π0.7\pi_{0.7}π0.7:一个具备涌现能力的可引导的通用机器人基础模型
π0.7\pi_{0.7}π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
摘要
π0.7\pi_{0.7}π0.7 可以在未见过的环境中遵循各种语言指令,包括使用各种厨房用具的多阶段任务,提供zero-shot 跨形态泛化,例如让机器人在未见过任务的情况下折叠衣物,并执行具有挑战性的任务,比如开箱即用地操作咖啡机,其性能可以匹配很多经过强化学习微调的专用模型。π0.7\pi_{0.7}π0.7 的核心思想是在训练过程中使用多样化的上下文条件。提示中包含的这些条件信息,使模型能够精确地执行许多具有不同策略的任务。它不仅基于描述应执行内容的语言指令,还基于额外的多模态信息,说明执行任务的方式或策略,包括任务性能的元数据和子目标图像。这使得 π0.7\pi_{0.7}π0.7 能够利用非常多样的数据,包括示范、可能不理想的(自主)数据,包括失败案例以及来自非机器人的数据。我们的实验评估了 π0.7\pi_{0.7}π0.7 在多个机器人平台上的各类任务表现,这些任务需要速度和灵巧性、语言跟随能力,以及组合任务泛化能力。
I. 引言
基础模型的原理是,通过在大规模、多样化的数据集上训练,通用能力会自然而然地出现。例如,大型语言模型不仅可以记忆事实和语义知识,还可以以新的方式组合这些知识,解决需要不太可能联系的问题,应用用户定义的格式(例如 JSON),并进行链式思维推理。这种组合式概括能力可以说是通用能力的基石,但在物理智能领域却一直难以实现。虽然像视觉-语言-动作模型(VLA)这样的机器人基础模型在规模和能力上有了显著提升,但它们对新任务的泛化能力或以新方式重组技能的能力至今仍有限。与语言模型不同,语言模型可以从训练数据中组合不同能力来解决新问题,而此前的 VLA 不仅缺乏解决新任务的能力,而且往往在没有特定任务微调的情况下,也难以流畅完成所有训练指令。
π0.7\pi_{0.7}π0.7表现出强烈的组合泛化特性 ------ 能够执行各种语言指令,在灵巧任务上达到与更多专门微调模型相当的性能,甚至能够以新的方式组合这些行为。这得益于利用大规模、多样化的数据集,包括来自拥有不同策略的众多机器人的数据、自动执行过程中产生的次优数据(包括强化学习后训练代理的数据以及失败数据),以及来自人类执行任务的视频和互联网上的通用多模态数据。然而,单纯使用这些数据并不会自动成功:当示例在策略和任务表现上差异很大时,单纯的训练过程会导致模型将数据中的不同模式平均在一起,从而产生次优结果。在训练 π0.7\pi_{0.7}π0.7 时,我们通过对数据进行详细的上下文标注来应对这一挑战,这些标注不仅包含"做什么"的信息,还包含"如何做"的知识,并通过各种多模态条件信号提供给模型。通过这种方式,每个训练单元都教会机器人细微的概念和技能,它不仅能有效完成训练任务,还能以新的方式组合这些技能来解决新任务。我们提出的提示结构包括详细的语言标签、策略元数据以及多模态信息,例如子目标图像。这使我们能够解决大规模多样化数据集中的模糊性,从次优行为中学习而不影响性能,并在指令、实体类型和环境上实现广泛的泛化。
关于提示或上下文可以提升基础模型性能的想法,在其他领域已经有所探索。例如,用于图像和视频生成的模型会利用提示扩展来生成高质量的作品。我们的方法在很多方面与这些方法相似。不过,在机器人领域,仅仅用更详细的文字来描述数据是不够的------决定任务成功和熟练度的细节可能更微妙(比如,关于整个实验过程质量的信息),或者只是很难用语言表达(比如,一件干净叠好的T恤的具体外观)。因此,除了使用更详细的文字外,我们的模型还在提示中加入了一系列额外的元数据,如图1所示,包括实验质量信息(策略元数据)、机器人使用的控制方式、以及子目标图像。这些信息在测试时可以提供也可以省略,但在训练中加入它们可以让模型更有效地组合它训练过的概念,并展现出多种新兴能力。
在我们的评估中,我们展示了 π0.7\pi_{0.7}π0.7 展现出超越以往机器人基础模型的多种能力:
• 开箱即用的表现:π0.7\pi_{0.7}π0.7 可以可靠地执行高精度、长时间跨度的任务,例如使用咖啡机、叠衣服、拿出垃圾袋、折叠纸箱和削蔬菜,无需任何特定任务的后训练,并且可以适应各种环境。
• 指令泛化能力:π0.7\pi_{0.7}π0.7 可以在未见过的环境中遵循各种语言指令,并表现出对复杂、未见过语言描述的强大泛化能力。例如,π0.7\pi_{0.7}π0.7 能够在完全未见过的厨房和卧室环境中,执行一系列开放式指令。
• 跨实体泛化:π0.7\pi_{0.7}π0.7 可以实现零样本跨实体迁移,使得像叠 T 恤这样的灵巧任务可以转移到从未训练过任何叠衣服任务的机器人上,并且其表现与专家操作者初次远程操控机器人的表现相当。
• 组合任务泛化能力:π0.7\pi_{0.7}π0.7 可以通过以前未见过的方式组合技能来执行新任务。例如,我们可以提示 π0.7\pi_{0.7}π0.7 使用新的厨房电器,如将红薯放入空气炸锅,或者提示它以新的方式完成任务。
通过消融和规模研究,我们还从经验上证明,多样化的数据集和详细的上下文之间存在强大的协同效应:我们的方法可以在不影响模型性能的情况下,从混合质量的数据和非标准数据源中学习,而且在训练中提供详细的上下文信息时,多样化的数据可以提升模型的性能。
II. 相关工作
通用机器人操作策略 。目前有大量研究致力于开发通用机器人的策略。这些通用策略有时是从零开始训练的 1--6,但更常见的是使用预训练的视觉-语言模型 7--23 或预训练的视频生成模型 24--28 进行初始化。各种研究还开发了视觉-语言-动作(VLA)的架构组件,如记忆 29--37、用于长远规划的层级结构 13, 14, 38--40 以及目标图像条件 41。我们开发了一个在单个模型中融合了这三种组件的 VLA 模型,基于 π0.6\pi_{0.6}π0.6-MEM 架构 37, 42。虽然通用策略最常在机器人示范数据上训练,但已有研究展示了如何通过结合网络数据 7、人类的第一视角视频 25, 43--49 和自主机器人经验 50--52 来提升预训练效果。我们整合了所有这些数据源,发现多样数据与详细提示的结合能够得到一个具有强组合泛化特征且开箱即用表现优异的模型。
跨任务和载体(embodiments)的泛化。之前的很多工作都致力于学习能够泛化的机器人策略,不仅能适应不同的环境、物体和背景,还能适应全新的任务和载体。通常,这通过利用人类视频数据来实现,要么用于通用表示学习53--58,要么通过直接用人类动作进行监督45, 59--65,或者通过提取二维点tracks66--69。其他工作则试图通过在训练或推理过程中直接利用互联网预训练的基础模型来提高泛化能力70--76。随着大规模、跨载体的机器人数据集越来越多77,也有一些工作专注于显式提升机器人之间的跨形态迁移能力78--84。与其使用现有数据集,一些工作提出了专门的手持设备,用来收集可以泛化到各种机器人载体的数据85, 86。在本研究中,我们发现合适的提示可以让我们的模型利用多样的机器人、人类和互联网数据,在任务和形态之间实现强泛化能力。
用子目标图像提示机器人 。与 π0.6\pi_{0.6}π0.6-MEM 相比,我们模型的一个核心架构组件是允许模型使用目标图像(包括生成的子目标图像)进行提示。在大量研究中,已经探索了将机器人操作策略与目标图像和视频关联的方法。其中一些研究使用了用户提供的图像 87--90,而另一些则将策略与来自独立模型生成的目标图像 91--98 或以连锁思维方式生成的目标图像 41 相关联。另外,图像和视频生成可以集成到策略训练目标中 24--26, 99--101,以提升策略表示并产生更具泛化能力的操作。我们认为我们的贡献对这些工作是互补的:我们并不打算提出新的架构或模型设计,而是提供一种方法论,使视觉语言代理(VLA)能够利用更多样化的数据来源,同时通过实证分析显示这能显著提升组合泛化能力。据我们所知,我们的实证结果远超以往研究中报告的量化改进,展示了精巧技能的零样本迁移能力,例如将洗衣折叠技能迁移到不同机器人,并能泛化到新颖的对象交互,如操作空气炸锅。
III. 基于流的视觉-语言-动作模型
VLA 的训练始于一个预训练的视觉-语言模型(VLM)主干,并将其适配用于机器人控制。训练数据集 D\mathcal{D}D 包含机器人轨迹,即观测值 ot\mathbf{o}_tot 和动作 at\mathbf{a}_tat 的序列。观测值 ot=It1,...,Itn,qt\mathbf{o}_t = \\mathbf{I}_t\^1, \\ldots, \\mathbf{I}_t\^n, \\mathbf{q}_tot=It1,...,Itn,qt 由 nnn 个相机图像 Iti\mathbf{I}_t^iIti 和机器人的关节配置 qt\mathbf{q}_tqt 组成,而动作 at\mathbf{a}_tat 则由关节或末端执行器指令组成。
VLA 通常被训练来预测一个动作块(action chunk) ,对应于未来动作的短轨迹 at:t+H\mathbf{a}{t:t+H}at:t+H,这是基于最近的观测历史 ot−T:t\mathbf{o}{t-T:t}ot−T:t(通常会执行一个更短的动作视界(horizon),H^<H\hat{H} < HH^<H)。该动作块可以由一个"动作专家(action expert)"生成,这是一个关注 VLM 主干的小型 Transformer,能够在运行时进行快速推理。动作专家通常使用流匹配(flow matching)102(或扩散)目标函数,以捕捉机器人动作的多模态特性。为了学习有效的表示,我们的模型还使用了知识隔离(knowledge insulation)训练方案 103:VLM 主干通过 FAST tokens 104 进行监督,虽然动作专家关注 VLM 主干中的所有激活值,但来自动作专家的梯度不会流入 VLM 主干,从而确保 VLM 是通过相对稳定的离散交叉熵损失进行训练的。
在设计 π0.7\pi_{0.7}π0.7 时,我们探讨了添加到每个训练样本上下文中的额外信息如何能够支持从多样化和异构数据集(包括次优行为和失败案例)中进行学习。正如我们将展示的,利用这些数据进行训练可以产生一个具有更强鲁棒性和灵巧性的模型,并使模型能够更广泛地泛化。VLA πθ\pi_\thetaπθ 的训练目标对应于由下式给出的近似对数似然:
maxθEDlogπθ(at:t+H∣ot−T:t,Ct).(1) \max_\theta \mathbb{E}_\mathcal{D} \\log \\pi_\\theta(\\mathbf{a}_{t:t+H} \\mid \\mathbf{o}_{t-T:t}, \\mathcal{C}_t). \quad (1) θmaxEDlogπθ(at:t+H∣ot−T:t,Ct).(1)
需要注意的是,流匹配(flow matching)动作专家优化的是一个近似下界,而不是封闭形式的对数似然 10。数据集 D\mathcal{D}D 通常由高质量的人类演示轨迹组成;然而,如前所述,我们使用了更广泛的数据集,其中包括失败的片段和次优的自主 rollout,以及诸如以自我为中心的人类视频数据等其他数据源。我们将展示如何使用足够详细和信息丰富的上下文 Ct\mathcal{C}_tCt 来整合这些多样化的数据,并且------也许令人惊讶的是------这甚至能带来更好的策略性能和泛化能力。
IV. π0.7\pi_{0.7}π0.7 概述
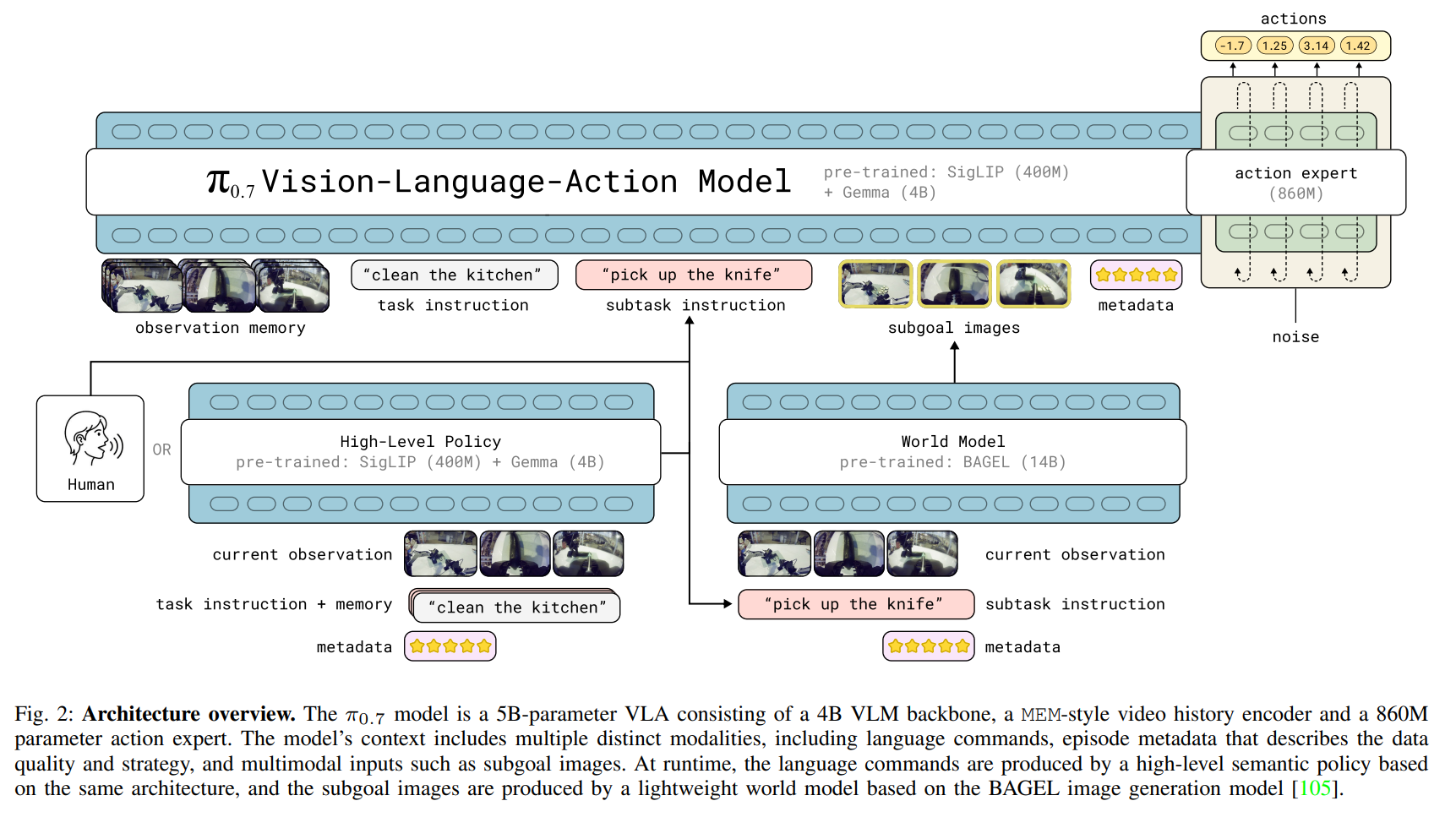
π0.7\pi_{0.7}π0.7 是我们最新的机器人基础模型,它建立在 π0.6\pi_{0.6}π0.6 42 现有的 VLA 架构和 MEM 记忆系统 37 之上,并扩展了多模态上下文条件调节功能。该模型包含一个 VLM 骨干网络,其参数初始化自 Gemma3 40 亿参数 VLM 106(包括一个 4 亿参数的视觉编码器),以及一个具有 8.6 亿参数的流匹配(flow matching)动作专家模块。该模型总共约有 50 亿个参数。视觉编码器同样从 Gemma3 初始化,并遵循 MEM 视频历史编码器 37 的设计,对历史观测值同时应用时间维度和空间维度的压缩,并为任意数量的历史帧输出固定数量的 token。模型架构的概述见图 2,第 VI-B 节更详细地描述了该架构。
我们之前的模型,π0\pi_0π0、π0.5\pi_{0.5}π0.5 和 π0.6\pi_{0.6}π0.6,使用简短的任务文本描述作为上下文。在训练 π0.7\pi_{0.7}π0.7 时,我们扩展了上下文以包含额外的信息和模态:更具表现力的语言指令、episode元数据(episode metadata)以及子目标图像,从而使得在多样化且可能次优的数据上进行训练成为可能。
V. 提示词的多样化
在本节中,我们描述 π0.7\pi_{0.7}π0.7 所使用的上下文 CtC_tCt 中包含的提示词的每个部分。模型经过训练以处理包含这些组件中每一个的提示词,尽管在训练过程中每个组件都会被随机丢弃,以便它也能处理任何子集,从而在测试时提供灵活性。
A. 子任务指令
继 π0.5\pi_{0.5}π0.5 14 之后,除了整体文本任务描述 ℓt\ell_tℓt(例如,"打扫厨房")之外,我们在提示词中包含了捕捉 下一个语义子任务 的中间高层文本。我们将此中间文本表示为 ℓ^t\hat{\ell}_tℓ^t(例如,"打开冰箱门")。在推理过程中,ℓ^t\hat{\ell}_tℓ^t 可能由学习到的顶层策略或人类生成(或被省略)并且可能会随时间而变化。我们从多样化的任务和场景中收集数据,然后用详细的文本描述对这些片段进行标注。
将模型以语义子任务为条件,还使我们能够 逐步用语言指导 模型。由于该模型经过训练能够遵循多样化的语言指令,它可以在新任务中遵循人类的实时指令,例如,将红薯放入空气炸锅(图 14)。在指导之后,我们可以利用这些语言指导数据对 π0.7\pi_{0.7}π0.7 进行微调,使其作为一个高层策略,将机器人观测值、任务规格说明以及过去的子任务指令历史映射到新的子任务指令(图 2 左下)。随后,这一高层策略引导机器人完全自主地执行任务。
B. 子目标图像
虽然子任务指令能有效传达任务的高层意图,但它们可能缺乏对执行至关重要的细节------例如,"打开冰箱门"并未指定机械臂应如何抓取把手。子目标图像通过用图像描绘场景期望的近期未来状态来解决这一问题,从而更丰富地规定了任务取得成功后世界应该是什么样子。
我们考虑多视角子目标 gt=Gt1,...,Gtn\mathbf{g}_t = G_t\^1, \\ldots, G_t\^ngt=Gt1,...,Gtn,其中 GtiG_t^iGti 是相机 iii 期望的近期未来图像。多视角子目标同时指定了以环境和物体为中心的结果(通常在底座视角中最容易观察)以及机械臂/夹爪的结果(通常在手腕视角中最容易观察),从而改善了控制的空间定位。
在运行时,子目标图像由一个轻量级世界模型 生成,它接收与主模型相同的子任务指令 ℓ^t\hat{\ell}tℓ^t,但得益于在网络规模视频和图像编辑任务上的预训练,能够泛化到多样化的任务和场景。生成的以机器人当前观测为基础的子目标图像,通常比语言指令能更清晰地消除策略目标的歧义,从而在语言跟随和泛化方面带来提升。我们将该模型表示为 gψg\psigψ,其训练目标为:
maxψEDgLCFM(gt⋆,gψ(ot,ℓ\^t,m)), \max_\psi \mathbb{E}_{D_g} \left \\mathcal{L}_{\\text{CFM}} \\left( \\mathbf{g}_t\^\\star, g_\\psi(\\mathbf{o}_t, \\hat{\\ell}_t, m) \\right) \\right, ψmaxEDgLCFM(gt⋆,gψ(ot,ℓ\^t,m)),
其中 LCFM\mathcal{L}_{\text{CFM}}LCFM 是标准的流匹配(flow matching)损失 102,gt⋆\mathbf{g}_t^\stargt⋆ 是未来的子目标图像,mmm 是来自第 V-C 节的episode元数据(episode metadata),数据集 DgD_gDg 是来自第 V-A 节的一个子集,其中的片段被标注了特别高质量的子任务标签 ℓ^t\hat{\ell}tℓ^t。片段末尾的图像帧作为真实子目标,即 gt⋆=otend\mathbf{g}t^\star = \mathbf{o}{t{\text{end}}}gt⋆=otend。
遵循 SuSIE 93,我们的世界模型使用现成的、经过网络规模预训练的图像生成和编辑模型进行初始化。我们从 BAGEL 105 进行初始化,这是一个 140 亿参数的混合Transformer模型,具备图像理解、编辑和生成能力。通过使用网络数据、非机器人数据源(如第一人称人类视频)和其他视频数据来增强我们的世界模型训练,我们可以从这些数据源中获取语义和物理概念,然后通过子目标图像将它们迁移到 π0.7\pi_{0.7}π0.7 中。实现细节见附录 C。
C. episode 元数据
扩展提供给模型上下文的一个关键目标是能够在更广泛、更多样化的轨迹数据集上进行训练。π0.7\pi_{0.7}π0.7 不仅使用高质量的演示数据,还利用低质量的演示(包括失败的演示)甚至来自先前模型的自主数据。由于我们仍然希望 π0.7\pi_{0.7}π0.7 在测试时能尽可能好地执行任务,我们需要用关于任务如何 执行的信息适当地标记这些多样化的轨迹,以便模型能够正确地对其进行上下文化处理。为此,我们在上下文中添加了各种具有给定训练episode属性的"episode元数据"信息。我们将这组元数据表示为 mmm,它可能包含各种标签,包括:
- 整体速度:episode的时间步长度。我们将数值以 500 步为间隔进行离散化,例如,1750 到 2250 之间的值被归入"2000 步"。通常,更快的速度也对应着更高的质量,例如,该episode中的错误较少。
- 整体质量:任务执行质量,表示为 1 到 5 之间的分数,其中 5 表示最高质量。
- 错误:指示机器人是否在给定的动作片段中犯错的标签(例如,未能抓取物体或执行了错误的子任务)。这些标签由人类对我们的数据进行粗略标注提供。
因此,π0.7\pi_{0.7}π0.7 模型使用来自多样化数据混合的真实episode速度以及关于episode质量和错误片段的人工标注进行训练。数据多样性(例如,不同速度的片段)为模型提供了必要的信号,使其能够学习将此类元数据与目标动作关联起来。在运行时,通过元数据提示,可以指示模型高速、高质量且无误地执行任务。
D. 控制模式
我们还考虑在底层动作执行中使用不同的控制模式。具体而言,我们在训练过程中同时包含关节级(joint-level)和末端执行器(end-effector)动作,并使用文本标识符 c∈{joint,ee}c \in \{\texttt{joint}, \texttt{ee}\}c∈{joint,ee} 在提示词中指定控制模式。这样在运行时,我们可以根据任务选择控制模式。
E. 完整提示词及训练细节
text
<Multi-view observation><Multi-view subgoals>
Task: peel vegetables. Subtask: pick up the peeler. Speed: 8000. Quality: 5. Mistake: false. Control Mode: joint.<Proprioception>将所有上下文信息结合在一起,上面的示例说明了可能提供给模型的一个潜在提示词。
在训练过程中,我们随机丢弃(dropout)提示词的每个部分,这为 π0.7\pi_{0.7}π0.7 提供了在测试时使用提示词组件的任意子集的灵活性(例如,带或不带子目标图像运行)。首先,我们发现当给定子目标图像时,模型的训练速度显著加快------动作预测任务本质上变成了一个"逆动力学"问题,即推断当前帧和未来帧之间的机器人动作。因此,在训练中,我们仅在每批 25% 的样本中添加视觉子目标图像。在带有子目标图像的样本中,我们也以 30% 的概率丢弃子任务指令 ℓ^t\hat{\ell}_tℓ^t,因为视觉子目标通常可以用更丰富的细节替代等效的文本子任务描述。对于episode元数据,我们以 15% 的概率完全丢弃它,此外每个组件(整体速度、整体质量和错误标签)也分别以 5% 的概率被丢弃。我们不对控制模式应用丢弃。
VI. π0.7\pi_{0.7}π0.7 模型和训练方案
我们现在来讨论如何通过在多样化数据上训练,将不同的上下文融入 π0.7\pi_{0.7}π0.7 模型,以及模型架构、训练和推理的具体细节。
A. 训练数据集
π0.7\pi_{0.7}π0.7 的训练数据集包含了各种任务的演示数据,这些任务使用了许多不同的机器人平台(包括固定式和移动式、单臂或双臂机器人)并且在多样化环境中进行(实验室环境和家庭环境,以及真实家庭环境),还有大量策略评估产生的自主数据、策略执行中人类干预的数据、开源机器人数据集、以自我视角拍摄的人类视频数据,以及来自网络的辅助非机器人数据,包括物体定位与属性预测、视觉问答和纯文本数据预测。我们还包括视频语言任务,包括对内部机器人数据和网络数据的视频字幕。
在训练方案上,我们与经典的视频语言模型训练方法有显著不同:我们在训练中大量使用次优的机器人数据。这包括低质量的示范(失败的实验或有大量错误的成功实验)以及在模型评估实验中由先前版本模型收集的数据。例如,我们使用 π0.6∗\pi^*{0.6}π0.6∗ 模型在强化学习训练中收集的数据作为额外样本,实际上允许 π0.7\pi{0.7}π0.7模型从中提取行为模式。将实验元数据纳入上下文,使我们的模型能够有效利用所有这些评估数据,正如我们在第 IX-A 节中将看到的,这使它能够达到与针对单个任务使用强化学习进行高性能训练的模型相似的表现。这相当于一种"蒸馏"过程,使通用的 π0.7\pi_{0.7}π0.7 模型能够继承强化学习训练专家的能力。次优数据还可以丰富给定任务中的可能状态和场景,并提高鲁棒性,使模型在某些情况下甚至能够在高精巧任务中超越强化学习训练或通常的单任务后训练策略。
B. 模型架构
π0.7\pi_{0.7}π0.7 模型与之前的 π0.5\pi_{0.5}π0.5 和 π0.6\pi_{0.6}π0.6 模型相比,主要的架构修改包括使用 MEM 37 的历史视觉编码器以及上下文中的视觉子目标图像。模型输入最多四个摄像头图像(前视图、两个手腕视图,可选的后视图),每个图像最多包含六帧历史画面,以及最多三个子目标图像(不包括后视图)。历史帧通过视觉编码器处理,并压缩为与单帧相同数量的 token;子目标图像也通过同一个编码器处理。摄像头观测图像和子目标图像首先都被调整为 448x448 像素。在采样历史帧时,我们使用 1 秒的步长,整个历史帧有 0.3 的概率被完全丢弃。后视图图像(如果有)也有 0.3 的概率被丢弃。
我们采用块因果掩码( block-causal masking)方案,使得观察 token 和子目标图像 token 在内部使用双向注意力,而目标图像 token 还可以额外关注观察信息。后续的文本 token 使用因果注意力(具体请参见附录的注意力掩码可视化)。我们还将机器人的本体状态 qtq_tqt(包括历史状态)传入模型骨干。与使用离散化文本 token 来表示 qtq_tqt 的 π0.6\pi_{0.6}π0.6 不同,π0.7\pi_{0.7}π0.7 遵循 MEM,通过线性投影将状态维度映射到骨干维度来嵌入状态。每个历史状态都被视为单独的 token;如果历史帧被丢弃,对应的状态 token 也会被屏蔽。
更轻量的"动作专家"是一个拥有8.6亿参数的变换器,它通过流匹配目标训练来预测连续动作。我们使用自适应RMSNorm来注入时间步信息用于流匹配。动作专家处理的动作标记数量固定为50,代表一个50步的动作块。这50个标记彼此双向注意,也可以注意VLM骨干网络的激活。π0.7还在训练时使用实时动作分块(RTC)107, 108方法,以在推理延迟情况下生成平滑的动作轨迹。训练时,我们模拟0到12个时间步的延迟,对应50Hz机器人上最大240ms的推理延迟。
C. 使用子目标图像进行训练
当训练 π0.7 以处理子目标图像时,我们需要模型能够适应不同延迟和不同图像质量水平的目标,包括我们世界模型生成的图像。这就要求在训练时仔细选择提供给模型的子目标作为上下文。我们在训练轨迹的未来时间步的真实图像和生成图像的组合上进行训练。我们发现以下采样方案在选择真实图像的时间步时比较有效:以0.25的概率,我们采样片段结束的图像(与世界模型的预测目标一致);以0.75的概率,我们从当前时间步起的0--4秒内均匀采样未来图像。除了这些真实图像之外,我们还通过从世界模型中采样大量子目标图像来缓解真实图像和生成图像之间的训练-测试不匹配,并构建额外的训练示例,将这些生成的图像加入 π0.7 的上下文中,而不是使用真实未来图像。
VII. 运行时提示 π0.7\pi_{0.7}π0.7
在运行时,我们配置 π0.7\pi_{0.7}π0.7 以根据不同的上下文形式运行,从而实现所需的行为,而无需任何特定任务的后训练。对于任何任务,我们总是使用控制模式和episode元数据来提示模型。对于选择episode元数据,我们遵循以下规则:
- 整体速度:按任务设置,取该任务episode长度的第 15 个百分位数。
- 整体质量:始终设置为 5,即最高分。
- 错误:始终设置为 false,表示没有错误。
子任务指令 ℓ^t\hat{\ell}_tℓ^t 由学习到的高层语言策略 提供,或者由人类监督员 提供以进行指导(见第 V-A 节)。当使用子目标图像时,只要语义意图发生变化(即新的 ℓ^t\hat{\ell}_tℓ^t),或者自生成上一个子目标图像以来经过了 Δ=4\Delta = 4Δ=4 秒(以先发生者为准),我们就会刷新子目标图像。完整工作流程见算法 1。我们应用异步推理:视觉子目标和子任务指令的生成在单独的线程中进行,而 VLA 推理总是使用最新的可用结果。
对于所有实验,我们使用 5 个去噪步骤来生成 50 步的动作块(action chunks),并执行块中的 H^∈{15,25}\hat{H} \in \{15, 25\}H^∈{15,25} 步。由于每个提示组件都是在使用 dropout 的情况下训练的,π0.7\pi_{0.7}π0.7 也可以针对提示词(prompt)的任何部分使用无分类器引导(Classifier-Free Guidance, CFG)109,例如引导生成的动作趋向更高的速度。具体而言,每个动作去噪步骤遵循:
∇alogπθ(at:t+H∣ot,Ct)+β(∇alogπθ(at:t+H∣ot,Ct)−∇alogπθ(at:t+H∣ot,Ctuncond)) \nabla_{\mathbf{a}} \log \pi_\theta(\mathbf{a}{t:t+H} | \mathbf{o}t, \mathcal{C}t) + \beta (\nabla{\mathbf{a}} \log \pi\theta(\mathbf{a}{t:t+H} | \mathbf{o}t, \mathcal{C}t) - \nabla{\mathbf{a}} \log \pi\theta(\mathbf{a}_{t:t+H} | \mathbf{o}_t, \mathcal{C}_t^{\text{uncond}})) ∇alogπθ(at:t+H∣ot,Ct)+β(∇alogπθ(at:t+H∣ot,Ct)−∇alogπθ(at:t+H∣ot,Ctuncond))
其中 Ctuncond\mathcal{C}_t^{\text{uncond}}Ctuncond 表示在"无条件"模式下使用的上下文集合,β\betaβ 是 CFG 权重。虽然上下文的任何部分都可以被丢弃,但我们在episode元数据上应用 CFG,以激发灵巧任务中的强大性能。我们使用中等大小的 β∈{1.3,1.7,2.2}\beta \in \{1.3, 1.7, 2.2\}β∈{1.3,1.7,2.2}。
VIII. 机器人系统详情
我们将 π0.7\pi_{0.7}π0.7 部署在多种机器人平台上(图 4),包括带有两个 6 自由度机械臂的双臂移动操作机器人、带有轻量级 6 自由度机械臂的静态双臂操作机器人("BiPi"),以及带有 Robotiq 夹爪的双臂 UR5e 系统,我们将其用于跨形态(cross-embodiment)实验。额外的泛化和语言跟随实验使用单臂 6 自由度系统,该系统使用与 BiPi 平台相同的机械臂。
请注意,虽然我们的大部分数据是使用类似于 BiPi 平台的机械臂收集的,但我们用于cross-embodiment测试的 UR5e 机械臂明显更长,具有不同的形态,并且重得多。实际上,由于机械臂的形状、它们在桌子上方的定位方式(在两侧而不是在一侧边缘)以及夹爪和手指的形状,UR5e 机械臂需要采用不同的操作策略,这使得向该平台的跨形态迁移成为一个重大挑战。
所有操作机器人都使用平行夹爪。UR5e 机器人的运行频率为 20 Hz,而其他所有机器人的运行频率均为 50 Hz。每个机器人都有一个前置摄像头以及每个机械臂上的腕部摄像头,移动机器人还有一个后置摄像头。π0.7\pi_{0.7}π0.7 模型的动作输出通过简单的 PD 控制器应用于每个机器人。为了控制末端执行器的运动,我们应用数值逆运动学将目标末端执行器位姿转换为目标关节位置。
