这篇论文是 GTI: Graph-based Tree Index with Logarithm Updates for Nearest Neighbor Search in High-Dimensional Spaces ,主题是:面向高维空间最近邻搜索的动态图-树混合索引结构 。论文发表在 PVLDB,核心贡献是提出一种叫 GTI 的索引,用树结构降低构建和更新成本,用图结构保持高效搜索能力。
原文标题
GTI: Graph-based Tree Index with Logarithm Updates for Nearest Neighbor Search in High-Dimensional Spaces
中文翻译
GTI:一种用于高维空间最近邻搜索、支持对数级更新的基于图的树索引
详细讲解
1. GTI
GTI 是作者提出的新方法名称,全称可以理解为 Graph-based Tree Index,也就是"基于图的树索引"。它不是纯图索引,也不是纯树索引,而是把两者结合起来。
2. Graph-based Tree Index
直译是"基于图的树索引"。更准确地说,这篇论文的方法是:
先对全部数据建立一个树索引,树负责组织数据、支持更新;
然后在树的某一层上建立一个轻量级的图索引,图负责快速导航和近似最近邻搜索。
所以它是一个树为主体、图为加速导航结构的混合索引。
3. Logarithm Updates(对数级更新复杂度)
指的是对数级更新复杂度,也就是更新数据时,时间复杂度大约是:O(logn)
意思是:当数据量变大时,更新成本不会线性增长,而是增长得比较慢。
比如数据量从 100 万增加到 1 亿,理论上更新代价不会增加 100 倍,而只是随着 log 规模增长。
4. Nearest Neighbor Search, NNS
最近邻搜索,是指:给定一个查询对象 q,在数据库中找到和它最相似、距离最近的对象。
例如:你输入一张图片,系统在图库中找最相似的图片;你输入一句文本,向量数据库找语义最接近的文本;推荐系统中,找和某个用户兴趣最相近的商品或用户。
5. High-Dimensional Spaces
高维空间指的是数据不是二维、三维,而是几十维、几百维甚至上千维。
例如:图片特征向量可能是 128 维、512 维;文本 embedding 可能是 768 维、1536 维;
推荐系统中的用户向量、商品向量也往往是高维的。
高维空间的问题是:传统树索引比如 R-tree、KD-tree 在高维下效果会变差,这就是论文后面提到的 curse of dimensionality,维度灾难。
**汇报:**这篇论文的题目是《GTI: Graph-based Tree Index with Logarithm Updates for Nearest Neighbor Search in High-Dimensional Spaces》。从标题可以看出,论文关注的是高维空间中的最近邻搜索问题。作者提出了一种名为 GTI 的图-树混合索引结构,它以树索引组织全量数据,并在树的内部层构建轻量级图索引,从而兼顾图索引的高效查询能力和树索引的低构建、低更新成本。标题中的 logarithm updates 表明该方法重点解决动态数据场景下的高效更新问题,即希望实现平均意义上的对数级更新复杂度。
1. 摘要第一段翻译与讲解
原文
Nearest neighbor search (NNS) is fundamental for high-dimensional space retrieval and impacts various fields, such as pattern recognition, information retrieval, recommendation systems, and vector database management.
中文翻译
最近邻搜索是高维空间检索中的基础问题,并且影响着许多领域,例如模式识别、信息检索、推荐系统以及向量数据库管理。
详细讲解
这一句话是在交代研究背景:为什么最近邻搜索重要。
最近邻搜索本质上解决的是一个问题:
给定一个查询对象,怎样在大量高维数据中快速找到最相似的数据?
在现在的人工智能和数据库系统中,很多数据都会被表示成向量。例如图片、文本、用户行为、商品特征,都可以变成一个高维向量。向量之间的距离越近,通常代表它们越相似。所以 NNS 是很多系统的底层能力。
这里涉及的几个概念
1. 最近邻搜索,NNS
NNS 的英文是 Nearest Neighbor Search。
假设数据库中有很多点:O={o1,o2,...,on}。现在给一个查询点 q,最近邻搜索要找到距离 q 最近的对象。如果找 1 个,就是 1-NN;如果找 k 个,就是 k-NN,也叫 k 近邻搜索。
2. 高维空间检索
"高维空间检索"可以理解为:数据都被表示成高维向量,然后系统根据向量距离进行检索。
比如在文本检索中:"人工智能发展趋势"这句话会被编码成一个向量;数据库里每篇文档也会被编码成向量;系统通过计算向量相似度,找到语义最相关的文档。
3. 模式识别
Pattern recognition,模式识别。
例如人脸识别、语音识别、手写数字识别。系统需要判断一个新样本和已有样本中哪个最相似。
4. 信息检索
Information retrieval,信息检索。
比如搜索引擎、论文检索、文档检索。现在很多检索系统不再只是关键词匹配,而是把文本变成向量,再做最近邻搜索。
5. 推荐系统
Recommendation systems,推荐系统。
例如给用户推荐商品、视频、新闻时,系统可能会找和当前用户兴趣向量最相似的商品向量。
6. 向量数据库管理
Vector database management,向量数据库管理。
向量数据库比如 Milvus、Faiss、Weaviate、Pinecone 等,核心能力之一就是在海量向量中做快速最近邻搜索。
汇报:论文首先指出,最近邻搜索是高维空间检索中的基础问题。随着图像、文本、推荐系统以及向量数据库的发展,大量数据都会被表示为高维向量,而系统需要根据向量之间的距离或相似度快速找到与查询对象最接近的数据对象。因此,最近邻搜索不仅是数据库领域的重要问题,也广泛服务于模式识别、信息检索、推荐系统和向量数据库管理等应用场景。
2. 摘要第二句话:翻译与讲解
原文
Among existing NNS methods, graph-based methods often excel in query accuracy and efficiency.
中文翻译
在现有的最近邻搜索方法中,基于图的方法通常在查询准确率和查询效率方面表现突出。
详细讲解
这句话是在说:目前做最近邻搜索的方法很多,但其中图索引方法通常是效果最好的一类。
最近邻搜索常见方法大致有四类:
- 树方法,比如 KD-tree、R-tree、M-tree;
- 哈希方法,比如 LSH;
- 量化方法,比如 Product Quantization;
- 图方法,比如 HNSW、NSG、KNN Graph。
这篇论文重点讨论的是第四类:graph-based methods,基于图的最近邻搜索方法。
什么是"基于图的方法"?
你可以把数据集中每个向量看成一个点。
图方法会把这些点连接起来:相似的点之间连边,不相似的点之间一般不连边。也就是说,它构造的是一个"近邻关系图"。
例如有 5 个数据点:o1,o2,o3,o4,o5。如果 o1 和 o3 很相似,就在它们之间连一条边。如果 o1 和 o5 离得很远,就不连边。这样最后形成一个图结构。
为什么图方法查询快?
因为查询时不需要把所有点都算一遍。它通常会从图中的某个入口点开始,然后沿着"越来越接近查询点"的方向走。
这个过程有点像:你在地图上找一个地方,不是把全世界每个地点都查一遍,而是先找到一个大致方向,然后一步步沿着更接近目标的位置走过去。
图方法常用的是 greedy search,贪心搜索。
大概逻辑是:当前在点 oi;查看它的邻居;选择离查询点 q 更近的邻居;继续往前走;直到找不到更近的邻居为止。这样可以用比较少的距离计算,快速找到近似最近邻。
为什么图方法准确率高?
因为图结构显式保存了数据之间的近邻关系。换句话说,它不是简单地把高维空间切块,也不是把数据粗暴压缩,而是直接记录:哪些点和哪些点本来就是邻近的。
所以在高维空间中,图方法通常能更好地保持数据之间的相似关系。
这也是为什么很多近似最近邻库和向量数据库会使用图索引,例如 HNSW 这类方法。
这里的两个评价指标
1. Query accuracy:查询准确率
查询准确率指的是:算法找到的结果和真实最近邻结果有多接近。
在近似最近邻搜索中,常用指标是 Recall,召回率。比如真实最近邻有 10 个,算法找到了其中 9 个,那么 recall 就是: 9/10=0.9。召回率越高,说明结果越接近精确答案。
2. Query efficiency:查询效率
查询效率指的是:一次查询需要花多少时间、做多少次距离计算、访问多少节点。
在实际系统里,查询效率通常体现为:查询延迟低;吞吐量高;同样准确率下速度更快。
汇报:在现有最近邻搜索方法中,图索引方法通常能够在查询效率和查询准确率之间取得较好的平衡。其基本思想是将数据对象表示为图中的顶点,并通过边刻画对象之间的近邻关系。查询时,算法可以从某个入口点出发,沿着图中更接近查询对象的方向进行贪心导航,从而避免对全量数据进行遍历。因此,相比树方法、哈希方法和量化方法,图方法在高维空间中往往能够获得更高的召回率和更低的查询延迟。
图方法的优势:查询快、准确率高。
原因是:它把数据之间的近邻关系显式建成图;查询时可以沿着图结构快速导航;不用暴力扫描所有数据。但是它的短板是建图贵,更新难。
3. 摘要第三句话:翻译与讲解
原文
However, these methods face significant challenges, including high construction costs and difficulties with dynamic data updates.
中文翻译
然而,这些方法也面临显著挑战,包括索引构建成本高,以及难以支持动态数据更新。
详细讲解
它是在说:图方法虽然查询效果好,但是在实际系统中并不完美。它主要有两个问题:
第一,建图成本高。 第二,动态更新困难。
这两个问题就是 GTI 这篇论文的主要出发点。
一、什么叫"construction costs",构建成本?
这里的 construction 指的是 index construction,也就是索引构建。
在最近邻搜索中,如果没有索引,每次查询都要和所有数据计算距离,这叫暴力搜索,太慢。
所以通常要先构建索引。
对于图方法来说,构建索引就是:把每个数据点作为图中的顶点;再为每个点找到若干近邻;
然后在近邻之间连边;最后形成一个可用于导航搜索的图结构。
问题是:这个过程非常耗时。因为如果数据量很大,比如一百万、一千万甚至十亿级向量,要为每个点找到合适的邻居,本身就很复杂。
举个简单例子
假设有 100 万个向量。如果想为每个向量找 10 个近邻,最朴素的方式是:每个点都和其他点算距离;再选出最近的 10 个点;然后连边。这个代价非常高。
虽然实际图索引不会这么暴力,会使用近似构建、启发式优化、并行化等方法,但总体来说,图索引的构建仍然比树索引、哈希索引要重很多。
论文在引言中也提到,对于十亿级数据集,图索引构建即使并行化,也可能需要数小时甚至数天,并且会显著增加内存使用。
二、什么叫"dynamic data updates",动态数据更新?
dynamic data updates 指的是数据集不是静态不变的,而是会不断发生变化。
主要包括两类:
1. 插入 insertion
比如:新增商品;新增图片;新增文档;新增用户行为数据;新增 embedding 向量。
2. 删除 deletion
比如:商品下架;用户删除内容;过期新闻被移除;违规内容被删除;数据库中某些向量失效。
在真实系统中,数据往往是不断变化的。所以一个好的索引结构不仅要查得快,还要能在数据变化后快速维护索引。
三、为什么图方法更新困难?
因为图索引中每个点不是孤立的。每个点都和其他点通过边连接起来。
如果插入一个新点,那么系统不仅要把这个新点放进去,还要考虑:它应该连接哪些邻居?哪些已有点应该把它作为邻居?图的导航结构是否会被破坏?
如果删除一个点,问题更复杂。删除这个点之后:它的出边要删掉;其他点指向它的入边也要删掉;被影响的邻居可能需要重新找新的邻居;
图的连通性和搜索质量可能下降。所以删除操作比插入更麻烦。这也是很多图索引方法只支持插入,不好支持删除,或者采用"懒删除"。
四、什么是"懒删除"?
懒删除,英文一般叫 lazy deletion。
意思是:当一个对象被删除时,系统不马上彻底修改图结构,而是先给它打一个删除标记。
查询时如果遇到这个对象,就跳过它。这样删除操作本身很快,但问题是:图里会积累很多无效节点;搜索路径可能经过被删除节点;索引质量逐渐下降;最终需要周期性重建索引。所以懒删除只是把成本推迟了,并没有真正消除成本。
五、这一句话和 GTI 的关系
作者提出 GTI,就是要解决图方法的这两个痛点:
第一,用树结构先组织全量数据,避免在所有对象级别上构建一个巨大图,从而降低构建成本。
第二,只在树的 level 1 层构建轻量级图,并设计插入和删除算法,使更新复杂度平均达到 O(logn)。
所以 GTI 的核心思想不是"完全抛弃图",而是:保留图的快速导航能力;减少图的规模;用树来承担数据组织和动态更新。
汇报:尽管图索引方法在高维最近邻搜索中具有较高的查询效率和准确率,但它们在实际动态场景中仍然面临两个关键问题。首先,图索引需要维护大量对象之间的近邻关系,因此构建成本较高,在大规模数据集上甚至可能需要数小时或数天。其次,图结构对数据更新并不友好,尤其是删除操作会影响节点的入边、出边以及整体导航结构,容易导致索引质量下降。因此,如何在保持图索引查询性能的同时降低构建成本并支持高效动态更新,是本文关注的核心问题。
图方法的矛盾是:查询强,但维护难。
具体表现为:建图成本高;插入和删除复杂;懒删除会导致索引质量下降,最终仍需重建。
4. 摘要第四句话:翻译与讲解
原文
Recent efforts have focused on combining graph methods with hashing, quantization, and tree-based approaches to address these issues, but problems with large index sizes and update performance remain unresolved.
中文翻译
近年来的研究主要尝试将图方法与哈希、量化以及树索引方法相结合,以解决上述问题;但是,索引规模过大和更新性能不足的问题仍然没有得到彻底解决。
详细讲解
这句话的逻辑是:前面说图方法有两个问题:**构建成本高;动态更新困难。**那学术界和工业界当然不会坐视不管,所以出现了很多"混合方法"。也就是不再只用纯图结构,而是把图和其他技术结合起来。
一、为什么要做 hybrid methods?
Hybrid methods 指的是"混合方法"。
在这篇论文语境里,主要是:图 + 哈希;图 + 量化;图 + 树。
作者想说明,已有研究已经在尝试缓解图索引的问题,但这些方法仍然存在不足。
二、图 + 哈希是什么思路?
哈希方法的代表是 LSH,Locality-Sensitive Hashing,局部敏感哈希。
它的大致思想是:把高维向量映射到若干哈希桶里;相似的向量更可能落到同一个桶中;查询时只在相关桶里找候选对象。如果和图结合,哈希可以用来:快速缩小搜索范围;为图搜索提供较好的起始点;减少部分距离计算。
但是问题是:哈希本身可能需要多张哈希表;和图索引同时存在时,索引空间会变大;哈希桶划分不一定稳定,动态更新仍然不够理想。
论文后文提到的 LSH-APG 就是这类代表方法,它用轻量级 LSH 框架改善图搜索速度和剪枝条件,但仍存在懒删除和索引规模较大的问题。
三、图 + 量化是什么思路?
量化,英文是 quantization。
简单理解就是:把原始高维向量压缩成更小、更粗略的表示。例如原本一个向量是:0.1234,0.9876,0.4567,...,量化之后可能变成: 1,9,4,...,或者被编码成更短的码字。
这样做的好处是:节省内存;加快距离计算;降低图构建和搜索时的存储压力。
但是缺点是:量化会带来误差;压缩后的向量不一定能完全保持真实距离关系;在高维空间中,误差可能影响查询准确率;动态更新时,图结构维护问题依然存在。
所以图 + 量化主要解决的是存储和计算压缩问题,但不一定能彻底解决更新问题。
四、图 + 树是什么思路?
树方法的优势是:构建相对轻;更新比较方便;可以支持精确查询和范围查询。但树方法在高维空间中容易受"维度灾难"影响,查询效率下降。
所以图 + 树的思路就是:用树来划分数据空间;在某些树节点或叶节点内部建立图;利用图提高局部搜索效率。论文中提到的 ELPIS 就是这类方法。它先用树划分数据集,然后在叶节点内部构建子图,从而避免对整个数据集建一个完整的大图,降低构建成本。
但是这类方法的问题是:如果每个叶节点或多个局部区域都建图,整体索引规模仍然不小;数据频繁插入删除时,树结构变化可能影响局部图;多个子图之间的全局导航能力可能不足;更新性能仍然不够理想。
五、"large index sizes" 是什么意思?
large index sizes 指的是索引占用空间过大。这里的索引不是数据本身,而是为了加速查询额外建立的数据结构。比如:哈希表;图中的边;树节点;量化码本;邻接表;辅助表。
如果方法同时维护"图 + 哈希"或"图 + 树 + 额外结构",那索引空间可能很大。在大规模向量数据库中,索引空间非常重要。因为图索引通常要放在内存中,索引越大,内存压力越大,系统可扩展性越差。
六、"update performance" 是什么意思?
update performance 指的是数据插入、删除时索引维护的效率。这里不仅仅是"能不能更新",还包括:更新是否实时;是否需要重建索引;单次插入删除是否足够快;更新后查询质量是否稳定;是否会积累无效节点或过期边。很多方法看起来支持更新,但实际上可能依赖懒删除、周期性重建,或者更新后性能下降。
所以作者说:已有方法还没有彻底解决 update performance 的问题。
这一句话在论文中的作用
这句话是在说明:现有混合方法已经是一个合理方向,但仍有缺口。也就是说,GTI 不是凭空提出的,它是在已有 hybrid methods 的基础上进一步推进。
作者要解决的是:如何设计一个更轻量、更动态、更适合实时更新的图-树混合索引。
它后面就会引出:GTI 只在树的 level 1 层建轻量级图;树覆盖全量数据;图负责全局导航;插入删除平均达到对数复杂度。
汇报时可以这样讲
针对图索引构建成本高和动态更新困难的问题,已有研究开始探索图与哈希、量化或树索引相结合的混合方法。例如,哈希可以用于缩小候选范围,量化可以降低向量存储和距离计算成本,树结构则可以用于划分数据空间并减少全局建图开销。然而,这些方法通常需要同时维护多种索引结构,导致索引规模仍然较大;同时,在频繁插入和删除的动态场景下,它们往往仍依赖懒删除或周期性重建,因此更新性能问题并没有被彻底解决。这也构成了本文提出 GTI 的直接动机。
已有方法已经尝试"图 + 其他技术",但仍有两个问题:索引太大;更新不够快、不够实时。
所以 GTI 的目标不是简单提出一个新图索引,而是提出一个:轻量级、可动态更新、查询效果仍接近图方法的图-树混合索引。
5. 摘要第五句话:翻译与讲解
原文
In response, this paper proposes GTI, a novel, lightweight, and dynamic graph-based tree index for high-dimensional NNS.
中文翻译
针对上述问题,本文提出了 GTI,一种新颖的、轻量级的、支持动态更新的基于图的树索引,用于高维最近邻搜索。
详细讲解
前面几句话的逻辑是:图方法查询效果好;但是构建成本高、动态更新难;已有图 + 哈希、图 + 量化、图 + 树的方法仍然存在索引规模大、更新效率不足的问题;
所以作者提出 GTI。也就是说,GTI 的提出是为了同时解决三个目标:轻量化构建;支持动态更新;保持高效最近邻搜索能力。
一、GTI 是什么?
GTI 的全称可以理解为:Graph-based Tree Index 。也就是:基于图的树索引 ,或者更自然地说,图-树混合索引。但是注意,它不是简单地"树里面加图",也不是"图外面套树"。
它的结构特点是:树索引覆盖全部数据;图索引只建立在树的某一内部层上;图负责快速导航;树负责数据组织、局部访问和动态更新。
论文在摘要中明确说,GTI 会在整个数据集上构建树索引,并且在树的 level 1 层使用轻量级图索引,从而降低图构建成本。
二、为什么说它是 novel,新颖的?
这里的 novel 不是说"树"和"图"本身是新的,而是说它们的结合方式比较特别。
已有图-树混合方法往往是:先用树把数据划分到叶节点;再在叶节点内部建很多局部子图;查询时先走树,再进入某些图中搜索。
而 GTI 的区别是:它不是在每个叶节点都建图;而是在树的 level 1 层,也就是叶子上一层,建立一个轻量级图;查询时也不是先从根节点往下遍历树,而是直接在图上搜索 ;到达图底层顶点后,再通过指针访问对应叶节点中的局部对象。所以它既利用图的全局导航能力,又避免在所有数据对象上建一个巨大图。
三、为什么说它是 lightweight,轻量级的?
轻量级主要体现在:图不是建立在全部数据对象上,而是建立在树的 level 1 entries 上。
假设原始数据有 100 万个对象。如果用传统图索引,可能要为 100 万个对象都建立图顶点和邻接边。而 GTI 先用树把数据分组。每个 leaf node 里放多个对象,level 1 的 entry 可以看作这些叶节点或局部区域的代表点。于是图只需要在这些代表点上建立。如果每个叶节点大约包含 100 个对象,那么图顶点数量就可能从 100 万降到大约 1 万级别。这样图规模变小,构建时间和空间成本都会下降。
四、为什么说它是 dynamic,动态的?
dynamic 指的是它适合数据不断变化的场景。也就是支持:插入新对象;删除已有对象;不需要频繁全量重建索引;更新复杂度平均达到对数级。
GTI 能做到这一点,是因为它把更新拆成两部分:
树更新: 所有数据对象都在树里,所以插入删除主要先更新树;
图更新: 只有当树的 level 1 发生变化时,才同步更新图。
大多数插入删除不会马上影响 level 1,因此图不需要频繁大规模改动。这就是它动态更新效率高的关键。
五、为什么是 graph-based tree index,而不是 tree-based graph index?
作者叫它 graph-based tree index,直译是"基于图的树索引"。但是从结构上看,它其实是一个树索引为主体、图索引用于导航增强的混合结构。
可以这样理解:树是基础数据组织结构;图建立在树的内部节点上;图帮助树提升高维最近邻搜索性能。所以它不是完全替代树,而是用图增强树。
汇报时可以这样讲
针对现有图索引构建成本高、索引规模大以及动态更新困难的问题,作者提出了一种新的图-树混合索引 GTI。GTI 的核心思想是以树索引组织全量数据,并仅在树的内部层构建轻量级图索引。这样一方面可以利用树结构降低构建和更新开销,另一方面又可以利用图结构在高维空间中的快速导航能力,从而在动态场景下兼顾查询效率、查询准确率和更新性能。
novel:结构设计新;
lightweight:图规模小、构建和空间成本低;
dynamic:支持插入删除,适合动态数据。
全量数据建树,部分代表节点建图;树负责更新,图负责导航。
6. 摘要第六句话:翻译与讲解
原文
GTI constructs a tree index built across the entire dataset and employs a lightweight graph index at the level 1 of the tree to significantly reduce graph construction costs.
中文翻译
GTI 在整个数据集上构建一个树索引,并在树的第 1 层使用一个轻量级图索引,从而显著降低图索引的构建成本。
详细讲解
这句话包含 GTI 最重要的结构设计:全量数据建树;只在树的 level 1 建图。
这也是 GTI 为什么能降低构建成本的核心原因。
一、什么叫 "tree index built across the entire dataset"?
意思是:GTI 会对整个数据集建立一个树索引。
假设数据集中有很多高维向量:O={o1,o2,...,on}。GTI 不是只对一部分数据建树,而是所有对象都被组织进树结构里。
这棵树的作用主要有三个:
第一,组织全量数据。
所有对象都在树里,因此树是 GTI 的基础数据结构。
第二,支持动态插入和删除。
树结构通常比图结构更容易更新。插入一个对象时,只需要找到合适的叶节点;删除一个对象时,也主要影响局部节点。
第三,支持精确查询和范围查询。
图方法通常更适合近似搜索,而树方法可以通过剪枝支持精确搜索。所以 GTI 后面能同时支持 approximate NNS 和 exact NNS,与这棵树有关。
二、什么叫 "level 1 of the tree"?
在论文中,作者把树的叶子层称为 Level 0 。那么 Level 1 就是叶子节点的上一层。
叶子节点 = 叶节点 = tree 的最底层节点。
可以这样理解:
Level 2: 根节点或更高层内部节点
Level 1: 叶子节点的父层,也就是 GTI 建图的位置
Level 0: 叶子层,真正存放数据对象在论文第 4 节中,作者明确说明:GTI 的图索引是建立在树中"紧邻叶子条目之上的那一层",也就是 level 1;图中的底层顶点还会指向对应的叶节点。
三、为什么不在所有数据对象上建图?
传统图索引通常是:每个数据对象都是图中的一个顶点;每个顶点连接若干近邻;整个图覆盖全部对象。这样查询效果好,但代价很大。如果有 100 万个对象,图就有大约 100 万个顶点,还要保存大量边。
GTI 不这么做。它先用树把对象分组,然后只对 level 1 的 entry 或代表点建图。也就是说,图中的顶点不是所有原始对象,而是树中某些内部层的代表对象。这样图顶点数量大幅减少。
举个直观例子
假设有 100 万个向量。如果传统 HNSW 对全量数据建图,那么图可能有:100 万个顶点
每个顶点若干条边
如果 GTI 的每个叶节点大约管理 100 个对象,那么 level 1 的 entry 数量可能只有:100万 / 100 = 1万个左右。也就是说,图顶点数量可能从 100 万降到 1 万。
这会显著降低:图构建时间;图存储空间;图更新开销。
四、那只在 level 1 建图,会不会损失查询效果?
如果图不覆盖所有对象,只覆盖 level 1 的代表点,那查询时怎么找到真正的最近邻?
GTI 的做法是:图负责找到可能相关的局部区域;树的叶节点负责补充局部对象搜索。
具体来说:图的顶点对应 level 1 的 entry;每个图顶点在底层会有一个指针,指向它对应的树叶节点;查询时先在图上导航,找到接近查询点的代表点;然后通过指针访问对应叶节点中的真实数据对象。所以 GTI 不是只搜代表点,而是通过代表点定位到局部数据区域,再搜索叶节点中的对象。这就是它能兼顾轻量和准确率的关键。
五、"lightweight graph index" 轻量在哪里?
这里的 lightweight 主要有三层含义。
**第一,图顶点少。**不是每个数据对象都进图,而是 level 1 的代表点进图。
**第二,图边少。**顶点少了,维护的邻居关系自然也少。
**第三,图更新少。**插入或删除一个对象时,如果没有导致叶节点分裂或下溢,那么 level 1 不变,图就不需要更新。
所以 GTI 的图是"轻量级导航图",而不是"全量对象图"。
六、这句话在方法设计中的地位
这句话可以说是 GTI 的核心结构定义:GTI = 全量树索引 + level 1 轻量图索引。
这和已有图-树方法的区别在于:已有方法可能在多个叶节点局部建子图,或者查询时依赖从树顶向下遍历;GTI 则是在树的 level 1 建一个全局图,并且查询时直接从图开始导航。这样既保留了图的全局搜索能力,又避免了全量建图的高成本。
汇报时可以这样讲
GTI 的核心结构可以概括为"全量建树、局部建图"。具体来说,GTI 首先在整个数据集上构建树索引,用树结构对高维数据进行层次化组织;随后,它并不对所有原始数据对象建立图,而是只在树的 level 1 层,即叶子节点上一层的代表 entry 上构建轻量级图索引。这样可以显著减少图中的顶点数量和边数量,从而降低图索引的构建时间、存储空间和更新开销。同时,图底层顶点会指向对应的叶节点,使查询过程既能利用图的全局导航能力,又能访问树叶节点中的局部真实对象。
entry 是 node 里面的一条记录;非叶子 entry 通常代表一个子区域,并指向下一层节点;GTI 不是拿整棵树建图,而是拿树 Level 1 entry 的 center 建一个多层轻量图。
它的好处是:图规模小,所以构建便宜;树覆盖全量数据,所以更新方便;图 + 叶节点联合搜索,所以查询效果还能保持。
7. 摘要第七句话:翻译与讲解
原文
It also features effective data insertion and deletion algorithms that enable logarithmic real-time updates.
中文翻译
此外,GTI 还设计了有效的数据插入和删除算法,从而实现对数级的实时更新。
详细讲解
这句话讲的是 GTI 的动态更新能力。你可以把这句话拆成三层理解:
第一,它支持插入。
第二,它支持删除。
第三,插入和删除的平均复杂度是对数级,也就是 O(logn)。
这就是论文标题里 Logarithm Updates 的来源。
一、为什么"插入"和"删除"这么重要?
在真实系统里,数据不是静态的。
比如:电商平台每天有新商品上架、旧商品下架;社交平台每天有新帖子发布、旧帖子删除;向量数据库里新的文档 embedding 不断加入;搜索系统里旧内容会过期或被移除。
所以索引不能只适合一次性建好、永远不变的数据集。如果每次有新数据都要重建整个图索引,那成本太高。
GTI 想解决的就是:数据变化时,不要重建整个索引,而是局部更新。
二、插入操作在 GTI 里怎么发生?
假设来了一个新对象 o_{new}。GTI 的插入大致是:
第一步:把新对象插入树索引
第二步:检查树的叶子节点有没有分裂
第三步:如果没有分裂,图不用动
第四步:如果叶子节点分裂,Level 1 多了新的 entry,才把新的 center 插入图也就是说:**大多数插入只影响树,不影响图。**这是 GTI 更新快的关键。
举个例子
假设一个叶子节点最多放 10 个对象。现在某个叶子节点里有 8 个对象:
Leaf N6: [o1, o2, ..., o8]新插入一个对象 o_{new}:
Leaf N6: [o1, o2, ..., o8, o_new]这个叶子节点还没满,所以:
只更新树的叶子节点
图不需要变化但是如果原来这个叶子节点已经有 10 个对象,再插入一个新对象,就超容量了。
这时候叶子节点可能会分裂成两个叶子节点:
原来:
Leaf N6: 10 个对象
插入后:
Leaf N6a: 一部分对象
Leaf N6b: 另一部分对象这时树的 Level 1 会新增一个 entry 来代表新叶子节点。因为 GTI 的图是建立在 Level 1 entries 上的,所以这时候图也要新增一个顶点。
论文算法 2 也是这个逻辑:先插入树;如果插入导致叶节点分裂,并产生新的 Level 1 entry,才执行图插入,并让新图顶点指向新的叶节点。
三、删除操作在 GTI 里怎么发生?
删除比插入更麻烦。因为图里面有边。如果要删除一个图顶点,不仅要删这个顶点自己的边,还要删其他顶点指向它的边。所以传统图索引删除很难。
GTI 的删除大致是:
第一步:先找到要删除的对象
第二步:从树里面删除这个对象
第三步:检查树的叶子节点是否发生下溢或被删除
第四步:如果 Level 1 没变化,图不用动
第五步:如果 Level 1 删除了某个 entry,才删除图中对应顶点和相关边也就是说,和插入一样:**多数删除也只影响树,不影响图。**只有当删除导致树的 Level 1 entry 变化时,才需要更新图。
什么叫"下溢 underflow"?
树节点一般有容量限制:最多能放多少 entry;最少也要保留多少 entry。如果删除对象后,一个节点里的 entry 太少了,就叫 underflow,下溢 。简单说就是:节点太空了,不满足树结构要求,需要合并或调整。
发生下溢后,树结构可能要合并节点,Level 1 的 entry 也可能被删除或调整。如果 Level 1 entry 被删除,对应的图顶点也要删除。
四、为什么能做到 O(logn)?
树索引的高度一般是对数级的。也就是说,如果数据量是 n,树高大约是:logn
插入或删除一个对象时,通常只需要沿着树从根到叶子走一条路径。所以树更新是 O(logn)。
GTI 的图又不是建在全部数据上,而是建在 Level 1 entries 上,规模比全量数据小很多。
并且图不是每次都更新,只有树的 Level 1 发生变化时才更新。所以整体平均更新复杂度可以保持在对数级。
论文第 4.5 节总结,GTI 的插入和删除都可以保持 logarithmic complexity,即对数级时间复杂度。
五、"real-time updates" 是什么意思?
这里的 real-time 不一定是严格意义上的毫秒级实时系统,而是指:当数据插入或删除时,索引可以立刻局部维护;不用等到周期性重建;不用大量离线重构;更新后索引可以继续服务查询。
你可以把它理解为:GTI 更适合动态场景,而不是只适合静态数据集。
六、GTI 和传统图索引更新的区别
传统图索引,例如全量 HNSW 或 NSG,可能是:每个真实对象都是图顶点,插入/删除一个对象都可能影响很多边,图结构维护复杂
GTI 是:真实对象主要在树里,图只维护 Level 1 的代表点,普通对象插入删除多数不影响图,只有叶节点分裂/下溢时才更新图。所以 GTI 的更新代价更低。
七、这句话在论文中的作用
这句话是在强调 GTI 不只是"建图更轻",还解决了动态数据场景的问题。
前一句讲:GTI 在 Level 1 建轻量图,降低构建成本。
这一句讲:GTI 有插入删除算法,实现对数级实时更新。
这两个点合起来,就是 GTI 相比传统图方法的主要优势。
汇报时可以这样讲
除了降低图索引构建成本之外,GTI 还重点面向动态数据场景设计了插入和删除算法。其基本思想是将更新过程拆分为树更新和图更新两部分:所有对象首先在树索引中完成插入或删除;只有当树的叶节点发生分裂或下溢,并导致 Level 1 entry 发生变化时,才同步更新图索引。由于树索引本身具有对数级访问和更新特性,而图索引只建立在 Level 1 的代表 entry 上,规模远小于全量数据图,因此 GTI 能够在平均意义上实现对数级的实时更新。
8. 摘要第八句话:翻译与讲解
原文
Additionally, we have developed an effective NNS algorithm for GTI, which not only achieves approximate search performance on par with SOTA graph-based methods but also supports exact NNS.
中文翻译
此外,作者还为 GTI 设计了一种有效的最近邻搜索算法,该算法不仅能够达到与当前先进图方法相当的近似搜索性能,而且还支持精确最近邻搜索。
详细讲解
这句话很重要,因为它说明 GTI 不只是"建得快、更新快",还要证明:查得也不能差。
如果一个索引构建快、更新快,但查询准确率很低,那也没有意义。所以作者强调 GTI 的搜索有两个能力:
1. 支持 approximate NNS,也就是近似最近邻搜索
2. 支持 exact NNS,也就是精确最近邻搜索一、什么是 approximate NNS?
Approximate Nearest Neighbor Search,近似最近邻搜索,简称 ANNS。
它不保证返回的结果一定是全局真实最近邻,但希望返回结果足够接近真实答案。
比如真实最近的 5 个对象是:o3, o17, o25, o90, o101
近似搜索返回:o3, o17, o25, o88, o101
它错了一个,但整体很接近真实结果。在高维大规模检索里,很多系统都接受近似结果,因为精确搜索太慢。比如向量数据库、推荐系统、图像检索、语义检索,通常更关心:能不能很快返回高质量结果,而不是必须 100% 精确。
二、什么是 exact NNS?
Exact Nearest Neighbor Search,精确最近邻搜索,指的是:系统必须返回真正距离查询点最近的对象,不能只是近似。比如真实最近邻是 o17,那算法就必须返回 o17,不能返回一个"差不多近"的对象。精确搜索通常更慢,但在一些场景中很重要,例如:机器人避障;自动驾驶路径规划;医学影像诊断;安全相关检索;需要严格正确性的数据库查询。
论文在引言中也提到,一些应用要求精确搜索,例如机器人和自动驾驶中的障碍定位,以及基于医学影像的疾病诊断。
三、为什么图方法通常擅长近似搜索,但不擅长精确搜索?
传统图索引的查询通常是贪心搜索。
它大致是:从入口点开始,找当前邻居中离查询 q 更近的点,不断向更近的点移动,直到找不到更近的点。
这个过程很快,但问题是:它可能陷入局部最优。
什么是局部最优?
举个直观例子。你在山里找最低点。你每一步都往附近更低的地方走。最后你到达了一个小山谷,周围都比它高。你以为找到了最低点。但其实远处还有一个更低的大山谷,只是你当前邻居走不到那里。这就叫局部最优。
在图搜索中也是一样:当前点周围没有更接近查询点的邻居;但全局上可能还有更近的点,只是搜索没走到。所以图方法通常是高效近似,而不是天然精确。
四、GTI 为什么可以同时支持近似和精确?
因为 GTI 同时有图和树。
图:负责快速找到可能相关的区域
树:负责保证可达性和精确检
在近似搜索时,GTI 主要利用图:先在图上快速导航,找到接近 q 的 Level 1 代表点,访问这些代表点指向的叶子节点,在候选对象中返回近似最近邻,这样速度快,效果接近先进图方法。
在精确搜索时,GTI 可以进一步利用树:先用近似搜索得到一批候选结果,用候选结果形成搜索半径或剪枝边界,再在树上进行精确搜索和验证,最终返回真正的 k 个最近邻。
所以 GTI 的优势是:图提供高效起点和候选;树提供精确搜索能力。
五、"on par with SOTA graph-based methods" 是什么意思?
SOTA 是 state-of-the-art 的缩写,意思是"当前最先进水平"。
on par with 意思是"与......相当"。
所以这句话的意思是:GTI 的近似搜索性能可以达到和当前先进图方法相近的水平。也就是说,作者不是只说 GTI 更新快,还要证明:它在查询效果上没有明显牺牲。
摘要后面也说,实验结果显示 GTI 的搜索效果与先进近似最近邻方法相当,同时更新效率相比先进树方法有约 10 倍提升。
六、这一句的核心逻辑
近似查询:性能接近 SOTA 图方法
精确查询:借助树结构也能支持 exact NNS这其实是 GTI 的一个卖点:很多图方法擅长 approximate NNS,但不天然支持 exact NNS;而很多树方法支持 exact NNS,但高维下查询慢。GTI 试图把两者结合起来。
汇报时可以这样讲
在查询方面,GTI 并不仅仅追求低构建成本和高更新效率,而是进一步设计了适用于该图-树混合结构的最近邻搜索算法。
对于近似最近邻搜索,GTI 直接利用建立在树 Level 1 entries 上的轻量级图进行导航,并通过图底层顶点指向的叶节点访问真实对象,从而获得接近先进图索引方法的查询性能。
与此同时,由于 GTI 保留了覆盖全量数据的树索引结构,它还可以在近似候选结果的基础上进一步执行树上的精确搜索,因此能够支持 exact NNS。这使得 GTI 同时具备图索引的高效近似搜索能力和树索引的精确查询能力。
近似搜索:直接用图导航 + 访问叶节点
精确搜索:用图先找候选,再借助树做精确验证所以 GTI 的目标不是只做一个动态索引,而是希望在:构建成本、更新效率、近似搜索性能、精确搜索能力这几个方面取得平衡。
9. 摘要实验结果句:翻译与讲解
原文
Extensive experiments on six real-world datasets demonstrate that GTI achieves an approximately 10× improvement in update efficiency compared to SOTA tree-based methods, while achieving search effectiveness comparable to SOTA approximate NNS methods.
中文翻译
作者在六个真实世界数据集上进行了大量实验,结果表明:与当前先进的树索引方法相比,GTI 的更新效率大约提升了 10 倍;同时,它的搜索效果可以达到与当前先进近似最近邻搜索方法相当的水平。
详细讲解
这句话其实是在总结 GTI 的两个实验结论:
1. 更新更快:比先进树方法大约快 10 倍
2. 查询不差:搜索效果接近先进近似 NNS 方法这两个结论分别对应论文前面提出的两个核心目标:动态更新能力、高质量最近邻搜索能
一、什么叫 "six real-world datasets"?
意思是作者不是只在人工构造的小数据上测试,而是在六个真实数据集上做实验。
在最近邻搜索论文里,常见实验会比较:查询时间;召回率;索引构建时间;索引大小;插入时间;删除时间。所以这句话的作用是告诉读者:GTI 不是只在理论上可行,而是在多个真实数据集上验证过。
二、什么是 "update efficiency"?
update efficiency 指的是索引更新效率。也就是当数据发生变化时,索引维护得快不快。
主要包括:插入新对象的时间,删除已有对象的时间,更新后索引是否还能保持查询质量,是否需要周期性重建。
GTI 的优势就在于:它不是把所有真实对象都放进图里,而是主要把真实对象放在树里。所以很多插入和删除只需要更新树,不需要更新图。
三、"10× improvement" 怎么理解?
"approximately 10× improvement" 可以理解为:更新效率大约提升一个数量级。
比如,如果某个先进树方法更新一批数据需要 10 秒,GTI 可能大约只需要 1 秒。
当然,这不是说每个数据集、每个操作都严格快 10 倍,而是整体实验结果表现出大约 10 倍量级的提升。这句话里比较对象是:GTI vs SOTA tree-based methods。也就是和先进树索引方法比较更新效率。
四、为什么是和树方法比更新?
GTI 明明是图-树混合方法,为什么这里说更新效率和树方法比?
因为树方法本来就比较擅长动态更新。传统图方法更新很难,而树方法相对容易更新。如果 GTI 能比先进树方法更新还快,说明它在动态场景下确实很有优势。
但这里也要注意:这句话是摘要中的高度概括。真正严谨汇报时可以说:
实验显示,GTI 在更新效率上相较于先进树索引方法有约 10 倍提升,同时仍保持接近先进近似 NNS 方法的搜索效果。
五、什么叫 "search effectiveness"?
search effectiveness 指的是搜索效果,而不是单纯搜索速度。
在近似最近邻搜索中,搜索效果通常看:Recall / 召回率、Precision / 准确率、查询结果和真实最近邻的重合程度。比如真实 top-10 最近邻中,算法找回了 9 个,那么 recall 就是 0.9。
GTI 的图比全量图小,那大家自然会担心它搜索准确率下降。
实验结果说明:虽然 GTI 的图更轻量,但通过"图导航 + 叶节点访问"的设计,它的搜索效果仍然可以接近先进近似最近邻方法。
论文摘要中明确说,GTI 在六个真实数据集上相较先进树方法实现约 10 倍更新效率提升,同时搜索效果与先进近似 NNS 方法相当。
六、什么是 "SOTA approximate NNS methods"?
SOTA approximate NNS methods 指当前先进的近似最近邻搜索方法。
这里通常包括一些高性能近似搜索方法,比如:先进图索引方法、先进混合索引方法、高性能 ANN 方法。它们的特点是查询效果强、速度快,但通常构建和更新成本较高。
作者想表达的是:GTI 虽然更轻量、更动态,但查询效果没有明显落后。
七、这句话的论文逻辑作用
这句话是摘要中的"实验验证"部分。它对应前面提出的三个问题:
| 问题 | GTI 的回答 |
|---|---|
| 图索引构建成本高 | 只在树 Level 1 建轻量图 |
| 图索引动态更新难 | 设计插入和删除算法,平均对数级更新 |
| 轻量图会不会查不准 | 实验显示搜索效果接近先进 ANN 方法 |
所以摘要整体逻辑就闭环了。
汇报时可以这样讲
实验部分中,作者在六个真实世界数据集上对 GTI 进行了系统评估。结果表明,GTI 在动态更新方面具有明显优势:相比当前先进的树索引方法,其更新效率大约提升了 10 倍。同时,尽管 GTI 并没有对全量数据对象构建图索引,而是仅在树的 Level 1 entries 上构建轻量级图,但其近似最近邻搜索效果仍然能够达到与先进近似 NNS 方法相当的水平。这说明 GTI 在降低构建和更新成本的同时,并没有显著牺牲查询质量,因而更适合数据频繁变化的高维检索场景。
GTI 通过全量树索引和 Level 1 轻量图索引,在动态更新效率和近似搜索质量之间取得了较好平衡。
GTI 的更新效率比先进树方法大约提升 10 倍;搜索效果又能接近先进近似最近邻方法。
传统图索引虽然查得快,但更新难,尤其删除很麻烦。传统树索引虽然更新方便,但高维查询效果可能不好。
GTI 的价值就在于折中:树负责动态维护;图负责高效导航;轻量图减少构建和更新压力。
1. Introduction 全文翻译
最近邻搜索,Nearest Neighbor Search,简称 NNS,是一种用于在数据集中识别与查询对象最接近数据点的关键技术,在高维空间检索中发挥着基础作用。该技术广泛应用于多个领域,包括模式识别、信息检索、推荐系统、检索增强生成以及向量数据库管理等。例如,top-k 查询会根据排序函数得分返回最重要的 k 个查询结果,它覆盖了多种查询模型、数据访问方式和排序函数;从对象与查询之间相似性的角度看,top-k 查询与最近邻搜索具有相似性。因此,NNS 的不同变体可以用于回答 top-k 查询。
近年来,一些 top-k 研究在无索引方法和 R-tree 数据预处理基础上,将 skyline 查询与 top-k 查询结合起来,在某种程度上发挥了类似 NNS 的作用。然而,这类面向 top-k 查询的树方法在高维空间中会受到维度灾难的限制,导致搜索性能下降。过去几十年中,研究者提出了许多提高 NNS 效率的方法,包括树方法、哈希方法、量化方法和图方法。其中,图方法由于能够有效表示对象之间的近邻关系,并通过贪心算法获得高准确率查询结果,因此在查询效率与准确率之间取得了较优平衡,已经成为许多实际应用中较受欢迎的方法。
尽管图方法有明显优势,但它们也面临显著挑战。图索引的构建通常非常耗时,对于十亿级数据集,即使使用并行化,也可能需要数小时甚至数天。虽然并行处理可以加速构建过程,但它也会显著增加内存使用,从而限制系统扩展性,并使大规模数据集管理更加复杂。此外,图方法在动态数据更新方面表现较弱,因此不太适合数据频繁变化的场景。例如,Microsoft 和 Facebook 等大型平台在其搜索引擎中集成了图方法,但仍面临实时更新问题。当出现新数据,例如 ChatGPT 相关的新进展时,这些方法可能无法及时更新,从而导致查询性能下降。为了解决这一问题,已有研究提出了增量构建方法,可以支持数据插入,但往往难以处理数据删除,例如社交媒体内容被删除的情况。周期性重建方法可以同时处理插入和删除,但重建成本很高。
近期研究开始探索混合方法,例如将图方法与哈希、量化或树方法结合起来,以缓解图方法在构建和更新方面的瓶颈。例如,ELPIS 使用树索引划分数据集,并在叶节点内构建子图,从而避免在整个数据集上构建完整图,降低构建成本。然而,ELPIS 在频繁数据更新场景下仍然存在挑战。类似地,有研究使用量化压缩向量来构建和搜索图,以减少内存使用并加速构建和搜索过程,但图索引本身仍然难以更新。LSH-APG 则使用轻量级 LSH 框架提高搜索速度和剪枝条件,从而降低构建和搜索成本,并支持数据插入和删除。然而,它采用的懒删除策略仍然需要周期性索引调整,而且哈希索引与图索引同时存在会导致较大的索引规模,进而可能影响查询性能。
混合方法为解决现有方法的局限提供了有前景的方向。图 1 展示了本文的动机:树方法在索引构建和动态更新方面较高效,适合动态场景,但在高维空间中的搜索性能通常较差;相比之下,图方法在最近邻搜索方面表现很好,但构建和更新成本较高。为了解决这些问题,本文提出了一种混合的树-图索引,希望同时利用二者优势:既支持动态更新,又保持高效查询性能,尤其是在高维空间中。然而,要实现这一目标,需要解决三个关键挑战。
挑战一:优化图构建成本。 图结构以优秀的查询性能著称,但构建成本昂贵。虽然并行化可以加速构建,但它需要大量内存,从而限制扩展性,并使大规模数据管理更加复杂。近期一些方法尝试通过树索引对数据进行层次划分,以加速图构建。然而,这些方法仍需要维护对象之间复杂的邻居关系,因此内存需求依然较高。为了解决这一问题,本文提出一种多粒度划分方法:使用树索引对数据进行层次划分,并选择性地只在树的某一个内部层上构建图。这样可以有效降低开销,并更高效地管理近邻关系。
挑战二:实现实时图更新。 图方法在高效更新数据方面存在困难,这是因为搜索过程依赖复杂的邻居结构。电商平台商品列表频繁变化,社交媒体内容不断更新,这些动态环境会使现有树-图方法难以应对。为了解决这一问题,本文设计了高效的数据插入和删除算法,使 GTI 能够实现对数级实时更新。具体来说,本文将更新操作拆分为两个部分:对所有对象执行树更新;对选定内部节点执行图更新。由于树更新本身具有对数级时间复杂度,而图节点数量相对较少,因此整体更新复杂度平均保持在 O(logn)。
挑战三:保持高效搜索性能。 混合树-图方法在搜索阶段通常需要自顶向下遍历树,这可能限制搜索性能。此外,过度依赖树的划分信息可能削弱图的全局导航结构,导致查询准确率下降。另一方面,现有混合树-图方法往往只支持近似查询,不适合需要精确搜索的应用,例如机器人和自动驾驶中的障碍定位、路径规划,以及基于医学影像的疾病诊断。为了解决这一问题,本文方法不同于传统做法:它不先遍历树,而是直接在图上进行搜索,从而避免树遍历带来的性能限制,并保持高效的图查询能力。同时,GTI 利用图中的全局邻居关系和树叶节点中的局部邻居关系,保证对数据集的覆盖能力和较高查询准确率。此外,该混合结构同时支持高效近似查询和精确查询,发挥了树和图两个组成部分的优势。
综上,本文的主要贡献包括以下四点。第一,提出了一种轻量级、动态的基于图的树索引 GTI,用于高维空间中的最近邻搜索。GTI 在整个数据集上构建树索引,并在树的 Level 1 层构建轻量级图索引,从而显著降低索引构建时间和空间成本。第二,提出了面向动态场景的高效数据更新策略,包括插入和删除算法,使 GTI 支持对数级实时更新。第三,基于较低的构建成本和较强的更新能力,本文设计了高效的近似最近邻搜索算法,使 GTI 的性能可以与先进图方法相当;同时,GTI 还支持精确最近邻搜索,涵盖传统树索引支持的查询类型。第四,作者在六个真实数据集上进行了系统实验,结果表明 GTI 相比先进树方法在更新效率上约提升 10 倍,相比图方法具有更低构建成本,并保持了与先进近似 NNS 方法相当的搜索效果。这些结果说明 GTI 在动态场景中具有较强的应用潜力。
最后,论文其余部分安排如下:第 2 节回顾相关工作,第 3 节给出问题定义,第 4 节介绍提出的轻量级动态图-树索引 GTI,并说明其构建和更新方法;第 5 节详细介绍最近邻搜索过程;第 6 节报告实验研究;第 7 节总结全文并讨论未来方向。
2. Introduction 这一节主要讲了什么?
Introduction 的作用就是完成一套很标准的论文逻辑:
研究背景 → 现有方法优势 → 现有方法问题 → 需要混合方法 → 混合方法仍有不足 → 本文提出 GTI → 总结贡献它主要讲了四件事。
第一,NNS 很重要。最近邻搜索是高维空间检索的基础,和模式识别、信息检索、推荐系统、RAG、向量数据库都有关。
第二,图方法查得好,但维护难。图方法在高维近似最近邻搜索中通常效果很好,但是构建成本高、内存消耗大,而且动态插入删除困难。
第三,已有混合方法还不够。图 + 树、图 + 哈希、图 + 量化都能缓解一些问题,但仍存在索引规模大、懒删除、周期性重建、实时更新不足等问题。
第四,GTI 的核心动机。作者希望设计一种图-树混合索引:树负责全量数据组织和动态更新,图负责高效搜索导航,并且图只建立在树的 Level 1 上,从而减少图规模。
3. Introduction 里的关键重点
你汇报这篇论文时,Introduction 里最重要的不是 top-k、skyline、R-tree 这些细枝末节,而是下面这三个挑战。
挑战一:图构建成本太高
传统图索引通常需要在大量对象之间维护近邻边。数据越大,图构建越慢,占用内存越多。
GTI 的解决办法是:不在所有对象上建图,而是在树的 Level 1 entries 上建轻量图。
挑战二:图索引动态更新困难
插入一个新点还相对容易,但删除一个点会影响入边、出边和邻居关系,容易破坏图结构。
GTI 的解决办法是:先更新树,只有 Level 1 发生变化时才更新图,从而实现平均 O(logn)更新。
挑战三:混合方法不能牺牲搜索性能
如果只是降低构建和更新成本,但查询准确率下降,那方法就没有竞争力。
GTI 的解决办法是:查询时直接从图开始搜索,不先自顶向下遍历树,并且在图底层访问对应叶节点中的真实对象。
4. 关键图表:Figure 1 Motivating Example
Figure 1 是 Introduction 里最关键的图。它不是实验图,而是动机图,用来说明为什么需要 hybrid method。
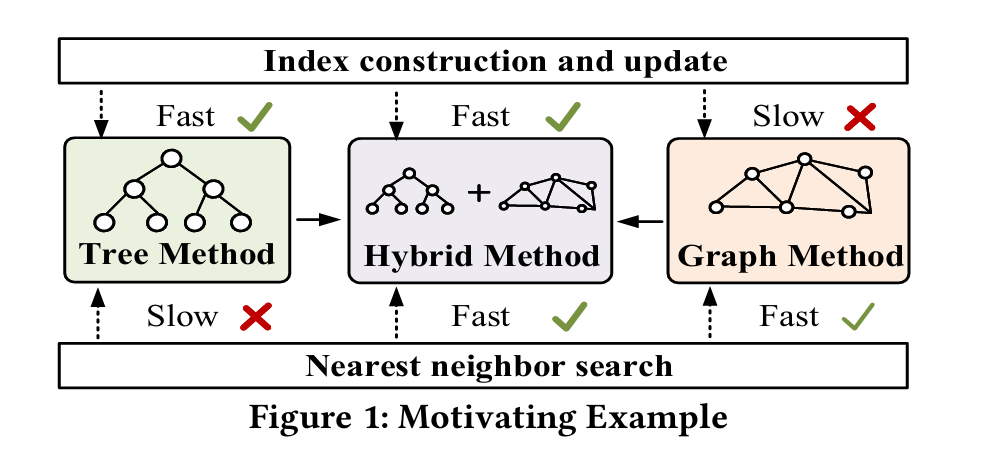
图中比较了三类方法:
| 方法 | 索引构建和更新 | 最近邻搜索 |
|---|---|---|
| Tree Method | 快 | 慢 |
| Graph Method | 慢 | 快 |
| Hybrid Method | 快 | 快 |
它想表达的是:树方法动态性好,但高维查询弱;图方法查询强,但构建和更新弱;GTI 这类混合方法希望同时获得两边优势。
你汇报 Figure 1 时可以这样说:
图 1 给出了本文的基本动机。传统树索引在构建和更新方面较高效,因此适合动态数据场景,但在高维最近邻搜索中容易受到维度灾难影响,查询效率较低。图索引则相反,它能够利用近邻关系实现高效搜索,但构建和更新成本较高。本文提出的 GTI 属于混合方法,希望通过树结构降低构建和更新开销,通过轻量级图结构保持高效搜索性能,从而在动态高维检索场景中取得更好的平衡。
5. 这一节你真正需要记住的汇报主线
你可以把 Introduction 压缩成这样一段来理解:
最近邻搜索是高维检索和向量数据库中的基础问题。现有图索引方法在查询效率和准确率上表现突出,但构建成本高、内存占用大,并且不适合频繁插入删除的动态场景。已有图与树、哈希、量化结合的混合方法虽然缓解了一部分问题,但仍存在索引规模大、更新性能不足和搜索性能受限等问题。为此,本文提出 GTI,通过在全量数据上构建树索引,并仅在树的 Level 1 entries 上构建轻量级图索引,在降低构建和更新开销的同时保持较好的搜索效果。Introduction 最后将问题归纳为三个挑战:降低图构建成本、实现实时更新、保持高效搜索性能。
2. Related Work 全文翻译
2. Related Work
在本节中,作者回顾了高维空间中最近邻搜索的已有研究工作。
2.1 最近邻搜索的基础解决方案
已有大量方法被提出,用于高效解决高维空间中的最近邻搜索问题。这些方法可以分为四大类:哈希方法、量化方法、树方法和图方法。
哈希方法。
哈希方法将高维数据对象映射到若干低维哈希桶中,并通过定位真实答案所在的哈希桶来回答查询。虽然哈希方法在精度方面可以提供理论保证,但它们也面临一些挑战,包括结果质量较低,以及对范围查询和其他复杂搜索功能支持不足。
量化方法。
量化方法根据量化后的特征值对数据对象进行划分,并搜索与查询对象具有相同量化值的候选点,作为最终结果。然而,量化误差会导致其难以获得较高查询准确率,尤其是在高维空间中。
树方法。
树方法通过 pivot mapping 或 hyperplane partitioning 等方式将数据空间划分为子空间,并构建树索引来管理这些子空间。通过将搜索空间缩小到重叠子空间中的点,树方法可以在较低索引开销下同时支持近似搜索和精确搜索,并且能够灵活适应动态场景。
图方法。
图方法利用对象之间的最近邻关系构建近邻图,从而支持近似最近邻搜索。相较于其他方法,图方法通常在查询准确率和查询效率方面表现更优。已有图方法往往基于 Delaunay Graph、Relative Neighborhood Graph、K-Nearest Neighbor Graph 和 Minimum Spanning Tree 等基础图结构。尽管图方法具有优势,但它们也面临较高构建成本和更新困难的问题。为了缓解构建成本,已有研究提出了近似近邻图和并行构建策略,但这些方法仍然会带来较大的索引规模。另一方面,为了处理更新问题,已有研究提出了周期性重建方法,但这种方法又受到较高重建成本的限制。
2.2 混合解决方案
鉴于图方法具有较强的查询性能,研究者开始探索基于图的混合方法,希望通过将图与树、哈希表和量化对象结合起来,提高整体性能。虽然这些混合方法可以改善图搜索性能,但它们仍然面临一些显著挑战,包括较高的图构建成本,以及难以处理动态数据操作。
近年来,研究重点逐渐转向降低构建成本和支持动态真实应用。典型方法包括:ELPIS 和 LANNS,它们通过树的层次划分信息有效降低图构建成本;LVQ 提供了一种通用量化框架,用于改善数据压缩并加速图导航;LSH-APG 使用轻量级 LSH 框架,为图提供高质量搜索种子和剪枝条件;MNG 使用内积技术加速图导航,并引入懒删除策略与周期性重建操作,以支持图更新。
然而,上述方法的图规模仍然较大,这给图索引在主内存中的存储以及动态更新带来了挑战。近期研究 SPFresh 提出了一种轻量级增量重平衡协议,专门用于更新存储在磁盘上的 posting lists。虽然它采用的重建策略适用于基于 posting centroids 的小图,但该方法本质上是面向磁盘数据管理系统设计的。因此,SPFresh 不适用于主内存数据管理,也无法支持需要实时更新的场景。
受这些挑战以及图-树混合方法潜力的启发,本文提出了一种新的动态图树索引 GTI。GTI 通过在树索引之上构建轻量级图来解决构建瓶颈,并通过基于图的单点检索和对数级树更新操作支持高效实时更新。因此,GTI 能够实现比已有方法更高效的索引更新,并达到与树方法相当的构建效率,同时保持近似图方法的高搜索性能,并支持精确相似性搜索。
这一节主要讲了什么?
Related Work 这一节主要做了两件事。
第一,它把高维最近邻搜索方法分成了四类:哈希、量化、树、图。这部分是在建立研究背景,说明不同技术路线各有优缺点。
第二,它重点讲了混合方法。因为 GTI 本身就是图-树混合索引,所以作者需要说明已有混合方法为什么还不够。已有方法虽然尝试用树、哈希或量化来降低图索引成本,但仍然存在图规模大、主内存存储压力大、动态更新困难、懒删除和周期性重建等问题。
所以这一节的逻辑可以概括为:
基础方法各有优缺点
↓
图方法搜索性能最好,但构建和更新困难
↓
混合方法试图改进图方法
↓
已有混合方法仍存在图规模大和实时更新不足
↓
因此需要 GTI这一节有哪些关键点?
关键点一:四类基础 NNS 方法的优缺点
这一节最基础的内容是四类方法对比:
| 方法类别 | 基本思想 | 优点 | 主要问题 |
|---|---|---|---|
| 哈希方法 | 将高维对象映射到哈希桶 | 有一定理论保证,查询快 | 结果质量可能较低,复杂查询支持不足 |
| 量化方法 | 将向量压缩/离散化 | 节省存储,加速计算 | 量化误差影响准确率 |
| 树方法 | 划分数据空间并建树 | 构建和更新灵活,可支持精确查询 | 高维空间中性能下降 |
| 图方法 | 构建对象间近邻图 | 查询效率和准确率强 | 构建成本高,更新困难 |
关键点二:GTI 最相关的是树方法和图方法
哈希和量化在这篇论文里只是背景。
真正和 GTI 相关的是:
**树方法:**优点是更新快、能支持精确查询;缺点是高维搜索效果差。
**图方法:**优点是高维近似搜索效果好;缺点是建图贵、更新难。
GTI 就是想把这两个方法结合起来:
树负责低成本构建、动态更新和精确查询;
图负责高效近似搜索导航。关键点三:已有混合方法仍然没有解决 GTI 关注的问题
这一节提到的混合方法可以这样理解:
**ELPIS / LANNS:图 + 树。**它们利用树结构划分数据,减少全局建图成本,但仍然面临图规模和动态更新问题。
**LVQ:图 + 量化。**它主要通过压缩向量减少内存、加速图导航,但不能从根本上解决图更新困难。
**LSH-APG:图 + 哈希。**它用 LSH 提供搜索种子和剪枝条件,也支持插入删除,但仍然使用懒删除,需要周期性调整,而且哈希索引和图索引共存会增大索引规模。
**MNG:动态图方向。**它通过内积技术加速图导航,并使用懒删除和周期性重建支持更新,但重建成本仍然存在。
**SPFresh:磁盘场景下的增量更新。**它更适合磁盘上的 posting lists,不适合主内存实时更新场景。
这一部分的核心不是让你记住每个方法细节,而是记住作者想表达的结论:
现有混合方法虽然已经在降低构建成本和支持动态应用方面做了尝试,但仍然没有很好地解决图规模大、实时更新不足和主内存管理压力大的问题。
汇报:相关工作部分首先回顾了高维最近邻搜索的四类基础方法,包括哈希方法、量化方法、树方法和图方法。哈希方法通过哈希桶缩小候选范围,但结果质量和复杂查询支持有限;量化方法能够降低存储和距离计算成本,但量化误差会影响查询准确率;树方法构建和更新成本较低,并且可以支持精确查询,但在高维空间中容易受到维度灾难影响;图方法能够较好地刻画对象之间的近邻关系,因此在查询效率和准确率上表现突出,但其构建成本高、索引规模大,并且动态更新困难。
随后,作者重点讨论了图与树、哈希、量化等结构结合的混合方法。已有混合方法在一定程度上缓解了图索引的构建和搜索成本,例如利用树划分减少全局建图开销,利用量化降低内存使用,或者利用哈希提供搜索种子和剪枝条件。然而,这些方法仍然存在图规模较大、懒删除、周期性重建以及实时更新能力不足等问题。因此,GTI 的提出主要是为了在保留图索引高效搜索能力的同时,利用树结构降低构建和更新成本,并进一步适应动态高维检索场景。
3. Problem Formulation 全文翻译

N = tree node,树节点
e = tree entry,树节点中的条目
v = graph vertex,图顶点
| 符号 | 含义 |
|---|---|
| (q) | 查询对象 |
| (o) | 数据对象 |
| (O) | 对象集合 |
| (n) | 对象数量,即 ( |
| (d(. , .)) | 距离函数 |
| (N) | 树节点 |
| (e) | 树 entry |
| (v) | 图顶点 |
| (N_c) | 树节点容量 |
| (m) | 图稀疏度 |
作者首先形式化定义最近邻搜索和范围查询。表 1 总结了论文中经常使用的符号。最近邻搜索是数据库管理和人工智能中的基础问题,并且广泛应用于高维空间。
(1)k最近邻搜索问题定义如下。

在问题定义部分,作者首先给出了 (k) 最近邻搜索的形式化定义。
给定对象集合 (O)、查询对象 (q)、距离函数 (d(. , .)) 和整数 (k),(k)-NNS 的目标是在 (O) 中找到距离 (q) 最近的 (k) 个对象。该定义要求结果集合中不存在某个对象比集合外对象离查询点更远的情况,因此它对应的是精确最近邻搜索。
接下来:为什么需要近似最近邻?
论文接着说:在大规模高维数据集中,精确 k-NNS 的计算成本可能非常高。因此,一个更高效、也可能更实用的替代方案是近似最近邻搜索,定义如下。
这句话很重要,它说明:精确搜索太贵,所以近似搜索在实际中更常用。

详细讲解:AkNNS 是什么?
近似最近邻搜索就是:不强求 100% 返回真实最近邻,但希望返回的结果足够接近真实最近邻。
比如真实最近邻距离查询点的距离是 10。
如果 ϵ=0.1,那么允许返回距离不超过:(1+0.1)×10=11 的对象。
所以如果算法返回一个距离为 10.5 的对象,虽然它不一定是真正最近的,但也可以接受。
ϵ 是什么?
ϵ是误差容忍参数。如果 ϵ=0,那近似搜索就退化成精确搜索。
如果 ϵ 越大,算法允许返回越"不精确"的结果,但通常查询可以更快。可以这样理解:
ε 越小 → 结果越准,但查询越难
ε 越大 → 允许误差越大,查询可能越快不过在实际实验中,很多论文不直接报告 ϵ,而是用 Recall,召回率 来衡量近似搜索效果。

由于在大规模高维数据集中进行精确 (k)-NNS 代价较高,论文进一步定义了 (ϵ)-近似 (k) 最近邻搜索。近似搜索允许返回结果与真实最近邻之间存在一定误差,只要结果对象与查询点的距离不超过真实近邻距离的 (1+ϵ)倍即可。在实验评估中,作者使用 recall 来衡量近似搜索质量,即近似结果与真实 (k) 最近邻结果之间的重合比例。

k-NNS 和 Range Query 的区别
| 查询类型 | 控制条件 | 返回结果 |
|---|---|---|
| k-NNS | 固定数量 k | 返回最近的 k 个对象 |
| Range Query | 固定半径 r | 返回半径 r 内所有对象 |
为什么 GTI 还要提 Range Query?
因为 GTI 里面有树结构。树索引通常很适合支持范围查询和精确查询。
作者在本节最后说:本文关注的是 GTI 如何在动态场景中高效回答一般最近邻搜索,同时支持近似查询和精确查询。此外,由于 GTI 是混合树-图结构,它天然支持精确范围查询。
它说明 GTI 不是只做 approximate NNS,而是:
支持近似最近邻搜索
支持精确最近邻搜索
支持精确范围查询这也是它相比很多纯图 ANN 方法的优势之一。
汇报时可以这样讲
论文还定义了范围查询。给定查询对象 (q)、距离函数 d(. , .)和搜索半径 (r),范围查询返回数据集中所有与 (q) 的距离不超过 (r) 的对象。与 (k)-NNS 固定返回最近的 (k) 个对象不同,范围查询固定的是距离阈值,因此返回数量是不确定的。
由于 GTI 保留了覆盖全量数据的树索引结构,它不仅支持近似最近邻搜索,也能够支持精确最近邻搜索和精确范围查询。
第 3 节汇报时哪些地方需要重点讲?
重点一:精确 NNS 和近似 NNS 的区别
这是后面理解 GTI 搜索算法的基础。精确 NNS 要求结果完全正确;近似 NNS 允许少量误差,但速度更快。GTI 两个都支持,这是本文的卖点之一。
汇报时你可以强调:很多图索引主要面向 approximate NNS,而 GTI 由于保留了树结构,所以还可以支持 exact NNS。
重点二:Recall 是实验中衡量近似搜索效果的关键指标
后面实验部分会大量使用 recall。
你需要提前讲清楚:recall 表示近似搜索结果与真实最近邻结果的重合比例,越高说明近似搜索结果越接近精确答案。
这个指标非常重要,因为作者说 GTI 的搜索效果接近 SOTA ANN 方法,本质上就是看 recall 和查询效率之间的权衡。
重点三:Range Query 体现树结构的价值
范围查询不是本文最核心的任务,但它能说明 GTI 的树索引不是摆设。
GTI 的图负责快速近似导航,但树结构使它仍然能够支持精确查询和范围查询。
所以这也是 GTI 相比纯图方法的一个补充优势。
第 3 节汇报总结稿
问题定义部分主要给出了本文涉及的三类查询任务。首先是精确 (k) 最近邻搜索,即给定对象集合 (O)、查询对象 (q)、距离函数 d(. , .)和整数 (k),目标是返回数据集中距离 (q) 最近的 (k) 个对象。其次,由于大规模高维数据上的精确搜索计算成本较高,论文进一步定义了 (ϵ)-近似 (k) 最近邻搜索,允许返回结果与真实最近邻之间存在一定误差,并使用 recall 衡量近似搜索结果与真实 (k) 最近邻结果的重合程度。最后,论文定义了范围查询,即返回所有与查询对象距离不超过给定半径 (r) 的对象。本文提出的 GTI 主要面向动态场景下的最近邻搜索,既支持高效近似查询,也支持精确最近邻搜索,并且由于其保留了树结构,因此天然支持精确范围查询。
4. Index 这一节整体在讲什么?
第 4 节的标题是 Index,也就是"索引"。
它主要回答一个问题:
GTI 这个索引到底长什么样?它怎么建?怎么插入?怎么删除?复杂度是多少?
4.1 Overview:GTI 总体框架
4.2 Index Structure:GTI 的具体结构,包括树索引和图索引
4.3 Index Construction:GTI 怎么构建
4.4 Index Updating:GTI 怎么插入和删除数据
4.5 Index Complexity Analyses:空间和时间复杂度分析4.1 Overview 原文翻译
图方法擅长表示对象之间的近邻关系,并且能够实现高效的近似最近邻搜索;而树方法则具有较低的构建和更新成本。受此启发,本文提出了 Graph-based Tree Index,简称 GTI。GTI 将图的查询优势与树索引的动态更新优势结合起来。
GTI 支持轻量级索引构建和动态实时更新,同时能够实现高效、全面的最近邻搜索。如图 2 所示,GTI 集成了树索引和图索引,其中图索引建立在树的某一个内部层上。本文首先利用树结构对数据集进行层次化划分,然后选择性地在树的一个内部层上构建图,从而降低整体构建成本。同时,GTI 通过高效的树更新和轻量级图更新支持灵活的数据更新,并且平均能够达到对数级复杂度。最后,GTI 能够高效支持近似最近邻搜索和精确最近邻搜索,从而满足不同查询需求。
4.1 详细讲解
1. 为什么要把树和图结合?
因为树方法和图方法的优缺点正好互补。
树方法的优点:构建成本低,更新方便,支持插入、删除,支持精确查询和范围查询。
树方法的缺点:高维空间下搜索性能差,容易受维度灾难影响。
图方法的优点:高维近似搜索效果好,查询速度快,召回率高。
图方法的缺点:建图成本高,占用内存大,插入删除困难。
所以 GTI 的基本思想就是:用树解决构建和更新问题,用图解决高维搜索问题。
树负责管理数据,图负责快速导航。
2. 什么叫 "Graph-based Tree Index"?
GTI 先在全量数据上建立一棵树;然后从树的某个内部层,也就是 Level 1,取出 entry 的 center;再用这些 center 作为图顶点,构建一个轻量级图;图底层顶点还会指向对应的叶子节点。
所以 GTI 的结构可以抽象成:
全量数据对象
↓
树索引负责层次组织
↓
树 Level 1 entries 的 center
↓
构成轻量级图顶点
↓
图顶点指回对应叶子节点3. 为什么说 GTI 是 lightweight?
lightweight,也就是"轻量级"。GTI 轻量的核心原因是:它不是对所有原始数据对象建图,而是只对树 Level 1 的代表 entry 建图。
举个例子:如果有 100 万个真实对象,传统图索引可能有 100 万个图顶点。但 GTI 先把对象分到很多叶子节点里,然后只拿叶子节点上一层的代表 entry 建图。如果每个叶子节点平均有 100 个对象,那么图顶点可能从 100 万减少到大约 1 万。
这会直接降低:图构建时间,图边存储空间,图更新成本,搜索时图遍历成本。
4. 为什么说 GTI 是 dynamic?
dynamic,也就是"动态"。这里指 GTI 支持数据变化,包括:插入新对象,删除旧对象,更新后继续查询,不需要频繁重建整个索引。
GTI 能做到这一点,是因为:所有真实对象都在树里;树本身适合插入和删除;图只在 Level 1 上维护代表点;普通插入删除通常只影响叶子节点,不一定影响 Level 1;只有 Level 1 entry 发生变化时,才需要更新图。
所以 GTI 的更新逻辑是:
对象变化 → 先更新树
如果 Level 1 不变 → 图不动
如果 Level 1 变化 → 更新轻量图这就是它能实现平均 O(logn)更新的原因。
Figure 2:GTI 总体框架图重点讲解
Figure 2 是这一节最重要的图,标题是 The overall framework of GTI,即 GTI 的总体框架。
图 2 其实把 GTI 分成了三大阶段:
Index construction:索引构建
Index update:索引更新
Nearest neighbor search:最近邻搜索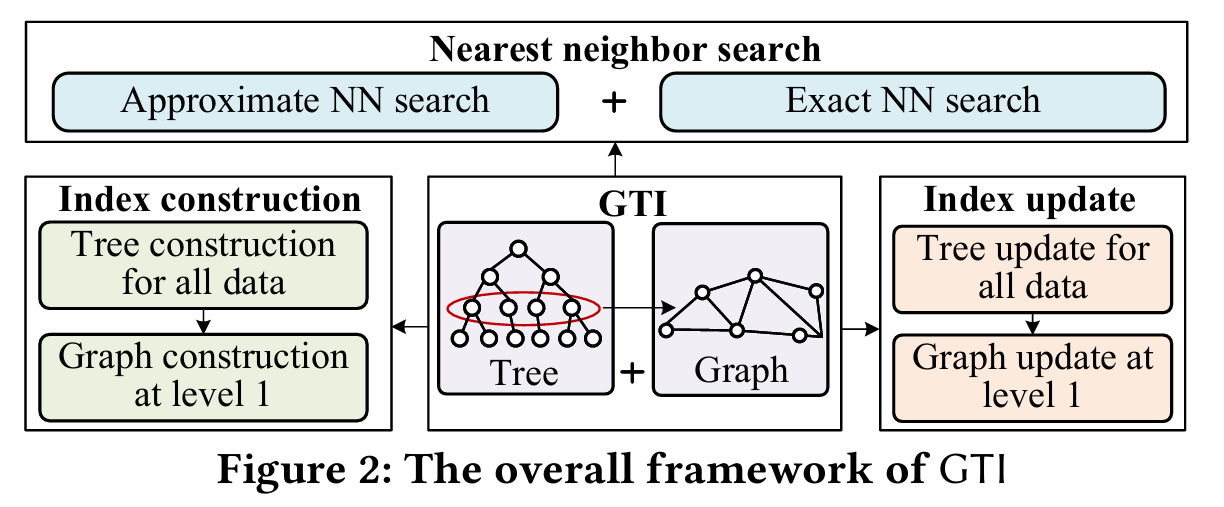
第一部分:Index construction,索引构建
图中左侧表示构建过程:Tree construction for all data → Graph construction at level 1
意思是:第一步,对所有数据建立树索引;第二步,在树的 Level 1 上建立图索引。
这里要注意:树覆盖所有数据,图只覆盖 Level 1 的代表 entry。
所以构建阶段不是"树和图各自独立建一遍全量索引",而是:先有树,再从树的一层抽取代表点建图。这就是 GTI 降低建图成本的关键。
第二部分:Index update,索引更新
图中中间表示更新过程:Tree update for all data → Graph update at level 1
意思是:数据插入或删除时,首先更新树;如果更新影响到了树的 Level 1,再同步更新图。
这里的核心是:图更新不是每次都发生,而是有条件发生。
比如插入一个对象,只要叶子节点没分裂,Level 1 没新增 entry,图就不用变。
第三部分:Nearest neighbor search,最近邻搜索
图中右侧表示查询能力:Approximate NN search + Exact NN search
意思是 GTI 支持两类搜索:
近似最近邻搜索:主要利用图快速导航,速度快。
精确最近邻搜索:利用树结构进行进一步验证,保证结果正确。
这也是 GTI 相比很多纯图 ANN 方法的优势之一。
Figure 2 可以怎么向老师汇报?
你可以这样讲:
图 2 给出了 GTI 的整体框架。GTI 主要由树索引和图索引两部分组成。
在索引构建阶段,GTI 首先在全量数据上构建树索引,对数据进行层次化组织;随后只在树的 Level 1 层构建轻量级图索引,从而避免在所有原始对象上建图,降低构建和存储成本。
在索引更新阶段,GTI 首先执行树更新,只有当树的 Level 1 entry 发生变化时,才同步更新图索引,因此可以支持对数级实时更新。
在查询阶段,GTI 同时支持近似最近邻搜索和精确最近邻搜索,其中图结构用于快速导航,树结构用于维护全量数据并支持精确查询。
混淆二:GTI 的图是不是只有一层?
不是。GTI 是"在树的 Level 1 上建图",但图本身可以是多层的 HNSW-like graph。
也就是说:树的 Level 1:决定图顶点来自哪里。图的 Layer:图自身的层次结构
混淆三:为什么 GTI 能同时支持 approximate 和 exact?
因为它同时保留了图和树。
图 → 高效近似搜索
树 → 全量组织、精确搜索、范围查询如果只有图,通常更偏近似;如果只有树,高维下查询慢;GTI 是想两者兼得。
4.1 汇报总结
第 4 节开始介绍 GTI 的索引设计。
GTI 的总体思想是将树索引和图索引结合起来:树索引覆盖全部数据,用于层次划分、动态更新和精确查询;图索引只建立在树的 Level 1 entries 上,用于高效近似搜索导航。
图 2 展示了 GTI 的整体框架,包括索引构建、索引更新和最近邻搜索三个阶段。
构建时先建树、再在 Level 1 建轻量图;更新时先更新树,必要时更新图;查询时同时支持 approximate NN search 和 exact NN search。
4.2 Index Structure 原文翻译
本文提出的混合索引 GTI 由两个关键组成部分构成:
第一,树索引。树索引用于对数据集进行高效的层次化划分,维护节点内部的局部邻居信息,并降低构建和更新开销。
第二,图索引。图索引轻量地构建在树的某一个内部层上,用于建立全局邻接关系,并支持快速导航以定位查询区域。
为了更清楚地理解 GTI 的结构,论文在图 3 中给出了完整示意图。
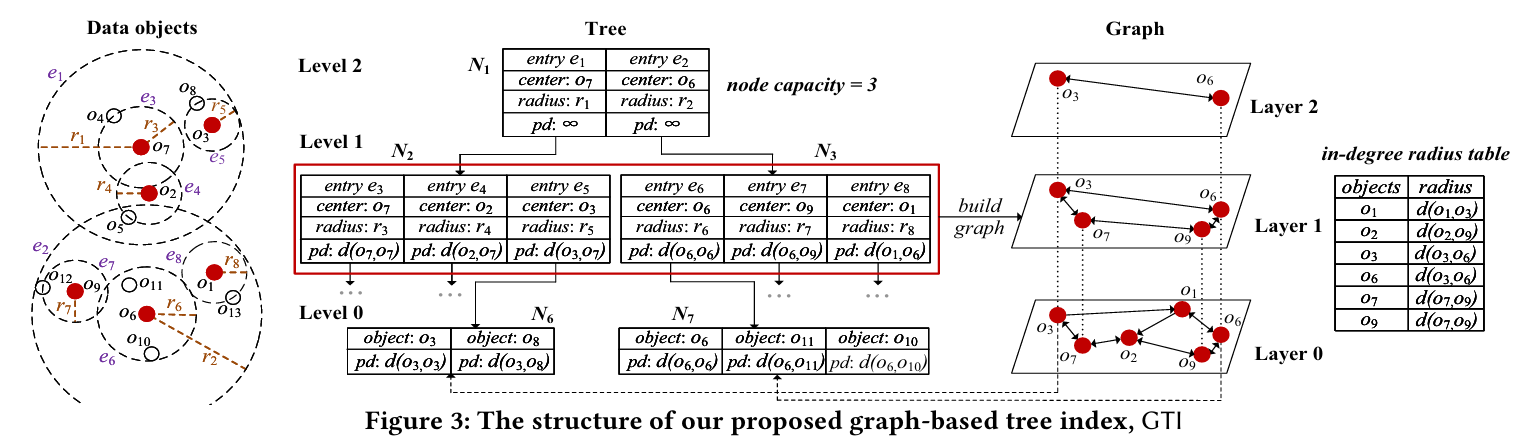
一、The Tree Index:树索引翻译
树索引建立在完整数据集之上,其中节点和 entry 会维护局部邻域关系。为了高效构建树索引并支持数据更新,作者使用了一种类似 M-tree 的结构。根据近期综述,M-tree 在动态索引中表现较好。
具体来说,这棵树使用 ball partitioning,球形划分 的方式对数据进行层次化组织。每个节点可以看作一个由中心点 和半径定义的高维超球体。叶子节点对应最小的超球体,包含相邻的数据对象;非叶子节点则代表更大的超球体,包含多个相邻的子超球体。树是从底向上逐步构建的,通过嵌套超球体逐渐将数据集划分为多个簇。
GTI 中每个节点包含多个 entry。每个 entry 保存一个对象,以及该对象到其父 entry 中心的距离 pd。如果是非叶子 entry,它还包含一个指向子树节点的指针,以及该子树节点对应超球体的中心点和半径。
例如在图 3 中,节点 N2 包含三个非叶子 entry:e3、e4、e5。其中最后一个 entry e5 指向其子树节点 N6。N6 表示一个以 o3 为中心、半径为 r5的超球体,并且存储了中心 o3 到父 entry e1 的中心 o7 的距离 d(o3,o7)。节点中 entry 的数量受到节点容量 Nc 限制。图 3 中节点容量为 3,因此每个节点最多包含 3 个 entry。实际使用中,叶节点和内部节点可能设置不同的节点容量,以适应图索引。
二、树索引详细讲解
这一部分你一定要抓住几个概念:ball partitioning、center、radius、entry、pd、child pointer。
1. GTI 的树不是普通二叉树
GTI 用的是类似 M-tree 的结构。M-tree 适合处理度量空间数据,也就是只要能定义距离函数 d(⋅,⋅),就可以组织数据。这很适合最近邻搜索,因为最近邻本质上就是基于距离。
2. 什么是 ball partitioning?
Ball partitioning 可以翻译成"球形划分"。意思是:每个节点代表一个"球形区域"。
在二维空间中,它像一个圆:中心点 center = o3,半径 radius = r5,圆内包含若干对象。
在高维空间中,它不是圆,而是超球体 hypersphere。
你可以理解为:一个节点 = 一个以某个对象为中心、半径为 r 的数据区域
比如:N6 表示:以 o3 为中心,半径为 r5,覆盖 o3、o8 等对象。
这样做的好处是:查询时可以通过中心和半径判断某个区域是否可能包含近邻,从而剪枝。
3. 树节点 Node 和 Entry 再明确一下
node 是容器。entry 是 node 里面的一条记录。
比如图 3 中:N2 是一个 node,N2 里面有 e3、e4、e5 三个 entry
每个 entry 可以代表一个对象,也可以代表一个子区域。
4. 叶子 entry 和非叶子 entry 的区别
叶子 entry:叶子节点最底层,直接存真实对象。
例如:
Leaf node N6
├── entry: object o3
├── entry: object o8
└── entry: object ...这类 entry 的作用是保存真实数据对象。
非叶子 entry
非叶子节点中的 entry 不是直接存一堆真实对象,而是代表下面一个子树区域。
它通常包含:
center:这个子区域的中心
radius:这个子区域的半径
child pointer:指向下面的子节点
pd:该中心到父 entry 中心的距离例如图 3 里的 e5:
e5:
center = o3
radius = r5
child pointer → N6
pd = d(o3, o7)意思是entry e5 代表一个以 o3为中心、半径为 r5 的区域,这个区域的具体对象在子节点N6 里。
5. pd 是什么?
论文里 entry 会存一个 pd。pd 可以理解为:parent distance。
即当前 entry 的中心点到父 entry 中心点的距离。
e5 的 center 是 o3
父 entry e1 的 center 是 o7
所以 e5 的 pd = d(o3, o7)为什么要存这个?主要是为了查询和剪枝时减少重复距离计算。
在树索引里,很多剪枝判断都依赖三角不等式。提前存好某些中心距离,可以避免每次都重新计算。
汇报时不用深入讲三角不等式,只要说:
pd 是当前 entry 中心到父 entry 中心的距离,用于辅助树搜索中的距离计算和剪枝。
三、The Graph Index:图索引翻译
GTI 的图索引建立在树中紧邻叶子 entry 上方的一层节点 上,也就是图 3 中的 Level 1。论文中把叶子 entry 所在层称为 Level 0,所以 Level 1 就是叶子层的上一层。这个设计用于维护全局邻居关系,从而支持快速查询导航。
GTI 的图借鉴了先进图方法 HNSW 的层次结构:搜索从图的顶层开始,然后逐渐向底层深入。具体来说,图的顶层包含最少的顶点和最长的边;越往底层,边越短,顶点数量越多。上层中的顶点一定会出现在下层,最终底层包含所有图顶点。图是增量构建的。对于每个新顶点,随机选择一个整数 l,表示这个顶点最多属于多少层。比如 l=2 表示该顶点只出现在第 0 层和第 1 层。然后在每一层为所有顶点增量构建近邻图。通过对 l 使用指数衰减概率,图的期望层数可以达到对数级。已有研究证明,这种随机确定顶点最大层高的策略是有效的。
为了提高搜索质量,并缓解图顶点不完整可能导致的局部最优问题,图底层的每个顶点都会保存一个指向树中对应叶节点的指针。这个指针指向该图顶点对应的树 entry 的子节点。当搜索访问图底层的某个顶点时,算法会同时搜索图上的顶点以及该顶点对应的树叶节点中的对象,从而同时利用图中的全局邻居关系和树叶节点中的局部邻居关系。
例如图 3 中,图底层的顶点 o3 对应树 Level 1 中的 entry e5,并且有一个指针指向 e5 的子节点,也就是叶子节点 N6。当搜索访问到底层图中的顶点 o3时,也会通过这个指针访问 N6 中的对象。为了图示清晰,图 3 只画出了 o3 和 的指针,其他底层图顶点的指针被省略了。
此外,GTI 还维护了一个 in-degree radius table,入度半径表,用于存储每个顶点和其反向邻居之间的最大距离。这个表跨所有图层维护,用于支持图上的删除操作。比如图 3 中,o2 在不同图层中的反向邻居分别包括 o1,o7,o9,其中最大距离是 d(o2,o9)。
四、图索引详细讲解
1. GTI 的图建在哪里?
一句话:GTI 的图建在树的 Level 1 entries 上。不是建在所有真实对象上。
具体过程是:树 Level 1 entry 有 center,这些 center 被拿出来作为图顶点 v。
例如图 3 中:树 Level 1 中有 e3、e4、e5、e6、e7、e8 等 entry,它们的 center 分别是 o7、o2、o3、o6、o9、o1 等,这些 center 就成为图中的顶点。
所以图中的顶点看起来也是 o1,o2,o3,但注意:它们在图中代表的是 Level 1 entry 的中心,不是说所有原始对象都在图里。
2. 为什么要建在 Level 1?
因为 Level 1 很特殊。它在叶节点的上一层,每个 Level 1 entry 通常指向一个叶节点。
所以它既比全量对象少很多,又离真实对象很近。你可以理解为:
叶子节点:真实对象集合
Level 1 entry:这些对象集合的代表
图顶点:代表点之间的近邻关系这样做有两个好处:
第一,图规模小。因为图顶点数大约等于叶子节点数量,而不是对象数量。
第二,能访问真实对象。因为每个图顶点都有指针指向对应叶子节点。
3. GTI 图为什么不是普通单层图?
论文说它借鉴 HNSW,所以是多层图。
你可以想象成:
Graph Layer 2:少量代表点,边比较长,用于快速跳转
Graph Layer 1:更多代表点
Graph Layer 0:所有代表点,边比较短,用于精细搜索查询时:
先从顶层快速找大方向
再逐层向下精细搜索
最后到底层访问叶节点这个设计是为了兼顾速度和准确率。
4. "上层顶点一定包含在下层"是什么意思?
假设图有三层:
Layer 2: {o3}
Layer 1: {o3, o7, o9}
Layer 0: {o1, o2, o3, o6, o7, o9}如果一个顶点在 Layer 2 出现,那么它一定也在 Layer 1 和 Layer 0 出现。
这类似金字塔结构:
越上层,点越少
越下层,点越多
底层包含所有图顶点这样查询可以从粗到细。
5. 图顶点为什么要指向叶节点?
这是 GTI 的关键设计。因为图只覆盖 Level 1 代表点,不覆盖所有真实对象。如果图搜索只返回代表点,那不够。所以作者让每个底层图顶点指向它对应的叶节点。比如:
图顶点 o3 → 叶节点 N6
N6 里面有真实对象 o3、o8、...当搜索访问到 o3 这个图顶点时,它不只计算 o3 自己,还会进入 N6看里面的真实对象。这样 GTI 就能弥补轻量图覆盖不全的问题。
你可以把它理解成:
图负责找到哪个区域值得看
叶节点负责提供该区域内的真实对象6. 什么是 in-degree radius table?
这个概念后面删除算法会用到,现在先建立直觉。图中有边,比如:
o1 → o2
o7 → o2
o9 → o2那么对于 o2 来说,o1,o7,o9都是它的反向邻居,也就是有边指向 o2 的点。
删除 o2 时,不仅要删除 o2 指向别人的边,还要删除别人指向 o2 的边。
问题是:如果不专门存入边,想找到所有指向 o2 的点,就要遍历整个图,成本很高。
GTI 的办法是维护一个 入度半径表。它不存所有反向邻居,而是存:
每个顶点到其所有反向邻居的最大距离比如 o2 的反向邻居是:{o1, o7, o9}
其中最远的是 o9,那么:IRo2 = d(o2, o9)
删除 o2 时,就可以用树做一个范围查询:以 o2 为中心,半径 = IRo2。
这样找出来的候选集合里一定包含所有可能指向 o2 的反向邻居。这个设计是为了支持高效删除。
五、Figure 3 重点讲解:GTI 结构图怎么看?
Figure 3 是论文中非常重要的一张图,标题是 The structure of our proposed graph-based tree index, GTI。
这张图分成三部分:
左边:Data objects 和 Tree
右边:Graph
右下/表格:in-degree radius table1. 左边:Tree 部分
树有三层:
Level 2:根或更高内部节点
Level 1:GTI 建图所用的 entry 所在层
Level 0:叶子层,存真实对象图中 node capacity = 3,表示每个节点最多 3 个 entry。
其中 e5 是一个非叶子 entry:表示以 o3 为中心、半径 r5 的区域,下面的叶节点是 N6。
叶节点 N6 中有真实对象,比如 o3,o8 等。
2. 右边:Graph 部分
图建在 Level 1 的 entry centers 上。
例如:
e5 的 center = o3 → 图顶点 o3
e6 的 center = o6 → 图顶点 o6
e7 的 center = o9 → 图顶点 o9图是多层的:越上层顶点越少,越下层顶点越多。底层 Layer 0 包含所有图顶点。
3. 图顶点到叶节点的指针
图中画出了:
图顶点 o3 → 叶节点 N6
图顶点 o6 → 叶节点 N7意思是:当图搜索访问 o3 时,也会访问 N6里的真实对象。这就是 GTI 能够"图规模小但搜索不差"的关键。
4. in-degree radius table
图中右下角有一个表,记录每个图顶点的入度半径。
例如:
o2 : d(o2, o9)
o7 : d(o7, o9)对于顶点 o2,它所有反向邻居中最远的距离是 d(o2,o9)。这个表主要用于后面的删除操作。
你汇报 Figure 3 时可以这样讲:
图 3 展示了 GTI 的具体索引结构。左侧是树索引,树按照层次结构组织全量数据,其中 Level 0 为叶子层,存放真实数据对象;Level 1 中的 entry 代表对应叶节点的局部区域,每个非叶子 entry 包含中心点、覆盖半径以及指向子节点的指针。右侧是建立在 Level 1 entry centers 上的轻量级图索引。该图采用类似 HNSW 的多层结构,上层顶点较少、边较长,用于快速导航;底层包含所有图顶点,并且每个底层图顶点指向对应的树叶节点。这样,查询时可以先利用图进行全局导航,再通过指针访问叶节点中的真实对象。图中还维护了入度半径表,用于在删除图顶点时高效定位反向邻居。
六、4.2 这一节你需要记住的核心
GTI 的树负责全量数据组织,图负责 Level 1 代表点之间的全局导航,图底层顶点通过指针连接回真实数据所在的叶节点。
更具体地说:
Tree Index:
- 建在全量数据上
- 使用类似 M-tree 的球形划分
- node 里有 entries
- 非叶子 entry 有 center、radius、child pointer、pd
- 叶子 entry 存真实对象
Graph Index:
- 建在 tree Level 1 entries 的 center 上
- 使用 HNSW-like 多层图
- 底层图顶点指向对应叶节点
- 维护 in-degree radius table 支持删除七、这一节汇报时要重点讲什么?
如果你汇报时间有限,4.2 至少讲三个点。
第一,树索引结构:
GTI 使用类似 M-tree 的树结构,通过中心和半径形成嵌套超球体,对全量数据进行层次划分。
第二,图索引建在哪里:
GTI 不是在所有数据对象上建图,而是在树 Level 1 entries 的 center 上构建轻量级图,从而减少图顶点和边的数量。
第三,图和树如何连接:
图底层顶点保存指向对应叶节点的指针,因此查询时既能利用图的全局导航关系,也能访问叶节点中的真实对象,结合全局和局部近邻信息。
我的疑惑:
一、树索引里的"超球体"到底是什么意思?
1. 为什么用"球"来表示一个树节点?
GTI 的树结构类似 M-tree。M-tree 的思想是:用距离来组织对象。
一个节点或 entry 可以表示成:center = 中心对象,radius = 半径。
它覆盖的区域就是:所有距离 center 不超过 radius 的对象。
二维里你可以想象成一个圆,高维里它就是"超球体"。论文里也说,每个树节点可以看作由中心和半径定义的 hypersphere,叶节点对应较小的超球体,非叶节点对应更大的超球体。
2. 球里面的对象是不是"最接近的实体"?
不是严格意义上的"最接近"。
它更像是:这些对象被聚到同一个局部区域里,由同一个 center 和 radius 管理。
比如有一个 entry:center = o3、radius = r5、child → N6
意思是:N6 里面的对象都在 o3 附近,距离 o3 不超过 r5
但这不代表:N6 里面所有对象互相之间都是最近邻;也不代表查询 q 的最近邻一定在 N6;也不代表 N6 外面就没有比 N6 里面更近的对象。它只是一个空间组织结构。
3. 那这个球有什么用?
它的核心作用是:剪枝。比如查询点是 q,某个节点表示一个球:center = c,radius = r。
如果 q 离这个球很远,那么这个球里的所有对象都不太可能是最近邻。
直觉上:q 到 center 很远,球半径又不够大,那 q 到球里任何对象都不会太近。所以搜索时可以少看一些节点。
4. 树里的球是层层嵌套的
GTI 的树可以理解为大球套小球:
Level 2:大球,覆盖很多小区域
Level 1:中球,覆盖若干叶子节点
Level 0:小球/叶节点,覆盖真实对象所以你可以这样理解:
树索引不是直接告诉你答案,而是把全量数据组织成一层层局部区域,方便搜索和更新。
二、多层图到底是怎么来的?
GTI 的图是建立在树 Level 1 entries 的 center 上的;这些 center 作为图顶点,然后按照 HNSW 类似的随机分层策略形成多层图。
论文中说,GTI 借鉴 HNSW 的层次图结构:顶层顶点最少、边最长;越往底层,顶点越多、边越短;上层顶点一定出现在下层,底层包含所有顶点。
1. 为什么图会有多层?
多层图的直觉是:上层负责快速跳远,下层负责精细搜索。
类似地图导航。你从北京去上海,不会一开始就看小区道路。你会先看:高速/主干道 → 城市道路 → 街道 → 小区路
多层图也是这样:
上层图:点少,连接的是比较远的代表点,负责快速确定方向
下层图:点多,连接的是更局部的近邻,负责精细搜索2. "上面的边长,下面的边短"是什么意思?
这里的"边长"不是画图上的线长,而是指:边连接的两个顶点在向量空间中的距离。
假设图里有一些点:o1, o2, o3, o4, ..., o1000
在上层,因为点很少,能连的点也少,所以两个相邻顶点可能距离比较远。
在底层,点很多,每个点可以找到更近的邻居,所以边通常连接局部近邻。
上层边长 = 跨区域跳转
下层边短 = 局部精细查找3. 多层图是怎么构建出来的?
假设树 Level 1 一共有 1000 个 entry center。
这些 center 都会成为图底层 Layer 0 的顶点:Layer 0:1000 个顶点
然后构建图时,每个顶点会被随机分配一个最高层数。比如:
o1 最高到 Layer 0
o2 最高到 Layer 0
o3 最高到 Layer 2
o4 最高到 Layer 1
o5 最高到 Layer 0
...如果 o3 的最高层是 Layer 2,那么它会出现在:
Layer 2
Layer 1
Layer 0如果 o4 的最高层是 Layer 1,那么它会出现在:
Layer 1
Layer 0如果 o5 的最高层是 Layer 0,那么它只出现在:
Layer 0所以最终形成类似金字塔:
Layer 2:很少的点
Layer 1:更多点
Layer 0:所有点这就是多层图的来源。
4. 为什么上层点少、下层点多?
因为每个顶点进入更高层的概率比较低。
可以理解为随机抽样:
所有点都在 Layer 0
一部分点被抽到 Layer 1
更少一部分点被抽到 Layer 2
极少数点被抽到 Layer 35. 那上层点少,会不会漏掉近邻?
上层不是用来最终返回答案的。它只是用来快速找到一个好的方向或入口。真正候选结果主要在底层 Layer 0 里找。
搜索过程大概是:
先在最高层粗略找接近 q 的点
↓
拿这个点作为下一层入口
↓
在下一层继续找更近的点
↓
到底层后展开更多邻居
↓
再访问对应叶节点中的真实对象所以多层图的作用是加速导航,不是每一层都要包含完整答案。
三、GTI 里的"多层图"和"树 Level 1"怎么对应?
这是最容易混的点。你可以这样分开:
树 Level 1:决定图顶点来自哪里
图 Layer 0/1/2:决定这些顶点如何分层导航假设树 Level 1 entries 的 center 一共有 1000 个:
v1, v2, ..., v1000那么 GTI 用这些点建图:
Graph Layer 2:少量 v
Graph Layer 1:更多 v
Graph Layer 0:全部 1000 个 v注意:图的每个顶点都是树 Level 1 entry 的 center。
底层图顶点再指向对应叶节点:
v17 → Leaf N17
v28 → Leaf N28这样查询时:
先在多层图上快速找到接近 q 的代表点
再通过代表点进入叶节点
再在叶节点里看真实对象四、需不需要先看索引构建部分才能理解?
索引构建部分会帮助理解"多层图怎么建出来",但在看构建算法前,你至少要先有现在这个直觉。
也就是说:现在先理解这三句话就够了:
1. 树里的球是数据区域,不是最终答案。
2. GTI 的图顶点来自树 Level 1 entry 的 center。
3. 多层图是为了从粗到细导航:上层点少边长,下层点多边短。然后再看 4.3 Index Construction,你就会明白算法为什么是:
先构建树
取出 Level 1 entries
把每个 entry 的 center 插入图
每个图顶点指向对应叶节点五、用一个小例子把树和图串起来
假设有 100 个真实对象。树先把它们分成 10 个叶节点:
Leaf N1: 10 个对象
Leaf N2: 10 个对象
...
Leaf N10: 10 个对象每个叶节点上面有一个 Level 1 entry 代表它:
e1: center=o3, child→N1
e2: center=o15, child→N2
...
e10: center=o92, child→N10GTI 拿这些 center 建图:
图顶点:o3, o15, ..., o92如果是多层图,可能长这样:
Layer 2: o3
Layer 1: o3, o45, o92
Layer 0: o3, o15, o27, o38, o45, o56, o63, o70, o81, o92查询 q来了:
先在 Layer 2 找方向
↓
到 Layer 1 找更近的代表点
↓
到 Layer 0 找几个最近的代表点
↓
通过这些代表点进入叶节点
↓
在叶节点里的真实对象中找最终候选所以 GTI 不是直接在 100 个真实对象上建图,而是在 10 个叶节点代表点上建图。
六、你可以这样向老师解释这部分
GTI 的树索引采用类似 M-tree 的球形划分思想,每个非叶子 entry 可以看作由中心点和半径定义的高维超球体,用来覆盖其子节点中的一组对象。因此,这里的超球体并不表示其中对象一定都是全局最近邻,而是表示一个局部数据区域,便于后续查询时进行空间组织和剪枝。GTI 随后从树的 Level 1 entries 中取出 center 作为图顶点,构建轻量级图索引。该图采用类似 HNSW 的多层结构:上层顶点较少,边通常跨越较大距离,用于快速全局导航;下层顶点更多,边更局部,用于精细搜索。最终,底层图顶点会指向对应的叶节点,使查询可以先通过图定位相关区域,再进入叶节点访问真实对象。
4.3 Index Construction:索引构建。这一节回答的是:
GTI 这个"树 + 图"的索引,具体是怎么一步一步建出来的?
这一节的核心对应 Algorithm 1: Index Construction。你需要重点理解三步:
第一步:对所有数据对象建树;
第二步:取出树 Level 1 的 entries;
第三步:把这些 entries 的 center 插入图,并让图顶点指向对应叶节点。4.3 Index Construction 原文翻译
图索引可以加速近似最近邻搜索,但构建成本较高,并且需要大量内存来存储邻居关系。已有一些优化技术,比如优化图结构、使用并行化,以及利用树划分信息,能够缓解计算开销。然而,由于图通常需要索引整个数据集,因此高空间成本的问题仍然存在。
与已有方法直接索引每一个数据对象不同,本文方法首先使用树索引对数据集进行层次化划分,然后只基于树 Level 1 的节点构建图索引。这样可以同时降低时间成本和空间成本。在图构建过程中,GTI 还维护一个入度半径表,用于支持后续高效索引维护。此外,为了提高索引搜索质量,GTI 会从图顶点添加指向树叶节点的指针。
Algorithm 1 给出了 GTI 索引构建过程。算法的输入包括对象集合 O、树节点容量 Nc,以及图稀疏度 m。其中,m 控制图中每个顶点最多保留多少邻居。算法输出 GTI 索引 I。
首先,算法初始化 GTI 索引,其中包括树索引和图索引。随后,它按照 M-tree 的插入操作依次将所有数据对象插入树索引,从而对整个数据集进行层次化划分。M-tree 是已有研究中表现较好的树索引方法之一。
接下来,算法在树 Level 1 的 entries 上构建图索引。首先取出树 Level 1 中的所有 entries,并初始化一个空的入度半径表。随后,对于每一个 Level 1 entry,算法将该 entry 的 center 作为图顶点增量插入图中。类似 HNSW 方法,顶点会被插入到图的不同层中,并且采用自顶向下的图搜索为每个顶点在相应层中寻找邻居。图中上层每个顶点最多有 m个邻居,底层每个顶点最多有 2m 个邻居。与此同时,算法同步记录每个顶点最大入边距离,并将其存入入度半径表,以支持后续高效更新。随后,在图的底层中,为每个顶点添加一个指针,使其指向该 entry 对应的树叶节点。最后,算法返回树索引和图索引,共同构成最终的 GTI 索引。
Algorithm 1 逐步讲解
输入是什么?
Algorithm 1 的输入有三个:
O:对象集合,也就是全部数据对象
Nc:树节点容量
m:图稀疏度1. O:对象集合
就是所有高维向量。比如:O = {o1, o2, o3, ..., on}。每个 oi 都是一个数据对象,可能是一张图片的向量、一段文本的 embedding,或者一个商品向量。
2. Nc:树节点容量
Nc 控制一个树节点最多能放多少 entry。比如 Nc=3,就表示一个 node 最多放 3 个 entry。论文 Figure 3 中就是用 node capacity = 3 做示意。
你可以理解为:
Nc 越大:每个节点能放更多 entry,树可能更矮
Nc 越小:每个节点能放更少 entry,树可能更高3. m:图稀疏度
m 控制每个图顶点最多连接多少邻居。比如 m=16,可以理解为每个图顶点在上层最多连接 16 个邻居。论文中说,图上层每个顶点最多有 m 个邻居,底层最多有 2m 个邻居。
你可以理解为:
m 越大:图更稠密,搜索可能更准,但索引更大、构建更慢
m 越小:图更稀疏,索引更轻,但搜索质量可能下降所以 m 是一个控制图规模和搜索质量之间平衡的参数。
输出是什么?
输出是 GTI 索引 I。它由两部分组成:I = IT ∪ IG。其中:
IT:Tree Index,树索引
IG:Graph Index,图索引也就是说,最后得到的是一个混合索引,而不是单独的树或单独的图。
Algorithm 1 的整体流程
伪代码可以分成三大阶段。
阶段一:初始化树和图
伪代码第 1 行:IT ← ∅, IG ← ∅
意思是:先创建一个空的树索引 IT 和一个空的图索引 IG。此时索引还没有任何数据。
阶段二:把所有对象插入树
伪代码第 2 到 4 行:
foreach oi ∈ O do
create leaf entry e
e.center ← oi
e.pd ← ∞
InsertTree(IT, e, Nc)这一段意思是:遍历数据集中的每一个对象 oi,把它包装成一个 leaf entry,然后插入树索引。
这里注意两个点。
1. 为什么要 create leaf entry?
因为树里面存的不是裸对象,而是 entry。对于真实对象 oi,需要先创建一个叶子 entry:
e.center = oi
e.pd = ∞然后把这个 entry 插入树。
你可以理解为:真实对象 oi → 包装成树里的 leaf entry → 插入树
2. 为什么 pd=∞?
这里的 pd 是当前 entry 到父 entry 中心的距离。
刚创建 leaf entry 时,它还没有被真正放到树中的某个位置,所以暂时不知道父 entry 是谁,也就不知道 parent distance。
因此先设为 ∞,后续插入树时再更新。
3. InsertTree 做什么?
InsertTree(IT, e, Nc) 就是把 entry 插入树。它遵循 M-tree 的插入逻辑,大致包括:
从根节点开始,找到合适的子节点;
一路向下找到叶子节点;
把新对象插入叶子节点;
如果节点超过容量 Nc,则进行节点分裂;
必要时向上调整父节点 entry 的中心和半径。这一步完成后,所有对象都被组织进树结构中。
所以到第 4 行结束时:
树索引 IT 已经建好了;
全量数据都在树里;
树已经形成 Level 0、Level 1、Level 2... 的层次结构。阶段三:取出 Level 1 entries,建立图
伪代码第 5 行:E ← entries in Level 1 of IT
意思是:从已经建好的树索引中,取出 Level 1 的所有 entries。这些 entries 就是后面建图的基础。
Level 1 entries 是什么?
Level 1 中的 entry 通常指向 Level 0 的叶节点。
所以 Level 1 entries 可以理解为:每个叶子节点区域的代表点集合
阶段四:初始化入度半径表
伪代码第 6 行:IR ← ∅
这里 IR 是 in-degree radius table,也就是入度半径表。
它用于记录:每个图顶点到其反向邻居的最大距离。
这个表主要服务后面的删除操作。现在先空着,随着图构建逐渐填入。
阶段五:把 Level 1 entry center 插入图
伪代码第 7 到 10 行:
foreach ei ∈ E do
v ← ei.center
leaf ← ei.child
InsertGraph(IG, v, IR, m)
add pointer from v to leaf这一段是 GTI 图索引构建的核心。
对于每一个 Level 1 entry ei:
第一,取它的 center:v = ei.center,这个 center 成为图顶点。
第二,取它指向的叶节点:leaf = ei.child
第三,把 v 插入图:InsertGraph(IG, v, IR, m)
第四,给图底层的 v 添加指针:v → leaf
这一步到底做了什么?
假设 Level 1 有三个 entry:
e1: center=o3, child=N6
e2: center=o6, child=N7
e3: center=o9, child=N8那么 GTI 会做:
把 o3 插入图,并让图顶点 o3 指向叶节点 N6
把 o6 插入图,并让图顶点 o6 指向叶节点 N7
把 o9 插入图,并让图顶点 o9 指向叶节点 N8最终得到:
Graph vertex o3 → Leaf N6
Graph vertex o6 → Leaf N7
Graph vertex o9 → Leaf N8这个指针是 GTI 能够访问真实对象的关键。
因为图只包含代表点,不包含所有对象。
通过指针,查询时才能进入叶节点,看里面的真实对象。
InsertGraph 里面大概发生什么?
这里论文没有在 Algorithm 1 展开 InsertGraph 的全部细节,但它说类似 HNSW。
你可以理解为:
给新顶点 v 随机分配最高层;
从图的最高层开始搜索;
逐层找到 v 在该层应该连接的邻居;
把 v 插入对应层;
更新邻接边;
更新入度半径表 IR。例如 v=o3,随机最高层是 2:
o3 会出现在 Layer 0, Layer 1, Layer 2如果 v=o6,随机最高层是 1:
o6 会出现在 Layer 0, Layer 1如果 v=o9,随机最高层是 0:
o9 只出现在 Layer 0这就是多层图逐步形成的过程。
Algorithm 1 最后返回什么?
伪代码第 11 行:return IT ∪ IG。意思是返回树索引和图索引的组合。也就是最终 GTI:
GTI = Tree Index + Graph Index其中:
Tree Index:覆盖全量数据
Graph Index:建立在树 Level 1 entries 的 center 上
Graph bottom layer pointers:连接图顶点和树叶节点
IR table:辅助后续删除更新4.3 的关键思想
这一节最重要的不是每一行伪代码,而是构建顺序:先建树,再建图。
为什么必须先建树?因为 GTI 的图顶点来自树的 Level 1 entries。
如果树都没有建好,就不知道 Level 1 entries 是哪些,也就不知道哪些点要进入图。
所以构建顺序一定是:
全量对象 → 建树 → 提取 Level 1 entries → 建图 → 添加叶节点指针用一个小例子完整走一遍
假设有 12 个对象:O = {o1, o2, ..., o12}。树节点容量 Nc=4。
第一步:建树
GTI 把 12 个对象插入树,可能形成 3 个叶节点:
N4: [o1, o2, o3, o4]
N5: [o5, o6, o7, o8]
N6: [o9, o10, o11, o12]然后 Level 1 有 3 个 entry:
e1: center=o2, radius=r1, child=N4
e2: center=o6, radius=r2, child=N5
e3: center=o10, radius=r3, child=N6第二步:取 Level 1 entries
E = {e1, e2, e3}第三步:把 centers 插入图
取出 center:
e1.center = o2
e2.center = o6
e3.center = o10所以图顶点是:
v1 = o2
v2 = o6
v3 = o10然后在这些点之间建立近邻关系:
o2 ------ o6 ------ o10真实图可能是多层的,但直觉上就是让这些代表点之间建立邻居连接。
第四步:添加指针
o2 → N4
o6 → N5
o10 → N6查询时,如果图搜索访问到 o6,就可以进入 N5 查看:
[o5, o6, o7, o8]所以最后 GTI 的结构是:
树:存全部 12 个真实对象
图:只存 3 个代表点
指针:代表点连接到对应叶节点这就是 GTI "轻量"的核心。
为什么这样能降低构建成本?
传统图索引:12 个对象 → 12 个图顶点
GTI:12 个对象 → 3 个叶节点 → 3 个 Level 1 representative centers → 3 个图顶点
如果数据量是 100 万:
传统图:100 万个图顶点
GTI 可能是:1 万个 Level 1 centers 作为图顶点
图的构建成本和存储成本就明显下降。
为什么还要维护入度半径表?
这是为了后面的删除。插入图顶点时,系统会产生邻接边。比如:o2 → o6,o10 → o6
这意味着 o6 有反向邻居 o2 和 o10。如果以后要删除 o6,需要知道哪些点指向它。但如果直接保存所有入边,空间成本会变大。所以 GTI 只保存一个"最大入度半径":
IR[o6] = max(d(o6,o2), d(o6,o10))以后删除 o6时,可以以 o6 为中心、IRo6 为半径,在树上做范围搜索,找出可能的反向邻居。
这就是入度半径表的作用。
Algorithm 1 汇报时怎么讲?
你可以这样讲:
在索引构建阶段,GTI 采用"先建树、再建图"的流程。具体来说,算法首先初始化树索引和图索引,并将数据集中的所有对象依次作为 leaf entry 插入树索引,从而利用类似 M-tree 的结构对全量数据进行层次化划分。随后,算法取出树 Level 1 层的所有 entries,并将每个 entry 的 center 作为图顶点插入轻量级图索引中。图构建过程类似 HNSW,会为顶点建立多层近邻关系,同时维护入度半径表以支持后续删除操作。最后,GTI 在图底层顶点和对应树叶节点之间建立指针,使查询过程能够先通过图进行全局导航,再访问叶节点中的真实对象。因此,GTI 避免了在全量对象上建图,从而显著降低图构建和存储成本。
4.3 你需要重点记住什么?
这一节你真正需要掌握四句话:
1. GTI 先对所有对象建立树索引。
2. 然后取树 Level 1 entries 的 center 作为图顶点。
3. 图顶点插入 HNSW-like 多层图,并维护入度半径表。
4. 每个底层图顶点指向对应叶节点,使图搜索能够访问真实对象。最核心的一句话是:
GTI 不是对全量数据建图,而是先通过树聚合数据,再只对 Level 1 的代表点建轻量图。
当我们说:InsertGraph(IG, v, IR, m).意思不是简单地把 v 放进去就结束。
它还要做一件关键事情:**给这个新顶点 vvv 找邻居,并建立连接边。**这个过程大致是:
新顶点 v 进来
↓
在已有图中搜索和 v 比较近的候选顶点
↓
从候选顶点中选出最多 m 个近邻
↓
把这些近邻作为 v 的 graph neighbors
↓
在图中添加边所以边是由"近邻选择"产生的。
HNSW 类方法在实现中会维护邻接关系,并可能对已有邻居的连接进行更新或修剪,但论文这里没有展开 InsertGraph 的具体细节,所以我们不能武断说它一定会同步添加反向边。
这篇论文更关心的是:图中存在入边和出边,删除时需要处理两类边。
GTI 的图边是在 InsertGraph 插入每个 Level 1 entry center 时,通过图搜索找到候选近邻,再从候选近邻中选择若干个点作为邻居而产生的。边在维护上可以理解为有方向的邻接关系:u→v 表示 v在 uu 的邻居列表里;因此 u→vu \to vu→v 不必然意味着 v→uv \to uv→u。正因为入边不容易直接找到,GTI 才维护 in-degree radius table 来支持删除。
在图构建过程中,GTI 并不是简单地将 Level 1 entry 的 center 加入图中,而是在每次插入新图顶点时,采用类似 HNSW 的增量建图方式。具体来说,算法会先在已有图中搜索与新顶点接近的候选邻居,再根据图稀疏度参数 (m) 从候选集合中选择若干邻居,并建立邻接边。这里的边可以理解为有方向维护的邻接关系,即 (u \to v) 表示 (v) 被保存在 (u) 的邻居列表中,但这并不必然意味着 (v \to u) 同时存在。由于删除某个顶点时不仅要删除它指向其他顶点的出边,还要删除其他顶点指向它的入边,而入边不容易直接定位,所以 GTI 在构建图时同步维护入度半径表,用于后续通过树的范围查询快速找到可能的反向邻居。
4.4 Index Updating:索引更新 。这一节非常重要,因为它对应 GTI 的核心卖点之一:支持动态插入和删除,并实现平均对数级更新复杂度。
这一节分两部分:
Object Insertion:对象插入,对应 Algorithm 2
Object Deletion:对象删除,对应 Algorithm 34.4 Index Updating 开头部分翻译
在真实应用场景中,数据插入和删除非常频繁。已有图方法往往难以处理这些动态更新,因为它们依赖维护全局导航关系。例如,阿里巴巴淘宝电商平台中集成的图方法 NSG 就面临动态更新困难的问题。虽然一些图方法可以通过增量构建支持数据插入,但它们通常难以处理数据删除,例如商品下架这类场景。虽然懒更新或周期性重建策略可以同时处理数据插入和删除,但重建成本仍然是一个明显限制。
GTI 结合了树结构和图结构的优势,使其能够灵活支持数据插入和删除,同时在更新后仍然保持较好的图查询性能。GTI 的更新过程包括两个部分:树索引更新 和图索引更新。树索引更新较为高效,因为它只需要调整受影响的局部节点。对于图索引更新,作者设计了高效的数据更新算法,并利用树结构的精确搜索能力辅助图更新。由于 GTI 的图索引不是建立在整个数据集上,而是只建立在树 Level 1 entries 上,因此图更新操作相对轻量。因此,GTI 的索引更新复杂度相对于树更新保持在对数级。
这一段先讲什么?
这一段的核心是:GTI 把更新拆成两层:先更新树,再看是否需要更新图。
也就是说,GTI 不会每次插入或删除对象都直接大规模改图。
它的更新逻辑是:
对象变化
↓
先更新树
↓
如果树 Level 1 没变化,图不动
↓
如果树 Level 1 发生变化,才更新图这就是 GTI 更新快的关键。
为什么传统图索引更新难?
因为图索引中每个点都和其他点有邻接关系。
插入一个点时,要考虑:
新点应该连向谁?
已有点是否应该连向新点?
图的导航结构是否仍然合理?删除一个点时更麻烦,要考虑:
删除这个点本身
删除它指向别人的边
删除别人指向它的边
修复受影响节点的邻居关系所以图方法如果直接在全量数据对象上建图,更新代价会很高。
GTI 的策略是:不要把所有真实对象都放进图,只把树 Level 1 的代表点放进图。
这样普通对象变化时,通常只影响树叶节点,不影响图。
Object Insertion:对象插入翻译
对象插入 GTI 时,需要同时考虑树插入和图插入。当一个新对象到来时,它首先被插入树索引。如果这次插入触发了树节点分裂,也就是说树的 Level 1 中新增了一个 entry,那么图索引也必须相应更新。
Algorithm 2 给出了将新对象 ooo 插入 GTI 索引的过程。算法输入包括待插入的新对象 o 和当前 GTI 索引 I,输出是更新后的 GTI 索引 I。
首先,算法将新对象插入 GTI 的树索引中。然后,算法判断是否需要更新图索引。如果对象 o 的插入导致树的叶节点分裂,并在 Level 1 中产生了新的 entry,那么 GTI 会同步执行图插入。具体来说,它先获取图索引信息,包括图 IG、入度半径表 IR 和图稀疏度 m。然后,将新 entry 的 center 作为新顶点插入图中,方式类似 HNSW。接着,在图底层新顶点和新 entry 对应的子叶节点之间添加指针。需要注意的是,论文采用 M-tree 中的 M_LB_DIST 节点分裂策略,以保证每次节点分裂只会在上一层产生一个新的 entry。如果插入没有导致叶节点分裂,那么树的 Level 1 不发生变化,图索引也不需要更新。最后,算法返回更新后的 GTI 索引。
Algorithm 2:对象插入逐步讲解
Algorithm 2 的输入是:新对象 o,当前 GTI 索引 I
输出是:更新后的 GTI 索引 I
情况一:插入对象后,叶节点没有分裂
叶节点还没满,所以树结构没有变化。这时:
树更新完成
Level 1 entry 没有变化
图不需要更新也就是说,GTI 只做了一次树插入。
情况二:插入对象后,叶节点发生分裂
假设某个叶节点最多能放 10 个对象,现在已经满了:
Leaf N6:
[o1, o2, o3, o4, o5, o6, o7, o8, o9, o10]现在插入新对象 onew。叶节点装不下了,就要分裂。
这时,树的上一层 Level 1 需要新增一个 entry 来指向新的叶节点。
因为 GTI 的图顶点来自 Level 1 entry 的 center,所以新增了 e_{new},图里也要新增一个顶点:v_new = e_new.center = o8
然后执行:InsertGraph(IG, v_new, IR, m),也就是把 o8 插入图,并为它建立邻接边。
最后还要加指针:图底层顶点 o8 → 叶节点 N6b
Algorithm 2 每一行在做什么?
第 1 行:取出树索引信息
IT, Nc ← tree index information from I意思是:从 GTI 索引 I 中取出树索引 IT 和树节点容量 Nc。因为插入对象首先要更新树。
第 2 行:创建 leaf entry
create leaf entry e
e.center ← o
e.pd ← ∞意思是:把新对象 ooo 包装成一个叶子 entry。这里的 pd=∞pd = \inftypd=∞ 是临时值,因为还没有插入树,不知道它的父 entry 是谁。
第 3 行:插入树
InsertTree(IT, e, Nc)意思是:按照 M-tree 的插入规则,把新 entry 插入树索引。这一步可能只是普通插入,也可能导致节点分裂。
第 4 行:判断是否发生叶节点分裂
if insertion of e leads to leaf node split then这行是整个插入算法的关键。如果叶节点没有分裂:
算法直接结束
图不用动如果叶节点分裂:
说明 Level 1 多了新 entry
图必须同步更新第 5 行:取出图索引信息
IG, IR, m ← graph index information from I如果需要更新图,就取出:
IG:图索引
IR:入度半径表
m:图稀疏度第 6 行:找到新 Level 1 entry 的 center
v ← center of the new entry in IT's Level 1叶节点分裂后,Level 1 会产生一个新 entry。这个新 entry 有自己的 center。算法把这个 center 作为新图顶点 vvv。
第 7 行:插入图
InsertGraph(IG, v, IR, m)这一步就是我们刚才讨论过的图插入:
给 v 随机分层
在已有图中找候选近邻
选出邻居
添加邻接边
更新入度半径表第 8 行:添加图顶点到叶节点的指针
add pointer from bottom-layer v to new entry's child leaf node这是 GTI 的关键连接。因为 v 是新 Level 1 entry 的 center,而这个 entry 指向某个叶节点。
所以图底层顶点 v 要指向这个叶节点。这样以后查询访问到 v 时,可以进入对应叶节点看真实对象。
第 9 行:返回更新后的 GTI
return IT ∪ IG返回更新后的树和图。
这一节最重要的理解
GTI 插入算法的重点不是"每次插入都更新图",而恰恰相反:
大多数情况下,插入只更新树;只有叶节点分裂导致 Level 1 新增 entry 时,才更新图。
这也是它能动态更新快的原因。
为什么插入复杂度可以低?
因为普通插入只是在树中找路径,然后插入叶节点。
树的高度通常是对数级,所以树插入大约是:
O(log n)只有少数情况下叶节点分裂,才需要插入图顶点。
而 GTI 的图又很小,因为它只建在 Level 1 entries 上,不是全量对象图。所以整体平均更新成本较低。
这一部分汇报时可以这样讲
在对象插入过程中,GTI 首先将新对象作为 leaf entry 插入树索引。如果该插入没有导致叶节点分裂,则树的 Level 1 结构不发生变化,因此图索引不需要更新。只有当叶节点分裂,并在 Level 1 中产生新的 entry 时,GTI 才会将该新 entry 的 center 作为新图顶点插入图索引,并在图底层顶点和对应新叶节点之间建立指针。也就是说,GTI 将大部分对象插入操作限制在树结构内部,只有在树的代表层发生变化时才更新轻量级图索引,从而降低动态图维护成本。
你这一节需要记住的核心
GTI 插入 = 先插树,再看是否需要插图具体来说:
普通插入:
对象进入已有叶节点 → Level 1 不变 → 图不变
分裂插入:
叶节点分裂 → Level 1 新增 entry → 图新增顶点 → 添加指针GTI 删除对象时,先从树中删除;只有当删除导致树的 Level 1 entry 被移除时,才需要同步删除图中的对应顶点。
Object Deletion 原文翻译
GTI 中对象删除包含两个主要过程:树删除 和图删除。
首先,算法需要定位并从树索引中高效删除目标对象。如果这次删除导致树节点发生下溢,例如树 Level 1 中某个 entry 被移除,那么就需要更新图索引。
当图中的一个顶点需要被删除时,算法需要删除该顶点以及它在所有图层中的入边和出边。删除出边比较直接,因为出边直接保存在图的邻接表中。但是,删除入边更复杂,因为入边数量可能较大且不固定。如果直接保存所有入边,会造成较大的空间开销;如果为了找入边而遍历所有图顶点,又会非常耗时。
为了解决这个问题,作者设计了一种高效图删除算法。该算法利用入度半径表中保存的每个顶点的最大入边距离,并结合树上的范围查询,高效定位并删除所有反向邻居,从而准确删除相关边。
先解释这一段的核心问题
插入比较简单,因为插入一个新对象通常只影响一个叶节点。
但删除难在两点:
第一,要先找到这个对象是否存在。
第二,如果删除影响到了 Level 1 entry,就要删图顶点;而删图顶点不仅要删它自己的出边,还要删别人指向它的入边。
Algorithm 3 输入和输出
Algorithm 3 的输入是:
o:要删除的对象
I:当前 GTI 索引
ef:搜索参数输出是:
更新后的 GTI 索引 I这里的 ef 是近似搜索中的搜索参数,后面第 5 节会详细讲。你现在可以先理解为:
ef 控制近似搜索时保留多少候选,通常 ef 越大,搜索越准但越慢。
Algorithm 3 整体流程
Algorithm 3 可以分成五个阶段:
第一步:取出树和图的信息
第二步:先尝试用近似搜索找到要删除的对象
第三步:如果近似搜索没找到,再用树的精确范围查询确认
第四步:从树里删除对象
第五步:如果树删除导致 Level 1 entry 被移除,再更新图我们一步一步讲。
第一阶段:取出树和图信息
伪代码第 1--2 行:
IT ← tree index information from I
IG, IR, m ← graph index information from I意思是:从 GTI 索引里取出:
IT:树索引
IG:图索引
IR:入度半径表
m:图稀疏度因为删除可能涉及树,也可能涉及图,所以两个部分的信息都要拿出来。
第二阶段:先用近似搜索找对象
伪代码第 3 行:
o′ ← AkNNSearch(o, I, ef, 1)这里做了一件有点特别的事:
把要删除的对象 o 当作查询对象,做一次 approximate 1-NN search。
也就是说,算法先问:
在 GTI 中,离 ooo 最近的 1 个对象是谁?
如果 ooo 本身存在于索引中,那么理论上最近的对象应该就是 ooo 自己,因为距离:
d(o,o)=0d(o,o)=0d(o,o)=0
所以算法先用近似搜索快速定位目标对象。
为什么不用一开始就精确查找?
因为近似搜索通常更快。
GTI 本身有图索引,图搜索速度较高。
所以作者先尝试用近似搜索定位对象:
如果找到 o,直接删除
如果没找到,再用精确方法兜底这是一种效率优先的策略。
论文也说明,算法优先使用 AkkkNN search 来定位目标对象,因为它比精确范围搜索性能更好。
第三阶段:如果近似搜索没找到,用树精确确认
伪代码第 4 行:
if o′ ≠ o then o′ ← RangeSearchT(o, 0, IT)意思是:
如果近似搜索返回的 o′o'o′ 不是要删除的 ooo,说明近似搜索没有准确找到目标对象。
这时算法用树索引做一次精确范围查询:
查询中心 = o
查询半径 = 0也就是找所有满足:
d(o,x)≤0d(o,x) \le 0d(o,x)≤0
的对象。
在一般距离函数下,只有 x=ox=ox=o 时距离才是 0。
所以半径为 0 的范围查询相当于:
精确查找对象 ooo 是否存在。
第四阶段:如果还没找到,说明对象不存在
伪代码第 5 行:
if o′ ≠ o then return I意思是:
如果近似搜索没找到,树上的半径 0 范围查询也没找到,那说明要删除的对象 ooo 不在索引里。
这时直接返回原索引,不做任何修改。
第五阶段:从树中删除对象
伪代码第 6 行:
DeleteTree(o′, IT)如果确认找到了对象 ooo,就先从树索引中删除它。
这一步按照 M-tree 的删除规则执行。
注意:GTI 删除对象时,永远先删树。
因为真实对象存放在树的叶节点里,而图里只存 Level 1 entry 的 center。
删除树之后,有两种情况
情况一:删除后叶节点没有下溢
比如某个叶节点原来有 8 个对象:
N6: [o1, o2, o3, o4, o5, o6, o7, o8]删除 o8o8o8 后:
N6: [o1, o2, o3, o4, o5, o6, o7]这个叶节点仍然满足最小容量要求,没有下溢。
那么:
Level 1 entry 不变
图不需要更新算法就结束。
情况二:删除导致叶节点下溢或为空
比如某个叶节点原来只有一个对象:
N6: [o3]删除 o3o3o3 后:
N6: []这个叶节点空了,可能要被删除。
如果叶节点被删除,那么它的父层 Level 1 中对应的 entry 也要被删除。
比如原来:
e5: center=o3, child→N6现在 N6N6N6 不存在了,e5e5e5 也要移除。
由于 GTI 的图顶点就是 Level 1 entry 的 center,所以图中的顶点 o3o3o3 也要删除。
这就是为什么只有特定情况下才需要图删除。
第六阶段:判断是否需要更新图
伪代码第 7 行:
if deletion of o′ leads to leaf node underflow then这一行是删除算法的关键判断。
如果删除没有导致叶节点下溢:
图不变如果导致叶节点下溢,并且 Level 1 entry 被删掉:
图中对应顶点也要删除第七阶段:找到要删除的图顶点
伪代码第 8 行:
v ← center of the deleted entry in IT's Level 1意思是:
找到被删除的 Level 1 entry 的 center。
这个 center 就是图中的顶点 vvv。
比如:
被删除的 entry e5:
center = o3
child → N6那么:
v = o3图里要删除的就是顶点 o3o3o3。
第八阶段:删除图顶点到叶节点的指针
伪代码第 9 行:
delete pointer to v's leaf node from bottom-layer of the graph因为 vvv 对应的叶节点已经被删除或调整了,所以图底层中 vvv 指向该叶节点的指针也要删掉。
比如原来:
图顶点 o3 → 叶节点 N6现在 N6N6N6 没了,所以要删除这个指针。
第九阶段:用入度半径表找到反向邻居候选
伪代码第 10 行:
C ← RangeSearchT(v, IR[v], IT)这一步非常关键,也是 Algorithm 3 最难理解的地方。
它的意思是:
在树上做一个范围查询:
查询中心 = v
查询半径 = IR[v]其中 IRvIRvIRv 是入度半径表中记录的:
所有指向 v 的反向邻居里,距离 v 最远的那个距离所以这个范围查询返回的候选集合 CCC,理论上会包含所有可能指向 vvv 的反向邻居。
为什么这样能找到反向邻居?
假设图里有这些边:
o1 → v
o7 → v
o9 → v那么 o1,o7,o9o1,o7,o9o1,o7,o9 是 vvv 的反向邻居。
入度半径表记录:
IR[v] = max(d(v,o1), d(v,o7), d(v,o9))假设最远的是 o9o9o9,那么:
IR[v] = d(v,o9)现在以 vvv 为中心、IRvIRvIRv 为半径做范围查询,那么:
o1, o7, o9 都一定在这个范围内所以可以把它们找出来。
第十阶段:从候选集合里筛出真正反向邻居
伪代码第 11 行:
N ← reserve neighbors of v in C这里原文应是 reverse neighbors,也就是反向邻居。
意思是:
范围查询得到的 CCC 只是候选集合,里面可能包含很多不是反向邻居的对象。
所以还要检查它们的邻接表,筛出真正有边指向 vvv 的点。
比如范围查询得到:
C = {o1, o2, o7, o8, o9}但真正有边指向 vvv 的只有:
N = {o1, o7, o9}那么 NNN 就是后面删除图边时需要用到的反向邻居集合。
第十一阶段:删除图顶点和相关边
伪代码第 12 行:
DeleteGraph(IG, N, v, IR, m)这一步要做的事情包括:
删除顶点 v
删除 v 指向别人的出边
删除别人指向 v 的入边
更新入度半径表 IR
可能标记一些受影响顶点需要修复其中:
出边容易删,因为 vvv 自己的邻接表里就有。
比如:
v → o2
v → o6直接删掉 vvv 的邻接表即可。
入边难删,比如:
o1 → v
o7 → v
o9 → v这些边存在于 o1,o7,o9o1,o7,o9o1,o7,o9 的邻接表里,所以要先找到这些反向邻居,然后逐个从它们的邻接表中删除 vvv。
这就是为什么前面要找 NNN。
第十二阶段:为什么还要重新插入一些对象?
伪代码第 13--14 行:
foreach r ∈ objects to be reinserted do
IG ← InsertGraph(IG, r, IR, m)这一步也很重要。
删除一个图顶点后,某些顶点的邻居数量可能减少,或者图结构质量变差。
比如原来:
o1 的邻居列表: [v, o5, o8]现在 vvv 被删了:
o1 的邻居列表: [o5, o8]如果图构建规则要求某一层最多或尽量保持 mmm 个邻居,那么 o1o1o1 的邻居结构可能需要修复。
更重要的是,删掉一个中间连接点可能影响图的导航能力。
所以算法会把一些受影响的顶点重新插入图,以重新建立合理的邻居关系。
论文也指出,删除可能会减少某些顶点的邻居数,使它们违反图构建规则;同时,仅访问这些顶点现有邻居不一定能找到真正的最近邻,因此需要将这些顶点重新插入图,以重建正确邻居集合。
第十三阶段:返回更新后的 GTI
伪代码第 15 行:
return IT ∪ IG返回更新后的树索引和图索引。
用一个完整例子串起来
假设现在 GTI 中有:
Level 1 entry:
e5: center=o3, child→N6
Graph vertex:
o3并且图里有边:
o1 → o3
o7 → o3
o9 → o3
o3 → o6入度半径表记录:
IR[o3] = d(o3,o9)因为 o9o9o9 是指向 o3o3o3 的反向邻居中最远的。
现在要删除对象 o3o3o3。
第一步:定位对象
先用近似 1-NN 搜索找 o3o3o3。
如果找不到,再用树做半径 0 的范围查询。
第二步:从树里删除
删除 o3o3o3 后,假设叶节点 N6N6N6 为空,于是 N6N6N6 被删除,Level 1 的 e5e5e5 也被删除。
第三步:删除图顶点
因为 e5e5e5 的 center 是 o3o3o3,所以图顶点 o3o3o3 也要删。
先删:
o3 → N6 的指针再用:
RangeSearchT(o3, IR[o3], IT)找出可能指向 o3o3o3 的候选对象。
然后筛出真正反向邻居:
{o1, o7, o9}删除:
o1 → o3
o7 → o3
o9 → o3
o3 → o6最后对受影响点进行必要的重插入修复。
Algorithm 3 的核心思想
Algorithm 3 最重要的不是每一行,而是这个思路:
删除真实对象 → 先删树
如果 Level 1 不变 → 图不动
如果 Level 1 entry 被删 → 删图顶点
删图顶点时 → 用 IR 表 + 树范围查询找反向邻居
删完后 → 对受影响顶点重插入修复图结构为什么这比传统图删除更高效?
传统图删除为了找入边,可能要遍历所有图顶点:
for each vertex u in graph:
if v in u.neighbors:
delete edge u → v这很慢。
GTI 用入度半径表加树范围查询:
只查 v 附近 IR[v] 半径内的候选点
再筛出真正反向邻居这样避免全图遍历。
而且 GTI 的图本身就比较小,因为它只建在 Level 1 entries 上。
所以删除更新更轻量。
这一部分汇报时可以这样讲
在对象删除过程中,GTI 首先需要定位待删除对象。算法优先使用近似 1-NN 搜索快速查找该对象,如果近似搜索失败,则进一步利用树索引执行半径为 0 的精确范围查询作为兜底。确认对象存在后,GTI 先从树索引中删除该对象。如果删除没有导致叶节点下溢,则 Level 1 entry 不发生变化,图索引无需更新。只有当叶节点下溢并导致 Level 1 entry 被删除时,GTI 才删除图中对应的顶点。
图删除的难点在于不仅要删除该顶点的出边,还要删除其他顶点指向它的入边。为避免遍历整个图,GTI 维护入度半径表,记录每个顶点到其反向邻居的最大距离。删除顶点时,算法以该顶点为中心、以入度半径为半径,在树上执行范围查询,从而获得包含所有反向邻居的候选集合,再筛选出真正指向该顶点的反向邻居并删除相关边。最后,对于邻居结构受到影响的部分顶点,算法会将其重新插入图中,以恢复图的导航质量。
你需要重点记住的几个点
1. 删除不是每次都更新图
普通删除:
树叶节点仍正常 → Level 1 不变 → 图不变
结构性删除:
叶节点下溢/被删 → Level 1 entry 被删 → 图删对应顶点2. 入度半径表是为删除服务的
它的作用是:
不用遍历整个图,也能找到可能指向被删顶点的反向邻居3. 删除图顶点后要修复图
因为删掉一个顶点可能破坏邻居结构,所以要对受影响顶点重新插入,恢复图的搜索质量。
4. GTI 删除快的根本原因
图只建在 Level 1 entries 上,规模小;
普通对象删除大多只影响树;
需要图删除时,用 IR + 树范围查询避免全图扫描。下一步我们讲 4.5 Index Complexity Analyses,也就是空间复杂度、构建时间复杂度和更新时间复杂度。这个部分公式比较多,我会帮你把每个复杂度公式翻译成人话,并告诉你汇报时该怎么讲。