最近半年 AI Agent 这词到处都是,GitHub 上相关项目动不动就几十万 Star,朋友圈天天这个炸了 那个爆火😂。但真要问一句「Agent 到底是什么?」,很多人答不上来,今天我就来扫个盲。
我这一年主要拿 Claude Code 改代码,Agent 用得多。这篇把这些概念理一理:从最基础的 Token,到多 Agent 协作,一共 16 个概念,自底向上分成 5 层。每个概念配一张图,再配几个按 GitHub Star / Fork 热度筛过的代表项目,看完能对 Agent 有个完整的认识。
先放一张全景图:
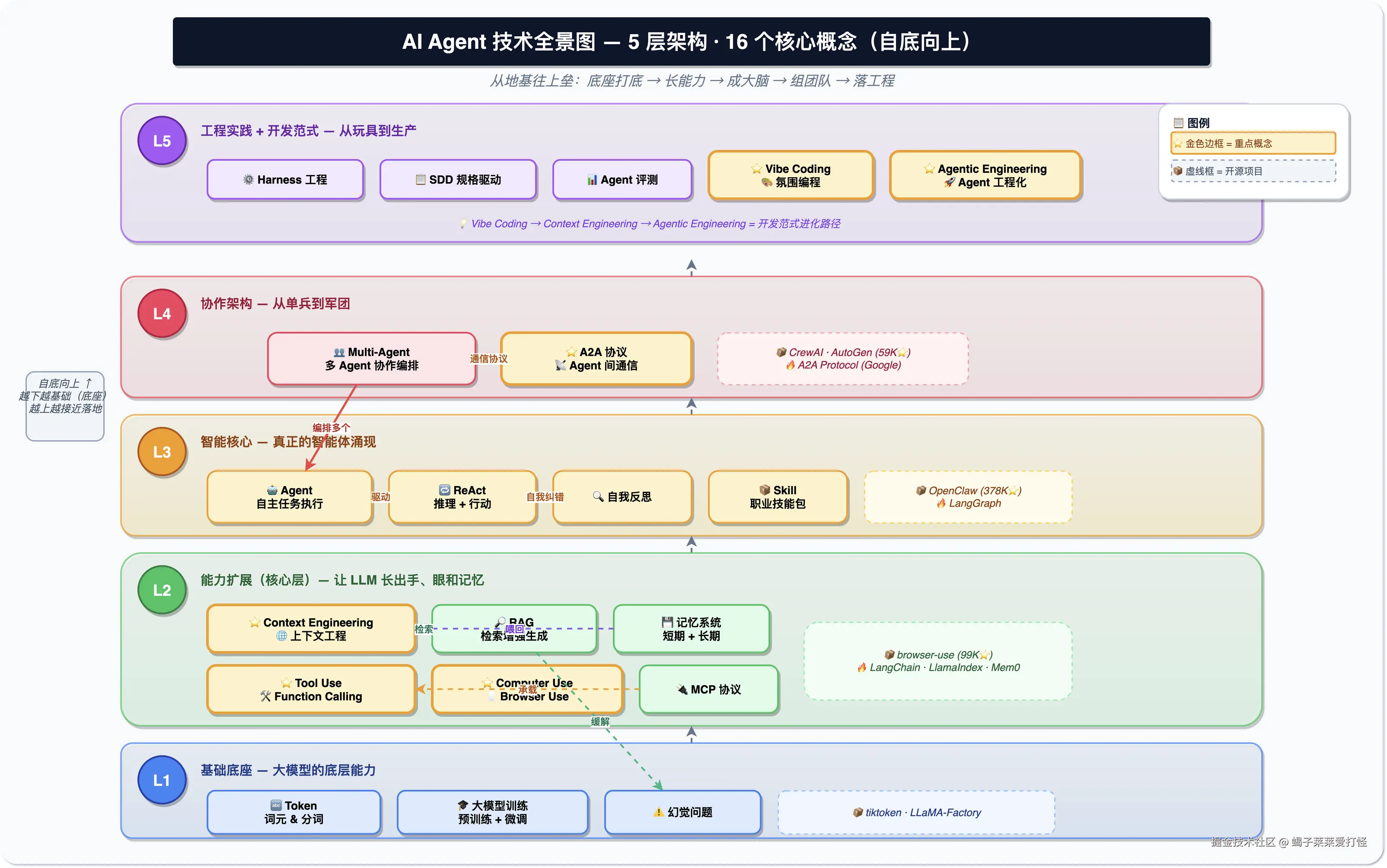
为什么要分层?因为 Agent 这些概念是一层一层垒起来的,下面的不懂,上面的就悬空。比如不懂 Token,就理解不了为什么会有上下文窗口这个限制。从底往上看一遍,整个脉络就清楚了。
第一层:基础底座
这一层是地基,看着不起眼,但后面会反复用到。三个概念。
Token:AI 只认数字
模型不认汉字也不认英文,它只认数字。你输入的一段话,会被分词器切成一个个小单元(叫 Token),每个对应一个数字,模型干的活就是对这些数字做运算。
Token 直接影响三件事:上下文能塞多少、API 怎么计费、回复有多快。这也是为什么 Claude Code 要弄个 CLAUDE.md 文件------把项目架构浓缩成几百行,而不是把整个代码库都塞进去,怕的就是上下文被无关内容占满。
要数 Token 的话,tiktoken(OpenAI 出的)最方便。想看更通用的分词器实现,也可以顺手看看 Hugging Face Tokenizers 和 SentencePiece。
训练:从通才到专家
你可能会好奇,为什么同一个模型,写代码的时候很聪明,问它冷门问题就开始瞎编?这跟训练有关。
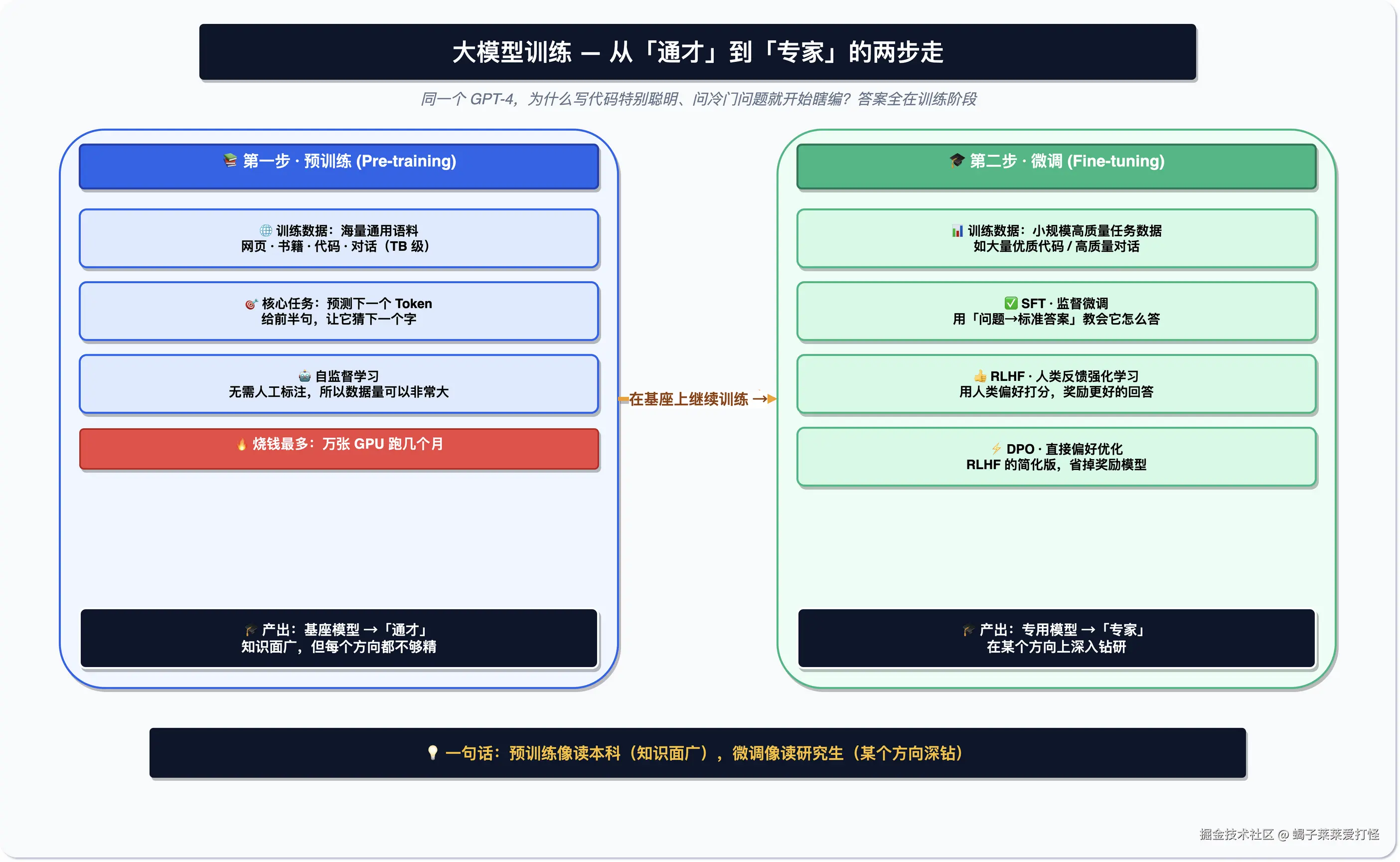
训练分两步。第一步叫预训练,拿海量的通用数据(网页、书、代码)喂给它,让它学会语言和常识。这一步最烧钱,几万张显卡跑上几个月。第二步叫微调,用规模小但更专业的数据接着练,比如想让模型擅长写代码,就拿大量优质代码来微调。
打个比方,预训练像读本科,知识面广但都浅;微调像读研究生,在一个方向上钻深。
微调框架里 LLaMA-Factory(约 72K Star)最火,支持 LLaMA、Qwen 这些主流模型。偏训练加速可以看 Unsloth,偏 RLHF / SFT 流程可以看 TRL。
幻觉:它不是故意骗你
你大概也被 AI 一本正经地忽悠过。我问过一个模型,Spring 里有没有处理消息重试的注解,它信誓旦旦给了我一个 @AsyncRetryable,参数、用法讲得头头是道------结果加进代码编译就报错,这注解压根不存在。
这就是幻觉。原因在于大模型本质上是个概率预测器,它算的是「下一个词最可能是什么」,而不是「正确答案是什么」。所以它有时候会编出看起来挺合理、其实是错的内容。它不是坏了,是天生就这么运作。用的时候自己验证一下,别全信。
第二层:能力扩展
底座有了,模型已经是个合格的聊天机器人。但要变成能干活的 Agent,它得有记忆、会用工具、能查资料。这些能力基本都在这一层。
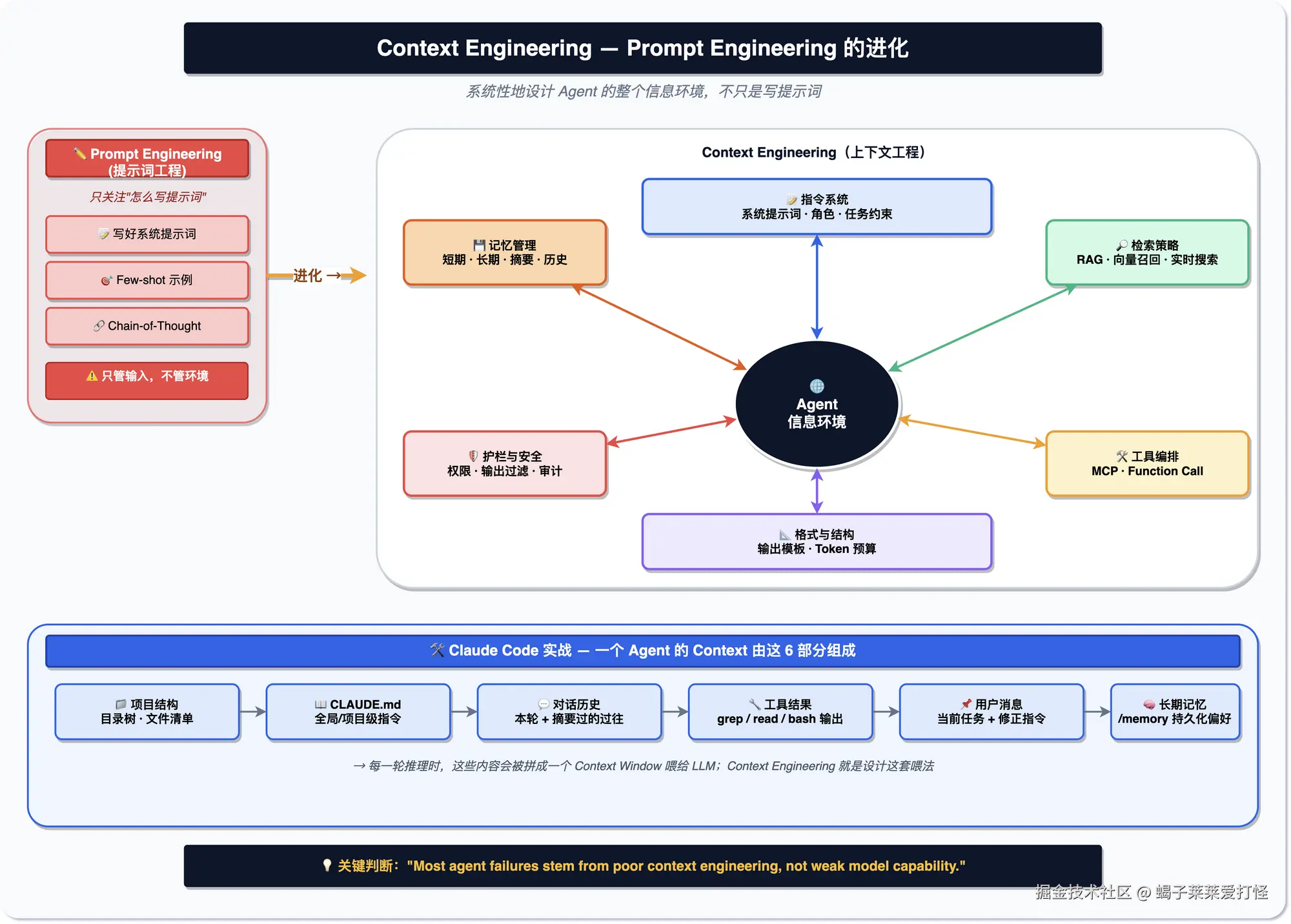
Context Engineering:2025 -26年比较火的概念
最近一年有个变化:大家不太提 Prompt Engineering(提示词工程)了,开始说 Context Engineering(上下文工程)。
以前的提示词工程,关心的是「这句话怎么写」。但 Agent 面对的是复杂任务,它需要的不只是一句提示词,而是整个信息环境:项目背景、之前做过什么决定、有哪些工具能用、输出要什么格式、有什么安全约束。把这些都系统地准备好,就是上下文工程。Maven 有份报告说得挺到位:大部分 Agent 失败,不是因为模型不行,是上下文没喂对。
RAG:让 AI 开卷考试
问大模型一个公司内部的问题,它经常瞎编,因为训练数据里没有你们公司的资料。
RAG(检索增强生成)的思路很简单:让它回答之前先查资料,相当于开卷考试。流程是------提问 → 把文本转成向量 → 在向量库里找最相关的内容 → 把找到的拼进提示词 → 交给模型生成回答。
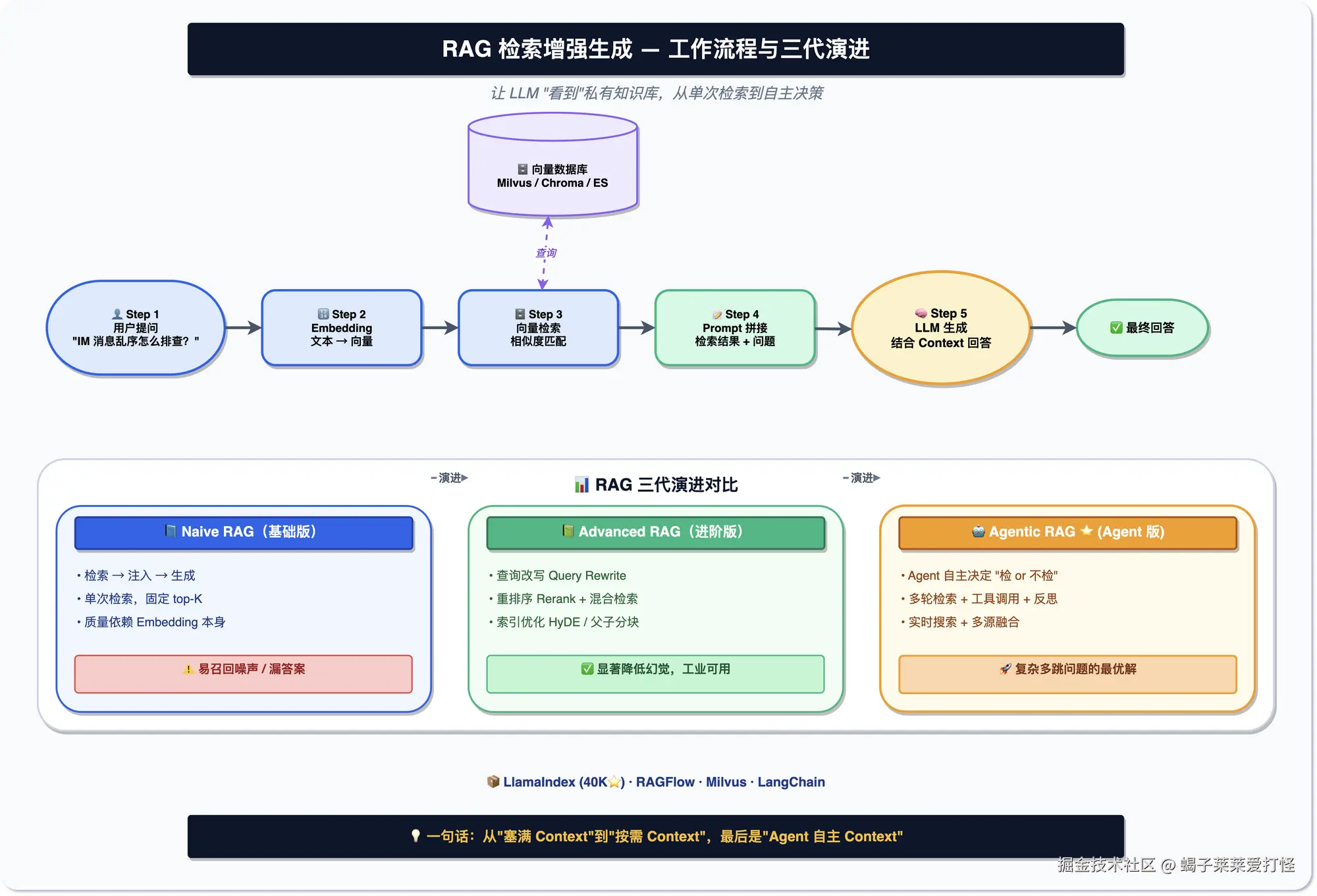
RAG 也分代,最新的叫 Agentic RAG,不再傻乎乎检索一次就回答,而是让一个 Agent 来决定要不要查、查什么、要不要多查几轮。
框架标杆是 LlamaIndex(约 50K Star),主打深度文档理解的有 RAGFlow(约 83K Star),传统检索问答工程里 Haystack 也值得看。
记忆
你发现没,每开一个新的对话,AI 都不记得你是谁,上次聊的全忘。Agent 要干活就得有记忆:短期记忆管当前这摊事(太长会自动摘要),长期记忆把你的偏好存下来,下次直接用。相当于给它配了个笔记本,省得每次重新自我介绍。
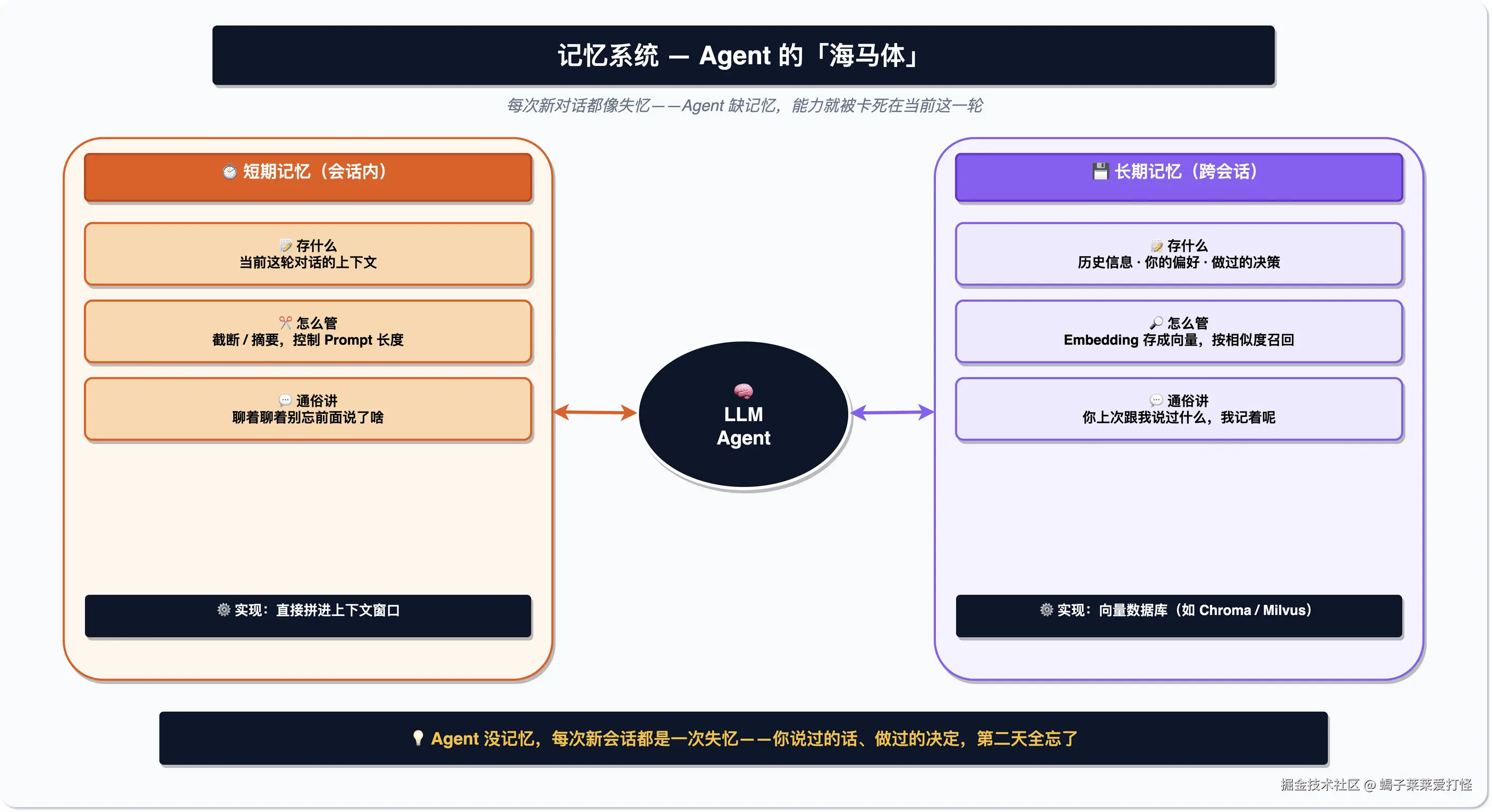
Mem0(约 59K Star)专门做这个。如果想看更完整的长期记忆 / Agent 状态管理,可以看 Letta;偏记忆服务化可以看 Zep。
Tool Use:Agent 的手
Claude 是怎么「看到」你代码文件的?它不是自己打开文件看,而是调了一个叫 Read 的工具。这就是 Tool Use,也叫 Function Calling。
这里有个关键点:模型自己不执行函数,它只是决定「该调哪个函数」,真正执行的是外面的程序。理解了这个,下面 MCP 才好懂。
Computer Use / Browser Use:Agent 的眼睛
有些事没有 API 可以调,得像人一样去看屏幕、点按钮、填表单。Computer Use 让 Agent 能看屏幕截图、模拟鼠标键盘;Browser Use 更专注,专门操作浏览器。browser-use(约 99K Star)这个项目,Star 数比很多 Agent 框架都高,因为只要人能在浏览器里干的事,它都能干。工程里还经常搭配 Playwright 做浏览器自动化和回归验证。
MCP:统一接口
接一个新工具就得写一套代码,今天接数据库写一套,明天接文件系统又写一套,挺烦的。MCP(Model Context Protocol)就是来解决这个的,相当于 Function Calling 的标准化版本。
它的架构分三层:Host 是 AI 应用(比如 Claude Code),Client 负责在 Host 内部和外部通信,Server 是提供具体能力的工具服务。配的时候,就是声明每个 Server 能干啥。
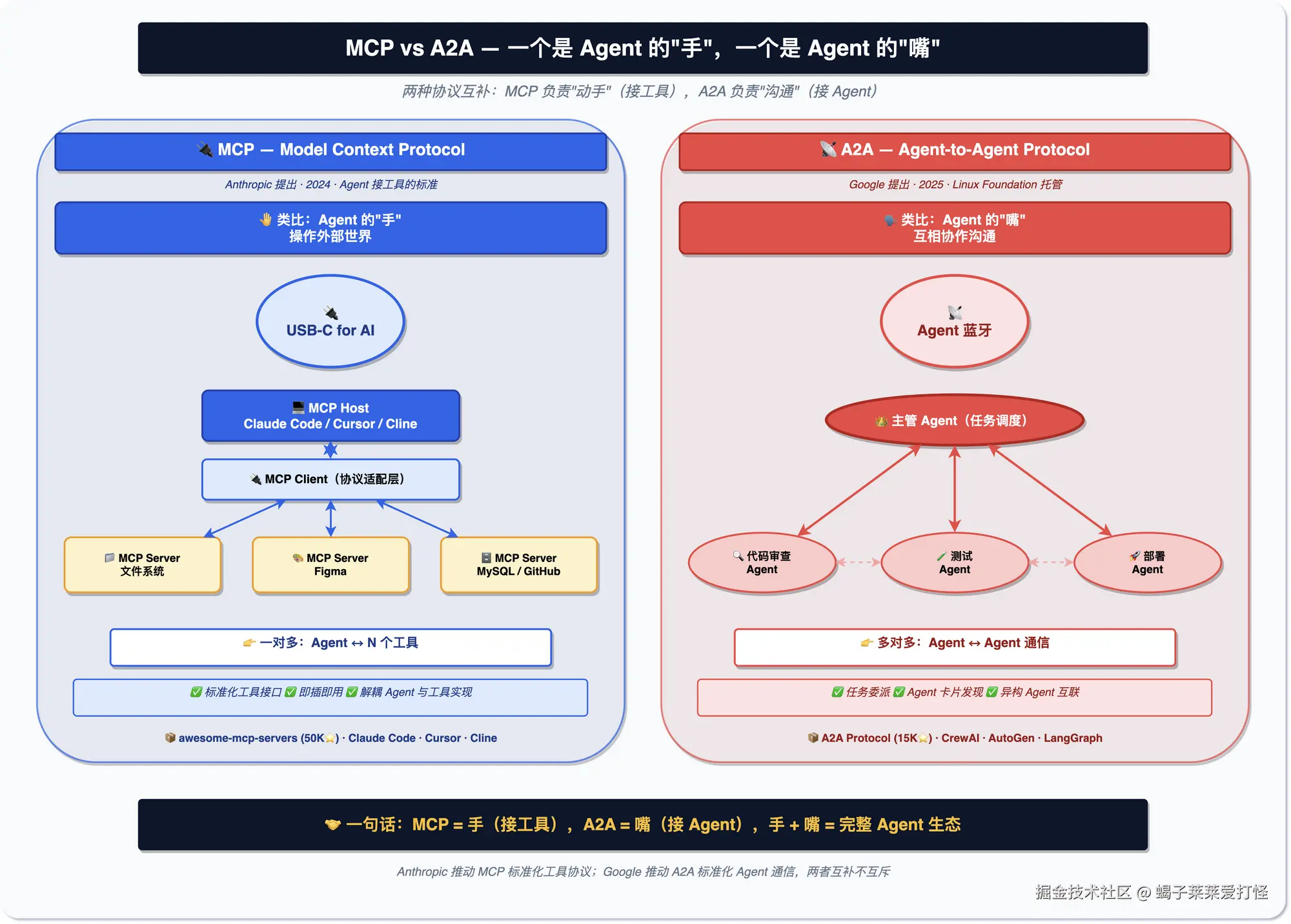
MCP 管的是 Agent 怎么连工具,服务器合集可以看 awesome-mcp-servers(约 89K Star),官方服务器合集是 modelcontextprotocol/servers(约 87K Star)。至于 Agent 之间怎么通信,那是第四层 A2A 的事。
第三层:智能核心
能力和工具都有了,这层看 Agent 怎么把它们串起来完成任务。
Agent:从对话到执行
普通聊天是你问一句、它答一句。Agent 是你给个任务,它自己拆解、自己执行、自己检查,搞完给你结果。
一句话:Agent = 模型 + 规划 + 记忆 + 工具调用。它不是聊天框,是个能自己干活的角色。
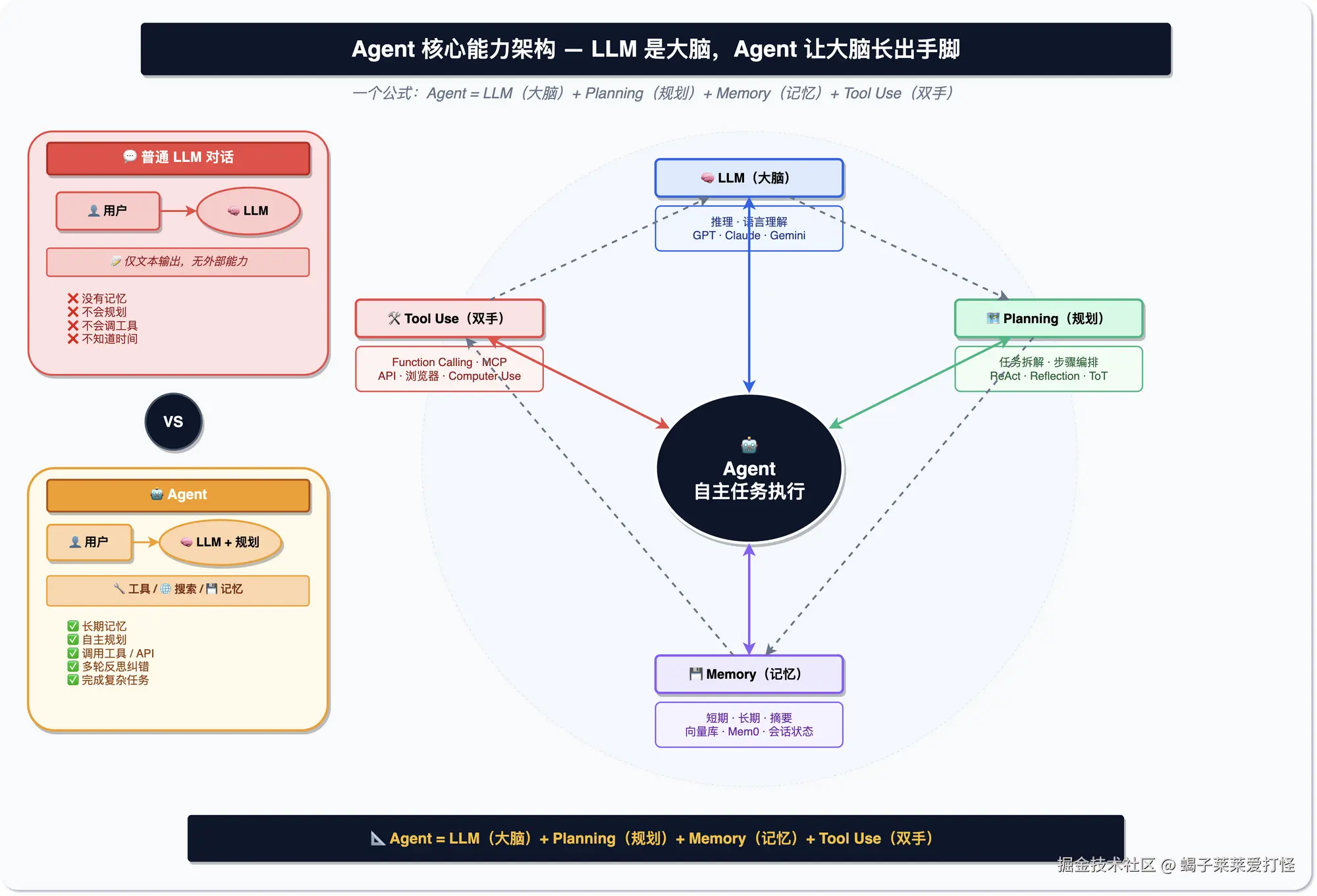
跟普通对话对比一下:
| 普通对话 | Agent | |
|---|---|---|
| 交互 | 一问一答 | 给任务,自己搞定 |
| 工具 | 没有 | 能调外部工具 |
| 拆解 | 不拆,直接答 | 自己拆成多步 |
| 反馈 | 没有 | 做完看结果,不行重来 |
OpenClaw(约 379K Star)就是典型的 Agent。写代码这块,Claude Code 和 Cursor 是主流;如果想看 SDK 层怎么封装 Agent,可以看 OpenAI Agents SDK、Pydantic AI。
CoT 和推理模型:先想再答
CoT(思维链)就是让模型在给答案之前,先把推理过程写出来,逼它一步步想,别直接跳到结论。对数学、写代码这种需要多步推理的事,效果明显。
2024 年 OpenAI 的 o1 把这事推进了一步,出现了推理模型(o1、DeepSeek R1、Claude 的 extended thinking)------把长链推理直接练进模型里,不用你再写「一步一步想」,它自己就会。DeepSeek-R1 是开源推理模型的代表。
ReAct:想一步做一步
Agent 怎么完成一个复杂任务?不是一口气干完,而是「想一想、做一步、看看结果、再想下一步」,循环往复。
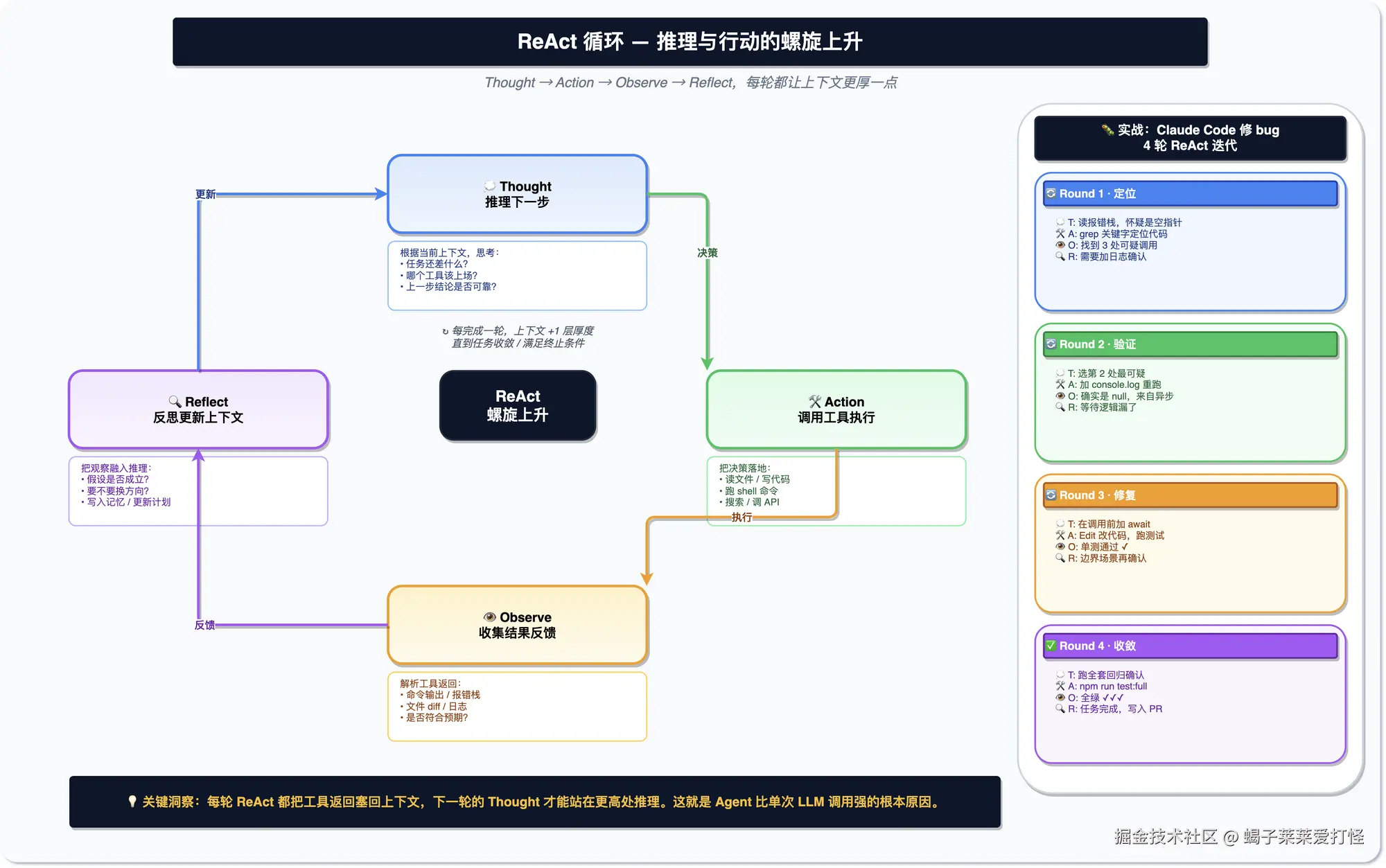
你可能会说,这不就是平时调试代码的流程吗?差不多,区别在于这个循环是 Agent 自己跑的,不用你在旁边一步步指挥。
编排框架里 LangGraph(约 35K Star)比较成熟。它背后的 LangChain 生态更大,但 LangGraph 更贴近 Agent 的状态机和循环编排。
反思
人做完题会检查一遍,Agent 也该会。反思就是生成之后再评估,根据反馈修正。分两种:一种是自己审自己,适合检查格式、有没有改错地方;另一种是丢进真实工具里验证,比如跑测试、编译看有没有报错。
Skill:岗位手册
Skill 是结构化的知识包,给 Agent 补充某个领域的流程和工具。模型本身像个聪明但不懂具体流程的新人,Skill 就像是给它的岗位手册,看完就知道这事该怎么干。
第四层:协作
一个人能力再强也有上限,2026 年比较热的方向是让多个 Agent 一起干活。
Multi-Agent:组队干活
产品拆需求、前后端并行、测试验收,一个人理论上全能干,实际干不过来,Agent 也一样。常见的编排有三种:顺序的(一个接一个,像流水线)、并行的(同时干,最后汇总)、层级的(一个主管拆活、底下的人各干各的)。
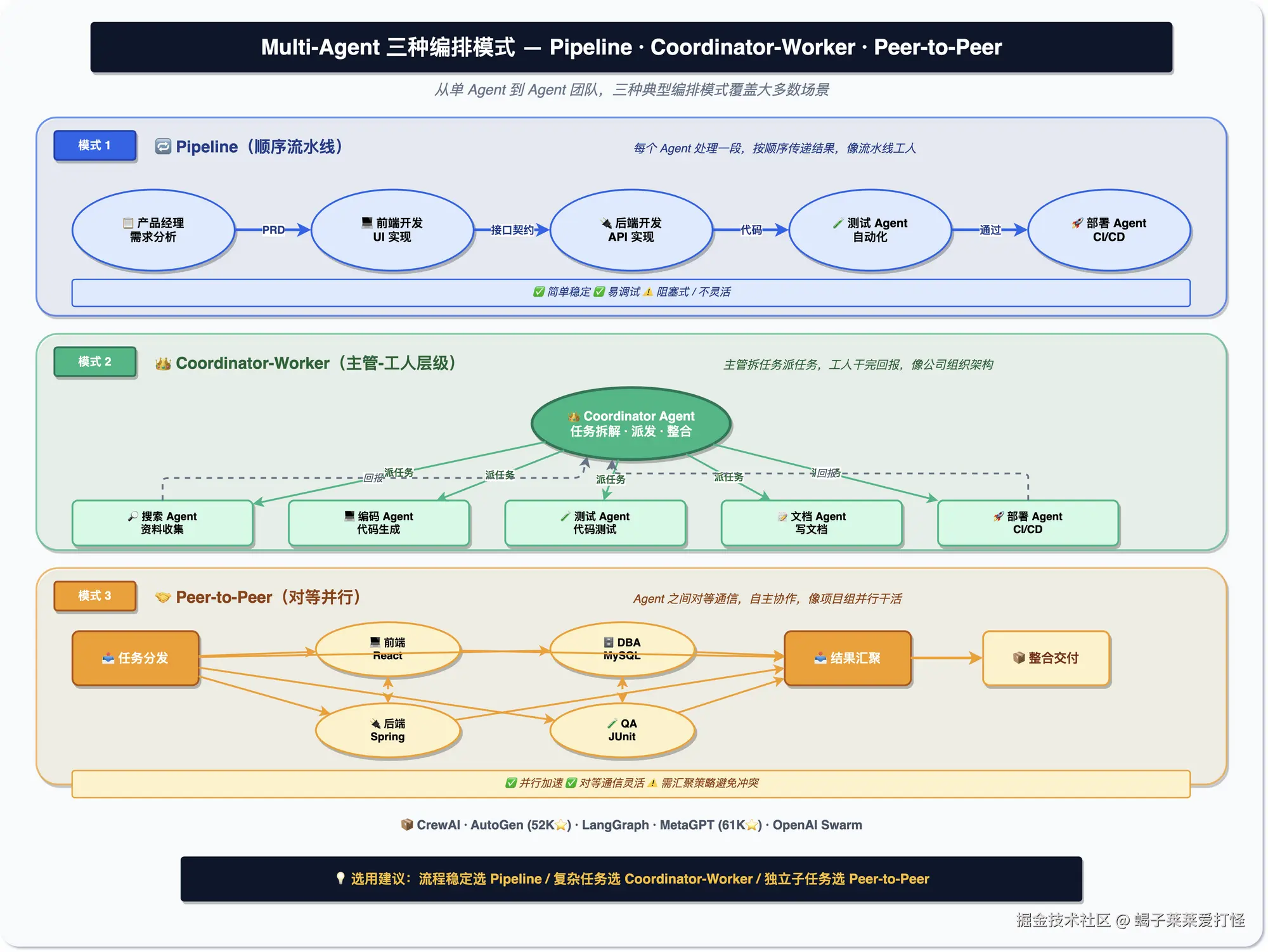
框架里 CrewAI(约 54K Star)比较简单,AutoGen(微软的,约 59K Star)更灵活,MetaGPT(约 69K Star)专门做多 Agent 软件开发。还有个热度很高的新项目 Paperclip(约 71K Star),主打"零人公司"------把 Agent 组织成一家公司,连 CEO、预算、组织架构都有。它本质还是多 Agent 编排框架;而且这项目 3 个月涨到 7 万 Star。足以看出热度火爆。
A2A:Agent 之间的通信协议
MCP 解决了 Agent 怎么调工具,但没解决 Agent 怎么跟另一个 Agent 说话。Google 2025 年推出了 A2A 协议来补这块------让不同框架、不同公司做的 Agent 能互相发现、通信、协作。
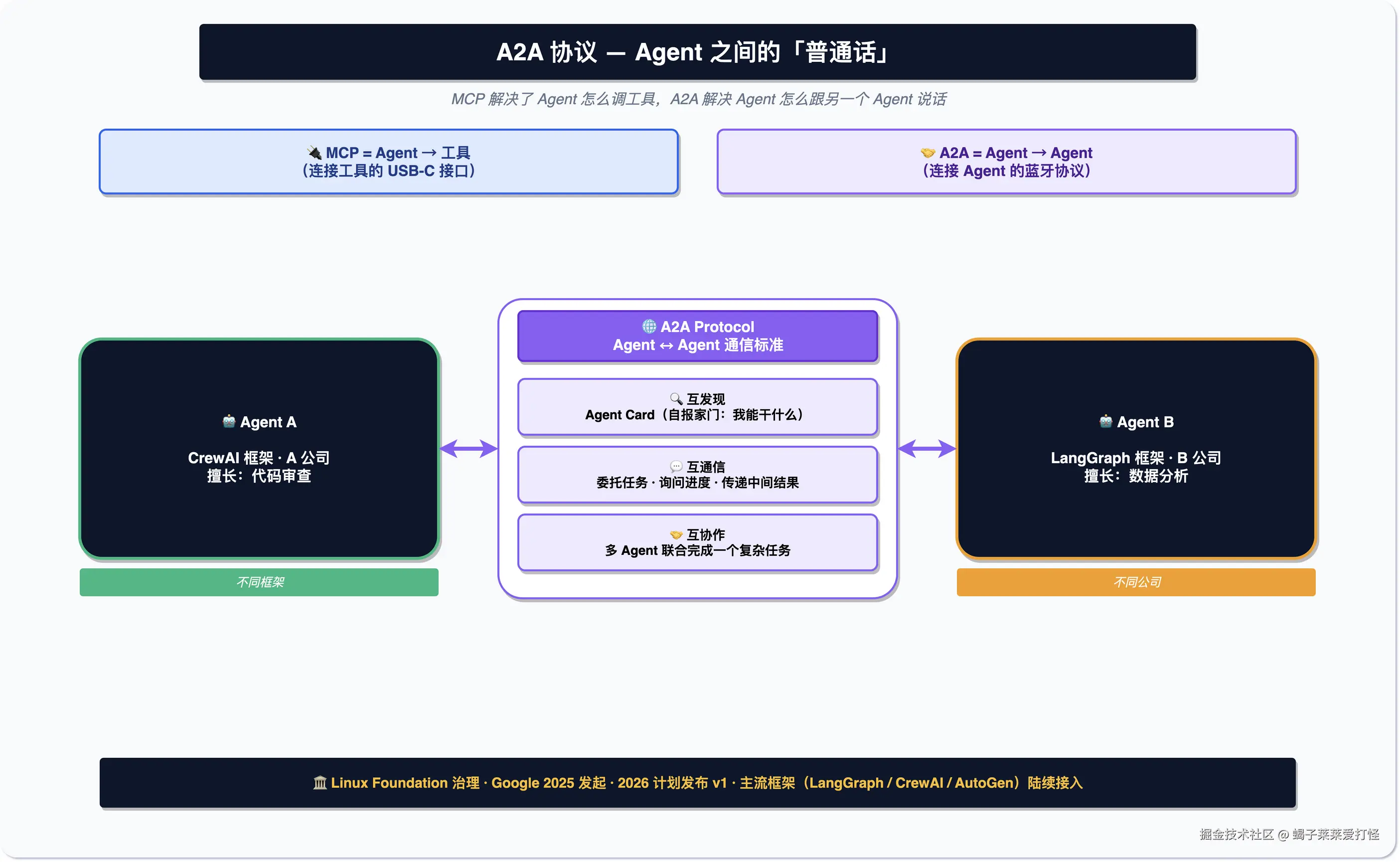
一句话区分:MCP 是 Agent 连工具的接口(像 USB-C),A2A 是 Agent 连 Agent 的协议(像蓝牙)。A2A 仓库在 A2A Protocol(24K+ Stars)。
第五层:工程实践
光有概念,Agent 在生产环境里跑不稳,还得靠工程手段兜底。
开发方式这几年也在变,大概三个阶段:
- Vibe Coding(氛围编程):Karpathy 2025 年提的,用大白话描述要啥让 AI 写,适合做 demo。
- Context Engineering(上下文工程):系统地管上下文,写 CLAUDE.md、配记忆、接 MCP。
- Agentic Engineering(Agent 工程化):搭一套让 Agent 能稳定运行的工程底座,权限、沙箱、日志、测试都配上。
不想写代码也能搭 Agent 的话,Langflow(约 150K Star)、Dify(约 145K Star)和 Flowise(约 54K Star)可以可视化拖拽。
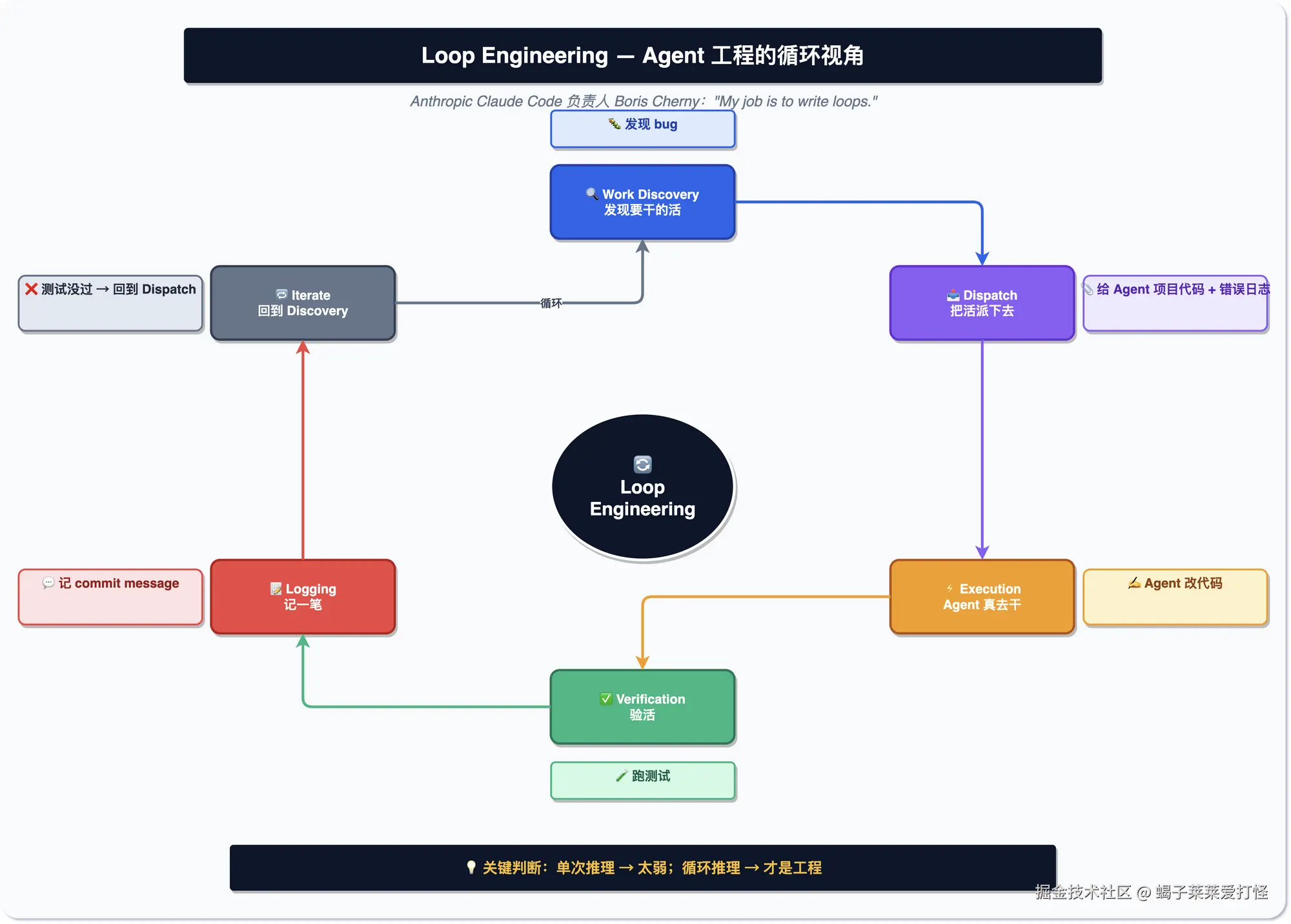
最后还有个概念叫 Loop Engineering(循环工程)。Claude Code 的负责人 Boris Cherny 说过一句话:「我现在不写提示词了,我的工作是写循环。」意思是把 Agent 干活看作一个循环------发现任务、分派、执行、验证、记录------工程师要设计的是这个循环本身。这套东西里干货和营销掺半,但「循环」这个视角确实给了个能落地的调试切入点。
概念和项目对照表
我按两个维度筛了一遍:先看项目和概念是否强相关,再看 GitHub Star / Fork 热度。Star 代表关注度,Fork 代表二次使用和改造的人多不多。数字是我写稿时从 GitHub API 查的,后面肯定会变,所以这里只保留到约数。
| 概念 | 推荐项目(按热度优先) | 适合看什么 | Star / Fork |
|---|---|---|---|
| Token / 分词 | tiktoken | OpenAI 模型 Token 计算 | 约 18.5K / 1.5K |
| Token / 分词 | SentencePiece | 经典子词分词算法 | 约 11.9K / 1.4K |
| Token / 分词 | Tokenizers | 高性能通用 tokenizer | 约 10.8K / 1.1K |
| 训练 / 微调 | LLaMA-Factory | 一站式微调主流开源模型 | 约 72.2K / 8.8K |
| 训练 / 微调 | Unsloth | 低成本、高速微调 | 约 66.6K / 6.0K |
| 训练 / 微调 | TRL | SFT、RLHF、偏好优化 | 约 18.7K / 2.8K |
| 推理模型 | DeepSeek-R1 | 开源推理模型代表 | 约 92.0K / 11.7K |
| RAG | RAGFlow | 文档解析 + RAG 工作流 | 约 82.9K / 9.6K |
| RAG | LlamaIndex | 数据连接、索引、检索编排 | 约 50.2K / 7.6K |
| RAG | Haystack | 传统检索问答工程框架 | 约 25.6K / 2.9K |
| 向量库 / 检索底座 | Chroma | 本地向量库和检索实验 | 约 28.4K / 2.3K |
| 记忆 | Mem0 | Agent 长短期记忆 | 约 58.7K / 6.7K |
| 记忆 | Letta | 长期记忆和有状态 Agent | 约 23.4K / 2.5K |
| 记忆 | Zep | 记忆服务化 | 约 4.7K / 0.6K |
| Tool Use / Agent SDK | OpenAI Agents SDK | Agent、工具调用、handoff 封装 | 约 27.2K / 4.2K |
| Tool Use / Agent SDK | Pydantic AI | 类型安全的 Agent 开发 | 约 17.8K / 2.2K |
| MCP | awesome-mcp-servers | MCP Server 生态目录 | 约 89.3K / 11.7K |
| MCP | modelcontextprotocol/servers | 官方 MCP Server 示例 | 约 87.3K / 11.0K |
| Browser Use | browser-use | Agent 操作浏览器 | 约 99.1K / 11.1K |
| Browser Use | Playwright | 浏览器自动化和回归验证 | 约 91.1K / 5.9K |
| Browser Use | Selenium | 经典浏览器自动化 | 约 34.2K / 8.7K |
| Agent | OpenClaw | 端到端 Agent 产品形态 | 约 379.0K / 79.3K |
| Agent 框架 | LangChain | LLM 应用生态入口 | 约 139.4K / 23.1K |
| Agent 框架 | LangGraph | 状态图、循环、可控 Agent | 约 34.9K / 5.8K |
| Multi-Agent | Paperclip | "零人公司"、Agent 公司化编排 | 约 70.8K / 13.2K |
| Multi-Agent | MetaGPT | 多 Agent 软件开发流程 | 约 68.8K / 8.8K |
| Multi-Agent | AutoGen | 多 Agent 对话与协作 | 约 59.0K / 8.9K |
| Multi-Agent | CrewAI | 角色分工式多 Agent | 约 53.7K / 7.5K |
| A2A | A2A Protocol | Agent 之间通信协议 | 约 24.3K / 2.5K |
| 评测 / 反思 | promptfoo | Prompt 和 Agent 输出评测 | 约 22.3K / 2.0K |
| 评测 / 反思 | DeepEval | LLM / RAG / Agent 测试 | 约 16.2K / 1.5K |
| 评测 / 反思 | Ragas | RAG 质量评估 | 约 14.4K / 1.5K |
| 可观测 / 反馈闭环 | Langfuse | LLM 调用链路、反馈、评估 | 约 29.2K / 3.0K |
| 可观测 / 反馈闭环 | Phoenix | LLM 可观测和实验分析 | 约 10.2K / 0.9K |
| 幻觉 / 护栏 | Guardrails AI | 输出校验、约束和护栏 | 约 7.0K / 0.6K |
| 低代码 Agent | Langflow | 可视化搭建 Agent / RAG | 约 149.7K / 9.3K |
| 低代码 Agent | Dify | 企业级 LLM 应用平台 | 约 145.4K / 22.9K |
| 低代码 Agent | Flowise | 拖拽式 LLM 工作流 | 约 53.6K / 24.5K |
最后
16 个概念过完了。如果只记一句话,就是上面那个:Agent = 模型 + 规划 + 记忆 + 工具调用,剩下那些概念都是在给这个公式添砖加瓦。
光看不动手没用,挑一个顺眼的项目装上跑跑,比看十篇文章都管用。
如果觉得这篇对你有用,欢迎关注「蝎子莱莱爱打怪」公众号 , ------专注 AI 和即时通讯相关技术的分享和思考,不贩卖焦虑,只说真话、讲干货。