目录
[核心论文与论文 HTML/PDF 整理](#核心论文与论文 HTML/PDF 整理)
[1. 标准 Transformer、自注意力基础](#1. 标准 Transformer、自注意力基础)
[2. 位置编码与方向性](#2. 位置编码与方向性)
[3. 长序列与稀疏注意力](#3. 长序列与稀疏注意力)
[4. 线性化、低秩近似与高效 Attention](#4. 线性化、低秩近似与高效 Attention)
[5. Cross-Attention、Axial Attention、卷积混合结构](#5. Cross-Attention、Axial Attention、卷积混合结构)
[6. LayerNorm / RMSNorm / 训练稳定性](#6. LayerNorm / RMSNorm / 训练稳定性)
干货分享,感谢您的阅读!
如果只保留一个最重要的理解框架,我建议把几乎所有注意力变体都看成是在同一个统一公式上改三件事:谁能看谁,也就是掩码与稀疏连接图;怎么看位置,也就是绝对位置、相对位置、RoPE、ALiBi 这类位置机制;怎么算得更省,也就是稀疏化、核技巧线性化、低秩近似,或者像 FlashAttention 这种不改数学定义但重排计算与显存访问的工程优化。这个视角与原始 Transformer、相对位置编码工作、T5 的相对偏置、ALiBi,以及高效 Transformer 综述是相吻合的。
标准自注意力的核心价值,是它能用一层全连接式的"内容寻址"来建立任意 token 对任意 token 的依赖;原始 Transformer 还特别强调了它的最大路径长度为常数级,这正是它比 RNN 更擅长建模中长距离依赖的原因之一。可问题也同样直接:标准注意力每层时间复杂度是,显式注意力矩阵本身就要
的空间,这在长上下文下会很快成为瓶颈。
因此,工程上通常不是"哪个变体最先进",而是"我的瓶颈到底是什么"。如果你的上下文长度还在几千到一万多 token 的量级,而且你又希望和标准注意力完全等价,那么第一选择往往不是近似注意力,而是 Dense Attention + 合适的位置编码 + FlashAttention 或 PyTorch/Hugging Face 的高效后端;FlashAttention 论文和官方仓库都明确说明,它保持 exact attention 的语义,同时通过 tiling 降低 HBM 读写与显存占用,在长序列下会带来明显的速度与内存收益。
如果你的任务是长文档编码、问答、摘要,稀疏/局部类方法通常更自然,因为它们直接把"谁应该看到谁"编码成图结构。Longformer 用"局部窗口 + 任务相关全局 token",BigBird 用"窗口 + 随机 + 全局",Reformer 用 LSH 找近邻,Transformer-XL 则走"跨 segment 记忆复用"的路线。它们背后的共同逻辑都是:不要求每个位置都看全部位置,而是只保留足够的信息流通结构。
如果你的瓶颈是超长序列的算力或显存,而且可以接受近似,那么线性化注意力与低秩近似值得考虑。Linear Transformer 把 softmax attention 改写成核特征映射的线性形式;Performer 用 FAVOR+ 给 softmax kernel 提供可证明的高效近似;Linformer 假设注意力矩阵近似低秩,先把 (K,V) 在序列维上投到更低维;Nyströmformer 则用 landmarks 近似完整 softmax 矩阵。它们都在"放弃完整 (n\times n) 矩阵"这一点上收敛,但近似方式、数值稳定性和适合任务并不相同。
最后,很多时候会把注意力当作一个孤立模块来学,这会错过真正的工程重点。交叉注意力解决的是"从别的记忆里读信息",在 encoder-decoder、多模态和检索增强里至关重要;可分离/轴向注意力解决的是"多维数据不能直接全连接 flatten";Conformer、ConvBERT、CoAtNet 这类结构说明,注意力本身很强,但局部归纳偏置、卷积模块和归一化位置往往同样决定训练稳定性与最终效果。
一、从标准自注意力开始
(一)QKV
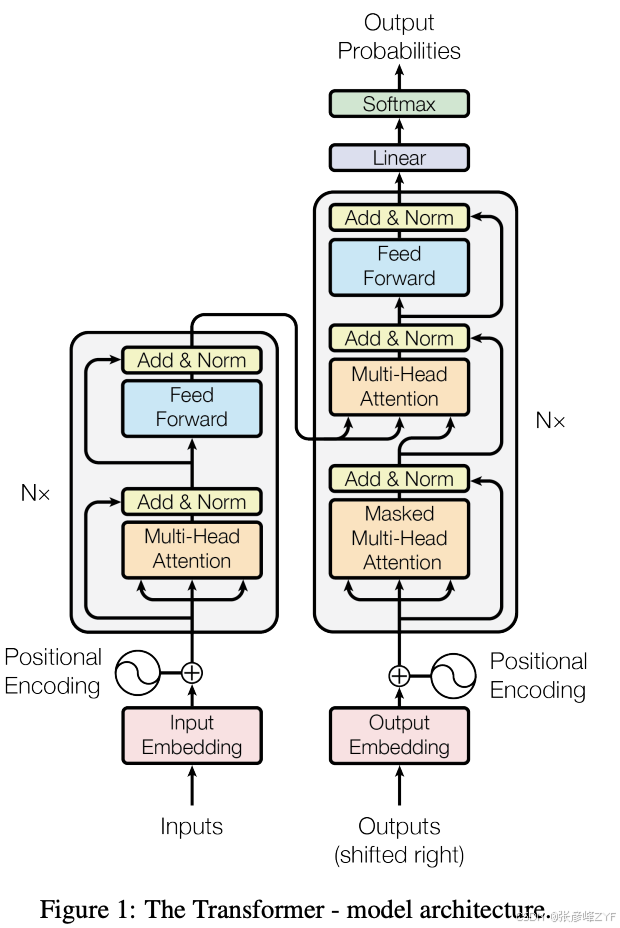
标准自注意力最简洁的写法是:给定输入矩阵,先线性映射得到
、
、
然后计算:
原始论文指出,缩放的原因是当维度变大时,点积的量级会变大、softmax 更容易进入梯度很小的区域。
更直观地说,Query 像"我现在想找什么" ,Key 像"你这里能提供什么线索" ,Value 像"真正要被取走的信息"。于是,每个 token 都会拿自己的 Query 去和所有 Key 计算相似度,再把得到的权重分配给所有 Value,得到一个新的上下文化表示。动手学深度学习中文版对这种"动态权重汇聚"的讲法尤其直观,适合作为入门直觉。
(二)注意力层
原始 Transformer 还给了一个非常重要、经常被忽视的结构性结论:与循环层相比,自注意力一层就能建立任意两个位置之间的依赖,因此最大路径长度是 ;但代价是每层复杂度会随序列长度呈平方增长。这个"路径更短,代价更高"的张力,正是几乎所有后续注意力变体存在的原因。

多头注意力只是把同一个输入投影到多个子空间里分别做注意力,然后把各头结果拼接后再做一次输出投影。它的关键不是"并行"本身,而是让模型在不同表示子空间里学到不同的依赖模式。原论文明确写出,多头注意力可以让模型在不同位置、不同表示子空间上联合关注信息;D2L 中文版也把它解释为"让不同头关注不同范围与不同关系"。
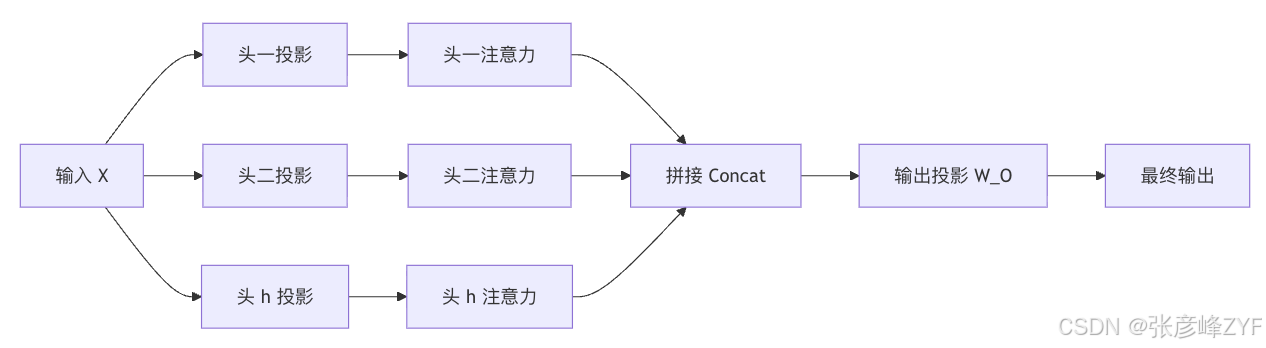
从工程上看,多头并不改变标准注意力的序列长度复杂度量级,仍然需要处理 (n\times n) 的关系图,但它通常比单头更稳也更强,因为单头平均化会抹掉一些结构信息。原始论文还特别指出,在每个头维度缩小的情况下,总计算量与单头全维度注意力是相近的。
(三)直击要点
下面给一个长度为 8、只为教学而造的小例子,把"权重怎么算、输出怎么变"真正算透。为了便于手算,我取,让
,并令 8 个输入向量为:
| 位置 | 向量 |
|---|---|
| 1 | 1, 0 |
| 2 | 0, 1 |
| 3 | 1, 1 |
| 4 | 1, 0 |
| 5 | 0, 2 |
| 6 | 0, 1 |
| 7 | 0, 3 |
| 8 | 1, 2 |
我们只看第 5 个位置,故 。按标准公式,缩放分数是:
对应的双向 attention 权重约为:
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 权重 | 0.009 | 0.035 | 0.035 | 0.009 | 0.144 | 0.035 | 0.591 | 0.144 |
此时输出约是:
如果把它改成因果注意力,位置 5 就不能看 6、7、8,于是权重变成:
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 权重 | 0.037 | 0.152 | 0.152 | 0.037 | 0.623 | 0 | 0 | 0 |
这时输出约是:
这个小例子最直观地说明了两件事。第一,注意力输出不是"找一个最像的 token",而是"对所有可见 token 做一个内容相关的动态加权平均"。第二,因果掩码不是小修小补,而是直接改了关系图:原本第 5 位最想看的是第 7 位,但因果约束把这条边彻底砍掉,于是输出方向都变了。标准公式与因果 mask 的定义来自原始 Transformer;这里的具体数字则是我为了教学而手工构造的。
如果把标准注意力翻成最短伪代码,大概就是这样:
python
# X: [n, d_model]
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
scores = (Q @ K.T) / sqrt(d_k)
scores = scores + position_bias + attention_mask
A = softmax(scores, dim=-1)
Y = A @ V这个版本几乎已经包含了全文的大部分变体:position_bias 可以换成相对位置、RoPE 等;attention_mask 可以换成因果 mask、局部窗口、稀疏图;而 scores 的计算过程则可以被线性化、低秩化或用更高效的 kernel 重写。
二、位置编码与方向性
T5 论文对一个关键事实说得很直接:self-attention 本身是 order-independent 的,本质上更像对集合做运算。这就是为什么 Transformer 必须额外注入位置信息;不然你把序列整体打乱,模型从机制上并不知道哪个 token 在前、哪个在后。
原始 Transformer 用的是绝对位置编码,把位置向量直接加到输入 embedding 上;后来的相对位置家族则转向"把位置信息加到注意力分数里"或者"直接作用在 (Q,K) 的几何关系上"。Shaw 的相对位置表示、T5 的 bucketed relative bias、Transformer-XL 的相对位置方案、RoPE 的旋转编码,以及 ALiBi 的线性距离惩罚,都是这条思路的不同落点。
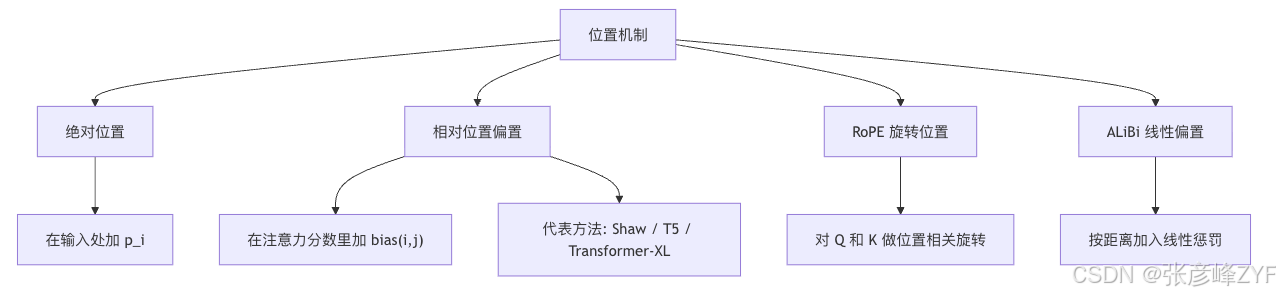
先看 Shaw 相对位置表示。这篇工作最重要的贡献不是"又发明了一种位置编码",而是把位置从"输入属性"改成了"token 两两关系"的属性。论文报告,在 WMT14 英德和英法翻译上,相对位置表示相对绝对位置有提升,而且把绝对和相对位置一起用并没有继续带来收益。
再看 T5 的 relative attention bias。T5 明确写到,它没有为每个精确相对距离都学一个高维向量,而是用了更简单的标量偏置,把它直接加到 attention logits 上;同时,它把相对距离分 bucket,小距离精确,大距离按对数量化,默认用 32 个 bucket,到偏移 128 以后更远的位置会合并到同一 bucket。Hugging Face 的 T5 实现源码也清楚展示了这一点:relative_attention_bias 是一个 Embedding(num_buckets, num_heads),并通过 _relative_position_bucket 把位置差映射成 bucket id。
从直觉上看,T5 的做法非常工程化:它承认"远处的大量不同距离不值得逐个精确区分",于是把建模容量主要留给近距离,把更远的距离压缩成更粗的桶。这也是为什么它在 encoder-decoder 场景下常常很稳定:你能以很低的参数成本获得相对位置信号。
RoPE 则走了另一条非常漂亮的路线。RoFormer 论文写得很明确:它用旋转矩阵编码绝对位置,同时使 self-attention 的点积里隐含显式的相对位置信息;论文和 Hugging Face 文档都强调,RoPE 具备更长序列的灵活性、随相对距离增大而衰减的依赖特性,并能与更高效的线性 self-attention 协同。
RoPE 之所以在大模型时代特别受欢迎,核心不只是"效果好",还在于它不需要显式构造额外的 (n\times n) 位置偏置矩阵。你只需要在每个位置上对 (Q,K) 做一次位置相关旋转,点积时相对位置信息自然出现,这一点和"直接往 scores 里加 bias"的方法相比,常常更省事也更好并入现有 kernel。RoFormer 原始论文和 Hugging Face 文档都把这一点描述得很清楚。
ALiBi 更激进:它干脆不加位置 embedding,而是直接对 query-key 分数施加一个与距离成正比的线性惩罚。OpenReview 与 arXiv 摘要都指出,ALiBi 在长度 1024 上训练的 1.3B 模型可以外推到 2048,达到和在 2048 长度上训练的正弦位置模型相同的 perplexity,同时训练快约 11%、内存少约 11%。
如果把位置方法按"工程默认值"来选,基本建议是:decoder-only 生成模型优先考虑 RoPE 或 ALiBi;encoder-decoder 模型里,T5 风格的 relative bias 依然非常稳;如果你特别强调长文本外推、而且希望实现尽可能简单,ALiBi 是很硬核的选择。这个建议本质上来自这些方法在原论文中各自强调的性质,而不是某个单一 benchmark 的排名。
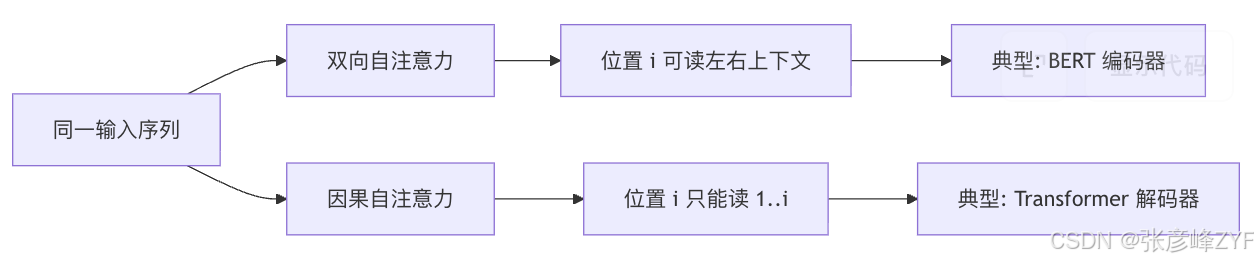
方向性的差异,也就是双向 与因果,同样可以放进统一公式里看:它们主要改的是 mask,而不是改 (Q,K,V) 的定义。原始 Transformer 明确写到,decoder 的 self-attention 要把未来位置 mask 掉,保证位置 (i) 只依赖于不超过 (i) 的已知输出;而 BERT 的核心则是"双向 Transformer",通过 masked language modeling 同时利用左、右上下文。
最后,Transformer-XL 可以看作"相对位置 + 长期记忆复用"的代表。它不是简单换一种位置编码,而是把相邻 segment 的隐藏状态缓存下来,通过 segment-level recurrence 扩展有效上下文;论文摘要写到,它能学习到比 vanilla Transformer 长 450% 的依赖,并在评估时快很多。直觉上,它更像是给 causal 模型装上"可跨段延伸的记忆带",尤其适合自回归语言建模。
三、长序列与稀疏化
长序列注意力最核心的思想,是承认"全连接交互太贵",因此不再让每个位置看全部位置,而是只保留一张足够连通、足够符合任务 inductive bias 的稀疏图。高效 Transformer 综述把这条路线总结得很清楚:很多方法本质上都在改 attention graph,而不是改 Transformer 的整体框架。
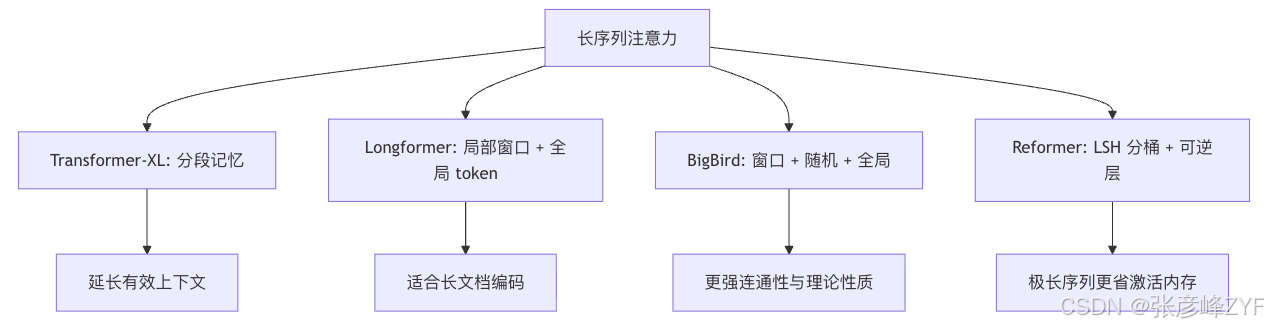
Longformer 是最容易一眼看懂的长序列模型之一。论文明确写到,它把注意力机制做成了"局部 windowed attention + task-motivated global attention "的组合,而且 global attention 是对称的:一个全局 token 会看全序列,全序列也能看它。当窗口宽度固定时,计算复杂度对序列长度是线性的。AllenAI 的 Longformer 论文和 Hugging Face 中文文档都把这一点说得非常清楚。
Longformer 的直观体会是:大多数 token 只需要看邻居来逐层聚合局部上下文,但某些"任务关键位置"必须变成信息枢纽。分类时这个枢纽常常是 [CLS];问答里可能是问题 token;摘要任务里则可能是特殊控制 token。这也是它在长文档 NLP 里特别自然的原因。相应的工程陷阱也很明显:global token 选得不好,信息就会堵住。
BigBird 在 Longformer 的"窗口 + 全局"基础上,又加了一层随机连接。论文摘要与正文都强调,BigBird 的最终注意力机制同时具有三种边:local、random 和 global;并且作者给出了很强的理论结果,说明这种稀疏 attention 仍然保持 sequence function 的 universal approximation,并且是 Turing complete。
从图论直觉看,局部窗口保证邻域细节,global token 提供中心汇聚,而随机边则显著缩短整体图的平均路径长度,防止信息只能靠一层层局部传递得太慢。BigBird 的价值,不只是"再省一点算力",而是它努力在局部性、全局汇聚和远距离捷径之间取得平衡。
Reformer 走的是完全不同的路:它不手工指定谁看谁,而是先用 LSH 把相近的 query/key 分到相同 bucket,再只在 bucket 内近似做注意力。论文摘要写到,它把注意力复杂度从平方降低到近似;同时它还引入 reversible layers,从而不用为每层都存完整激活。
Reformer 的优点是对超长序列很有吸引力,但它比 Longformer/BigBird 难调,因为哈希轮数、bucket 大小、排序过程以及可逆层的实现都更复杂。原论文自己也承认,LSH attention 是更重的结构性改变,会影响训练动态。基本工程建议是:除非你真的长到稠密/局部模型都扛不住,否则优先从 Longformer/BigBird 或 exact kernel 优化开始 。这个判断是基于各论文的方法复杂度与实现代价做出的工程推断。
把稀疏注意力家族统一成一句伪代码,其实就更清楚了:
python
for i in range(n):
visible = local_window(i, w) | global_tokens | random_tokens(i)
score_i = (q[i] @ K[visible].T) / sqrt(d_k)
attn_i = softmax(score_i)
y[i] = attn_i @ V[visible]你会发现,这类模型的真正设计自由度根本不是"softmax 怎么算",而是 visible 到底怎么定义。Longformer 把它定义成局部邻域加少量全局点,BigBird 再加随机边,Reformer 则让哈希结果来决定这个可见集合。
为了直观看 mask 长什么样,这里给一个很有用的 ASCII 示意:
双向:
11111111
11111111
11111111
11111111
11111111
11111111
11111111
11111111
因果:
10000000
11000000
11100000
11110000
11111000
11111100
11111110
11111111
局部窗口 w = 2:
11100000
11110000
11111000
01111100
00111110
00011111
00001111
00000111如果你脑子里能稳稳地看到这三张图,那么后面看到 Longformer、BigBird、Mamba-2 Hybrid 甚至各种块稀疏实现时,都会立刻明白:它们本质上都在重写"可见边集"。
四、线性化与低秩近似
如果说稀疏注意力是在改"图结构",那么线性化与低秩近似是在改"矩阵算法"。它们不一定会显式砍边,但都会避免直接构造完整的 attention matrix。高效 Transformer 综述把这一路线又细分为 kernel-based、low-rank、memory-compressed 等多个方向。
(一)线性化
最经典的线性化注意力代表,是 Linear Transformer。Katharopoulos 等人把自注意力表达成核特征映射的线性点积,利用矩阵乘法结合律,把复杂度从 降到
,而且指出这样一来,自回归 Transformer 会显露出与 RNN 的关系。
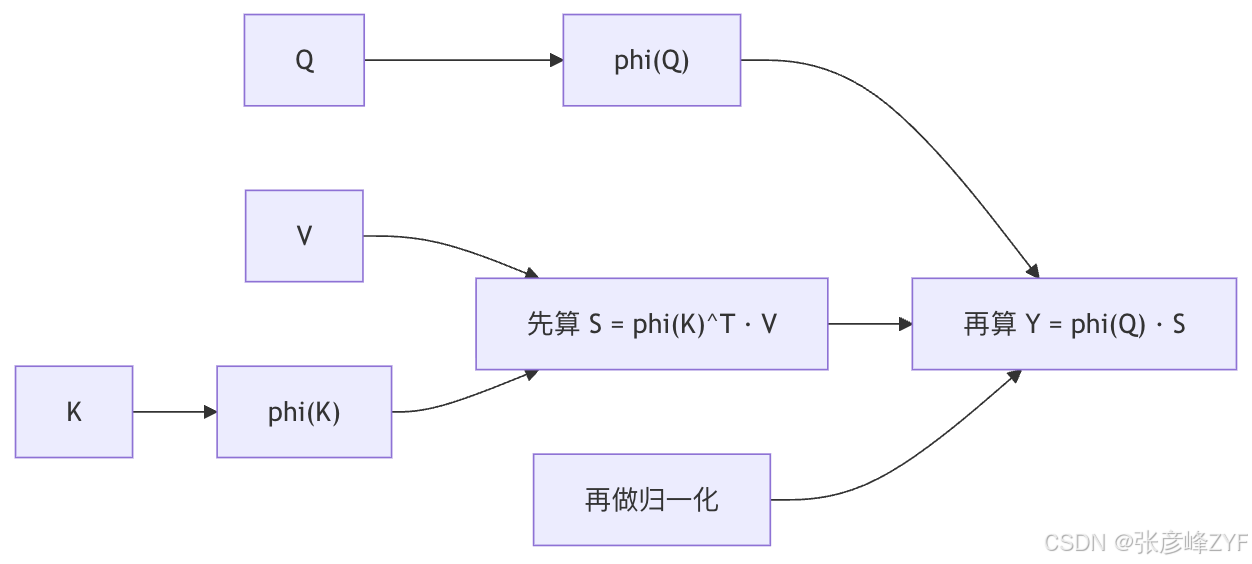
这类方法最核心的恒等式,是把 替换成
于是你可以先把所有 key-value 信息压成一个累计统计量,再对每个 query 做读取。这就是为什么它对流式、在线、自回归场景特别友好------它天然适合 prefix-scan 或递推计算。
Performer 是这条路线里更成熟也更"论文味"的版本。论文明确指出,它不依赖稀疏或低秩先验,而是用 FAVOR+ 对 softmax kernel 做可证明的高效近似,并给出线性时间和空间复杂度;同时,FAVOR+ 通过 positive orthogonal random features 来降低近似方差。
直观体会是:Linear Transformer 更像"提出一种结构等价重写",Performer 更像"把 softmax kernel 的近似这件事做扎实"。如果你只是想理解线性 attention 的大方向,Linear Transformer 更好懂;如果你要认真落地长序列近似 attention,Performer 往往是更强的研究起点。论文与 Google Research 的开源实现都可直接参考。
(二)低秩近似
Linformer 的原始论点非常直接:self-attention 的 context mapping matrix 通常是近似低秩的,因此可以先把 (K,V) 在序列维上从 (n) 投影到更小的 (k),再计算一个更小的 attention。论文摘要与 ar5iv 页面都明确写到,它通过这种低秩投影把复杂度从 降到
。
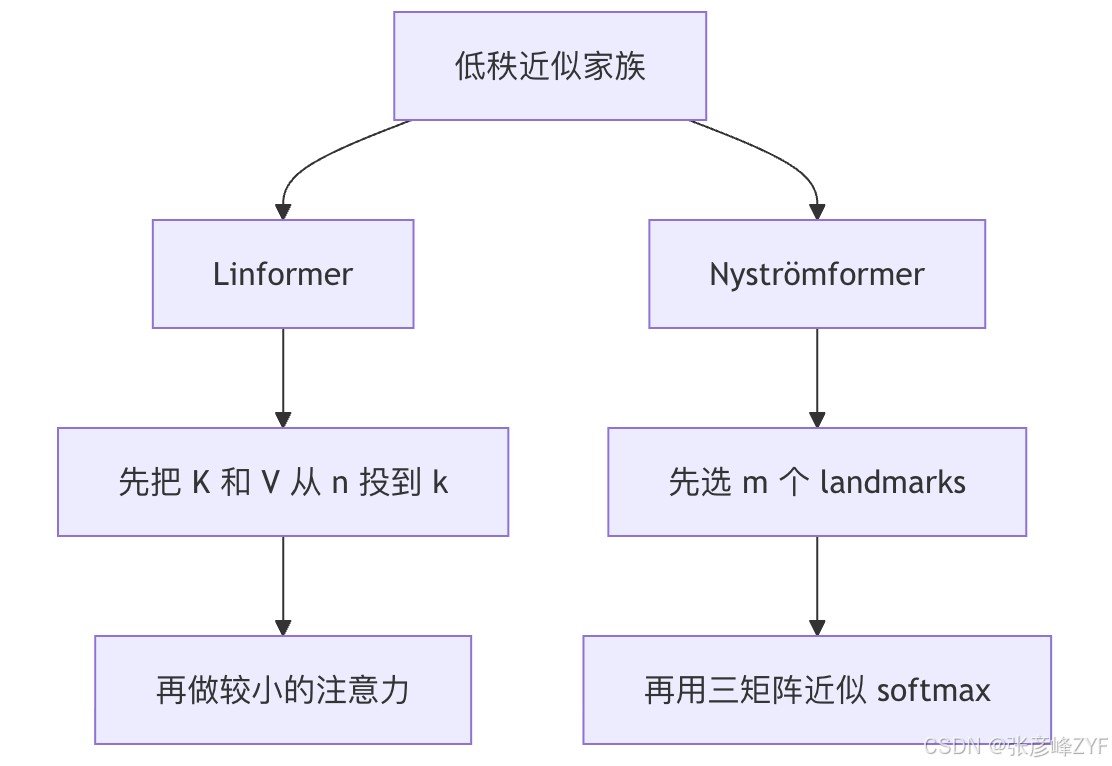
Linformer 的理解重点,不是死记某个公式,而是抓住这句话:不是所有 token-to-token 关系都需要在完整高维空间里显式存下来。它假设很多注意力模式可以被一个较低秩的矩阵逼近,因此直接把序列维压缩掉。Linformer 原论文给了理论与谱分析支持,但论文之外一个实际问题是:我没有检索到一个和论文同名、如今仍被研究社区广泛维护的"官方"代码仓库;工程上更常见的是社区实现,例如 lucidrains/linformer 这类 PyTorch 版本,因此落地时务必核对实现细节。
Nyströmformer 的思路又不同。它不用学习一个固定投影,而是先选 (m) 个 landmarks,用它们构造三个较小矩阵来近似原始 softmax matrix;论文还明确写到,它用 Segment-means 选 landmarks,用迭代法近似 Moore-Penrose 伪逆,并在主分支旁加了一个 1D depthwise convolution 的 skip connection 帮助训练。
这类方法的直观图景是:Linformer 说"我先把长度维压缩",Nyströmformer 说"我先找少量代表点,再用这些代表点重建全图"。如果你的注意力模式比较"可被代表点概括",Nyström 近似会很自然;如果你的模式更像"整体上低秩",Linformer 更直接。两者都不属于稀疏图思路,它们是在保留"全局交互"语义的同时,对矩阵结构做近似。
如果把这几类方法的复杂度放在一张表里,差异会更清楚。下面记 (n) 为序列长度、(d) 为隐藏维度、(w) 为窗口宽度、(r) 为随机边数、(g) 为全局 token 数、(k) 为低秩投影长度、(m) 为随机特征或 landmarks 数:
| 家族 | 核心做法 | 典型时间量级 | 典型中间存储 | 最适合的场景 |
|---|---|---|---|---|
| Dense attention | 全连接 attention | (O(n^2 d)) | (O(n^2)) | 中短上下文、需要 exact |
| 局部/稀疏 attention | 只算部分边 | (O(n(w+r+g)d)) | (O(n(w+r+g))) | 长文档编码 |
| Transformer-XL | 分段记忆复用 | 单段内仍近似 (O(n^2 d)) | 需要 memory cache | 长自回归上下文 |
| Reformer | LSH 分桶近邻 | 近似 (O(n\log n)) | 激活存储更省 | 超长序列 |
| Linear / Performer | 核特征映射 | 近似 (O(nmd)) | 近似 (O(nm)) | 超长序列、流式 |
| Linformer | 序列维低秩投影 | (O(nkd)) | (O(nk)) | 低秩结构明显的编码任务 |
| Nyströmformer | landmarks 近似 | (m) 固定时近似线性 | (O(nm + m^2)) | 长序列全局近似 |
| FlashAttention | exact 但重排 IO | 算术量级仍是二次 | 不显式存全 attention 矩阵 | exact 长上下文训练/推理 |
上表的量级来自原始 Transformer、Longformer、BigBird、Reformer、Linear Transformer、Performer、Linformer、Nyströmformer 以及 FlashAttention 的复杂度分析与实现说明;其中 FlashAttention 需要特别注意:它不改变 exact attention 的数学定义,只是显著改善 IO 与显存行为,因此它更像"工程优化"而不是"注意力归纳偏置的改变"。
如果你要自己实现一个最简线性注意力,伪代码可以写成:
# phi: 正值特征映射,例如 Performer/Linear Attention 各有不同构造
Qf = phi(Q) # [n, m]
Kf = phi(K) # [n, m]
KV = Kf.T @ V # [m, d_v]
Z = 1.0 / (Qf @ Kf.T.sum(dim=1)) # 归一化项,实际实现常更稳定
Y = (Qf @ KV) * Z[:, None]而如果你长上下文但又不想改模型语义,优先记住这一条工程经验:先试 exact dense + SDPA/FlashAttention,再试近似方法。PyTorch 的 scaled_dot_product_attention、Hugging Face 的 attention interface,以及 FlashAttention 官方仓库都已经把很多工程细节封装好了。
五、交叉注意力与结构融合
原始 Transformer 明确指出,decoder 里的 encoder-decoder attention 是这样定义的:Query 来自 decoder 的上一层,Key 和 Value 来自 encoder 输出。这层的意义非常大,因为它把"自己内部做上下文化"与"去外部记忆里取信息"区分开了。后来自然语言的 seq2seq、多模态模型、检索增强生成,几乎都建立在这个操作之上。
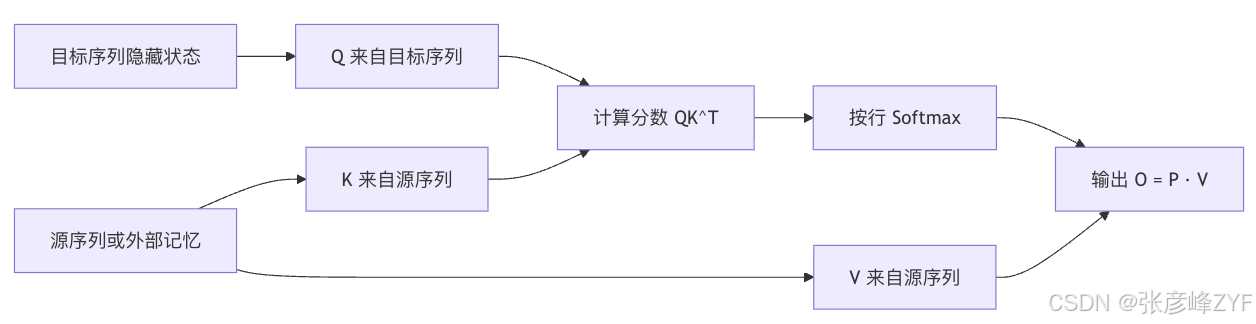
如果用一句话概括:自注意力是在同一条序列里重新布线,交叉注意力是在两条序列或两块记忆之间做内容寻址。你做翻译、摘要、语音到文本、多模态对齐时,真正想要的是"目标端按需读取源端",这就已经不是 self-attention 的问题了,而是 cross-attention 的问题。
再看可分离注意力。在多维数据上,直接把二维或三维张量 flatten 成一长串再做全连接 attention,复杂度会很快爆炸。Axial Attention 的工作把这一点说得非常清楚:它不展平张量,而是一次只沿一个轴做注意力;对图像来说,就是先按行,再按列。论文指出,对多维张量,这种 axial attention 相比标准全连接 attention 会带来显著的计算和内存节省,同时通过堆叠多个轴向层仍然获得全局感受野。

Axial attention 的直观体会很重要:它不是随便拆,而是利用数据天然的多维结构,把"全局交互"拆成多次低成本的一维全局交互。对于 的图像,全连接 flatten attention 的代价大致与
同阶,而轴向注意力可以下降到
这类形式,论文甚至直接指出在多维张量上能节约一个明显的资源因子。它非常适合图像、视频、谱图这类数据。
最后是注意力与卷积/归一化的结合。Conformer 是这条路线里最经典的代表。它的 ar5iv 页面明确写到,一个 Conformer block 由两层 macaron-style 的半步 FFN、一个带相对位置的 MHSA 和一个卷积模块组成,整体是"FFN / MHSA / Conv / FFN"的三明治结构;卷积模块里有 pointwise conv、GLU、1D depthwise conv、BatchNorm 和 swish,而 self-attention 子层使用的是来自 Transformer-XL 的相对位置方案与 pre-norm residual。

Conformer 给人的最深体会是:注意力不擅长一切局部模式,卷积也不擅长一切远距离关系,把两者硬凑在一起并不够,关键在于模块顺序和残差/归一化位置。Conformer 的消融实验明确显示,卷积子块是最关键的改动之一,而 Macaron-style FFN、相对位置编码也都带来额外收益。
类似的思路也出现在其他混合结构里。ConvBERT 观察到并不是所有注意力头都需要全局视野,于是用 span-based dynamic convolution 替换部分头;CoAtNet 则直接提出 depthwise convolution 与 self-attention 可以通过简单的 relative attention 统一,并把卷积层与注意力层分阶段堆叠。它们都说明:注意力不是卷积的替代品,而是更适合和局部归纳偏置合作。
归一化位置同样极其重要。关于 Transformer 中 LayerNorm 的位置,Xiong 等人的工作系统分析了 Post-LN 与 Pre-LN,指出 Pre-LN 会让梯度在初始化时行为更稳定,并能减少甚至去掉学习率 warm-up 的依赖;而 RMSNorm 论文则进一步指出,不一定非要做均值居中,保留 RMS 归一化就能得到更简单、更高效的替代。T5 的实现源码也明确采用了 RMSNorm 风格的 layer norm。
所以,从工程视角看,注意力模块本身的选择 只是一半问题;另一半问题是:它和卷积怎么排?和 FFN 怎么排?LayerNorm 是放在子层前还是后?是不是该上 RMSNorm?这些决定训练稳定性的问题,在大模型里往往不亚于"你选了哪一种注意力"。
六、工程建议与结论
这里如果你是在做大模型工程,而不是专门写一篇新 attention 论文,那么你最好按下面的顺序决策。第一步,先问自己"我的主要痛点到底是精度、长度、显存、吞吐还是流式推理";第二步,先看 exact attention 的工程优化能不能解决问题;第三步,再决定是否真的需要换近似或结构性稀疏 attention。FlashAttention、PyTorch SDPA 与 Hugging Face 的后端接口已经把"exact 但更高效"的空间做得很大了。
如果把"何时选用"压缩成一张表:
| 场景 | 优先候选 | 原因 | 主要风险 |
|---|---|---|---|
| 上下文不算极长,但必须 exact | Dense attention + RoPE/ALiBi + FlashAttention | 不改模型语义,最稳 | 仍然是二次算术量级 |
| 长文档分类、抽取、阅读理解 | Longformer / BigBird | 稀疏图更符合任务结构 | global token 设计很关键 |
| 极长自回归上下文 | 因果 attention + KV cache;必要时 Transformer-XL 或 ALiBi | 利于外推和缓存 | 长度外推仍需验证 |
| 显存特别紧、序列特别长 | Performer / Linformer / Nyströmformer | 近似线性 | 可能损失精细检索与复制能力 |
| encoder-decoder 或多模态对齐 | Cross-attention | 自然支持"从外部记忆读取" | 源端长度也会带来成本 |
| 图像、视频、语音等多维/局部结构强的数据 | Axial / Conformer / Conv-Attention hybrid | 同时利用全局与局部归纳偏置 | 结构更复杂、超参更多 |
这个表不是"排行榜",而是把各论文的机制特性翻译成实际选型语言。Longformer/BigBird 更适合长文档 encoder;Transformer-XL 原生偏向长程自回归;Performer/Linformer/Nyströmformer 是近似算法家族;Axial/Conformer/ConvBERT/CoAtNet 则更多面向多维数据或强局部结构任务。
有几个常见陷阱,强烈建议在真正上模型前就记住:
- 第一,不要一看到长序列就默认必须换近似 attention;很多场景下,真正的瓶颈先是 IO 和显存,而不是 attention 的数学定义,这也是 FlashAttention 能在 exact 设定下获得大收益的原因。
- 第二,稀疏图不是免费午餐;如果你的 global token、random edge 或 segment memory 设计得不好,信息流会被掐断。
- 第三,位置编码的"长上下文外推性"不能只看论文口号;ALiBi、RoPE、Transformer-XL 都有各自强项,但真实任务里依然要在目标长度上做验证。
如果希望继续深入并且要结合实现,推荐优先阅读和对照这些资源。标准注意力与多头注意力看原始 Transformer,再配合 D2L 中文版;双向编码看 BERT 官方与 Hugging Face 中文文档;相对位置与 RoPE 看 Shaw、T5、RoFormer 及其 Hugging Face 实现;长文档看 Longformer、BigBird、Transformer-XL;稀疏近似和线性近似看 Reformer、Performer、Linformer、Nyströmformer; exact 高效实现看 PyTorch SDPA 与 FlashAttention 官方仓库。相应的官方或原始实现包括 google-research/bert、kimiyoung/transformer-xl、allenai/longformer、google-research/performer、Dao-AILab/flash-attention、ZhuiyiTechnology/roformer,以及 Hugging Face Transformers 中的 BERT、Longformer、RoFormer、T5 等模块;中文入门最稳的则是《动手学深度学习》中文版和 Hugging Face 中文文档。
综合全文把"自注意力及其变种"的真正核心总结成三句话:
- 第一,先学会把所有变体还原成统一公式;这样你不会被名字吓住。
- 第二,先分清楚你是在改归纳偏置,还是在改矩阵算法,还是在改工程执行方式;这能避免误选。
- 第三,大模型场景里最常见的成功路径,并不是最奇怪的 attention 论文,而是在合适的位置编码、归一化与高效 kernel 之上,谨慎地引入稀疏或近似。这也是为什么,真正成熟的工程方案往往看起来没有论文分类那么花哨,但更稳。
开放问题与局限说明
上面我们已经覆盖了大多数主流机制,但仍有几类内容没有展开到论文级细节,比如:更细分的 block-sparse 变体、Grouped Query Attention 与 Multi-Query Attention、MoE 中的路由注意力、以及 RoPE 的各种 extrapolation trick。它们和本文主题密切相关,但严格说已经超出"自注意力及其主要变种"的主干范围。另一个需要说明的点是:Linformer 的"官方、持续维护实现"在公开检索中没有 Longformer、BERT、FlashAttention 那么明确,因此我在实现建议里刻意把它标成"社区常用实现为主",以免误导。
推荐阅读和参考
核心论文与论文 HTML/PDF 整理
1. 标准 Transformer、自注意力基础
| 主题 | 链接 |
|---|---|
| Attention Is All You Need | NeurIPS PDF |
2. 位置编码与方向性
| 主题 | 链接 |
|---|---|
| Shaw 相对位置表示:Self-Attention with Relative Position Representations | arXiv |
| T5:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | arXiv PDF |
| RoFormer / RoPE:Rotary Position Embedding | arXiv |
| ALiBi:Train Short, Test Long | OpenReview |
| ALiBi arXiv 版本 | arXiv |
| Transformer-XL | arXiv |
3. 长序列与稀疏注意力
| 主题 | 链接 |
|---|---|
| Longformer | ar5iv HTML/PDF |
| BigBird | arXiv |
| BigBird ar5iv 版本 | ar5iv HTML/PDF |
| Reformer | ar5iv HTML/PDF |
| Efficient Transformers Survey | arXiv |
| Efficient Transformers Survey ACM PDF | ACM PDF |
4. 线性化、低秩近似与高效 Attention
| 主题 | 链接 |
|---|---|
| Linear Transformers Are Secretly Fast Weight Programmers | arXiv |
| Linear Transformers PMLR 页面 | PMLR |
| Performer / FAVOR+ | ar5iv HTML |
| Linformer | arXiv |
| Linformer ar5iv 版本 | ar5iv HTML |
| Nyströmformer | ar5iv HTML |
| FlashAttention | arXiv |
5. Cross-Attention、Axial Attention、卷积混合结构
| 主题 | 链接 |
|---|---|
| Axial Attention | ar5iv HTML/PDF |
| Conformer | ar5iv HTML |
| ConvBERT | arXiv |
| CoAtNet | arXiv |
6. LayerNorm / RMSNorm / 训练稳定性
| 主题 | 链接 |
|---|---|
| On Layer Normalization in the Transformer Architecture | arXiv |
| On Layer Normalization PMLR PDF | PMLR PDF |
| RMSNorm | arXiv |
官方或常用代码仓库
| 项目 | 链接 |
|---|---|
| Google BERT 官方仓库 | google-research/bert |
| Transformer-XL 官方仓库 | kimiyoung/transformer-xl |
| Performer 官方实现 | google-research/google-research/performer |
| FlashAttention 官方仓库 | Dao-AILab/flash-attention |
| RoFormer / RoPE 仓库 | ZhuiyiTechnology/roformer |
| Linformer 社区常用实现 | lucidrains/linformer |
| Hugging Face T5 源码 | modeling_t5.py |
| Hugging Face RoFormer 英文文档源码 | roformer.md |
框架与模型文档
| 主题 | 链接 |
|---|---|
| PyTorch SDPA:scaled_dot_product_attention | PyTorch Docs |
| Hugging Face Attention Interface | Transformers Docs |
| Hugging Face BERT 文档 | 英文文档 |
| Hugging Face 中文 BERT 文档 | 中文文档 |
| Hugging Face 中文 Longformer 文档 | 中文文档 |
| Hugging Face 中文 RoFormer 文档 | 中文文档 |
| Hugging Face 中文 T5 文档 | 中文文档 |
中文入门与直观教程
| 主题 | 链接 |
|---|---|
| D2L 中文:自注意力与位置编码 | 动手学深度学习 |
| D2L 中文:多头注意力 | 动手学深度学习 |
推荐阅读顺序
建议按这个顺序读,效率最高: