让 AI 替你翻书:LLM Wiki 知识管理实战指南
作者:科技界的一粒微尘
一位工程师用 Obsidian + AI Agent 搭建嵌入式 Linux 知识库的完整实践
📋 本文概览: 当知识从文档堆变成一张关联网络,搜索就不再是唯一的入口。本文以鸿鸥派 Hi3519DV500 开发板项目为实例,完整展示 LLM Wiki 的搭建思路、三层架构、三种使用方式,以及与 RAG 互补配合的最佳实践。全文包含 3 张架构图解和 5 张实操截图。
老规矩先看预览
一、痛点:工程师的知识困境
每一个硬件工程师或嵌入式开发者,都面对过同一个问题:项目资料越来越多,但真正想用的时候找不到。
以鸿鸥派 Hi3519DV500 开发板项目为例,一个典型的嵌入式项目会积累这些资料:
原厂资料: SDK 开发指南、硬件设计手册、数据手册(PDF 版本,随便一份就几百页)
自建文档: 编译环境搭建记录、操作命令手册、问题排查日志
学习笔记: 芯片架构分析、外设接口梳理、AI 推理参数速查
工具与脚本: 烧录工具、驱动包、测试脚本
这些资料分散在几十个目录中,格式有 PDF、Word、Markdown、Excel,甚至还有图片和压缩包。你需要查一个 RTSP 推流地址时,可能要打开七八个文件才能找到。
传统的解决方案有两种:
一种是「堆文件夹」------ 把所有资料按目录存好,你需要什么自己去翻。结果往往是翻了一下午,找到了三年前的版本,发现参数已经改了。
另一种是「用 RAG」------ 把所有文档扔给大模型,每次问问题都重新搜索一遍。听起来很美好,但每次问同样的问题都要消耗 Token,而且模型不理解「这个参数从哪来的」。
那么,有没有第三种方案?
有,就是 LLM Wiki。
二、什么是 LLM Wiki
LLM Wiki(Large Language Model Wiki)是 Andrej Karpathy 提出的一种知识管理理念。核心思想很简单:
把知识写下来,而不是存起来。
传统的知识库是「仓储式」的------把一堆文档丢进去,需要时再翻出来。LLM Wiki 是「蒸馏式」的------让 AI Agent 把原始资料提炼成互相关联的知识页面,形成一张知识网络。
💡 核心区别: 传统知识库存的是「文件」,LLM Wiki 存的是「知识」。
一张图说明它的三层架构:
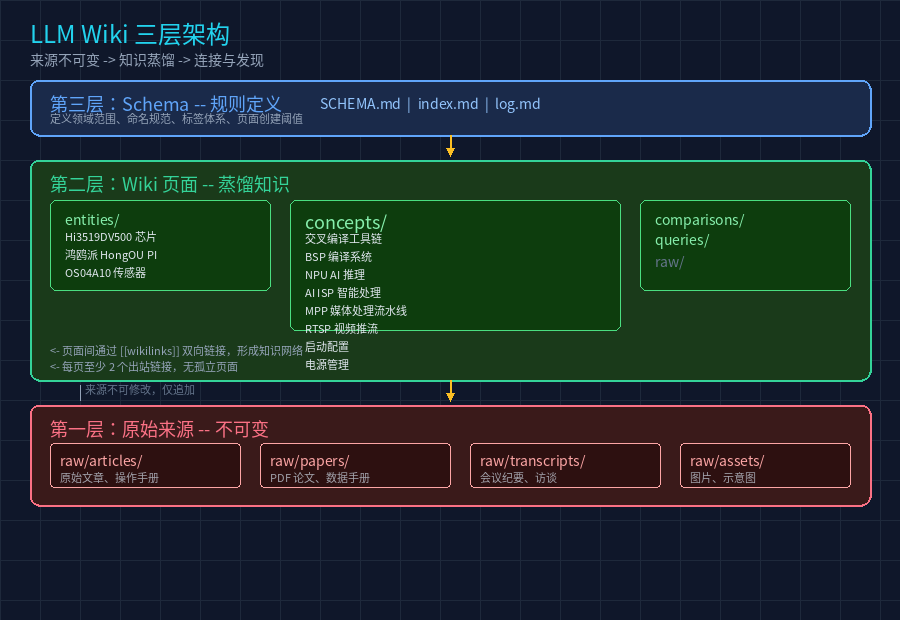
图中可见三个层次:底层 raw/ 存放原始文章和数据手册(不可修改),中间层 entities + concepts 是 AI 蒸馏后的知识页面,顶层 SCHEMA.md + index.md + log.md 控制规则。箭头方向代表数据流向------来源不可变,知识不断生长。
第一层 ------ 原始来源(raw/): 所有原始资料,包括文章、论文、会议纪要、图片。这一层的原则是「不可变」------一旦摄入就不再修改,只做追加。如果将来来源文件有更新,通过 SHA256 哈希值比对来判断是否需要重新摄入。
第二层 ------ 蒸馏知识: 这是 Wiki 的核心。AI Agent 把第一层的原材料提炼成结构化的知识页面,分为三种类型:
- 实体页(entities/): 描述真实存在的事物,比如
Hi3519DV500 芯片、鸿鸥派 HongOU PI、OS04A10 图像传感器 - 概念页(concepts/): 描述抽象的知识主题,比如
NPU AI 推理、MPP 媒体处理流水线、RTSP 视频推流 - 对比页(comparisons/)和查询归档(queries/): 记录有价值的对比分析和查询结果
每个页面都通过 [[wikilinks]] 双向链接在一起。打开任意一页都可以顺着链接跳到相关页面,就像 Wikipedia 一样。
第三层 ------ 规则定义(Schema): 控制整个 Wiki 的「宪法」。SCHEMA.md 定义领域范围、命名规范、标签体系、页面创建阈值。index.md 是内容目录。log.md 记录所有操作历史。
三、以鸿鸥派项目为例:Wiki 长什么样
我把鸿鸥派 Hi3519DV500 项目中的全部知识蒸馏成了一个嵌入式 Linux LLM Wiki,包含 14 个页面:
3 个实体页: Hi3519DV500 芯片、鸿鸥派 HongOU PI、OS04A10 图像传感器
11 个概念页: 交叉编译工具链、BSP 编译系统、NPU AI 推理、AI ISP 智能图像处理、MPP 媒体处理流水线、RTSP 视频推流、启动配置、电源管理、DDR4 接口设计、传感器时钟配置、外设接口总览
这些页面覆盖了从硬件设计到软件开发的完整知识链。为了方便理解,可以想象一个三层同心圆:
外圈 ------ 芯片级知识: Hi3519DV500 芯片是什么架构、OS04A10 摄像头怎么接、鸿鸥派开发板的硬件资源有哪些。这些是「物」的知识,定义了你手上有哪些东西。
中圈 ------ 系统级知识: 交叉编译工具链怎么配、BSP 怎么编译、启动配置要烧写哪些分区。这些是「怎么搭环境」的知识,决定了你能不能把代码跑起来。
内圈 ------ 应用级知识: NPU 怎么跑 YOLOv8 模型、RTSP 怎么推流、AI ISP 怎么调参。这些是「怎么用」的知识,直接驱动业务功能。
Wiki 的美妙之处在于:这三圈知识通过 [[wikilinks]] 互相链接,从外到内或从内到外都可以顺着连接探索。比如你从「NPU AI 推理」出发,可以往回找到「Hi3519DV500 芯片」了解算力规格,往前找到「RTSP 视频推流」了解怎么看结果,横向找到「AI ISP 智能图像处理」了解它和 NPU 推理的关系。
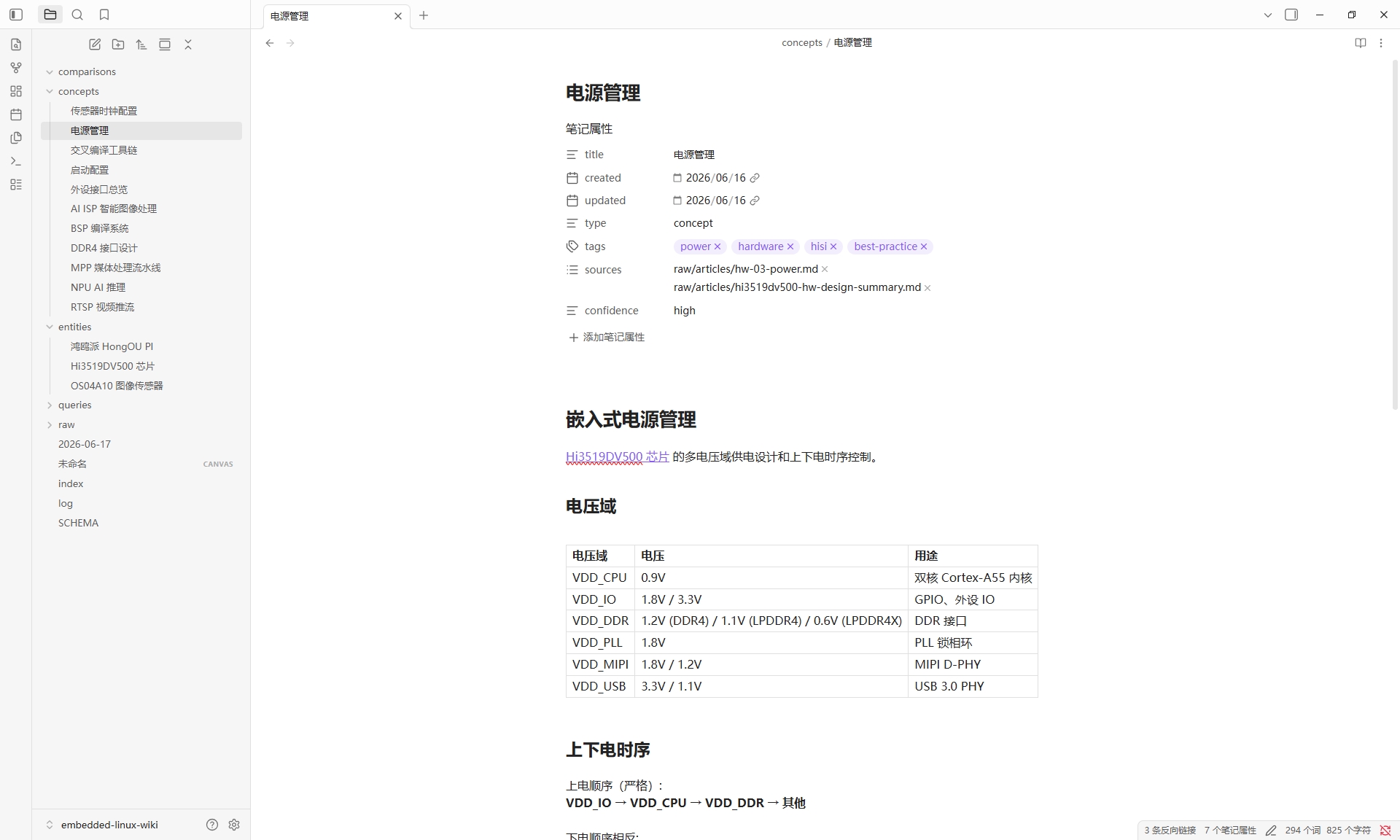
左侧文件树清晰展示了 Wiki 的完整结构:
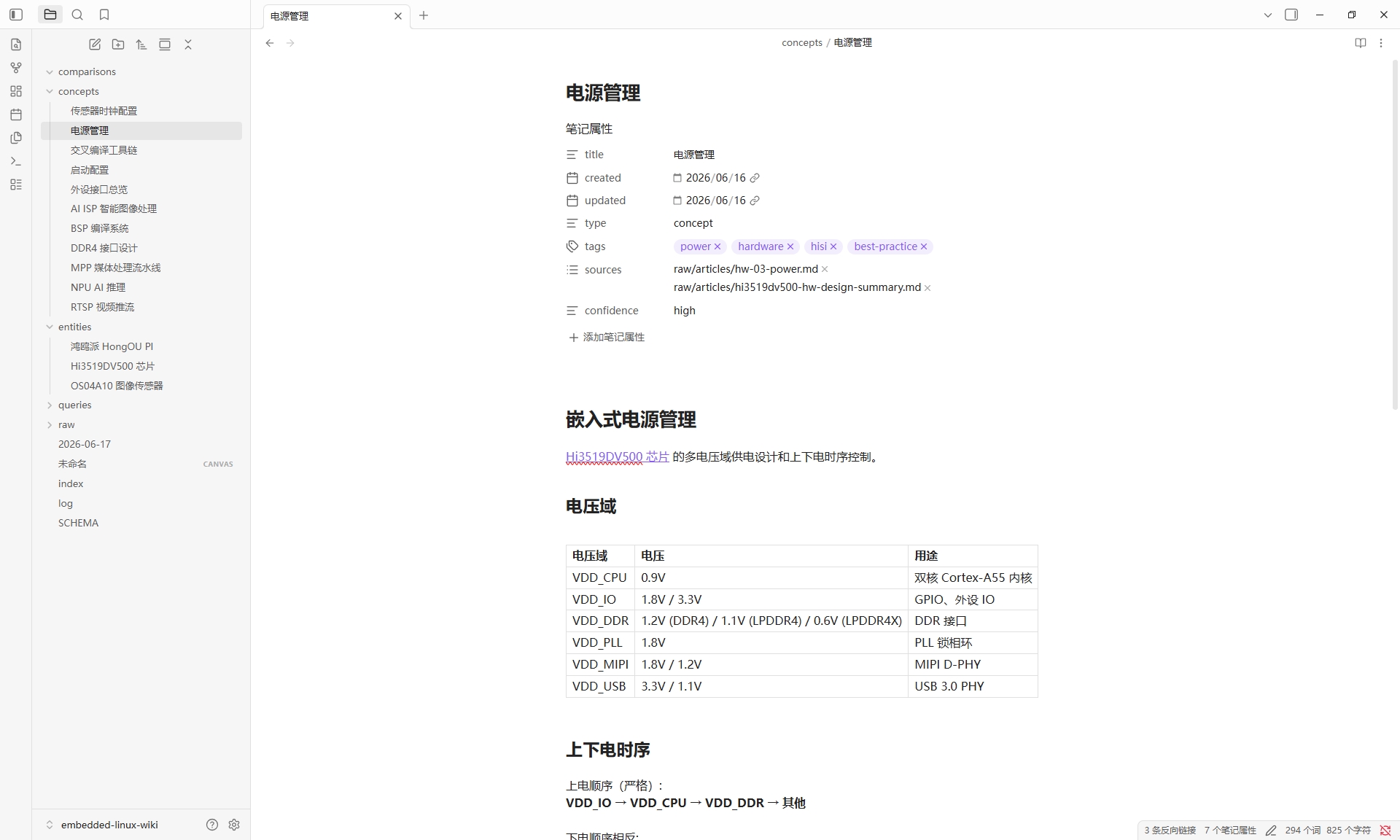
entities/下有 3 个实体(芯片、开发板、传感器),concepts/下有 11 个概念页面(NPU 推理、RTSP 推流、电源管理等),raw/目录存放原始来源。右侧是电源管理.md页面,包含 YAML 头部、标签体系和结构化表格。
Obsidian 中打开这个目录,左侧文件树一目了然。entities/ 目录下是芯片、开发板、传感器三个实体;concepts/ 目录下是 11 个概念页面。每一页都有完整的 YAML 头部信息(创建日期、更新日期、类型、标签、来源引用)和严谨的页面结构。
最惊艳的是 Graph View------所有 [[wikilinks]] 连接在一起,形成一张知识网络。你可以看到「Hi3519DV500 芯片」链接到「NPU AI 推理」,后者又链接到「RTSP 视频推流」和「MPP 媒体处理流水线」。「启动配置」链接到「传感器时钟配置」和「电源管理」。每一页至少链接 2 个其他页面,没有孤立的知识点。
(限于本文格式,Graph View 的动态交互效果无法在静态截图中完整展示,建议在 Obsidian 中亲自打开体验)
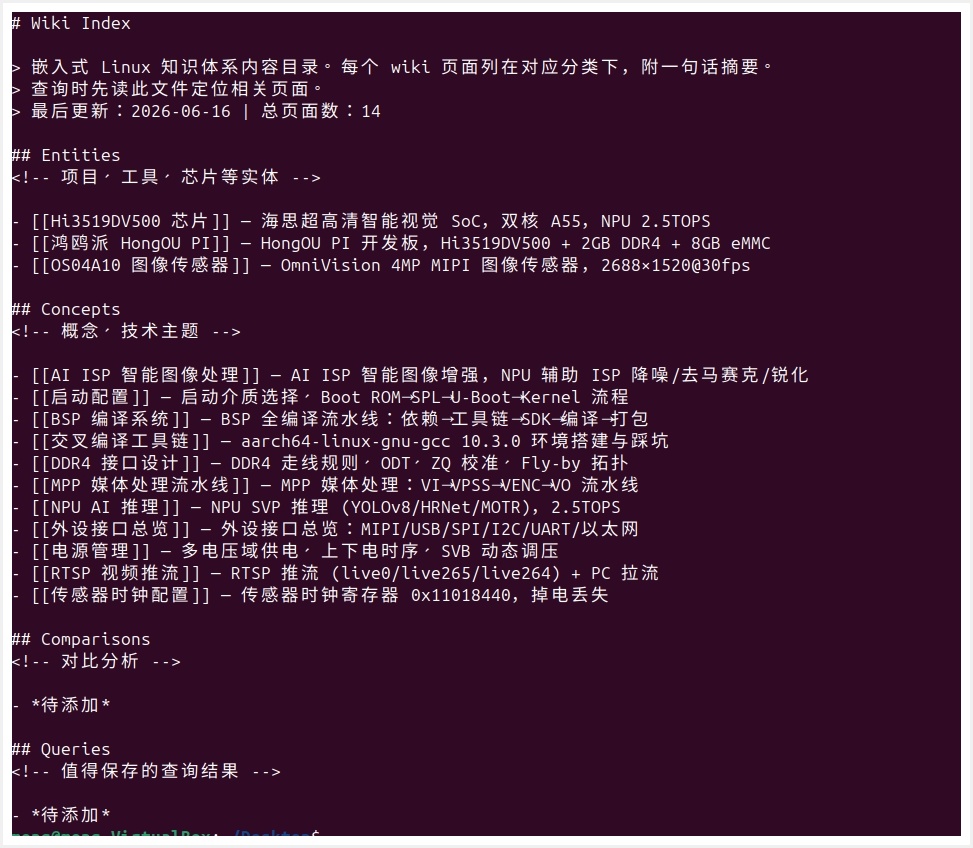
终端中直接
cat index.md即可看到全部 14 个页面的完整目录。Entities 分类下列出了芯片、开发板、传感器三个实体;Concepts 分类下列出了 11 个概念页面,每个条目都有一句话摘要。
如果你不喜欢图形界面,终端里也能看:
bash
# 查看总目录
cat "/home/ros2/obsidian/embedded-linux-wiki/index.md"
# 查看具体页面
cat "/home/ros2/obsidian/embedded-linux-wiki/concepts/NPU AI 推理.md"
# 查看最近操作记录
cat "/home/ros2/obsidian/embedded-linux-wiki/log.md"Wiki 本质上就是一个目录下的 markdown 文件,没有任何特殊的数据格式依赖。VSCode、vi、Notepad++,任何一个文本编辑器都能打开和修改。
四、三种使用方式
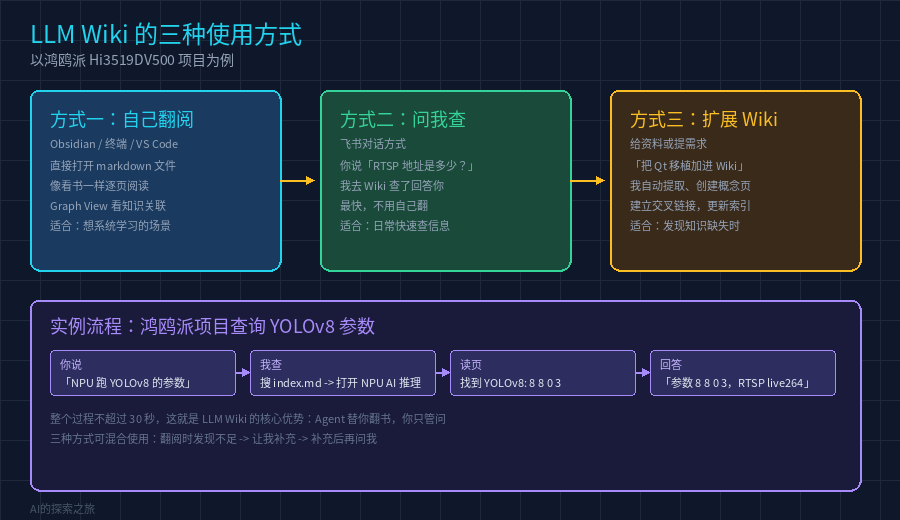
图中展示了 LLM Wiki 的三种使用方式:左边「自己翻阅」适合系统学习,中间「问我查」适合日常快速获取信息,右边「扩展 Wiki」适合知识补充。底部是鸿鸥派项目中查询 YOLOv8 参数的完整流程示例。
方式一:自己翻阅
这是最传统的方式------打开 Obsidian 或文本编辑器,像看书一样浏览。适合你想系统学习某个知识领域的时候。
比如你想了解 NPU 推理的完整流程,可以打开 index.md 找到 NPU AI 推理,点击进入页面。看完后顺着底部的 [[wikilinks]] 点击 RTSP 视频推流 了解怎么看推理结果,再点击 MPP 媒体处理流水线 了解视频数据是怎么从摄像头流向 NPU 的。
这种链式阅读让你不知不觉间建立起完整的知识框架。
方式二:问我查
这是最方便的方式------直接通过对话问 AI,AI 去 Wiki 里找答案。
比如我(AI Agent)正在通过飞书与工程师沟通。工程师问:「NPU 跑 YOLOv8 的参数是多少?」
我只需要三步:
第一步: 打开 index.md,找到涉及 NPU 和 AI 推理的相关页面
第二步: 打开 NPU AI 推理 页面,找到如下内容:
yaml
YOLOv8: 参数 8 8 0 3,RTSP 地址 /live264
HRNet: 参数 a 0 3,RTSP 地址 /live264
MOTR: 参数 b 0 0 3,RTSP 地址 /live264第三步: 回复工程师:「YOLOv8 的调用参数是 8 8 0 3,推理结果通过 RTSP 在 live264 查看,拉流命令是 ffplay -vf "vflip,hflip" rtsp://192.168.1.168/live264」
整个过程不超过 30 秒,工程师不需要自己打开任何一个文件。这就是 LLM Wiki 的核心优势------Agent 替你翻书,你只管问。
方式三:扩展 Wiki
当发现 Wiki 缺少某块知识时,告诉 AI 来补充。
比如工程师说:「把 OpenCV 在海思平台上的交叉编译移植步骤加到 Wiki 里。」
AI 会这样做:
第一步: 从提供的资料中提取关键信息(OpenCV 版本、cmake 参数、依赖库、IVE 硬件加速适配)
第二步: 创建一个新的概念页 OpenCV 交叉编译与移植.md,包含完整的 YAML 头部和页面结构
第三步: 建立 [[wikilinks]] 链接到现有页面------链接到 交叉编译工具链(因为要用到 aarch64-linux-gnu-gcc)、链接到 BSP 编译系统(因为放在 BSP 编译流程中)、链接到 NPU AI 推理(因为 OpenCV 处理后的数据可能送入 NPU)
第四步: 更新 index.md,在 concepts 分类下加上新页面链接
第五步: 在 log.md 中追加操作记录
这样,下次任何人问「怎么在鸿鸥派上部署 OpenCV」,Wiki 里已经有答案了。而且是结构化的、与其它知识关联的。
五、LLM Wiki vs RAG
有人会问:既然已经有了 RAG(Retrieval-Augmented Generation,检索增强生成),为什么还需要 LLM Wiki?
回答这个问题最好的方式是对比两张「考试卷」。

左右对比 LLM Wiki 和传统 RAG 的原理、适合场景、优缺点。底部给出最佳实践:两者互补不是互斥------RAG 做快速检索,LLM Wiki 做深度理解。
RAG 的模式是「开卷考试」: 每次遇到问题,大模型都在海量文档中现场翻找答案。好处是灵活------加一份新文档,重建索引就行。坏处是每次考试都翻书,同样的知识点每次都要重新算一次 Token。
LLM Wiki 的模式是「做笔记」: 平时把知识点整理成结构化的笔记,考试时直接翻笔记。好处是高效------知识点提炼过一次就能反复用,而且笔记之间有关联关系,能看到知识的全貌。坏处是需要有人花时间做笔记。
在实际项目中,两者是互补的,不是互斥的:
什么时候用 RAG: 查精确的参数值、命令、数字。比如「OS04A10 的 MIPI 数据通道数是多少?」------这种问题在原始数据手册里就有精确答案,RAG 检索出来直接给就行。
什么时候用 LLM Wiki: 理解概念之间的关系、构建知识体系、长期积累。比如「NPU 推理和 AI ISP 有什么区别,数据流是怎么走的?」------这种问题需要把多个概念串联起来,Wiki 的链接结构天然适合。
💡 鸿鸥派项目的最佳实践: 两套同时用。日常问题先用 LLM Wiki 回答(速度快、无 Token 消耗),如果 Wiki 里没有精确数据,再 fallback 到 RAG 检索原始文档。这样做的好处是:
- 70% 的常见问题从 Wiki 直接回答,零 Token 开销
- 30% 的精确参数从 RAG 检索,但 RAG 的索引覆盖了全量文档
- 随着 Wiki 不断扩展,那 30% 会逐渐变成 20%、10%
六、如何开始使用 LLM Wiki
如果你也想建立自己的 LLM Wiki,这里是最简洁的入门路径:
第一步:确定领域和范围
Wiki 不是越大越好。一个 Wiki 最好只覆盖一个领域,比如「嵌入式 Linux」、「深度视觉算法」或「机械设计」。范围一旦确定,SCHEMA.md 里的标签体系、页面创建阈值和命名规范才有了依据。不要试图用一个 Wiki 装下所有知识------那是项目文档库的职责,不是 Wiki 的。
第二步:准备原始资料
把你手头所有相关的原始文档集中到 raw/ 目录中。不需要整理格式,PDF 数据手册、Markdown 笔记、网页摘录、PPT 都可以。AI Agent 会处理格式转换。关键原则是:原始资料不可修改。如果发现资料有错,不要在 raw/ 里改,而是在 Wiki 页面中标注更正。这样将来重新摄入时可以比对 SHA256 哈希值来判断是否需要更新。
第三步:让 AI 摄入并蒸馏
这是最关键的一步。AI 会按以下流程自动处理:
内容筛选: 读取所有原始资料,根据 SCHEMA.md 的领域规则判断哪些内容值得提取
实体识别: 识别核心实体(芯片型号、开发板、传感器、工具)和核心概念(协议、架构、流程、设计模式)
页面创建: 创建结构化的 Wiki 页面,每页包含 YAML 头部(创建日期、标签、来源引用)和结构化正文
链接建立: 建立 [[wikilinks]] 交叉链接,确保每页至少链接到 2 个相关页面
索引更新: 更新 index.md(内容目录)和 log.md(操作记录)
以鸿鸥派项目为例,AI 从 17 个原始文档中提取了 3 个实体页和 11 个概念页,共 14 页。整个过程花了不到 5 分钟。
第四步:日常使用和维护
使用有三种方式(翻阅、问答、扩展),前面已经详细说了。
维护的关键原则是:每次有新的知识来源,就摄入一次。 好比给 Wiki 施肥,让它不断生长。比如工程师发现了一个新的编译坑,写了一份排查记录,把这个文档扔给 AI,AI 会自动判断是新建一个「踩坑记录」页面还是追加到现有页面中。
另外,定期运行 lint 检查也很重要。AI 可以自动检查:有没有孤立的页面(没有被任何其他页面链接)、有没有断裂的 wikilinks(链接到了不存在的页面)、有没有页面超过 200 行需要拆分、有没有冲突的知识(两个页面说法矛盾)、有没有超过 90 天没更新的陈旧内容。
这些检查让 Wiki 保持健康和活跃。
七、总结
LLM Wiki 不是一个产品,而是一种思维方式。它从「存文件」转向「存知识」,从「每次重新搜索」转向「一次提炼、反复使用」。
对于嵌入式开发者来说,项目周期长、资料种类多、知识折旧慢,这种知识管理方式特别适合。你不需要记住每一个参数和命令------把知识交给 Wiki,把精力留给创造。
来看看 Wiki 中一页的完整内容。打开 NPU AI 推理.md:
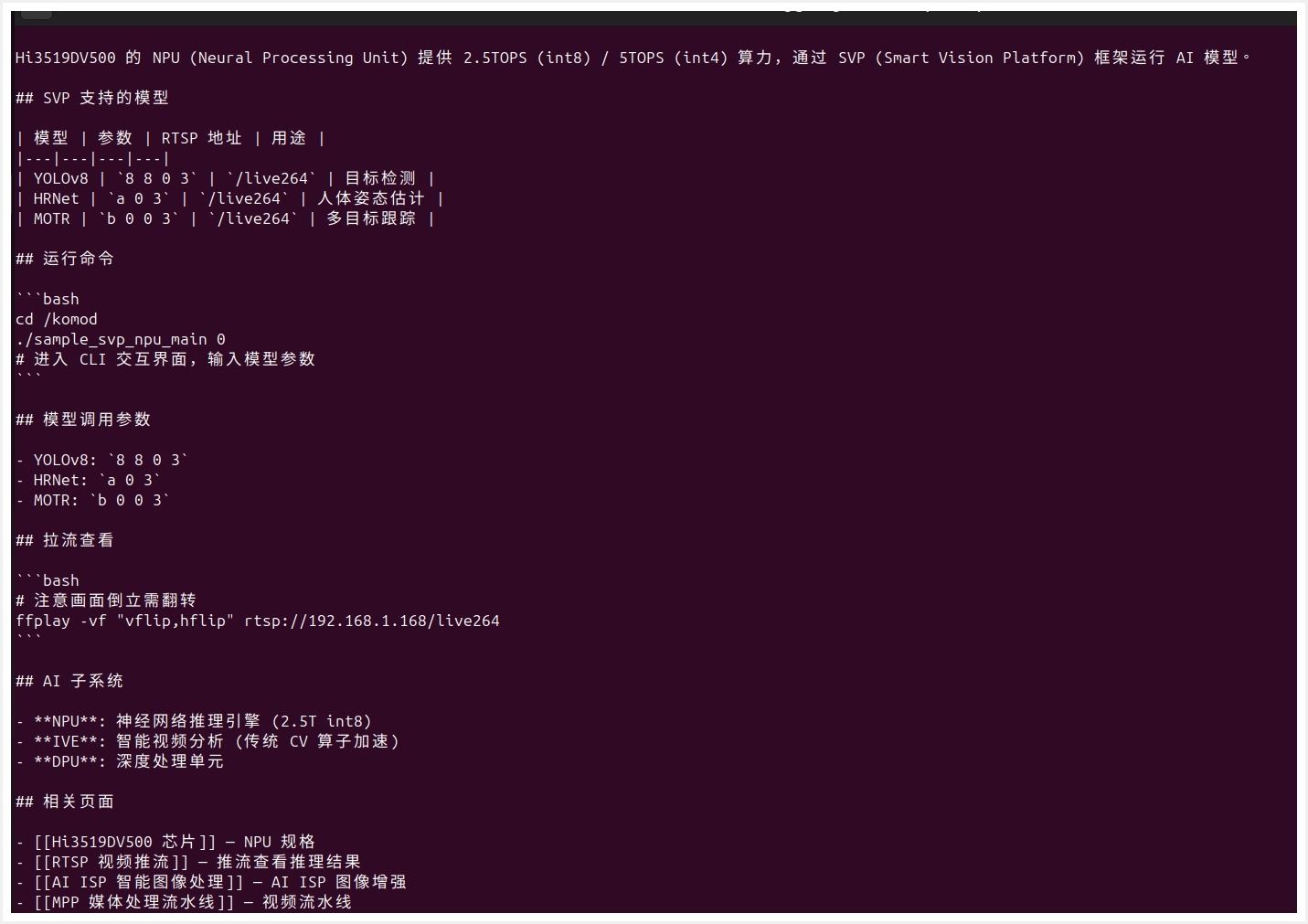
这一页包含了 YAML 头部(类型、标签、来源引用)、SVP 支持的模型表格(YOLOv8/HRNet/MOTR)、运行命令、模型调用参数、拉流查看方式等完整信息。底部通过
[[wikilinks]]链接到相关页面。
每一页都是这样结构化的:前端元数据让机器可读,正文让工程师可读,底部的链接让知识可发现。这样一来,无论是直接翻阅还是通过 AI 问答,知识都以一致的格式呈现。
Wiki 的知识是「一次提炼、百次复用」的。 在 RAG 模式下,每次问「NPU 算力是多少」都要重新搜索、重新生成答案,浪费 Token。而在 Wiki 模式下,这句话已经写在了 Hi3519DV500 芯片.md 页面里,每次回答都是直接从 Wiki 读出,不消耗任何 Token。日积月累,这种差距非常可观。
作者:科技界的一粒微尘
一位在嵌入式 Linux 和 AI 视觉领域摸爬滚打的工程师。关注「AI的探索之旅」,一起探索技术与工程的交叉点。
📌 文章中的示意图
本文共包含 6 张示意图:
| 编号 | 文件名 | 内容 |
|---|---|---|
| 图1 | wiki-architecture.png | LLM Wiki 三层架构图 |
| 图2 | usage-flow.png | 三种使用方式与实例流程 |
| 图3 | wiki-vs-rag.png | LLM Wiki 与 RAG 对比图 |
| 图4 | obsidian-screenshot.jpg | Obsidian 文件树+电源管理页面截图 |
| 图5 | terminal-index.jpg | 终端 cat index.md 截图 |
| 图6 | npu-page.jpg | 终端 cat NPU AI 推理.md 截图 |