过去企业交付数据能力,普遍采用 "直接开放库表权限 + 研发定制接口" 的传统模式。这种模式在数据需求少、消费方单一的阶段尚可运行,但随着业务数字化程度加深,数据分析、业务系统、运营活动、第三方合作等场景对数据的需求愈发碎片化、高频化,传统交付方式的效率与安全矛盾日益突出。
行业正在形成共识:数据服务化是企业数据能力输出的核心路径。将数据封装为标准化、可复用、可管控的 API 服务,以接口的形式对外交付数据能力,是破解 "取数难、交付慢、风险高" 困局的根本解法,也是企业数据建设从 "资源管理" 迈向 "价值输出" 的必经阶段。

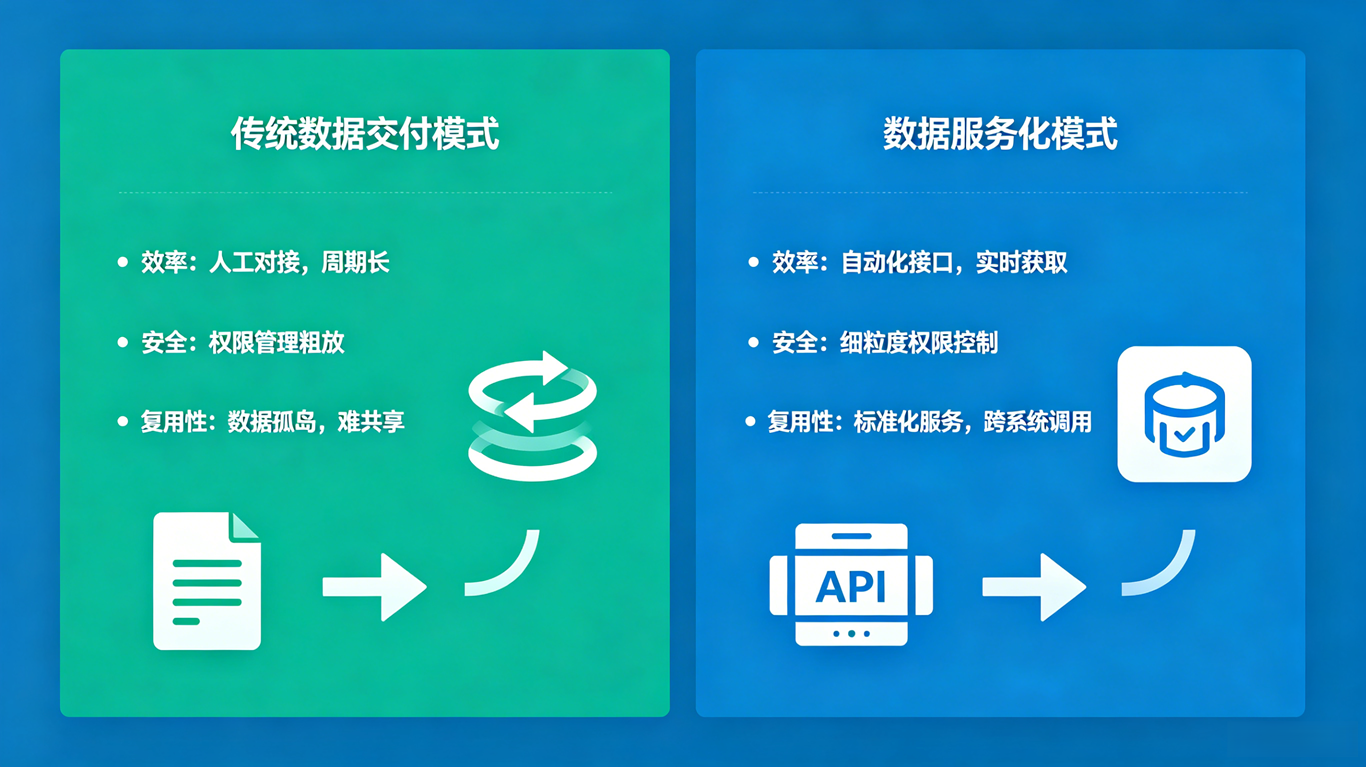
一、传统数据交付的三大核心痛点
数据价值的释放,离不开高效的交付链路。而绝大多数企业的传统数据交付模式,普遍存在效率、安全、复用三大结构性痛点,成为数据价值流转的堵点。
1. 交付效率低,研发资源长期承压
传统模式下,业务侧的每一个数据需求,几乎都要走 "需求提报→研发排期→编写 SQL→开发接口→测试上线" 的完整流程。一个普通的数据查询接口,从需求确认到正式上线,平均需要 3-5 天;复杂的跨库统计需求,周期甚至长达一两周。 一方面,业务侧抱怨取数太慢,运营活动、数据分析都要等排期,错失业务窗口;另一方面,后端研发团队被大量同质化的数据查询需求占用精力,80% 的接口开发都是重复的 CRUD 逻辑,无法聚焦核心业务逻辑的建设。供需两端的矛盾,几乎是所有成长型企业的共性难题。
2. 安全不可控,权限粒度粗放
为了提升取数效率,很多企业会选择直接给业务人员、分析师开放数据库查询权限。这种方式看似灵活,实则隐藏着巨大的安全风险。 库表级别的权限粒度过粗,无法做到行级、列级的精细化管控,敏感数据容易泄露;直接连接数据库执行 SQL,无法统一拦截高危操作,一个写得不好的查询就可能拖垮整个生产库;同时,数据访问没有统一的审计链路,谁查了什么数据、用在了哪里,都无法完整追溯。在数据合规要求日益严格的当下,这种粗放的交付方式已经难以为继。
3. 能力难复用,数据资产无法沉淀
传统的数据交付大多是 "点对点" 的定制开发:针对某个业务场景写一个接口,针对某次活动写一段查询 SQL。这些接口和逻辑散落在各个业务系统、各个开发人员手中,没有统一的管理和沉淀。 当新的业务场景有相似需求时,往往无法直接复用已有能力,研发只能重新开发一遍,造成大量重复劳动。企业的数据能力始终无法积累形成可复用的资产,数据建设始终在低水平重复,越做越重,效率却没有提升。
二、数据服务化的核心逻辑:从 "给权限" 到 "给服务"
数据服务化,简单来说就是将数据查询、统计、计算等能力,封装为标准化的 Restful API,以服务的形式对外提供。数据消费方不需要直接接触底层数据库,也不需要关心数据存储在哪、用的什么数据库,只需要调用标准化的接口,就能获取所需的数据能力。
其核心逻辑是实现了两层解耦: 第一层是存储与消费解耦 。底层数据库的架构、选型、位置对消费方透明,无论底层是 MySQL、PostgreSQL 还是 ClickHouse,消费方拿到的都是统一格式的接口服务。底层架构调整时,不会影响上层业务使用,大幅提升了架构的灵活性。 第二层是生产与消费解耦。数据服务的提供方负责数据逻辑的维护、安全管控、性能优化,消费方只需要关注业务逻辑,拿来即用,不需要具备数据库专业能力。双方各司其职,既提升了效率,也保障了安全与质量。
如果说传统的库表权限模式是 "把厨房直接开放给食客,让大家自己生火做饭",那么数据服务化就是 "中央厨房做好标准化菜品,通过窗口统一对外供应"。前者灵活但混乱、风险高,后者规范、高效、可控,更适合企业规模化的数据消费场景。
三、数据服务化带来的四大核心变革
从 "直接给权限" 转向 "提供服务",不是简单的交付形式变化,而是对企业数据流转体系的全方位重构,会在效率、安全、业务赋能、资产沉淀四个维度带来根本性的提升。
1. 研发效率:从重复造轮子到能力复用
数据服务化首先解决的就是研发效率问题。通过可视化配置的方式,基于 SQL 逻辑快速生成标准化接口,原本需要数小时甚至数天的接口开发工作,可以缩短到几分钟完成。 更重要的是,所有生成的数据接口统一沉淀在服务目录中,新的业务需求可以直接复用已有接口,无需重复开发。企业的数据服务资产越积累,重复开发的工作量就越少,研发团队可以从大量的 CRUD 重复劳动中解脱出来,聚焦于更核心的业务逻辑与架构设计。
2. 安全管控:从粗放开放到全链路可控
数据服务化是兼顾效率与安全的最佳方案。所有数据访问都通过统一的 API 网关入口,企业可以在网关层实现统一的鉴权、脱敏、限流、审计能力。 权限粒度可以精确到接口级别,不同角色只能调用授权范围内的接口;敏感字段可以在接口层自动脱敏,消费方接触不到原始明文数据;所有接口调用都有完整的日志记录,谁在什么时间调用了什么接口、返回了什么数据,全程可追溯。既满足了业务取数的灵活性,又把风险牢牢控制在可控范围内。
3. 业务赋能:从需求排队到自助消费
数据服务化降低了数据消费的技术门槛。业务人员、产品经理、数据分析师不需要掌握 SQL,也不需要申请数据库权限,只需要调用对应的数据接口,就能获取所需的数据。 对于高频、标准化的取数场景,业务方可以完全自助完成,不再需要占用研发资源排期等待。数据需求的响应周期从天级缩短到分钟级,业务团队可以基于数据快速迭代、快速决策,真正让数据驱动业务落地。
4. 资产沉淀:从零散逻辑到服务资产
当所有数据接口都在统一平台上管理时,企业的数据能力就从零散的个人经验、散落的代码片段,沉淀为可复用、可管理、可迭代的公共服务资产。 随着业务发展,企业会逐步形成覆盖用户、订单、商品、运营等各个领域的数据服务体系。这套体系是企业的数字资产,越用越完善,越用越高效,最终成为支撑业务快速创新的数据底座。这是传统点对点交付模式永远无法实现的价值。
四、企业落地数据服务化的两阶段路径
数据服务化不是一步到位的重型工程,企业可以根据自身规模和发展阶段,循序渐进地推进建设。我们将其归纳为两个核心阶段,成长型企业可以按路径逐步落地。
第一阶段:快速生成,场景切入
对于处于发展初期、数据需求快速增长的企业,不需要上来就搭建完整的 API 网关和服务治理体系。核心目标是快速解决 "取数慢、开发累" 的痛点,优先提升交付效率。 这个阶段的核心是引入可视化的数据 API 生成能力,通过 Web 端配置 SQL、设置请求参数、配置返回格式,一键生成标准接口。优先覆盖高频、通用的数据查询场景,比如运营报表、用户查询、订单统计等,快速释放研发生产力。 这个阶段投入小、见效快,几周内就能看到明显的效率提升,非常适合中小企业作为数据服务化的切入点。
第二阶段:统一网关,体系化运营
当企业的数据接口数量越来越多,消费方覆盖多个部门、多个系统时,就需要进入第二阶段,建设统一的数据 API 网关,实现体系化的服务治理。 这个阶段的核心是建立统一的服务出入口,实现接口的全生命周期管理:统一的鉴权认证、流量控制、熔断降级,保障服务的稳定可靠;统一的调用监控、用量统计、异常告警,实现可观测性;统一的服务目录、版本管理、下线机制,让数据资产有序沉淀。 至此,企业就形成了完整的数据服务化体系,数据能力可以安全、高效、稳定地输送到各个业务场景,成为企业数字化的核心支撑能力。

结语
企业的数据建设,大致会经历 "存得下→管得住→用得好" 三个阶段。如果说 Web 统一管控解决了 "管得住" 的问题,那么数据服务化就是迈向 "用得好" 的核心路径。
它不是一个遥不可及的概念,而是一套可落地、可迭代的务实方案。小到一个团队的取数效率提升,大到整个企业的数据资产建设,都可以从数据服务化中获益。未来,数据服务能力将成为企业数字化水平的核心标志,谁能更快地让数据流动起来、价值释放出来,谁就能在业务竞争中占据先机。