很多人讲 AI Agent,容易把重点放在模型推理、Prompt、ReAct、Tool Calling 上。但从 OpenAI 官方 openai/codex 的开源实现看,Codex 更值得关注的地方不是"模型会不会调用工具",而是它把 Agent 做成了一套相对完整的运行时系统。
Codex 源码给我的最大启发是:
生产级 Agent 的核心不是假设模型永远可靠,而是承认模型只是一个不稳定的决策组件,然后用运行时系统把状态、工具、安全、上下文和协议管理起来。
换句话说,模型决定 Agent 的能力上限,Runtime 决定 Agent 是否可控、可恢复、可扩展、可审计。
本文基于 OpenAI 官方 openai/codex 仓库源码整理,源码阅读基准为当前仓库的 commit 1b24ba912ac4c56ef936364deb1c3e294b0ef9fa。由于 Codex 仍在快速演进,具体文件名、类型名和协议字段可能随版本变化。
本文不是官方架构说明,也不是逐行源码解析,而是把源码里的关键实现提炼成一套可复用的 Agent Runtime 工程模式。文中的架构图和 Runtime 分层是作者抽象,不一定和源码类型一一对应。
如果这篇文章准备作为上游仓库贡献,需要注意:它更像源码阅读笔记或技术文章,不是 Codex 官方产品文档;更适合发布在博客、技术专栏或仓库外的工程笔记中。
术语和源码锚点
为了避免把"源码事实"和"设计抽象"混在一起,先列出本文主要参考的源码位置。
| 主题 | 关键源码 |
|---|---|
| Turn 运行时 | codex-rs/core/src/session/turn.rs |
| 上下文历史 | codex-rs/core/src/context_manager/history.rs |
| 上下文压缩 | codex-rs/core/src/compact.rs、codex-rs/core/src/compact_remote.rs、codex-rs/core/src/compact_remote_v2.rs |
| 工具路由和注册 | codex-rs/core/src/tools/router.rs、codex-rs/core/src/tools/spec_plan.rs、codex-rs/core/src/tools/registry.rs |
| 工具并发和错误处理 | codex-rs/core/src/tools/parallel.rs |
| Shell 和审批 | codex-rs/core/src/tools/handlers/shell.rs、codex-rs/core/src/tools/runtimes/shell.rs |
| MCP 工具调用 | codex-rs/core/src/mcp_tool_call.rs |
| Hook 运行时 | codex-rs/core/src/hook_runtime.rs |
| 权限和沙盒模型 | codex-rs/protocol/src/permissions.rs |
| App Server 协议 | codex-rs/app-server-protocol/src/protocol/common.rs、codex-rs/app-server-protocol/src/protocol/v2/turn.rs、codex-rs/app-server-protocol/src/protocol/v2/item.rs、codex-rs/app-server-protocol/src/protocol/event_mapping.rs、codex-rs/app-server-protocol/src/protocol/thread_history.rs |
几个核心概念:
| 概念 | 含义 |
|---|---|
| Thread | 一个持久会话,包含多个 Turn |
| Turn | 用户一次输入触发的一轮 Agent 工作,内部可以包含多次模型采样和工具调用 |
| Item | Turn 内的原子事件,例如用户消息、Agent 消息、工具调用、命令执行、文件变更 |
| History | Core 维护的模型上下文历史,不等同于 UI 展示历史 |
| Rollout | 持久化事件记录,用于回放、恢复和审计 |
| Compaction | 将长上下文压缩为 replacement history,使后续模型调用能继续 |
| ToolRouter | 把模型输出的工具调用标准化成内部工具调用 |
| ToolRegistry | 管理工具定义和执行入口 |
| ToolCallRuntime | 执行工具调用,并处理并发、取消和错误转换 |
| HookRuntime | 在生命周期节点运行横切策略,例如工具前后、权限请求、停止前、压缩前后 |
一、Codex 不是一个简单的 Agent Demo,而是 Agent Runtime
最简化的 Agent Demo 通常是这样的:
text
用户输入
↓
调用模型
↓
模型返回工具调用
↓
执行工具
↓
把工具结果喂回模型
↓
直到模型返回最终回答用伪代码表示,大概是:
python
while True:
response = model.generate(messages)
if response.tool_calls:
results = execute_tools(response.tool_calls)
messages.append(results)
else:
return response.text这个结构可以跑通 Demo,但离生产环境很远。
真实的编码 Agent 需要同时处理:
- 运行中的用户追加输入、取消和任务继续;
- 工具调用的失败、超时、并发和副作用;
- 上下文增长、压缩和历史回放;
- 高风险命令、文件修改和网络访问的审批;
- UI 对进度、Diff、命令输出和审批状态的结构化展示;
- 不同入口之间的一致协议和一致状态。
Codex 的工程价值就在于,它没有把 Agent 写成一个简单 while 循环,而是围绕这个循环构建了一套运行时。
下面这张图是对源码结构的概念抽象,不是官方组件拓扑图:
这个架构说明一个关键设计:
Agent 能力应该沉淀在 Core Runtime 中,而不是散落在 CLI、IDE、Web UI 里。
这也是 Codex 能够同时服务多种入口的基础。不同入口不一定都经过 App Server,但它们复用的是同一套 Core 能力和协议模型。
二、普通 Agent Demo 和 Codex Runtime 的差异
| 维度 | 普通 Agent Demo | Codex 式 Agent Runtime |
|---|---|---|
| 执行模型 | 简单 while 循环 | 可继续、可插入输入、可取消的 Turn 运行时 |
| 状态管理 | 一个 messages 数组 |
Thread / Turn / Item / History / Rollout |
| 工具调用 | 直接 if/else 分发 | Router / Registry / Runtime 分层 |
| 工具并发 | 默认串行或默认并行 | 根据工具能力调度 |
| 用户介入 | 一轮完成后再输入 | 执行中可追加输入和约束 |
| 上下文管理 | 不断追加历史 | 稳定上下文布局 + 自动压缩 |
| 安全控制 | Prompt 约束 | Sandbox + Approval + Policy |
| UI 协议 | 返回最终文本 | 流式结构化事件 |
| 扩展方式 | 修改主循环 | Hooks / MCP / Extensions / Dynamic Tools |
| 可观测性 | 日志有限 | 生命周期事件、Diff、工具结果、审批记录 |
这个对照表可以概括 Codex 的核心价值:
Codex 展示的不是"如何写一个 Agent",而是"如何把 Agent 做成软件系统"。
三、Turn:把 Agent Loop 做成可继续的运行时
源码事实
对应源码:codex-rs/core/src/session/turn.rs。
run_turn 是 Codex 的核心 Turn 执行逻辑。它不是一次性调用模型,也不是简单地递归执行工具,而是在一个异步循环中持续处理:
- 当前输入;
- pending input;
- 模型采样;
- 工具调用;
- token 状态;
- auto compact;
- stop hook;
- cancellation;
- error event。
其中一个关键判断可以抽象为:
text
needs_follow_up =
model_needs_follow_up
|| has_pending_input这说明 Codex 是否继续执行,不只取决于模型是否还要调用工具,也取决于用户是否在运行过程中追加了新输入。
设计抽象
Codex 把"一次用户请求"抽象成一个 Turn。一个 Turn 不是简单的 request-response,而是可以包含多个模型调用、多个工具调用、多个中间事件的运行过程。
这带来一个重要能力:steering。
例如:
text
用户:帮我重构这个模块。
Agent:开始阅读代码并准备修改。
用户:不要改公共接口。
Agent:把这条新约束加入后续上下文,继续执行。如果 Agent Loop 是一个不可中断的函数调用,就很难支持这种中途介入。
需要注意的是,turn.rs 本身主要证明的是 Turn 内循环可以继续、取消、追加输入和触发 compaction;真正的断线恢复、历史回放和持久化恢复,还要结合 Thread/App Server 协议以及 rollout/thread store 机制来看。
更准确地说,Codex 的恢复能力主要是:
- 恢复会话视图;
- 回放已经持久化的事件;
- 在合适的位置继续交互;
- 重建客户端可展示的 Thread / Turn / Item 历史。
它不应该被理解成"正在运行的 OS 进程、Shell 命令或外部工具调用可以无损迁移和恢复"。
可迁移原则
生产级 Agent Loop 应该是异步状态机,而不是一次性同步函数。
它至少应该支持:
- 中途追加输入;
- 中途取消;
- 工具失败后继续;
- 上下文压缩后继续;
- 生命周期 Hook;
- 最终状态显式记录。
边界
状态机比简单循环复杂得多。它要求系统明确区分:
- 当前 Turn;
- 历史 Turn;
- 用户新输入;
- 工具返回;
- 模型输出;
- 系统注入上下文;
- Hook 追加上下文;
- UI 展示事件;
- 持久化 rollout 事件。
如果只是做一个内部小工具,不一定需要完整 Turn Runtime。但只要 Agent 要长期运行、支持多客户端或处理真实代码仓库,这种复杂度基本不可避免。
四、Context:上下文不是聊天记录,而是运行时状态
源码事实
对应源码:codex-rs/core/src/context_manager/history.rs、codex-rs/core/src/session/turn.rs。
Codex 在构造模型请求时,会把多类信息组合进上下文:
- 模型基础指令;
- 沙盒和权限说明;
- 用户配置;
- 项目级
AGENTS.md; - Skills / Plugins / MCP 工具相关信息;
- 当前工作目录和环境信息;
- 历史消息;
- 工具调用和工具结果;
- 当前用户输入;
- Hook 或系统追加的上下文。
这说明上下文不只是"聊天历史",而是 Agent Runtime 的一部分。
设计抽象
Codex 倾向于保持上下文布局稳定,并把新的模型输出、工具结果和用户输入追加到后面:
text
稳定上下文布局
+
模型输出
+
工具调用
+
工具结果
+
新的用户输入这种设计的好处是历史结构相对稳定,后续请求更容易保留旧请求作为新请求的前缀。
这对支持 Prompt Cache 的模型服务很重要。稳定前缀越多,越有机会复用前面请求的计算结果,从而降低长任务的采样成本。
可以把它理解成:
text
请求 1:
[A][B][C][D]
请求 2:
[A][B][C][D][E]
请求 3:
[A][B][C][D][E][F]其中 [A][B][C][D] 是相对稳定的前缀。
这不是普通的消息数组排序问题,而是性能设计问题。对长时间运行的 Agent 来说,上下文布局有点像一份运行时契约:它不是业务逻辑,却会直接影响缓存命中率、延迟和成本。
这里的"运行时契约"只是一个设计类比,不是 Codex 的正式术语。实际请求还会受到工具 spec、hook 注入、context injection、模型切换和 compaction 等因素影响,因此不能把 Codex 简化成纯粹的线性 append。
可迁移原则
设计 Agent 上下文时,不要只问"模型需要看到什么",还要问:
- 哪些内容应该稳定放在前面?
- 哪些内容经常变化,应该追加在后面?
- 哪些内容是开发者指令?
- 哪些内容是用户约束?
- 哪些内容是工具观察结果?
- 哪些内容可以压缩?
- 哪些内容必须原样保留用于审计?
边界
追加式上下文会持续增长。如果没有压缩机制,长任务一定会遇到上下文窗口限制。
另外,Prompt Cache 是否有效还取决于模型服务、请求参数、缓存策略和上下文长度,不能简单假设"前缀一样就一定命中"。
五、Compaction:管理长上下文,而不是简单截断
源码事实
对应源码:codex-rs/core/src/session/turn.rs、codex-rs/core/src/compact.rs、codex-rs/core/src/compact_remote.rs、codex-rs/core/src/compact_remote_v2.rs。
在 turn.rs 中,Codex 会在采样前和 Turn 中途检查 token 状态。当 token 达到自动压缩条件且任务仍需继续时,会触发 auto compact。
具体链路可以从这些函数看到:
run_pre_sampling_compactauto_compact_token_statusrun_auto_compactrun_inline_auto_compact_taskrun_inline_remote_auto_compact_task
这个逻辑背后有一个关键判断:
text
如果上下文达到压缩条件,并且 Agent 仍然需要继续,
就先压缩上下文,再继续后续模型调用。设计抽象
最粗暴的上下文管理方式是截断:
text
删除最早的 N 条消息但对编码 Agent 来说,这非常危险。早期消息里可能包含:
- 用户的核心目标;
- 关键约束;
- 已经做过的尝试;
- 修改过的文件;
- 测试失败原因;
- 安全边界;
- 下一步计划。
Codex 的方向是压缩,而不是简单删除。当前实现中,compaction 会生成新的 replacement history,并用它替换后续发送给模型的有效历史;同时,系统会通过 compaction item、rollout event 和 thread history reducer 保留理解"何时发生压缩、压缩后如何继续"的信息。
这里要区分三种历史视角:
| 视角 | 作用 |
|---|---|
| 原始 rollout 事件 | 用于持久化、回放、恢复和审计 |
| Core 有效模型上下文 | 用于控制 token、推理和任务连续性 |
| App Server Thread/Item 视图 | 用于客户端展示、分页、恢复 UI 状态 |
这三者不能混为一谈。有效模型上下文可以被压缩和替换;原始事件和协议视图则承担回放、审计和用户展示职责。
可迁移原则
一个可靠的 compaction 结果不应该只是聊天摘要,而应该保留:
- 当前任务目标;
- 用户明确约束;
- 已完成工作;
- 修改过的文件;
- 关键命令结果;
- 失败尝试;
- 尚未解决的问题;
- 下一步应该继续做什么。
可以把它理解为 Agent 的"中场交接文档"。
边界
Compaction 会带来信息损失。压缩摘要如果漏掉关键约束,后续 Agent 可能做出错误修改。
因此,生产级 Agent 最好保留可回放的事件记录,同时将压缩后的 replacement history 作为后续模型输入。不要把 compaction 摘要当成唯一存档。
六、Tools:工具系统分成 Router、Registry 和 Runtime
源码事实
对应源码:codex-rs/core/src/tools/router.rs、codex-rs/core/src/tools/spec_plan.rs、codex-rs/core/src/tools/registry.rs。
在 tools/router.rs 中,Codex 定义了统一的 ToolCall,包含:
text
tool_name
call_id
payloadToolRouter 持有:
text
registry
model_visible_specsToolRouter 负责把模型返回的不同调用形式转成统一的内部工具调用,再交给 registry 分发。
更准确地说,这里有两个层面。
模型输出侧,build_tool_call 直接标准化的调用形式包括:
- Responses API 的 function call;
- custom tool call;
- client-side tool search call。
工具注册侧,ToolRouterParams 和 spec_plan.rs 会把多种来源的工具接入 registry 和可见 spec,例如:
- MCP 工具;
- extension tool;
- dynamic tool;
- deferred / discoverable tools。
设计抽象
Codex 没有把工具调用写成大量 if tool_name == ... 的分支,而是做了分层。本文把执行这一层抽象称为 Tool Runtime;在源码中对应的核心类型更接近 ToolCallRuntime。
text
模型输出
↓
ToolRouter:标准化工具调用
↓
ToolRegistry:查找工具定义和 Handler
↓
ToolCallRuntime:执行、取消、并发、错误转换工具系统被拆成三个问题:
| 层次 | 解决的问题 |
|---|---|
| Tool Spec | 模型能看到什么工具、参数 Schema 是什么 |
| Tool Router | 模型输出如何转成统一内部调用 |
| Tool Registry | 工具定义和执行入口如何注册 |
| Tool Runtime | 工具如何执行、取消、并发和返回结果 |
可迁移原则
当 Agent 工具数量超过几个以后,就不应该继续用 if/else 分发。
更合理的设计是:
- 工具有统一名称;
- 工具有统一参数 Schema;
- 工具有统一返回格式;
- 工具声明自己的能力;
- 工具错误能被标准化;
- 工具执行和模型循环解耦。
边界
Router / Registry / Runtime 会增加前期抽象成本。对于三五个固定工具的简单 Agent,直接函数调用可能更快。
但一旦接入 MCP、插件、动态工具、权限策略、并发调度,这种分层会显著降低后续复杂度。
七、Parallelism:工具并发由能力声明,而不是默认全并行
源码事实
对应源码:codex-rs/core/src/tools/parallel.rs。
ToolCallRuntime 内部持有一个 RwLock:
text
parallel_execution: Arc<RwLock<()>>执行工具时,Codex 会先判断该工具是否支持并行:
text
supports_parallel = router.tool_supports_parallel(&call)如果支持并行,获取 read lock;否则获取 write lock。
可以抽象为:
text
支持并行的工具:共享锁
不支持并行的工具:独占锁设计抽象
这比"全部串行"或"全部并行"都更合理。
因为不同工具的副作用不同。
例如:
text
读取文件 A
读取文件 B这两个操作通常可以并行。
但下面两个操作不适合并行:
text
修改 pom.xml
运行 mvn test如果测试命令在文件修改到一半时启动,就可能得到不稳定结果。
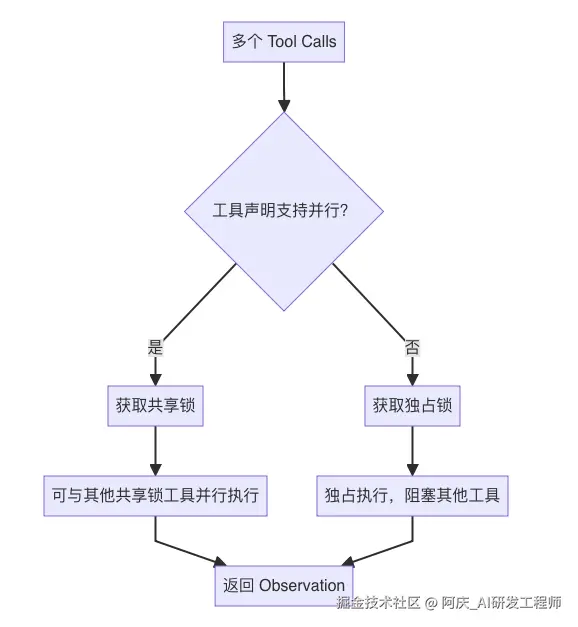
可迁移原则
工具并发不应该由调度器拍脑袋决定,而应该由工具声明自身能力。
至少要区分:
- 纯读工具;
- 只读但耗时工具;
- 修改文件工具;
- 执行命令工具;
- 访问外部服务工具;
- 涉及凭据或权限的工具;
- 不可取消工具;
- 取消时需要清理资源的工具。
边界
能力声明本身可能不准确。一个工具是否"可并行",不只取决于工具代码,也取决于它操作的资源。
例如两个不同工具都修改同一个文件,即使它们各自声明可并行,也可能冲突。
因此,更严格的系统可以进一步引入资源级锁,例如:
text
file:package.json
db:migration
network:external-apiCodex 当前实现更像是工具级并发控制,已经比盲目并发可靠,但不是完整的事务系统。
八、Errors:工具失败不一定是系统失败
源码事实
对应源码:codex-rs/core/src/tools/parallel.rs、codex-rs/core/src/tools/registry.rs。
在 parallel.rs 中,工具调用返回错误时,Codex 会区分 fatal error 和普通 function call error:
text
FunctionCallError::Fatal
→ CodexErr::Fatal
→ Turn 失败
其他 FunctionCallError
→ failure_response
→ success=false 的工具输出返回给模型这意味着很多工具失败不会直接终止 Agent,而是作为环境反馈继续进入模型上下文。
设计抽象
对编码 Agent 来说,命令失败是常态。
例如:
text
cat config.yaml
→ 文件不存在
npm test
→ 某个测试失败
grep keyword
→ 没有匹配结果这些结果不一定表示 Agent 失败,而是 Agent 理解环境的一部分。
所以更合理的设计是:
text
工具失败
↓
标准化错误
↓
作为 Observation 返回给模型
↓
模型决定下一步修正策略可迁移原则
Agent 工具错误至少应该分层:
| 错误类型 | 处理方式 |
|---|---|
| 参数错误 | 返回给模型,让模型修正 |
| 文件不存在 | 返回给模型,让模型搜索或创建 |
| 命令退出码非零 | 返回 stdout/stderr,让模型分析 |
| 超时 | 返回超时信息,允许模型换策略 |
| 权限不足 | 进入审批或阻断 |
| 内部状态损坏 | 终止 Turn |
| 凭据泄露风险 | 系统层拦截,不交给模型自由处理 |
边界
不是所有错误都适合交给模型恢复。
涉及权限、凭据、数据破坏、重复危险操作的错误,应该由系统策略处理,而不是让模型"自己想办法"。
九、Safety:安全边界放在模型之外
源码事实
对应源码:codex-rs/core/src/tools/handlers/shell.rs、codex-rs/core/src/tools/runtimes/shell.rs、codex-rs/core/src/mcp_tool_call.rs、codex-rs/protocol/src/permissions.rs。
Codex 的源码体现了一个原则:安全不能只依赖 Prompt。
模型可以提出动作,但动作是否真的执行,要经过系统层判断。Shell 工具会经过 approval policy、exec policy、sandbox permissions 等检查;MCP 工具也有独立的 tool approval 路径,例如 maybe_request_mcp_tool_approval。
设计抽象
一个编码 Agent 可以执行 Shell、修改文件、安装依赖、访问网络。只靠 Prompt 写一句:
text
请不要执行危险命令。不够。
因为模型可能:
- 误判命令风险;
- 被仓库里的恶意文本提示注入;
- 被工具返回内容误导;
- 为了完成任务尝试越权操作。
Codex 的安全边界可以抽象为:
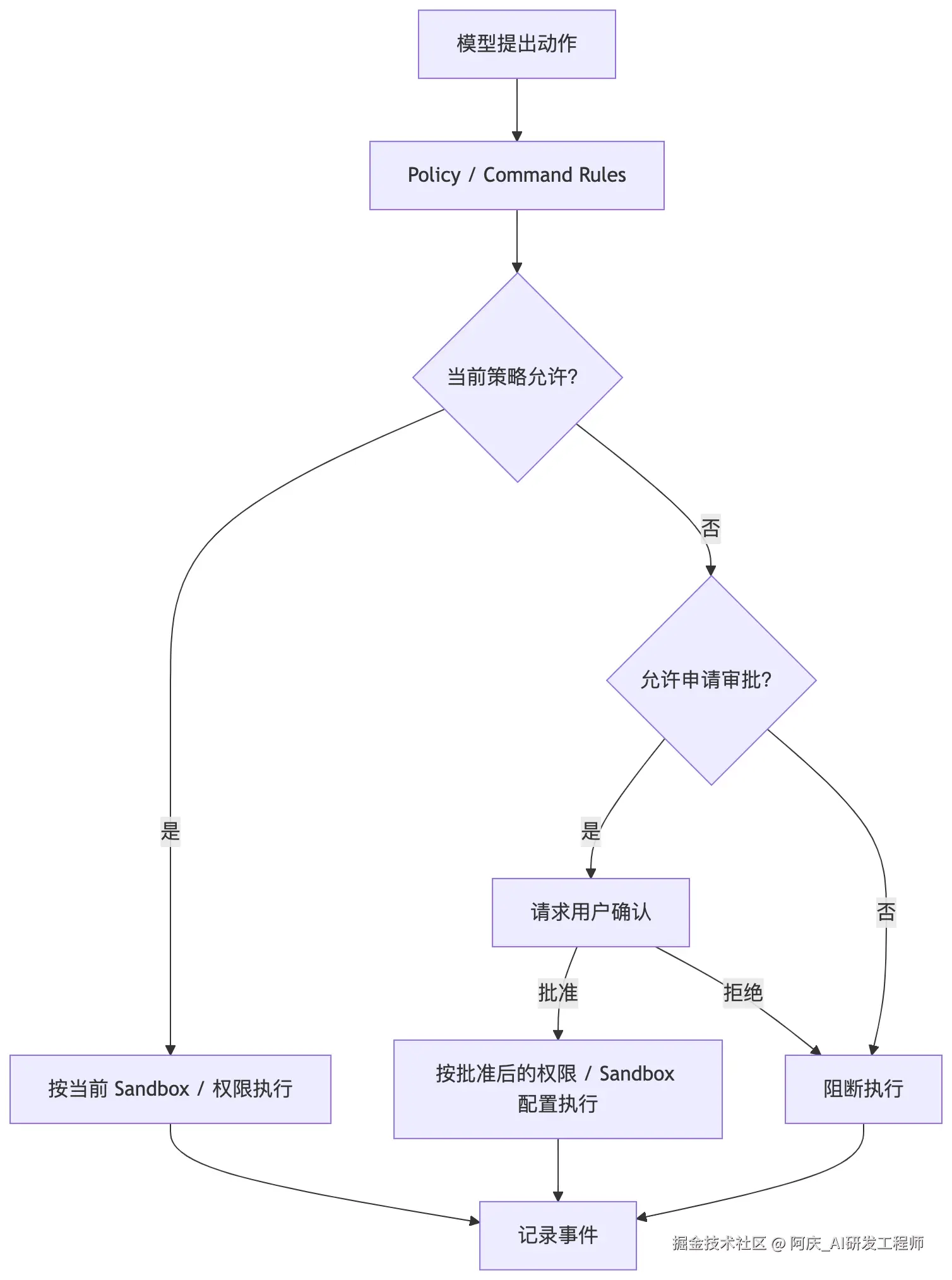
这里有两个不同概念:
| 控制 | 作用 |
|---|---|
| Sandbox | 定义 Agent 技术上能访问什么 |
| Approval | 定义 Agent 什么时候必须问用户 |
Sandbox 是技术边界,Approval 是跨越默认策略或提升权限前的用户确认机制。审批不等于完全移除沙盒,而是让运行时按批准后的权限和沙盒配置执行动作。
MCP 的特殊边界
MCP Server 本质上是外部进程或远程服务。Codex 可以在发起 MCP tool call 前做审批,也可以在特定能力或元数据机制下传递工具调用相关状态;但 MCP Server 内部访问了什么文件、网络和凭据,不一定完全受 Agent 主进程沙盒约束。
所以 MCP Server 也应该有自己的权限模型,而不是默认信任。
可迁移原则
生产级 Agent 的安全控制应该放在模型之外。
至少包括:
- 文件访问边界;
- 网络访问边界;
- 命令白名单 / 黑名单 / 审批规则;
- 凭据隔离;
- 高风险操作人工确认;
- 工具执行审计;
- 外部 MCP Server 的独立权限控制。
边界
安全边界越严格,Agent 自主性越低;边界越宽,风险越高。
合理设计不是"所有操作都问用户",而是:
- 低风险操作自动执行;
- 中风险操作进入沙盒;
- 高风险操作请求审批;
- 禁止操作直接阻断。
这样既能降低审批疲劳,也能避免把安全完全交给模型判断。
十、Protocol:用结构化事件驱动 UI,而不是返回一段文本
源码事实
对应源码:codex-rs/app-server-protocol/src/protocol/common.rs、codex-rs/app-server-protocol/src/protocol/v2/turn.rs、codex-rs/app-server-protocol/src/protocol/v2/item.rs、codex-rs/app-server-protocol/src/protocol/event_mapping.rs。
Codex App Server 使用 Thread、Turn、Item 作为协议模型。
- Thread:一个持久会话;
- Turn:用户一次输入触发的一轮 Agent 工作;
- Item:Turn 中的原子事件,例如用户消息、Agent 消息、工具执行、审批请求、Diff。
Item 有生命周期事件:
text
item/started
item-specific delta notification
item/completedTurn 也有生命周期事件:
text
turn/started
turn/completed
turn/diff/updated
turn/plan/updated这些方法名和类型定义可以在 common.rs、v2/turn.rs、v2/item.rs 中找到;Core 事件到 App Server 协议事件的映射在 event_mapping.rs 中。
设计抽象
编码 Agent 的一次执行过程可能包含:
- 模型开始推理;
- 读取文件;
- 运行命令;
- 输出 stdout/stderr;
- 生成代码 Diff;
- 请求用户批准;
- 工具执行失败;
- 修改后继续测试;
- 最终总结。
如果只返回一段自然语言,客户端很难稳定展示这些过程。
所以 Codex 使用结构化事件,让 UI 不需要解析自然语言来猜 Agent 在做什么。
例如:
text
turn/started
item/started: CommandExecution
item/agentMessage/delta
item/commandExecution/outputDelta
turn/diff/updated
item/commandExecution/requestApproval
item/completed
turn/completed可迁移原则
如果你要做一个严肃的 Agent 产品,协议层应该表达领域事件,而不是只表达字符串。
这样 UI 可以稳定实现:
- 实时进度;
- 命令输出;
- Diff 展示;
- 审批弹窗;
- 失败重试;
- 断线后重建视图;
- 历史回放。
这里的"断线后重建视图"主要指客户端重新连接后基于持久化状态重建 Thread / Turn / Item 展示,不等同于正在运行的任意外部进程都能透明恢复。
边界
结构化协议会增加客户端和服务端的复杂度。
如果只是一个命令行脚本,简单文本输出就够了。但如果要支持 IDE、Web、多 Agent 并行、断线恢复、审批流,结构化事件几乎是必选项。
十一、Hooks:用生命周期扩展点解耦策略和核心循环
源码事实
对应源码:codex-rs/core/src/hook_runtime.rs。
在 hook_runtime.rs 中,Codex 支持多个生命周期 Hook,包括但不限于:
- session start;
- subagent start;
- user prompt submit;
- pre tool use;
- post tool use;
- permission request;
- stop;
- subagent stop;
- pre compact;
- post compact。
PreToolUseHookResult 可以继续执行,也可以阻断工具调用;Stop Hook 可以在 Agent 准备结束时要求继续;Pre/Post Compact Hook 可以围绕上下文压缩插入策略。
设计抽象
Hooks 的价值在于:策略不需要全部写进主循环。
例如:
- 工具执行前做安全检查;
- 工具执行后做审计;
- 用户输入后注入额外上下文;
- Agent 停止前检查是否运行测试;
- 上下文压缩前后记录状态;
- 权限请求时接入外部审批系统。
这些逻辑如果全部写进 run_turn,核心循环会迅速膨胀。
Hooks 让 Agent Runtime 变成可扩展平台,而不是一个写死的工具脚本。
可迁移原则
Prompt 适合表达软约束,Hook 和 Policy 适合执行硬约束。
例如:
text
Prompt:
请尽量运行测试。
Stop Hook:
如果本轮修改了代码但没有运行测试,则阻止结束,并向模型注入继续测试的上下文。前者是建议,后者是运行时策略。
边界
Hooks 也会带来复杂度:
- Hook 本身可能失败;
- 多个 Hook 的执行顺序需要定义;
- Hook 可能修改上下文,影响模型行为;
- Hook 可能阻断任务,造成用户困惑;
- Hook 也需要审计和可观测性。
因此,Hook 不应该被滥用。适合放在 Hook 里的,是横切关注点:
- 安全;
- 审计;
- 组织策略;
- 质量门禁;
- 外部系统集成。
业务主流程仍然应该保持清晰。
十二、Codex 反向说明了哪些 Agent 反模式
从 Codex 的设计,可以反推出一些常见 Agent 反模式。
| 反模式 | 问题 | 更好的方式 |
|---|---|---|
| 把 Agent 写成一个 while 循环 | 无法中途插入输入、取消、恢复或表达生命周期 | 把 Agent Loop 做成可继续、可打断、可持久化记录的 Turn 运行时 |
| 工具调用直接写 if/else | 工具数量增长后不可维护,权限、并发、错误处理散落各处 | 使用 Tool Router / Registry / Runtime 分层 |
| 所有工具默认并行 | 文件修改、测试执行、数据库操作容易产生竞态 | 工具声明并发能力,运行时按能力调度 |
| 只靠 Prompt 做安全 | Prompt 是软约束,模型可能误判或被提示注入影响 | 安全边界必须由 Sandbox、Policy、Approval 强制执行 |
| 把自然语言当 UI 协议 | 客户端无法稳定展示命令、Diff、审批和错误 | 使用结构化事件协议 |
| 上下文只追加不压缩 | token 成本失控,长任务中途崩溃,历史噪声越来越多 | 保留可回放事件记录,同时用 replacement history 控制模型上下文 |
十三、不应该盲目照搬 Codex 的地方
Codex 的设计有很强的工程参考价值,但不意味着所有 Agent 都应该照搬。
1. App Server 不一定适合小型 Agent
如果你的 Agent 只有 CLI 一个入口,而且任务很短,不一定需要 Thread / Turn / Item 协议。
App Server 的价值主要体现在:
- 多客户端;
- 长任务;
- 客户端断线后重建视图;
- IDE 集成;
- 多 Agent 并行;
- 审批和 Diff 展示。
2. 追加式上下文请求依赖缓存收益
Codex 倾向于以稳定前缀和追加式历史构造模型请求,这有利于无状态请求、缓存复用和可恢复性;当上下文过长时,再通过 compaction 生成 replacement history。
但如果你的模型服务没有 Prompt Cache,或者缓存命中率很低,这种方式会增加成本。
3. 工具级并发控制不是完整事务系统
Codex 的工具并发控制已经比盲目并发更可靠,但它不是数据库事务,也不是文件级锁系统。
如果你的 Agent 会频繁修改共享资源,可能还需要更细粒度的资源锁。
4. Hooks 不是万能扩展点
Hooks 适合做横切策略,不适合承载复杂业务主流程。
如果所有逻辑都塞进 Hooks,系统会变得难以推理。
5. MCP 不等于完整 Agent 协议
MCP 适合统一工具接入,但不一定适合作为完整 Agent 产品协议。
复杂 Agent UI 还需要:
- Turn 生命周期;
- Item 生命周期;
- 流式事件;
- Diff;
- 审批;
- 客户端断线后重建视图;
- 用户中途介入。
MCP 更像工具协议,不是完整的 Agent 应用协议。
总结
从 Codex 的开源源码可以看出,生产级 Agent 的关键不是把 Tool Calling 跑通,而是围绕模型构建一个可恢复、可审计、可扩展、可控的运行时系统。
可以用一个公式概括:
text
生产级 Agent
=
模型能力
× 上下文工程
× 工具运行时
× 状态管理
× 安全边界
× 结构化协议
× 可观测性模型越强,Agent 的上限越高;Runtime 越成熟,Agent 的下限越稳。
Codex 最值得学习的地方,不是某个神奇 Prompt,也不是某个复杂规划算法,而是它把 Agent 当成一个真实软件系统来设计:
- 有状态;
- 有权限;
- 有生命周期;
- 有协议;
- 有工具运行时;
- 有审计;
- 有恢复机制;
- 有明确的安全边界。
这也是 Agent 从 Demo 走向生产的核心分水岭。
参考资料
本文主要参考当前仓库源码和协议定义:
codex-rs/core/src/session/turn.rscodex-rs/core/src/context_manager/history.rscodex-rs/core/src/compact.rscodex-rs/core/src/compact_remote.rscodex-rs/core/src/compact_remote_v2.rscodex-rs/core/src/tools/router.rscodex-rs/core/src/tools/spec_plan.rscodex-rs/core/src/tools/registry.rscodex-rs/core/src/tools/parallel.rscodex-rs/core/src/tools/handlers/shell.rscodex-rs/core/src/tools/runtimes/shell.rscodex-rs/core/src/mcp_tool_call.rscodex-rs/core/src/hook_runtime.rscodex-rs/protocol/src/permissions.rscodex-rs/app-server-protocol/src/protocol/common.rscodex-rs/app-server-protocol/src/protocol/v2/turn.rscodex-rs/app-server-protocol/src/protocol/v2/item.rscodex-rs/app-server-protocol/src/protocol/event_mapping.rscodex-rs/app-server-protocol/src/protocol/thread_history.rs
公开阅读时,建议使用 commit 1b24ba912ac4c56ef936364deb1c3e294b0ef9fa 的 GitHub permalink 固定源码版本,避免后续代码演进导致文件位置或实现细节变化。