PageHelper会通过修改SQL语句的方式,在SQL后面动态拼接上limit语句
流程
ThreadLocal 隔离线程数据
PageHelper 是一个基于 MyBatis 的 拦截器(Interceptor) 实现的分页插件。它的核心原理是在 MyBatis 执行 SQL 之前,动态修改 SQL 语句,加入数据库方言相关的分页语法(比如 MySQL 的 LIMIT)。
PageHelper.startPage() 会将分页参数封装成 Page 对象,存入当前线程的 ThreadLocal
实现线程隔离,多并发请求之间分页参数互不干扰。
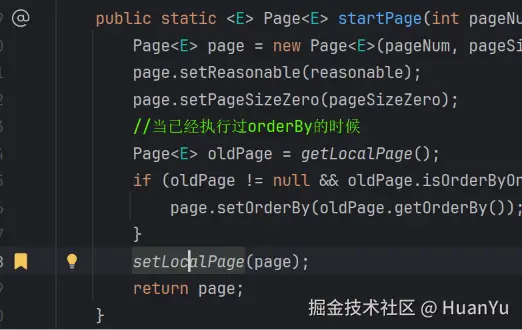
MyBatis 拦截器捕获查询请求
PageInterceptor 通过 @Intercepts 注解拦截 Executor 的 query 方法。
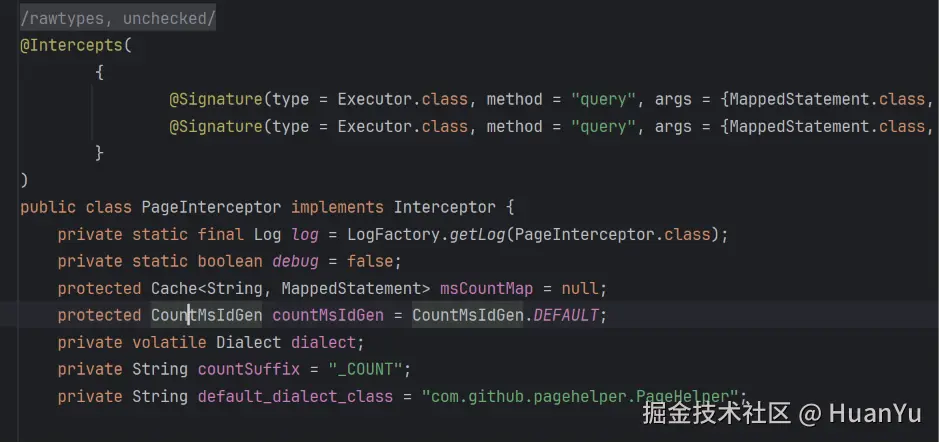
Executor是 MyBatis 的核心执行器接口,定义了所有 SQL 执行方法。
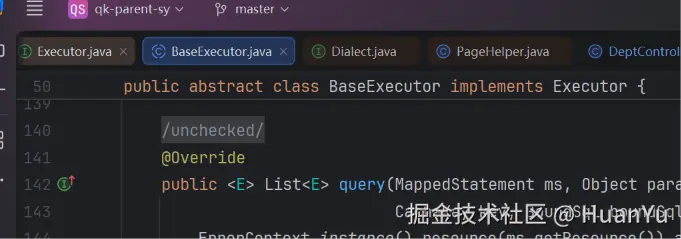
dialect.skip() 内部调用了 PageHelper.getLocalPage(),从 ThreadLocal 取分页参数
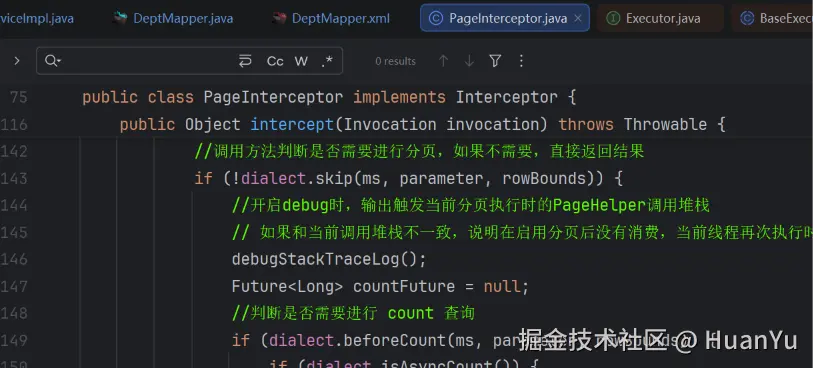
总数查询 + 分页数据查询
执行 COUNT 查询
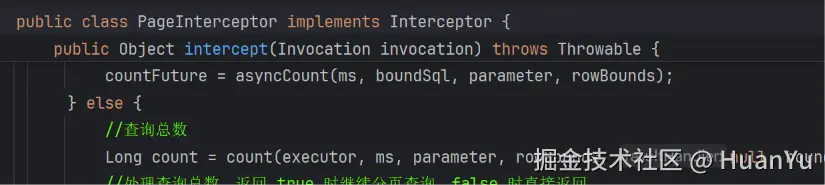
改写 SQL(加 LIMIT)+ 执行分页查询
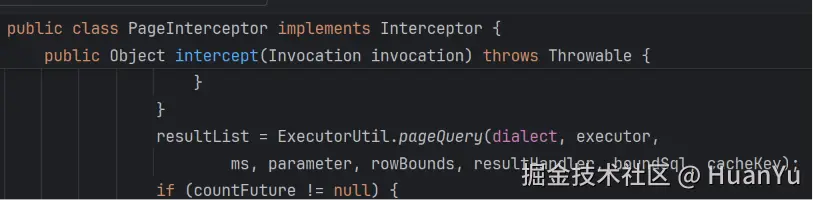
清理 ThreadLocal
PageHelper.startPage() 必须紧跟 Mapper 查询,拦截器只会在有分页参数的查询执行后 才会清理
ThreadLocal如果查询没执行,或执行前就异常了,
ThreadLocal不会被清理
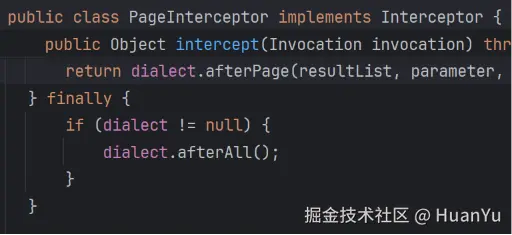
存储分页参数->拦截并改造 SQL->封装结果并清理现场
返回数据
ini
PageHelper.startPage(1,10)
List<Dept> list=deptMapper.selectDept(name, status);这里容易产生误区,以为返回的是单纯的Dept对象集合
此时deptMapper.selectDept(name, status)返回的对象为page对象,为list接口的一个实现类
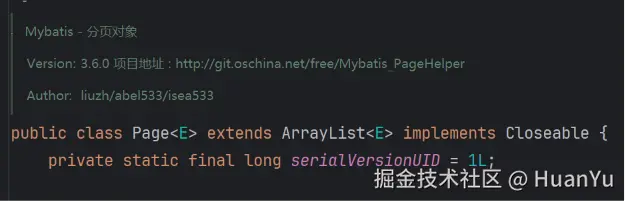
page对象中不仅有Dept数据集合,还有着页码等信息
ini
List<User> data = page.getResult();
long total = page.getTotal();实际项目中,更多的是pageInfo来接收数据:
ini
List<Dept> list=deptMapper.selectDept(name, status);
//PageInfo的构造器中将page的结果集合分页属性拆分
PageInfo<Dept> pageInfo=new PageInfo<>(list);
pageResult.setRows(pageInfo.getList());
pageResult.setTotal(pageInfo.getTotal());一是因为Controller层不应该直接依赖MyBatis持久层
二是Page中有很多前端不需要的属性,直接返回会污染接口。
而PageInfo 把 Page 的 20+ 个属性精简整理,只返回前端常用的