上文提到,大语言模型(LLM)在生成文本方面表现出色。但它们并非为对结构化领域(例如产品、患者、财务账户、法律政策)进行可靠的推理而设计的。
如果你的AI应用需要 准确 的查询,而不仅仅是 看起来合理 ,那么你需要的不仅仅是一个模型,而是一个能让 AI"停止猜测"的语义层。
本项目通过一个电商导购案例,演示如何构建以本体为核心的语义层,实现用户意图识别增强和基于知识图谱的可信数据查询。
流失的业务知识
在传统BI数据架构中,业务知识往往在数据流转过程中不断丢失,让我们看一下图。
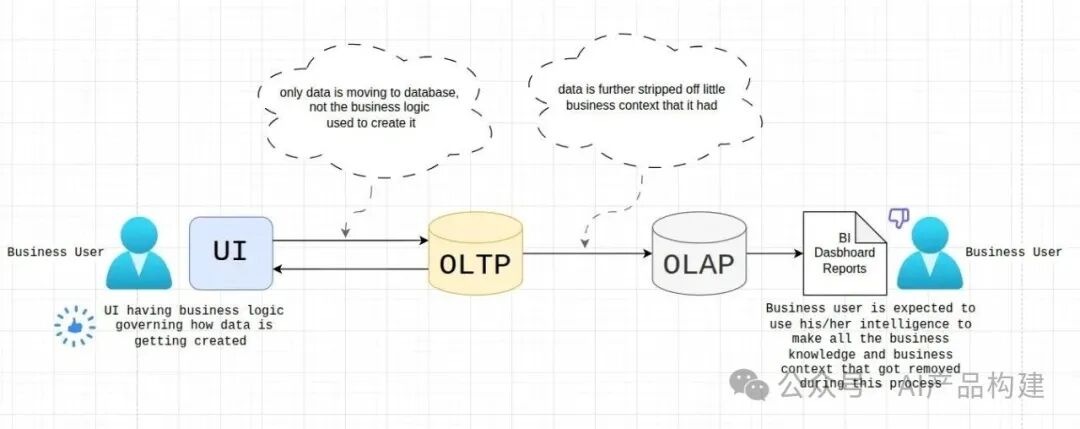
UI 层: 会话层,业务规则和用户上下文则散落在界面代码中,无法被下游复用;
OLTP 层: 事实数据层,只记录"发生了什么",不记录"为什么这样"(领域知识);
OLAP 层: 数据聚合层,聚合进一步剥离业务语义,只剩指标和维度;
BI/仪表盘层: 报表展示层,信息滞后,依赖数据分析师解释和处理语义摩擦。
最终结果是: 数据越往下游走,业务含义越稀薄,最后靠人的经验来"猜"数据背后的业务意图。
为什么仅靠 Agent 和 RAG 还不够
AI时代,引入 智能体(Agent) 后,系统可以主动调用工具、查询对话历史、组装上下文,把用户的自然语言问题转化为可执行流程。
但大模型(LLM)有幻觉,如果你让一个未经训练的大模型帮你找一件价格低于800元、尺码为M、两天内送达的防水夹克,它会给出一个听起来正确,但对你的用户完全没有帮助的回复。它甚至可能凭空想象出一个产品名称和价格,并且信心满满。
没有训练过的大模型无法理解"防水"作为产品属性和作为营销词汇的真正含义。
它无法核查库存。它也无法确保"两天送达"是实际的物流限制,而非猜测。
经过训练的模型可以更好的理解特定场景的知识,但它不是完美的解决方案,训练结果不稳定,LLM在长上下文情况下仍然会发生中间迷失和注意力稀释。
后来有了RAG。知识以向量形式存储,并为LLM提供上下文检索。
RAG 的工作原理通常是这样的:检索相关的信息(文字或图片)的上下文,将其传递给模型,让模型基于向量知识库生成响应。
听起来不错。但它不能做到以下几点:
▸ 它不强制执行基于本体的语义------该模型仍然按照自身的规则解释检索到的事实。
▸ 并不能验证检索到的片段在结构上是否彼此一致。
▸ 它并不能阻止模型将不相关的图节点混合到一个听起来合理但实际上无效的答案中。
▸ 并不能保证价格范围或产品型号供应等限制条件会得到遵守。
▸ 即使检索到的事实不完整,该模型仍然能够给出可靠的答案。
RAG增强了检索,但它并不提供正式的领域理解。向量检索不是精确匹配,大模型仍然在进行猜测,只是有了更好的数据来进行猜测。
知道发生了什么,还知道它是如何发生的
对于追求准确性胜过噪音信息的场景,我们需要通过本体进行强制语义匹配。
为此,我们需要构建一个以本体为核心的语义层------它把业务规则和领域知识建模为本体,让 Agent 在查询知识图谱之前先把用户意图翻译成确定性的结构,最终通过语义增强的检索得到更可信、更可解释的结果。
当用户说"安踏黑色透气运动鞋 300元以下 42码 2天内发货"时,它表达的是六个独立的结构化条件------品牌筛选、颜色筛选、特性筛选、价格筛选、尺码筛选和物流筛选------而不是一串需要 LLM 自行理解的模糊关键词。
同样,当用户说"适合跑步的鞋"时,语义层可以把"跑步"这个业务场景映射为透气、轻便、缓震三个具体特性要求,再交给知识图谱精确检索,最终让 LLM 基于已验证的商品事实组织回答。
技术上,你不需要彻底重构原有的架构,可以通过"边车"架构添加语义层。
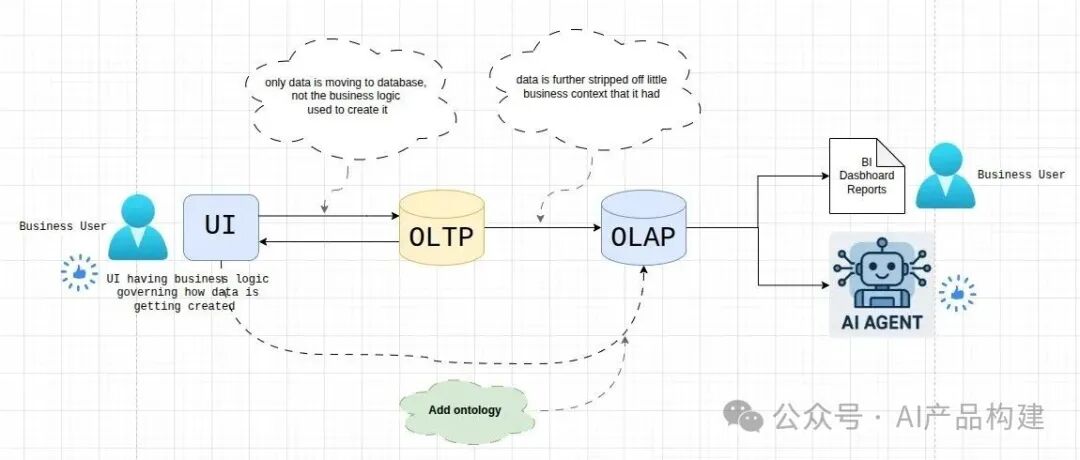
简明语义工程架构
我们面对的挑战是:
❝用户用自然语言提出业务问题("适合跑步的鞋"、"耐磨包裹性好的篮球鞋"),但传统检索系统只能匹配字面关键词,无法理解这些词背后的业务含义。❞
这和传统 BI 的问题本质相同:业务语义被困在文档/人脑中,没有沉淀到数据层。
| 原架构层 | 本项目对应层 | 改进点 |
|---|---|---|
| UI 层(用户会话/业务规则) | 语义层 / 本体层 | 采用正则解析用户查询,把"跑步→透气/轻便/缓震"等业务规则从 UI/人脑中抽离,编码为可复用、可解释的本体模型,为Agent提供用户意图识别和查询上下文 |
| OLTP 层(事实数据) | neo4j知识图谱 | 采用Neo4j作为知识图谱存储,实现精确的结构化检索。Neo4j以实体-关系方式存储带业务语义的产品事实,保留"什么产品有什么特性、什么尺码、什么价格"等业务结构。 |
| BI(报表展示) | Agent编排层+LLM | 采用LangGraph作为Agent框架,基于精确的上下文查询知识图谱,减少语义摩擦; |
转变在于:
❝让系统(Agent)真正理解业务知识❞
1. 语义层/本体层:理解上下文
本体=业务词典 + 翻译规则
作用:理解查询上下文,也就是理解"用户说的词是什么意思"。
❝本体就像餐厅的"菜单翻译器"。客人说"来杯提神的",它知道提神 = 咖啡;客人说"来份辣的",它知道辣 = 川菜。没有它,Agent可能不知道运动鞋还分篮球鞋、跑步鞋。❞

本体不是 Schema。Schema 告诉你存在哪些字段,而本体告诉你事物 意味着 什么。
在本项目中,本体定义了:
▸ 概念和类型 ------ Product、Brand、Color、Feature、Size、Category、ShippingOption
▸ 类型化关系 ------ HAS_FEATURE、IN_CATEGORY、HAS_COLOR、AVAILABLE_IN_SIZE、HAS_SHIPPING
▸ 有效属性约束 ------ 透气、缓震、防滑、轻便、耐磨、包裹性 是运动鞋领域的有效特征;
▸ 语义消歧规则 ------
▸ "300元以下"映射为价格约束
▸ "42码"映射为尺码变体筛选
▸ "2天内发货"映射为物流约束
▸ "跑步"、"打篮球"、"通勤"、"户外"等业务场景映射为具体特性组合,实现从自然语言到结构化查询的翻译
本体是意义模型。它并不存储事实,而是定义存在哪些事物,它们之间哪些关系是合法的,以及哪些规则支配着有效的组合。你可以把它想象成整个系统在处理任何数据之前都要执行的规则手册。
没有本体,你只有数据;有了本体,你才有意义。
2. 知识图谱层:真理之源
知识图谱=事实仓库 + 验证器
作用:存储真实数据,并验证语义层生成的条件是否能查询到结果。
❝知识图谱就像仓库管理员。本体模型把用户需求翻译成"取货单",仓库管理员按单找货。有货就拿出来,没货就告诉系统"找不到"。它保证推荐的东西真实存在。❞
本体赋予意义,知识图谱赋予真理。

知识图谱具有溯源信息,并且是实时更新的。它知道哪些产品存在、哪些产品有库存、它们的价格以及它们实际具备的功能------不是模型根据之前处理过的类似文本推测它们可能具备的功能。
知识图谱用 Cypher 语言做精确过滤:
▸ 品牌对不对?
▸ 颜色有没有?
▸ 特性是否全部满足?
▸ 价格、尺码、库存是否 OK?
关键特点:
▸ 只返回事实:每个结果都是数据库里真实存在的
▸ 可解释:能清楚看到为什么推荐/不推荐
▸ 不会幻觉:不会像 LLM 那样编造不存在的商品
Neo4j 在本项目中作为知识图谱层,承担着"事实仓库"和"验证器"的双重角色。它不仅仅是一个存储产品数据的数据库,而是以图的形式保存了产品、品牌、颜色、特性、尺码、发货选项等实体之间的语义关系。
当语义层把用户自然语言翻译成结构化查询条件后,Neo4j 通过 Cypher 查询精确匹配真实存在的产品节点,只返回满足所有约束的事实数据。
这种基于图结构的存储方式让系统能够清楚地回答"为什么推荐这款鞋"------因为它确实具备用户要求的品牌、颜色、特性、尺码和价格,并且当前有库存。相比让 LLM 直接从文本中推断答案,Neo4j 保证了推荐结果的可验证性和可解释性,从根本上避免了模型幻觉。
3. 语义编排层:桥梁
语义编排层= 流水线调度员
作用:把整个过程拆成若干步骤,按顺序执行,并记录每步结果。
❝语义编排层就像餐厅后厨的"传菜员"。客人点单后,它依次把单子传给:翻译员(本体模型)→ 质检员(校验)→ 仓库(Neo4j)→ 厨师(LLM)。每步完成后把结果传给下一步,保证流程不乱。❞

语义编排层位于用户意图和大语言模型(LLM)之间,确保每一步都符合领域规范。
这时,像 LangGraph(或任何类似的 Agent 框架)这样的工具就派上了用场,你也可以自定义。具体使用哪个工具并不重要,重要的是架构角色。
编排层的作用是充当用户自然语言与本体/知识图谱结构化世界之间的调度员和翻译器。具体包括:
1解析意图:将用户自然语言映射到本体定义的概念(品牌、颜色、特性、价格等)
2校验意图:根据领域规则检查概念组合是否合法,剔除不合理的要求
3检索事实:把结构化条件交给 Neo4j,只返回真实存在的商品数据
4组装上下文:把检索到的事实和解析出的意图整理成 Grounded Prompt
5调用 LLM 生成:让 LLM 基于已验证的事实生成自然语言回复,而不是自由发挥
电商案例V1.0
功能设计
1基于本体(硬编码)的语义识别 :通过 Python 字典和正则匹配实现了轻量化的硬编码本体语义解析。能够识别预定义概念和业务场景映射,包括从用户查询中提取品牌、颜色、特性、尺码、价格等结构化查询信息,将"跑步""打篮球"等业务场景自动映射为具体产品特性
2基于知识图谱的增强检索:支持基于知识图谱精确查询事实数据,包括对用户输入进行格式校验,避免 LLM 幻觉。
硬编码本体
| 概念 | 类型 | 允许值 |
|---|---|---|
| brand | attribute | 安踏、李宁、361 |
| color | attribute | 黑色、白色、红色、蓝色、灰色、绿色 |
| feature | attribute | 透气、缓震、防滑、轻便、耐磨、包裹性 |
| size | variant | 36、37、38、39、40、41、42、43、44、45 |
| category | category | sneakers、运动鞋 |
| price | constraint | 任意数字 |
| shipping | constraint | 任意数字 |
场景映射
| 场景词 | 自动映射特性 |
|---|---|
| 跑步、跑、马拉松、慢跑 | 透气、轻便、缓震 |
| 篮球、打球、实战 | 包裹性、缓震、耐磨、防滑 |
| 通勤、日常、上班、走路 | 透气、轻便 |
| 户外、训练、健身、爬山 | 耐磨、防滑、包裹性 |
| 夏天、夏季、热天 | 透气、轻便 |
架构设计
本系统采用四层协作架构,由编排层统一调度语义层、数据层和 LLM 生成层,实现从用户自然语言到可信自然语言回复的完整流程。
用户层:用户以自然语言输入业务查询。
编排层: LangGraph 实现流水线,负责业务调度和状态传递。编排层通过语义层进行语义解析(结构化),并执行 Cypher 查询,最后将返回的事实结果组装成 Grounded Prompt,交给 LLM 生成回复。
语义层:语义层进行意图解析,将自然语言转化为品牌、颜色、特性、尺码、价格等结构化数据,包括执行"跑步→透气/轻便/缓震"等业务场景映射。
数据层:Neo4j 实现结构化的事实数据存储(知识图谱),用于大模型查询;
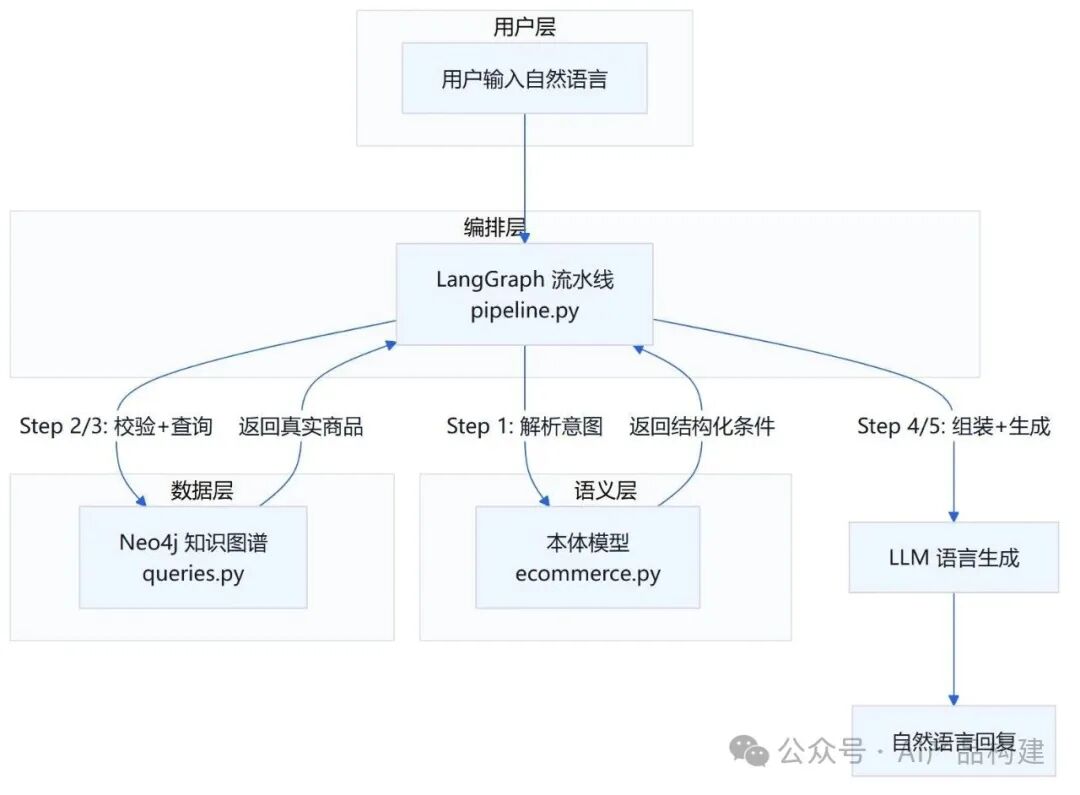
流程设计

1用户查询:用户以自然语言输入需求,例如"适合跑步的鞋"或"安踏黑色透气运动鞋 300元以下 42码"。
2语义解析: 语义层通过正则匹配从查询中提取品牌、颜色、特性、尺码、价格等关键词,并映射到本体预定义的概念上;若开启语义层,还会将"跑步""打篮球"等业务场景映射为具体特性组合。
3语义校验: 根据领域规则校验解析出的意图是否合理,剔除无效或冲突的属性组合,并生成警告信息。
4事实数据查询:将结构化查询条件交给 Neo4j 知识图谱,通过固定 Cypher 模板精确查询事实数据。
5提示词组装:把语义层解析结果和知识图谱返回的验证过的事实整理成 Grounded Prompt,明确限制 LLM 只能基于给定事实作答。
6LLM 基于事实生成回复:调用大语言模型基于 Grounded Prompt 生成自然语言回答,优先推荐最佳匹配并说明理由。
UI设计
采用streamlit搭建了一个简化的Agent用户界面:
1支持模型选择;
2支持开启和关闭语义层;
3支持常用输入快捷键;
4支持流水线跟踪。
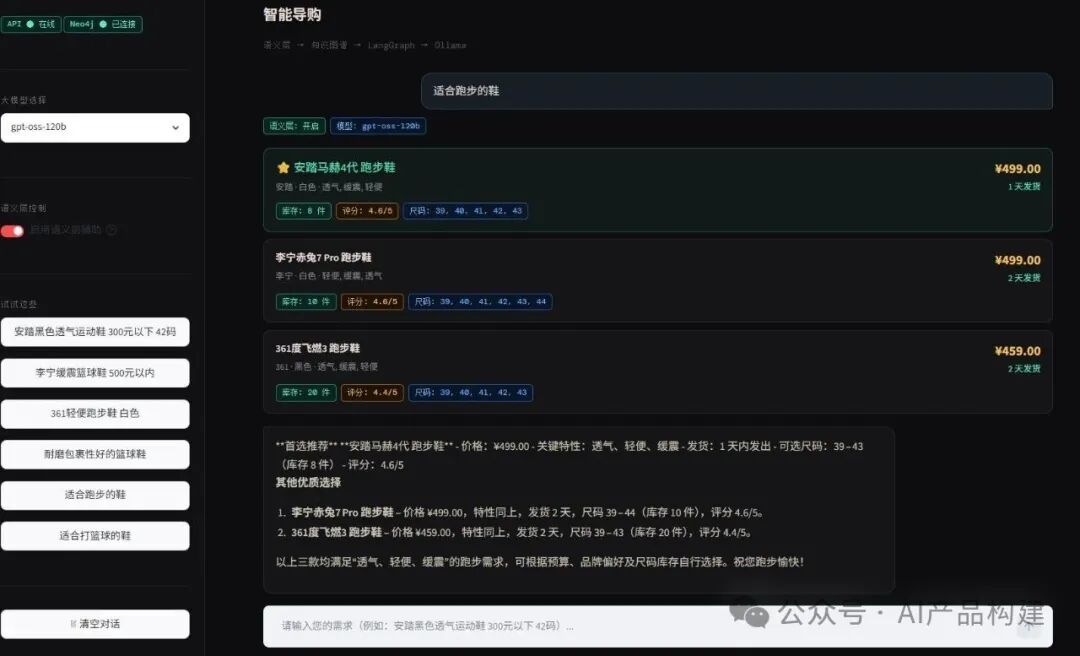
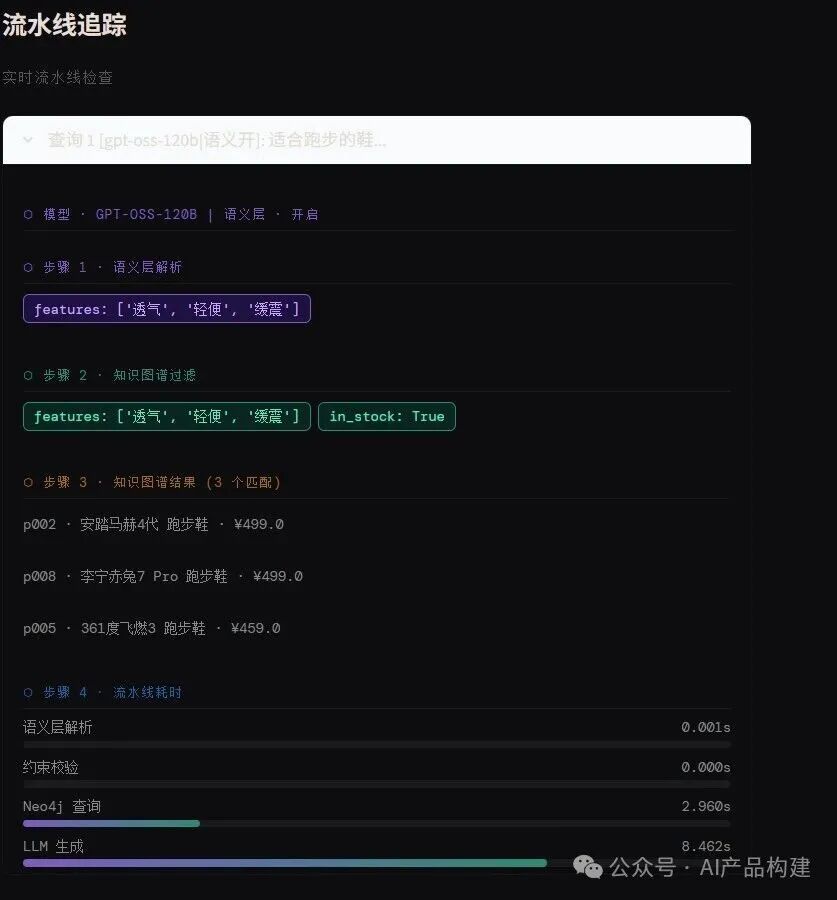
实测结果
使用了10组测试用例,对语义层进行开启和关闭对比测试。
| 查询 | 语义层开启 | 语义层关闭 | 差异原因分析 | |
|---|---|---|---|---|
| 1 | 安踏黑色透气运动鞋 300元以下 42码 | 0 条 | 0 条 | 无差异(字面特征已明确) |
| 2 | 李宁缓震篮球鞋 500元以内 | 1 条 (p008) | 1 条 (p008) | 无差异(字面特征已明确) |
| 3 | 361轻便跑步鞋 白色 | 0 条 | 0 条 | 无差异(字面特征已明确) |
| 4 | 耐磨包裹性好的篮球鞋 | 3 条 | 3 条 | 无差异(字面特征已明确) |
| 5 | 安踏柏油路霸2 绿色 39码 | 1 条 (p007) | 1 条 (p007) | 无差异(精确匹配) |
| 6 | 适合跑步的鞋 | 3 条 跑步鞋 | 5 条 含篮球鞋 | 显著差异 |
| 7 | 适合打篮球的鞋 | 1 条 (p009) | 5 条 全部返回 | 显著差异 |
| 8 | 日常通勤穿的鞋 | 4 条 轻便透气鞋 | 5 条 含篮球鞋 | 显著差异 |
| 9 | 户外训练的鞋 | 2 条 (p009, p006) | 5 条 全部返回 | 显著差异 |
| 10 | 夏天穿的透气鞋 | 4 条 | 4 条 | 无差异(字面已含"透气") |
关键结论
语义层对用户意图识别准确性有显著提升:
▸ 查询 6/7/8/9 在关闭语义层时,系统无法理解"跑步/打篮球/通勤/户外"这些场景词的含义,只能返回所有库存商品。
▸ 开启语义层后,系统自动映射到对应的特性组合,精准过滤无关商品。
核心改进点:
1理解隐含意图:用户说"跑步",系统知道要透气/轻便/缓震
2过滤无关商品:不会把篮球鞋推荐给跑步用户
3基于真实数据:所有推荐都经过 Neo4j 验证,不编造
4流程可追踪:每步结果都能看到,出了问题好排查
为什么这种架构能提升准确性?
当用户输入 "查找安踏品牌、黑色、透气、300元以下、42码、2天内发货的运动鞋。
本体层能理解:
▸ 安踏 → 品牌属性
▸ 黑色 → 产品颜色属性
▸ 透气 → 产品特性
▸ 42码 → 尺码变体筛选器
▸ 300元以下 → 价格约束
▸ 2天内发货 → 发货时间限制
▸跑步 / 打篮球 / 通勤 / 户外 → 场景语义映射到具体特性组合
当用户说"适合跑步的鞋"时,本体层还会扩展为:
▸ features CONTAINS ALL "透气", "轻便", "缓震"
知识图谱层提供经过验证的事实,用于匹配产品------实际品牌、颜色、特性、价格、库存水平和发货时间。
编排层基于用户结构化的查询信息构建精确的查询结果:
▸ brand = "安踏"
▸ color = "黑色"
▸ features CONTAINS "透气"
▸ price < 300
▸ size "42" in stock
▸ shipping_days <= 2
▸ stock > 0
如果没有本体层,编排层会把"运动鞋"当作关键词去图谱里模糊匹配。大模型或许能返回正确的结果,也或许不能,没有任何保证。
更麻烦的是,如果用户说"适合慢跑的鞋",没有语义层,Agent可能根本不知道"跑步"和"慢跑"有什么区别,只能返回所有跑步鞋,包括越野跑。
在本体层,我们可以通过子类、等价类、互斥类的构建,让Agent知道跑鞋分为慢跑/日常训练鞋 、中长跑/竞速鞋 和越野跑鞋几类,它们适合不同的路面,从专业的角度,它们是截然不同的。
V1.0适合的业务场景/领域
V1.0 最适合结构化商品检索型电商导购,可应用于客服机器人、站内搜索、智能推荐筛选等场景。
| 特征 | 说明 |
|---|---|
| 商品属性明确 | 有品牌、颜色、尺码、价格、特性等固定维度 |
| 用户查询口语化 | "适合跑步的鞋"、"夏天穿的透气鞋" |
| 需要场景理解 | 用户不直接说特性,但场景词隐含特性需求 |
| 数据量可控 | 几十到几千个 SKU,规则匹配足够覆盖 |
| 准确性要求高 | 不能乱推荐,必须基于真实库存数据 |
不适合的场景
▸ 开放式闲聊:"运动鞋历史是怎样的?" → 没有对应商品属性
▸ 强个性化推荐:"给我推荐一双潮鞋" → 系统不懂"潮"是什么
▸ 跨领域通用问答:需要大量外部知识,V1.0 没有RAG和搜索功能
V1.0 的局限
没有完美的架构。
V1.0仅仅是个开始,它还有很多局限性。
| 局限 | 说明 |
|---|---|
| 规则硬编码 | 场景映射写死在代码里,新增场景要改代码 |
| 无上下文推理 | 不知道"篮球鞋"是"运动鞋"的一种 |
| 无同义词扩展 | "跑鞋"和"跑步鞋"要分别写规则 |
| 特征匹配太严格 | 要求所有特性同时满足,容易空结果 |
| 无多跳关系 | 不能推荐"买了这双的人还买了..." |
这些正是我们后续版本要逐步解决的问题:
▸ 基于OWL/TTL的本体模型,本体模型导入
▸ 本体和事实数据映射
▸ 多跳查询
▸ 推理查询
▸ 意图识别
▸ POLE+O语义层框架
▸ RAG
▸ 向量数据库
未完待续...