目录
有需要本项目的代码、文档、完整资源,或者需要部署调试的朋友,可以私信博主。

图 1 系统整体效果封面展示
一、项目背景
音乐平台每天都会产生大量用户行为数据,歌单、歌曲、标签、播放量、收藏量、评论量、分享量和用户评论共同构成了一个很有观察价值的内容生态。单纯把这些数据存成表格并不难,真正有意思的是把分散的数据串起来,看到不同分类的热度差异、歌单增长趋势、用户评论情绪,以及热门音乐内容背后的关键词和主题。
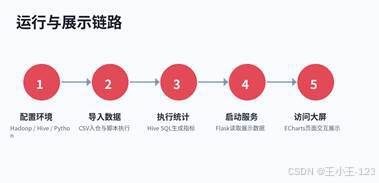
我做这个系统时,核心想法是把"数据采集---数据清洗---Hive离线分析---文本挖掘---可视化展示"连成一条完整链路。前端不只是放几张图,而是尽量把数据处理后的指标集中到大屏和单页图表中,方便从不同角度查看网易云音乐歌单数据。项目的重点不是做一个孤立的爬虫,也不是只输出几张图,而是把数据工程、离线计算和可视化应用组合到一起。
压缩包中的资料包含爬虫代码、评论采集脚本、数据预处理Notebook、Hive相关脚本、SQL文件、Flask大屏程序、可视化HTML结果和评论分析结果。整理后可以看到,这个项目已经具备较完整的开发流程:前面负责拿到数据和处理数据,中间负责用Hive做指标计算,后面负责把结果用ECharts和大屏页面展示出来。
二、项目整体思路
这个系统围绕网易云音乐歌单数据展开,数据来源主要包括歌单列表、歌单详情、歌曲信息、标签信息和热门歌单评论。采集完成后,先对原始字段做清洗和规范化处理,再通过Hive完成多维统计分析,最后将结果整理为可视化页面和数据大屏。评论数据单独进入文本分析流程,用来生成评论词云、关键词提取、情感倾向分布和LDA主题分析结果。
整体路线并不复杂,但每一步都需要考虑数据的可维护性。例如歌单数据字段多、分类多,评论文本也比较口语化,如果不做清洗,后面的词云和主题结果会很杂;如果只在本地用普通脚本临时统计,后续扩展数据量时又不方便。因此我把Hive作为离线分析核心,用SQL沉淀分类、时间、来源、标签和歌曲热度等指标,再交给展示层调用。
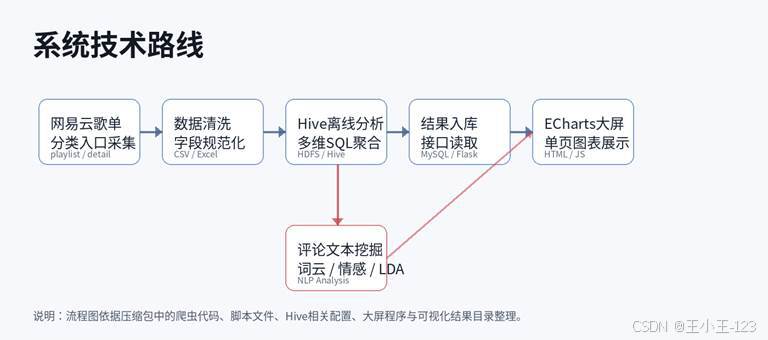
图 2 系统技术路线整理
三、资料结构
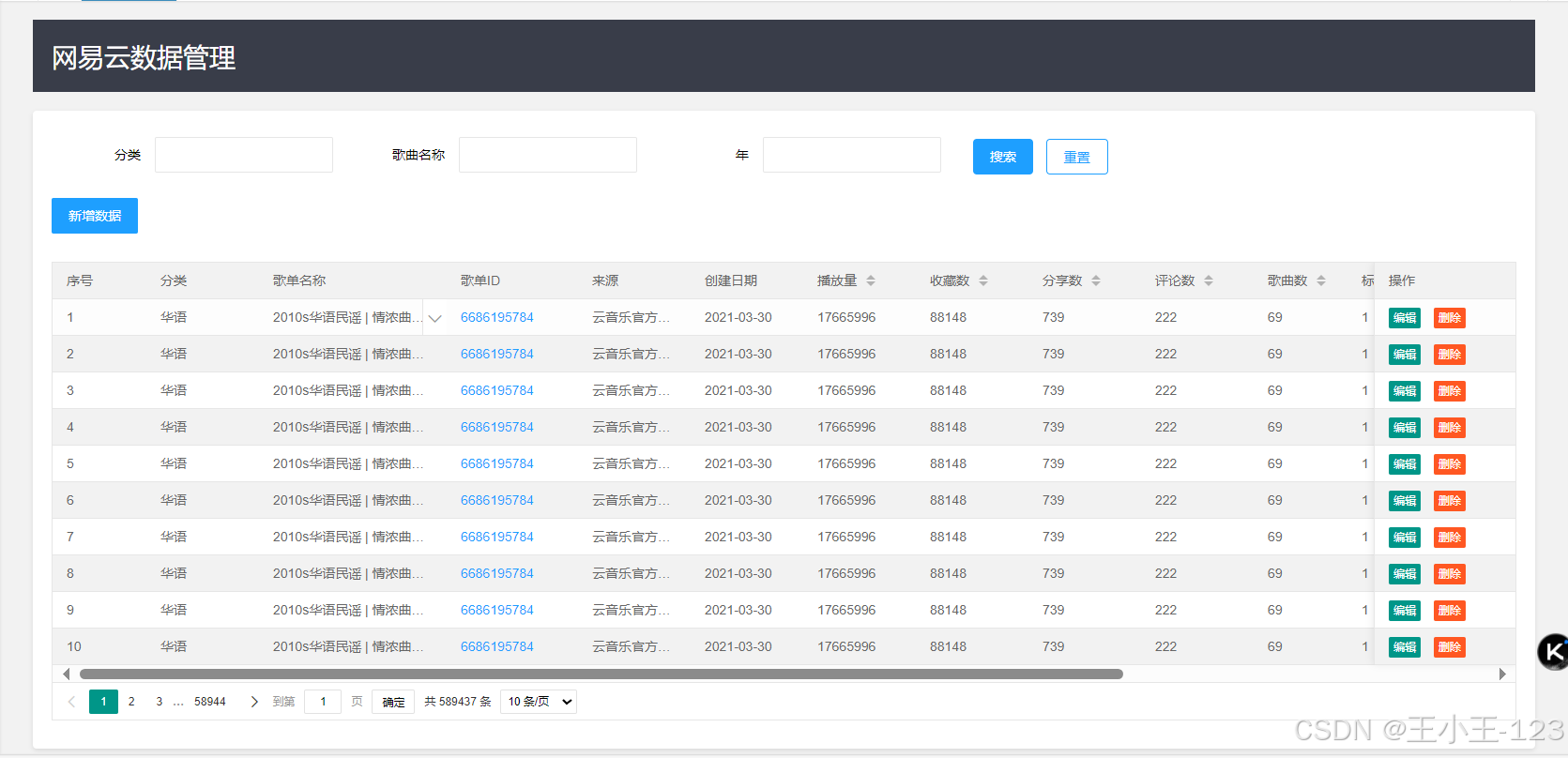
从项目目录可以看出,整个资源被拆成了几个比较清晰的部分:爬虫代码负责采集歌单和详情,评论获取目录负责采集热门歌单评论,脚本文件中放置Hive配置与启动脚本,大屏目录中包含Flask应用和静态资源,项目页面目录中保留了大量单页可视化HTML结果,可视化结果目录则集中存放了评论分析相关页面。除此之外,还有Notebook、SQL文件、原始数据和处理后的数据文件,便于复现实验过程。
这种结构比较适合二次整理和交付。对于只想看效果的人,可以先看大屏和单页图表;对于想学习实现流程的人,可以顺着爬虫、预处理、Hive脚本、可视化代码逐步运行;对于需要做课程设计或毕业设计拓展的人,也可以在现有结构上继续扩展推荐、用户画像、歌单相似度分析等功能。

图 3 项目目录结构脱敏展示
四、数据采集
数据采集部分主要分为两条线:一条线抓取歌单分类、歌单列表和歌单详情,另一条线针对热门歌单继续抓取评论。歌单侧更关注结构化字段,例如歌单标题、分类标签、播放量、收藏量、评论量、分享量、歌曲数量、创建时间和来源等;评论侧更关注文本内容、评论时间、用户昵称等信息,后续会进入分词、停用词过滤、情感判断和主题提取流程。
从运行截图可以看到,采集程序会持续写入歌单信息和评论页数据。为了适合公开展示,我对截图中的长编号等信息做了遮挡处理,只保留运行状态和数据写入效果。实际运行时,脚本会按照页面或分类逐步推进,采集结果保存为CSV,后续再进入预处理和Hive分析环节。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
| 图 4 歌单详情采集运行截图 | 图 5 评论采集运行截图 |
五、数据预处理
爬虫拿到的数据通常不能直接进入可视化。比如播放量、收藏量、评论量等字段可能存在文本格式,时间字段需要拆分成年、月、星期等维度,歌单标签需要做切分,评论文本需要去掉无意义符号和停用词。预处理Notebook主要承担这些工作,把原始CSV转换成更适合Hive建表和统计分析的数据。
在这个项目中,我比较看重字段的统一性。歌单分析要覆盖分类、来源、时间、标签数量、歌曲数量等多个维度,如果前期字段没有处理好,后面写Hive SQL时会出现大量临时修补。把清洗规则提前固定下来,后续无论是生成大屏指标,还是输出单页HTML图表,都会稳定很多。
评论文本的预处理则更偏向自然语言处理。项目中准备了停用词库和保留词文件,配合分词、关键词提取、词云生成和主题模型使用。这样做的好处是可以把评论里的高频情绪词、场景词和音乐偏好词提取出来,不只是停留在播放量、收藏量这类数字指标上。
六、Hive离线分析
Hive部分是这个项目的数据分析核心。歌单数据量较大,字段维度也比较多,把数据导入Hive后,可以通过SQL按分类、来源、时间、标签数量、歌曲数量等维度进行统计。比如不同分类下歌单数量占比、不同分类的平均播放量和总播放量、各分类平均收藏量、评论量、分享量、每年新增歌单数量趋势、每月新增趋势、星期维度增长情况、歌曲出现频次Top20、歌曲加权热度Top20等,都可以通过离线聚合得到。
与直接在Python里临时统计相比,Hive方案更适合展示"大数据分析系统"的完整链路。数据进入HDFS后,表结构和SQL脚本可以沉淀下来,后续换数据或扩展字段时,不需要从零开始改展示页面。对于课程设计或毕业设计来说,这一层能够体现数据仓库思想,也能把Hadoop生态的应用价值展示出来。

图 6 Hive离线分析流程展示
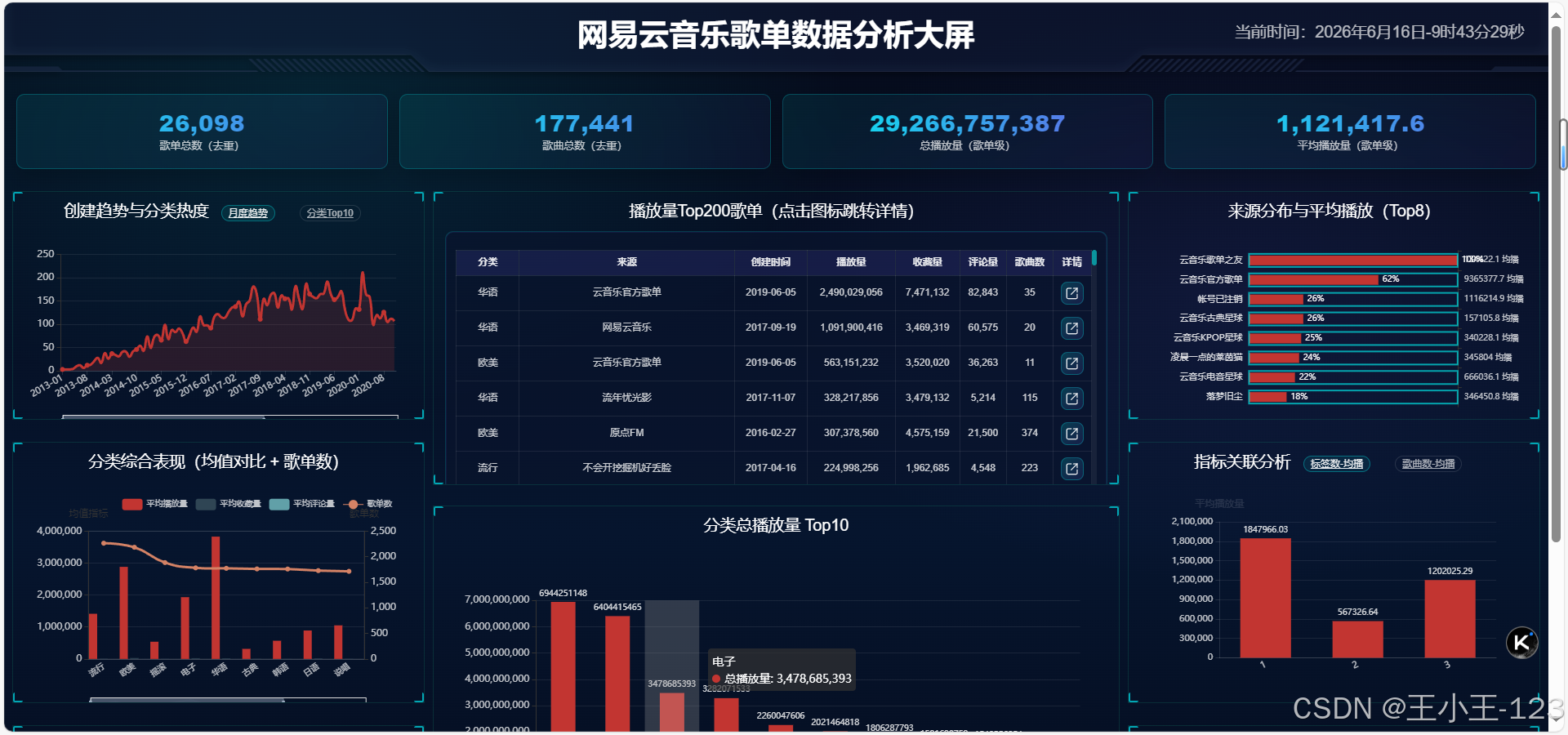
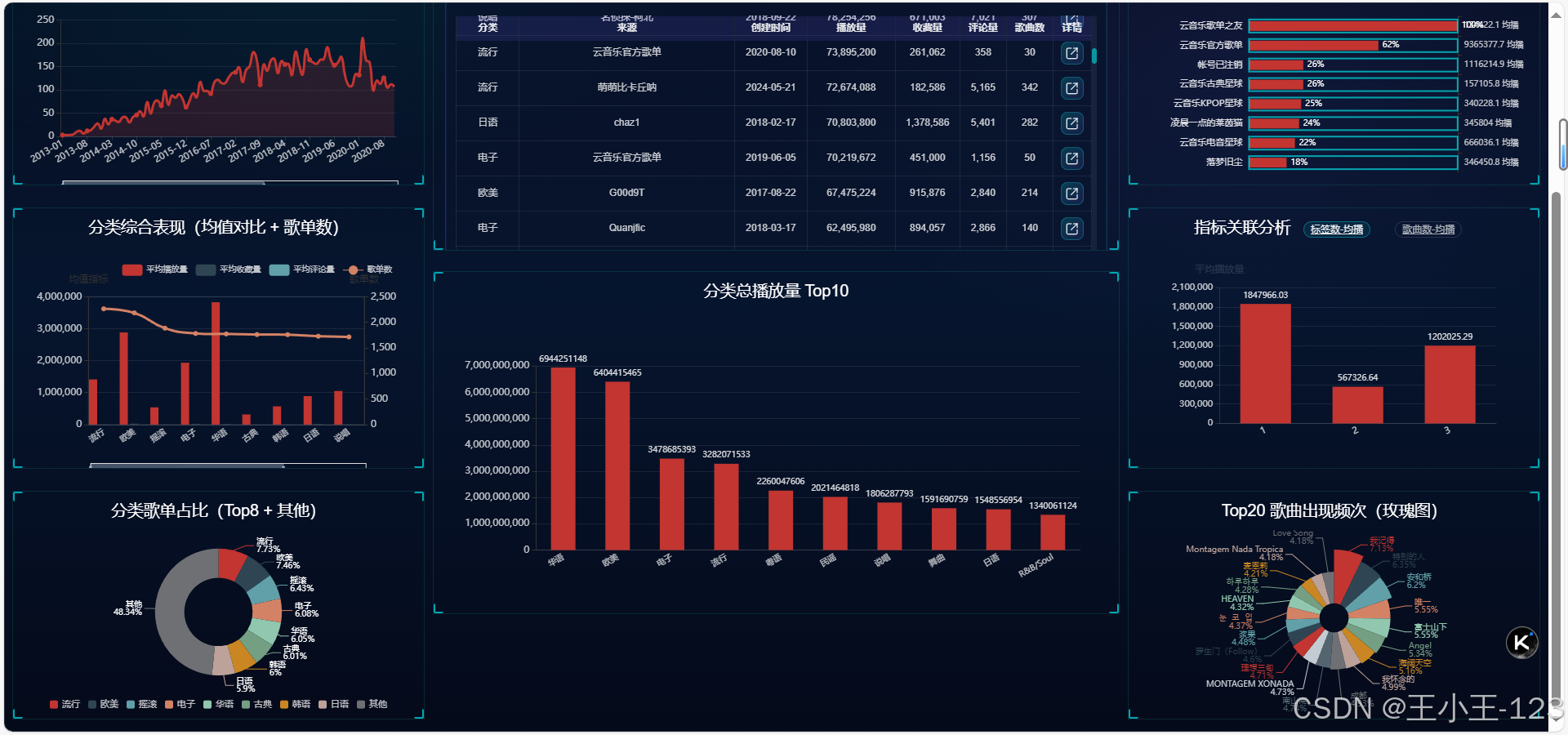
七、可视化大屏
展示层采用Flask作为后端入口,前端使用ECharts进行图表渲染。大屏页面更适合展示项目整体效果,页面中可以集中呈现分类播放表现、歌单来源分布、时间趋势、评论情感、热门标签词云等内容。相比单独打开一堆HTML文件,大屏的优势在于聚合展示,适合答辩、演示和项目宣传。
大屏目录中包含app.py、views、templates以及static资源,说明项目不是只停留在本地画图,而是已经做成了Web页面形态。页面资源中包含ECharts、词云组件、地图资源和样式文件,整体更接近一个可运行的数据可视化应用。公开展示时,我对界面做了脱敏化整理,保留图表布局和功能效果,不暴露真实路径、账号或其他不适合公开的信息。
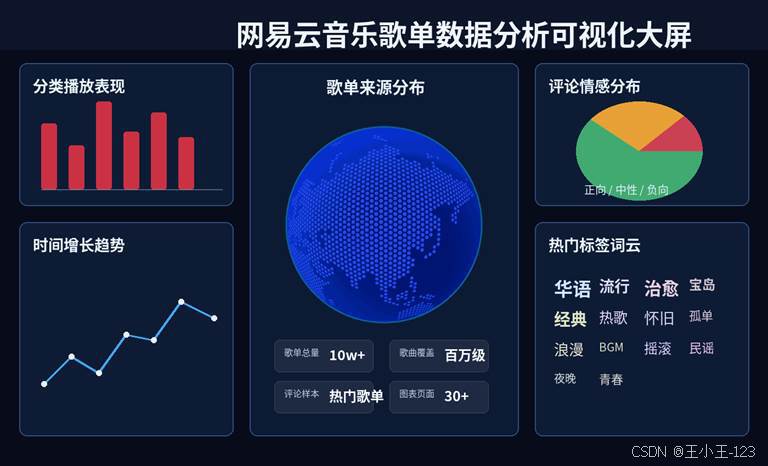
图 7 数据可视化大屏脱敏展示
八、单页图表
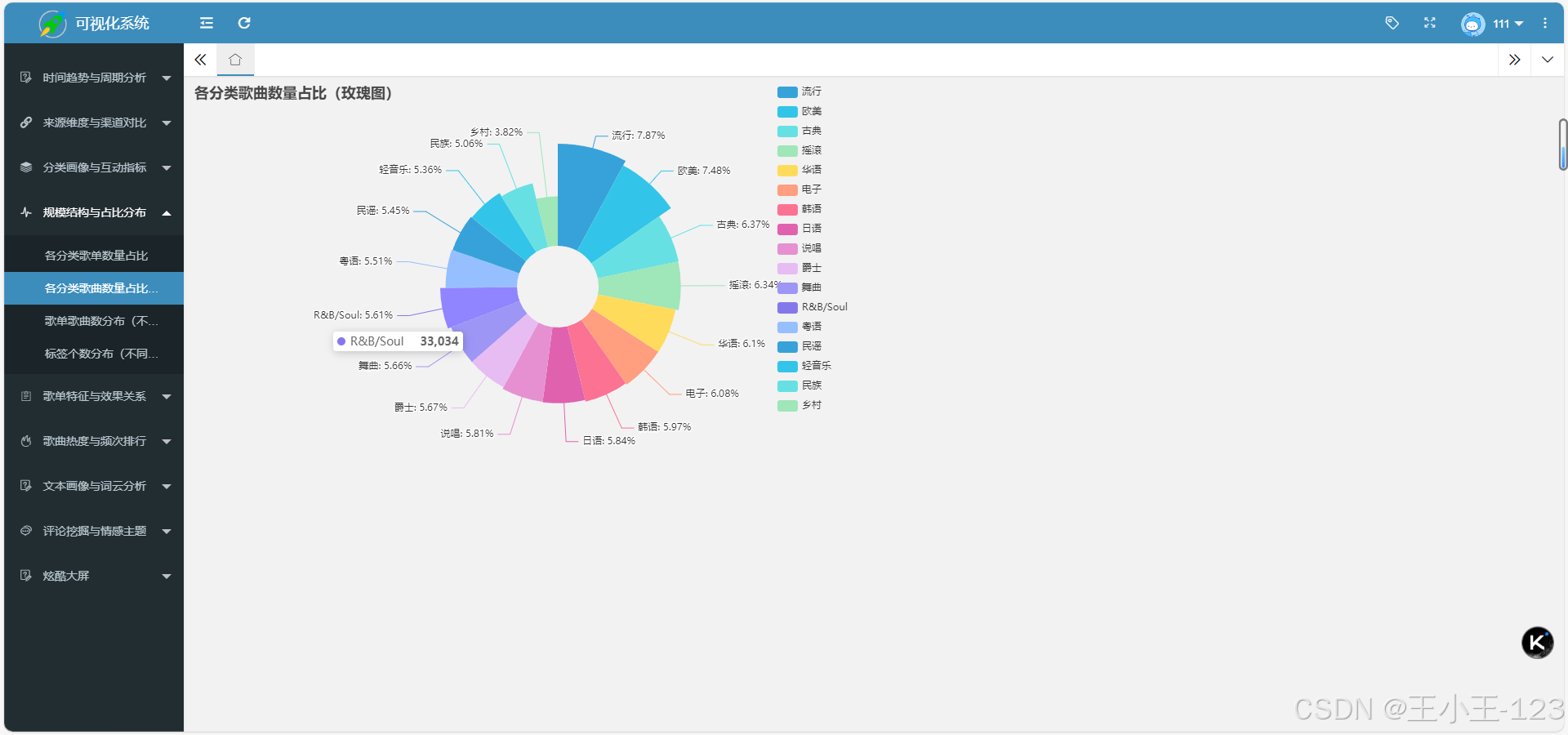
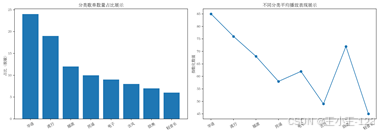
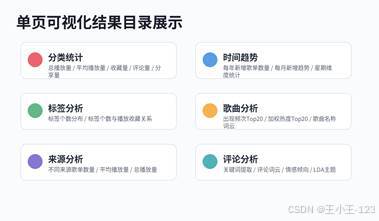
除了综合大屏,项目中还保留了大量单页可视化结果。单页图表的作用是把每一个分析主题独立展开,便于逐个查看。例如分类维度可以查看歌单数量占比、歌曲数量占比、各分类总播放量、平均播放量、平均收藏量、平均评论量和平均分享量;时间维度可以查看每年、每月、星期下的新增歌单情况;标签维度可以观察标签个数分布及其与平均播放量、平均收藏量之间的关系。
歌曲维度则更关注内容热度,包括歌曲出现频次Top20、歌曲加权热度Top20、歌曲名称词云、中文歌曲名称词云和非中文歌曲名称词云等。来源维度可以展示不同来源的歌单数量、总播放量和平均播放量。这些图表组合起来之后,项目不只是简单展示"哪些歌单热门",而是能从多个角度观察平台内容结构。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
| 图 8 分类统计图表效果展示 | 图 9 单页可视化结果目录展示 |
九、评论文本分析:从用户留言里提取内容氛围
评论分析是这个项目中比较有展示价值的一部分。播放量和收藏量反映的是行为结果,评论文本更接近用户真实表达。项目针对热门歌单评论做了关键词提取、词云展示、情感倾向分布和LDA主题分析。通过这些结果,可以看到评论区里高频出现的情绪词、记忆词、音乐场景词,也可以观察用户对某些歌单的共鸣点。
在处理评论时,分词和停用词非常关键。如果直接统计原始文本,高频词里会混入大量语气词、无意义词和重复符号。经过清洗后,词云图会更聚焦,情感分布也更适合用来展示整体评论倾向。LDA主题分析则可以把评论内容拆成若干主题方向,比如情绪共鸣、怀旧记忆、歌手讨论、场景陪伴、曲风标签等,方便进一步解读。

图 10 热门歌单评论分析结果展示
十、系统模块
项目可以拆成六个模块:数据采集层、数据处理层、离线计算层、分析挖掘层、展示应用层和资源沉淀层。采集层解决数据来源问题,处理层解决数据质量问题,离线计算层负责生成稳定指标,分析挖掘层负责对评论文本进行进一步加工,展示应用层负责大屏和单页图表呈现,资源沉淀层则保留脚本、SQL、Notebook和HTML结果,方便复盘和交付。
这一套结构的好处是每一层都可以单独替换或扩展。比如后续想把采集范围扩大到更多音乐分类,只需要扩展爬虫入口;想增加推荐功能,可以在现有歌单标签、歌曲频次和播放热度基础上继续建模;想接入数据库后台,也可以把Hive统计结果进一步同步到关系型数据库中,再由Flask接口统一读取。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
| 图 11 系统模块拆分展示 | 图 12 项目运行链路展示 |
十一、功能亮点
这个项目最值得保留的地方,是它没有只做单点功能。爬虫、Hive、Notebook、SQL、Flask、ECharts和评论文本分析都在同一套资料中出现,说明开发过程比较完整。对于需要展示项目的人来说,既能讲数据采集,又能讲Hive离线计算,还能讲可视化大屏和评论分析,内容层次比较丰富。
在展示时,可以重点突出三条主线。第一条是数据工程主线:网易云歌单数据采集、清洗、入仓和SQL聚合;第二条是数据分析主线:分类、时间、来源、标签、歌曲热度等指标分析;第三条是文本挖掘主线:评论关键词、词云、情感倾向和LDA主题。三条线合在一起,项目的完整性就比较清楚。
界面部分也有可继续优化的空间。比如可以把单页HTML进一步整合到统一导航中,把大屏指标改成数据库动态读取,把评论分析结果增加筛选条件,把某些图表增加联动效果。项目当前已经具备基础展示能力,后续如果继续打磨,可以向"音乐内容分析平台"或"音乐平台用户评论洞察系统"方向扩展。
每文一语
真正有价值的项目,不只是把数据抓下来,而是把杂乱的数据整理成可以被理解、被复现、被继续扩展的作品。