CVPR 2025 | Speedy-Splat:基于稀疏像素与稀疏基元的快速3DGS
一、论文信息
论文题目:Speedy-Splat: Fast 3D Gaussian Splatting with Sparse Pixels and Sparse Primitives
论文作者:Alex Hanson、Allen Tu、Geng Lin、Vasu Singla、Matthias Zwicker、Tom Goldstein
发表单位:University of Maryland, College Park
发表会议:CVPR 2025
二、论文主要贡献
本文针对3DGS存在的渲染效率受限、模型过参数化严重、训练开销大的问题,提出了 Speedy-Splat 高效加速框架,在 Mip-NeRF 360、Tanks & Temples、Deep Blending 三大标准数据集上实现了平均 6.71 倍的渲染加速、1.47 倍的训练提速,仅带来可忽略的画质损失,为移动端等资源受限设备上的实时高质量 3D 新视角渲染提供了高效可行的解决方案。

图 1 在 Tanks & Temples 卡车场景中,与 3DGS相比,将高斯数量减少了超过 90%,仅略微降低了 PSNR,并将渲染速度加快了 6.2 倍。此外,我们将训练时间加快了 1.38 倍
三、创新点
1、SnugBox:一种用于计算高斯 - 瓦片包围盒相交关系的精确算法。
2、AccuTile:SnugBox 的扩展算法,用于精确计算高斯与瓦片的相交关系。
3、Soft Pruning:一种在模型致密化阶段对高斯元进行剪枝的增强方法。
4、Hard Pruning:一种在致密化阶段完成后对高斯元进行剪枝的增强方法。
三、相关工作
3.1 3DGS技术概述
3DGS 是一种以可微 3D高斯元为基元,通过 参数化点基表示 对场景进行建模的技术。给定一组真值训练图像 Igt={Ii∈RH×W}i=1KI_{gt}=\{I_{i} \in \mathbb{R}^{H ×W}\}{i=1}^{K}Igt={Ii∈RH×W}i=1K,该方法首先通过运动恢复结构(Structure from Motion, SfM)生成稀疏点云,以此作为 3D 高斯元的初始均值(中心位置),完成场景初始化;同时将估计得到的相机位姿 Pgt={ϕi∈R3×4}i=1KP{gt}=\{\phi_{i} \in \mathbb{R}^{3 ×4}\}{i=1}^{K}Pgt={ϕi∈R3×4}i=1K 与对应图像配对,用于后续的场景优化。每个 3D 高斯基元 GiG{i}Gi由 5 类参数定义:3 个几何参数 ------ 均值 μi∈R3\mu_{i} \in \mathbb{R}^{3}μi∈R3、缩放si∈R3s_{i} \in \mathbb{R}^{3}si∈R3、旋转 ri∈R4r_{i} \in \mathbb{R}^{4}ri∈R4;2 个颜色参数 ------ 视角相关的球谐函数系数 hi∈R16×3h_{i} \in \mathbb{R}^{16 ×3}hi∈R16×3、不透明度 σi∈R\sigma_{i} \in \mathbb{R}σi∈R。所有高斯元的参数集合可表示为:
G={Gi={μi,si,ri,hi,σi}}i=1N,(1) \mathcal{G}=\left\{\mathcal{G}{i}=\left\{\mu{i}, s_{i}, r_{i}, h_{i}, \sigma_{i}\right\}\right\}_{i=1}^{N}, \quad(1) G={Gi={μi,si,ri,hi,σi}}i=1N,(1)
其中 N 为模型中的高斯元总数。
给定相机位姿 ϕ\phiϕ,场景渲染的过程为:将所有高斯元投影至图像空间,对每个像素执行 alpha 混合。模型通过随机梯度下降优化图像重建损失,损失函数定义为:
L(G∣ϕ,Igt)=∥IG(ϕ)−Igt∥1+LD−SSIM(IG(ϕ),Igt)(2) L\left(\mathcal{G} | \phi, I_{gt}\right)=\left\| I_{\mathcal{G}}(\phi)-I_{gt}\right\| {1}+L{D-SSIM}\left(I_{\mathcal{G}}(\phi), I_{gt}\right)\tag{2} L(G∣ϕ,Igt)=∥IG(ϕ)−Igt∥1+LD−SSIM(IG(ϕ),Igt)(2)
其中 IG(ϕ)I_{\mathcal{G}}(\phi)IG(ϕ)为相机位姿 ϕ\phiϕ下的渲染图像。
在优化过程中,场景会定期执行致密化操作:对不确定性高的高斯元进行克隆与分裂,同时移除尺寸过大、完全透明的高斯元;此外,还会定期重置高斯元的不透明度。
3.2 3DGS 渲染细节
3DGS 采用基于瓦片的渲染策略,将待渲染图像划分为 16×16 像素的瓦片。每个高斯元被投影至图像空间后,会计算其与这些瓦片的相交关系;随后对生成的高斯-瓦片映射进行排序,按深度对高斯元排序,最终用于逐像素渲染。
渲染的运行时开销主要由 6 个核心函数决定。表 1 通过实验统计了所有场景下各函数的平均执行时间,同时展示了本文方法带来的性能提升,后续小节将对每个函数进行详细说明。

表1. 第5.1节中各场景下每个函数的平均执行时间(毫秒)表头依次为预处理、前缀和、带键复制、基数排序、瓦片范围识别、渲染、整体耗时。每行的操作会累积应用到所有后续行。对于每个模型,通过对三次运行中每次渲染测试集20次的执行时间取平均来收集准确的测量结果,以减少方差。最快和第二快的时间已用颜色标注。
3.2.1 预处理
预处理核采用并行化设计,每个线程处理单个高斯元 GiG_{i}Gi,核心计算内容为:GiG_{i}Gi到图像空间的 2D 投影,以及该高斯元相交的瓦片数量。
具体计算流程为:通过观察变换矩阵 WWW与透视投影,将均值 μi\mu_{i}μi投影至图像空间,得到 2D 均值 μi2D\mu_{i_{2D}}μi2D与深度值,存储供后续处理使用;将尺度参数 sis_{i}si与旋转参数 rir_{i}ri分别转换为对角尺度矩阵 SiS_{i}Si与旋转矩阵RiR_{i}Ri,进而定义 3D 协方差矩阵:
∑i3D=RiSiSiTRiT(3) \sum_{i_{3D}}=R_{i} S_{i} S_{i}^{T} R_{i}^{T} \tag{3} i3D∑=RiSiSiTRiT(3)
3D 协方差矩阵通过下式完成投影:
∑^i3D=JW∑i3DWTJT(4) \hat{\sum}{i{3D}}=J W \sum_{i_{3D}} W^{T} J^{T}\tag{4} ∑^i3D=JWi3D∑WTJT(4)
其中 J 为透视投影一阶近似的雅可比矩阵。舍弃 ∑^i3D\hat{\sum}{i{3D}}∑^i3D的最后一行与最后一列,即可得到 2D 协方差矩阵 ∑i2D\sum_{i_{2D}}∑i2D。
随后,通过 ∑i2D\sum_{i_{2D}}∑i2D 的最大特征值计算该高斯元 GiG_{i}Gi 相交的瓦片数量(如图 2a 所示),同时计算 ∑i2D−1\sum_{i_{2D}}^{-1}∑i2D−1,以及由变换矩阵 W 与球谐系数 hih_{i}hi 推导的视角相关颜色 cic_{i}ci,三者均存储供后续处理使用。
3.2.2 排序
预处理完成后,通过 4 个函数对高斯元进行处理,为逐像素渲染做准备:
- 前缀和(InclusiveSum):一种 CUDA 基元,对所有高斯元的相交瓦片数量计算前缀和,为高斯 - 瓦片映射分配键数组与值数组。
- 带键复制(duplicateWithKeys):一个高斯并行核,重新计算高斯 - 瓦片相交关系,为每个相交瓦片生成对应的键,键的内容为瓦片索引与高斯深度。
- 基数排序(RadixSort):一种 CUDA 基元,对键数组进行排序,使高斯索引先按瓦片、再按深度有序排列。
- 瓦片范围识别(identifyTileRanges):一个跨键数组并行的核,在像素渲染前对排序后的键做后处理。
3.2.3 渲染
渲染核采用像素级并行设计。对每个像素 p,加载其对应瓦片内的所有高斯元,并按基数排序确定的深度顺序依次处理。每个高斯元的 alpha 值计算如下:
αi(p)=σigi(p)(5) \alpha _{i}(p)=\sigma {i}g{i}(p) \tag{5} αi(p)=σigi(p)(5)
其中gig_{i}gi 为投影后的 2D 高斯在像素 p 处的取值,定义为:
gi=eq,q=−12(p−μi2D)∑i2D−1(p−μi2D)T(6) g_{i}=e^{q}, q=-\frac{1}{2}\left(p-\mu_{i_{2D}}\right) \sum_{i_{2D}}^{-1}\left(p-\mu_{i_{2D}}\right)^{T} \tag{6} gi=eq,q=−21(p−μi2D)i2D∑−1(p−μi2D)T(6)
当 αi>1255\alpha_{i}>\frac{1}{255}αi>2551 时,该高斯元会被纳入像素颜色 CCC 的 alpha 合成计算,合成公式为:
C(p)=∑i∈Nciαi(p)∏j=1i−1(1−αj(p))(7) C(p)=\sum_{i \in \mathcal{N}} c_{i} \alpha_{i}(p) \prod_{j=1}^{i-1}\left(1-\alpha_{j}(p)\right)\tag{7} C(p)=i∈N∑ciαi(p)j=1∏i−1(1−αj(p))(7)
四、方法
提出的 Speedy-Splat 方法,源于对 3DGS渲染中两处核心效率瓶颈的关键洞察:第一,高斯溅射算法严重高估了高斯元在图像中的有效范围;第二,其他近期剪枝相关研究所示,3DGS 模型存在严重的过参数化问题。
4.1 精确瓦片相交计算
3DGS 通过计算高斯元GiG_iGi投影后 2D 协方差矩阵∑i2D\sum_{i_{2D}}∑i2D的最大特征值λmax\lambda_{max}λmax,确定其相交瓦片:所有与以μi2D\mu_{i_{2D}}μi2D为中心、半径为
r=⌈3λmax⌉(8) r=\left\lceil 3 \sqrt{\lambda_{max }}\right\rceil \tag{8} r=⌈3λmax ⌉(8)
的圆形内接正方形相交的瓦片,都会被分配给该高斯元。这种方法在计算中完全忽略了高斯元的不透明度σi\sigma_iσi,普遍高估了高斯元的有效范围,如图 2a 所示。
而如图 2b 所示,高斯元GiG_iGi的实际有效范围,由其 alpha 值αi\alpha_iαi的阈值决定。具体而言,当像素ppp对应的αi<1255\alpha_i<\frac{1}{255}αi<2551时,高斯元GiG_iGi对该像素的渲染结果无任何贡献。通过在瓦片相交计算中采用这一实际有效范围,能够大幅缩减每个高斯元关联的瓦片数量。
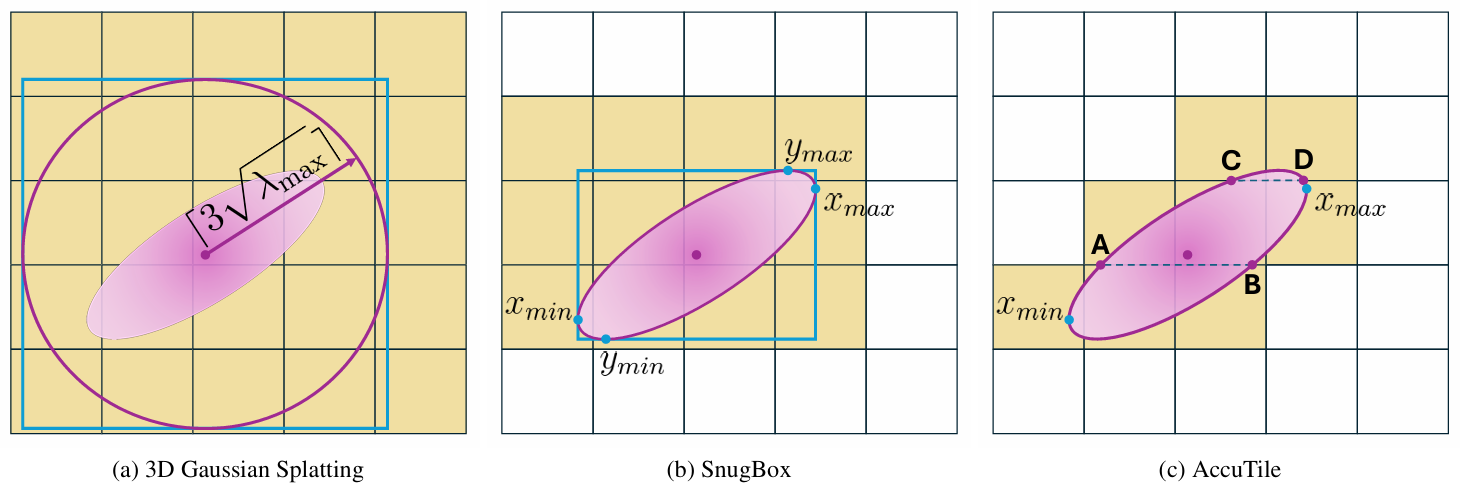
图 2 不同方法的高斯瓦片分配结果(a)3DGS:当瓦片与半径为⌈3λmax⌉\left\lceil 3 \sqrt{\lambda_{max }}\right\rceil⌈3λmax ⌉的圆的内接正方形相交时,便将该高斯分配给此瓦片。
(b) 本文 SnugBox 方法:当瓦片与公式 (14) 所定义椭圆的轴对齐极值所构成的紧致包围盒相交时,便将该高斯分配给此瓦片。
© 本文 AccuTile 方法:仅当瓦片通过算法 1 判定与椭圆实际相交时,才将该高斯分配给此瓦片;算法通过遍历 SnugBox 给出的矩形瓦片范围的短边,计算出最小与最大瓦片。在本示例中,AccuTile 算法沿瓦片行方向遍历,仅需处理xminx_{min}xmin、xmaxx_{max}xmax以及 A、B、C、D 这几个关键点。
将 alpha 贡献阈值直接代入公式 5,即可确定高斯元GiG_iGi在像素维度的最远有效边界。对公式进行整理可得:
2log(255σi)=(p−μi2D)∑i2D−1(p−μi2D)T.(9) 2 log (255\sigma _{i})=(p-\mu {i{2 D}})\sum {i{2 D}}^{-1}(p-\mu {i{2 D}})^{T}.\tag{9} 2log(255σi)=(p−μi2D)i2D∑−1(p−μi2D)T.(9)
可将公式改写为如下形式:
p=(pxpy),μi2D=(μxμy),∑i2D−1=(abbc)(10) p=\left( \begin{array} {c}{p_{x}}\\ {p_{y}}\end{array} \right) ,\mu {i{2D}}=\left( \begin{array} {c}{\mu _{x}}\\ {\mu _{y}}\end{array} \right) ,\sum {i{2D}}^{-1}=\left( \begin{array} {ll}{a}&{b}\\ {b}&{c}\end{array} \right) \tag{10} p=(pxpy),μi2D=(μxμy),i2D∑−1=(abbc)(10)
设定阈值t与中心对齐坐标xdx_dxd、ydy_dyd:
t=2log(255σi)(11) t=2 log \left(255 \sigma_{i}\right) \tag{11} t=2log(255σi)(11)
xd=px−μx(12) x_{d}=p_{x}-\mu_{x} \tag{12} xd=px−μx(12)
yd=py−μy(13) y_{d}=p_{y}-\mu _{y} \tag{13} yd=py−μy(13)
由此可得到像素有效范围需满足的椭圆方程:
t=axd2+2bxdyd+cyd2(14) t=a x_{d}^{2}+2 b x_{d} y_{d}+c y_{d}^{2} \tag{14} t=axd2+2bxdyd+cyd2(14)
方法利用该像素有效范围,缩减每个高斯元对应的高斯 - 瓦片映射数量。为此,提出两种计算精确瓦片相交关系的方法:第一种是 SnugBox 算法,为每个高斯元计算紧致包围盒;第二种是 AccuTile 算法,在 SnugBox 的基础上进一步识别高斯元相交的精确瓦片集合。
4.1.1 SnugBox 算法
提出的 SnugBox 方法,利用上述椭圆有效范围,计算轴对齐包围盒,从而更精准地判定与高斯元GiG_iGi相交的瓦片。为推导该包围盒,对公式 14 进行变形,求解ydy_dyd:
yd=−bxd±(b2−ac)xd2+tcc(15) y_{d}={\frac {-bx_{d}\pm {\sqrt {(b^{2}-ac)x_{d}^{2}+tc}}}{c}}\tag{15} yd=c−bxd±(b2−ac)xd2+tc (15)
为求解 y 轴方向包围盒的边界yminy_{min}ymin与ymaxy_{max}ymax,需要找到满足∂yd/∂xd=0\partial y_{d} / \partial x_{d}=0∂yd/∂xd=0的xdx_dxd取值,将这些xdx_dxd值记为xdargax_{d_{arga}}xdarga,即ydy_dyd取极小值和极大值对应的自变量。对公式 15 求导并求解xdargax_{d_{arga}}xdarga,可得:
xdargs=±−b2t(b2−ac)a(16) x_{d_{a r g s}}= \pm \sqrt{\frac{-b^{2} t}{\left(b^{2}-a c\right) a}} \tag{16} xdargs=±(b2−ac)a−b2t (16)
将xdargax_{d_{arga}}xdarga代入公式 15,再叠加μy\mu_yμy,即可得到yminy_{min}ymin与ymaxy_{max}ymax。基于公式 14 的对称性,可交换ydy_dyd与xdx_dxd、常数a与c,将公式 15 和 16 改写为关于xdx_dxd与ydargy_{d_{arg}}ydarg的形式,进而求解 x 轴方向包围盒的边界xminx_{min}xmin与xmaxx_{max}xmax。
确定包围盒边界后,沿用 3DGS 的处理逻辑,将边界值除以瓦片尺寸、取整并裁剪至图像边界,转换为对应的瓦片索引。如图 2 所示,与原生 3DGS 相比,SnugBox 能够生成紧致度大幅提升的包围盒。同时,该算法仅需执行固定次数的运算,计算开销极低,且仅在渲染管线中被调用两次 ------ 一次是在预处理阶段统计每个高斯元相交的瓦片数量,另一次是在带键复制阶段生成高斯 - 瓦片映射数组。表 1 的实验结果表明,SnugBox 提升了所有下游环节的执行效率,实现了平均 1.82 倍的整体渲染加速。
4.1.2 AccuTile 算法
算法 1 概述了提出的 AccuTile 算法,该算法在 SnugBox 的基础上进一步扩展,用于识别与高斯元相交的精确瓦片。算法的输入为 SnugBox 生成的紧致包围盒,及其对应的矩形瓦片范围(分别对应图 2b 中的蓝色方框与黄色瓦片)。AccuTile 会根据包围盒的短边维度,选择遍历该瓦片范围的行或列,以判定与高斯元实际相交的精确瓦片。具体而言,我们先计算给定行或列内椭圆的最小与最大有效边界,再将这些边界点转换为对应的相交瓦片,最小与最大瓦片之间的所有瓦片均与椭圆相交。
算法 1 AccuTile 算法为简化表述,此处概述的算法针对 SnugBox 瓦片范围包围盒的行进行遍历,与图 2c 的示例一致。实际实现中,算法会沿瓦片范围的短边执行。下标(t、b、l、r)分别代表上、下、左、右四个边界。

AccuTile 的核心在于,计算每行 / 列内椭圆的最小与最大有效边界,每次迭代仅需计算两个点。椭圆曲线仅有的拐点,是 SnugBox 计算得到的包围盒极值点。若其中一个或两个拐点位于当前瓦片行 / 列内,则它们即为该行 / 列内椭圆的有效边界极值;若两个拐点均不在当前行 / 列内,则椭圆在该行 / 列边界上的取值呈单调递增或递减趋势,极值点必然位于该行 / 列的其中一条边界线上。由于前一行 / 列的上边界与后一行 / 列的下边界共享,因此每次迭代仅需计算椭圆与下一条边界线的交点即可。综上,AccuTile 算法的瓦片计数时间复杂度与瓦片范围的短边长度成正比,瓦片处理时间复杂度与相交瓦片数量成正比。
图 2 展示了 AccuTile 如何将 SnugBox 生成的紧致包围盒,进一步收缩为高斯元实际相交的精确瓦片集合。从底部开始遍历 SnugBox 得到的瓦片范围行(图 2b):最下方瓦片行的下边界低于包围盒下边界,因此无需计算初始交点;该行的上边界低于包围盒上边界,因此通过公式 15 计算交点 A 与 B。由于xminx_{min}xmin位于该行内,因此将其设为该行椭圆的最小有效边界emine_{min}emin,而 B 为极值点,因此设为最大有效边界emaxe_{max}emax,最终该行的瓦片范围为包含xminx_{min}xmin的瓦片至包含 B 的瓦片。对于下一行,我们保留交点 A 与 B,同时计算上边界的交点 C 与 D;此时 A 与xmaxx_{max}xmax分别位于该行内,因此分别设为该行的emine_{min}emin与emaxe_{max}emax,对应的瓦片即为该行的有效瓦片范围。对于最后一行,我们保留交点 C 与 D,由于该行的上边界高于包围盒上边界,无需额外计算交点,因此该行的瓦片范围为 C 与 D 对应的瓦片之间的所有瓦片。
从图 2b 到图 2c,瓦片数量得到了进一步缩减,远少于原生 3DGS 方法(图 2a)的瓦片数量。表 1 的实验结果表明,AccuTile 进一步提升了所有下游环节的执行效率,最终实现了平均 1.99 倍的整体渲染加速。
4.2 高效剪枝方法
PUP 3D-GS 是一种通过量化每个高斯元对训练视图的敏感度,移除敏感度最低的固定比例高斯元的剪枝方法。其敏感度通过对L2L_2L2损失的海森矩阵近似计算得到:
H=∇G2L2=∑ϕ∈Pgt∇GIG(ϕ)∇GIG(ϕ)T,(17) H=\nabla_{\mathcal{G}}^{2} L_{2}=\sum_{\phi \in \mathcal{P}{g t}} \nabla{\mathcal{G}} I_{\mathcal{G}}(\phi) \nabla_{\mathcal{G}} I_{\mathcal{G}}(\phi)^{T}, \tag{17} H=∇G2L2=ϕ∈Pgt∑∇GIG(ϕ)∇GIG(ϕ)T,(17)
其中∇GIG(ϕ)\nabla_{G} I_{G}(\phi)∇GIG(ϕ)为相机位姿ϕ\phiϕ下,渲染图像IGI_GIG对所有高斯元参数的梯度。PUP 3D-GS证明,当L1L_1L1残差趋近于 0 时,该海森矩阵计算结果是精确的。
通过将海森矩阵拆分为仅捕捉高斯元内部参数关系的块对角元素,可得到每个高斯元对应的敏感度:
Hi=∑ϕ∈Pgt∇GiIG(ϕ)∇GiIG(ϕ)T(18) H_{i}=\sum_{\phi \in \mathcal{P}{g t}} \nabla{\mathcal{G}{i}} I{\mathcal{G}}(\phi) \nabla_{\mathcal{G}{i}} I{\mathcal{G}}(\phi)^{T} \tag{18} Hi=ϕ∈Pgt∑∇GiIG(ϕ)∇GiIG(ϕ)T(18)
其中∇Gi\nabla_{G_i}∇Gi为仅对高斯元(G_i)的参数求解的梯度。该式在固定其他所有高斯元的前提下,衡量了L2L_2L2损失对高斯元GiG_iGi的敏感度。
为专门捕捉几何敏感度,仅使用均值μi\mu_iμi与尺度sis_isi共 6 个参数对HiH_iHi做进一步近似,并对结果取对数行列式,得到具有代表性的标量评分UiU_iUi:
Ui=log∣∇μi,siIG∇μi,siIGT∣(19) U_{i}=log \left|\nabla_{\mu_{i}, s_{i}} I_{\mathcal{G}} \nabla_{\mu_{i}, s_{i}} I_{\mathcal{G}}^{T}\right| \tag{19} Ui=log ∇μi,siIG∇μi,siIGT (19)
基于该评分,最多可稳健地从模型中剪枝 90% 的高斯元,同时保持高视觉质量。
尽管 PUP 3D-GS 实现了出色的压缩比与渲染速度提升,其公式存在两个核心缺陷:第一,海森矩阵的计算需要与(N×36)成正比的存储空间,其中N为高斯元数量;相比之下,3DGS 模型每个高斯元存储 59 个参数,内存占用与(N×59)成正比。尽管该评分在事后剪枝中效果优异,但过高的存储开销使其无法在训练过程中使用。第二,海森矩阵的计算需要均值μ\muμ与尺度S的像素级梯度,而这些是高斯元的 3D 参数,要获取对应的梯度,需要先对像素并行的渲染核做反向传播,再在每个像素的线程中对贡献于该像素的所有高斯元做反向传播,这打破了 3DGS 中高效的梯度流 ------3DGS 中,渲染核输出的像素级梯度经并行聚合后,传递给 2D 的μ2D\mu_{2D}μ2D与∑2D\sum_{2D}∑2D参数,再经高斯元维度的并行计算,得到μ\muμ与s的梯度。
该方法在 PUP 3D-GS 的基础上,提出了可嵌入 3DGS 训练的高效剪枝评分,并设计了两种不同的剪枝模式:在训练前 15000 次迭代的致密化阶段执行的软剪枝(Soft Pruning),以及在 15000 次迭代、致密化阶段完成后执行的硬剪枝(Hard Pruning)。
4.2.1 高效剪枝评分
我们的核心洞察是,通过对海森矩阵重参数化,可同时解决上述两个缺陷。具体而言,我们通过计算像素p处高斯元GiG_iGi的 2D 投影值gi(p)g_i(p)gi(p)(公式 6)对应的海森矩阵近似值,来表征高斯元GiG_iGi所有空间参数的影响。由此,公式 19 中的剪枝评分UiU_iUi可改写为:
Ui=log∣∇giIG∇giIGT∣(20) U_{i}=log \left|\nabla_{g_{i}} I_{\mathcal{G}} \nabla_{g_{i}} I_{\mathcal{G}}^{T}\right| \tag{20} Ui=log ∇giIG∇giIGT (20)
由于gig_igi为标量,且对数函数为单调递增函数,可将该评分进一步简化为:
Ui=(∇giIG)2(21) U_{i}=\left(\nabla_{g_{i}} I_{\mathcal{G}}\right)^{2} \tag{21} Ui=(∇giIG)2(21)
梯度∇giIG\nabla_{g_{i}} I_{G}∇giIG在渲染过程的反向传播中已完成计算,可高效地对其求平方并在所有像素维度聚合。更重要的是,该评分的最大存储空间需求仅与高斯元数量N成正比,将存储需求降低了 36 倍,使其可在训练过程中直接使用。
4.2.2 软剪枝(Soft Pruning)
为保证海森矩阵近似的稳健性,团队观察到,模型的L1L_1L1损失在 6000 次迭代后已降至较低水平,且除执行不透明度重置外,后续始终保持在低位。因此,对致密化进行扩展,加入了软剪枝方法:在 6000、9000、12000 次迭代的三次不透明度重置前,立即对模型执行剪枝。实验中发现,该方法可支持极高的剪枝比例 ------80% 的剪枝比例下,模型的视觉保真度仍能得到完整保留。
4.2.3 硬剪枝(Hard Pruning)
同时观察到,模型在致密化阶段结束后的性能,已与完全训练后的模型高度接近。致密化阶段后的迭代本质上是对模型的微调,与 PUP 3D-GS 和 LightGaussian 的思路类似,可在剪枝后利用这部分迭代对模型做进一步优化。在实际实现中,硬剪枝方法从 15000 次迭代开始,每 3000 次迭代以固定比例对模型执行一次剪枝。每次硬剪枝移除 30% 的高斯元,与软剪枝配合使用时,实验结果显示其可将所有场景的总高斯元数量平均降低 10.6 倍。