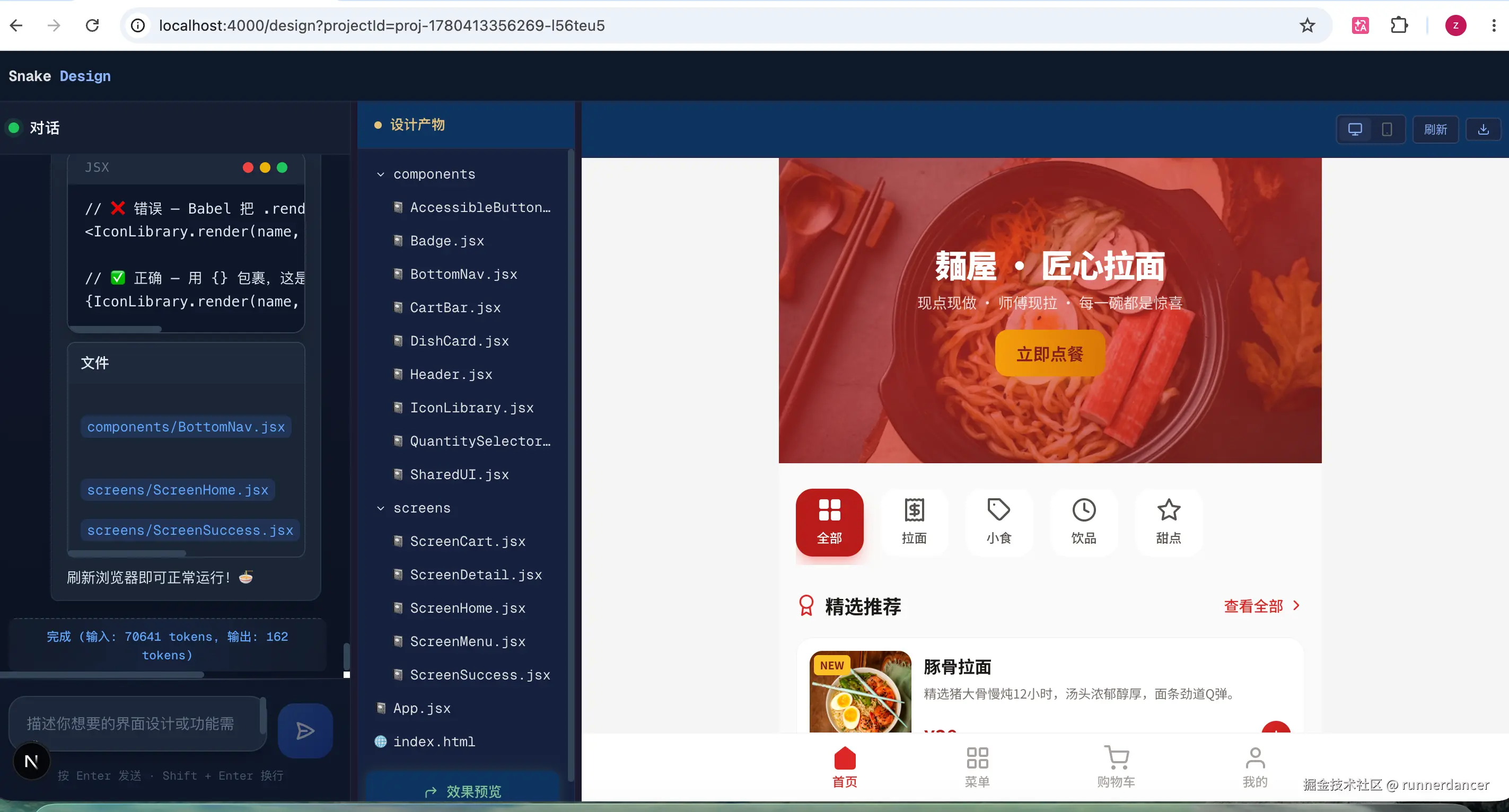
最近在手搓纯web版Agent,从Agent Loop开始,到渐进式加载skill,再到执行skill的脚本。调用llm接口等全部流程,包括视觉稿在线预览,都在前端完成,不经过后端。在浏览器实现虚拟的文件系统
仓库地址:Snake Design。在线体验地址:snake-design.vercel.app/。这个项目主要是复刻claude design,可以一句话生成UI设计稿,带交互原型。下面是用GLM-4.6V-Flash生成的效果
背景
大模型只会做文字接龙,给它一段文字,然后根据概率预测下一个字。确切地说,模型只认识token,给他一段token,它预测下一个token。那我们调用LLM接口时,传给LLM的messages是怎么转换成token id的,这中间涉及哪些过程。搞懂了这个过程,也就能理解什么是提示词缓存,以及提示词缓存解决了什么问题。
什么是上下文
大模型本身是没有记忆的,每次请求都是独立的。这意味着,每次对话都必须带上完整的上下文,模型才能给出准确的回答。我们在调用大模型接口时传的 messages 参数,就是完整的上下文。我们所说的上下文管理,也是对messages进行管理。
注意,这里的messages和我们在聊天框看到的历史消息记录是两套东西。messsages是最终投喂给模型的输入,这是给模型看的,而历史消息记录是给人看的。上下文管理本质上就是对messages做增,删,改,确保不超过模型的context上限。
messages 里通常包含三部分内容:
- system:系统人设
- 每一轮的用户提问
- 模型上一轮的回答
模型就是看着"用户问了什么 + 它自己刚才答了什么"来继续对话的。
如果不带历史回复会怎样?
举个例子:
第一轮
- 你:帮我写一个 Python 排序代码
- 模型:给了你一段完整代码
第二轮(只发新问题,不带模型刚才的代码)
- 你:帮我把这段代码改成降序
在这个场景,我们的messages数组没有带上模型刚才的回答,即那段代码,那它只收到了两个问题:
-
- 帮我写 Python 排序代码
-
- 帮我把这段代码改成降序
模型看不到它刚才给我们的那段代码,也不知道"这段代码"指的是哪段,只能瞎猜或重写。
因此,如果不带历史回复,或者历史对话信息,会导致:
- 上下文断联:记不住刚才聊的内容
- 重复回答:反复重新开局,不接话
- 逻辑混乱:接不上上一轮的结论
- 改写、续写、迭代需求直接废掉
所以,和大模型对话时必须携带完整的上下文。
大模型接口收到 messages 后做了什么
LLM 接口收到 messages 后,大致会经历这几个步骤:拿到 messages → 按固定格式拼接成一整段长文本 → 切分成 Token → 进 Prefill 算 KV。
第一步:理解核心前提
大模型根本不认识 JSON 数组 ,它只会读一串连续的token。
我们传给大模型的可能是这样的 JSON:
json
[
{ "role": "system", "content": "你是专业程序员" },
{ "role": "user", "content": "解释一下KV缓存" },
{ "role": "assistant", "content": "KV缓存就是..." }
]但对模型来说,这就是一堆"角色+内容"。接口后台的第一件事,就是把数组压扁,拼成一段符合模型规则的连续文本。
第二步:如何拼接成文本?
每个大模型都有固定的角色分隔模板,这不是随便拼的。
通用的拼接逻辑是:给每个 role 加上专属的标记头和尾,把对话串起来:
- 先写标记:系统角色开始 + 系统内容
- 再写标记:用户开始 + 用户提问
- 再写标记:助手开始 + 助手回答
- 最后停在:助手开始,等着模型往下生成
举个例子,原始 messages:
- system:你是专业程序员
- user:解释一下KV缓存
- assistant:KV缓存就是存注意力中间数据
后台自动拼成的完整长文本大概是这样(模拟格式):
sql
<|system|>
你是专业程序员
<|user|>
解释一下KV缓存
<|assistant|>最后停在 <|assistant|> 后面,意思是:该模型接着往下说话了。
那些 <|system|> <|user|> <|assistant|> 都是特殊占位符 Token,不是普通文字,模型专门用来区分谁在说话。
第三步:如何计算 Token?
分词(Tokenize)
把拼好的整段长字符串,按模型自带的词表字典切碎:
- 常见整词:
缓存→ 1个 Token - 生僻长词、英文、字母:拆成好几个 Token
- 角色标记
<|system|>→ 单独 1 个特殊 Token
最终结果
一整段对话 + 角色标记,全部被切成一长串数字 ID 列表。文字 → 切碎成 Token → 每个 Token 对应一个数字 ID。大模型不认识文字,只认识这串数字 ID。
我们看到的"消耗多少输入 token"、"上下文窗口 4k/8k",算的就是这一整段拼完、切完的总 Token 数。
第四步:Token 如何进入模型计算?
- 把这串 Token 数字送入模型的 Prefill 预填充阶段
- 一次性并行计算所有 Token 的注意力,生成全套 KV 缓存
- 有了 KV 状态,就开始逐字 Decode,一个一个往外吐回答
完整流程串联
- 我们在前端构造
messages对话数组 - 接口后台按角色模板把数组拼接成带特殊标记的长文本
- 对长文本做 Token 分词,转成数字 ID 序列
- 统计 Token 数量(计费、判超长)
- 送入模型 Prefill,计算生成 KV 缓存
- 模型基于完整上下文,逐字生成回复
大模型如何生成文本
前面提过,LLM 的核心就是根据当前输入生成下一个字或词。那为什么 LLM 接口可以按照 JSON 格式返回给我们,包括回复、工具调用等指令?
实际上,模型在生成、续写、多轮对话的全过程中,自始至终都严格按一套固定规则拼接文本,和 messages 数组转文本是同一套规则。
不管是我们发的 messages,还是模型自己正在一个字一个字生成回复,底层都遵循同一套角色模板拼接规则 :<|系统|>、<|用户|>、<|助手|> 这种特殊标记 + 内容拼接。
模型不是随便凑文字,是按固定格式拼成一整条结构化长文本,再预测下一个字。这些特殊标记和结构化文本是经过训练的
模型如何回复
我们传的 messages 会被拼成:
sql
<|system|>
你是智能助手
<|user|>
世界最高峰是
<|assistant|>模型停在 <|assistant|> 后面,准备从这里开始续写。
模型开始逐字生成时,每吐出一个字,自动拼到整个结构化文本末尾:
第一步生成「珠」→ 全局文本变成:
sql
<|system|>
你是智能助手
<|user|>
世界最高峰是
<|assistant|>
珠第二步再生成「穆」→ 自动继续往后拼:
sql
<|system|>
你是智能助手
<|user|>
世界最高峰是
<|assistant|>
珠穆每生成一个 token,都原样套这套格式,追加到整段结构化文本最后。
模型如何生成调用工具的指令
普通对话用<|system|> <|user|> <|assistant|>等特殊标记拼接
工具调用多两个角色标签:
<|function_call|>:助手要调用工具<|function_result|>:工具返回结果给模型
工具调用完整拼接过程
-
System 固定:需要告诉模型可以调用的工具、参数格式、技能列表、入参规则等。
-
用户提问 :
<|user|> 今天北京天气怎么样? -
模型判断要调工具 :模型不会直接回答,而是在
<|assistant|]后面,按格式生成工具调用结构:
json
<|assistant|>
<|function_call|>
{"name":"查天气","parameters":{"城市":"北京"}}底层就是普通文本续写,只是续写的是 JSON 格式的工具调用内容。
-
后端拦截这个 function_call :接口后端识别到模型输出了工具调用,不再继续生成回答,而是去执行函数,拿到结果:
北京:晴,25℃ -
把工具结果按规则拼回去:后端构造一条工具结果消息,塞进 messages,按模板拼接:
<|function_result|>
北京:晴,25℃ -
模型再接着续写正常回答 :模型看到
<|function_result|>结果后,继续在后面生成自然语言:<|assistant|>
北京今天天气晴朗,气温25度,适合出门。
整体拼接后的完整长文本
sql
<|system|>
你有查天气、计算器等工具,严格按JSON格式调用
<|user|>
今天北京天气怎么样?
<|assistant|>
<|function_call|>
{"name":"查天气","parameters":{"城市":"北京"}}
<|function_result|>
北京:晴,25℃
<|assistant|>
北京今天天气晴朗,气温25度,适合出门。全程就是一套拼接逻辑,只是多加了两个标签。
和普通对话的区别
- 普通对话:只循环 user ↔ assistant
- 工具调用:多了一轮闭环
user → assistant(发工具调用) → function_result → assistant(给答案)
所有工具调用、Skill 调用、插件调用,底层没有特殊魔法,依然是模板拼接 + Token 预测 + KV 缓存。模型只是"按格式续写一段工具调用文本",后端识别后执行,再把结果拼回上下文。
为什么必须按规则拼接?
-
模型会被训练成用格式标记区分谁说话:
<|user|>后面是用户说的,<|assistant|]后面是模型要说的。 -
模型续写时只在
<|assistant|]标签后面往下接字,不会跑到用户位置、系统位置去生成。 -
如果整套格式乱了,模型就会乱插话、逻辑跑偏、答非所问。
什么是提示词缓存
Prompt Caching(提示词缓存/前缀缓存) 是大模型推理的核心优化技术:把请求里重复的前缀(静态内容)缓存下来,下次请求前缀完全一样时,直接复用,不用再算一遍,从而降延迟、省成本、减算力。
核心原理
大模型推理分两阶段:
- Prefill(预填充):把提示词转成 Token、算注意力 KV 状态,计算最重、最费钱。
- Decode(解码):在已有上下文上逐字生成,成本低。
Prompt Caching 的做法是:把 Prefill 算出的 KV Cache 跨请求暂存;新请求若前缀完全一致(Token 级精确匹配),直接复用缓存,跳过 Prefill,只算新增部分。
能带来什么好处
- 延迟大减:长提示词场景,响应可从秒级降到百毫秒级。
- 成本大降:缓存命中的输入 Token 计费通常是原价的 1/10~1/4(如 OpenAI/Anthropic 新模型)。
- 算力节省:避免重复的 Transformer 注意力计算,GPU 占用大幅降低。
生效规则
- 前缀必须精确匹配:任何 Token 差异(空格、标点、大小写)都会失效。
- 长度门槛:如 OpenAI 要求前缀 ≥ 1024 Token,按 128 Token 增量对齐。
- 缓存时效:通常 5~10 分钟无访问自动过期,低峰最长约 1 小时。
- 最佳写法:静态内容(系统指令、角色、示例)放前面,动态内容(用户输入、变量)放后面。
典型适用场景
- 多轮对话(上下文复用)
- 固定系统指令 + 动态用户问题
- 反复处理同一份长文档/知识库
- 高频模板化查询(客服、FAQ、RAG)
一句话总结:Prompt Caching 就是"同样的前缀只算一次",让长提示词请求又快又便宜。
Prompt Caching 的缓存前缀是什么
Prompt Caching 的缓存前缀,就是把我们传入的整个 messages 数组,按模型固定模板拼接、转成 Token 后的那整串 Token 序列。
缓存的 key 是什么?
缓存的key可以简单理解成,是将messages数组转换后生成的完整 Token 序列:
- 按模型模板拼接 messages → 变成一整段带
<|system|>``<|user|>``<|assistant|>的长文本 - 对这段文本做 Tokenize → 得到一长串数字 Token ID
- 这串从头开始的前缀 Token,就是 Prompt Caching 用来匹配缓存的唯一标准
多轮对话如何命中缓存?
Prompt Cache 不是必须整个前缀完全一模一样,而是前面一截开头完全一样就行,越长的前缀,越长能复用。
让我们用符号来表示:S=system,U1=用户1,A1=助手1,U2=用户2,A2=助手2,U3=用户3
第一轮
- 请求:
S+U1 - 跑完 Prefill,缓存:Token 序列
[S, U1]
第二轮
- 请求:
S+U1+A1+U2 - 它的完整 Token 前缀是:
S+U1+A1+U2
模型拿这个前缀从头去匹配缓存:
- 开头先比对:
S+U1→ 和第一轮缓存完全一模一样 - 命中最长公共前缀:
S+U1 - 直接复用这一段的 KV,不用重新算 S+U1
- 只需要后面新增的
A1+U2做 Prefill 补算 - 然后把整条更长的
S+U1+A1+U2重新存入缓存覆盖旧的
第三轮
- 请求:
S+U1+A1+U2+A2+U3 - 拿它从头去和第二轮缓存做前缀匹配
- 第二轮缓存是:
S+U1+A1+U2 - 第三轮开头正好就是:
S+U1+A1+U2,Token 完全对齐 - 直接完整命中第二段全部缓存,不用重算前面一大截,只补算后面
A2+U3
只要新请求的开头,和缓存里的开头,有一长截完全一样的 Token 前缀,就能命中这一截,不用重算。
缓存是前缀可复用,不是整段等长才能复用。比如缓存存了:1234,新请求前缀是:1234567
虽然长度不一样,但开头 1234 完全一样,直接复用 1234,只算后面 567。
这就是多轮对话能每轮都复用前一轮缓存的根本原因。
总结
了解这些,可以更好帮助我们理解提示词缓存的原理,在实际agent应用中可以更好的组织我们的提示词