本篇开始进入第四篇章:HMM 核心机制。
前面几篇已经讲完设备内存成为 MM 一等公民所需要的基础设施:
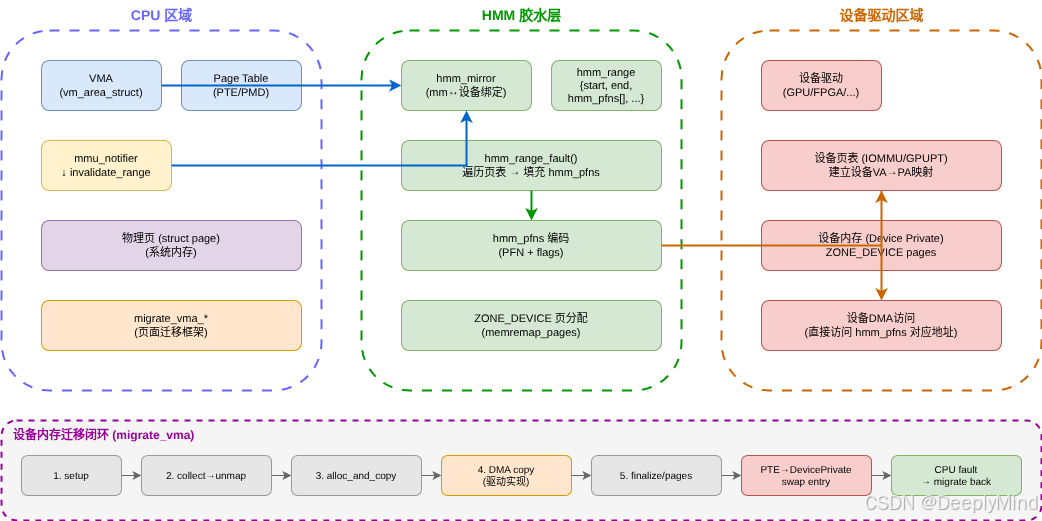
ZONE_DEVICE、dev_pagemap、device private entry 和migrate_vma。从这一篇开始,我们把视角切到 HMM 本体:它如何帮助设备驱动镜像 CPU 地址空间、读取页表、获得 PFN/权限,并在 MMU notifier 的并发协议下更新设备页表。
如果把前面的内容比作铺路,HMM 就是跑在这条路上的"胶水层"。它负责:
- 让设备驱动能安全读取某个进程的 CPU 页表;
- 把虚拟地址范围转换成设备可消费的 PFN/权限数组;
- 在需要时触发远程缺页,让缺页路径复用普通 MM 机制;
- 借助
mmu_interval_notifier防止设备页表使用过期 CPU 映射; - 和
ZONE_DEVICE、dev_pagemap、migrate_vma拼成设备内存迁移闭环。
这一篇重点是建立全景图:HMM 的问题边界是什么,核心数据结构是什么,API 该怎么串起来,和前面几篇讲过的机制分别是什么关系。
本篇按以下主线组织:
- 问题背景:传统设备内存模型的痛点,HMM 要解决什么问题
- 设计定位:HMM 的两大能力支柱与架构位置
- hmm_range:一次页表镜像的完整描述------结构体、PFN 编码、fault 策略、使用模式
- hmm_range_fault() 内部实现:pagewalk 骨架与 present PTE 的正常路径
- 非驻留状态的处理:hole、device private entry、swap/migration/exclusive
- 协作关系:HMM 与 mmu_interval_notifier、ZONE_DEVICE、migrate_vma、DMA helper 的配合
- 实践参考与边界:test_hmm 样例、错误处理、HMM 不做什么
1. 问题背景
在深入 HMM 机制之前,我们先理解它要解决的根本问题:为什么传统的设备内存模型不够用?
1.1 传统模型的痛点
历史上,GPU 这类设备通常有自己的内存分配 API。程序要把数据交给 GPU,就要申请一块设备侧 buffer,再把普通 malloc()、匿名页、文件页里的数据显式拷贝过去。这样会形成两个割裂的地址空间:
text
CPU address space: malloc / mmap / file mapping
GPU address space: driver buffer / VRAM object / GPU VA对数组、图像这类扁平数据,显式拷贝还能忍。但对链表、树、图、C++ 对象、语言运行时结构,复制就非常痛苦:指针关系要重建,库 API 要重复设计,调试时还要同时理解 CPU 副本和设备副本。
1.2 HMM 的目标:共享进程地址空间
HMM 的目标是让设备更接近"共享进程地址空间"的模型:CPU 上有效的用户指针,设备也可以用同一个虚拟地址去访问。设备驱动需要把 CPU 页表的一段映射镜像到设备页表里,并且在 CPU 页表变化时及时失效自己的镜像。
这不是单靠一个分配器能解决的。它需要 MM 的页表遍历、缺页、notifier、设备内存 struct page、迁移等机制共同配合。
理解了这个背景,我们就能更好地把握 HMM 的设计定位。
2. 设计定位
HMM 既不是一个独立的内存分配器,也不是一个完整的设备驱动框架。它的定位是一个交汇点------连接 CPU 内存管理和设备页表管理的桥梁。本部分从能力分类和架构位置两个角度来理解这一定位。
2.1 HMM 的两大能力支柱
官方文档把 HMM 的能力分成两类,理解这点对于把握 HMM 的设计边界很重要。
第一类:地址空间镜像
设备驱动想知道某段用户虚拟地址当前对应哪些 PFN、是否可写、是否需要 fault。HMM 提供 hmm_range_fault(),它在 mmap_lock 下遍历 CPU 页表,把结果填进 hmm_range->hmm_pfns[]。驱动随后把这些 PFN 转成设备页表项或 DMA 地址。
第二类:设备内存纳入 core MM
设备私有内存通过 ZONE_DEVICE 拥有 struct page,通过 dev_pagemap 挂接驱动回调,通过 device private entry 表达 CPU 不可直接访问,通过 migrate_vma 在 CPU 内存和设备内存之间迁移。
两类能力的互补关系
这两类能力不是互相替代,而是互补:
- 地址空间镜像解决"设备如何访问进程已有内存";
- 设备内存迁移解决"热数据如何搬到设备本地内存里"。
HMM 本体最直接的 API 是 hmm_range_fault();迁移主干是上一章讲的 migrate_vma_*()。两者共同服务于 SVM,也就是 Shared Virtual Memory。
2.2 整体架构:HMM 站在谁和谁之间
理解了能力分类后,我们把 HMM 放到更大的架构图中,看它如何连接各个子系统。
a. 页表镜像路径
可以把 HMM 放在这张关系图中:
text
用户进程 VA
-> CPU page table
-> hmm_range_fault()
-> hmm_pfns[]: PFN + 权限 + 错误/特殊标志
-> driver device page table / DMA mapping
-> device 访问同一份数据b. 失效通知路径
同时,还有一条失效路径:
text
CPU 页表变化 / unmap / migration / permission change
-> mmu_interval_notifier invalidate
-> driver 清理设备页表镜像
-> 正在构建页表的线程通过 read_retry 重试c. 设备内存迁移路径
再加上设备内存迁移路径:
text
CPU 页迁到设备内存
-> migrate_vma
-> ZONE_DEVICE page
-> CPU PTE = device private entry
-> CPU fault 时 migrate_to_ramHMM 的交汇点定位
所以 HMM 的位置不是一个独立子系统,而是一个交汇点:它一端读 CPU 页表,一端服务设备页表;一端依赖 MMU notifier 的并发协议,一端依赖 ZONE_DEVICE/migrate_vma 的迁移协议。
理解了 HMM 的设计定位后,下面我们深入它的核心数据结构 hmm_range。
3. hmm_range ------ 一次页表镜像的完整描述
struct hmm_range 是 HMM 的核心对象:它把"一段用户虚拟地址的页表镜像请求"封装成一个结构体。本部分围绕这个对象展开------先看它在头文件里的样子,再拆解结构体字段、输出编码、fault 策略,最后给出驱动使用它的标准模式。读完本部分,你应该能完整回答"如何描述并发起一次页表镜像请求"。
3.1 include/linux/hmm.h:HMM 的公开接口
HMM 的主要公开接口在 include/linux/hmm.h。这个头文件很短,但信息密度很高(后面会细说,这里可以先有个印象):
c
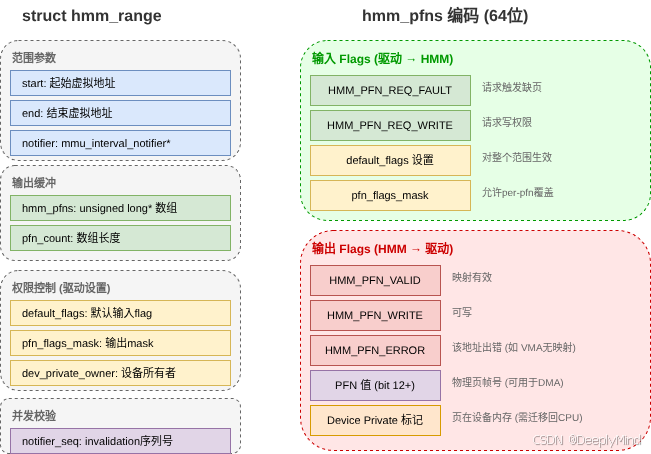
struct hmm_range {
struct mmu_interval_notifier *notifier;
unsigned long notifier_seq;
unsigned long start;
unsigned long end;
unsigned long *hmm_pfns;
unsigned long default_flags;
unsigned long pfn_flags_mask;
void *dev_private_owner;
};
int hmm_range_fault(struct hmm_range *range);围绕它还有一组 PFN 编码 helper:
c
static inline struct page *hmm_pfn_to_page(unsigned long hmm_pfn);
static inline phys_addr_t hmm_pfn_to_phys(unsigned long hmm_pfn);
static inline unsigned int hmm_pfn_to_map_order(unsigned long hmm_pfn);这就是本篇要抓住的主轴:驱动填一个 hmm_range,调用 hmm_range_fault(),然后消费 hmm_pfns[]。下面我们逐一解析这些组件。
3.2 struct hmm_range:一次页表镜像请求
struct hmm_range 表示"一段用户虚拟地址的页表快照/缺页请求"。字段可以分成四组,每组承担不同职责:
第一组:地址范围
start:虚拟地址起点,包含;end:虚拟地址终点,不包含;hmm_pfns:输出数组,每个页一个unsigned long。
第二组:notifier 并发协议
notifier:驱动注册的mmu_interval_notifier;notifier_seq:mmu_interval_read_begin()返回的序列号。
第三组:fault 策略
default_flags:整段范围默认要求,如是否要 fault in;pfn_flags_mask:允许每个hmm_pfns[i]携带的单页请求位。
第四组:设备私有页 owner
dev_private_owner:如果页表里遇到 device private entry,并且 owner 匹配,就把设备页 PFN 报告给驱动;否则按 fault/错误路径处理。
这说明 hmm_range 不只是输入 [start, end)。它同时携带了"并发有效性"、"fault 策略"和"设备私有页身份"三类上下文,这种设计让一个结构体承载了完整的请求语义。
3.3 hmm_pfns\[\]:设备驱动真正消费的结果
理解了 hmm_range 的结构后,我们来看它最重要的输出:hmm_pfns[] 数组。这是设备驱动真正消费的页表镜像结果。
HMM 的输出不是 struct page **,而是 unsigned long hmm_pfns[]。每一项由两部分组成:
text
高位 flags | 低位 PFN相关 flags 在 enum hmm_pfn_flags 中:
c
HMM_PFN_VALID
HMM_PFN_WRITE
HMM_PFN_ERROR
HMM_PFN_DMA_MAPPED
HMM_PFN_P2PDMA
HMM_PFN_P2PDMA_BUS
HMM_PFN_REQ_FAULT
HMM_PFN_REQ_WRITE输出语义是:
| 标志 | 输出含义 |
|---|---|
HMM_PFN_VALID |
PFN有效 ,至少可读 |
HMM_PFN_WRITE |
该 PFN 对应映射可写,必须同时有 VALID |
HMM_PFN_ERROR |
这个地址不能给设备访问,如 poison、特殊映射、无 VMA |
HMM_PFN_P2PDMA |
这是 P2P DMA 相关页面 |
HMM_PFN_P2PDMA_BUS |
使用 bus mapped P2P transfer |
HMM_PFN_DMA_MAPPED |
该项已经完成 DMA map,作为 sticky flag 保留 |
输入语义则复用了其中两个高位:
| 标志 | 输入含义 |
|---|---|
HMM_PFN_REQ_FAULT |
这项必须 fault 到 HMM_PFN_VALID,否则 hmm_range_fault() 失败 |
HMM_PFN_REQ_WRITE |
这项必须 fault 到可写,必须和 REQ_FAULT 组合使用 |
这有一点巧妙:同一个数组既是输入请求,也是输出结果。调用前,驱动可以在数组中标记某些页需要写 fault;调用后,HMM 会把对应项改写成当前 CPU 页表状态。
为了避免驱动手动处理 flags,HMM 提供了 helper:
c
page = hmm_pfn_to_page(hmm_pfn);
phys = hmm_pfn_to_phys(hmm_pfn);
order = hmm_pfn_to_map_order(hmm_pfn);其中 map_order 用来表达 CPU 映射粒度。比如 PMD 级 THP 映射时,每个 PFN 项会带相同的 order,驱动可以据此优化设备页表更新。
3.4 default_flags 和 pfn_flags_mask:整段策略与单页策略
有了 hmm_range 结构和 hmm_pfns[] 编码格式的知识,我们来看一个容易初看困惑的设计:fault 策略的双层控制。
hmm_range 里的这两个字段共同决定 hmm_range_fault() 的行为:
如果驱动只想读取当前状态,不希望 HMM 触发缺页,可以让 default_flags = 0,并且不在 hmm_pfns[] 中设置请求位。这样遇到 none 或不可访问映射时,输出可能是 0 或 HMM_PFN_ERROR。
如果驱动希望整段范围至少可读,可以设置:
c
range.default_flags = HMM_PFN_REQ_FAULT;
range.pfn_flags_mask = 0;这样每个页都要求 fault 到 HMM_PFN_VALID。
如果整段要求可读,但只有个别页要求可写,可以这样:
c
range.default_flags = HMM_PFN_REQ_FAULT;
range.pfn_flags_mask = HMM_PFN_REQ_WRITE;
range.hmm_pfns[index] = HMM_PFN_REQ_WRITE;mm/hmm.c 中 hmm_pte_need_fault() 会把单页请求和默认请求合并:
c
pfn_req_flags &= range->pfn_flags_mask;
pfn_req_flags |= range->default_flags;然后判断是否需要读 fault 或写 fault。这个设计避免驱动为整段范围逐项预填相同请求,也允许少数页覆盖默认策略。
至此,我们说清楚了 hmm_range 的结构、输出编码和 fault 策略。最后一步,是看驱动在实际代码里如何把这些字段串成一次调用。
3.5 标准使用模式:begin → fault → retry 循环
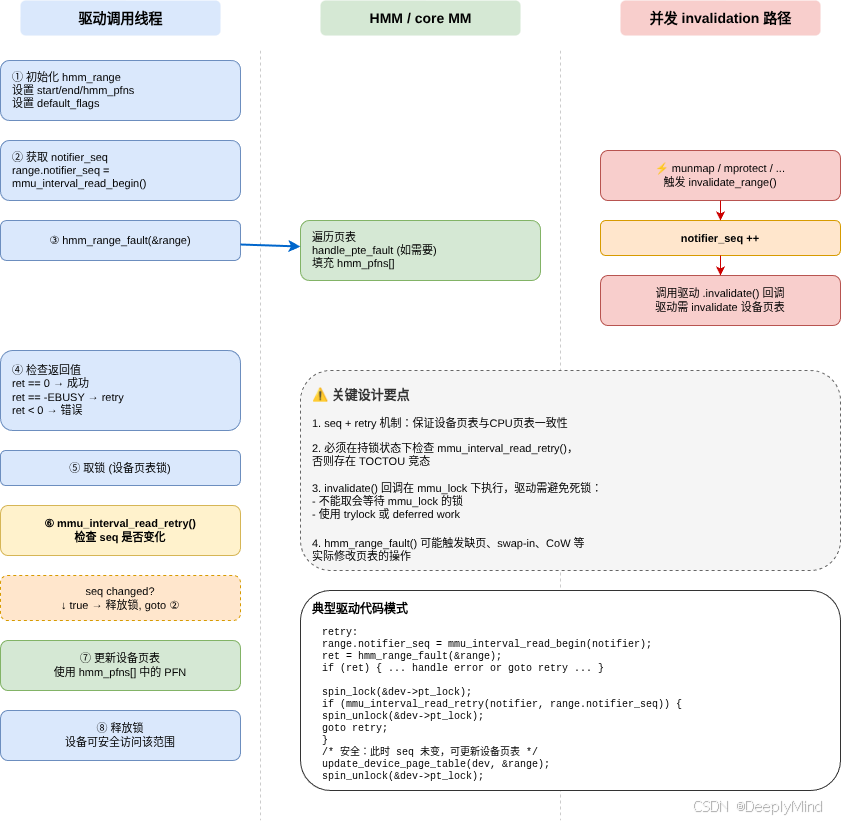
hmm_range_fault() 是 HMM 的核心入口,负责遍历 CPU 页表并填充 hmm_pfns[]。但驱动并不能"调一次就用结果"------CPU 页表随时可能在背后变化。所以官方文档给出的标准模式是一个三段式循环:
c
again:
range.notifier_seq = mmu_interval_read_begin(&interval_sub);
mmap_read_lock(mm);
ret = hmm_range_fault(&range);
mmap_read_unlock(mm);
if (ret == -EBUSY)
goto again;
if (ret)
return ret;
take_lock(driver->update);
if (mmu_interval_read_retry(&interval_sub, range.notifier_seq)) {
release_lock(driver->update);
goto again;
}
/* use range.hmm_pfns[] to update device page table */
release_lock(driver->update);这段代码体现了 HMM 使用模式中最重要的并发约束:hmm_range_fault() 读取 CPU 页表时,CPU 页表可能被另一个线程修改。驱动不能只靠 mmap_lock 得到一个永久有效的设备页表镜像,因为 mmap_lock 释放后 CPU 页表随时可能变化。
所以标准模式分两段:
- 在
mmap_read_lock()下调用hmm_range_fault(),得到一个 PFN 快照; - 拿驱动自己的 update lock,然后调用
mmu_interval_read_retry()确认这段快照在构建设备页表前没有被 invalidate。
如果 retry 失败,就丢弃这次结果,重新 begin → fault → retry。
lib/test_hmm.c 的 dmirror_range_fault() 就是这个模式:
c
range->notifier_seq = mmu_interval_read_begin(range->notifier);
mmap_read_lock(mm);
ret = hmm_range_fault(range);
mmap_read_unlock(mm);
...
mutex_lock(&dmirror->mutex);
if (mmu_interval_read_retry(range->notifier, range->notifier_seq)) {
mutex_unlock(&dmirror->mutex);
continue;
}这也是 mmu_interval_notifier 的落点:HMM 并不是单独"读一次页表就完事",它必须和 interval notifier 的序列号协议搭配。
至此,我们完整描述了"如何发起一次页表镜像请求"。接下来,我们掀开 hmm_range_fault() 的盖子,看它内部如何遍历页表。
4. hmm_range_fault() 内部实现
理解了外部使用模式后,我们来看 hmm_range_fault() 内部做了什么。本部分聚焦"正常路径":先看实现骨架如何复用 pagewalk 框架,再看最常见的 present PTE 如何被转换成 hmm_pfns[]。
4.1 内部实现骨架
hmm_range_fault() 要求调用者已经持有 mmap_lock:
c
mmap_assert_locked(mm);然后循环检查 interval notifier:
c
if (mmu_interval_check_retry(range->notifier, range->notifier_seq))
return -EBUSY;
ret = walk_page_range(mm, hmm_vma_walk.last, range->end,
&hmm_walk_ops, &hmm_vma_walk);它复用了第 1.6 篇讲过的 pagewalk 框架:
c
static const struct mm_walk_ops hmm_walk_ops = {
.pud_entry = hmm_vma_walk_pud,
.pmd_entry = hmm_vma_walk_pmd,
.pte_hole = hmm_vma_walk_hole,
.hugetlb_entry = hmm_vma_walk_hugetlb_entry,
.test_walk = hmm_vma_walk_test,
.walk_lock = PGWALK_RDLOCK,
};每个回调的任务都是:读取 CPU 页表状态,结合 default_flags/pfn_flags_mask/hmm_pfns[i] 的请求策略,最后填充 hmm_pfns[]。
遇到缺页或权限不足时,如果请求要求 fault,HMM 会调用:
c
handle_mm_fault(vma, addr, FAULT_FLAG_REMOTE | maybe_WRITE, NULL)也就是说,设备驱动不是自己手写缺页逻辑,而是让 HMM 以"远程访问"的身份复用普通 MM fault 路径。
接下来,我们先看最常见的正常路径------present PTE。
4.2 present PTE:最简单的 PFN 提取
最简单的情况是 PTE present。hmm_vma_handle_pte() 先转换权限:
c
static inline unsigned long pte_to_hmm_pfn_flags(struct hmm_range *range,
pte_t pte)
{
if (pte_none(pte) || !pte_present(pte) || pte_protnone(pte))
return 0;
return pte_write(pte) ?
(HMM_PFN_VALID | HMM_PFN_WRITE) : HMM_PFN_VALID;
}如果请求不需要 fault,或者当前权限已经满足请求,就把 PFN 和 flags 写入输出:
c
new_pfn_flags = pte_pfn(pte) | cpu_flags;
*hmm_pfn = (*hmm_pfn & HMM_PFN_INOUT_FLAGS) | new_pfn_flags;这里保留了 HMM_PFN_INOUT_FLAGS,也就是 DMA/P2PDMA 等 sticky flags。这样 HMM 可以在"输入请求 → 输出结果"的转换中保留驱动已经建立的一些 DMA 状态。
5. 非驻留状态的处理
present PTE 只是最简单的一种情况。真实页表里大量 PTE 是"不在内存"的:地址范围根本没建立映射(hole)、页面驻留在设备私有内存(device private entry)、页被换出或正在迁移(swap / migration entry)等。HMM 必须理解所有这些非驻留状态,因为设备页表镜像要和 CPU MM 状态保持一致。本部分把这些状态按"决策树的不同分支"组织起来。这一段也是4.3的重点,本部分只建立分类认识。
5.1 none、hole、特殊 VMA:快照或远程 fault
当页表项不存在时,情况就复杂一些。HMM 会进入 hmm_vma_walk_hole()。它先计算这段范围是否需要 fault:
c
required_fault = hmm_range_need_fault(..., cpu_flags = 0);如果没有 VMA 且请求需要 fault,返回 -EFAULT。如果没有请求 fault,则把对应输出填成 HMM_PFN_ERROR 或 0。
如果有 VMA 且请求要求 fault,则调用 hmm_vma_fault()。这个函数用 FAULT_FLAG_REMOTE 调 handle_mm_fault(),必要时附加 FAULT_FLAG_WRITE。
这条路径对应设备页表构建时常见的情况:GPU 准备访问某段虚拟地址,但 CPU 还没有真正 fault in 这些页。驱动可以通过 HMM_PFN_REQ_FAULT 要求 HMM 先把页建立起来,再返回 PFN。
5.2 device private entry:owner 匹配时直接报告 PFN
上一章讲过,CPU 页表里可能有 device private entry,表示页面驻留在设备私有内存。HMM 对这种 entry 的处理体现了它与设备内存基础设施的紧密配合:
c
if (softleaf_is_device_private(entry) &&
page_pgmap(softleaf_to_page(entry))->owner ==
range->dev_private_owner) {
cpu_flags = HMM_PFN_VALID;
if (softleaf_is_device_private_write(entry))
cpu_flags |= HMM_PFN_WRITE;
new_pfn_flags = softleaf_to_pfn(entry) | cpu_flags;
goto out;
}如果 device private page 属于当前驱动,HMM 不会把它迁回 CPU,而是直接把设备页 PFN 报告给驱动。这非常合理:驱动正在镜像自己的地址空间,如果某页已经在自己的设备内存里,设备当然可以继续用这个 PFN。
如果 owner 不匹配,或者请求要求 fault 到 CPU 可访问状态,则会走 fault/错误路径。这避免了一个驱动误用另一个驱动的 device private page。
5.3 其他非驻留状态:migration entry、swap、exclusive
如果 PTE not-present,但不是当前 owner 的 device private entry,HMM 会按 softleaf 类型分流处理:
- swap entry:如果请求 fault,就触发 fault,把页换入;
- device private entry:如果不是 owner 匹配,且请求 fault,就触发迁回或错误;
- device exclusive entry:如果请求 fault,就撤销 exclusive;
- migration entry :等待 migration entry 完成,返回
-EBUSY让外层重试; - 其他未知或不支持 entry :返回
-EFAULT或输出HMM_PFN_ERROR。
可以看到,这些分支共享同一套决策逻辑:先判断"请求是否要求 fault",再根据 entry 类型决定是触发 fault、等待、还是直接报错。HMM 必须覆盖所有这些非驻留 PTE,因为设备页表镜像必须和 CPU MM 状态保持一致。
至此,我们完成了 hmm_range_fault() 从正常路径到非驻留状态的总览。接下来,我们跳出函数内部,看 HMM 如何与其他子系统协作。
6. 协作关系
HMM 不是一个孤立的子系统,它的价值正是体现在与多个内核子系统的协作上。本部分逐一分析 HMM 与 mmu_interval_notifier、ZONE_DEVICE/dev_pagemap、migrate_vma 以及 DMA helper 的配合关系。
6.1 HMM 与 mmu_interval_notifier
2.4 篇已经讲过 interval notifier。这里再放回 HMM 场景里看。
设备页表镜像有两个并发方向:
- 读侧:驱动调用
hmm_range_fault()读取 CPU 页表,然后更新设备页表; - 写侧:CPU MM 修改页表,比如 unmap、mprotect、migration、reclaim,需要通知设备驱动失效旧映射。
mmu_interval_notifier 负责把这两边串起来。驱动注册一个区间 notifier,invalidate 回调中拿和设备页表更新相同的锁,清理设备页表映射,并调用 mmu_interval_set_seq() 更新序列号。
读侧在真正使用 hmm_pfns[] 前调用 mmu_interval_read_retry()。如果序列号变化,说明刚才读到的 CPU 页表快照已经过期,必须重来。
这就是 HMM 的并发核心:hmm_range_fault() 负责"读页表并输出 PFN",interval notifier 负责"证明这份输出在设备页表更新时仍然有效"。
6.2 HMM 与 ZONE_DEVICE / dev_pagemap
3.2, 3.3 讲的是设备内存如何进入 core MM。现在我们看 HMM 如何消费这些基础设施。
HMM 在读页表时会遇到两类 PFN:
- 普通系统内存 PFN:来自 present PTE;
- 设备私有内存 PFN:来自 device private entry。
后者之所以能被 HMM 当成 PFN 报告,是因为设备内存已经通过 ZONE_DEVICE 拥有 struct page,并且通过 dev_pagemap 带着 owner 和 ops。hmm_vma_handle_pte() 中的 owner 判断正是通过:
c
page_pgmap(softleaf_to_page(entry))->owner这说明 HMM 并不是绕开前面的基础设施,而是在消费它们。
没有 ZONE_DEVICE,device private PFN 没有 struct page,HMM 很难把它和 MM 的 rmap、migration、fault 语义接上。
没有 dev_pagemap->owner,HMM 无法判断这个设备私有页是不是当前驱动能使用的页。
这三层依赖清晰地展示了 HMM 与设备内存基础设施的关系:HMM 是消费者,ZONE_DEVICE 和 dev_pagemap 是提供者。
6.3 HMM 与 migrate_vma
hmm_range_fault() 和 migrate_vma 经常出现在同一个驱动里,但它们回答的问题不同。
hmm_range_fault() 回答:
这段用户虚拟地址现在对应哪些 PFN?权限是什么?是否需要 fault?
migrate_vma 回答:
如何把这些虚拟地址背后的页面安全地从 CPU 内存搬到设备内存,或者从设备内存搬回 CPU 内存?
典型 SVM 驱动会同时用两者:
- GPU page fault 时,用
hmm_range_fault()获取 CPU 页表里的 PFN,然后建立 GPU 页表映射; - GPU 想把热数据迁到 VRAM 时,用
migrate_vma把系统页迁成 device private page; - CPU 访问 device private page 时,由
dev_pagemap->ops->migrate_to_ram()再用migrate_vma迁回; - CPU 页表变化时,mmu interval notifier 让 GPU 页表失效或重建。
这就是 HMM 的完整闭环:镜像、失效、迁移、回迁。四个环节共同支撑了 SVM(Shared Virtual Memory)的实现。
6.4 HMM 与 DMA helper
最后,我们看 HMM 在 DMA 层面的延伸。源码里有 include/linux/hmm-dma.h和 mm/hmm.c 后半部分的 DMA helper:
c
struct hmm_dma_map {
struct dma_iova_state state;
unsigned long *pfn_list;
dma_addr_t *dma_list;
size_t dma_entry_size;
};
int hmm_dma_map_alloc(...);
dma_addr_t hmm_dma_map_pfn(...);
bool hmm_dma_unmap_pfn(...);它们解决的是下一层问题:驱动拿到 PFN 后,如何把 PFN 变成设备可访问的 DMA 地址,并处理 P2PDMA、bus mapped P2P、DMA mapped sticky flag 等状态。
4.4 节会专门讲 HMM 与 DMA。本篇先把它放在全景图里:hmm_range_fault() 产出 PFN,DMA helper 可以把 PFN 转成设备总线地址。这形成了从虚拟地址到设备可访问地址的完整转换链条。
7. 实践参考与边界
理论层面的机制解析之后,本部分提供实践参考:一个最小化的 HMM 使用样例、错误码解读,以及 HMM 的能力边界。
7.1 test_hmm:最小化的 HMM 使用样例
lib/test_hmm.c 是学习 HMM 的最佳参考。它在 open 时为当前进程注册 interval notifier:
c
ret = mmu_interval_notifier_insert(&dmirror->notifier, current->mm,
0, ULONG_MAX & PAGE_MASK, &dmirror_min_ops);invalidate 回调里,如果不是自己发起的迁移通知,就拿 dmirror->mutex,更新 interval notifier 序列号并清理镜像页表:
c
mmu_interval_set_seq(mni, cur_seq);
dmirror_do_update(dmirror, range->start, range->end);需要建立镜像时,调用 dmirror_range_fault(),走 begin → hmm_range_fault() → retry 模式。拿到 hmm_pfns[] 后,dmirror_do_fault() 把 PFN 转成 page,并存入自己的 XArray 模拟设备页表:
c
page = hmm_pfn_to_page(*pfns);
entry = page;
if (*pfns & HMM_PFN_WRITE)
entry = xa_tag_pointer(entry, DPT_XA_TAG_WRITE);
entry = xa_store(&dmirror->pt, pfn, entry, GFP_ATOMIC);这就是一个最小设备页表镜像:没有真实 GPU 页表,但结构和真实驱动类似。对于想要理解 HMM 使用模式的开发者,这是最好的起点。
7.2 错误返回:驱动如何理解 hmm_range_fault()
在实际使用中,正确处理错误码至关重要。hmm_range_fault() 的注释列出了主要错误码:
| 返回值 | 含义 |
|---|---|
0 |
成功,hmm_pfns[] 已填充 |
-EINVAL |
参数无效,或 VMA 不支持 HMM,如 device file VMA |
-ENOMEM |
缺页或页表处理过程中内存不足 |
-EPERM |
请求写权限,但 VMA 不允许写 |
-EBUSY |
range 被 invalidate,需要等待或重试 |
-EFAULT |
请求 valid PFN 但无法建立,比如无 VMA 或非法访问 |
这里的 -EBUSY 很常见。它不一定是错误,更像并发协议中的"请重来"。例如遇到 migration entry 等待完成,或者 interval notifier 检测到范围失效,都会让外层重试。正确的做法是在外层循环中处理 -EBUSY,而非当作致命错误。
7.3 HMM 的能力边界:它不做什么
总览 HMM 时,也要知道它刻意不做什么。明确边界有助于正确使用:
HMM 不替设备定义页表格式
GPU、FPGA、SmartNIC 的页表项格式、权限位、TLB invalidate、命令提交都由驱动自己处理。HMM 只提供 PFN 和权限信息,设备页表的具体实现是驱动的责任。
HMM 不决定迁移策略
哪些页应该迁到 VRAM,什么时候迁回,是否预取,是否按 fault 迁移,这些都是驱动和用户态运行时策略。HMM 提供机制,策略由驱动决定。
HMM 不保证硬件 cache coherence
它提供 PFN、DMA helper、notifier 和迁移机制,但 cache coherency、atomic 能力、P2P 能力仍取决于平台和设备。
HMM 不绕过 Linux MM
相反,它的设计哲学正是复用:pagewalk、page fault、mmu notifier、struct page、migration entry、migrate_vma。这种设计让 HMM 与内核 MM 保持一致,而非另起炉灶。
8. 总结
本篇建立了 HMM 的全景图。让我们回顾主线:
问题背景:传统设备内存模型导致 CPU 和设备地址空间割裂,HMM 的目标是让设备共享进程地址空间。
设计定位:HMM 提供两大能力------地址空间镜像和设备内存纳入 core MM。它不是独立子系统,而是连接 CPU MM 和设备页表的交汇点。
hmm_range ------ 一次镜像请求的完整描述:
struct hmm_range用四组字段描述请求:地址范围、notifier 协议、fault 策略和设备 ownerhmm_pfns[]用 PFN + flags 编码输出每页的状态和权限,同一数组兼作输入请求default_flags与pfn_flags_mask提供整段与单页的双层 fault 策略- 驱动通过 begin → fault → retry 标准循环安全地发起请求
hmm_range_fault() 内部实现:复用 pagewalk 框架遍历 CPU 页表,正常路径下 present PTE 被直接转换成 PFN + 权限。
非驻留状态的处理:hole、device private entry、swap/migration/exclusive 等非驻留 PTE 按统一决策逻辑分流------先判断是否需要 fault,再按 entry 类型触发 fault、等待或报错,确保镜像与 CPU MM 状态一致。
协作关系:
- 与
mmu_interval_notifier配合实现并发安全 - 消费
ZONE_DEVICE和dev_pagemap提供的设备内存基础设施 - 与
migrate_vma共同形成镜像-失效-迁移-回迁的完整闭环 - DMA helper 完成 PFN 到设备总线地址的转换
本篇较长,但值得这么长。如果读到这里你都懂了的话,可以直接去读第五章的实际应用案例了。
一句话总结:
HMM 帮设备驱动安全地观察和镜像 CPU 地址空间,并把观察结果表示成设备可消费的 PFN/权限数组。
下一篇我们就进入 hmm_range_fault() 的逐行解析上半部分:入口流程、pagewalk 回调、present PTE 和大页映射如何被转换成 hmm_pfns[]。