资料来源:黄佳老师 极客空间。
多模态模式处理的是这样一类问题:Agent 接到的输入不再只是纯文本,而是同时包含图片、文字、表格、日志、PDF、截图,甚至音频和视频。工程师要做的是先判断每一种数据最适合以什么形态被模型消化,再把它们带着关联关系合并到推理层。
多模态融合的核心是数据形态设计,多模态融合是数据形态工程,也就是让每种数据找到最适合 Agent 消化的形态。
模型供应商负责让模型能看图、读 PDF、听音频;工程师负责判断这张图、这页 PDF、这段日志、这段音频该用什么形态进入 Agent。架构图可能该转 Mermaid,普通表格该转 Markdown,图表要先抽成 CSV/JSON 再算数,长日志要走预过滤和 Sub-Agent,音频要先 STT,PDF 要拆成 TOC、关键页、表格和关键图。
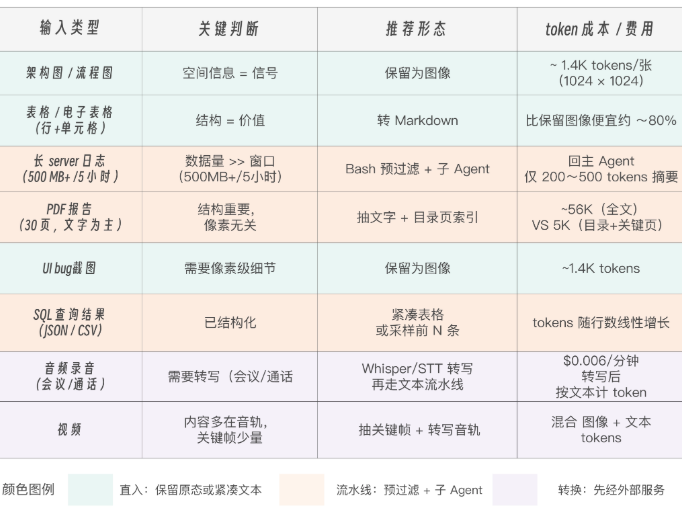
简单来说:空间关系本身是信号,就保留为图;否则,尽量转成紧凑、可检索、易压缩的文本或者清晰的结构(如 Json Schema)。架构图、流程图、UI 设计稿 这类材料,价值往往在空间关系里,应该保留为图。表格、字段截图、错误日志、合同条款这类材料,核心价值在文字和结构里,通常应该转成 markdown、JSON 或结构化文本。不过,真正落到生产里,还需要更细的决策卡,判断每一种输入形态该走哪条处理路径。
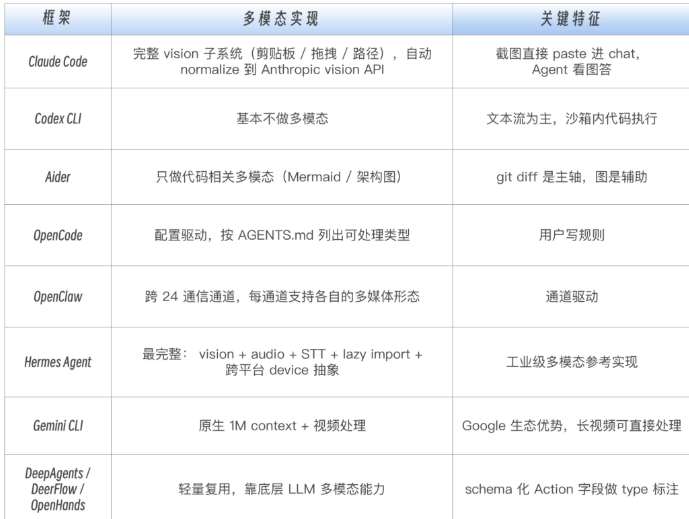
多模态融合不能只是一个 parse_file() 函数。生产里的融合器(fuser)至少要做三件事:
识别输入形态;
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Callable, Optional
from datetime import datetime
class ModalityType(Enum):
TEXT = "text" # 直接进入上下文
IMAGE = "image" # 空间关系是信号,保留为图
TABLE = "table" # 转 markdown
LOG = "log" # bash 预过滤 + sub-agent
PDF = "pdf" # TOC + 关键页 + 抽取文本
AUDIO = "audio" # STT 转文本
SQL_RESULT = "sql_result" # 抽样 / compact table按形态分发到不同处理路径;
每条输入都带一个业务提示。这个 hint 很重要,它告诉系统这份材料的业务含义,比如"市场规模图""auth 服务日志""用户上传截图"。
@dataclass
class ModalityInput:
type: ModalityType
payload: Any
hint: str = ""
keep_as_image: bool = False每次处理的 trace,方便后续排查成本、延迟和质量问题。
1、架构图 / 流程图:能转 Mermaid 就转 Mermaid
架构图看起来天然适合保留成图片,但很多项目里,Mermaid 更好用。一个 8 个节点的架构图,写成 Mermaid 可能只有几十个 token;存成 draw.io XML 可能上千 token;保留成 PNG,又不方便检索、修改和 diff。更重要的是,Mermaid 对模型很友好。服务调用、组件依赖、审批流程、数据流向,这些用 Mermaid 表达,模型通常读得清楚。所以我的建议是系统结构图、流程图、调用链,优先转 Mermaid。只有在 UI 布局、视觉标注、复杂空间位置关系很关键时,再保留为图。
2、表格 / 电子表格:默认转 Markdown
表格的核心价值通常在行、列、字段和数字,不在截图本身。普通业务表、财务表、SQL 查询结果,转成 Markdown 或 CSV 会更便宜,也更容易检索和计算。判断标准是如果 Markdown 能还原 95% 信息,就转 Markdown。保留为图的情况虽然也存在,但比较少,比如跨页表、多层表头、合并单元格、斜线表头、嵌套分组。这类表格硬转 Markdown 会丢结构,才值得走 vision。普通表格别截图,复杂版式表格再留图。
3、图表 / 热力图:保留图,但数字要落到数据
柱状图、折线图、散点图、热力图,很容易让人高估视觉模型的能力。模型看趋势通常还可以,但让它直接读精确数字、算同比、算环比,风险就高了。尤其是坐标轴密、图例多、双 Y 轴、颜色映射复杂的时候,答案可能看起来很顺,数字却错了。所以这类图建议分两步处理:图像保留,用来定位和理解趋势;数字抽出来,转成 CSV 或 JSON 后再计算。比如市场规模趋势图可以保留为图,让 Agent 知道这张图讲什么;但如果要回答"2024 到 2026 CAGR 是多少",就应该让 Agent 基于结构化数据算。让视觉模型帮你看图,结构化数据负责算数。
4、密集文字截图:有时直接当图更划算
如果是一整页密密麻麻的代码、报告截图、日志截图、表格截图,全部 OCR 成文本可能很长,还会带来格式噪声。此时把图片压到合适尺寸,直接交给 vision,有时更省 token,也更快。适合这种处理的场景包括长代码截图、整页报告截图、密集 UI 截图、以及带大量文字的监控页面。不过如果只是快速理解页面内容,保留为图也可以;如果后续要搜索、diff、计算、引用字段,还是要转成文本或结构化数据。
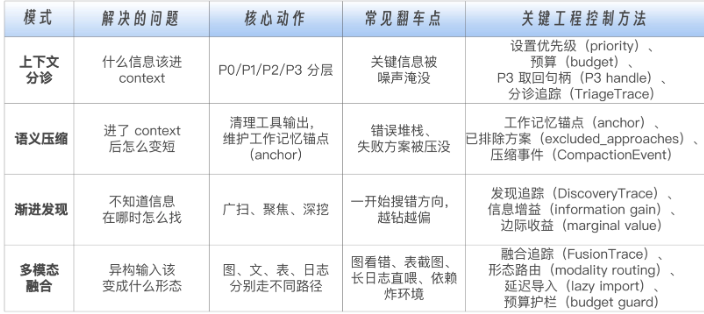
这四个模式的顺序也很重要。多模态融合最靠前,先决定数据形态;上下文分诊再决定哪些信息靠近模型;语义压缩负责长会话里的工作记忆;渐进发现负责未知空间里的探索。如果形态一开始就错了,后面如何分诊、压缩、探索,都是在错误材料上继续消耗。