模型本身只知道训练时见过的知识。
如果你问它最近发生的事情,或者企业内部文档里的内容,它通常并不知道。更麻烦的是,它有时不会直接说"不知道",而是编一个看起来很像真的答案。
这就是常说的幻觉。
RAG 要解决的核心问题就是:回答前先检索资料,再让模型基于资料生成答案。
RAG 全称是 Retrieval-Augmented Generation,中文通常叫"检索增强生成"。
可以拆成三步理解:
txt
Retrieval:先从外部知识库检索相关资料
Augmented:把资料和用户问题一起放进 prompt
Generation:模型基于资料生成回答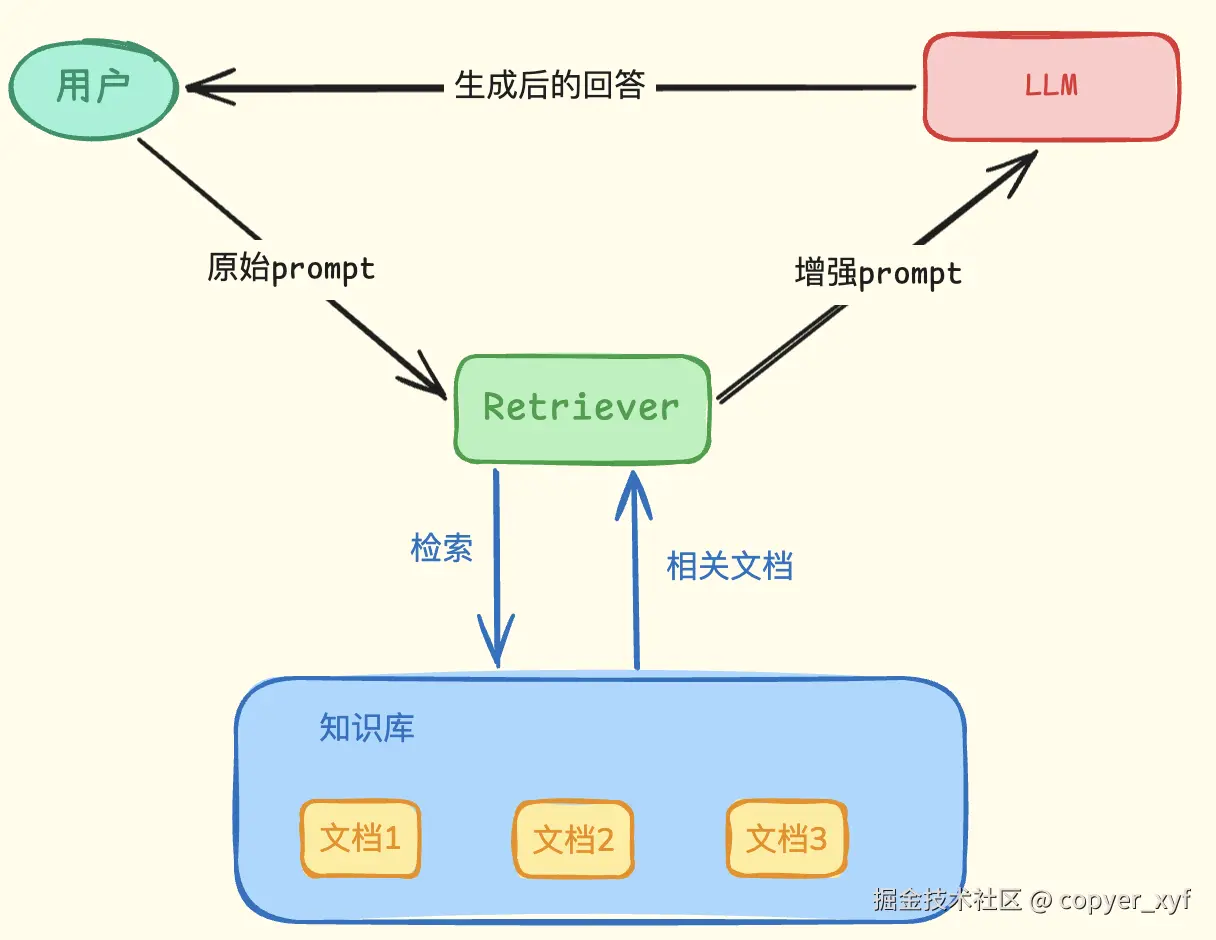
先记住一句话:RAG 不是让模型记住所有资料,而是在模型回答前,把相关资料找出来塞给它。
RAG 解决什么问题
普通模型调用大概是这样:
txt
用户问题 -> 模型 -> 答案RAG 调用会多一个检索环节:
txt
用户问题 -> 检索知识库 -> 拼接上下文 -> 模型 -> 答案所以 RAG 适合这些场景:
- 企业内部制度问答。
- 产品手册问答。
- 客服知识库。
- 文档、论文、电子书问答。
- 历史聊天记录检索。
它不适合解决所有问题。
如果问题本身不依赖外部资料,直接调用模型就够了。如果资料质量很差,RAG 也只会把差资料更快地送给模型。
向量和相似度
RAG 最难的地方不是"把资料塞进 prompt",而是"怎么找到相关资料"。
关键词搜索只看字面匹配:
txt
问题:员工吃饭报销超过 200 怎么办?
文档:餐饮类报销单次金额超过 200 元需要直属主管审批。这两个句子字面不完全一样,但语义是相关的。
所以 RAG 通常使用语义搜索。语义搜索的底层依赖向量。
向量可以理解成一组数字:
txt
"餐饮报销" -> [0.12, -0.38, 0.76, ...]
"吃饭费用" -> [0.11, -0.35, 0.72, ...]如果两个文本意思接近,它们的向量方向通常也会接近。
余弦相似度就是用向量夹角判断相似程度:
txt
夹角越小:越相似
夹角越大:越不相似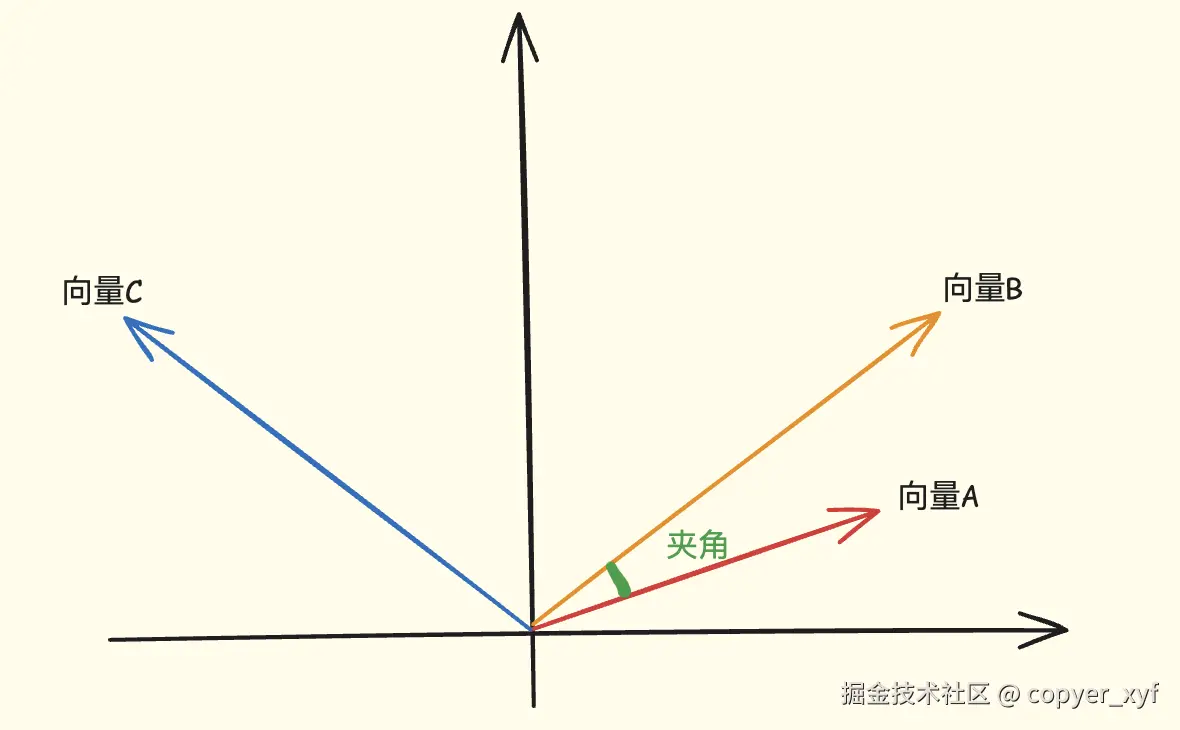
二维图只是为了方便理解。真实 embedding 通常是几百维、上千维,无法画出来,但数学上仍然可以计算相似度。
Embedding 模型
Embedding 模型负责把文本转成向量。
txt
文本 -> Embedding Model -> 向量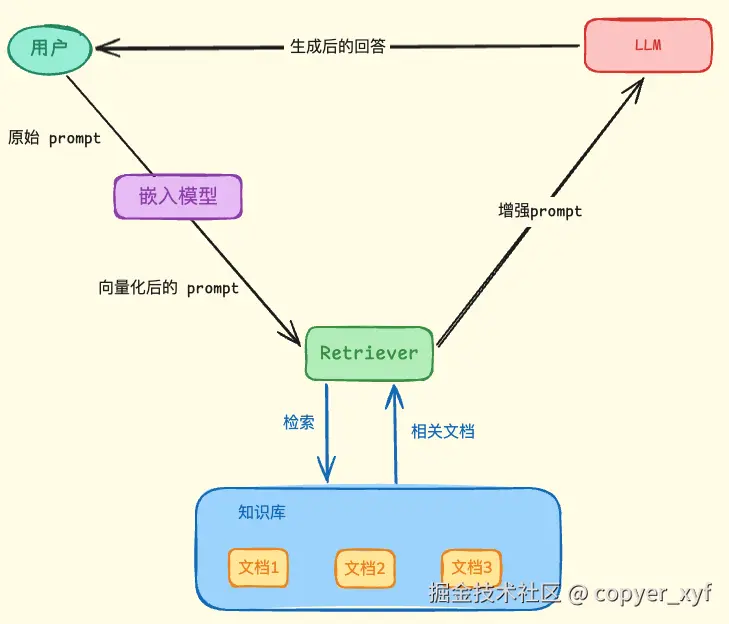
RAG 里有两个地方会用到 embedding:
txt
1. 建库时:把文档切块,并转成向量存起来
2. 提问时:把用户问题转成向量,去向量库里找相似文档注意一个关键点:文档向量和问题向量要使用同一个 embedding 模型。
如果建库时用 A 模型,查询时用 B 模型,向量空间可能不一致,相似度就没有意义。
内存向量库 InMemoryVectorStore
先用内存向量库看完整流程。
InMemoryVectorStore 适合学习和本地 demo。它把向量放在内存里,进程结束数据就没了。
txt
优点:不用启动数据库,代码简单
缺点:不能持久化,不适合生产先来安装依赖:
bash
uv add langchain-core langchain-openai先准备模型、embedding 和几份文档:
python
import os
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
model = ChatOpenAI(
# RAG 场景通常希望答案稳定、少发挥;创造性需求再调高 temperature。
temperature=0,
model=os.environ["AI_MODEL"],
api_key=os.environ["AI_KEY"],
base_url=os.environ["AI_BASE_URL"],
)
embeddings = OpenAIEmbeddings(
# 建库和查询必须使用同一个 embedding 模型,否则向量空间不一致。
model=os.environ["AI_EMBEDDING_MODEL"],
api_key=os.environ["AI_KEY"],
base_url=os.environ["AI_BASE_URL"],
)
# 定义一些文档,模拟知识库
documents = [
Document(
page_content="""
星河制造的日常费用报销分为办公采购、差旅费用和招待费用三类。
员工提交报销申请时,必须填写费用类型、用途、发生日期和金额。
餐饮类报销单次金额超过 200 元需要直属主管审批;超过 1000 元需要部门负责人审批。
所有报销必须在消费发生后的 30 天内提交,超期申请默认退回。
电子发票和纸质发票都可以使用,但票据信息必须完整可核验。
""".strip(),
metadata={
# metadata 不参与语义生成,但会在检索后帮助展示来源、做过滤和排查召回问题。
"id": "doc-expense-policy",
"title": "报销制度",
"topic": "expense",
},
),
Document(
page_content="""
星河制造当前主推两款工业传感器。
HX-100 面向中小型工厂,特点是部署成本低、功耗低、维护简单,适合基础温湿度监控。
HX-300 面向高要求产线,支持更高频率的数据采样,并带有异常波动预警能力。
两款产品都支持通过标准 API 接入企业内部系统,但 HX-300 在并发数据上传能力上更强。
""".strip(),
metadata={
"id": "doc-product-intro",
"title": "产品资料",
"topic": "product",
},
),
Document(
page_content="""
星河制造为所有正式销售的硬件产品提供 1 年标准保修服务。
HX-300 的企业版客户在签署增值服务协议后,可以获得 2 年延长保修和 7x12 小时技术支持。
若设备因人为损坏、非授权拆机或外部电力事故导致故障,不在免费保修范围内。
客户提交售后工单时,需要提供设备序列号、购买时间和故障现象说明。
""".strip(),
metadata={
"id": "doc-after-sale",
"title": "售后承诺",
"topic": "service",
},
),
]然后创建向量库并检索:
python
from langchain_core.vectorstores import InMemoryVectorStore
# 创建库(传入文档和嵌入模型)
vector_store = InMemoryVectorStore.from_documents(
documents,
embedding=embeddings,
)
question = "餐饮报销超过 200 元需要谁审批?"
# 普通 RAG 只需要文档时,用 similarity_search(question, k=2) 就够了。
# 这里为了教学和调试召回质量,使用 with_score 版本额外拿到相似度分数。
# with_score 会额外返回相似度分数,方便观察检索排序和排查召回质量。
# 真正交给模型的 context 通常不需要包含 score。
results = vector_store.similarity_search_with_score(question, k=2)
# 检索结果不能原样塞给模型,需要先整理成适合 prompt 阅读的上下文文本。
# item 的结构是 (Document, score):Document 给模型用,score 给开发者判断召回质量。
def format_retrieved_document(item, index: int) -> str:
doc, score = item
# score 留给日志和调试;context 只放模型回答需要的来源和正文。
print(f"资料 {index + 1} 相似度:{score:.4f}")
return f"""资料 {index + 1}
标题:{doc.metadata["title"]}
内容:{doc.page_content}"""
context = "\n\n".join(
format_retrieved_document(item, index)
for index, item in enumerate(results)
)
prompt = f"""
你是一个 RAG 学习案例助手。
请严格根据提供的资料回答问题,不要补充资料中没有的信息。
如果资料中找不到答案,请直接回答"根据当前知识库,无法回答这个问题"。
问题:
{question}
资料:
{context}
"""
result = model.invoke(prompt)
print(result.content)这段代码里,Document(...) 只是把原始文本整理成 LangChain 认识的文档对象。真正的正文放在 page_content,而标题、分类、来源这类辅助信息放在 metadata。
InMemoryVectorStore.from_documents(documents, embedding=embeddings) 会做两件事:先用 embedding 模型把每个文档转成向量,再把这些向量放进内存向量库。也就是说,这一步同时完成了"向量化"和"建库"。
检索时有两个常用 API。普通 RAG 只需要文档,直接用 similarity_search(question, k=2) 就够了。如果你想观察召回质量,再用 similarity_search_with_score(question, k=2),它会额外返回相似度分数。分数主要给开发者看,不是必须放进 prompt。
最后,model.invoke(prompt) 才是生成阶段:把用户问题和检索到的资料一起交给模型,让模型基于资料回答。
这就是最小 RAG:
txt
文档 -> 向量库
问题 -> 检索相关文档
相关文档 + 问题 -> prompt
prompt -> 模型回答Loader 和 Splitter
刚才的 demo 里,文档是手动写成 Document 的。
真实项目里,资料通常来自网页、PDF、Word、Markdown、数据库、对象存储。它们需要先变成统一的 Document。
txt
原始文件 -> Loader -> Document[]
Document[] -> Splitter -> 小块 Document[]
小块 Document[] -> Embedding -> 向量
向量 -> Vector Store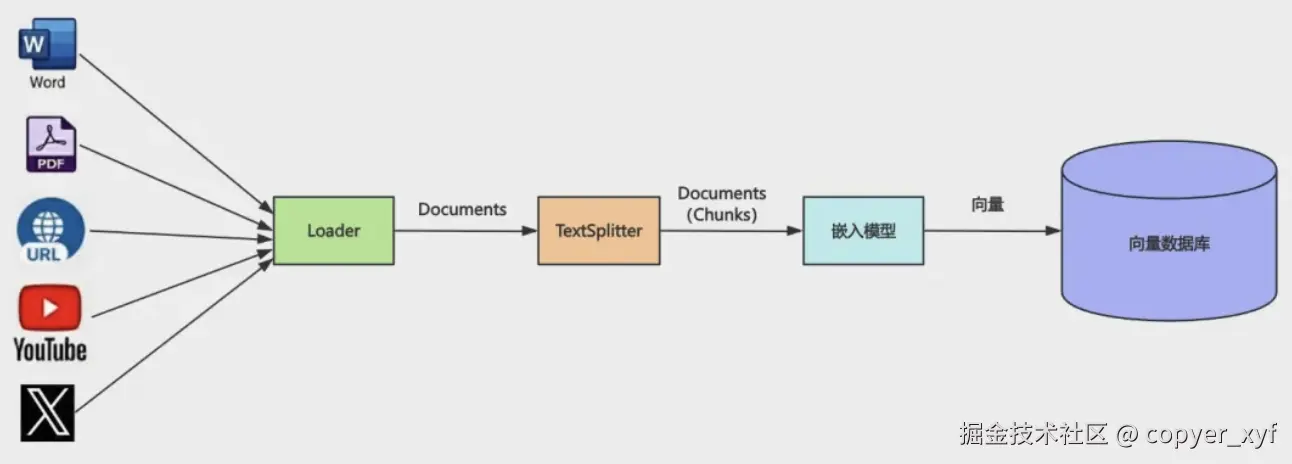
例如用网页 loader 读取页面:
这里会用到网页 loader 和 HTML 解析器:
bash
uv add langchain-community beautifulsoup4
python
from langchain_community.document_loaders import WebBaseLoader
# WebBaseLoader 会拿到网页正文和部分 metadata;真实项目通常还要额外做去噪和正文抽取。
loader = WebBaseLoader("https://example.com/article")
loaded_documents = loader.load()
print(loaded_documents[0].page_content)
print(loaded_documents[0].metadata)这里的 WebBaseLoader 负责读取网页,并把网页内容转换成 LangChain 标准的 Document 列表。
loader.load() 才是真正执行加载的动作。返回结果里的每一项都是一个 Document,正文在 page_content,来源 URL 等信息在 metadata。
真实项目里,网页加载后通常还要做正文抽取和去噪,否则导航栏、评论区、推荐列表可能会进入知识库。
如果文档很长,不能整篇塞进向量库,通常需要切块:
这里会用到文本切分器:
bash
uv add langchain-text-splitters
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
# 这里的单位默认是字符数,不是 token。中文场景要结合模型上下文再调。
chunk_size=400,
# overlap 是用存储成本换语义连续性,适合答案可能跨段落的资料。
chunk_overlap=50,
# 分隔符从强语义边界到弱边界排列,最后的空字符串表示实在不行再硬切。
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""],
)
split_documents = splitter.split_documents(loaded_documents)
print(len(split_documents))RecursiveCharacterTextSplitter 是通用首选的文本切分器。它不会一上来就硬切字符,而是按照 separators 从前到后尝试切分:先按段落,再按换行,再按句号、逗号、空格,最后实在不行才硬切。
chunk_size 是每个 chunk 的目标大小。默认情况下它按字符数计算,不是 token 数。chunk_overlap 是相邻 chunk 之间保留的重复内容,用来减少"答案刚好被切断"的问题。
split_documents(...) 接收一批 Document,返回切好的小 Document 列表。原文的 metadata 会继续跟着每个 chunk,后面做来源追踪时很重要。
chunk_size 控制每块大小。
chunk_overlap 控制相邻块之间重复多少内容。
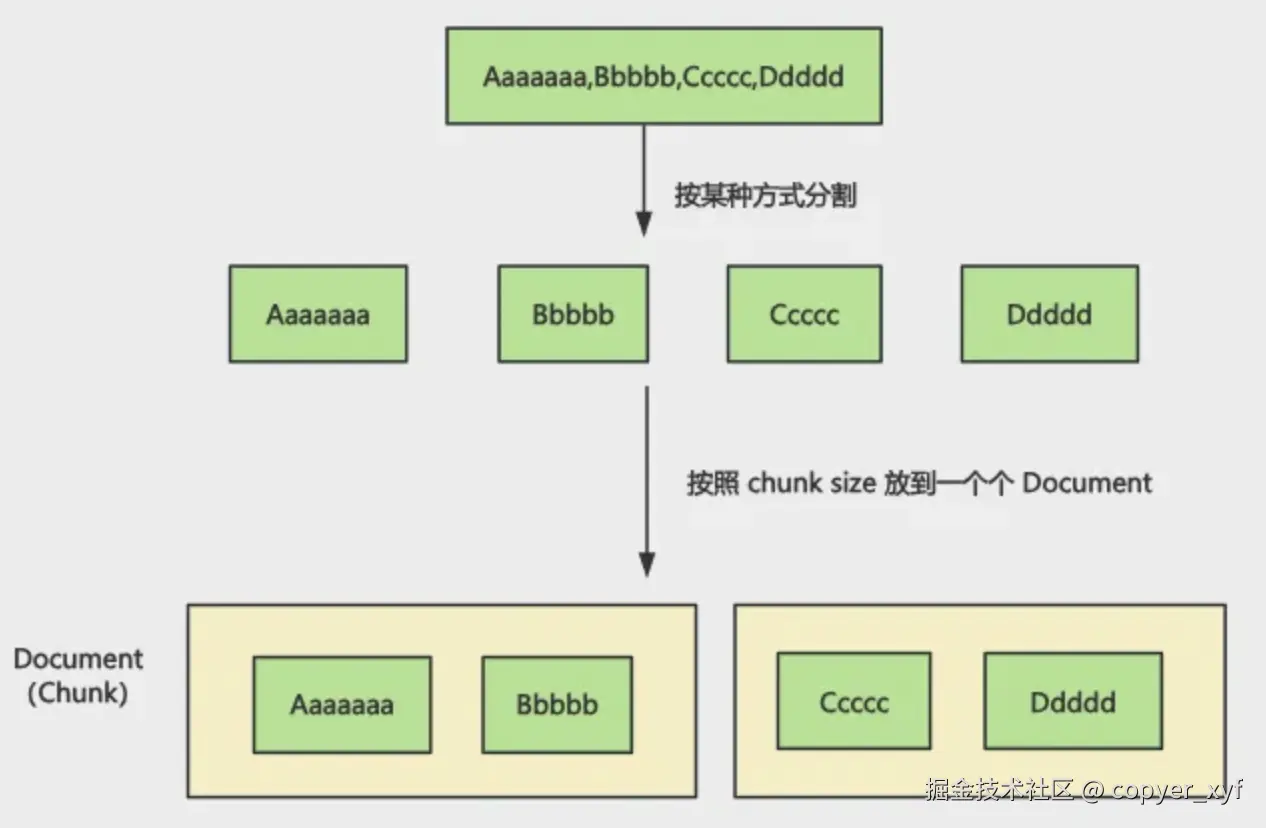
overlap 的作用是保留上下文连续性。

如果完全没有 overlap,某个答案可能刚好被切在两个块中间,检索时只拿到半句话。
但是 overlap 也不是越大越好。它会增加存储量、embedding 成本和检索噪声。
通常可以先从这个范围开始:
txt
chunk_overlap = chunk_size 的 10% 到 30%Splitter 类型
LangChain 里常见的 splitter 有这些:
python
from langchain_text_splitters import (
CharacterTextSplitter,
Language,
MarkdownTextSplitter,
RecursiveCharacterTextSplitter,
TokenTextSplitter,
)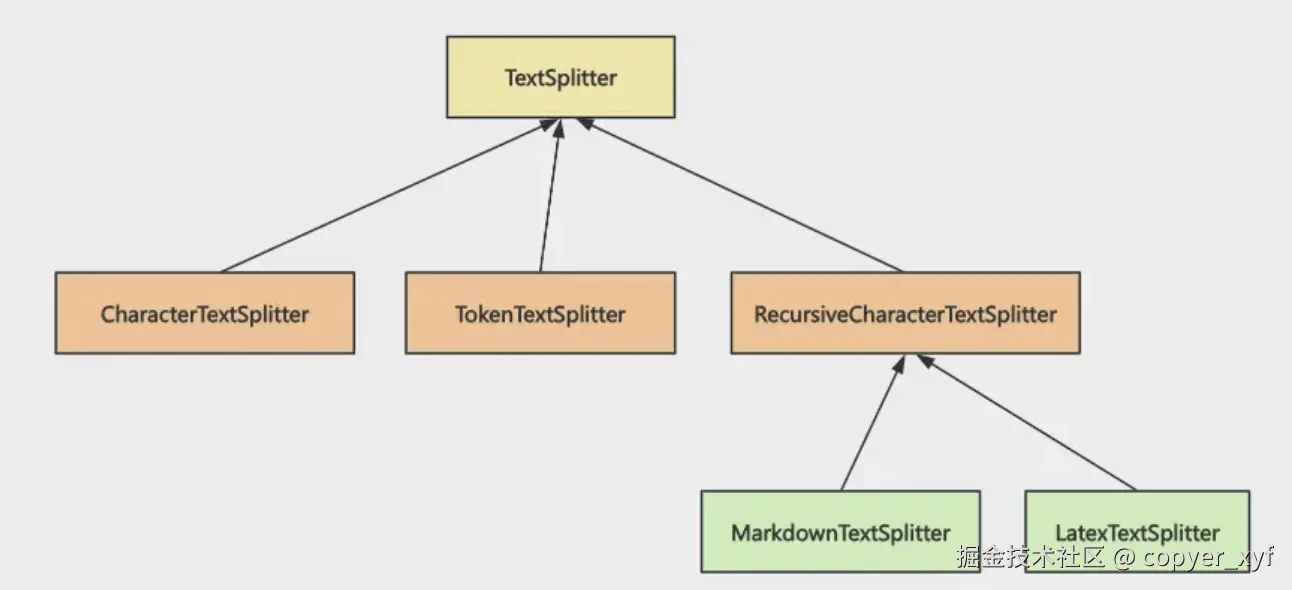
| 分割器 | 核心依据 | 推荐场景 | 特点 |
|---|---|---|---|
RecursiveCharacterTextSplitter |
多种分隔符递归尝试 | 通用文本、网页、PDF | 首选,尽量保留语义 |
CharacterTextSplitter |
单一分隔符 | 格式非常稳定的文本 | 简单,但容易切断语义 |
TokenTextSplitter |
Token 数量 | 严格控制上下文成本 | 精准,但可能切断句子 |
MarkdownTextSplitter |
Markdown 结构 | 技术文档、博客 | 更尊重标题结构 |
多数业务先用 RecursiveCharacterTextSplitter 就够了。
Token 分割
模型按 token 计费,也按 token 限制上下文长度。
在 Python 里,可以用 tiktoken 估算 OpenAI 系列模型的 token 数。
bash
uv add tiktoken
python
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4")
def count_tokens(text: str) -> int:
return len(enc.encode(text))
print(count_tokens("apple"))
print(count_tokens("苹果"))
# 如果模型没有明确对应关系,也可以直接使用 cl100k_base。
cl100k = tiktoken.get_encoding("cl100k_base")
print(len(cl100k.encode("RAG 是检索增强生成")))encoding_for_model("gpt-4") 会根据模型名选择对应的 token 编码器。这样算出来的 token 数更接近实际模型计费和上下文占用。
如果你使用的模型没有明确映射,可以直接用 get_encoding("cl100k_base") 做估算。很多 OpenAI 兼容模型也会用接近的编码方式。
enc.encode(text) 会把文本变成 token id 数组。数组长度就是 token 数,所以常见写法是 len(enc.encode(text))。
也可以直接用 TokenTextSplitter:
python
from langchain_core.documents import Document
from langchain_text_splitters import TokenTextSplitter
document = Document(
page_content="""
FastAPI 是一个用于构建 API 的现代 Python Web 框架。
它基于类型注解,适合构建高性能服务,也常用于 AI 应用后端。
""".strip()
)
splitter = TokenTextSplitter(
# TokenTextSplitter 适合强控成本;缺点是可能把句子从中间切开。
chunk_size=50,
# token overlap 通常比字符 overlap 更接近真实上下文成本。
chunk_overlap=10,
# encoding_name 要和目标模型尽量匹配;不确定时先用 cl100k_base 做估算。
encoding_name="cl100k_base",
)
chunks = splitter.split_documents([document])
for chunk in chunks:
print(chunk.page_content)TokenTextSplitter 是按 token 数切块的 splitter。它适合你必须严格控制上下文成本的场景,比如每个 chunk 最多只能占 500 tokens。
encoding_name 决定 token 怎么计算,应该尽量贴近你实际调用的模型。split_documents(...) 会按这个 token 预算输出多个 Document chunk。注意它更重视 token 数,不一定总能保住完整语义边界。
也可以让 RecursiveCharacterTextSplitter 按 token 计算长度:
python
import tiktoken
from langchain_text_splitters import RecursiveCharacterTextSplitter
enc = tiktoken.get_encoding("cl100k_base")
splitter = RecursiveCharacterTextSplitter(
# 使用 token 作为 length_function 后,chunk_size 就从"字符数"变成"token 数"。
chunk_size=100,
chunk_overlap=20,
separators=["\n\n", "\n", "。", ",", " ", ""],
# 这种写法兼顾语义边界和 token 预算,通常比纯 TokenTextSplitter 更适合中文资料。
length_function=lambda text: len(enc.encode(text)),
)这种方式通常更稳:尽量按语义切,又能控制 token 上限。
切代码
如果资料是代码,可以使用语言感知的 splitter:
python
from langchain_core.documents import Document
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
code = """
class ShoppingCart:
def __init__(self):
self.items = []
def add_item(self, product, quantity=1):
self.items.append({"product": product, "quantity": quantity})
"""
document = Document(
page_content=code,
metadata={"source": "shopping_cart.py"},
)
splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
# 代码切块要优先保护函数、类、作用域边界,避免检索到无法独立理解的半段逻辑。
chunk_size=300,
chunk_overlap=60,
)
chunks = splitter.split_documents([document])
print(chunks)代码 RAG 最怕随便按字符切,因为函数、类、注释可能被切散。
RAG 的关键点
RAG 做得好不好,通常不只取决于模型。
更关键的是这些环节:
txt
资料是否干净
切块是否合理
Embedding 模型是否合适
检索结果是否相关
Prompt 是否要求模型忠于资料常见问题:
| 问题 | 可能原因 |
|---|---|
| 答非所问 | 检索结果不相关 |
| 找不到答案 | chunk 太大、太小,或 embedding 不合适 |
| 回答编造 | prompt 没要求基于资料回答 |
| 成本太高 | chunk 太碎、overlap 太大、topK 太高 |
小结
这一篇要记住几个核心点:
- RAG 是检索增强生成,不是让模型永久记住资料。
- Embedding 模型负责把文本转成向量。
- 向量库负责按语义相似度找资料。
- Loader 把原始资料变成 Document。
- Splitter 把大文档切成适合检索的小块。
InMemoryVectorStore适合学习和本地 demo,生产环境需要换成持久化向量库。- RAG 的质量主要取决于资料、切块、检索和 prompt,而不是只取决于模型。