用 Claude Code 或 Codex 写代码,确实效率拉满。
但用过一阵子的人,大概都经历过一件事:Token 烧得飞快,尤其是中大型项目里,随便问一句「这个登录流程是怎么串起来的」,AI 就开始满项目翻文件,反反复复读个几十轮,一轮下来 Token 消耗六位数起步。
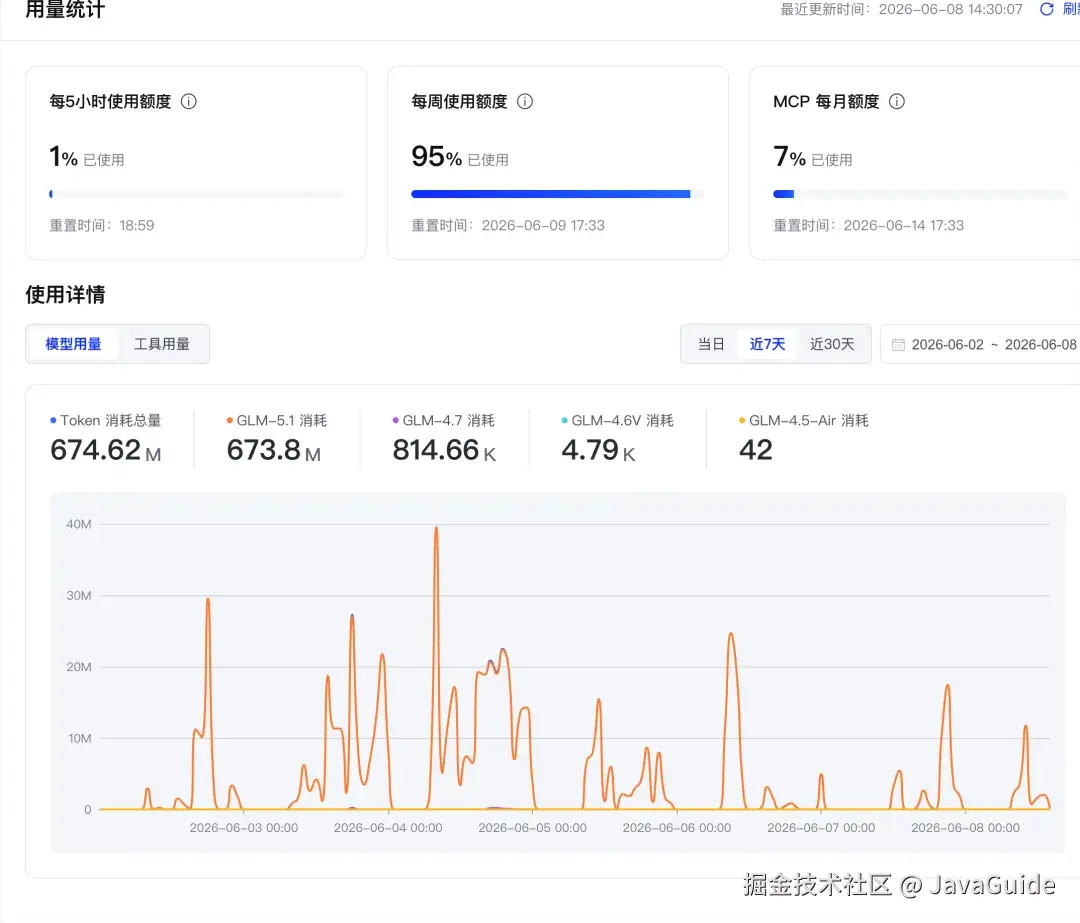
看订阅剩余额度或者月度 API 账单的时候,那个心情,懂的都懂。
下面是我的 GLM Max 订阅,这么顶的周额度经常不够用:
这几天小 G 在 GitHub 上发现一个叫 CodeGraph的开源项目,上线没几天就冲上了 Trending 榜,Star 数一路狂飙。
它的定位很很简单:给代码库建一张知识图谱,让 AI 编程工具不再靠蛮力翻文件,而是像查字典一样精准定位。
原理不难理解。
过去问 AI 一个架构问题,它得先全局搜关键词,然后挨个打开相关文件读完,再判断哪个是入口、哪些是被调用的辅助函数。一套下来可能几十步。
有了 CodeGraph 之后,AI 直接查图谱,一次性拿到完整的调用链和符号关系。几十步压缩到一两步,Token 自然就省了。

官方做了一组对比测试,用 Claude Opus 4.7 在 7 个真实开源项目上跑,每个问题跑 4 次取中位数。
结果是:平均省 35% 的费用,Token 减少 59%,速度快了 49%,工具调用次数砍掉 70%。
具体到个别项目上差距更大。比如在 VS Code 这种上万文件的项目上,Token 直接减少 73%;在 Tokio(Rust 异步运行时)上,费用省了 52%。
这组数据是拿 claude -p 跑无头测试得出的,WITH 和 WITHOUT 两个对照组用的是同一个问题、同一份代码,模型自带的 Read/Grep/Bash 都保留,唯一的变量就是 CodeGraph 的 MCP 服务器开没开。
说实话,这个提升幅度不是靠模型升级带来的,纯粹是工程层面的优化。
本质上,CodeGraph 解决的是一个上下文工程(Context Engineering)问题。Agent 在大型代码库里找代码,传统方式是 Just-in-Time 按需加载------先猜关键词 grep,再逐个读文件,一轮轮探索下去。Claude Code 就是这么干的:靠文件名和目录结构定位,靠搜索命令逐步缩小范围。
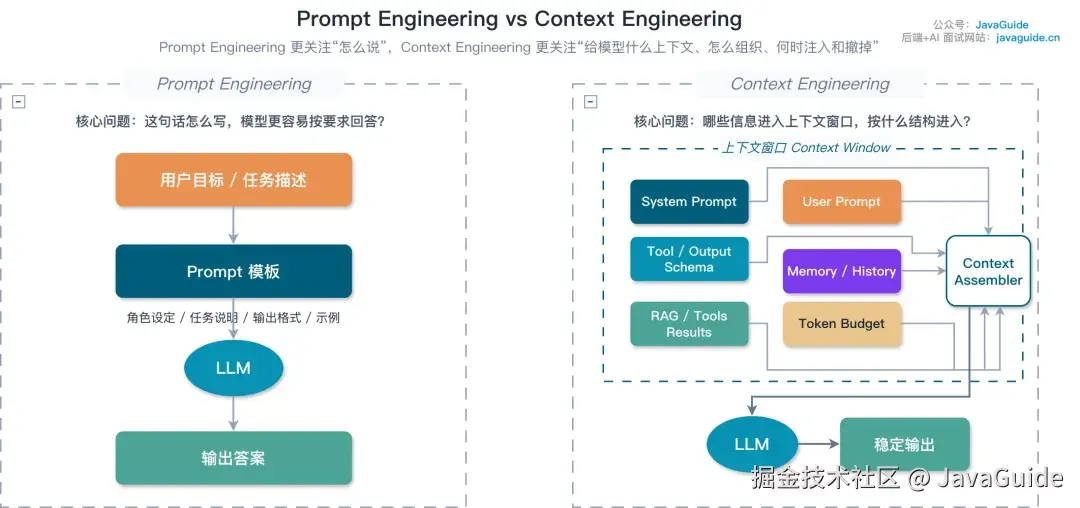
Context Engineering 和 Prompt Engineering 差别
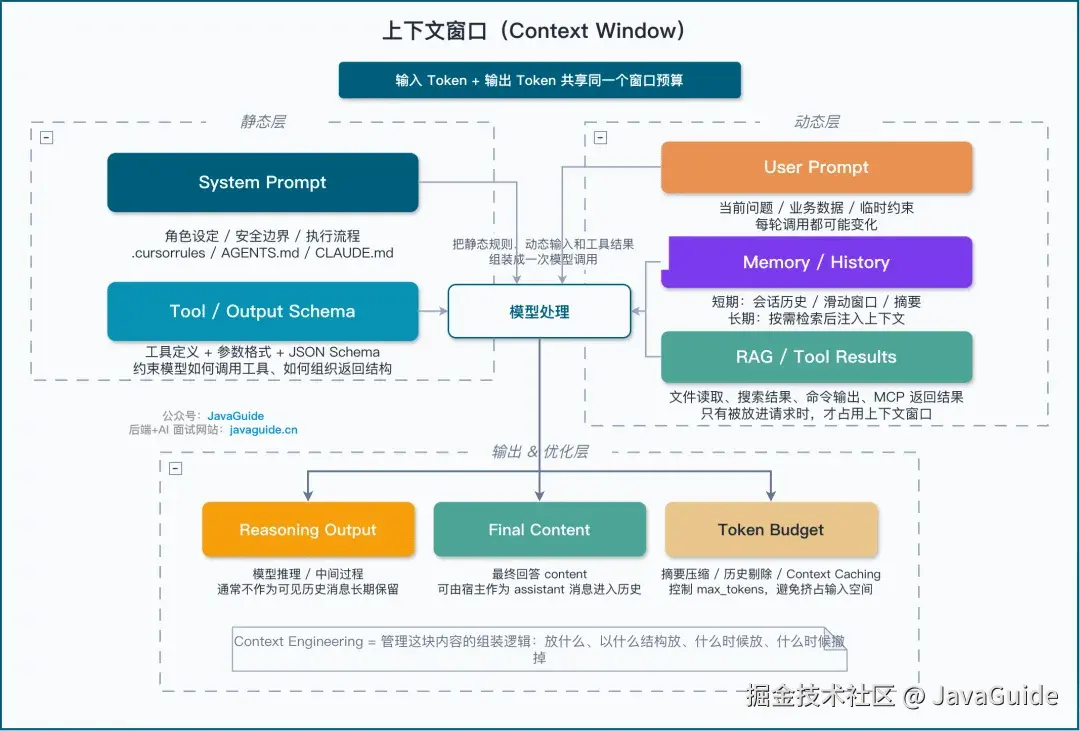
上下文窗口(Context Window)= LLM 的工作记忆
问题是,这种探索式搜索每多一轮,上下文窗口就多一轮噪声。研究数据表明,上下文利用率超过 40%~60% 之后,模型筛选关键信息的稳定性就开始下降------这叫 Context Rot(上下文腐化)。信息塞得越多,模型反而越容易漏掉关键内容。
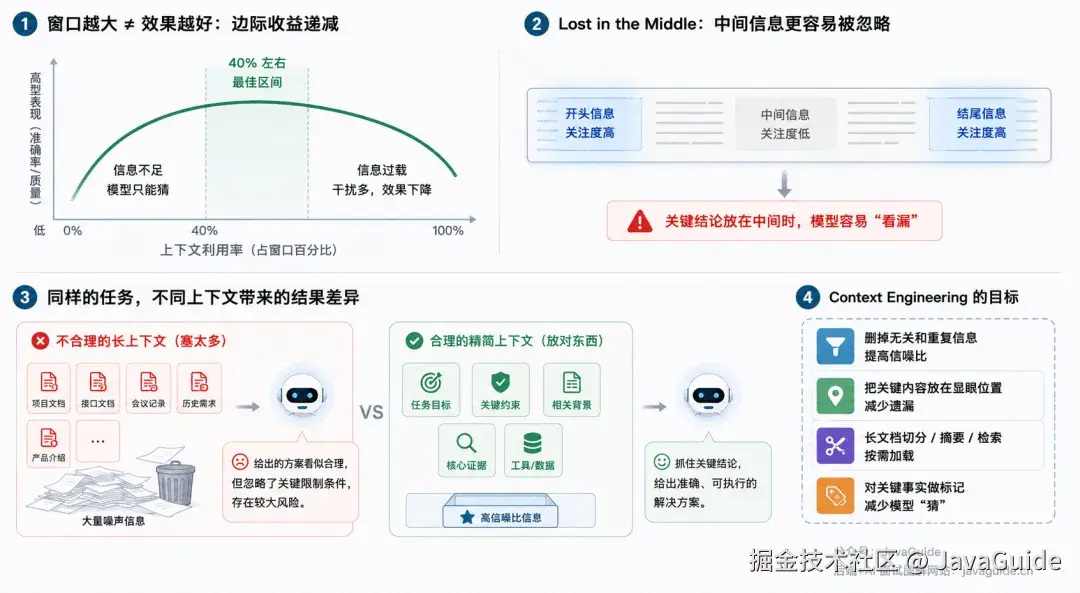
上下文为什么会失效
关于上下文工程和提示词工程的详细介绍,可以看这两篇:
CodeGraph 的做法是把"实时翻文件"前置成"查图谱",把几十步搜索压缩到一两步。不是给模型更大的窗口,而是让模型一开始就拿到更干净、更精准的上下文。
先来说说它到底是怎么建这张图谱的。
底层用的是 tree-sitter 做语法解析,把源代码拆成 AST,然后用语言特定的查询规则提取函数、类、方法这些节点,以及调用、导入、继承这些边。最后全部存进本地 SQLite 数据库(.codegraph/codegraph.db),还加了 FTS5 全文搜索索引。
这是 GPT 对 tree-sitter 的介绍:
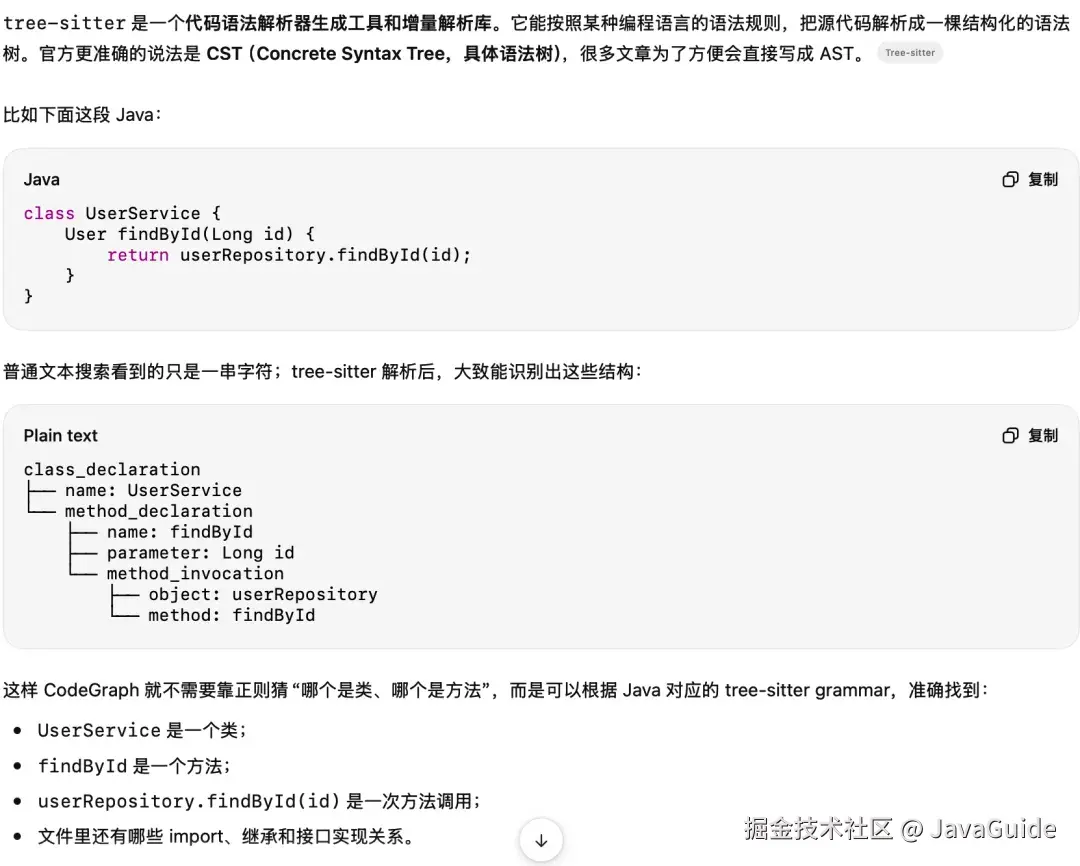
解析完之后还有一步引用解析:函数调用指向哪个定义、import 对应哪个源文件、类继承了谁,这些关系全部对上号。
支持的语言覆盖面挺广,官方列了 19+ 种:TypeScript、JavaScript、Python、Go、Rust、Java、C#、PHP、Ruby、C、C++、Swift、Kotlin、Dart、Lua、Luau、Svelte、Liquid、Pascal/Delphi,主流技术栈基本都盖到了。
接下来重点说说一个对后端开发者很实用的功能:Web 框架路由识别。
CodeGraph 能自动识别 URL 路径和对应处理函数之间的映射关系。支持 13 种主流框架,包括 Django、FastAPI、Express、NestJS、Laravel、Rails、Spring 等。
举个例子,在 Django 项目里问 AI「/api/users这个接口是谁实现的」,过去它得先找路由配置文件,再顺着配置找到视图函数,中间还可能搜岔了好几次。
有了 CodeGraph 之后,一次查询直接定位到处理函数,中间的搜索试错环节全部省掉。
再提一个细节,CodeGraph 的 MCP 服务器启动后会监听文件系统的变更事件,用 2 秒的防抖窗口过滤非代码文件,增量同步索引。也就是说,写代码的过程中图谱会自动保持最新,不需要手动触发重建。
整个项目 100% 本地运行,数据全部存在本地 SQLite 里,不需要联网,不传任何代码到外部服务器。对代码安全敏感的团队来说,这一点很关键。

至于和 Cursor 自带索引的区别,简单说:Cursor 走的是语义相似度匹配,而 CodeGraph 输出的是结构化的调用关系图。一个是模糊搜索,一个是精准查询,定位准确度上 CodeGraph 有它的优势。
这个区别放到更大的图检索视角下会更清晰。传统向量检索的本质是"找和问题最像的文本片段",它擅长判断"这段话和我的问题像不像",但不擅长理解"这些对象之间到底怎么连起来"。CodeGraph 的图谱检索走的是另一条路------把函数、类、调用关系显式建模成节点和边,查询时沿着图关系直接定位,不用靠语义猜测。
这跟知识图谱检索(GraphRAG)的思路一脉相承:检索对象从文本 Chunk 变成了实体、关系和路径,检索精度自然就不在一个层面上了。
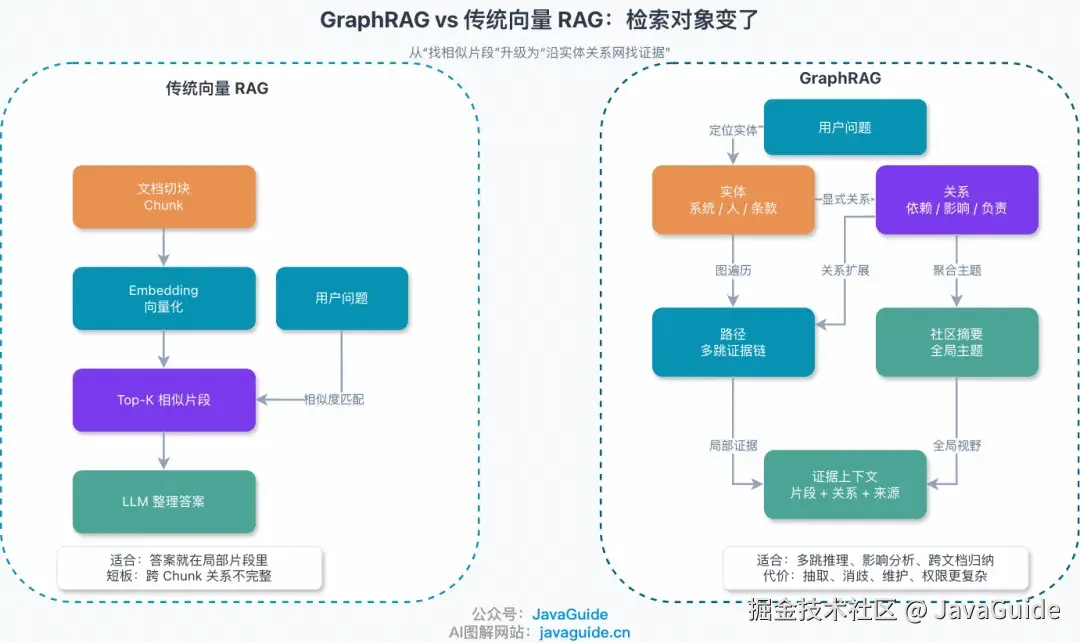
GraphRAG 和传统向量检索的本质区别
当然也得说句实话,CodeGraph 不是万能的。它依赖 tree-sitter 的语言解析能力,如果项目里有特别魔幻的语法或者动态生成的代码,图谱的覆盖可能会有遗漏。另外 macOS 用户如果没有装 Xcode 命令行工具,CodeGraph 会回退到兼容模式,速度会慢 5 到 10 倍,这个坑注意避开。
安装很简单,一行命令:
npx @colbymchenry/codegraph
跑起来后,安装器会自动检测系统里装了哪些 AI 编程工具(Claude Code、Cursor、Codex CLI、OpenCode、Hermes Agent),然后帮你配置好对接。
它会在 ~/.claude.json里加上 MCP 服务器配置,在 ~/.claude/CLAUDE.md里注入使用说明。Cursor 用户则会在 .cursor/rules/下生成规则文件。整个过程全自动,不需要手动改配置文件。
简单说下 MCP(Model Context Protocol):它是 AI 应用与外部工具之间的标准通信协议,底层用 JSON-RPC 2.0。AI 应用(Host)通过 MCP Client 连接 MCP Server,发现 Server 暴露的工具能力,然后按协议调用。CodeGraph 就是一个 MCP Server,把代码图谱查询能力暴露给了 Claude Code、Cursor 这些 Host。想深入了解 MCP 的架构细节,可以看这篇:什么是 MCP?和 Function Calling、Agent 什么关系?。
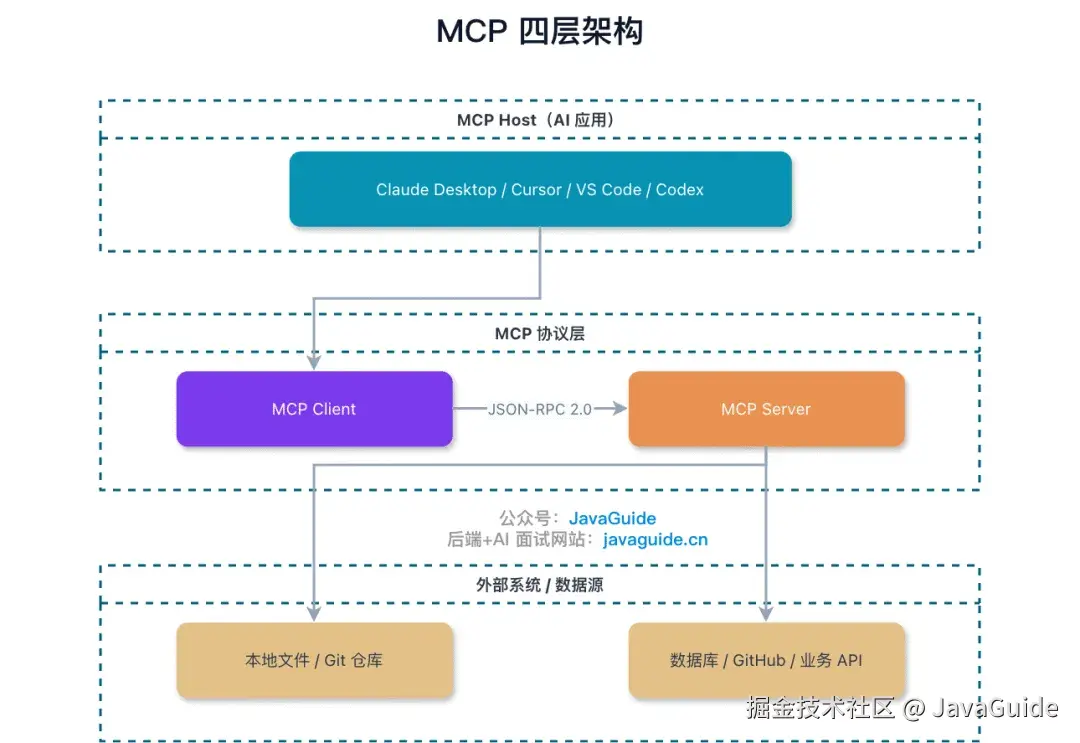
MCP 四层架构
配置完后,进到项目根目录执行:
codegraph init -i
等它建完索引,打开 AI 编程工具直接用就行。问问题的时候,AI 会自动调用 CodeGraph 的工具来查图谱,不需要额外操作。
当前版本是 v0.7.9,MIT 协议开源,需要 Node.js 18+。
写在最后
过去一年,大家都在卷谁的模型更聪明。但真正把 AI 编程工具落到日常开发里之后,会发现决定体验上限的往往不是模型本身,而是它「看懂代码」的速度和成本。
模型再强,每次探索代码都要烧几百万 Token、等十几分钟,用起来还是肉疼。
CodeGraph 的思路是把重复的文件扫描工作前置化,用一张本地图谱替代实时翻文件,这个方向小 G 觉得是对的。
它本质上跟知识图谱检索(GraphRAG)解决的是同一类问题------传统向量检索找的是"最像的文本片段",而图谱检索找的是"对象之间的关系和路径"。想深入了解这套思路的,可以参考这篇:万字详解 GraphRAG:为什么只靠向量检索撑不起复杂知识问答。
不过目前项目还比较新,社区生态和长期维护的稳定性都还需要时间验证。对于代码量不大的个人项目,可能感知不到太大的差异;但如果你的项目文件上千、又经常让 AI 做代码探索和重构,装一个试试看,省下来的 Token 钱应该够喝好几杯咖啡了。
GitHub 项目地址:github.com/colbymchenr...
感谢你能看到这里,有帮助的话,欢迎点赞分享,我们下期再见!