前言
为了研究openclaw,我又手搓了一个轮子😄,并且实现了openclaw中大部分的功能,包括Agent Loop、记忆、工具使用、Skills等,达到了基本可用状态。通过这次造轮子,让我对Agent的整体流程,以及相关的概念有了更深入的认知。同时,我给自己定了一个目标是全程AI Coding,全程指挥AI自己不写一行代码,也完美完成了这个目标。当然造轮子不是目的,通过造轮子的过程加深对Agent原理的理解,以及增加AI Coding项目经验,才是最有价值的地方。
本文章会着重讲解 Agent 框架设计,比如 Agent Loop 、工具使用、记忆等,让读者对整个Agent框架有较清晰的认知,但是不会讲特别具体的实现细节,因为这些可以通过看 源码 来理解,以及也会省略跟Agent关系不大的部分。
项目介绍
这是什么?
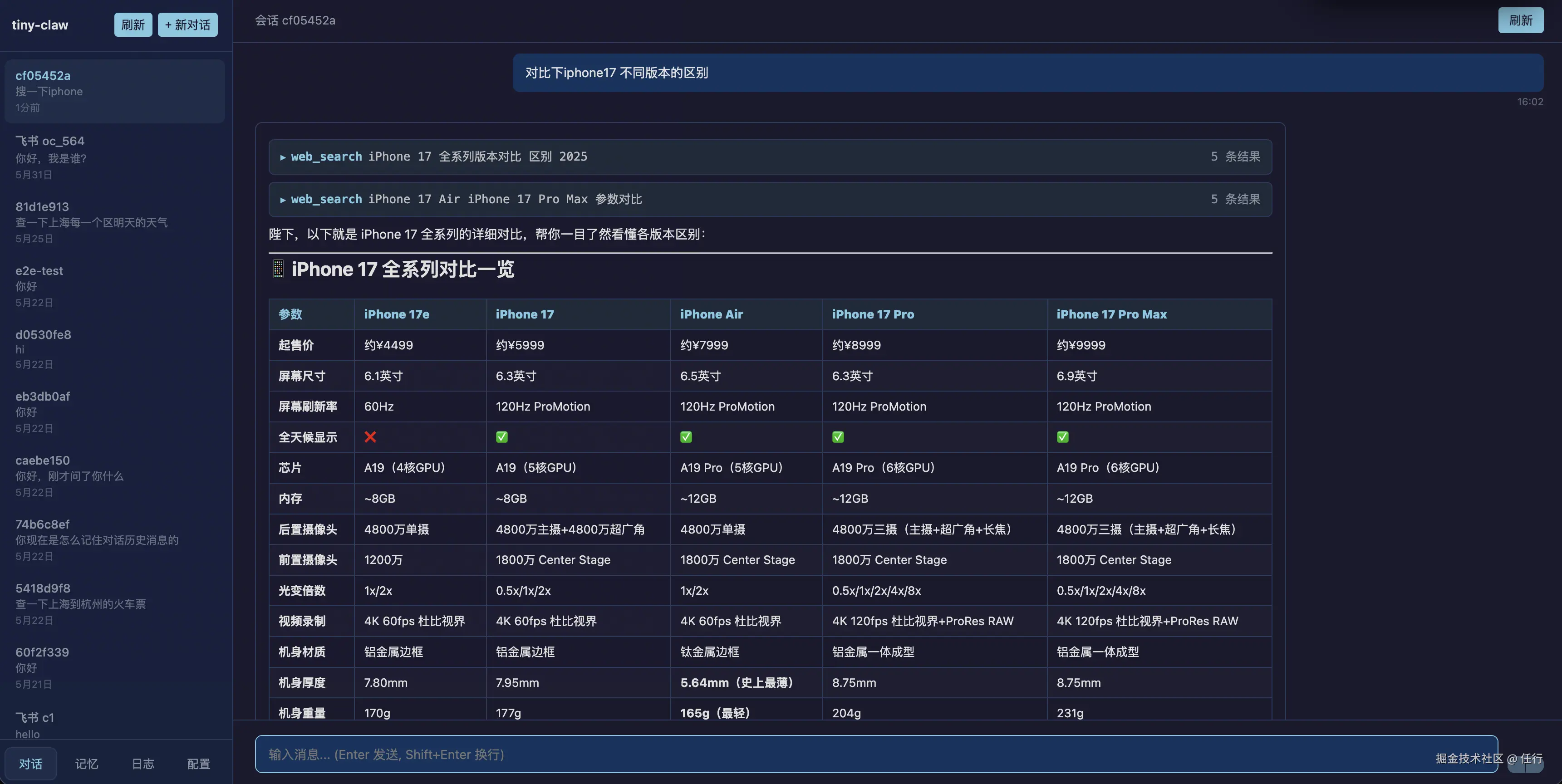
webui,展示了聊天、工具调用、会话管理等能力
使用技能查询风神数据
通过飞书插件对接飞书机器人
这是一个面向个人工作流的自主 AI Agent 项目,目标是构建一个可规划、可执行、可扩展的智能助手。它支持多轮对话、工具调用、WebUI、飞书接入、长期记忆、会话摘要、上下文压缩与命令审批等能力,可以帮助用户完成软件开发、资料检索、自动化执行和日常任务处理。
项目采用 TypeScript 编写,并以插件化架构为核心,工具、聊天命令、记忆、审批、日志等能力都可以通过插件注册和扩展。本项目既关注 Agent 的自主执行能力,也重视安全边界和运行稳定性,适合作为个人 AI 助手系统的实验平台与工程化原型。
-- 来自codex对此项目的总结
源码已开源,地址:github.com/lihongxun94...
如何本地部署
第一步:环境依赖
本项目是用JS编写,需要有Node运行环境,且版本 >= Node 20
第二步:clone代码
在你需要安装的位置执行 git clone git@github.com:lihongxun945/tiny-claw.git
第三步:安装依赖
项目的根目录下执行 npm i 安装依赖
第四步:配置大模型服务
将项目根目录的示例配置复制到工作目录: cp config.simple.example.json workspace/config.json
然后编辑 workspace/config.json 在其中加入大模型配置,示例如下:
json
{
"apiUrl": "https://ark.cn-beijing.volces.com/api/coding",
"apiKey": "YOUR_API_KEY",
"model": "glm-5.1",
"modelProvider": "anthropic-messages"
}第五步:启动服务
项目根目录下运行
npm run web:build编译webuinpm run gateway start启动网关
然后访问 http://localhost:3001/ 即可打开webui与Agent进行对话。
以上是所有必要配置,完成后就可以使用了,但是为了Agent能更好完成任务,还有几个其他重要配置你需要关注:
- 配置搜索引擎:默认搜索用的是 duckduckgo,这个是一个关键词检索服务而不是一个真正意义的搜索引擎,因此效果非常差,如果你的场景需要Agent使用网络搜索能力,强烈建议你配置一个真正的搜索服务,比如 Ollama websearch 、Brave Search等。
- 配置飞书机器人:可以参考
README配置飞书机器人,如果你还不清楚飞书机器人怎么申请和设置权限,可以参考这个文档 github.com/miaoxworld/...
接下来,让我们一起认识一下Agent是如何工作起来的。
Agent 和 大模型的区别
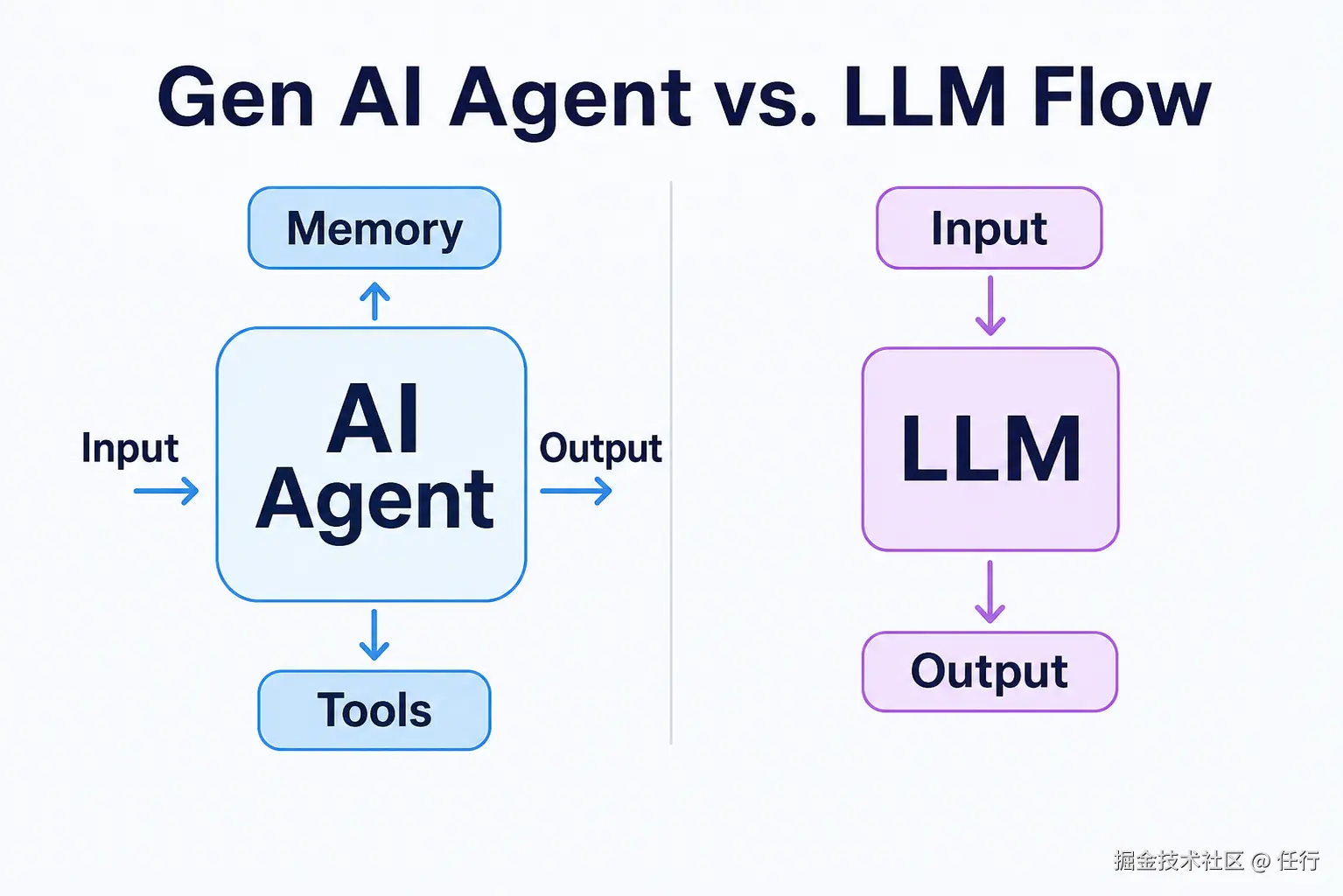
Agent的本质是可以自主完成任务的智能体,而大模型本质上只是一问一答的服务, "能否自主完成任务"这是Agent和大模型最大的区别。
那么Agent是实现"自主完成任务"的?
我们都知道Agent的核心是大语言模型,这是Agent的大脑,但是光有大语言模型并不能完成任务,因为大语言模型存在明显的不足:
- 大语言模型没有手:大语言模型只能输出文本、图片、视频等信息,无法调用工具,而一般我们的任务都需要调用web搜索、文件读写、bash指令等工具,没有这些能力无法完成任务。
- 大语言模型没有记忆:目前所有的大语言模型都是无状态的,每一次对话本质上都是独立的(但是基于大语言模型提供的聊天服务会增加记忆能力),这样在需要多轮对话的任务中就会丢失上下文导致任务失败。
- 大语言模型没有工作流:只有手和记忆也不行,为了完成一个大型任务,必须要有合适的流程,比如我让大模型写一个贪吃蛇,需要有UI设计、代码编写、自测等多个步骤,中间可能还会出现异常需要处理,总之必须有一个合适的任务机制来进行规划和管理,无法通过一次对话就完成。
明确了这三个问题,我们就知道Agent该怎么设计了,接下来的方案设计,核心都是围绕这三个问题进行的。为了方便,我给这个Agent起了一个名字叫皮皮虾。
我们可以把大模型的本质理解为一个无状态的函数:
output=Model(input)
我们能控制的只有两部分:构造输入给大模型的提示词,解析大模型输出的消息。所有和大模型的直接交互,本质上都是在构造输入(提示词)或者解析输出。有了这个认知,我们就可以理解如何解决刚才提到三个问题。
大白话讲解Agent的核心流程
Tools Use 如何给大模型装上一双手
针对第一个问题,我们需要让大模型可以使用工具,这里的工具涵盖范围非常广,只要能被大模型调用的外部能力,我们都可以当做"工具",比如皮皮虾实现了网络搜索、bash脚本、文件读写等工具。这些工具都可以简单理解为一个函数(或是一段程序),那么大模型怎么使用工具呢? 第一步就是需要让大模型知道有哪些工具可以用,以及怎么调用。
还记得上面说到我们和大模型的交互本质上就是构造输入和解析输出吗,显然,大模型要知道有些工具可以用,其实就是构造输入,通过将工具列表和使用方法输入和大模型,让大模型感知到这些工具。
比如我们可以在提示词中增加这样一段信息:
json
"tools" : [
{
"name" : "web_fetch" ,
"description" : "获取网页内容并转为纯文本。输入 URL,返回页面文本内容。" ,
"input_schema" : {
"type" : "object" ,
"properties" : {
"url" : {
"type" : "string" ,
"description" : "要获取的网页 URL"
}
},
"required" : [
"url"
]
}
}
]那么大模型就能知道有一个 web_fetch 能力可用,且知道如何调用的规范。那么大模型该怎么调用呢? 聪明的你肯定立刻明白了,只要在输出的消息中加入一段调用的逻辑就行了。
实际上确实是这样,大模型会自行判断是否需要搜索,如果需要的话,会按照约定的格式输出调用信息,如下:
css
[ { "type" : "tool_use" , "id" : "call_c0dd2a921a2c4245951a9332" , "name" : "web_search" , "input" : { "query" : "北京天气" } }]当我们解析到大模型的输出中包含 "tool_use" 时,就可以触发工具使用的逻辑,解析出需要调用的函数和对应的参数,执行调用。
如何让大模型有记忆
由于目前所有的大模型服务都是无状态的,因此你调用大模型服务的每一次对话本质上都是一次独立的调用,这样会导致连续对话时大模型会忘记之前的对话内容。
但是有的小伙伴可能会反驳了:"不对呀,我和豆包对话她记得很清楚呀"? 不要把豆包大模型服务和豆包应用搞混了,那不是大模型服务的记忆,而是豆包应用通过一些记忆管理的方式,赋予了大模型记忆。
由于大模型是无状态的,我们无法直接让他记住任何内容,因此我们只有一个办法,就是把需要记住的内容全部注入到提示词中,这样大模型就等价于拥有了记忆。举个最简单栗子,我们每一次都把最近几条聊天消息都追加到提示词中,大模型不就有记忆了?
swift
"messages" : [
// 省略一些更早的会话消息
{
"role" : "assistant" ,
"content" : [
{
"type" : "text" ,
"text" : "小明,这是北京今天及未来两天的天气情况:\n\n## 🌤 北京天气预报\n\n### 📅 今天(5月25日,星期一)\n- **当前**:多云,19°C,西南风 5 km/h\n- **早上**:小雨,20°C,降水概率 100%\n- **中午**:小雨,19°C,降水概率 100%\n- **傍晚**:多云,18~19°C,无降水\n- **夜间**:多云,18°C,无降水\n\n### 📅 明天(5月26日,星期二)\n- **早上**:☀️ 晴,23~25°C\n- **中午**:☀️ 晴,27°C\n- **傍晚**:☀️ 晴,26~27°C\n- **夜间**:🌙 晴朗,23~25°C\n\n### 📅 后天(5月27日,星期三)\n- **早上**:☀️ 晴,25~26°C\n- **中午**:☀️ 晴,26~27°C\n- **傍晚**:☀️ 晴,28~29°C\n- **夜间**:🌙 晴朗,26~27°C\n\n---\n\n⚠️ **温馨提示**:今天上午有小雨,出门记得带伞!明天开始转晴,气温回升,后天最高可达 29°C,注意防晒哦~"
}
],
"_timestamp" : 1779708096278
},
{
"role" : "user" ,
"content" : "明天去北京推荐一下景点" ,
"_timestamp" : 1779708061308
}
],这里用户只输入了"明天去北京推荐一下景点",但是我们可以把最近几次对话的消息都带着,这样就可以让大模型拥知道之前我还问过他天气相关的事情,就可以更好的推荐景点。
记忆是大模型非常重要的能力,历史消息只是非常基础的实现。记忆能力的设计是比较复杂的,其核心在于如何在有限的上下文长度中,尽量让大模型记住重要的信息。为什么是有限的上下文长度,而不是将所有消息都一股脑塞给大模型呢?一方面是现在的大模型提示词长度有限,另一方面是避免无用信息过多影响大模型注意力,同时还需要输入提示词过长带来的考虑成本因素。
除了这些外,记忆的存储结构也比较重要,这里我选择了相对简单的markdown文件做存吃,好处是实现简单且方便查看和编辑,后续可以考虑向量数据库存储数据接入RAG。
如何让大模型持续工作 Agent Loop
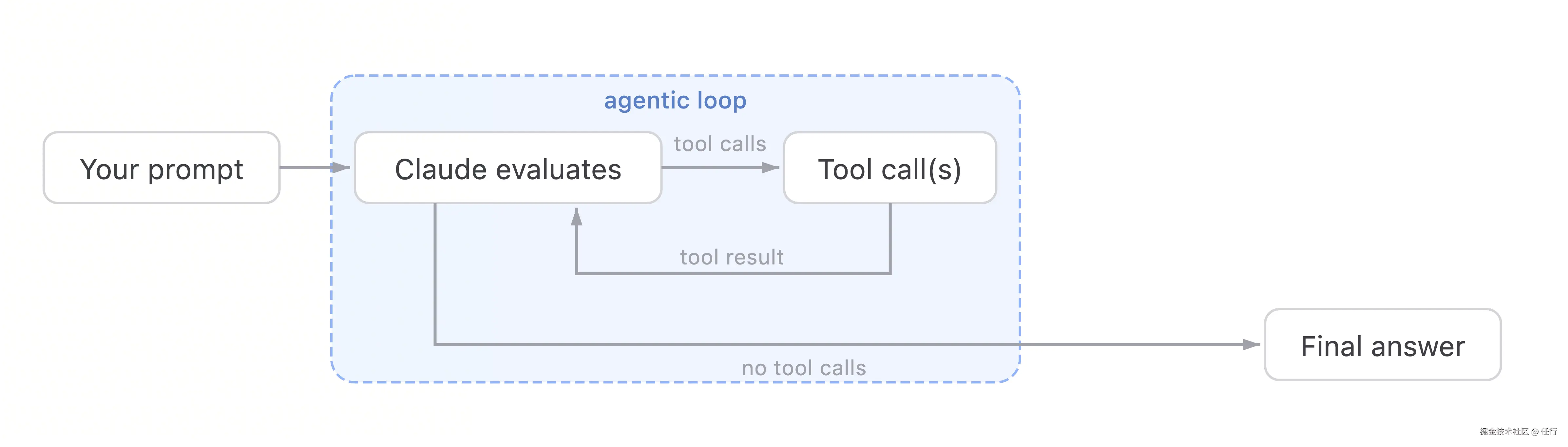
一个复杂的任务可能包含很多次的搜索、思考、执行命令等操作,不是单一一次大模型调用能完成的,所以能否持续稳定的工作,是Agent完成大型任务的基础。
Agent持续工作,本质上是不停进行大模型的循环调用,直到任务完成。这个循环调用的过程,就是"Agent Loop",上图是claude code中解释 Agent Loop的流程图。如何理解这个图呢?
当你输入提示词后,Agent会循环进行调用工具、理解结果的过程,直到任务完成。比如你输入"北京明天天气",大模型会先调用web_search进行搜索,根据搜索结果进行总结,然后输出一个表格。
那么怎么知道任务是否完成呢?很简单,只要没有工具调用就不会继续循环了,那么任务就是完成了。
当然这只是最核心的流程,实际上这里面会涉及到记忆、工具调用、Skills等很多内容,我们后文会逐步展开讲解。
核心架构设计
主循环生命周期和插件化架构
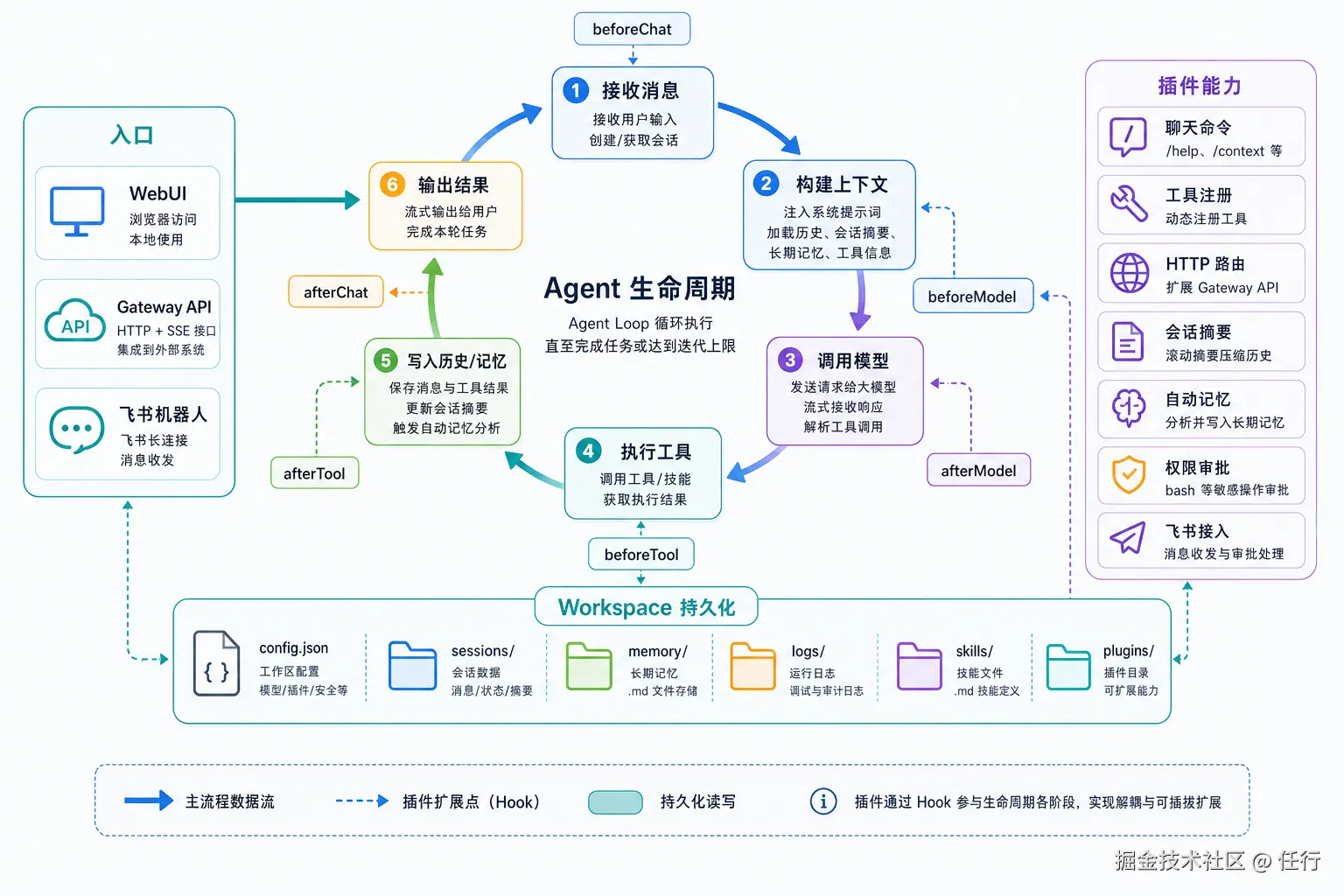
虽然是一个玩具,但是为了让AI Coding能持续稳定进行,我需要代码结构足够清晰,拓展性和可维护性足够强。因此我希望这个项目的核心架构非常稳定,后续迭代功能只需要在这个稳定的架构之上不断迭代,像搭积木一样简单可控。同时我也希望除了核心流程之外,大部分功能都是可插拔、可自定义的,可以通过配置文件启用插件,也可以通过工作目录中的 plugins 目录安装自定义插件。
基于这个目标,我设计了一个插件化的架构,其核心就是 Agent Loop,我把这个流程划分成不同的阶段,并定义对应的生命周期,可以作为插件的挂载点。目前有这些生命周期:
| 生命周期 | 说明 |
|---|---|
| init | 插件初始化阶段,用于注册工具、聊天命令、HTTP 路由、Hook 等能力。 |
| beforeChat | 用户消息进入 Agent 主流程前触发,可用于预处理输入、处理命令或拦截请求。 |
| beforeModel | 调用大模型前触发,可用于注入上下文、会话摘要、记忆、裁剪历史消息。 |
| afterModel | 大模型返回后触发,可用于解析或增强模型输出、记录日志、触发后处理。 |
| beforeTool | 工具执行前触发,可用于权限检查、审批、审计或修改工具参数。 |
| afterTool | 工具执行后触发,可用于记录工具结果、审计日志、截断结果或触发副作用。 |
| afterChat | 一轮对话结束后触发,可用于保存会话状态、更新摘要、自动记忆分析等。 |
| dispose | 插件卸载或进程退出时触发,用于释放连接、停止定时器、清理资源。 |
除了核心循环外,绝大部分功能都是通过插件形式实现的,这样每一个插件都能比较独立地进行迭代,避免对核心流程和其他插件造成影响。
记忆架构
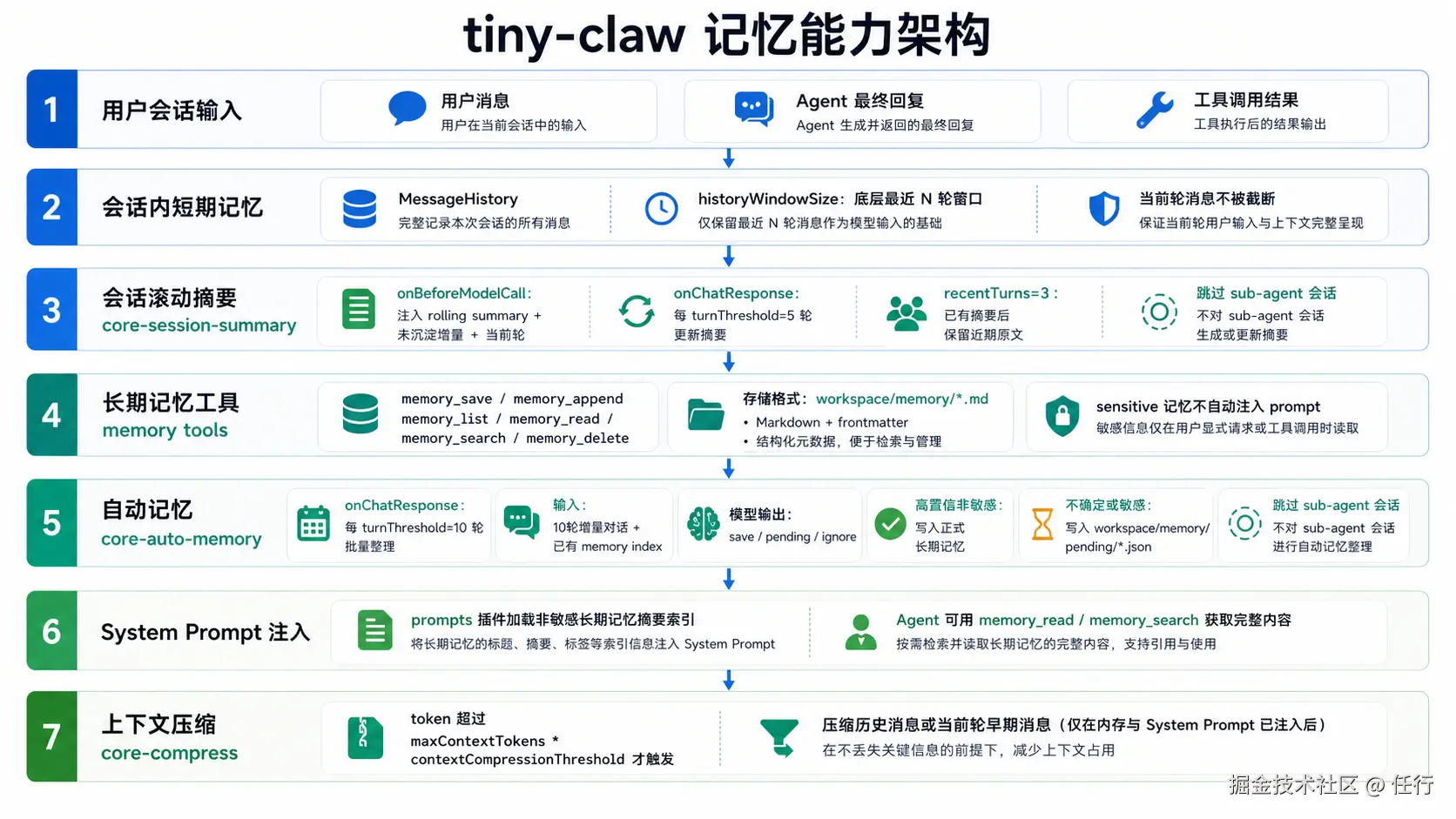
大模型如何在有限的上下文长度中记住所需的信息,是Agent设计的一个关键点。为了能让Agent拥有合理的记忆能力,本项目中设计了分层记忆能力,包括这些:
-
用户输入:当前轮对话用户输入的原始消息。
-
历史消息:一般来讲,当前对话的前几轮对话是相对比较重要的,直接将这些历史消息的原文放到提示词中,这样连续的对话中大模型总能很好记住最近的对话。
-
会话持久化记忆 Session Memory:对话轮次过多之后历史消息会变得非常大,所以当执行了一定轮次对话后,都会触发会话持久化记忆,会将之前的所有消息做一次压缩,并将压缩后的摘要信息存储起来。为了方便阅读和理解这里我依然选择使用markdown文件进行存储。这样可以以较少的成本记住会话关键信息,并且会话切换或者网关重启时依然能保持记忆。这个记忆是按照会话维度分别存储的,因此不会导致不同会话之间出现记忆混乱。
-
全局持久化记忆 :这是所有会话都可以读写的全局记忆,以markdown形式存储在
workspace/memories/中,并提供了工具可以让大模型在合适的时候主动写入或者读取记忆,也可以根据用户执行进行读写。为了避免全局记忆过大影响上下文,每次大模型默认只会读取记忆摘要,只有需要的时候才会读取全文。 -
System Prompt 身份设定 :通过
identity.md等文件给大模型做的身份设定,前面的三种都是Agent自动操作的,只有这个记忆是用户 -
上下文压缩: 上面这些都是会被注入到提示词模板中的,因此提示词会变得很大,有可能会超过上下文窗口,因此在发送给大模型前,会统一进行一次上下文压缩,并且这次压缩是通过规则设定的,而不是调用大模型进行压缩(因为可能已经溢出来,无法调用大模型进行压缩)
代码结构
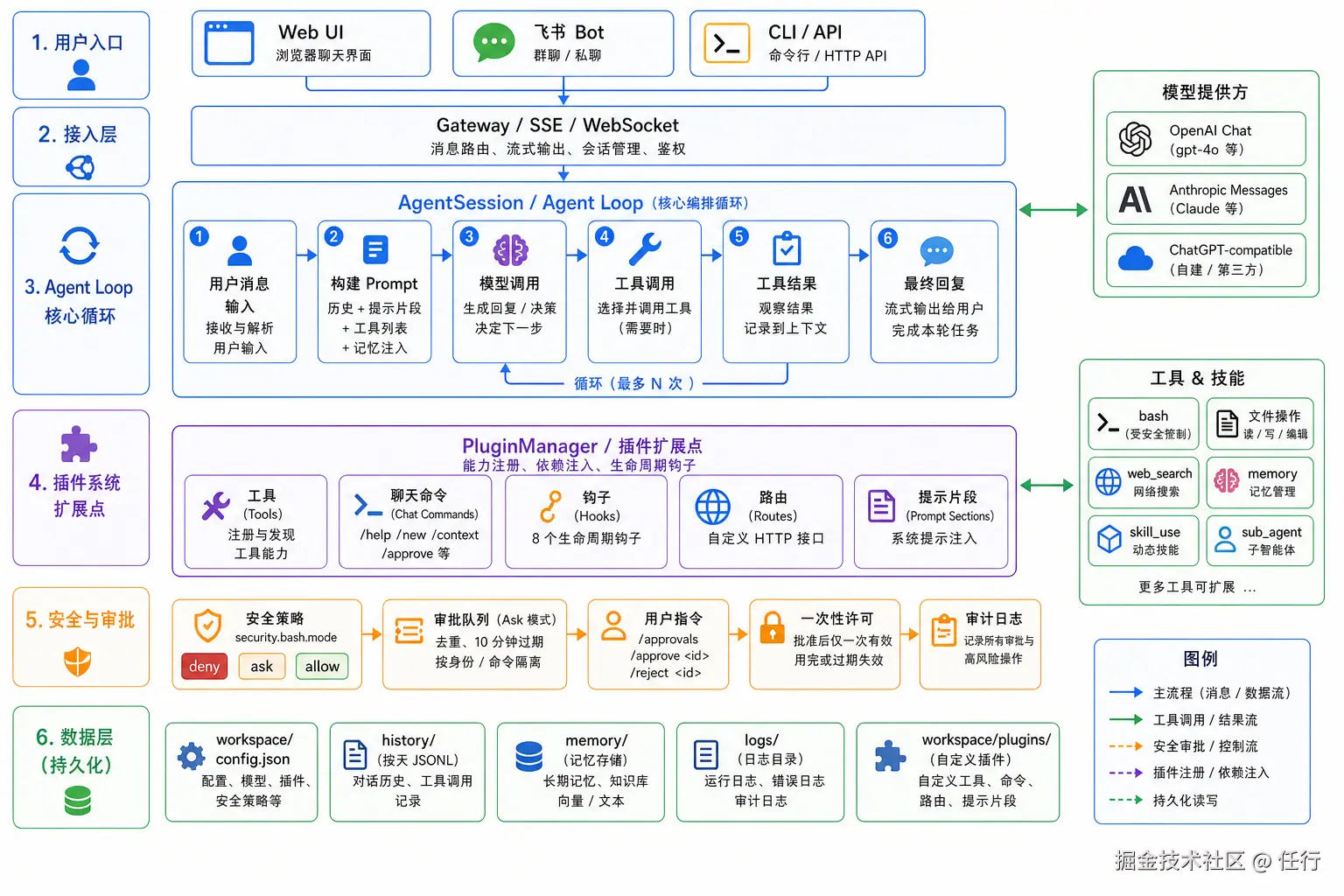
整体代码结构分为这些层:
-
接入层:封装好的接入能力,用户通过接入层与Agent进行交互
- gateway:启动网关服务,主要能力都通过网关对外提供,包括加载配置、收发消息、管理session、调用agent等,网关同时会启动webui服务
- webui:web界面,提供对话、会话管理、配置管理、日志查看等能力。
- cli:在命令行启动单次会话,适合无界面的环境或者简单测试
- 聊天工具:通过飞书、微信等聊天工具接入,目前只适配了飞书
-
Agent Loop:核心工作流,实现了主循环和生命周期挂载点,主循环的核心流程:
- 构建提示词:通过提示词模板构建提示词,将身份设定、历史消息、持久化记忆、工具、技能等和用户输入的提示词一起构建出输入给大模型的原始消息
- 调用大模型:构建好提示词后就可以直接调用大模型,这里要注意流式消息适配。
- 工具调用:大模型输出的结果中如果存在工具调用,那么需要解析出对应的工具名称、参数,然后执行调用,并将工具调用的结果加入到提示词中,继续调用大模型
- 最终回复:持续循环到没有任何工具调用时结束循环,输出最终结果给用户。
-
插件层:通过注册插件提供大部分核心功能,内置插件提供文件读写、网络请求、记忆管理、技能调用、SubAgent等能力,并可以在工作目录中自定义插件。
-
权限管理:既可以通过设置不同的模式来快速设置权限,也可以给每一类工具单独设置权限。
-
工作目录:用户的工作目录,区别于src目录,这里存放的是用户的配置、身份设定、技能、插件、持久化记忆、运行日志等数据。
基础功能实现
提示词
提示词是大模型唯一的输入,所以所有需要大模型知道的信息必须都放入提示词中。项目中默认的提示词模板如下:
shell
你是一个自主 AI Agent,名为 tiny-claw。你可以使用各种工具来帮助用户完成任务。
请根据用户的指令自主规划并执行任务,在需要时调用合适的工具。
每次执行工具后,基于结果决定下一步行动或给出最终回答。
重要规则:当工具已经返回了足够的信息来回答用户问题时,直接给出最终回答,不要重复调用相同的工具。避免不必要的工具调用。
当前日期:{{current_date}}
## 内置工具
{{tools}}
## 身份设定
{{identity}}
## 长期记忆
以下是你在之前的对话中记住的信息:
{{memories}}
## 可用技能
以下技能可通过 skill_use 工具激活:
{{skills}}当用户输入后,会将内置工具、身份设定、长期记忆、技能都注入到提示词,一起发送给大模型。聪明的你可能已经发现了,这里好像少了一些内容呀,比如用户输入的原文都不见了,历史消息也没有呀?
确实是这样,因为给大模型的提示词其实是一个JSON结构,这只是其中的一段文本,用户原文、历史消息、工具定义等都是通过独立的JSON对象发送的,大模型接收到的完整提示词是这样的:
swift
{
"provider" : "openai-chat" ,
"mode" : "chat" ,
"url" : "https://ark.cn-beijing.volces.com/api/coding/v3/chat/completions" ,
"body" : {
"model" : "glm-5.1" ,
"max_tokens" : 4096,
"messages" : [
{
"role" : "system" ,
"content" : "你是一个自主 AI Agent,名为 tiny-claw。你可以使用各种工具来帮助用户完成任务。\n请根据用户的指令自主规划并执行任务,在需要时调用合适的工具。\n每次执行工具后,基于结果决定下一步行动或给出最终回答。\n重要规则:当工具已经返回了足够的信息来回答用户问题时,直接给出最终回答,不要重复调用相同的工具。避免不必要的工具调用。\n调用 memory_save 保存长期记忆时,请尽量同时提供 summary、tags、scope;summary 应为不超过 80 字的短摘要。\n\n当前日期:2026-05-30\n\n## 内置工具\n- web_search: 搜索互联网获取信息。输入1-3个简短英文关键词(如 'JavaScript'、'iPhone 17'),不要输入完整句子或长查询。搜索结果由你负责总结。\n- web_fetch: 获取网页内容并转为纯文本。输入 URL,返回页面文本内容。\n- bash: 在 shell 中执行命令并返回输出。用于运行 git、npm、ls 等命令。不要用于读取文件(用 file_read)或写入文件(用 file_write/file_edit)。\n- file_read: 读取文件内容,返回带行号的文本。支持按行号范围读取。\n- file_write: 创建或覆盖写入文件。自动创建不存在的父目录。\n- file_edit: 精确替换文件中的文本片段。old_text 必须在文件中唯一匹配。用于修改已有文件,而非重写整个文件。\n- memory_save: 保存或覆盖一条长期记忆。当用户明确告诉你需要记住的信息时(偏好、约定、事实等),用此工具记录下来。name 是文件名(不含 .md),content 是记忆内容\n- memory_append: 追加内容到已有的长期记忆文件。当有新的信息需要补充到已保存的记忆中时使用,如果文件不存在会创建\n- memory_list: 列出长期记忆摘要索引。当用户询问你记住了什么、或者你想回顾已有记忆时使用。{{为避免文章太长,这里省略一些其他内容}}"
}, // 这里是提示词模板构造出来的内容
{
"role" : "user" ,
"content" : "查一下iphone"
},
{
"role" : "assistant" ,
"content" : "你的查询有点宽泛,我先按最新的 iPhone 资讯帮你搜一下,看看 2026 年 5 月这个时间点的相关消息。" ,
"tool_calls" : [
{
"id" : "toolu_vrtx_01WtVQ4qgzre5qDFJYunxd4w" ,
"type" : "function" ,
"function" : {
"name" : "web_search" ,
"arguments" : "{"query":"iPhone 2026"}"
}
}
]
},
// 以上是历史消息
{
"role" : "user" ,
"content" : "公众号运营规范是啥" // 用户最新输入的提示词其实在这里
}
],
"stream" : true,
"tools" : [ // function calling,所有function的定义在这里
{
"type" : "function" ,
"function" : {
"name" : "web_search" ,
"description" : "搜索互联网获取信息。输入1-3个简短英文关键词(如 'JavaScript'、'iPhone 17'),不要输入完整句子或长查询。搜索结果由你负责总结。" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"query" : {
"type" : "string" ,
"description" : "搜索关键词"
},
"count" : {
"type" : "number" ,
"description" : "返回结果数量,默认5" ,
"minimum" : 1,
"maximum" : 10
}
},
"required" : [
"query"
]
}
}
},
// 省略更多工具定义
]
}
}工具调用 Function Calling
| 工具名称 | 用途 |
|---|---|
| web_search | 搜索互联网信息,支持 DuckDuckGo / SearXNG / Brave provider |
| web_fetch | 获取网页正文内容 |
| bash | 执行 shell 命令 |
| file_read | 读取工作区内文件内容 |
| file_write | 写入文件,必要时创建父目录 |
| file_edit | 对文件做精确文本替换 |
| memory_save | 保存或覆盖长期记忆,支持 summary、tags、scope、sensitive 元数据 |
| memory_append | 向已有长期记忆追加内容 |
| memory_list | 列出长期记忆摘要索引,默认过滤敏感记忆 |
| memory_read | 读取指定长期记忆的完整内容 |
| memory_search | 按关键词搜索长期记忆摘要 |
| memory_delete | 删除指定长期记忆 |
| skill_list | 列出可用技能 |
| skill_use | 激活并读取指定技能的完整指令 |
| sub_agent_run | 并行启动一个或多个临时 sub-agent 执行独立子任务 |
目前实现了上面的这些内置工具,目前的实现主要是参考 ChatGPT 的 Function Calling规范。
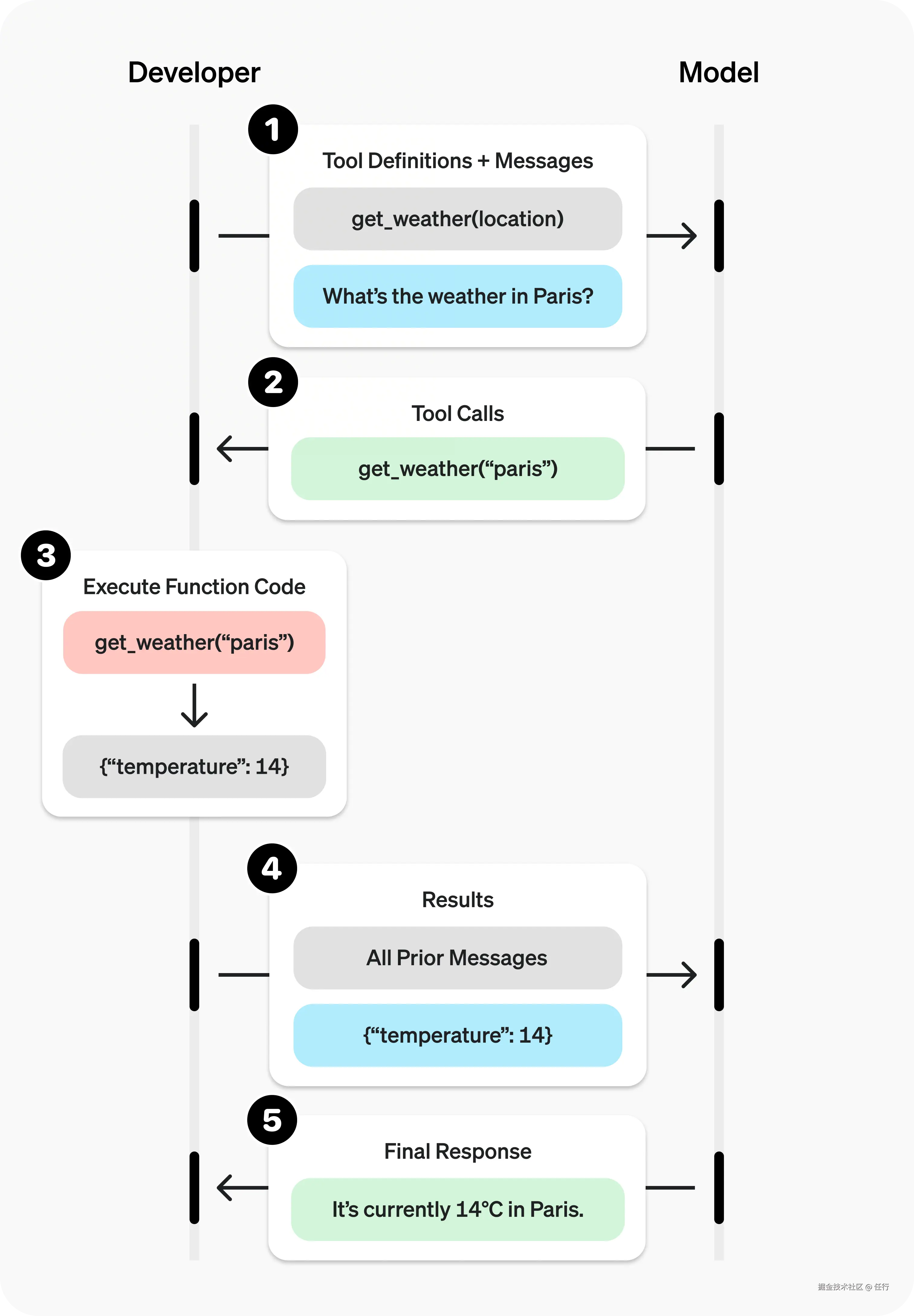
这里直接借用ChatGPT的官方文档中的流程图,可以很好解释 Function Calling的执行流程。
第一步,在提示词中注入工具的声明,比如这是 web_search 的声明,放在 tools字段。
第二步,当大模型接收到定义后,会判断需要的时候就调用工具,通过输出消息中的 toolCalls 字段来声明调用。
第三步:当Agent接收到大模型的输出时,根据 toolCalls 字段中的信息,解析出需要调用的工具和参数,并执行调用。
第四步:将调用工具的输出结果合并到历史消息中,然后再次调用大模型。
第五步:大模型读取到工具调用结果,并执行后续操作。
记忆能力
历史消息和会话记忆
会话记忆是最基础的记忆能力,当用户和Agent进行连续对话时,如何保证Agent不会忘记前面的对话呢?
最简单的实现显然是每一次对话,都将将历史对话全部写入到提示词中,这样做能保证AI总是记住当前会话的所有历史,但是随着对话进行,当历史变得非常多的时候会有2个明显问题:
- 上下文溢出:目前主流的模型提示词长度范围是128K~1MB,过长的历史消息会超出提示词长度
- 注意力不集中:即使提示词长度没有超出限制,过多的历史消息可能导致模型注意力不集中,表现为对话轮次越多则工作能力越低。
为了解决这个问题,需要增加了历史消息压缩功能,核心思路是保留最近N条消息的原文,把更早的消息整体压缩为摘要,如下所示:
python
"messages" : [
{
"role" : "user" ,
"content" : [
{
"type" : "text" ,
"text" : "[当前会话摘要]\n**用户目标**:查询北京天气\n**关键事实**:北京5月25日当前多云19°C(早/午有小雨,降水概率100%),5月26-27日转晴,最高温可达29°C。\n**已完成事项**:成功获取并回复北京天气预报。\n**涉及工具/API**:web_search(调用失败),web_fetch(wttr.in,调用成功)\n**未完成事项**:无"
},
{
"type" : "tool_result" ,
"tool_use_id" : "call_c0dd2a921a2c4245951a9332" ,
"content" : "{"error":"未找到相关结果"}"
}
],
"_timestamp" : 1779708065540
},
// 省略未被压缩的其他消息
]那么如何进行历史消息压缩呢? 显然最好的办法还是调用大模型。在触发历史消息压缩后,直接进行一次单独的大模型调用,让大模型进行压缩,然后将压缩的摘要消息存储。当前会话被压缩的历史消息,就叫"会话记忆",会话记忆只在当前会话中生效,不同的会话中不能共享,否则会出现记忆错乱。
json
{
"version": 1,
"sessionId": "70c58451-a7cf-48ce-820d-0d04f55c79d8",
"summary": "XXXXXXXXX", // 目前的摘要信息
"pendingMessages": [], // 还未被摘要的对话
"turnsSinceSummary": 3, // 还未被摘要的对话轮次数量
}会话记忆功能是如何实现的呢?这里是通过"滚动摘要"的方式实现的,上面是会话记忆的结构,summary 保存的是已经记录的摘要。每当发生一轮新的对话,会将对话内容写入 pendingMessages 中,并更新 turnsSinceSummary 计数,当计数达到配置的阈值时,会调用大模型对 summary 和 pendingMessages 一起做一次新的摘要,然后写入到 summary 中,并清空 pendingMessages 重置 计数。通过不断循环这个过程,就可以保证会话记忆总是最新的。
lua
- sessions
-- session-1
-- state.json // 持久化记忆
-- meta.json // 元数据
-- messages.jsonl // 历史消息
-- session-2
-- state.json
-- meta.json
-- messages.jsonl所有的会话记忆都是按照会话ID存储在 workspace/sessions 中,因此不同的会话之间的记忆是不共享的。
总结下最终大模型收到的会话记忆包括两部分:
- 最近N轮对话的全文,这个阈值在config中可以配置
- 所有更早的对话的摘要消息
这里其实还有一个小点:最近N轮对话的全文是否应该包括工具调用的全文呢? 经过思考,现在做法是只有当前正在进行的对话轮次需要记录所有工具调用,而最近的N轮对话是不需要的,不然很容易因为工具调用产生的大量输出而撑爆上下文,也可能因为数据量太大导致模型注意力不集中。
全局持久化记忆
除了会话记忆外,我们还可能会有一些需要全局记住的记忆,这里就需要全局持久化记忆。
如前文所说,本项目的持久化是基于markdown文件做的。为了能同时达到"记住尽量多的数据 " 和 "使用较少的上下文"的目的,我参考Skills的设计,将记忆按照文件组织,每一个文件只记住某一类事情,同时在文件头部增加摘要信息。
记忆文件在workspace中的存储位置和结构示意:
markdown
- workspace
- memory
- code-style.md // 编码规范
- wechat-publisher-guidelines.md // 公众号文章运营规范
- .... // 其他的记忆都分类放在此目录中记忆文件的格式示例如下:
yaml
---
name: wechat-publisher-guidelines
tags: [wechat, 公众号, 运营规范]
createdAt: 2026-05-30T09:17:25.212Z
updatedAt: 2026-05-30T09:17:25.212Z
sensitive: false
scope: global
summary: 微信公众号科普文章运营规范:选题、排版、内容、防重复、自我审查、推送全流程要求
---
这里是详细的记忆数据当构建提示词时,会自动加载全部记忆并注入到提示词中。 中间有一版设计的是参考skills,只注入summary,等大模型需要的时候调用 memory_read 读取完整记忆,后来测试发现这样并不靠谱,因为summary丢失了太多的细节,等于啥都没记住,所以还是改成了默认 读取完整记忆。
如果是有一些特别大的数据无法全部加载,则不应该存储在memory中,应该用RAG之类的方案,memory模块还是保持纯粹:默认全部加载。
Skills
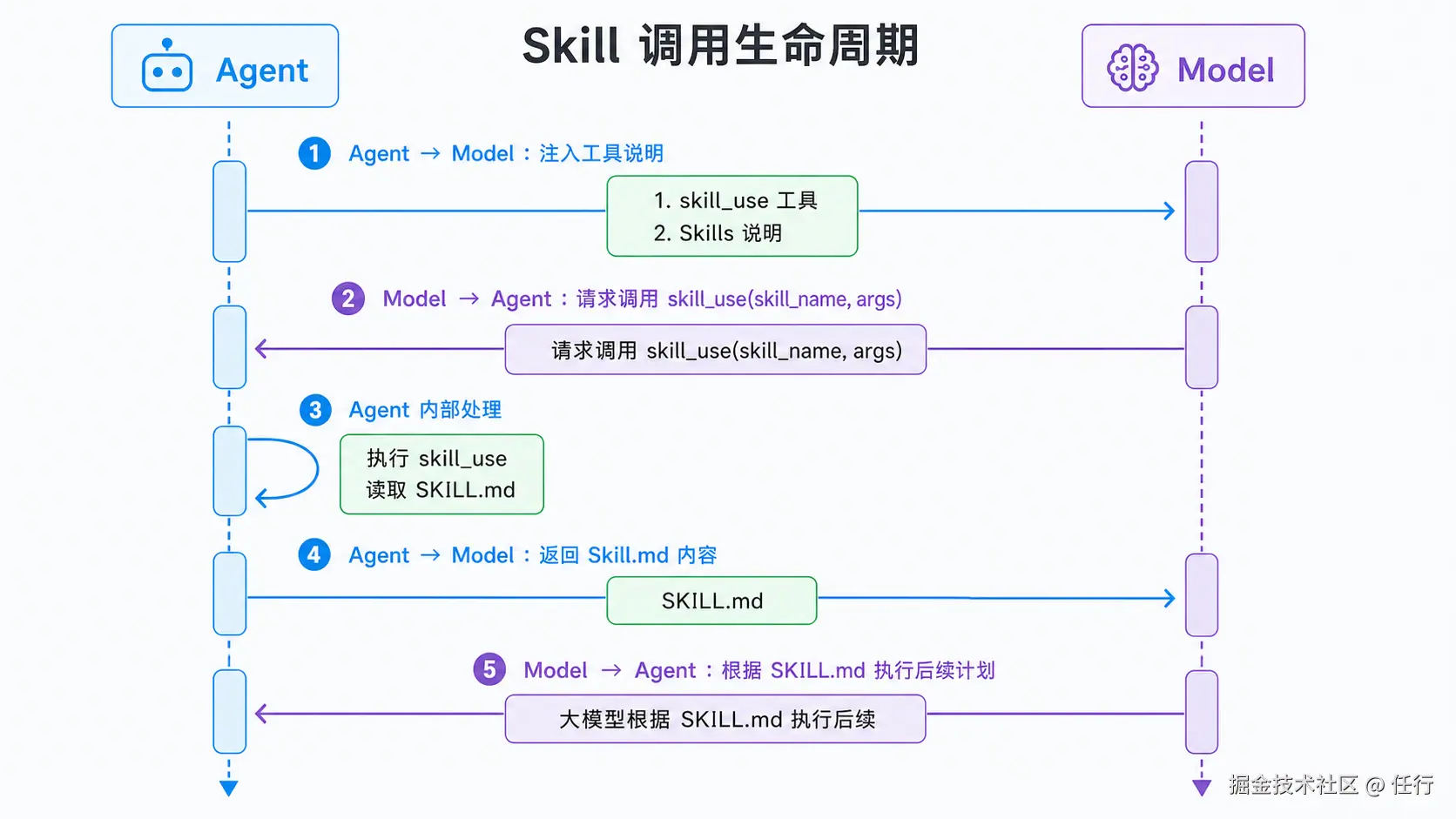
技能听起来是很高级的能力,实际实现却很简单,主要实现逻辑包括这几个步骤:
第一步,让模型感知到技能。为了让模型感知到有哪些技能可以用,只需要在提示词注入 skill_use工具,以及对应技能的说明即可。如下文是2个技能的说明,以文本形式放在提示词中:
kotlin
以下技能可通过 skill_use 工具激活:
code- review : 代码审查,检查代码质量、安全性和最佳实践
tea-open- api : 使用 TEA Open API 查询和分析 TEA 数据平台数据。**一定要在用户提到 TEA 、数据分析、事件分析、或提供 data. bytedance . net /tea-next 链接时使用这个 skill,即使他们没有明确说要查询数据!** 当用户提供 TEA - Next 分析页面链接、需要查询事件分析数据、修改查询条件(日期、分组、筛选)、或从 TEA 获取数据时使用此 skill。触发词: TEA 链接、事件分析、数据查询、data. bytedance . net 、tea-next、提取 DSL 。 第二步,当大模型需要的时候,会返回对 skill_use 工具的调用说明,包括需要调用的skill和对应的技能名称、参数
json
{
"toolCalls" : [
{
"type" : "tool_use" ,
"id" : "call_31436469f5574641a66b7690" ,
"name" : "skill_use" ,
"input" : {
"args" : "将以下中文翻译为英文:"这个城市19世纪因国内外贸易和优越的港口位置迅速崛起"" ,
"name" : "translate"
}
}
]
}第三步,当Agent接收到skill_use 后,会调用工具获取对应skill的完整文档 SKILL.md,发送给大模型,之后大模型可以根据这个完整的说明文档进行更进一步的其他调用,比如调用skill里面的一些方法。
权限和审批
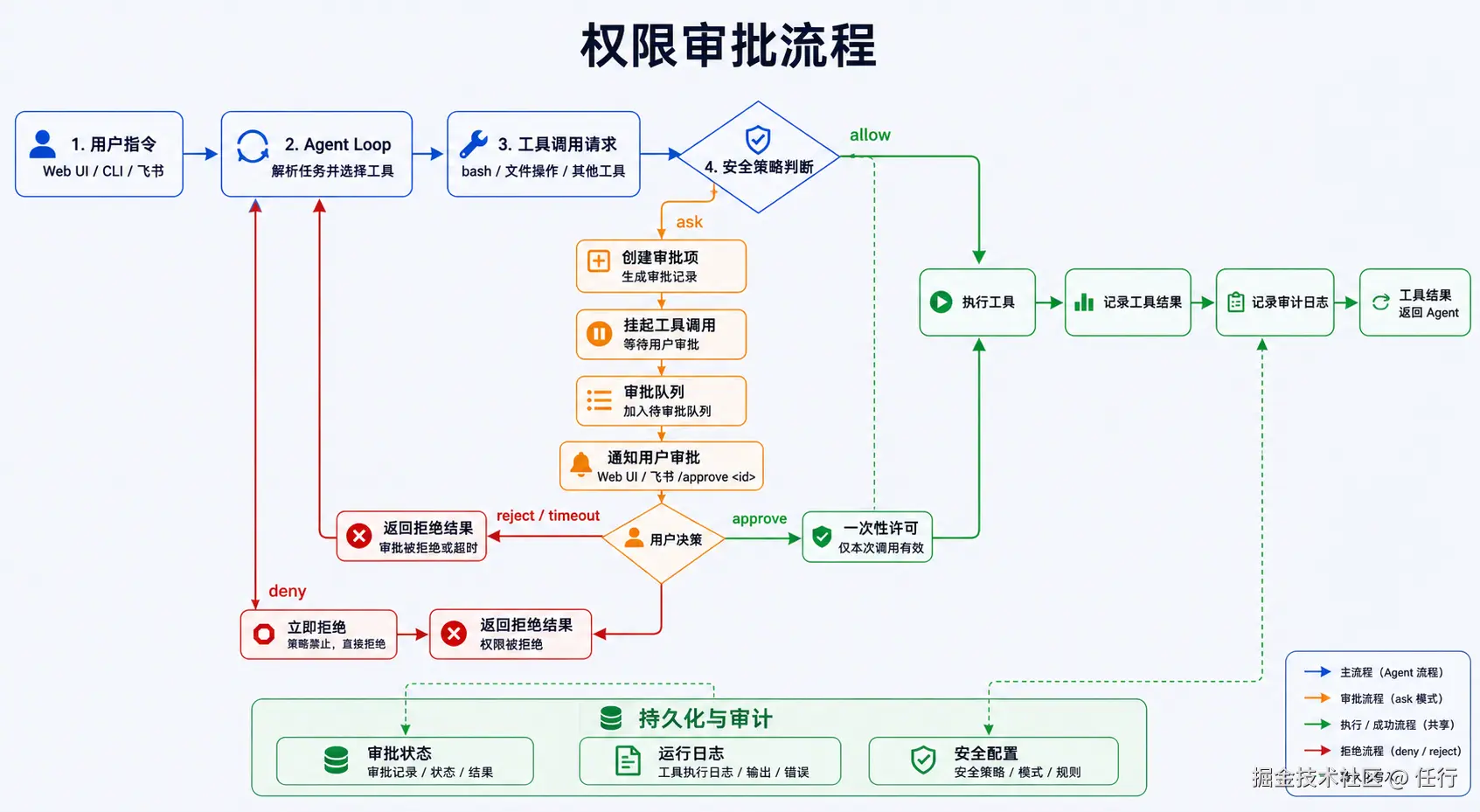
权限管理是Agent运行安全的基石。但权限管理不需要对所有工具都生效,主要针对bash file_write这类执行后会对宿主机带来变化的工具,而网络请求、文件读取相对安全,可以默认放行。以下说的都是针对这些危险工具调用。
我将权限配置分成两层:
- 全局模式:全局模式是默认权限,如果没有单独配置某个工具的权限,则会继承默认权限。
- 工具权限:每一个工具可以单独配置权限,这个权限优先级更高,会覆盖全局权限。
这样的好处是既可以通过一个字段进行全局权限管控,也可以针对某个工具进行单独配置。
json
{
"security": {
"mode": "ask", // 这里配置全局权限
"tools": { // 针对每个工具定制单独的权限
"bash": { "mode": "ask" },
"file_write": { "mode": "ask" }
},
"auditTools": true
}
}那么实现权限管理的核心是这三部分:如何触发、如何鉴权、如何暂停和恢复对话。
首先,如何触发权限校验呢?我是在需要鉴权的tools中实现的,比如 bash 工具,在需要调用前,会先执行权限检查:
typescript
execute: async (args, context) => {
const command = args.command as string;
const timeout = (args.timeout as number) ?? DEFAULT_TIMEOUT;
const cwd = resolve(workspacePath, (args.cwd as string | undefined) ?? ".");
// 检查权限
const permission = checkDangerousToolPermission({
workspacePath,
config: getConfig(),
toolName: "bash",
args,
context,
command,
cwd,
});
// 如果未通过,则返回鉴权结果
if (!permission.allowed) return permission.result;
return execute(command, timeout, cwd, context?.signal);
},checkDangerousToolPermission函数会读取配置决定返回结果,如果权限允许就继续执行,如果不允许则返回鉴权结果,结果包括两种:
-
需要授权:返回审批信息,需要用户审批后执行
-
拒绝:直接拒绝执行,无法继续调用
当触发授权后,如何进行授权,以及授权后如何恢复呢?
当授权模式是 ask 时,Agent不会调用工具,而是暂停当前会话,创建一个授权工单记录当前会话信息,并生成一个唯一 approveId ,然后返回一条首选消息给接入层,需要用户进行授权操作。当用通过webui点击授权,或者通过指令授权完成后,会通过工单记录的sessionId找到被暂停的会话,并恢复执行,并且执行工具时会检查是否和工单id匹配。
当前实现里,Session 的暂停和恢复是靠 AgentSession 内存状态完成的,核心字段是:
typescript
private pendingApprovals = new Map<string, PendingApprovalContinuation>();暂停时发生了什么?模型返回 tool_calls 后,AgentSession.runModelLoop() 会先把 assistant 消息写入历史,然后逐个执行工具。如果某个工具返回:
json
{
"requiresConfirmation": true,
"approvalId": "..."
}AgentSession 会检测到这是一个待审批的命令,则会进入暂停状态,执行如下操作:
- 不把这个 tool result 追加进模型历史
- 把暂停现场写入
pendingApprovals - 立刻
done,停止当前 loop
保存的暂停现场只有三项:
arduino
{
toolCall, // 被拦住的工具调用
skippedToolCalls, // 同一轮里还没执行的后续工具调用
iteration // 当前 loop 轮次
}也就是说,它不是保存整个协程栈,而是保存"恢复所需的最小状态"。
用户批准后,最终都会调用:
scss
session.resumeApproval(approvalId, actor)resumeApproval() 会执行这些操作:
- 从 pendingApprovals 里取出暂停现场
- 删除这条 pending,避免重复恢复
- 重新执行当时被拦住的 toolCall
- 这次权限检查会看到 approval 已经是 approved,于是放行
- 把真实工具结果追加为 tool_result
- 对同一轮里被跳过的其他 tool calls,补一个"已暂停执行"的 tool_result,避免消息链断裂
- 再调用 runModelLoop() 继续后续模型调用
关键点是:恢复不是重新发送用户问题,而是从"被拦住的工具调用"继续接上。
权限管理流程相对是比较复杂的,这里的实现还存在问题,比如一次触发多个工具调用如何授权,用户重启gateway后如何继续之前的授权,子agent中的授权流程等,都需要更复杂的方案来实现。
高级功能实现
Sub Agent
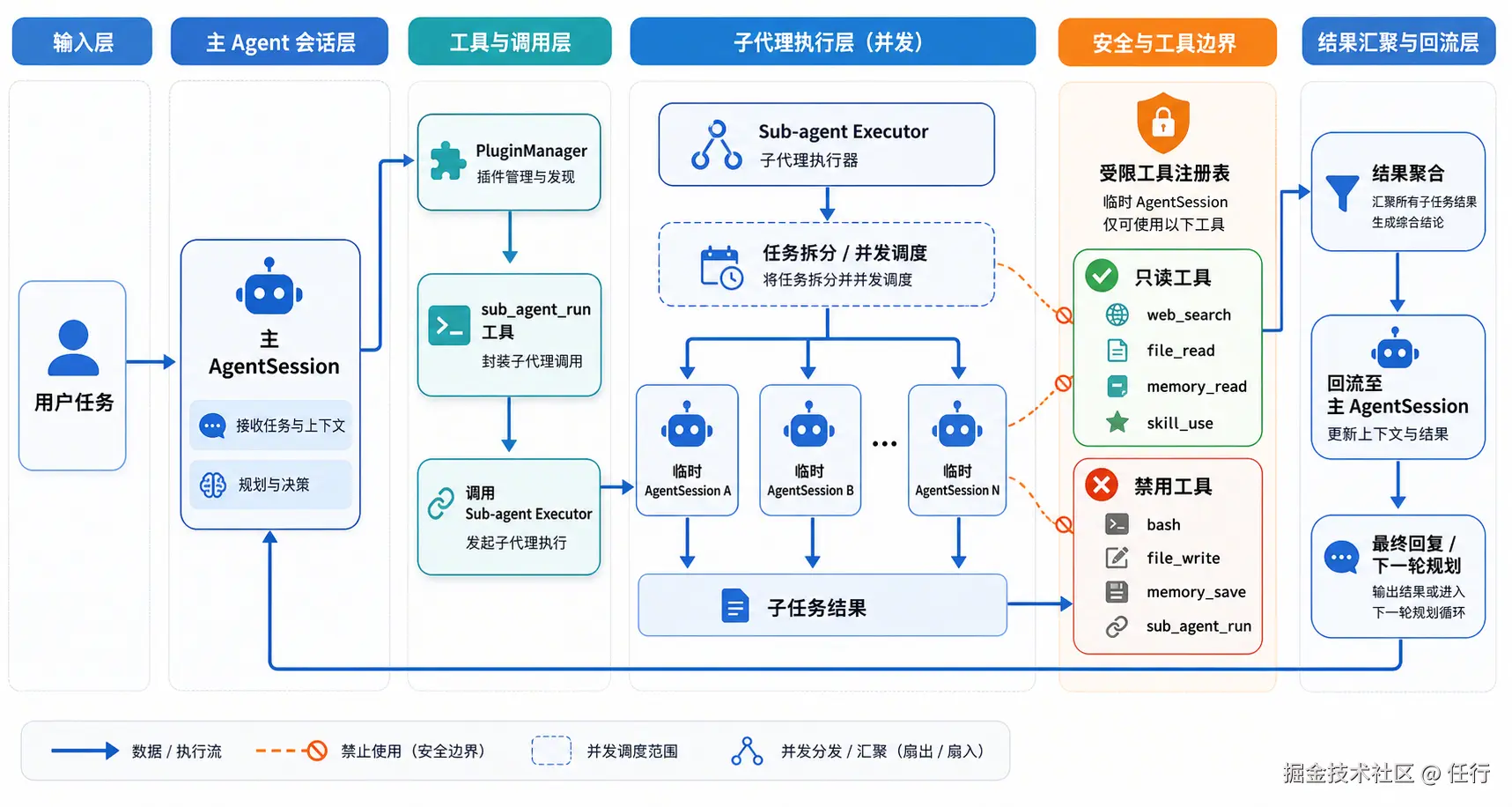
Sub Agent 顾名思义是一个子Agent,为什么需要引入这个能力呢?
其核心作用是是在大型任务中,可以通过子代理去完成子任务,子Agent可以自己规划完成这个子任务,主Agent只关注完成结果。这样做最大的好处是可以让子任务的上下文独立,不会进入到主任务的上下文,避免上下文中引入太多无用信息。
与Multi Agent 的区别?
Sub Agent 是临时、用完就作废的代理,其作用主要是通过拆分任务来隔离上下文,是主Agent完全管控的。而Multi Agent 是长期存在的,各自拥有不同身份的角色,他们之间是合作关系。他们之间的主要区别如下:
| 维度 | Subagents | Agent Teams |
|---|---|---|
| 生命周期 | 短期,任务完成就消失 | 长期,持续存在 |
| 通信方式 | 只和父 Agent 通信 | Agent 之间可以直接通信 |
| 状态共享 | 无共享状态 | 共享任务列表和状态 |
| 协调方式 | 父 Agent 集中协调 | 分布式协调 |
| 作用 | 隔离上下文、并行子任务 | 组成团队,合作完成大型项目 |
| 适用场景 | 独立任务、并行探索 | 需要持续协商的任务 |
表格来源这篇文章并做了一点修改,其内容基本符合我的理解 zhuanlan.zhihu.com/p/201770625...
显然,子Agent更像一个随时调用的工具,和其他的比如web_fetch 一样都是调用工具并拿到结果,不关注过程。他和普通的工具最大的区别在于其内部依然是一个完整的Agent,有完整的 Agent Loop,需要调用大模型服务。
理解了什么是Sub Agent,就知道该怎么实现了,在本项目中 Sub Agent 的实现和 web_fetch 之类的工具实现原理是一样的,包括两部分:
第一部分:通过已有的Tool Use 能力,注册一个 sub_agent 工具,让模型能感知到有这个工具的存在,并知道如何调用。
第二部分:实现 sub_agent 运行逻辑,其核心依然是加载合适的配置,然后启动一个 Agent Loop,这个能力已经封装好,核心代码如下:
ini
// 加载Sub Agent配置
const allowedTools = resolveSubAgentTools(config);
const pm = new PluginManager(workspacePath, {
allowedTools,
disabledTools: ALWAYS_DISABLED_TOOLS,
});
await pm.loadCorePlugins();
// 启动Agent Session
const session = new AgentSession(sessionId, workspacePath, pm, {
maxAgentIterations: maxIterations,
});
let finalText = "";
let sawDone = false;
const toolCalls: SubAgentTaskResult["toolCalls"] = [];
// 实现主循环
for await (const event of session.chat(buildSubAgentPrompt(workspacePath, task, allowedTools), actor)) {
if (event.type === "tool_call") {
toolCalls.push({ name: event.name, input: event.input });
} else if (event.type === "done") {
finalText = event.text;
sawDone = true;
} else if (event.type === "error") {
return {
id,
status: "error",
summary: "",
toolCalls,
error: event.message,
};
}
}
// 返回结果
return {
id,
status: sawDone ? "completed" : "max_iterations_reached",
summary: finalText.trim(),
toolCalls,
};需要注意的是,为了避免工作流混乱,Sub Agent 有如下限制,这些限制都是通过配置就可以实现的:
- Sub Agent 不能再次创建 Sub Agent,避免无限套娃陷入死循环
- Sub Agent 不能调用 bash 等敏感工具,也不能调用 memory_write 等写入记忆,避免通过 sub agent 突破权限控制或者污染主Agent上下文。
飞书插件
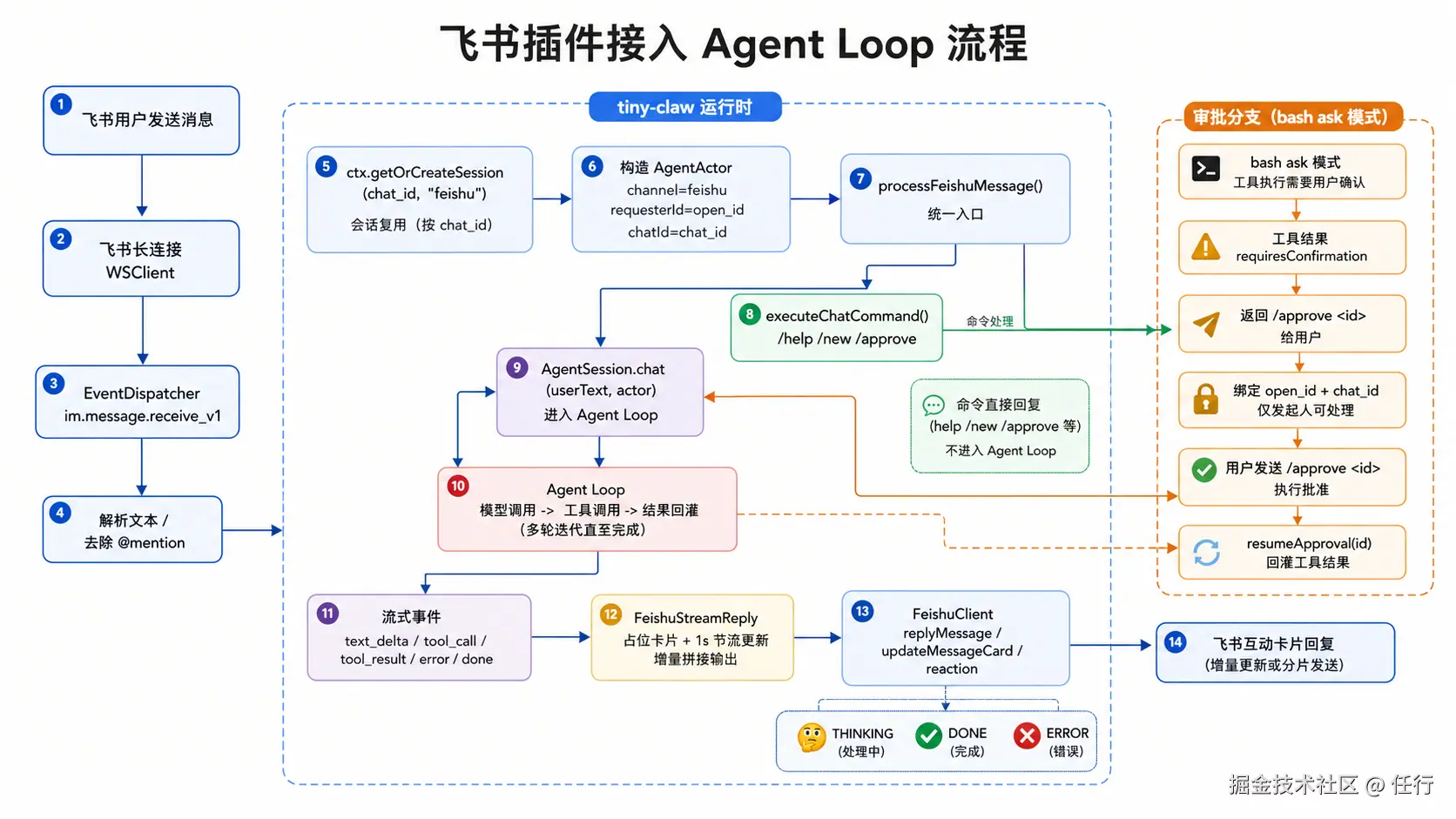
飞书官方插件实现了非常强大的能力,但是也依赖了openclaw的插件体系,如果完全对齐实现成本会很高,导致代码过于复杂,不符合本项目的初衷。因此这里我没有用官方飞书插件,而是实现了一个内置的简易版飞书插件,依赖飞书官方node-sdk,只实现基本的对话能力,没有文档、日程等高级能力。
飞书插件区别与 web_fetch 等工具,他不是一次简单的调用,而是一个新的接入层,在飞书中的对话其实是一个独立的会话,因此飞书插件其实内部维护了一个 AgentSession,而不是简单在某些生命周期钩子上注册能力。
核心代码简化之后如下:
typescript
const eventDispatcher = new EventDispatcher({
verificationToken: cfg.verificationToken ?? "",
}).register({
"im.message.receive_v1": async (data) => { // 收到飞书消息
if (data.message.message_type !== "text") return;
let userText: string
const content = JSON.parse(data.message.content) as { text?: string };
userText = stripMention(userText);
if (!userText) return;
const chatId = data.message.chat_id;
const messageId = data.message.message_id;
const requesterId = data.sender.sender_id?.open_id;
if (!requesterId) return;
const session = ctx.getOrCreateSession(chatId, "feishu"); // 根据情况创建新会话或者复用已有会话
const actor: AgentActor = { channel: "feishu", requesterId, chatId };
feishuClient.addReaction(messageId, "THINKING").catch(() => {});
// 处理飞书消息,此方法内部会调用 session.chat 完成对话,会话消息以流式形式推送给飞书
processFeishuMessage(
session,
userText,
messageId,
feishuClient,
ctx.workspacePath,
actor,
async (input, commandActor) => {
const result = await ctx.executeChatCommand(input, {
sessionId: session.id,
channel: "feishu",
actor: commandActor,
});
return result?.text;
},
).then(() => {
feishuClient.deleteReaction(messageId, "THINKING").catch(() => {});
feishuClient.addReaction(messageId, "DONE").catch(() => {});
}).catch((err) => {
feishuClient.deleteReaction(messageId, "THINKING").catch(() => {});
feishuClient.addReaction(messageId, "ERROR").catch(() => {});
ctx.log("ERROR", `消息处理失败: ${err instanceof Error ? err.message : String(err)}`, session.id);
});
},
});自动记忆 Auto Memory
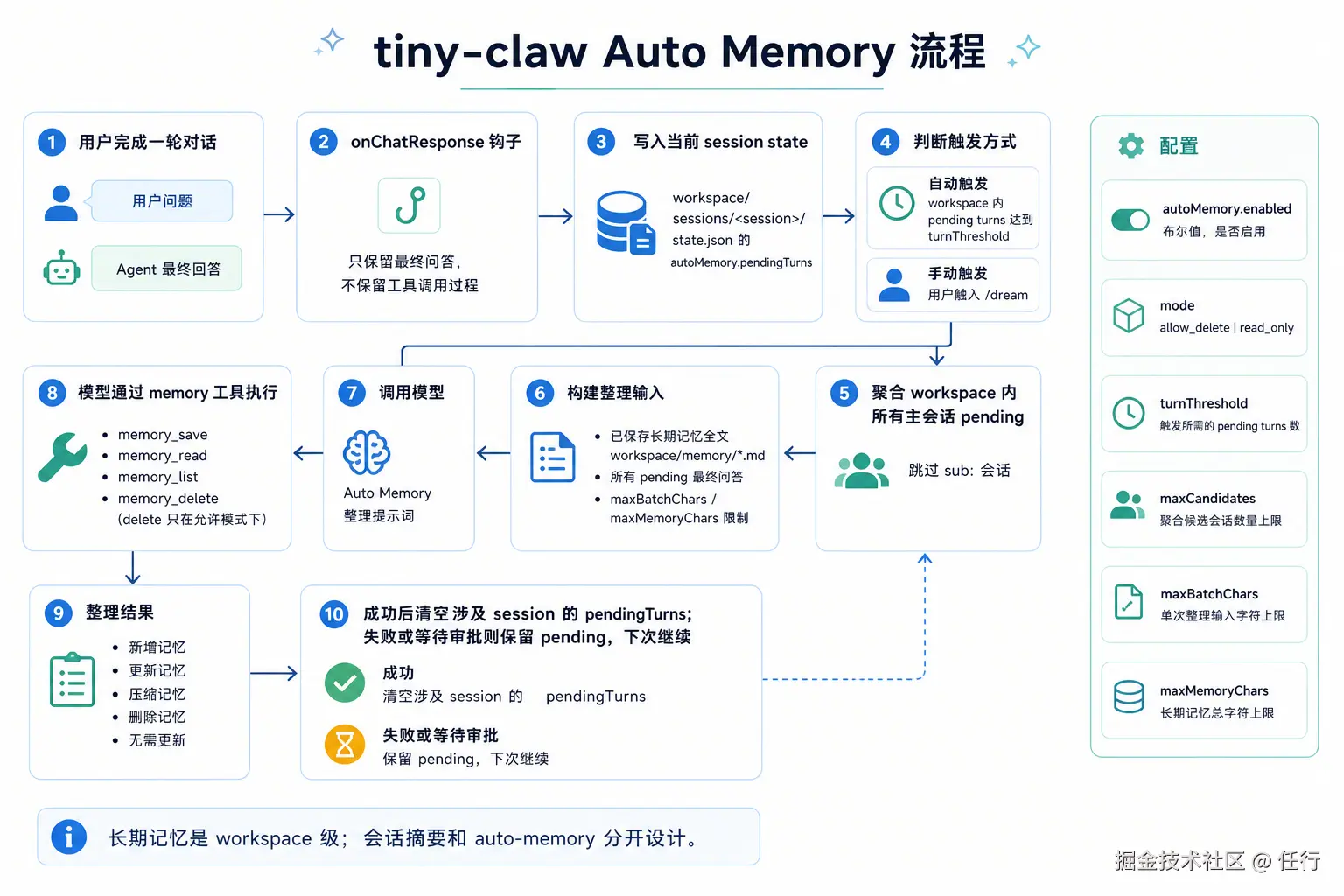
这里参考了claude code的 auto dream思路,claude code 会在一定条件下触发auto dream,会自动整理记忆,并将其中的重要记忆进行持久化存储,这是一个用户不感知的自动过程。
我觉得这是一个非常好的能力,因为现在的记忆机制只能自动整理会话记忆,对于全局记忆只提供了工具,但是没有提供一个自动化的记忆流程,因此我也参考claude code的实现了一个自动记忆能力。这个能力可以有效改善全局持久化记忆。
其核心思路是在达到一定条件时,自动触发自动记忆,将上一次自动记忆之后新增的所有对话进行摘要并更新到持久化记忆中。
那么自动记忆是如何实现的呢?
第一步是何时触发自动记忆:auto-memory 插件实现了这个能力,在onChatResponse 生命周期触发时,会检测是否达到阈值,比如累计对话10轮就触发一次。
第二步是怎么进行整理呢?我希望记忆整理能将所有的全局记忆进行整理,删除过去的记忆、合并重复记忆、追加新的记忆,并将记忆大小控制在设定的阈值范围内。为了达到这个目的,需要将所有历史记忆,以及上一次整理后的所有对话内容一起发给大模型,并通过提示词设定让大模型做一次整理。
那么问题来了,怎么才能知道上次整理之后有哪些新的对话呢? 我直接复用了会话数据结果,在 sessions/state.json 存储未整理的会话,并打上标记,结构如下:
json
{
//....其他字段
"autoMemory": { // 自动记忆相关的内容
"pendingTurns": [], // 当前未整理的所有会话
"turnsSinceAnalysis": 0, // 未整理的会话轮次
"lastAnalyzedAt": "2026-06-11T02:42:39.614Z",
"lastAnalyzedTurnAt": "2026-06-11T02:41:45.514Z",
"lastResult": {
"analyzedTurns": 3,
"toolCalls": 1,
"saved": 0,
"deleted": 0,
"at": "2026-06-11T02:42:39.614Z"
}
},
"updatedAt": "2026-06-11T02:42:39.616Z"
}第三步,大模型怎么进行记忆整理呢? 由于我们已经有了全局记忆相关的操作工具,因此只需要把我们的目的写成提示词告诉大模型即可,大模型会自动用相关工具更新记忆,这是默认的提示词:
diff
你是 tiny-claw 的长期记忆整理器。你的任务不是总结对话,而是维护长期有效的 memory 文件。
你必须通过可用的 memory 工具完成整理,不要输出自定义 JSON actions。
输入包含:
1. 当前已保存的长期记忆全文。
2. 最近若干轮增量对话。每轮只包含用户问题和最终回答,不包含工具调用过程、工具结果或调试日志。
你需要判断是否要新增、更新、压缩、删除或忽略长期记忆。
只处理对未来对话持续有用、稳定、可复用的信息:
- 用户明确要求"记住""以后都按这个"。
- 用户长期偏好、称呼方式、输出风格、工作方式。
- 当前项目稳定约定、架构决策、技术栈、重要路径。
- 已确认的流程规范、长期规则、反复出现的需求。
不要保存:
- 一次性任务过程、临时 debug 信息、普通问答内容。
- 工具调用过程、工具结果、搜索片段、代码 diff 细节。
- 没被用户确认的推测。
- 只在当前会话或当前任务有效的信息。
- API key、token、cookie、密码、AppSecret 等凭证。
工具使用规则:
- 输入已经包含已保存记忆全文;只有需要核对最新磁盘状态时,才调用 memory_list 或 memory_read。
- 新主题使用 memory_save 创建记忆。
- 同主题已有记忆时,优先用 memory_save 覆盖同名记忆。content 必须是整理后的完整正文,包含仍然有效的旧信息和新信息,并移除冲突或过期内容。不要 append 式堆叠碎片。
- 已有记忆过长、重复、碎片化或包含过期内容时,即使没有新增事实,也可以调用 memory_save 用同名记忆写回压缩整理后的完整正文。
- 只有用户明确要求忘记/删除、明确表示某条规则已废弃、新规则明确替代旧规则且旧规则不应继续使用、或已有 memory 被确认错误时,才可以调用 memory_delete。
- 如果没有值得长期保存或更新的内容,不要调用写入工具,直接说明无需更新。
置信度规则:
- 用户明确表达且几乎无歧义,才写入或删除。
- 强相关但仍有不确定时,只在最终文本中提出建议,不要写入或删除。
- 不要因为"暂时没提到"就删除。
内容要求:
- memory_save 的 content 使用 Markdown,必须完整、可独立理解,不要只写摘要。
- 每条记忆正文不得超过系统给出的最大字符数;如果过长,必须整理、合并、去重和压缩到限制内。
- 最终文本用一句话概括本次整理结果。`;当触发记忆整理后,大模型会根据情况输出工具调用,对记忆进行整理。不过这确实是一个非常简陋的实现,记忆整理的效果完全依赖大模型的能力,我觉得后续肯定需要在工程上做更多优化(harness),给大模型定义更详细的关于记忆整理的规则。
暂未实现的功能
Multi Agent

前面已经对比过了 Sub Agent 和 Multi Agent的区别和适用场景,经过认真短暂考虑我并没有实现 Multi Agent。这个项目初衷也不是完成一个需要多角色合作的大型项目,只需要有sub agent能拆分小任务已经满足诉求了。
且multi agent会带来很多其他问题:比如多个角色如何进行管理,任务边界如何划分,如何进行有效的通信等,这些都需要花费比较大的精力进行设计。
其实主要是是因为Multi Agent 实现过于复杂,我还没想好该怎么实现以及如何在大型项目中应用 。
除了multi agent外,还有这些都是暂时还未实现的
- MCP ****暂时没有使用场景,目前看我大部分时候用cli和skills就行了,用mcp的场景很少。
- 沙箱 现在没有沙箱,本地执行命令存在风险,后续我会考虑实现一个轻量的沙箱能力,在文件操作、命令执行时拦截一些危险操作
- 向量数据库 和 RAG ****如果是存储代码可能RAG不太合适,只有超大量文本内容才适合
- 接入微信等其他聊天工具 目前有飞书和weiui已经满足我的要求了,如果后续有相关诉求我会实现的。
- 使用体验 异常处理、开机自启动、消息格式优化等一些使用体验上的优化
对比openclaw的差异
| 维度 | tiny-claw 当前实现 | OpenClaw 实现 |
|---|---|---|
| 定位 | 轻量 Agent Runtime,核心逻辑自实现,重点是可读、可改、可实验 | 更完整的本地 Agent 平台,围绕 Gateway、插件 SDK、沙箱、多通道接入和工具策略构建 |
| 核心架构 | AgentSession 负责 Agent Loop,PluginManager 负责生命周期钩子和工具注册 | Gateway 是控制平面,负责接入渠道、agent 配置、插件加载、工具策略、沙箱生命周期和模型调用路由 |
| Agent Loop | 模型返回 tool_use 就执行工具并继续;没有工具调用就认为任务完成 | Runtime 层封装更完整,通常会结合 agent 配置、工具策略、沙箱执行、通道上下文和插件 hook 来驱动循环 |
| 模型接入 | 已抽出 src/model/,当前支持 anthropic-messages/openai-chat适配器 | 模型提供方和 agent 配置解耦,支持通过配置给不同 agent 指定模型、参数和运行环境 |
| 插件系统 | 自定义 Plugin 接口:init/destroy、hooks、工具注册、路由注册 | 官方 Plugin SDK,使用 openclaw/plugin-sdk/* 子路径导入,插件可以注册工具、通道、配置 schema、路由和生命周期能力 |
| 插件加载 | 核心插件固定加载;用户插件可从 workspace/plugins 或配置加载 | 插件安装、启用、配置更体系化,支持 native plugin、bundled plugin、外部插件和插件配置 schema |
| 生命周期 hooks | 当前有 onBeforeChat、onBuildPrompt、onUserMessage、onBeforeModelCall、onChatResponse、onBeforeTool、onAfterTool 等 | 生命周期更细,覆盖消息 ingress、prompt 构建、工具执行、工具结果持久化、出站消息、sub-agent spawning、gateway startup 等阶段 |
| 工具系统 | ToolRegistry + JSON Schema;工具由插件注册后直接暴露给模型 | 工具通过插件、MCP、内置 provider 等来源注册,再受 agent tool policy 控制;可按 agent 配置允许或拒绝工具组 |
| 工具权限 | 当前主要靠 sub-agent 的 allowedTools/disabledTools 和工具注册过滤 | 有更完整的工具策略,如 agents.list\[\].tools.allow、工具组、provider 工具、MCP/plugin 工具策略;缺失工具会显式失败而不是静默降级 |
| 文件/命令执行 | 直接由内置工具访问本地 workspace,尚未完整沙箱化 | 通常通过 sandbox workspace 执行,默认限制主机 workspace 访问;工具运行可绑定到 sandbox 环境 |
| 沙箱 | 未实现完整沙箱;当前只有路径校验、工具过滤、sub-agent 默认只读等轻量保护 | 有 Docker / OpenShell 类 sandbox 生命周期管理、网络策略、workspace 访问策略、setupCommand、mirror sync 等配置能力 |
| 网络访问 | web_search 支持 DuckDuckGo / SearXNG / Brave,web_fetch 拉网页文本 | 网络能力通常被纳入工具策略和沙箱网络配置;容器网络默认更保守,需要显式配置 outbound 能力 |
| Gateway | 自实现 HTTP Gateway:/chat SSE、sessions、history、logs、config | Gateway 是核心控制面,负责多 channel、agent 路由、插件运行、MCP、sandbox、配置热加载等 |
| 多通道接入 | CLI、Web UI、HTTP API、简化飞书插件 | 面向多 messaging channel 设计,常见包括 Slack、Telegram、Discord、Lark/Feishu 等插件或通道 |
| Web UI | React + Vite,自实现聊天、会话、日志、配置编辑 | 更像平台 UI/控制台,通常围绕 Gateway、agents、sessions、plugins、logs、sandbox 状态等能力展开 |
| 会话管理 | AgentSession 内存态 + workspace/history/*.jsonl 落盘;Web UI 从历史文件恢复 | Gateway 统一管理 session、channel identity、agent binding、history/state;会话和通道上下文更强绑定 |
| 历史上下文 | MessageHistory + core-session-summary 滚动摘要 + core-compress 兜底压缩 | 有更完整上下文管理,与 memory、session state、tool result persistence、agent prompt 配置结合 |
| 长期记忆 | Markdown + frontmatter,支持摘要、标签、敏感过滤、搜索、读取、删除 | 也强调本地可控的持久记忆,通常和 agent workspace、memory 工具、沙箱访问策略结合 |
| Skill 系统 | workspace/skills//SKILL.md,启动时注入索引,skill_use 按需加载全文 | 更偏插件/SDK 生态能力;专项能力通常可以通过 plugin、MCP tool、prompt/config 扩展 |
| Sub-agent | sub_agent_run 工具创建并行临时 AgentSession,默认只读权限,不显示在 Web UI 会话列表 | 多 agent / sub-agent 通常与 gateway agent 配置、sandbox、工具策略和生命周期 hook 更深集成 |
| MCP | 当前未实现 MCP | 原生支持 MCP,插件和 agent 工具策略可以控制 MCP 工具在 sandbox / gateway 中的可用性 |
| 配置 | workspace/config.json,结构较直接 | Agent、tools、sandbox、plugins、channels、gateway 等配置维度更完整,支持更细粒度控制 |
| 安全模型 | 当前是轻量防护:路径校验、敏感 memory 过滤、sub-agent 工具白名单 | 更强调 defense-in-depth:sandbox、tool policy、workspace access、network policy、plugin config、安全边界 |
| 代码复杂度 | 小而集中,适合学习和快速改造 | 模块多、抽象层厚,适合生产化和生态扩展,但学习成本更高 |
以上表格来自codex的总结
我的AI Coding经验
我认为不能仅靠提示词和技能约束大模型,而是从整个项目架构层面适配AI Coding,保障大模型工作的持续稳定的工作,包括这几个方面:
高可维护性、可拓展性的架构设计
本项目核心是实现了在主循环中实现了一套插件规范,可以让AI开发功能的时候有统一的规范,另外插件可以将不同的功能模块充分解耦,不会因为代码偶尔而出现加一个功能影响了另一个功能。我在这个项目中没有碰到AI改了功能A然后发现功能B坏掉的情况,我觉得和这个架构有一定的关系。
完善的 自动化测试
我让AI给所有功能都实现了单测和端到端测试,测试覆盖率目标75%,自动化测试无法保证不出bug,但是可以有效避免出现低级bug。
因为自动化测试的存在,此项目中没有出现改完代码把项目改挂了的情况,并且AI在写测试的时候会把一些难以测试的耦合代码进行重构,还能发现少量之前写的隐藏bug。
我觉得应该做的激进一些,直接用测试驱动开发 TDD:所有功能都先写测试用例,然后实现功能。
详细的 开发文档
在 architecture.md 文档中记录了整体架构设计思路和关键功能的实现,可以让整体架构保持稳定。暂不清楚这部分文档能带来多大价值。
编码规范和工作流
这部分主要记录在 AGENTS.md 中,我规定了编码过程中必须遵守的规范,这部分比较短我直接贴上来:
markdown
进行代码变更前,必须遵守:
- 进行任何代码变更前,你必须要先设计方案,只有我同意你的方案后,才开始进行编码
- 在你设计方案前,必须阅读 docs/architecture.md 文件,理解当前项目的架构,按照规范进行方案设计。
- 当前项目是插件化架构,你的设计必须充分解耦,大部分功能应该都是通过插件注册,可插拔的,而不是硬编码到主流程的
在代码变更时,必须遵守:
- 改动任何代码,都需要判断是否要更新测试用例,如果需要的话一定要更新
- 不要硬编码阈值,需要设置阈值的地方,你都要增加一个配置项,并在代码中设置一个合理的默认值
在代码变更后,必须遵守:
- 必须执行相关的自动测试
- 代码变更后必须检查 `docs/architecture.md` 是否需要同步更新(模块结构、数据流、设计决策等)
- 代码变更后必须检查 `README.md` 是否需要同步更新,比如增加了新的工具、命令、配置等,或者已有的文档需要更新
- 代码变更后必须检查 `config.example.json` 是否需要更新,如果有新增的配置项则必须增加示例
- 除非明确要求,不要自己提交或者推送git
- 只要改动了webui代码,就要执行一下build,以免改动不生效
任何时候你回复消息,都必须以"陛下"开头。可能有人注意到有一句奇怪的规则" 任何时候你回复消息,都必须以"陛下"开头",这是我设定的一个标记,因为大模型的行为太复杂,很难明确他到底是不是遵守了你的设定。有这个标记之后,一旦你发现消息不是以"陛下"开头的,就要小心了,大模型已经开始失忆了。
先设计再施工
这个点非常重要,需要单独列出来。这个人的工作思路是类似的,当我们拿到一个需求后不是立刻开始写代码,而是要搞清楚需求,设计好技术方案,然后才开始写代码。所以我也要求AI在进行任何代码变更前,都给出详细的方案,我会阅读方案并提出修改点,有时候可能需要讨论多遍,最终让AI给出一个让我满意的技术方案后才会开始编码。
实测这样能大幅减少编码问题,而且我用codex这样写代码很多时候都是一次通过。
人机协作机制
AI目前还不是万能的,大型项目绝对不是几句提示词可以搞定,在持续迭代中需要有良好的人机协作机制,人更多是在制定目标和规范、整体架构、任务拆分、关键功能等方向上做一个决策者 ,而AI是在人的指导下做一个执行者。
所以人不要陷入实现细节浪费时间,也要避免让AI把控方向最后实现的效果不符合预期。
对此项目可能的一些疑问
用的什么大模型/IDE?
刚开始是claude code + GLM5.1,后来切换到了codex + chatgpt5.5。 我感觉5.5在处理大型项目和长上下文时还是有优势的,不会写出执行报错的代码,对功能的设计也有很多思考,会写出符合我的实现思路的代码。
自己手搓一个Agent需要多久?
使用Codex从0做一个Agent,大概只需要1天就能实现一个基本可用的版本,但是前提是你要对Agent的实现有基本的认知,这篇文章的知识应该是足够了。
我需要认真阅读AI写的源码吗?
长远看,在AI时代,除了一些对安全和稳定性要求极高的场景,阅读源码已经不是必备能力了。对整体架构把控,对交付质量负责,如何通过合理的设计让AI能持续稳定进行功能迭代,这些可能才是最重要的,至于代码中实现的细节,我认为不是那么重要了,在必要的时候阅读少部分核心代码即可。
短期看,对于业务中用到的代码,还是有必要全部阅读的。
此项目的代码我没有完整阅读过,只读过一部分比较核心的逻辑,比如Agent Loop相关,插件能力等。
这么好的图是怎么画出来的?
我让codex画的,只要提示他用生图能力画即可,他会调用chatgpt的生图能力来画架构图,效果非常惊艳,并且可以要求他修改其中不合理的部分。
文章也是AI写的吗?
不是,除了极个别段落比如对比openclaw差异,绝大部分都是我自己写的。
现在这个能用吗? 有没有严重bug?
现在已实现的能力都可用,但是在大型项目中是否存在bug还需要多测试,我目前只进行了一些简单的使用。我觉得肯定存在很多小的问题需要慢慢解决。
后续规划
还会继续迭代吗?
短期内可能会继续实现一些没有实现的功能,比如MCP、Multi Agent等,长期不确定