by 雪隐_上班了 from juejin.cn/user/143341...
欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可联系授权。
写在前面:为什么要折腾这件事?
事情是这样的。
我手头有一台 5060Ti 16G(这名字每次打出来都像显卡厂商喝多了随便起的),平时除了打游戏,总得让它干点正事吧?
于是我把目光投向了 Google 家新出的 Gemma-4-26b-A4B-QAT ------
一个 260 亿参数的量化模型,听起来就很能打。
再加上最近 Claude Code 火得不行,但 API 调用费钱包疼。
那能不能把 Claude Code 背后的模型换成我本地的开源模型?
说干就干。
1. 主角登场:google/gemma-4-26b-a4b-qat
先简单介绍一下这位"选手":
- 260 亿参数,但用了 A4B 架构(MoE 的一种),实际激活参数没那么多,省显存
- QAT(量化感知训练):不是训练完再砍精度,而是训练时就做好了量化准备,效果更好
- 来自 Google:Gemma 系列是 Google 的开源模型,血统纯正
说白了,这是一个能在消费级显卡上跑起来的、接近 GPT-4 级别智商的模型。
当然,前提是你要有 16G 显存------正好我有一张。
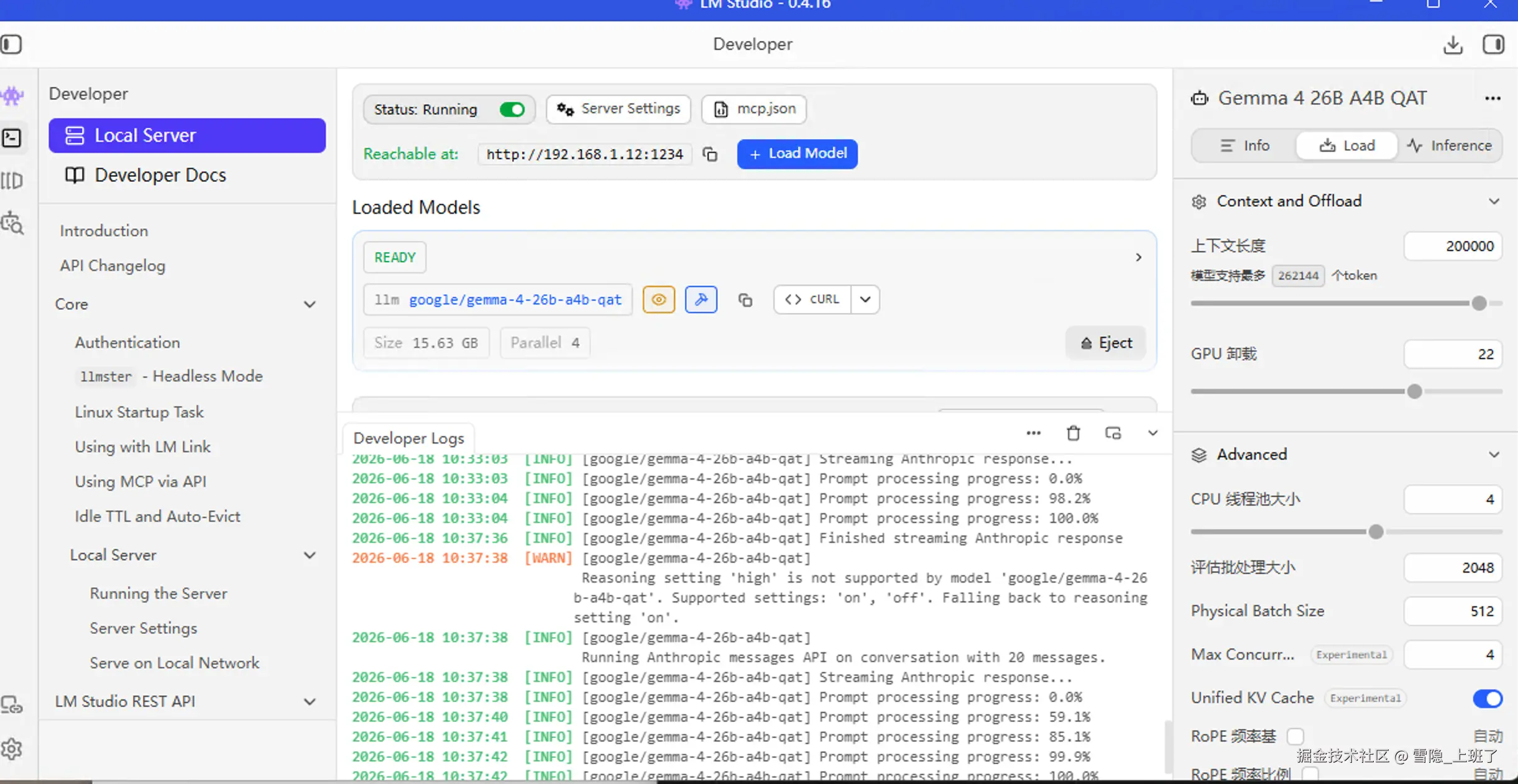
2. 安装:用 LM Studio 轻松搞定
过程不复杂,就是点几下鼠标的事。
首先去 LM Studio 下载桌面版,安装后打开。
在搜索框里输入 google/gemma-4-26b-a4b-qat,点击下载,等它跑完。
或者你也可以从 HuggingFace 手动下载模型文件,放到 LM Studio 的模型目录里(一般是 ~/.cache/lmstudio/models)。
然后加载模型,记得把上下文长度(Context Length)拉到 200K (后面会讲为啥)。
就这么简单,别在深夜操作,不然下载到一半你睡着了,醒来发现下完了但你忘了自己要干嘛。
对了,LM Studio 会帮你搞定依赖和 GPU 加速,省心得很。
3. 设置上下文长度:200K,不是 20K,是 200K!
为什么要设 200,000 tokens(200K)?
因为像 Claude Code、Cursor 这类 AI 编程助手,内部塞了一大堆系统提示词(system prompts) ,差不多 70K 左右。
如果上下文窗口不够大,这些内置提示词就把窗口撑爆了,你连"帮我写个 hello world"都发不出去。
而且 Claude Code 这类工具不仅仅要"文本能力",它还需要很强的 Agent 能力 ------
也就是说,模型得会自己决定调用什么工具、读什么文件、执行什么命令。
所以 200K 不是炫技,是刚需。
4. 安装 ccswitch:一键偷梁换柱
ccswitch 是一个神奇的工具,它的作用就是------
让 Claude Code 以为自己在调用 Claude API,实际上背后跑的是你本地的模型。 APIkey 随便写
简单说就是:
Claude Code:"我要调用 Claude 3.5!"
ccswitch:"好的好的,请稍等......"(转头把请求发给了你的 Gemma-4)
Claude Code:"嗯,回答得不错,继续工作。"
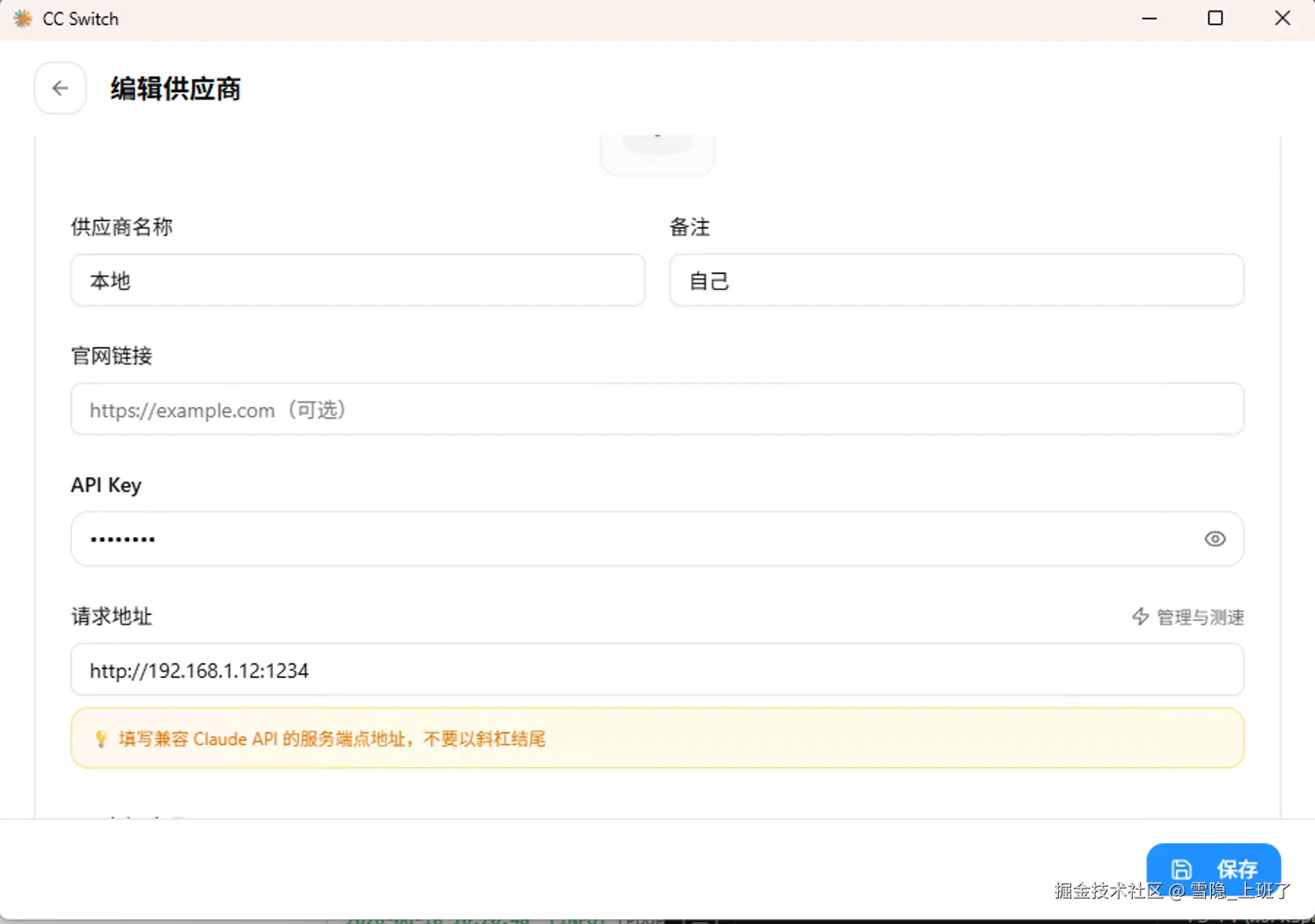
安装过程不复杂,git clone 下来,装依赖,配置一下环境变量就行。
如果你连这都搞不定......那这篇文章可能不适合你(手动狗头)。
5. 切换:把 Claude Code 的"灵魂"换成 Gemma-4
配置完 ccswitch 之后,你的 Claude Code 就"变心"了。
表面上它还是那个熟悉的 Claude Code 界面,实际上背后的模型已经换成了你本地的 Gemma-4-26b。
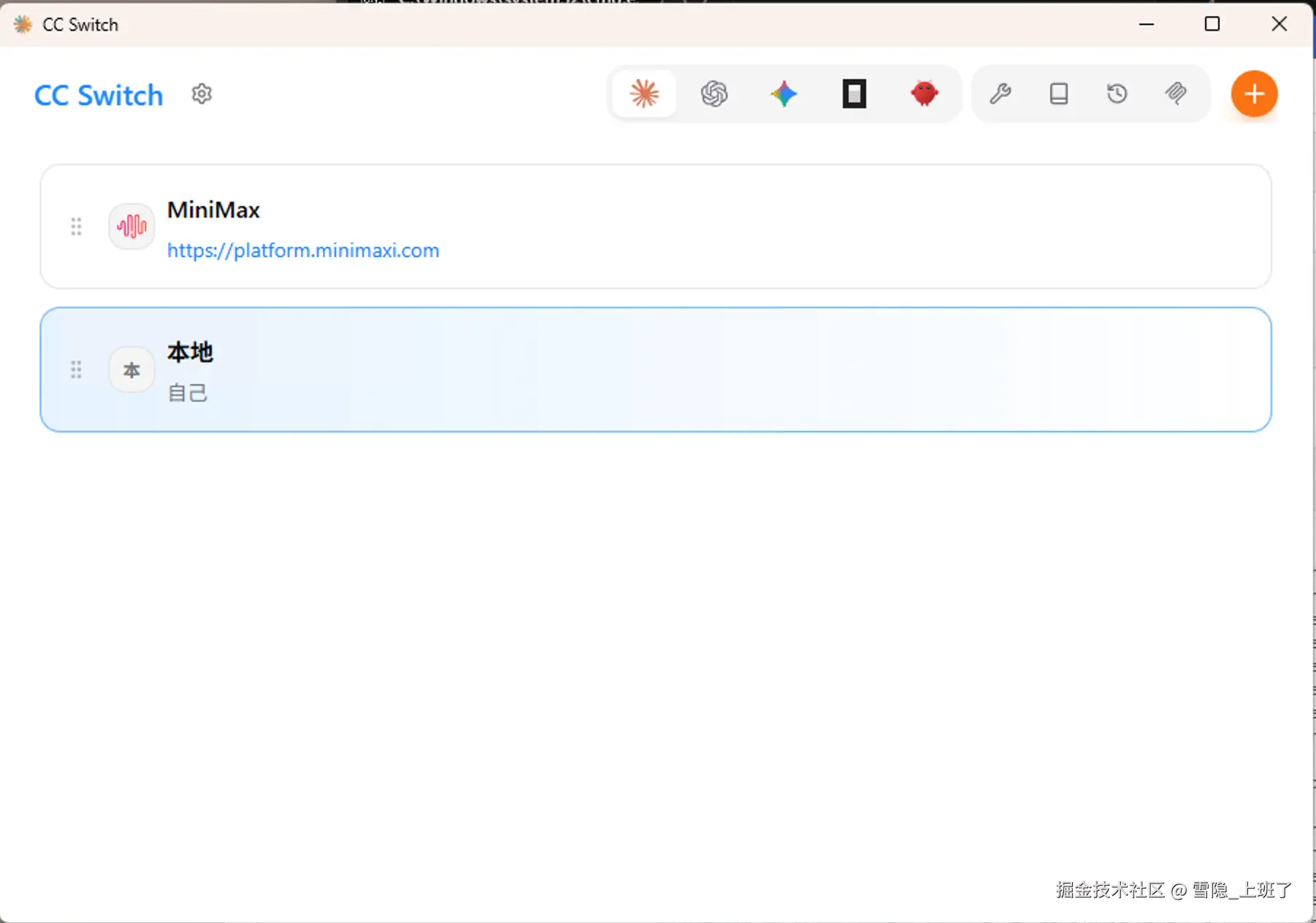
这时候你就可以:
- 不花一分 API 钱
- 在断网环境下继续写代码
- 不怕敏感代码被上传到云端
当然,代价也是有的------速度慢一点,智商低一点 。
后面会细说。
6. 实战检验:让它写个贪吃蛇
光说不练假把式。
我直接给 Claude Code(背后其实是 Gemma-4)下了一个指令:
"帮我写一个贪吃蛇小游戏,HTML + JavaScript,能跑就行。"
一顿折腾之后,它居然真的写出来了!
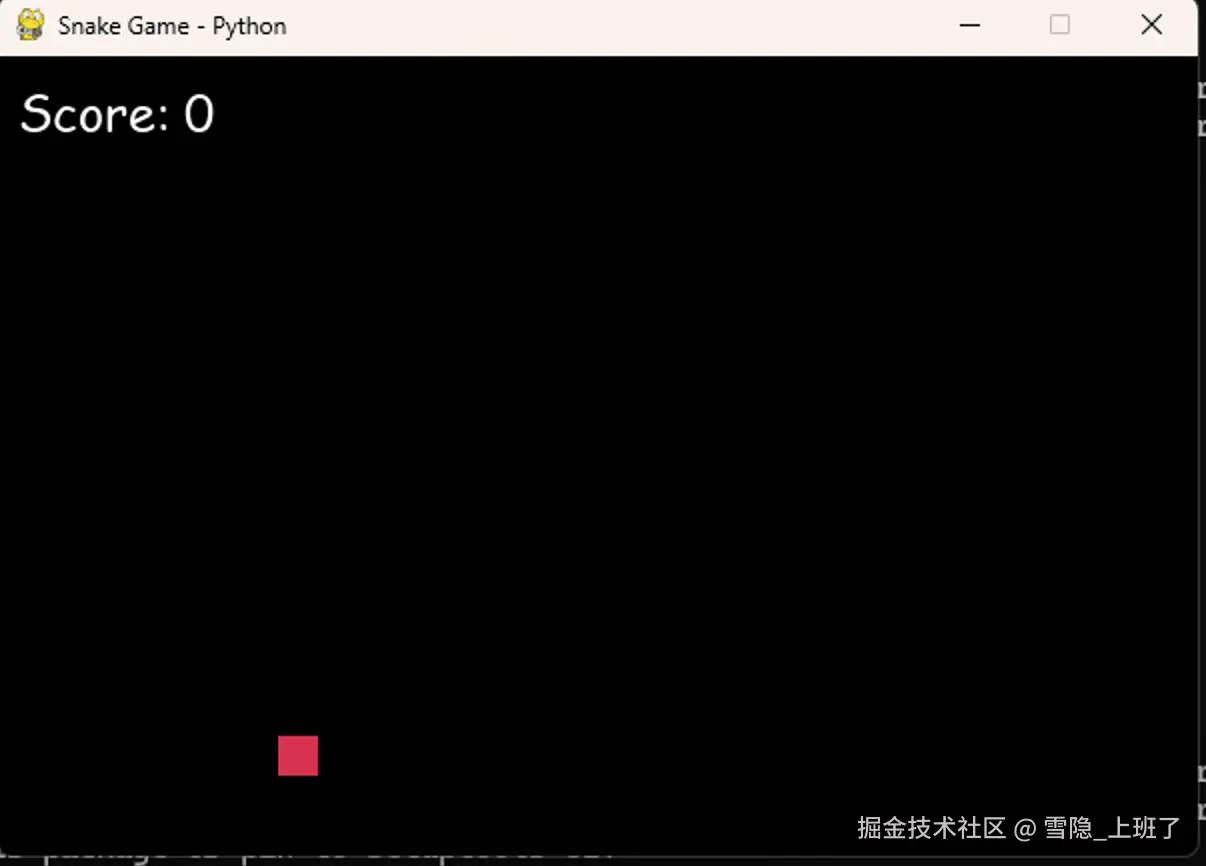
当然,第一次跑的时候有点小 bug------
蛇不吃食物,或者吃了不长大,或者直接穿墙。
没关系,把报错贴给它,让它自己改。
来回两三次,居然真的能玩了。
本地模型能写到这个程度,说实话我是有点意外的。
7. 资源占用:16G 显存,一滴不剩
来看看跑起来之后的情况:

- 16G 显存,全满
- 1.5G 共享内存也在用
基本上,这张 5060Ti 算是被榨干了。
速度呢?
大概 20 tokens / 秒 。
什么概念?
你打一行字,它给你蹦一个词。
能忍,但绝对算不上"流畅"。
如果你想让它帮你写一个完整项目,建议先去泡杯茶,再回来。
写在最后:折腾的意义是什么?
你可能会问:
"开源量化模型 + 本地部署,又慢又蠢,图啥?"
第一,有些地方真的没网
不是每个人都生活在 5G 全覆盖的大城市。
有些开发环境就是纯内网 ,连不上任何云 API。
这时候,本地模型就是唯一的救命稻草。
第二,有些代码真的不能上传
写金融系统、内部工具、涉密项目的时候,
你敢把代码贴给云端 API?
反正我不敢。
本地模型虽然笨一点,但至少你的代码不会出现在别人的训练数据里。
第三,慢和蠢,有时反而是好事
太依赖大模型,是一把双刃剑。
如果你用 GPT-4 写代码,刷刷刷就出来了,你可能根本看不懂它在写什么 。
出了问题,你也不知道怎么改。
但本地模型不一样------它写得不快,偶尔还犯错,
你必须亲自读它的代码、理解它的逻辑、帮它 debug 。
这个过程中,你反而真正掌握了代码的每一个细节。
这不是"退步",这是强制自己保持清醒。
所以,我的结论很简单:
- 如果你追求效率 + 质量,用云端 API,没毛病。
- 如果你追求隐私 + 掌控 + 不花钱,本地部署(尤其是用 LM Studio 这种顺手工具),值得一试。
至于"慢"和"蠢"?
那是你学习路上最好的刹车片。
好了,折腾完了,我去写下一个项目了。
下次见(如果显卡没烧的话)。