这一篇文章是Datawhale Hello-ROCm的课程笔记,主要记录了了Gemma4微调的过程
1. 基于LoRA的Gemma4微调
1.1 微调的目标:
简单来说,我们这次的目标是微调把Gemma4从一个通用模型调整(Fine-Turning)为一个可以准确识别情绪的崔志领域模型,或者更加概括的来说也可以说是通过微调让Gemma4猜得更加准确一些,具体的实现形式上我们会输入一个句子,然后预测这个句子中所包含的情绪
1.2 技术路线探究:微调?LoRA?
这次我们采用的是LoRA来对Gemma4进行微调,这里我们先来看一下微调的定义:
微调 是一种针对基座模型(Foundation Model)的下游工程定制手段 。它通过冻结(Freeze)或冻结大部分主干网络参数,在特定的、高质量的监督微调数据集(SFT Dataset)上进行有监督的二次训练。其工程本质是利用反向传播修改模型注意力机制(Attention)或前馈网络(FFN)中的权重参数矩阵 ,从而在不改变模型推理架构(Inference Architecture)的前提下,将通用的语义理解能力,固化为特定格式(如 JSON、特定代码规范)、特定领域知识、或者特定行为指令(Instruction-following)的工程交付物。
或者更加概括一些,微调就像是从市场上买来一锅熬好了24小时的高汤(预训练模型这里指的就是我们的Gemma4),但是你想要煮一锅酸汤肥牛,这个时候你就需要加入花椒和其他的香料,再次熬煮(这个地方就是接下来会展示出来的微调训练过程),才能得到你想要的酸汤肥牛的锅底。
微调的路线其实有很多,这次我们采用的是LoRA ,这个技术的核心特点是在微调过程中完全保持原基座模型(这里指的是我们Gemma4)的参数固定不动,仅在旁边增加一组参数量极小(通常不到 1%)的低秩矩阵来专门学习特定任务,这使得它能够将显存消耗和算力开销拉低到单张消费级显卡即可运行的程度,极大地降低了微调的硬件成本。在工程落地时,这些外挂参数可以通过矩阵加法在部署前直接静态合并进原模型的参数中,不仅在运行和部署时完全不会带来额外的响应延迟,而且由于庞大的基座模型未受触动,开发的时候只需为不同任务保存几十兆大小的独立补丁文件就可以在基座模型上实现不同的领域专用模型。
但是还有很多不同的微调技术路线可供参考,这里笔者总结几种比较常见的供参考和比较
| 微调范式 (Paradigm) | 可训练参数量占比 (Tunable Params %) | 计算与存储资源成本 (Compute & Memory Cost) | 推理运行时开销 (Inference Overhead) | 灾难性遗忘风险 (Forgetting Risk) | 工程适用场景与部署评价 (Engineering Deployment Evaluation) |
|---|---|---|---|---|---|
| 全参数微调 (Full Fine-Tuning) | 100% (全局权重协同更新) | 极高 (需要多卡/集群分布式训练) | 无 (未改变原生推理计算图) | 高 (易破坏预训练特征流形) | 适用于垂直领域基座模型的深度定制;由于资源消耗极大且存在知识遗忘,通常作为最后阶段的底座调整手段。 |
| LoRA / QLoRA (Low-Rank Adaptation) | 0.1% ~ 1% (仅训练外挂低秩子空间) | 极低 (单张消费级显卡可支持训练) | 无 (部署前可将参数矩阵静态合并) | 极低 (基座参数冻结,保留通用先验) | 兼顾模型表现与计算资源成本,在多租户场景下可实现高效的适配器热插拔部署。 |
| Adapter Tuning (适配器微调) | 1% ~ 3% (在网络层间嵌入串联结构) | 低 (仅更新层间新增的独立夹层) | 中等 (网络层数加深导致串行延迟增加) | 低 (核心网络权重保持冻结) | 早期参数高效微调的代表;因在线上高并发、低延迟要求的生产环境存在推理算力损耗,目前多被 LoRA 替代。 |
| Prefix / Prompt Tuning (前缀/提示微调) | < 0.1% (仅更新输入端虚拟 Token) | 极低 (仅涉及序列前端的向量训练) | 低至中 (计算无延迟,但挤占上下文窗口) | 极低 (完全不干扰模型内部参数拓扑) | 适用于多任务快速切换与轻量级微调;在面对复杂的控制逻辑、严格格式约束或长文本推理时,表现上限较低。 |
1.2 代码解读:
这里我们解析一下几个比较关键的代码段
python
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)这段代码是指令微调的数据预处理核心。大模型需要特定的对话格式才能理解人类的指令。这里我们把原始的文本和情感标签重新组装成系统提示、用户输入,并将正确的分类答案作为助手的回复。这种结构化的字典格式随后会替换掉原始的表格数据,让模型在微调时明确知道在特定情境下该给出什么样的标准回答。
python
training_args = SFTConfig(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="linear",
warmup_steps=50,
num_train_epochs=1,
logging_steps=5,
eval_strategy="steps",
eval_steps=25,
save_strategy="steps",
save_steps=25,
save_total_limit=2,
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_checkpointing=True,
bf16=BF16,
fp16=FP16,
tf32=False,
max_length=256,
packing=False,
completion_only_loss=True,
remove_unused_columns=False,
dataloader_num_workers=2,
optim="adamw_torch",
report_to="none",
seed=SEED,
data_seed=SEED,
)这段配置是整个单卡微调工程的控制中枢。受限于显存空间,代码把每次送入计算的样本数限制在四个,但是通过设置梯度累积步数,实际上是在内存里凑齐十六个样本的梯度后才进行一次真正的参数更新。开启梯度检查点选项则是用计算时间去换取宝贵的显存容量。另外代码中明确设置了仅对模型输出的答案部分计算损失,不对用户的题目本身计算误差,这样可以强迫模型将学习精力全部集中在如何生成正确的情感标签上。
python
if isinstance(base_model, PeftModel):
base_model = base_model.unload()
base_model.config.use_cache = False
trainer = SFTTrainer(
model=base_model,
train_dataset=sft_dataset["train"],
eval_dataset=sft_dataset["validation"],
peft_config=lora_config,
args=training_args,
processing_class=tokenizer,
)
trainable_params = 0
total_params = 0
trainable_param_names = []
for name, param in trainer.model.named_parameters():
total_params += param.numel()
if param.requires_grad:
trainable_params += param.numel()
trainable_param_names.append(name)
if trainable_params == 0:
raise RuntimeError("No trainable LoRA parameters were attached. Check target_modules before training.")这是启动微调任务的最终执行环节。代码首先做了一个安全检查,如果底座模型上已经挂载了旧的微调补丁就会先卸载掉,同时强制关闭推理缓存机制以防止训练时底层张量计算出错。接着把前面准备好的模型实体、格式化后的数据集以及各类参数配置全部打包交给训练器。中间的循环遍历专门用来统计并验证需要更新的参数量,确保外挂的旁路网络被正确激活。最后调用训练指令,模型就会开始在你的单卡环境下进行针对性的权重更新。
python
print("Loading tokenizer from:", LOCAL_MODEL_DIR)
tokenizer = AutoTokenizer.from_pretrained(
LOCAL_MODEL_DIR,
use_fast=True,
trust_remote_code=True,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
TEMPLATE_SOURCE_MODEL_ID = "google/gemma-4-E4B-it"
def _load_official_gemma_chat_template() -> str:
try:
template_dir = snapshot_download(
TEMPLATE_SOURCE_MODEL_ID,
cache_dir="./models",
allow_file_pattern=["chat_template.jinja"],
)
path = os.path.join(template_dir, "chat_template.jinja")
if os.path.exists(path):
with open(path, "r", encoding="utf-8") as f:
return f.read()
except Exception as e:
print("snapshot_download(allow_file_pattern) failed, fallback to HTTP. err =", e)
import urllib.request
url = (
"https://www.modelscope.cn/api/v1/models/"
f"{TEMPLATE_SOURCE_MODEL_ID}/repo?Revision=master&FilePath=chat_template.jinja"
)
with urllib.request.urlopen(url, timeout=60) as resp:
return resp.read().decode("utf-8")
if not getattr(tokenizer, "chat_template", None):
print(f"Loading official chat_template.jinja from {TEMPLATE_SOURCE_MODEL_ID} ...")
tokenizer.chat_template = _load_official_gemma_chat_template()
print("Loaded official chat_template, length =", len(tokenizer.chat_template))
else:
print("tokenizer.chat_template already set, leaving as-is.")
_probe = tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
],
tokenize=False,
add_generation_prompt=True,
)
print("chat_template probe output:\n" + _probe)
print("Loading base model from:", LOCAL_MODEL_DIR)
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
print("HIP version:", getattr(torch.version, "hip", None))
base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
base_model.to(device)
base_model.config.use_cache = False
base_model.config.pad_token_id = tokenizer.pad_token_id
base_model.config.bos_token_id = tokenizer.bos_token_id
base_model.config.eos_token_id = tokenizer.eos_token_id
base_model.generation_config.pad_token_id = tokenizer.pad_token_id
base_model.generation_config.bos_token_id = tokenizer.bos_token_id
base_model.generation_config.eos_token_id = tokenizer.eos_token_id这段代码承担了模型运行前最核心的基础设施搭建工作,主要包含分词器配置和基座模型加载两大部分。分词器不仅负责将自然语言切割成模型能够理解的张量标记,还需要处理指令微调的关键结构,也就是对话模板。为了防止缓存缺失导致训练报错,代码在此处设计了一套严密的防御机制,如果检测到分词器缺失官方的对话模板,就会自动触发兜底逻辑,通过网络请求直接从原始仓库抓取模板并进行动态注入,随后立即执行代码自检以确保模板拼接功能的可用性。在基座模型加载阶段,代码将庞大的神经网络权重调度到显存中,同时强制对齐了分词器与底层模型的各类边界符号标记,并主动关闭了推理缓存机制,从而排除了潜在的张量计算冲突。
1.3 实践部分:
这次还是用的是Radeon Cloud这个平台来实践,关键代码段分析可见上方
到了我们煮酸汤肥牛微调训练的时候了
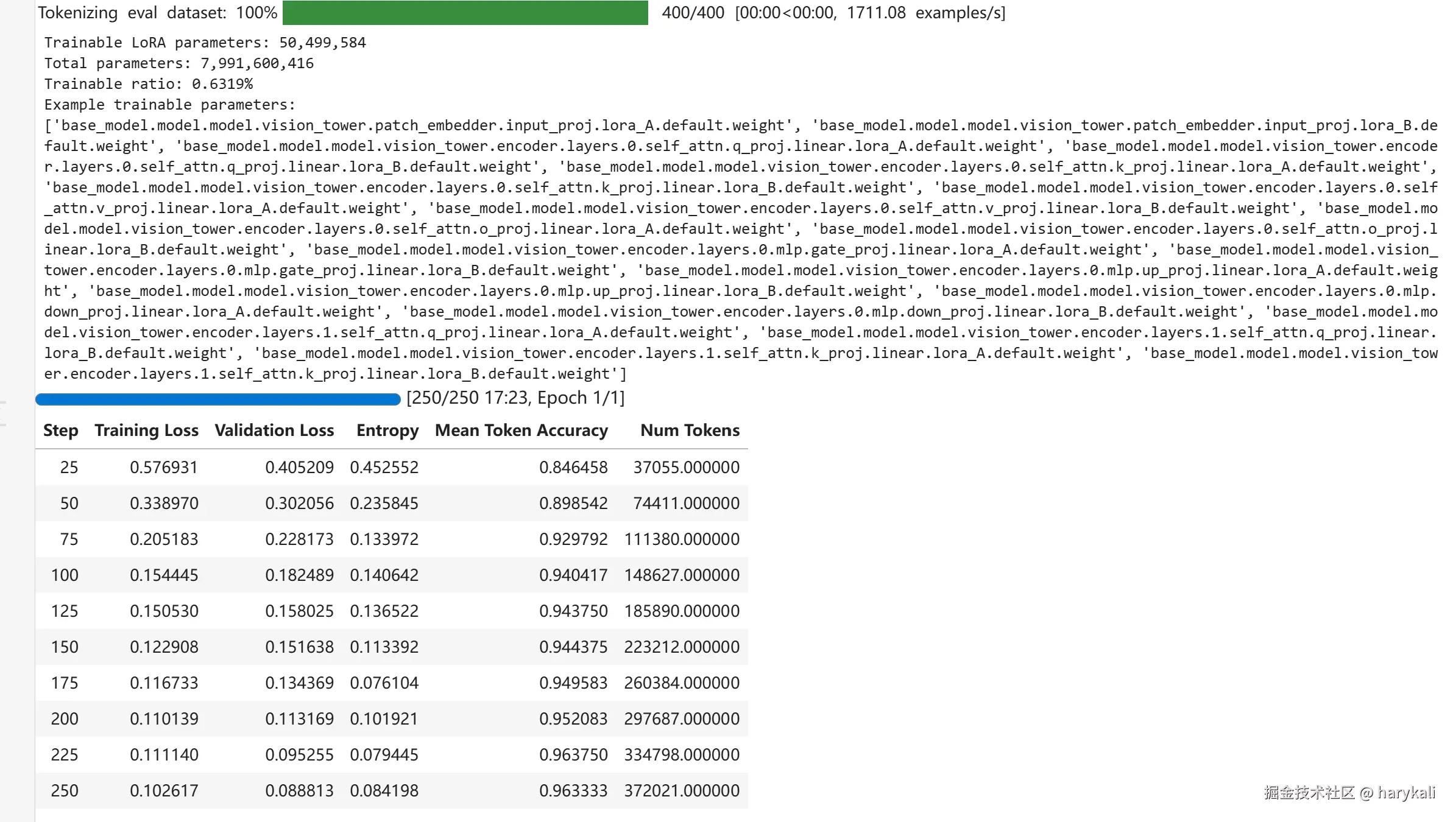
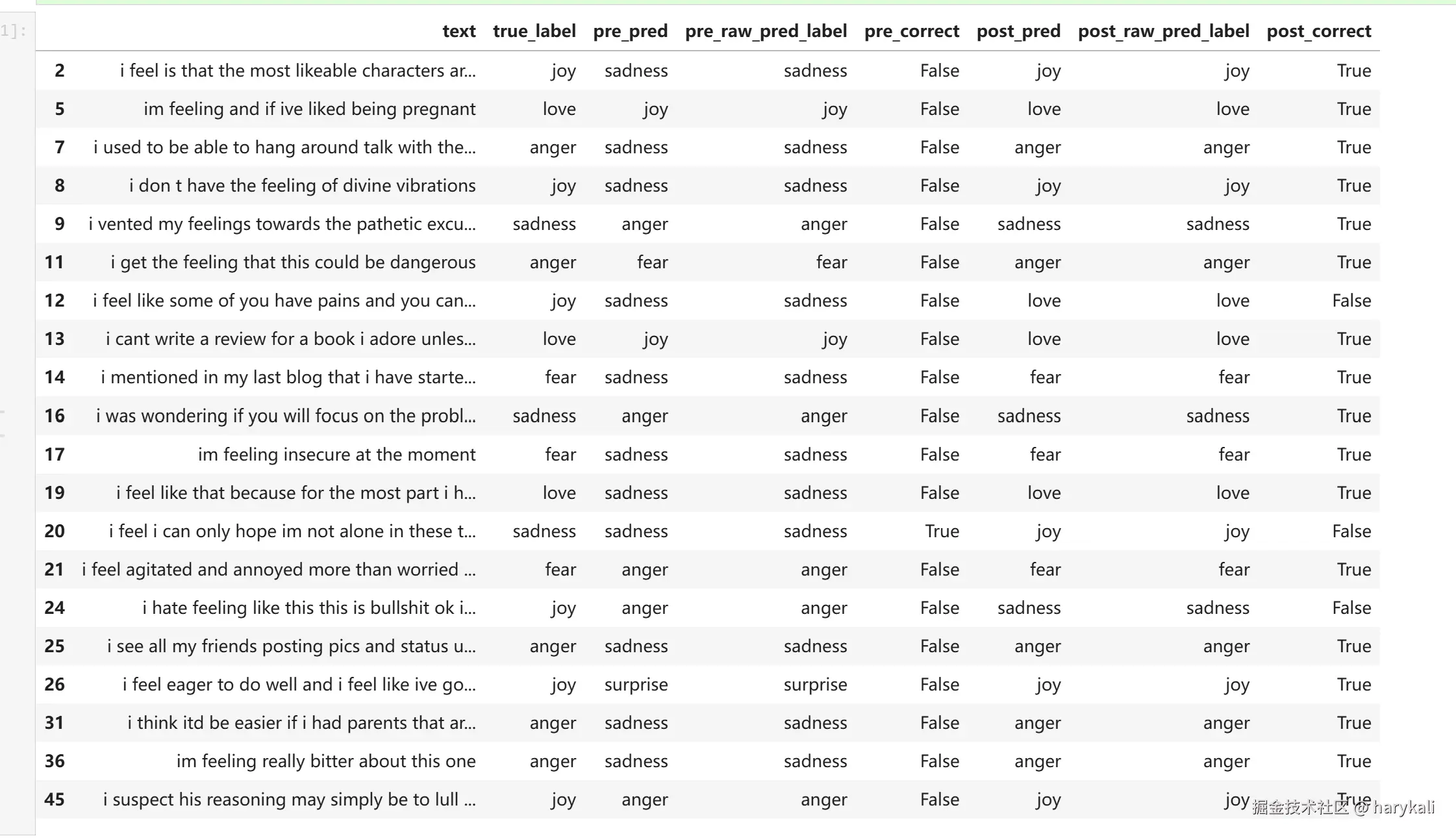
训练完成后就可以使用全新模型来预测句子的情绪了,可以重点留意一下此处进行微调之前的分数和进行微调之后的分数对比
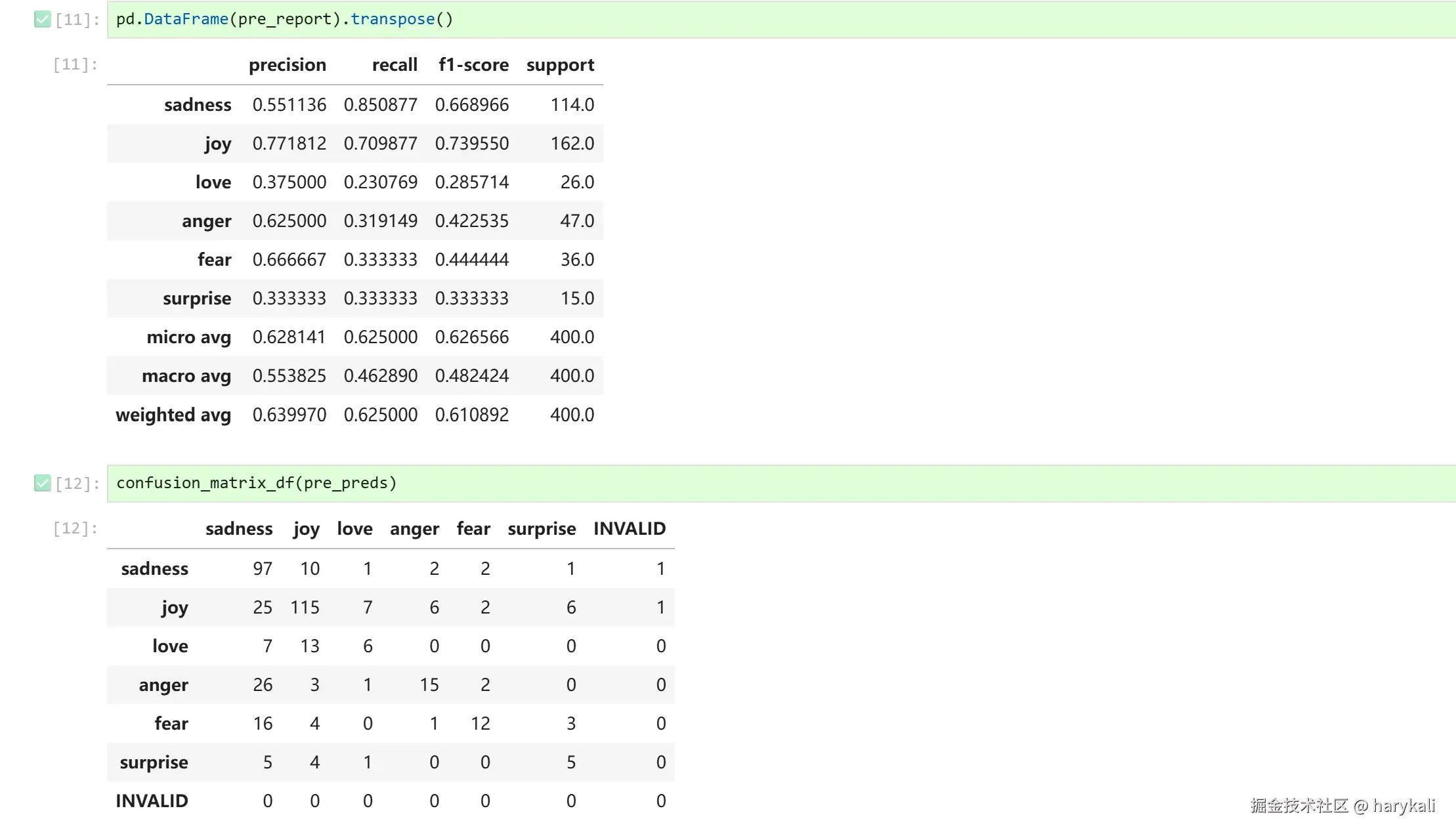
这里是微调前的数据
这里是微调后数据
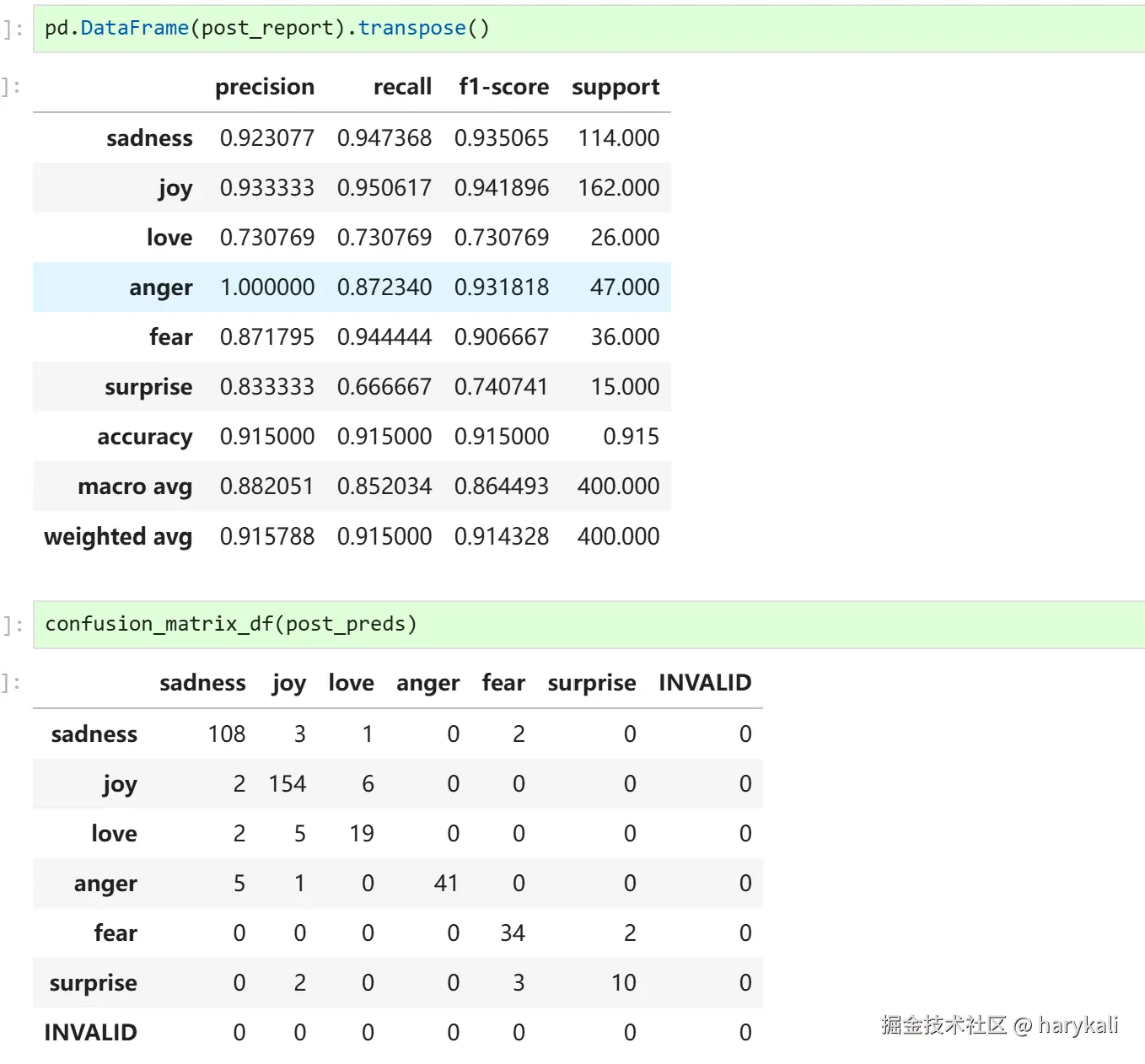
可以看见在微调之后,acc和f1都有了提升。
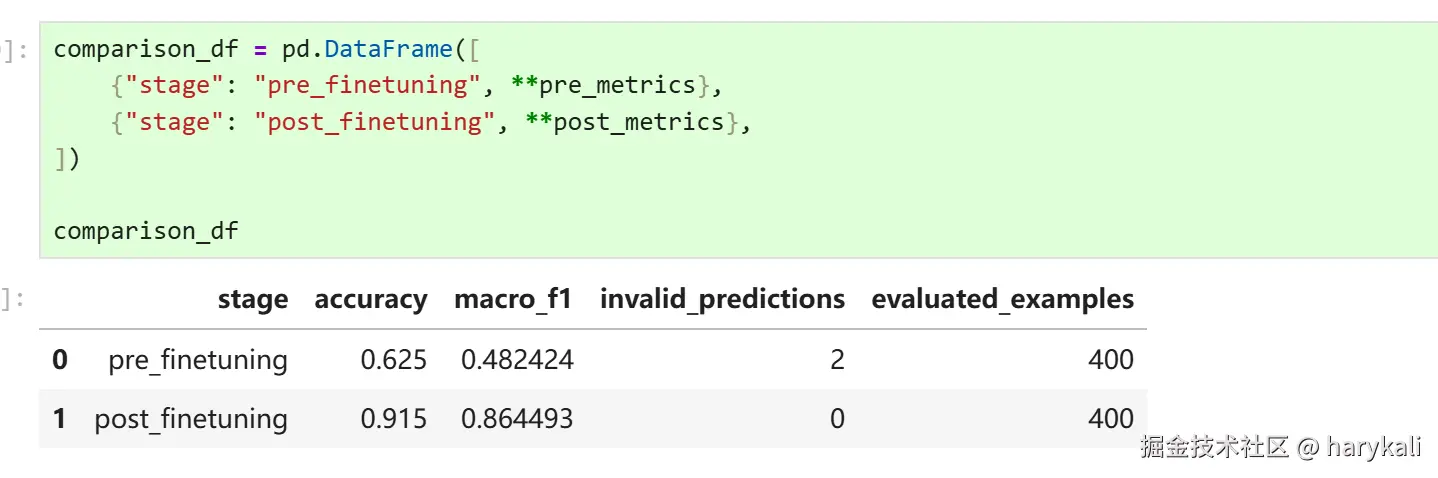
总结来说,这次微调使模型的分类性能实现了显著的提升,最直观的变化是整体准确率(Accuracy)从 62.5% 提升至 91.5% ,同时代表各类别平均表现的 Macro F1 分数也提高了 38.2%,表明模型对数据量较少的长尾类别的分类能力得到了根本性改善。
从混淆矩阵的实际数据来看,微调成功理清了原本容易混淆的类别边界。原先在 47 个 anger样本中有 26 个被错判成 sadness的漏报现象得到大幅缓解,其召回率(Recall)升至 0.872;同时,由于微调后没有任何其他类别的样本被错误地判断为愤怒,anger 的精确率(Precision)成功达到了 1.000。
与此同时,微调激活了Gemma4过自身原本就具备的语言情感推断能力,让样本极少的 love和 surprise的 F1 分数分别从 0.285 和 0.333 拔高到了 0.730 和 0.740 级别,实现了小样本下的有效捕捉。
最终,微调后的预测数据高度向对角线集中,非对角线上的误判明显大幅降低,原本偶发的非法输出(INVALID)完全清零,模型的输出行为变得非常规范,它的实际判断规律已经高度契合了测试集的真实答案。
我们不妨再仔细看看这个微调后的模型的实际输入输出表现:
