user_query}
Requirements:
1. Use simple and easy-to-understand language
2. Include all queried data information
3. If there are numbers, please use Chinese numeral expressions
"""
response_nl = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are responsible for converting query results into easy-to-understand natural language descriptions."},
{"role": "user", "content": nl_prompt}
],
temperature=0.7
)
description = response_nl.choices[0].message.content.strip()
print(f"Natural language description:\n{description}")
else:
print("No relevant data found.")
## 关闭数据库连接
conn.close()输出如下:
css
According to the query results, among the AAAAA-level scenic spots in Taiyuan, the current month's number of visitors to Jinci reached fifty thousand.这说明,在一个简单问答系统中,学习者不需要深入了解数据库结构或 SQL 语法,也能快速获取想要的信息。
结合 Agent、SQL data function 和 tool calls 的方案
前面的示例展示了直接生成 SQL 的方式。不过,在更复杂的业务场景中,通常需要一种更可控的方案。
Anna:Lewis,前面介绍的 Text2SQL 方法在简单场景中表现不错。不过,在处理复杂业务逻辑时,这种方法往往无法生成有效查询,或者稳定性无法保证。在实践中,你认为有没有更稳定的技术路线?
Lewis:我和行业里的朋友讨论过这个问题。确实,正如你指出的,这是 Text2SQL 面临的挑战。经过多次迭代之后,我们逐渐形成了一种兼顾效率和稳定性的中间方案,主要是利用 Agents 的 Tool Calls 能力,结合预先定义的 Data-Function 模板,这些模板内部包含 SQL 语句,以及 metadata extraction,实现从自然语言到结构化数据库表操作的安全过渡。
如何理解 metadata extraction
Anna:应该如何理解 metadata extraction?
Lewis:这里指的是提取数据库 metadata,包括字段信息、表结构和视图描述,并手动补充必要的资源文档。只有经过处理的 metadata 才能被嵌入成 vectors。
什么是 data functions
Anna:那么,data functions 是什么?
Lewis:Data functions 是一套函数模板体系,目标是建立通用数据函数,以支持常见查询场景。为具体业务开发 data functions,类似于为传统 ORM 框架,例如 MyBatis 和 Hibernate,开发模板机制。通过将复杂 SQL 逻辑封装进模板,可以提升代码复用性。
接下来是智能调度过程,它利用 function call 机制承担处理和重路由职责。大模型协作理解用户意图,检索相关 metadata 和适用 data functions,并执行单步或多步 SQL 组装与查询。
下面的代码示例演示如何结合使用 Agent、SQL-Data-Function 和 Tool Calls。代码通过模块化 tool definition 添加工具描述,并定义实现函数,为工具提供具体功能。
接下来,将数据库结构描述注入 system prompt,其中包括表字段的业务含义及其关系。
python
import sqlite3
from typing import Dict, Any, List
import json
from openai import OpenAI
import os
def load_schema_metadata() -> str:
"""加载数据库 metadata 描述"""
return '''
### Database Structure Metadata
scenic_spots (Tourist Attractions Information Table)
- scenic_id: Primary Key
- scenic_name: Name of the tourist attraction (e.g. "Jinci Temple")
- city: City where it is located (associated with city_info.city_name)
- level: Attraction level (AAAA/AAAAA)
- monthly_visitors: Number of visitors this month
city_info (City Information Table)
- city_name: Primary Key
- annual_tourism_income: Annual cultural tourism income (unit: Yuan)
- famous_dish: Specialty cuisine
'''接下来,使用 execute_sql 函数实现整个程序的基础查询层。该函数统一处理 SQL 执行、参数化查询、错误处理和结果格式化,从而确保数据访问的安全性和标准化。然后,将常见查询需求封装成三个核心函数:
query_scenic_spots 函数支持对景点进行多条件组合查询,例如按所在城市、景区等级、月游客数进行过滤。
query_city_info 函数可以对城市信息进行灵活查询,并支持排序。
cross_table_query 函数封装了景点信息表和城市信息表之间的关联查询逻辑。
这些函数是由业务逻辑预定义的 SQL-Data-Function。
python
def execute_sql(db_path: str, sql: str, params: tuple = ()) -> Dict:
"""执行 SQL 查询的基础方法"""
print("\n=== SQL Execution Details ===")
print(f"SQL Statement: {sql}")
print(f"Parameters: {params}")
try:
with sqlite3.connect(db_path) as conn:
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
cursor.execute(sql, params)
results = [dict(row) for row in cursor.fetchall()]
print(f"Execution results: {results}")
print("=== Execution Successful ===\n")
return {"success": True, "data": results, "message": "Execution Successful"}
except Exception as e:
print(f"Execution Failed: {str(e)}")
print("=== Execution Failed ===\n")
return {"success": False, "data": None, "message": f"Execution Failed: {str(e)}"}
def query_scenic_spots(db_path: str, city: str = None, level: str = None, min_visitors: int = None) -> Dict:
"""查询旅游景点的预定义函数"""
conditions = []
params = []
if city:
conditions.append("city = ?")
params.append(city)
if level:
conditions.append("level = ?")
params.append(level)
if min_visitors:
conditions.append("monthly_visitors >= ?")
params.append(min_visitors)
where_clause = " AND ".join(conditions) if conditions else "1=1"
sql = f"SELECT scenic_name, city, level, monthly_visitors FROM scenic_spots WHERE {where_clause}"
def query_city_info(db_path: str, city_name: str, order_by: str = None) -> Dict:
"""查询城市信息的预定义函数"""
order_clause = ""
if order_by:
order_clause = f" ORDER BY {order_by} DESC"
sql = f"SELECT * FROM city_info WHERE city_name LIKE ?{order_clause}"
return execute_sql(db_path, sql, (f"%{city_name}%",))
def cross_table_query(db_path: str, target_city: str, min_income: int) -> Dict:
"""预定义跨表 join 查询函数"""
sql = """
SELECT s.scenic_name, s.level, c.annual_tourism_income
FROM scenic_spots s
JOIN city_info c ON s.city = c.city_name
WHERE s.city = ? AND c.annual_tourism_income >= ?
"""
return execute_sql(db_path, sql, (target_city, min_income))上述函数为了安全使用参数化查询,以防止 SQL injection,并通过枚举严格约束参数值,例如将景区等级限制为 AAAA 或 AAAAA。此外,使用 QueryResult 对象统一格式化返回结构,确保其中包含执行状态 success、数据 data 和消息 message,并配合详细执行日志输出。系统实现了对执行异常的统一处理,同时保留原始错误信息。这种设计使查询过程更透明,也更容易调试。
接下来,使用大模型的 Tool Calls 功能实现 tool routing,其中每个 tool 对应一个预定义的 SQL-Data-Function 模板。工具调用结果会被自动加入对话上下文,从而更方便处理后续追问。
其中,define_tools 函数定义了三个结构化查询工具:query_scenic_spots 用于查询景点信息,支持按城市、景区等级和月游客量过滤;query_city_info 用于查询城市信息,支持按年度旅游收入或特色美食排序;cross_table_query 用于跨表查询,可以关联景点和城市信息。
process_query 函数实现了一个两轮对话查询流程。
两轮对话查询流程
第一轮:将用户问题和数据库 schema 信息发送给 GPT 模型,让它选择合适的查询工具;然后,根据 GPT 选择的 tool 执行对应数据库查询。
第二轮:将查询结果发送给 GPT 模型,生成自然语言答案。
python
def define_tools() -> List[Dict]:
"""定义结构化数据访问的基础函数"""
return [
{
"type": "function",
"function": {
"name": "query_scenic_spots",
"description": "Query scenic spot information based on conditions",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "The name of the city where it is located"},
"level": {"type": "string", "enum": ["AAAA", "AAAAA"]},
"min_visitors": {"type": "number", "description": "Minimum threshold of visitors"}
}
}
}
},
{
"type": "function",
"function": {
"name": "query_city_info",
"description": "Query city cultural tourism information",
"parameters": {
"type": "object",
"properties": {
"city_name": {"type": "string", "description": "City name"},
"order_by": {"type": "string", "enum": ["annual_tourism_income", "famous_dish"]}
}
}
}
},
{
"type": "function",
"function": {
"name": "cross_table_query",
"description": "Cross-table joint query for scenic spot and city information",
"parameters": {
"type": "object",
"properties": {
"target_city": {"type": "string", "description": "Target city name"},
"min_income": {"type": "number", "description": "Minimum annual tourism income"}
}
}
}
}
]
def process_query(db_path: str, user_input: str) -> str:
"""处理用户查询的完整流程"""
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY")
)
tools = define_tools()
schema_metadata = load_schema_metadata()
system_prompt = f"""
You can select the appropriate **data access method** according to the user's question.
The current **database structure** is as follows:
{schema_metadata}
Please give priority to using **predefined functions** to access data. Note:
- **City names** must be an exact match (e.g., 'Taiyuan City')
- **Scenic spot grades** must use the standard format (e.g., 'AAAA')
- **Numeric parameters** must be converted to integer type
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input}
]
### 第一次调用,选择工具
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools,
tool_choice="auto"
)
tool_calls = response.choices[0].message.tool_calls
if not tool_calls:
return response.choices[0].message.content
### 执行工具调用
messages.append(response.choices[0].message)
for tool_call in tool_calls:
func_name = tool_call.function.name
kwargs = json.loads(tool_call.function.arguments)
if func_name == "query_scenic_spots":
result = query_scenic_spots(db_path, **kwargs)
elif func_name == "query_city_info":
result = query_city_info(db_path, **kwargs)
elif func_name == "cross_table_query":
result = cross_table_query(db_path, **kwargs)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": func_name,
"content": json.dumps(result, ensure_ascii=False)
})
### 生成自然语言答案
final_response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
temperature=0.3
)
return final_response.choices[0].message.content到这里,一切都准备好了,我们可以开始进行自然语言查询。大语言模型会先将我们的自然语言输入转换成一次 tool invocation,然后执行 Data-Function 模板中的 SQL 语句,并将查询结果作为答案返回。完整代码可参考 github.com/PacktPublis...
scss
db_path = "data/tourism.db"
query = "Please help me find all AAAAA-level scenic spots in Taiyuan City and list the attractions with more than 40,000 visitors."
print("\n=== User Query ===")
print(f"Query Content: {query}")
result = process_query(db_path, query)
print("\n=== Final Result ===")
print(result)输出如下:
sql
=== User Query ===
Query Content: Please help me find all AAAAA-level scenic spots in Taiyuan City and list the attractions with more than 40,000 visitors.
=== SQL Execution Details ===
SQL Statement: SELECT scenic_name, city, level, monthly_visitors FROM scenic_spots WHERE city = ? AND level = ? AND monthly_visitors >= ?
Parameters: ('Taiyuan City', 'AAAAA', 40000)
Execution Result: [{'scenic_name': 'Jinci', 'city': 'Taiyuan City', 'level': 'AAAAA', 'monthly_visitors': 50000}]
=== Execution Successful ===
=== Final Result ===
Among the AAAAA-level scenic spots in Taiyuan City, the attractions with more than 40,000 visitors this month are:
- Jinci, with 50,000 visitors this month.上述程序的执行过程如下:
大模型分析用户意图,并选择调用 query_scenic_spots 工具。
参数转换:city="Taiyuan City"、level="AAAAA"、min_visitors=40000。
执行预定义 SQL 查询:SELECT ... WHERE city = 'Taiyuan City' AND level = 'AAAAA' AND monthly_visitors >= 40000。
将查询结果注入上下文。
大模型基于原始问题和查询结果生成最终答案。
该方案通过使用预定义 data functions 和严格参数控制,在保证灵活性的同时有效管理查询风险。结合 metadata descriptions 和 tool invocation mechanisms,它既保留了自然语言交互的便利性,也实现了对结构化数据的精准访问。虽然创建 SQL-Data-Functions 需要一定前期投入,但这种方法实现了更稳定可靠的执行。对于企业用户而言,系统稳定性和可控性往往优先于开发便利性,因此这种折中方案在实践中获得了积极反馈。
Text-to-Cypher:从自然语言到图数据库查询
在关系型数据库之后,RAG 系统中的另一个重要结构化数据源是图数据库。
理解图数据库
图数据库是一种基于图结构的数据存储形式。随着企业数据从结构化转向多模态、网络化和复杂关联,图数据库凭借强大的关系建模能力,特别适合表示复杂实体关系网络,因此成为处理这类复杂数据关系的首选工具之一。
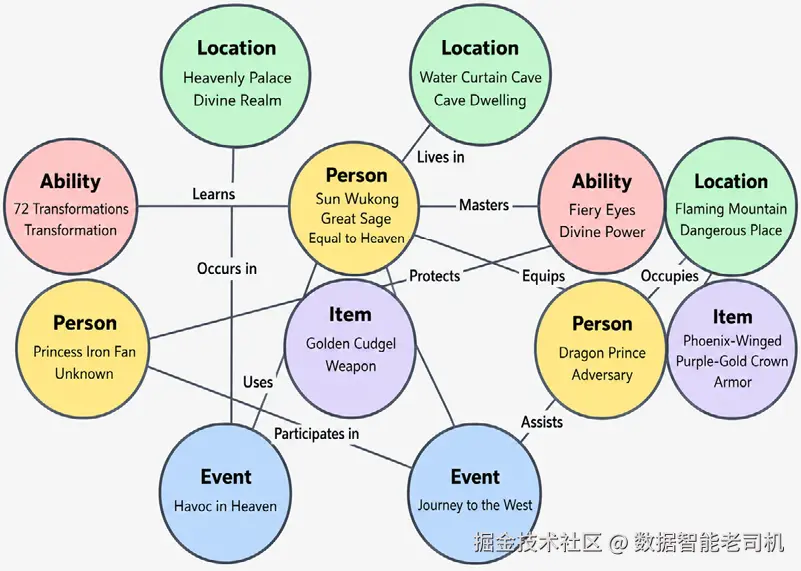
图 5.2:概念图通过语义关系连接角色、物品、能力、事件和地点。
图数据库的核心组件
图数据库的核心组件如下:
Node:表示数据中的实体,例如"Employee""Customer""Product"等。
Edge:描述节点如何连接,例如"manages""purchases""depends on"等。
Property:为节点或边提供更详细的附加信息,例如"Name""Age""Price""Time"等。
为什么图数据库在 RAG 中很重要
在 RAG 系统中,连接图数据库可以对实体关系网络进行高效查询和推理。例如,在社交网络关系分析、理解企业组织结构、优化物流网络路线等场景中,图数据库的应用尤其有效。引入图数据库后,系统不仅可以检索孤立文本或数据,还可以基于实体之间的关系进行深入推理并生成回答。
Alex:Lewis,我有点理解了,但你能不能给一个具体例子,说明图数据库的重要性?
Lewis:当然。我用一个假设例子来解释。假设在某个项目中,你帮助一家物流公司设计问答系统。当用户问"Huaguoshan Fresh Fruit 的供应链风险是什么?"时,初始 RAG 系统无法给出令人满意的答案。因为搜索结果只包含 Huaguoshan Fresh Fruit 的产品信息,以及公司的供应链风险文档,并没有提供有价值洞察。
没有 Text-to-Cypher 步骤的 RAG 系统可能会回答:"Huaguoshan Fresh Fruit 通常在四月至五月进入销售高峰。建议提前通知供应商协调供货,并确保仓库准备就绪。" 这种答案其实并没有真正回应用户的询问。
但是,在加入 Text-to-Cypher 步骤进行图数据库查询之后,RAG 系统利用图数据库中的关系,有效地将产品与供应商连接起来。它还通过供应商知识图谱关联当地天气情况,从而给出更准确的答案:"Huaguoshan Fresh Fruit 由供应商 A Pantao Yuan(位于上海,天气晴朗)和供应商 B Wuzhuangguan(位于广东,有强暴雨)供货。目前,Wuzhuangguan 可能因暴雨面临供应风险。建议监控其库存,并考虑备用供应商。" 这才是真正具备业务洞察的答案。
通过应用 community detection 等图分析算法,我们可以识别图结构中的"子群体",也就是内部节点连接紧密、但与其他群组连接较松散的集群。结合图数据库和 community detection 技术,RAG 系统不仅能进行简单文本匹配,还能深入理解数据内部关联,提供更丰富内容和更智能的决策支持。
Alex:Lewis,我觉得我懂了。Community detection 就像帮我们在数据里找到"朋友圈"!这样,系统就能发现那些关键关系,而不只是孤立的信息片段。
Lewis:没错。图数据库的典型代表是 Neo4j,而 Cypher 是 Neo4j 等图数据库中广泛使用的查询语言。Cypher 的设计类似 SQL,但专门用于处理图数据中的节点、关系和属性。
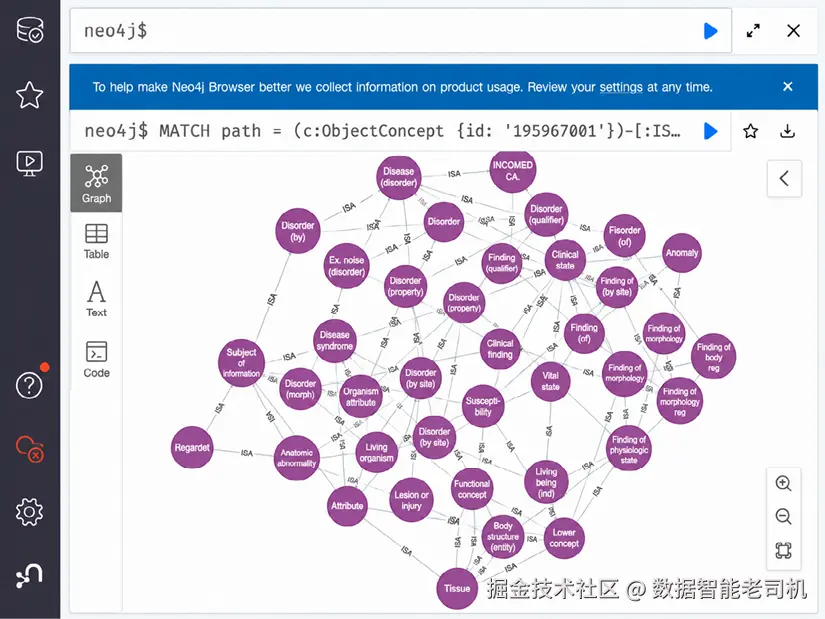
图 5.3:Neo4j 浏览器窗口展示一个复杂图,其中包含紫色节点和带标签连接。
Cypher 基础语法
Cypher 的基础语法如下:
节点匹配 :(n:Label) 表示匹配带有 Label 标签的节点。
关系匹配 :(a)-[r:RELATIONSHIP]->(b) 表示从节点 a 到节点 b 存在 RELATIONSHIP 类型的关系。
属性过滤 :使用 WHERE 子句过滤节点或关系的属性。
例如,要查找某个员工的所有直接下属,可以使用下面的 Cypher 查询:
perl
MATCH (e:Employee)-[:MANAGES]->(sub:Employee)
WHERE e.name = "Alice"
RETURN sub.name;这个查询会在图中查找所有由名为 Alice 的员工直接管理的员工。
Text-to-Cypher 工作流
Text-to-Cypher 的架构类似 Text-to-SQL,包含以下主要步骤:
自然语言理解:解析用户问题,提取意图、实体和关系。
Schema matching:将自然语言中的实体或关系映射到图数据库中的 node labels、relationship types 和 properties。
Cypher generation:基于解析结果动态生成 Cypher 查询。
查询验证和执行:检查生成的 Cypher 查询语法是否正确,并提交到图数据库执行。
关键区别在于,Cypher 查询通常需要考虑更复杂的多跳关系。此外,图数据库的 schema 通常更加灵活,这给查询生成带来了更大不确定性。
由于篇幅限制,我们无法在这里深入图数据库、Neo4j 和 Cypher 语言的所有细节。接下来,通过一个简单示例启发你理解自然语言转换成 Cypher 查询的过程。
示例:从自然语言生成 Cypher 查询
假设存在以下 node types:
Yokai :包含属性 name,妖怪名称,以及 strength,妖怪战斗力。
BattleScene :包含属性 location,场景位置,以及 difficulty,场景难度。
关系类型如下:
[:PARTICIPATES_IN]:表示某个妖怪参与了某个战斗场景。
[:LOCATED_IN]:表示某个战斗场景位于特定地点。
图数据库的 schema 如下:
css
Nodes:
(Yokai {name: "Bull Demon King", strength: 900})
(Yokai {name: "Lady White Bone", strength: 750})
(Yokai {name: "King Golden Horn", strength: 850})
(BattleScene {location: "Flaming Mountain", difficulty: "Hard"})
(BattleScene {location: "White Bone Cave", difficulty: "Normal"})
Relationships:
(Yokai {name: "Bull Demon King", strength: 900})-[:PARTICIPATES_IN]->(BattleScene {location: "Flaming Mountain", difficulty: "Hard"})
(Yokai {name: "Lady White Bone", strength: 750})-[:PARTICIPATES_IN]->(BattleScene {location: "Flaming Mountain", difficulty: "Hard"})
(Yokai {name: "King Golden Horn", strength: 850})-[:PARTICIPATES_IN]->(BattleScene {location: "White Bone Cave", difficulty: "Normal"})
(BattleScene {location: "Flaming Mountain", difficulty: "Hard"})-[:LOCATED_IN]->("Flaming Mountain")
(BattleScene {location: "White Bone Cave", difficulty: "Normal"})-[:LOCATED_IN]->("White Bone Cave")下面是一个 prompt,用来帮助大模型理解图数据库结构并生成 Cypher 查询。
vbnet
You are a Text-to-Cypher expert. Below is the schema of a graph database.
Nodes:
- Yokai: Properties: name (string), strength (integer)
- BattleScene: Properties: location (string), difficulty (string)
Relationships:
- PARTICIPATES_IN: From Yokai to BattleScene
- LOCATED_IN: From BattleScene to Location
User question: "Find all yokai that participate in scenes with a difficulty of 'hard', and return their strength."
Please generate a Cypher query.基于上述 prompt,大模型会生成下面的 Cypher 查询:
css
MATCH (yokai:Yokai)-[:PARTICIPATES_IN]->(scene:BattleScene {difficulty: "困难"})
RETURN yokai.name, yokai.strength;SQL 查询 vs Cypher 查询
下表总结了 SQL 和 Cypher 查询之间的主要差异。
| Query type | Data model | Query target | Syntax style | Complex relationship modeling capability |
|---|---|---|---|---|
| SQL query | 表格型,例如表、行、列 | 行和列 | 类自然语言的声明式语法 | 依赖多表 JOIN |
| Cypher query | 图结构,例如节点、关系、属性 | 节点和关系 | 声明式 + 图模式匹配 | 原生支持节点和关系,对复杂查询更高效 |
表 5.4:SQL 和 Cypher 查询在数据模型、查询目标、语法风格和复杂关系建模能力方面的对比。
Text-to-Cypher 的优势之一,是支持多跳查询和推理。当用户提出涉及多个节点和关系的问题时,例如"Find the department budgets of employees managed by Alice",Text-to-Cypher 可以生成一个跨多个节点的查询------先确定与查询相关的部门,再进一步检查这些部门的具体预算。
知识图谱与问答系统的结合,目前是一个非常重要的应用方向。通过将知识图谱纳入 RAG 系统,可以实现更智能的语义问答和深度推理,从而为企业智能决策提供更强技术支持。
Self-query retriever:从查询中自动生成 metadata filter conditions
对于向量数据,自然语言查询可以直接被 embedding,并用于检索相关信息,而不需要像 Text-to-SQL 或 Text-to-Cypher 那样构造特定查询语句。这个过程包含若干检索前优化技术,其中之一就是 Self-query Retriever 技术。该技术可以自动从自然语言查询中提取信息,生成 metadata filter conditions,从而帮助 vector stores 通过关键词对文档进行初步过滤。
Alex:Lewis,你这个解释不是很清楚。什么是 Self-query Retriever?从自然语言查询中自动生成 metadata filter conditions 是什么意思?还有,具体怎么通过关键词过滤?
Lewis:我觉得我已经讲得挺清楚了。不过,我们还是用一个具体例子来更清楚地解释这个设计理念。
视频检索的 metadata 字段
下面的代码示例演示如何使用 LangChain 框架构建一个智能视频检索系统。这里我们以山西文旅为例。假设我们已经加载了介绍景点、城市等内容的视频。爬取这些视频时,我们自然会获得以下 metadata fields,它们会作为 metadata filtering 的基础。
title:文档标题。
description:文档描述。
view_count:文档浏览量。
publish_date:发布日期。
length:文档长度,单位秒。

图 5.4:山西文物数字体验馆入口。
结合向量检索和 metadata filtering
通过使用 Self-query Retriever 技术,自然语言查询中的关键检索点可以被转换成结构化查询,并基于视频 metadata 进行精准过滤。这种方法结合了 vector retrieval 和 metadata filtering,形成了一种支持跨多个维度查询视频属性的混合检索方法。这个过程完美展示了向量检索和结构化检索的结合,非常值得深入研究。
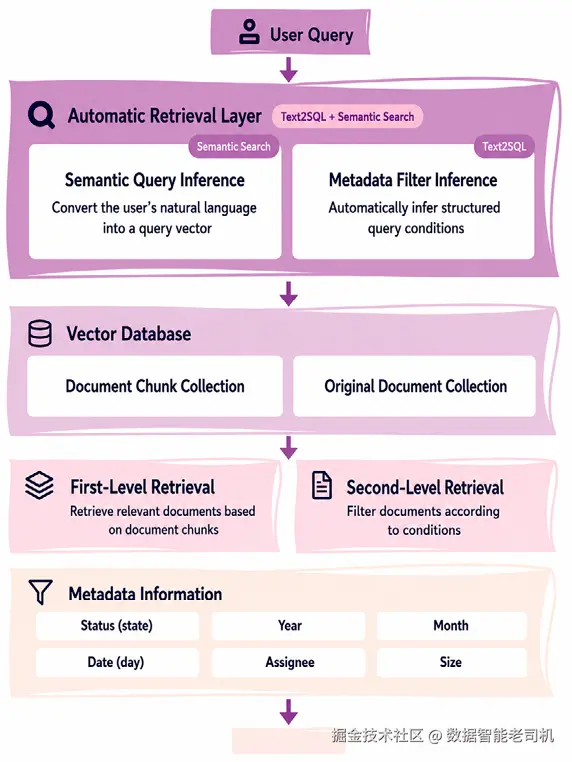
图 5.5:流程图展示一个用于文档搜索的多层自动化查询系统。
Lewis:我猜 LangChain 在其 RAG 文档中把 Self-query Retriever 归类为 query construction 技术,是因为生成 metadata 和 filter expressions 的过程,本质上构造了结构化检索元素。当然,从本质上看,这项技术也属于下一章要讨论的 hybrid retrieval。
安装所需库
首先,安装一些必要的库。pytube 和 youtube-transcript-api 用于连接 YouTube,Chroma 作为向量数据库,支持 Self-query Retriever 中的 metadata filters,作者也试过 Faiss 和 Milvus,但发现它们都不支持 Self-query Retriever,lark 是用于飞书的 Python API 交互包。
pip install pytube
pip install youtube-transcript-api
pip install langchain-chroma
pip install lark安装这些依赖后,作者在尝试通过脚本连接视频网站时遇到错误。在相关论坛帖子中,有人建议将 pytube 包中 innertube.py 文件的 InnerTube 类中的 client 值从 ANDROIDMUSIC 改为 WEB。做出这个修改后,问题得到解决。
图 5.6:代码编辑器展示 Python 类 InnerTube,其中设置了初始化和文件路径变量。
加载带 metadata 的文档
下面是使用 LangChain 中 YoutubeLoader 类加载文档的示例。
python
from langchain_community.document_loaders import YoutubeLoader
### 加载带 Metadata 的文档
docs = YoutubeLoader.from_youtube_url(
"https://www.youtube.com/watch?v=zDvnAY0zH7U",
add_video_info=True
).load()
### 查看第一个加载文档的 Metadata
print(docs[0].metadata)输出如下:
vbnet
{
'source': 'zDvnAY0zH7U',
'title': '...Tang Dynasty Wooden Architecture...in the Mountains of Shanxi...A Must-Visit Place in One's Lifetime',
'description': "The Tang Dynasty was the heyday of China's feudal society, with many Tang Dynasty stone architectural works across the country... At Mount Wutai, Shanxi, there is a grand Tang Dynasty wooden structure preserved, which is the largest and best preserved Tang Dynasty wooden structure in China.",
'view_count': 81598,
'publish_date': '2024-04-08 00:00:00',
'length': 1394,
'author': 'On the Journey'
}这些 metadata fields 正是我们用于 query filtering 的字段。计算浏览量、比较发布日期等,恰恰是传统数据库字段的优势,而不是向量语义检索的优势。
构建 self-query retriever
下面的代码分阶段构建 retriever:加载视频、创建 embeddings、配置 metadata fields,并初始化 retriever。
下面是完整的 Self-query Retriever 代码示例。
python
### 导入所需库
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_community.document_loaders import YoutubeLoader
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from pydantic import BaseModel, Field
### 定义视频 Metadata 模型
class VideoMetadata(BaseModel):
"""视频 metadata 模型,定义需要提取的视频属性"""
source: str = Field(description="Video ID")
title: str = Field(description="Video title")
description: str = Field(description="Video description")
view_count: int = Field(description="View count")
publish_date: str = Field(description="Publish date")
length: int = Field(description="Video length (seconds)")
author: str = Field(description="Author")
### 加载视频数据
video_urls = [
"https://www.youtube.com/watch?v=zDvnAY0zH7U", # Shanxi Foguang Temple
"https://www.youtube.com/watch?v=iAinNeOp6Hk", # China's Largest Compound
"https://www.youtube.com/watch?v=gCVy6NQtk2U", # Song Dynasty Underground Palace
]
### 加载视频 Metadata
videos = []
for url in video_urls:
try:
loader = YoutubeLoader.from_youtube_url(url, add_video_info=True)
docs = loader.load()
doc = docs[0]
videos.append(doc)
print(f"Loaded: {doc.metadata['title']}")
except Exception as e:
print(f"Failed to load {url}: {str(e)}")创建 vector store:
ini
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(videos, embed_model)为 retriever 配置 metadata fields。
metadata fields 设置如下:
bash
metadata_field_info = [
AttributeInfo(
name="title",
description="Video title (string)",
type="string",
),
AttributeInfo(
name="author",
description="Video author (string)",
type="string",
),
AttributeInfo(
name="view_count",
description="Video view count (integer)",
type="integer",
),
AttributeInfo(
name="publish_date",
description="Video publish date, a string in the format YYYY-MM-DD",
type="string",
),
AttributeInfo(
name="length",
description="Video length, an integer in seconds",
type="integer",
),
]创建 SelfQueryRetriever:
ini
llm = ChatDeepSeek(model="deepseek-chat", temperature=0) # 确定性输出
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="Video metadata including title, author, view count, publish date, and other information",
metadata_field_info=metadata_field_info,
enable_limit=True,
verbose=True
)执行示例查询:
python
queries = [
"Find two videos with more than 100,000 views",
"Show the most recently published video"
]
## 执行查询并输出结果
for query in queries:
print(f"\nQuery: {query}")
try:
results = retriever.invoke(query)
if not results:
print("No matching videos found")
continue
for doc in results:
print(f"Title: {doc.metadata['title']}")
print(f"Views: {doc.metadata['view_count']}")
print(f"Publish Date: {doc.metadata['publish_date']}")
except Exception as e:
print(f"Query error: {str(e)}")
continue输出如下:
vbnet
Loaded: ' ......Tang Dynasty Wooden Architecture in the Mountains of Shanxi......A must-visit place in one's lifetime'
Loaded: ' ......Private mansion, owner started out selling tofu......Twice the size of the Forbidden City'
Loaded: ' ......Live footage of a Song Dynasty underground palace......An internal refrigerator used for 2,000 years'
Query: Find videos with more than 100,000 views
Title: ' ......Live footage of a Song Dynasty underground palace......An internal refrigerator used for 2,000 years'
Views: 263138
Publish Date: 2024-01-27 00:00:00
Title: ' ......Private mansion, owner started out selling tofu......Twice the size of the Forbidden City'
Views: 907279
Publish Date: 2023-11-11 00:00:00
Query: Show the most recently published video
Title: ' ......Live footage of a Song Dynasty underground palace......An internal refrigerator used for 2,000 years'
Views: 263138
Publish Date: 2024-01-27 00:00:00Self-query retriever 通过 metadata configuration 实现从自然语言到结构化查询的转换,将"Find videos with more than 100,000 views"这样的请求转换成结构化查询条件。
其内部生成的解析文本如下,其中字段名 view_count、条件 gt 和值 100000 都是由大语言模型从用户问题中自动提取出来的。
json
{ "query": "Find two videos with more than 100,000 views", "filter": "gt("view_count", "100000")", "limit": 2 }从输出结果可以看到,Self-query Retriever 不仅能够准确识别符合条件的视频,还可以筛选出最近发布的视频。
Self-query retriever 的局限
不过,Self-query retriever 的表现并不稳定;对于某些查询,例如"Find videos published in January 2024",Lewis 在测试中发现其回答并不准确。
当出现错误时,用户需要深入 LangChain 代码库进行调试。这也是 LangChain 被批评的一点:它提供了有用工具,但工具并非完全可靠。因此,这些框架中的工具可能更适合作为灵感来源;在生产环境中,我们需要基于这些概念自行实现更稳健的方案。
Query translation:更好地解释用户问题
前面介绍的 query construction 方法通过大模型能力生成各种结构化查询语句,不同于 vector search,用于访问结构化数据源。相比之下,接下来要讨论的 query translation,主要关注通过 prompt engineering 对用户输入进行语义重构。
具体来说,当查询质量较低时------它可能包含噪声或含糊术语,或者没有覆盖所需信息检索的所有方面------就需要采用一系列优化技术,例如 rewriting、decomposition、clarification 和 expansion,来改进查询,使其更完整,从而获得更好的检索结果。
Query rewriting:将原始问题改写为合适形式
Query rewriting 指的是将原始问题重新表述为更合适的形式,以提升系统检索结果的准确性。
通过 prompts 引导大语言模型重写 queries
最直接的方法,是使用自定义 prompt templates,让大语言模型重写用户查询。下面是一个简单的 query rewriting 示例。
python
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
)
def rewrite_query(question: str) -> str:
"""使用大语言模型重写查询"""
prompt = """As a game customer service representative, you need to help users rewrite their questions.
Rules:
1. Remove irrelevant information (e.g., personal situations, chit-chat)
2. Use accurate gaming terminology
3. Preserve the core intent of the question
4. Convert vague questions into specific queries
Original question: {question}
Please provide the rewritten query directly (do not add any prefixes or explanations)."""
# 使用 DeepSeek 模型重写查询
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": prompt.format(question=question)}
],
)
return response.choices[0].message.content.strip()
query = "Well, I just started playing this game, it feels really hard, I can't get past the Putuo Mountain level no matter what. Which skills should I learn first? Any tips for beginners!"
print(f"\nOriginal query: {query}")
print(f"Rewritten query: {rewrite_query(query)}")输出如下:
kotlin
Original query: Um, I just started playing this game, and it feels really hard. I'm stuck at the Putuo Mountain level and just can't get through. Which skills should I learn first? Beginner seeking advice!
Rewritten query: For the Putuo Mountain level, which skills should beginners prioritize learning?经过大语言模型重写后,新查询变得更清晰、更简洁。它不仅节省 token 数,也能为玩家更有效地检索结果。
使用 RePhraseQueryRetriever 优化 queries
LangChain 提供了一个开箱即用的工具 RePhraseQueryRetriever,用于执行 query rewriting。它利用大语言模型和内部设置的 prompts,使查询更加简洁清晰。
下面的代码示例展示如何使用 RePhraseQueryRetriever 优化查询。
ini
import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers import RePhraseQueryRetriever
### 设置日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.re_phraser").setLevel(logging.INFO)
loader = TextLoader("data/Destruction of Gods/setup.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embed_model)
### 设置 RePhraseQueryRetriever,用大语言模型重构查询
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
query = "Well, I just started playing this game, it feels really hard, I'm stuck on the Putuo Mountain level and just can't get through. Which skills should I learn first? Any tips for a beginner?"
### 使用 RePhraseQueryRetriever 进行 Query Rewriting
docs = retriever_from_llm.invoke(query)日志输出如下:
yaml
INFO: langchain.retrievers.re_phraser: Re-phrased question: Vectorstore query: "Putuo Mountain level beginner skill recommendations game guide" Explanation: - Removed conversational fillers ("Well", "just") and emotional expressions ("feels really hard", "just can't get through", "Any tips for a beginner"). - Kept key game-specific terms: Location: "Putuo Mountain" (level implied), Core need: "skill recommendations", Context: "beginner" and "game guide". - Structured for optimal retrieval of strategy guides or skill trees relevant to the early-game hurdle.从日志信息可以看到,重写后的查询更加简洁清晰,不必要内容也被移除,这有助于提升检索效率和准确性。当然,这个新 Query 是英文的,因为 LangChain 的 RePhraseQueryRetriever 类内部默认 prompt 是英文。
我们可以自定义 prompt,并将其传给 RePhraseQueryRetriever 的 from_llm 方法,以确保重写结果为中文。不过,具体代码实现我留作作业,因为阅读 LangChain 文档,即 langchain\retrievers\re_phraser.py,并理解类设计细节,是技术人员必须具备的能力。
Query decomposition:将查询拆解成多个子问题
Query rewriting 的目标是让查询更加规范,而 query decomposition 更进一步,它会将一个查询拆解成多个子问题。这样可以从不同视角探索查询的不同方面,使检索到的内容更丰富。
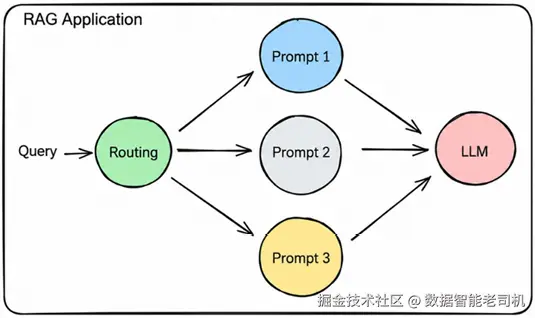
图 5.7:流程图展示一个 query 被路由到三个 prompts,每个 prompt 都指向 RAG apps 中的大模型。
通过 prompts 引导大语言模型分解查询并不困难,因此这里不提供 prompt 示例。你也可以使用 LangChain 提供的 MultiQueryRetriever 工具,让大语言模型从不同视角生成多个 queries。
对于每个生成的 query,retriever 都会从向量数据库中获取对应文档集。然后,所有查询结果中的文档会被去重并合并成一个更丰富的结果集,从而提供更多相关内容。
使用 MultiQueryRetriever
下面的示例展示 MultiQueryRetriever 如何从一个复杂用户问题中生成多个相关 queries。
ini
import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
### 设置日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
loader = TextLoader("data/灭神纪/设定.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding=embed_model)
### 使用 MultiQueryRetriever 生成多视角查询
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
question = "Well, I just started playing this game and it feels very difficult. How would you rate the difficulty of this game, how many levels are there, and in the Putuo Mountain level, hmm, I just can't get through. Which skills should I learn first? Any tips for beginners?"
docs = retriever_from_llm.invoke(question)日志输出如下:
vbnet
INFO:langchain.retrievers.multi_query:Generated queries: [
'What is the difficulty level of this game? How many levels are there? Are there any tips you can share for the Putuo Mountain stage?',
'For beginners, which skills should be learned first to better tackle the challenges in the game?',
'I find it difficult when playing this game. Are there any suggestions or tips to help me successfully pass the Putuo Mountain stage?'
]上述过程会自动生成多个形式的 queries,并返回 all queries 的合并结果,文档数量可能多于单个 query 得到的结果。
如果你想要更 complex 的 query expressions,也可以自定义 prompt template。例如,生成 5 个不同版本的查询,并让这些查询具备特定语气。
ini
### 加载游戏相关文档并构建向量数据库
...
### 自定义输出解析器
class LineListOutputParser(BaseOutputParser[List[str]]):
def parse(self, text: str) -> List[str]:
lines = text.strip().split("\n")
return list(filter(None, lines)) # 过滤空行
output_parser = LineListOutputParser()
### 自定义 Query Prompt Template
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an experienced game customer service agent. Please rewrite the user's query from 5 different perspectives
to help the user obtain more detailed game guidance.
Make sure each query focuses on a different aspect, such as skill selection, combat strategy, equipment matching, etc.
User's original question: {question}
Please provide 5 different queries, one per line.""",
)
### 设置大模型处理 Pipeline
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
llm_chain = QUERY_PROMPT | llm | output_parser
### 使用自定义 Prompt Template 的 MultiQueryRetriever
retriever = MultiQueryRetriever(
retriever=vectorstore.as_retriever(),
llm_chain=llm_chain,
parser_key="lines"
)
### 执行多角度查询
custom_docs = retriever.invoke("For the Putuo Mountain level, which skills should beginners prioritize learning?")日志输出如下:
vbnet
INFO:langchain.retrievers.multi_query:Generated queries: [
'In the Putuo Mountain checkpoint, which skills should beginners prioritize learning to enhance survivability?',
'In the Putuo Mountain checkpoint, which skills should beginners prioritize learning to improve output damage?',
'In the Putuo Mountain checkpoint, which skills should beginners prioritize learning to enhance team support capabilities?',
'In the Putuo Mountain checkpoint, which skills should beginners prioritize learning to enhance control ability?',
'In the Putuo Mountain checkpoint, which skills should beginners prioritize learning to deal with specific enemies or combat scenarios?'
]MultiQueryRetriever 适合需要多视角查询的场景,例如复杂问题或模糊查询。它可以增强检索结果的丰富性和多样性。
Query clarification:逐步细化并澄清用户问题
在论文 "Tree of Clarifications: Using Retrieval-Augmented Large Language Models to Answer Ambiguous Questions" 中,研究人员提出了一个名为 Tree of Clarifications,简称 ToC 的框架。该框架通过递归构建问题澄清树,逐步细化并澄清用户问题。对于"Which country has won the most medals in Olympic history?" 这样一个模糊问题,系统会生成一系列澄清问题,例如 In which edition of the Olympics? 或 In which sport?,以获得更多上下文信息。
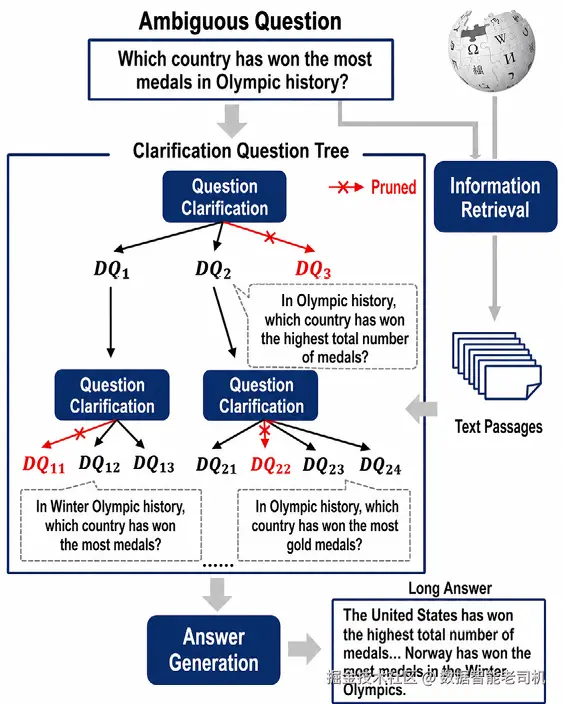
图 5.8:使用澄清问题树回答模糊问题的工作流,其中原始 query 被分解为更具体的子问题,不相关分支被剪枝,相关文本段落被检索,最终生成答案。
下面是一个问题澄清树的代码示例。该示例使用树结构探索问题的多种可能解释,并利用外部知识检索提升回答准确性。同时,它使用 few-shot prompting 生成综合答案。
python
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
from typing import List, Dict, Set, Optional
from dataclasses import dataclass
## 定义 Clarification Node 的数据结构
@dataclass
class ClarificationNode:
"""澄清节点的数据结构"""
id: str
text: str
aspect: str
depth: int
parent_id: Optional[str] = None
answers: Optional[List[str]] = None
## 构造知识库数据
def create_knowledge_base() -> Dict:
"""创建知识库"""
return {
"abilities": {
"combat": {
"physical": ["Invulnerability", "Superhuman Strength", "Iron-like Muscles"],问题管理模板:
python
def create_question_templates(character_name: str) -> Dict[str, Dict[str, str]]:
"""创建问题模板"""
return {
"abilities": {
"root": f"Which type of abilities would you like to know about regarding {character_name}?",
"combat": f"In terms of combat abilities, which skill of {character_name} are you most interested in?",
"perception": f"Regarding the perception abilities of {character_name}, which specific aspects do you want to learn about?"
},
"relationships": {
"root": f"Whose relationship with {character_name} would you like to know about?",
"allies": f"Among the allies of {character_name}, which type of relationship interests you?",
"enemies": f"Regarding {character_name}'s opponents, which faction are you interested in?"
}
}执行问题分析:
完整代码可参考 github.com/PacktPublis...
python
def identify_main_aspects(question: str) -> Set[str]:
"""识别问题的主要方面"""
aspects = set()
keywords = {
"abilities": ["abilities", "talents", "skills", "magic", "powers"],
"relationships": ["relationships", "friends", "enemies", "master-disciple", "making friends"]
}
for aspect, words in keywords.items():
if any(word in question for word in words):
aspects.add(aspect)
if not aspects:
aspects.add("abilities")
return aspects
def identify_character(question: str, characters: List[str]) -> Optional[str]:
"""识别问题中提到的角色"""
for character in characters:
if character in question:
return character
return None
### 构建问题澄清树
def build_clarification_tree(
question: str,
character: str,
knowledge_base: Dict,
templates: Dict[str, Dict[str, str]]
) -> nx.DiGraph:
G = nx.DiGraph()
# 添加根节点
root_id = "root"
G.add_node(root_id, text=question, depth=0)
# 分析问题的主要方面
main_aspects = identify_main_aspects(question)
# 构建树的每一层
for aspect in main_aspects:
if aspect not in knowledge_base:
continue
# 第一层:主要方面
node_id = f"{aspect}_root"
G.add_node(node_id,
text=templates[aspect]["root"],
depth=1)
G.add_edge(root_id, node_id)
# 第二层:子方面
for sub_aspect, sub_data in knowledge_base[aspect].items():
sub_node_id = f"{aspect}_{sub_aspect}"
template_text = templates[aspect].get(
sub_aspect,
f"What do you want to know about {sub_aspect}?"
)
G.add_node(sub_node_id, text=template_text, depth=2)
G.add_edge(node_id, sub_node_id)
# 第三层:具体细节
for detail_type, details in sub_data.items():
detail_node_id = f"{aspect}_{sub_aspect}_{detail_type}"
detail_text = f"Do you want to know about these related to {detail_type}: {', '.join(details)}?"
G.add_node(detail_node_id,
text=detail_text,
depth=3,
answers=details)
G.add_edge(sub_node_id, detail_node_id)
return G
## 澄清树可视化
def visualize_tree(G: nx.DiGraph, figsize=(15, 10)):
"""可视化澄清树"""
plt.figure(figsize=figsize)
pos = nx.spring_layout(G, k=2, iterations=50)
depths = nx.get_node_attributes(G, 'depth')
colors = ['lightblue', 'lightgreen', 'lightyellow', 'lightpink']
for depth in range(max(depths.values()) + 1):
nodes_at_depth = [node for node, d in depths.items() if d == depth]
nx.draw_networkx_nodes(G, pos,
nodelist=nodes_at_depth,
node_color=colors[depth],
node_size=2000)
nx.draw_networkx_edges(G, pos, edge_color='gray', arrows=True)
labels = nx.get_node_attributes(G, 'text')
nx.draw_networkx_labels(G, pos, labels, font_size=8, font_weight='bold')
plt.title("Clarification Tree")
plt.axis('off')
plt.tight_layout()
plt.show()
## 使用澄清树
kb = create_knowledge_base()
templates = create_question_templates("Sun Wukong")
tree = build_clarification_tree(question, "Sun Wukong", kb, templates)
visualize_tree(tree)生成的问题澄清树如下。
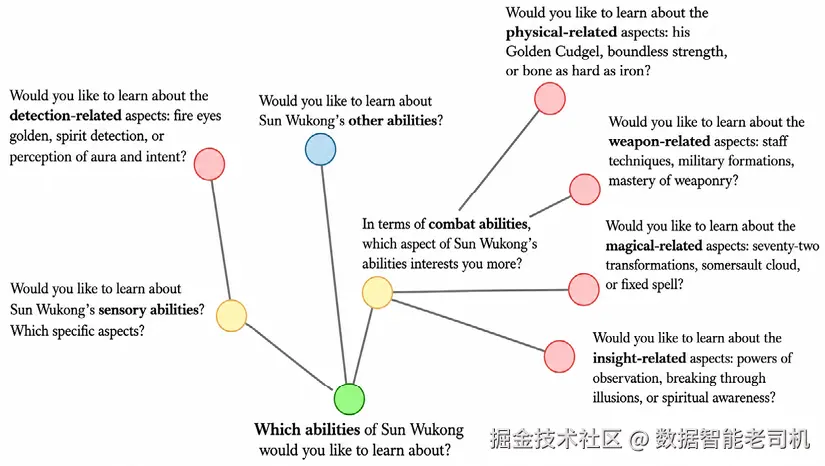
图 5.9:查询图展示关于孙悟空能力问题的层级拆解。
使用 HyDE 生成假设文档进行 Query expansion
Hypothetical Document Embeddings,简称 HyDE 技术,源自卡内基梅隆大学 Language Technologies Institute 的一篇论文,题为 Precise Zero-Shot Dense Retrieval without Relevance Labels。
该方法的核心在于:为给定 query 创建一个假设答案文档,对该文档进行 embedding,然后用这个 embedding 作为最终 query 的表示。
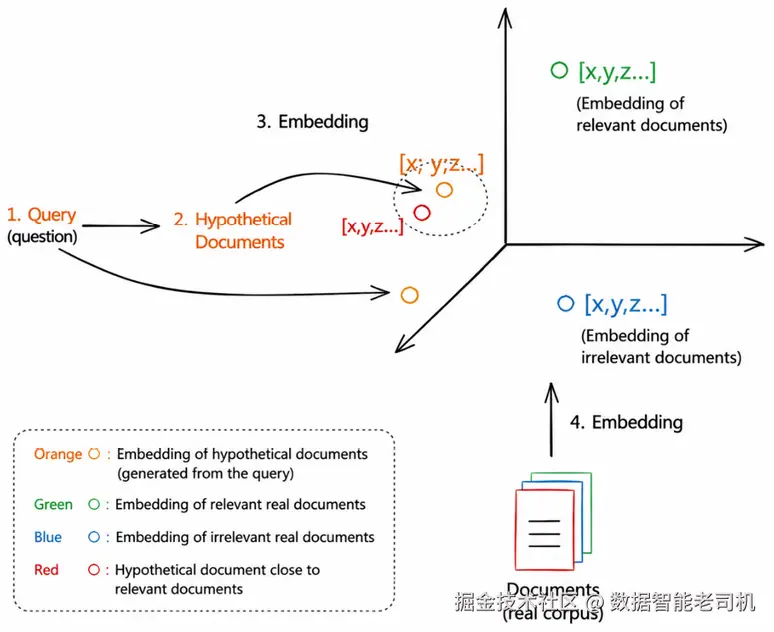
图 5.10:图示展示问题和文档如何作为向量嵌入到 3D 空间中进行比较。
这种创新方法的亮点在于,它并不直接学习相关性,而是通过生成假设文档来构建与 query 对齐的 embedding。这意味着在检索之前,系统会先生成一段假设内容。这种新范式通过比较生成的假设文档与真实答案文档之间的相似度来执行检索。这种方法极具创造性,为信息检索领域提供了一个全新视角。
HyDE 的实现非常直接,只需要一个基础 embedding 模型和一个用于生成假设文档的大模型。
ini
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
loader = TextLoader("data/灭神纪/情节片段.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectordb = Chroma.from_documents(documents=splits, embedding=embed_model)
### HyDE 文档生成模板
template = """Please write a piece of game content related to the following question:
Question: {question}
Content:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
llm = ChatDeepSeek(model="deepseek-chat")
### 创建用于生成假设文档的 Chain
generate_docs_for_retrieval = (prompt_hyde | llm | StrOutputParser())示例 RAG workflow 代码:
python
question = "What are the main skills of the protagonist in 'Myth of Demon Extinction: Hu Sun'?"
generated_doc = generate_docs_for_retrieval.invoke({"question": question})
print("\n=== Generated Hypothetical Document ===")
print(generated_doc)
retriever = vectordb.as_retriever()
retrieval_chain = generate_docs_for_retrieval | retriever
retrieved_docs = retrieval_chain.invoke({"question": question})
print("\n=== Retrieved Relevant Documents ===")
for i, doc in enumerate(retrieved_docs, 1):
print(f"\nDocument {i}:")
print(doc.page_content)
answer_template = """Answer the question based on the following content:
{context}
Question: {question}
Answer:"""
answer_prompt = ChatPromptTemplate.from_template(answer_template)
final_rag_chain = (answer_prompt | llm | StrOutputParser())
final_answer = final_rag_chain.invoke({"context": retrieved_docs, "question": question})
print("\n=== Final Answer ===")
print(final_answer)生成的假设文档如下:
rust
Generated hypothetical document: In the game Myth of Demon Extinction: Hu Sun, the protagonist possesses a variety of core skills, including the Golden Cudgel Skill for melee attacks using the Golden Cudgel, the Flame Skill for unleashing powerful fire attacks, the Lightning Skill for summoning lightning to deal area damage, as well as the Wind Skill utilizing the power of wind for ranged strikes, among others.检索到的相关文档如下:
vbnet
Retrieved relevant documents: Chaos splits the sky, dark clouds roll. Hu Sun stands atop the heavens, eyes like burning torches, wielding the Golden Cudgel with ease, bringing everything to stillness. An army of a million is instantly frozen in the wind. With a low shout: "Transformation!" he instantly multiplies into thousands, reality and illusion indistinguishable, as if a god descended to earth. The Seventy-Two Transformations are dreamlike and elusive, reality and falsehood impossible to tell, leaving enemy generals astonished: "How can this monkey possess such magical powers!" But Hu Sun has already soared on clouds, riding the Somersault Cloud straight up to the sky, his wild laughter echoing across mountains and rivers...最终答案如下:
less
Final answer: The main skills of the protagonist in Myth of Demon Extinction: Hu Sun include the Seventy-Two Transformations, Somersault Cloud, and the Golden Cudgel.HyDE 方法的优势在于它具有上下文感知能力;它通过生成假设文档捕捉 query 的上下文和潜在意图。这种方法可以通过自定义 prompt templates 来满足不同领域需求,也可以通过生成多个假设文档来扩展检索覆盖范围,并增强结果相关性。
不过,需要注意的是,生成假设文档需要额外计算资源和时间,而且 HyDE 的效果高度依赖所使用大模型的质量。因此,在实际应用中决定是否采用 HyDE 技术时,必须仔细权衡它带来的性能收益与所需成本。
Query routing:找到正确的数据源
构造或翻译 query 之后,系统可能仍然需要决定这个 query 应该去哪里。
Lewis:Alex,你能说说为什么 RAG 系统需要 query routing 吗?
Alex:我觉得可能和 hybrid vector storage 有关。在复杂 RAG 系统中,向量数据库里的 vector storage 可能有多种形式,也可能使用多个向量数据库,甚至不同类型的数据库会存储不同格式的数据。当我们的复杂查询被拆解成子问题后,需要将 query 高效路由到正确的数据源。
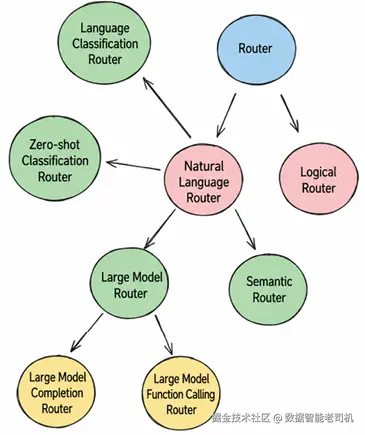
图 5.11:各种 router 类型之间的关系。
Anna:没错。而且不只是因为数据源不同,处理不同类型问题的方式也可能不同。例如,如果用户询问游戏内容,或者向客服投诉,后续处理方法可能完全不同。
Lewis:完全正确,这就是"将请求路由到最合适的地方"的过程,本质上其实是 intent recognition。随着系统规模扩大,使用 routing mechanisms 分发用户输入,可以确保不同数据源或处理流程都能通过 query routing 无缝集成。
Logical routing:确定 query 路径
Logical Routing 负责决定 query 应该被发送到哪里。系统从用户输入问题开始,通过大模型对问题进行分析和语义理解,并基于问题特征对其分类,生成结构化输出,以指导 retriever 的选择。
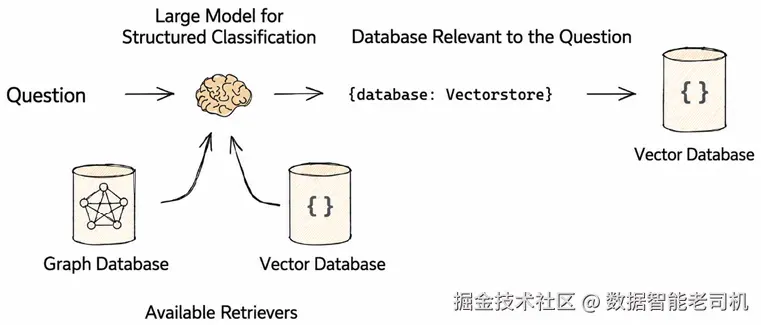
图 5.12:图示展示问题经模型分类后,查询图数据库或向量数据库的过程。
例如,问题首先被分类,以判断它与 graph database 相关,还是与 vector database 相关。在检索阶段,系统可以选择不同数据库,例如 graph databases 或 vector databases。
当问题涉及复杂实体关系或结构化数据时,例如查询组织结构或实体之间的关联,系统会选择图数据库执行查询并返回结果;而当问题需要基于语义相似度进行检索时,例如查找与某篇文档语义相似的内容,系统会选择向量数据库,将 query 和 data 转换成 vectors,并使用 vector similarity 查找相关内容。
再举一个例子,如果我们为不同场景构建了三个向量数据库,分别是 python_docs、js_docs 和 golang_docs,并希望将当前用户问题路由到 python_docs、js_docs 或 golang_docs 中的一个,那么可以先对问题进行分类,判断它属于哪种编程语言类别;然后根据分类结果执行对应的下游处理,选择 Python、JavaScript 或 Go 的处理逻辑。
示例:路由到不同数据源
下面是 LangChain 提供的 logical routing 代码示例。
python
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_deepseek import ChatDeepSeek
### 数据模型
class RouteQuery(BaseModel):
"""Route the user's query to the most relevant data source"""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Select the most suitable data source to answer the question based on the user's query",
)
### 支持 Function Calling 的大模型
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
system = """You are an expert at routing user questions to the appropriate data source.
Route them to the relevant data source according to the programming language involved."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
### 定义 Router
router = prompt | structured_llm关于在 query routing 后通过 Function / Tool Calls 功能访问不同数据源的完整示例,请访问 Lewis 的 GitHub 仓库。
Semantic routing:选择相关 prompts
Logical routing 指的是根据用户问题选择合适的数据源或检索方法,而 semantic routing 则是根据用户问题的"语义"选择有针对性的 prompt templates。
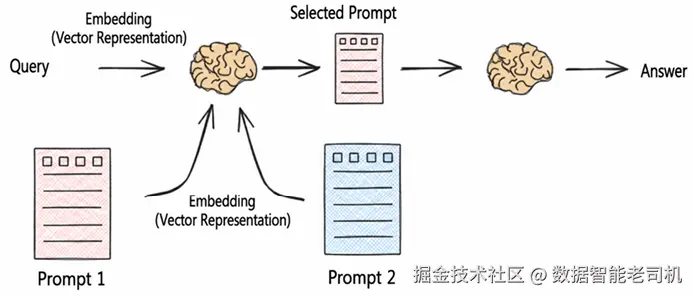
图 5.13:图示展示问题和 prompts 如何被嵌入、选择,并最终导向答案。
示例:路由到 prompt templates
下面是一个 semantic routing 的简单代码示例。
python
from langchain.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
### 定义两个 Prompt Templates
combat_template = """You are an expert proficient in game combat skills.
You excel at answering questions about game combat in a concise and easy-to-understand manner.
When you don't know the answer to a question, you will admit it honestly.
Here is a question:
{query}"""
story_template = """You are an expert familiar with game storylines.
You are good at breaking down complex plots and explaining them in detail.
When you don't know the answer to a question, you will admit it honestly.
Here is a question:
{query}"""
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
prompt_templates = [combat_template, story_template]
prompt_embeddings = embed_model.embed_documents(prompt_templates)
### 定义 Routing Function
def prompt_router(input):
query_embedding = embed_model.embed_query(input["query"])
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
## 选择最相似的 Prompt Template
print("Using combat skills template:" if most_similar == combat_template else "Using story template:")
return PromptTemplate.from_template(most_similar)
chain = (
{"query": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| ChatDeepSeek(model="deepseek-chat")
)
StrOutputParser()
print(chain.invoke("How does the monkey defeat his enemies?"))输出如下:
vbnet
Using the combat skills template: In battle, the monkey mainly focuses on using instant movement and powerful punching and kicking skills to defeat his enemies. He can also release his aura to enhance his combat power. Through continuous training and relentless effort, the monkey is able to quickly adapt to different opponents' fighting styles and find effective ways to deal with them. Ultimately, his calmness and strong will to fight are also important factors that allow him to defeat his enemies.总结
虽然检索前阶段的各种技术并不是 RAG 系统不可或缺的组成部分,但它们为我们优化 RAG 系统性能、设计更复杂系统提供了重要启发。
将结构化数据整合进 RAG 系统,是一个关键挑战。在真实业务应用中,只依赖非结构化数据的场景是有限的。学习者通常需要连接已有关系型数据库,或者查询 Excel、CSV 文件。因此,当我们把结构化数据引入 RAG 系统时,核心思路是保持数据原有结构清晰性,不要破坏它。
直接对结构化数据进行 embedding 并检索,往往效果并不理想,经常导致数据丢失,或者难以处理时间序列数据。Text-to-Query 技术可以帮助大模型或规则引擎理解问题中的 entities、intents 和 conditions,并将它们映射到数据库的表结构、字段、关系和查询逻辑,从而在 RAG 系统工作流中实现有效的结构化数据查询。正如 Lewis 强调的,希望大家理解其底层含义。这也是为什么 Text-to-SQL 需求如此显著------毕竟涉及内部数据库的操作,最终仍然需要 SQL 来解决,单靠向量检索无法满足这一需求。
不过,Text-to-SQL 和 Text-to-Cypher 等技术在简单场景中表现良好,但在复杂逻辑场景中缺乏稳定性。因此,一个折中方案是:首先提取数据库 metadata,包括字段信息、表结构和视图描述,并补充必要的人工解释,然后进行 embedding;接着,建立通用和特定 data functions,预定义复杂查询逻辑;最后,结合 Agent 的 Tool Calls 功能,让大模型在理解学习者意图后,基于 metadata 和 data functions 动态组装 SQL 语句并执行查询。
特别值得注意的是,Self-query Retriever 方法可以从查询中自动生成 metadata filter conditions。首先,定义 metadata,告诉 retriever 每个字段的类型和含义,使它能够准确解释查询意图。然后,它会自动生成一系列基于 metadata 的条件过滤语句,在检索之前执行结构化过滤。这建立了一种双重过滤机制:一方面,使用 vector storage 对内容执行语义搜索;另一方面,基于提取出的 metadata conditions 执行精确过滤,例如"view count greater than 100000"。这种设计使查询既能捕捉语义相关性,又能实现精确条件过滤。自动生成这些 metadata filters,正是 Self-query Retriever 在 query construction 阶段执行的额外工作,它结合了基于关键字段的检索和语义检索,体现了 hybrid retrieval 的特点。
通过检索前阶段的处理,系统可以更准确地构造查询、分解问题并过滤噪声,从而生成覆盖范围更广或内容更精确的更好查询。
最后,query routing 是复杂系统中 hybrid queries 的基础。如果系统中存在多个数据源,就应该先使用 routing 或 intent recognition 筛选目标数据源,然后定位合适路径。例如,它可以判断是否使用 Text-to-SQL 或 Text-to-Cypher 查询相关结构化数据库,从而提升后续检索和生成任务的准确性与效率。这些技术为跨结构化和非结构化数据源,或者多样化、多层级向量数据库数据源的智能混合查询场景奠定了基础,也展示了更高级的系统设计。