文章目录
-
- 前言
- 第一部分:完整代码解析
-
- [1.1 代码概述](#1.1 代码概述)
- [1.2 头文件与宏定义(1-77行)](#1.2 头文件与宏定义(1-77行))
- [1.3 行主序与列主序的核心问题(20-40行)](#1.3 行主序与列主序的核心问题(20-40行))
- [1.4 数据结构定义(79-83行)](#1.4 数据结构定义(79-83行))
- [1.5 CPU 参考实现(97-115行)](#1.5 CPU 参考实现(97-115行))
- [1.6 辅助函数(117-151行)](#1.6 辅助函数(117-151行))
- [1.7 GPU 初始化函数(153-207行)](#1.7 GPU 初始化函数(153-207行))
- [1.8 核心矩阵乘法函数(210-330行)](#1.8 核心矩阵乘法函数(210-330行))
-
- 内存分配与数据传输(225-242行)
- [CUBLAS 配置与调用(256-280行)](#CUBLAS 配置与调用(256-280行))
- 性能测量(272-302行)
- 结果验证(314-324行)
- [第二部分:cublasSgemm 函数详解](#第二部分:cublasSgemm 函数详解)
-
- [2.1 函数原型与数学公式](#2.1 函数原型与数学公式)
- [2.2 参数详解](#2.2 参数详解)
-
- handle
- [transa, transb](#transa, transb)
- [m, n, k](#m, n, k)
- [lda, ldb, ldc(Leading Dimension)](#lda, ldb, ldc(Leading Dimension))
- [alpha, beta](#alpha, beta)
- [2.3 核心概念:列主序存储](#2.3 核心概念:列主序存储)
- [2.4 正确的调用技巧](#2.4 正确的调用技巧)
- [2.5 完整使用流程](#2.5 完整使用流程)
- [2.6 性能测量技术](#2.6 性能测量技术)
- 第三部分:完整的最小示例
- 总结与最佳实践
前言
在 GPU 高性能计算领域,矩阵乘法是最基础也是最重要的操作之一。NVIDIA 的 CUBLAS 库提供了高度优化的矩阵乘法实现,但使用时需要特别注意行主序与列主序的差异。本文将结合一个完整的 CUBLAS 示例代码,深入解析 cublasSgemm 函数的使用方法。
cpp
//
// Matrix multiplication: C = A * B.
// Host code.
//
// This sample implements matrix multiplication as described in Chapter 3
// of the programming guide and uses the CUBLAS library to demonstrate
// the best performance.
// SOME PRECAUTIONS:
// IF WE WANT TO CALCULATE ROW-MAJOR MATRIX MULTIPLY C = A * B,
// WE JUST NEED CALL CUBLAS API IN A REVERSE ORDER: cublasSegemm(B, A)!
// The reason is explained as follows:
// CUBLAS library uses column-major storage, but C/C++ use row-major storage.
// When passing the matrix pointer to CUBLAS, the memory layout alters from
// row-major to column-major, which is equivalent to an implicit transpose.
// In the case of row-major C/C++ matrix A, B, and a simple matrix multiplication
// C = A * B, we can't use the input order like cublasSgemm(A, B) because of
// implicit transpose. The actual result of cublasSegemm(A, B) is A(T) * B(T).
// If col(A(T)) != row(B(T)), equal to row(A) != col(B), A(T) and B(T) are not
// multipliable. Moreover, even if A(T) and B(T) are multipliable, the result C
// is a column-based cublas matrix, which means C(T) in C/C++, we need extra
// transpose code to convert it to a row-based C/C++ matrix.
// To solve the problem, let's consider our desired result C, a row-major matrix.
// In cublas format, it is C(T) actually (because of the implicit transpose).
// C = A * B, so C(T) = (A * B) (T) = B(T) * A(T). Cublas matrice B(T) and A(T)
// happen to be C/C++ matrice B and A (still because of the implicit transpose)!
// We don't need extra transpose code, we only need alter the input order!
//
// CUBLAS provides high-performance matrix multiplication.
// See also:
// V. Volkov and J. Demmel, "Benchmarking GPUs to tune dense linear algebra,"
// in Proc. 2008 ACM/IEEE Conf. on Supercomputing (SC '08),
// Piscataway, NJ: IEEE Press, 2008, pp. Art. 31:1-11.
//
// Utilities and system includes
#include <assert.h>
#include <helper_string.h> // helper for shared functions common to CUDA Samples
// CUDA runtime
#include <cuda_runtime.h>
#include <cublas_v2.h>
// CUDA and CUBLAS functions
#include <helper_functions.h>
#include <helper_cuda.h>
#ifndef min
#define min(a,b) ((a < b) ? a : b)
#endif
#ifndef max
#define max(a,b) ((a > b) ? a : b)
#endif
typedef struct _matrixSize // Optional Command-line multiplier for matrix sizes
{
unsigned int uiWA, uiHA, uiWB, uiHB, uiWC, uiHC;
} sMatrixSize;
////////////////////////////////////////////////////////////////////////////////
//! Compute reference data set matrix multiply on CPU
//! C = A * B
//! @param C reference data, computed but preallocated
//! @param A matrix A as provided to device
//! @param B matrix B as provided to device
//! @param hA height of matrix A
//! @param wB width of matrix B
////////////////////////////////////////////////////////////////////////////////
void
matrixMulCPU(float *C, const float *A, const float *B, unsigned int hA, unsigned int wA, unsigned int wB)
{
for (unsigned int i = 0; i < hA; ++i)
for (unsigned int j = 0; j < wB; ++j)
{
double sum = 0;
for (unsigned int k = 0; k < wA; ++k)
{
double a = A[i * wA + k];
double b = B[k * wB + j];
sum += a * b;
}
C[i * wB + j] = (float)sum;
}
}
// Allocates a matrix with random float entries.
void randomInit(float *data, int size)
{
for (int i = 0; i < size; ++i)
data[i] = rand() / (float)RAND_MAX;
}
void printDiff(float *data1, float *data2, int width, int height, int iListLength, float fListTol)
{
printf("Listing first %d Differences > %.6f...\n", iListLength, fListTol);
int i,j,k;
int error_count=0;
for (j = 0; j < height; j++)
{
if (error_count < iListLength)
{
printf("\n Row %d:\n", j);
}
for (i = 0; i < width; i++)
{
k = j * width + i;
float fDiff = fabs(data1[k] - data2[k]);
if (fDiff > fListTol)
{
if (error_count < iListLength)
{
printf(" Loc(%d,%d)\tCPU=%.5f\tGPU=%.5f\tDiff=%.6f\n", i, j, data1[k], data2[k], fDiff);
}
error_count++;
}
}
}
printf(" \n Total Errors = %d\n", error_count);
}
void initializeCUDA(int argc, char **argv, int &devID, int &iSizeMultiple, sMatrixSize &matrix_size)
{
// By default, we use device 0, otherwise we override the device ID based on what is provided at the command line
cudaError_t error;
devID = 0;
devID = findCudaDevice(argc, (const char **)argv);
if (checkCmdLineFlag(argc, (const char **)argv, "sizemult"))
{
iSizeMultiple = getCmdLineArgumentInt(argc, (const char **)argv, "sizemult");
}
iSizeMultiple = min(iSizeMultiple, 10);
iSizeMultiple = max(iSizeMultiple, 1);
cudaDeviceProp deviceProp;
error = cudaGetDeviceProperties(&deviceProp, devID);
if (error != cudaSuccess)
{
printf("cudaGetDeviceProperties returned error code %d, line(%d)\n", error, __LINE__);
exit(EXIT_FAILURE);
}
printf("GPU Device %d: \"%s\" with compute capability %d.%d\n\n", devID, deviceProp.name, deviceProp.major, deviceProp.minor);
int block_size = 32;
matrix_size.uiWA = 3 * block_size * iSizeMultiple;
matrix_size.uiHA = 4 * block_size * iSizeMultiple;
matrix_size.uiWB = 2 * block_size * iSizeMultiple;
matrix_size.uiHB = 3 * block_size * iSizeMultiple;
matrix_size.uiWC = 2 * block_size * iSizeMultiple;
matrix_size.uiHC = 4 * block_size * iSizeMultiple;
printf("MatrixA(%u,%u), MatrixB(%u,%u), MatrixC(%u,%u)\n",
matrix_size.uiHA, matrix_size.uiWA,
matrix_size.uiHB, matrix_size.uiWB,
matrix_size.uiHC, matrix_size.uiWC);
if( matrix_size.uiWA != matrix_size.uiHB ||
matrix_size.uiHA != matrix_size.uiHC ||
matrix_size.uiWB != matrix_size.uiWC)
{
printf("ERROR: Matrix sizes do not match!\n");
exit(-1);
}
}
////////////////////////////////////////////////////////////////////////////////
//! Run a simple test matrix multiply using CUBLAS
////////////////////////////////////////////////////////////////////////////////
int matrixMultiply(int argc, char **argv, int devID, sMatrixSize &matrix_size)
{
cudaDeviceProp deviceProp;
checkCudaErrors(cudaGetDeviceProperties(&deviceProp, devID));
int block_size = 32;
// set seed for rand()
srand(2006);
// allocate host memory for matrices A and B
unsigned int size_A = matrix_size.uiWA * matrix_size.uiHA;
unsigned int mem_size_A = sizeof(float) * size_A;
float *h_A = (float *)malloc(mem_size_A);
unsigned int size_B = matrix_size.uiWB * matrix_size.uiHB;
unsigned int mem_size_B = sizeof(float) * size_B;
float *h_B = (float *)malloc(mem_size_B);
// set seed for rand()
srand(2006);
// initialize host memory
randomInit(h_A, size_A);
randomInit(h_B, size_B);
// allocate device memory
float *d_A, *d_B, *d_C;
unsigned int size_C = matrix_size.uiWC * matrix_size.uiHC;
unsigned int mem_size_C = sizeof(float) * size_C;
// allocate host memory for the result
float *h_C = (float *) malloc(mem_size_C);
float *h_CUBLAS = (float *) malloc(mem_size_C);
checkCudaErrors(cudaMalloc((void **) &d_A, mem_size_A));
checkCudaErrors(cudaMalloc((void **) &d_B, mem_size_B));
checkCudaErrors(cudaMemcpy(d_A, h_A, mem_size_A, cudaMemcpyHostToDevice));
checkCudaErrors(cudaMemcpy(d_B, h_B, mem_size_B, cudaMemcpyHostToDevice));
checkCudaErrors(cudaMalloc((void **) &d_C, mem_size_C));
// setup execution parameters
dim3 threads(block_size, block_size);
dim3 grid(matrix_size.uiWC / threads.x, matrix_size.uiHC / threads.y);
// create and start timer
printf("Computing result using CUBLAS...");
// execute the kernel
int nIter = 30;
// CUBLAS version 2.0
{
const float alpha = 1.0f;
const float beta = 0.0f;
cublasHandle_t handle;
cudaEvent_t start, stop;
checkCudaErrors(cublasCreate(&handle));
//Perform warmup operation with cublas
checkCudaErrors(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, matrix_size.uiWB, matrix_size.uiHA, matrix_size.uiWA, &alpha, d_B, matrix_size.uiWB, d_A, matrix_size.uiWA, &beta, d_C, matrix_size.uiWB));
// Allocate CUDA events that we'll use for timing
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
// Record the start event
checkCudaErrors(cudaEventRecord(start, NULL));
for (int j = 0; j < nIter; j++)
{
//note cublas is column primary!
//need to transpose the order
checkCudaErrors(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, matrix_size.uiWB, matrix_size.uiHA, matrix_size.uiWA, &alpha, d_B, matrix_size.uiWB, d_A, matrix_size.uiWA, &beta, d_C, matrix_size.uiWB));
}
printf("done.\n");
// Record the stop event
checkCudaErrors(cudaEventRecord(stop, NULL));
// Wait for the stop event to complete
checkCudaErrors(cudaEventSynchronize(stop));
float msecTotal = 0.0f;
checkCudaErrors(cudaEventElapsedTime(&msecTotal, start, stop));
// Compute and print the performance
float msecPerMatrixMul = msecTotal / nIter;
double flopsPerMatrixMul = 2.0 * (double)matrix_size.uiHC * (double)matrix_size.uiWC * (double)matrix_size.uiHB;
double gigaFlops = (flopsPerMatrixMul * 1.0e-9f) / (msecPerMatrixMul / 1000.0f);
printf(
"Performance= %.2f GFlop/s, Time= %.3f msec, Size= %.0f Ops\n",
gigaFlops,
msecPerMatrixMul,
flopsPerMatrixMul);
// copy result from device to host
checkCudaErrors(cudaMemcpy(h_CUBLAS, d_C, mem_size_C, cudaMemcpyDeviceToHost));
// Destroy the handle
checkCudaErrors(cublasDestroy(handle));
}
// compute reference solution
printf("Computing result using host CPU...");
float *reference = (float *)malloc(mem_size_C);
matrixMulCPU(reference, h_A, h_B, matrix_size.uiHA, matrix_size.uiWA, matrix_size.uiWB);
printf("done.\n");
// check result (CUBLAS)
bool resCUBLAS = sdkCompareL2fe(reference, h_CUBLAS, size_C, 1.0e-6f);
if (resCUBLAS != true)
{
printDiff(reference, h_CUBLAS, matrix_size.uiWC, matrix_size.uiHC, 100, 1.0e-5f);
}
printf("Comparing CUBLAS Matrix Multiply with CPU results: %s\n", (true == resCUBLAS) ? "PASS" : "FAIL");
printf("\nNOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.\n");
// clean up memory
free(h_A);
free(h_B);
free(h_C);
free(reference);
checkCudaErrors(cudaFree(d_A));
checkCudaErrors(cudaFree(d_B));
checkCudaErrors(cudaFree(d_C));
if (resCUBLAS == true)
{
return EXIT_SUCCESS; // return value = 1
}
else
{
return EXIT_FAILURE; // return value = 0
}
}
////////////////////////////////////////////////////////////////////////////////
// Program main
////////////////////////////////////////////////////////////////////////////////
int main(int argc, char **argv)
{
printf("[Matrix Multiply CUBLAS] - Starting...\n");
int devID = 0, sizeMult = 5;
sMatrixSize matrix_size;
initializeCUDA(argc, argv, devID, sizeMult, matrix_size);
int matrix_result = matrixMultiply(argc, argv, devID, matrix_size);
return matrix_result;
}结果如下图所示:
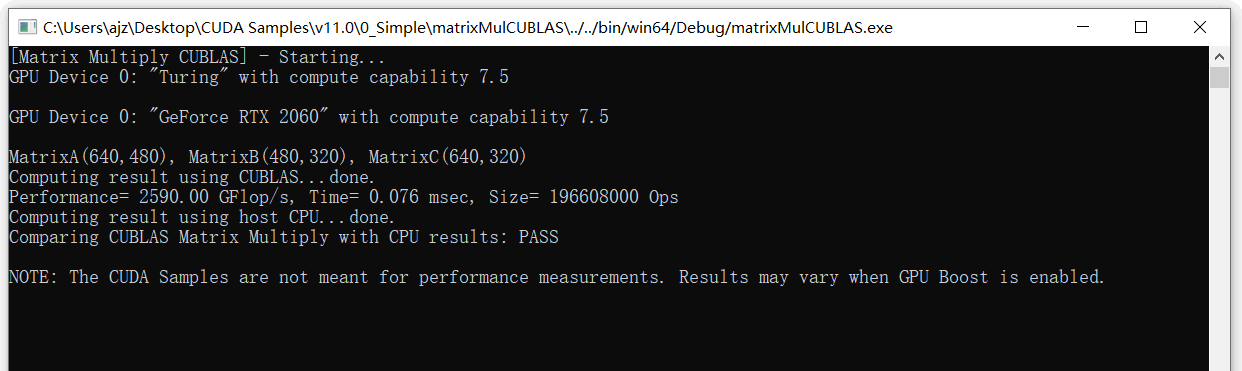
第一部分:完整代码解析
1.1 代码概述
这是一个使用 CUBLAS 库在 GPU 上进行矩阵乘法的完整示例,实现了 C = A * B 的计算,并提供了 CPU 参考实现用于验证结果。
1.2 头文件与宏定义(1-77行)
cpp
// Utilities and system includes
#include <assert.h>
#include <helper_string.h> // helper for shared functions common to CUDA Samples
// CUDA runtime
#include <cuda_runtime.h>
#include <cublas_v2.h>
// CUDA and CUBLAS functions
#include <helper_functions.h>
#include <helper_cuda.h>
#ifndef min
#define min(a,b) ((a < b) ? a : b)
#endif
#ifndef max
#define max(a,b) ((a > b) ? a : b)
#endif关键点:
cuda_runtime.h:CUDA 运行时 APIcublas_v2.h:CUBLAS 库 API 版本 2helper_cuda.h:CUDA Samples 提供的错误检查辅助函数- min/max 宏:如果没有定义则创建
1.3 行主序与列主序的核心问题(20-40行)
代码注释中详细解释了 CUBLAS 使用的关键难点:
cpp
// CUBLAS library uses column-major storage, but C/C++ use row-major storage.
// When passing the matrix pointer to CUBLAS, the memory layout alters from
// row-major to column-major, which is equivalent to an implicit transpose.核心概念:
- CUBLAS 使用列主序存储:矩阵在内存中按列连续存储
- C/C++ 使用行主序存储:矩阵在内存中按行连续存储
- 当传递矩阵指针给 CUBLAS 时,内存布局从行主序变为列主序,相当于隐式转置
解决方案:
cpp
// To solve the problem, let's consider our desired result C, a row-major matrix.
// In cublas format, it is C(T) actually (because of the implicit transpose).
// C = A * B, so C(T) = (A * B)(T) = B(T) * A(T).
// We don't need extra transpose code, we only need alter the input order!数学推导:
- 期望计算:
C = A × B(行主序) - CUBLAS 实际计算:
C_cublas = A^T × B^T = (A × B)^T - 因此:调用
cublasSgemm(B, A)而不是cublasSgemm(A, B)
1.4 数据结构定义(79-83行)
cpp
typedef struct _matrixSize {
unsigned int uiWA, uiHA; // A矩阵: 宽(WA)、高(HA)
unsigned int uiWB, uiHB; // B矩阵: 宽(WB)、高(HB)
unsigned int uiWC, uiHC; // C矩阵: 宽(WC)、高(HC)
} sMatrixSize;1.5 CPU 参考实现(97-115行)
cpp
void matrixMulCPU(float *C, const float *A, const float *B,
unsigned int hA, unsigned int wA, unsigned int wB)
{
for (unsigned int i = 0; i < hA; ++i)
for (unsigned int j = 0; j < wB; ++j)
{
double sum = 0;
for (unsigned int k = 0; k < wA; ++k)
{
double a = A[i * wA + k];
double b = B[k * wB + j];
sum += a * b;
}
C[i * wB + j] = (float)sum;
}
}三重循环逻辑:
- i 循环:遍历 A 的行(0 到 hA-1)
- j 循环:遍历 B 的列(0 到 wB-1)
- k 循环:计算点积(0 到 wA-1)
- 结果存储:
C[i * wB + j]
1.6 辅助函数(117-151行)
cpp
void randomInit(float *data, int size)
{
for (int i = 0; i < size; ++i)
data[i] = rand() / (float)RAND_MAX;
}
void printDiff(float *data1, float *data2, int width, int height,
int iListLength, float fListTol)
{
// 打印前 iListLength 个差异大于 fListTol 的元素
}1.7 GPU 初始化函数(153-207行)
cpp
void initializeCUDA(int argc, char **argv, int &devID,
int &iSizeMultiple, sMatrixSize &matrix_size)
{
// 选择 CUDA 设备
devID = findCudaDevice(argc, (const char **)argv);
// 解析命令行参数
if (checkCmdLineFlag(argc, (const char **)argv, "sizemult"))
{
iSizeMultiple = getCmdLineArgumentInt(argc, (const char **)argv, "sizemult");
}
// 设置矩阵尺寸
int block_size = 32;
matrix_size.uiWA = 3 * block_size * iSizeMultiple; // 宽度 A
matrix_size.uiHA = 4 * block_size * iSizeMultiple; // 高度 A
matrix_size.uiWB = 2 * block_size * iSizeMultiple; // 宽度 B
matrix_size.uiHB = 3 * block_size * iSizeMultiple; // 高度 B
matrix_size.uiWC = 2 * block_size * iSizeMultiple; // 宽度 C
matrix_size.uiHC = 4 * block_size * iSizeMultiple; // 高度 C
}1.8 核心矩阵乘法函数(210-330行)
这是整个程序的核心,展示了如何正确使用 CUBLAS:
内存分配与数据传输(225-242行)
cpp
// 分配主机内存
float *h_A = (float *)malloc(mem_size_A);
float *h_B = (float *)malloc(mem_size_B);
float *h_CUBLAS = (float *)malloc(mem_size_C);
// 分配设备内存
cudaMalloc(&d_A, mem_size_A);
cudaMalloc(&d_B, mem_size_B);
cudaMalloc(&d_C, mem_size_C);
// 数据传输到设备
cudaMemcpy(d_A, h_A, mem_size_A, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, mem_size_B, cudaMemcpyHostToDevice);CUBLAS 配置与调用(256-280行)
cpp
const float alpha = 1.0f; // 缩放因子
const float beta = 0.0f; // 不保留原有 C
cublasHandle_t handle;
cublasCreate(&handle); // 创建 CUBLAS 句柄
// 关键:反转参数顺序以处理行主序/列主序差异
cublasSgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N, // 不转置
matrix_size.uiWB, // m: B 的宽度
matrix_size.uiHA, // n: A 的高度
matrix_size.uiWA, // k: A 的宽度
&alpha,
d_B, // 先传 B(重要!)
matrix_size.uiWB,
d_A, // 后传 A(重要!)
matrix_size.uiWA,
&beta,
d_C,
matrix_size.uiWB);性能测量(272-302行)
cpp
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, NULL);
for (int j = 0; j < nIter; j++) {
cublasSgemm(...); // 执行多次取平均
}
cudaEventRecord(stop, NULL);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&msecTotal, start, stop);
// 计算性能(GFlops)
float msecPerMatrixMul = msecTotal / nIter;
double flopsPerMatrixMul = 2.0 * HC * WC * HB;
double gigaFlops = (flopsPerMatrixMul * 1.0e-9f) / (msecPerMatrixMul / 1000.0f);结果验证(314-324行)
cpp
// 从 GPU 拷贝结果
cudaMemcpy(h_CUBLAS, d_C, mem_size_C, cudaMemcpyDeviceToHost);
// CPU 计算参考结果
matrixMulCPU(reference, h_A, h_B, ...);
// L2 范数比较
bool resCUBLAS = sdkCompareL2fe(reference, h_CUBLAS, size_C, 1.0e-6f);第二部分:cublasSgemm 函数详解
2.1 函数原型与数学公式
cublasSgemm 执行的计算公式:
C = α * op(A) * op(B) + β * C其中:
A,B,C是存储在 GPU 显存中的矩阵α,β是标量op()可以是转置 (CUBLAS_OP_T) 或不转置 (CUBLAS_OP_N)
完整函数签名:
c
cublasStatus_t cublasSgemm(
cublasHandle_t handle, // cuBLAS 句柄
cublasOperation_t transa, // 对 A 的操作
cublasOperation_t transb, // 对 B 的操作
int m, // op(A) 和 C 的行数
int n, // op(B) 和 C 的列数
int k, // op(A) 的列数,op(B) 的行数
const float *alpha, // α 的指针(主机端)
const float *A, // A 的 GPU 指针
int lda, // A 的 leading dimension
const float *B, // B 的 GPU 指针
int ldb, // B 的 leading dimension
const float *beta, // β 的指针(主机端)
float *C, // C 的 GPU 指针
int ldc // C 的 leading dimension
);2.2 参数详解
handle
- 由
cublasCreate()创建 - 代表 cuBLAS 库的上下文
- 所有 API 调用都需要它
transa, transb
CUBLAS_OP_N:不转置CUBLAS_OP_T:转置CUBLAS_OP_C:共轭转置(仅复数类型)
m, n, k
这三个参数定义了矩阵的维度:
op(A)是 m × k 矩阵op(B)是 k × n 矩阵C是 m × n 矩阵
lda, ldb, ldc(Leading Dimension)
- 存储矩阵的数组中一列的元素个数
- 通常等于矩阵的行数
- 是理解 cuBLAS 的关键参数
alpha, beta
- 必须传递指针(即使是标量)
- alpha = 1.0, beta = 0.0 是最常见的配置
2.3 核心概念:列主序存储
cuBLAS 使用列主序存储矩阵:
- 矩阵在内存中按列连续存储
- 而 C/C++ 使用行主序(按行连续存储)
示例对比:
矩阵:
[1, 2, 3]
[4, 5, 6]
行主序存储(C/C++): [1, 2, 3, 4, 5, 6]
列主序存储(CUBLAS): [1, 4, 2, 5, 3, 6]2.4 正确的调用技巧
直接调用的错误:
cpp
// 错误示例
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
M, N, K,
&alpha, d_A, M, d_B, K,
&beta, d_C, M);正确的调用方式(调换技巧):
cpp
// 正确示例
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
N, M, K, // 调换 m 和 n
&alpha,
d_B, N, // 调换 A 和 B
d_A, K,
&beta,
d_C, N);数学原理:
- 行主序矩阵 A 传递给 CUBLAS → 被解释为 A^T
- 行主序矩阵 B 传递给 CUBLAS → 被解释为 B^T
- CUBLAS 计算:
C_cublas = A^T × B^T = (A × B)^T - 通过交换 A 和 B:
C_cublas = B^T × A^T = (A × B)^T不变 - 调换 m 和 n 使结果维度正确
2.5 完整使用流程
cpp
#include <cuda_runtime.h>
#include <cublas_v2.h>
int main() {
const int M = 2, N = 3, K = 4;
float h_A[M*K], h_B[K*N], h_C[M*N];
// 1. 初始化数据(行主序)
// ... 填充 h_A, h_B
// 2. 创建 cuBLAS 句柄
cublasHandle_t handle;
cublasCreate(&handle);
// 3. 分配 GPU 内存
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, M*K*sizeof(float));
cudaMalloc(&d_B, K*N*sizeof(float));
cudaMalloc(&d_C, M*N*sizeof(float));
// 4. 拷贝数据到 GPU
cudaMemcpy(d_A, h_A, M*K*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, K*N*sizeof(float), cudaMemcpyHostToDevice);
// 5. 调用 cublasSgemm
float alpha = 1.0f, beta = 0.0f;
cublasSgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N,
N, M, K, // 调换 m 和 n
&alpha,
d_B, N, // 调换 A 和 B
d_A, K,
&beta,
d_C, N);
// 6. 拷贝结果回主机
cudaMemcpy(h_C, d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
// 7. 清理资源
cublasDestroy(handle);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
return 0;
}2.6 性能测量技术
使用 CUDA Events 进行精确计时:
cpp
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, NULL);
// 执行要测量的操作
cudaEventRecord(stop, NULL);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
// 计算 GFlops
double flops = 2.0 * M * N * K; // 每个乘加算两次操作
double gflops = (flops * 1.0e-9) / (milliseconds / 1000.0);第三部分:完整的最小示例
下面是一个可直接运行的完整示例,包含 CPU 参考实现用于验证:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
#define M 2 // A 的行数,C 的行数
#define N 3 // B 的列数,C 的列数
#define K 4 // A 的列数,B 的行数
// CPU 参考实现
void cpu_gemm(float *C, const float *A, const float *B) {
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
float sum = 0;
for (int l = 0; l < K; l++) {
sum += A[i * K + l] * B[l * N + j];
}
C[i * N + j] = sum;
}
}
}
int main() {
// 1. 准备数据(行主序)
float h_A[M*K] = {1, 2, 3, 4,
5, 6, 7, 8};
float h_B[K*N] = {1, 2, 3,
4, 5, 6,
7, 8, 9,
10, 11, 12};
float h_C_cpu[M*N] = {0};
float h_C_gpu[M*N] = {0};
// 2. CPU 计算作为参考
cpu_gemm(h_C_cpu, h_A, h_B);
printf("Expected Result (CPU):\n");
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
printf("%8.0f ", h_C_cpu[i*N+j]);
}
printf("\n");
}
// 3. 初始化 CUBLAS
cublasHandle_t handle;
cublasCreate(&handle);
// 4. 分配 GPU 内存
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, M*K*sizeof(float));
cudaMalloc(&d_B, K*N*sizeof(float));
cudaMalloc(&d_C, M*N*sizeof(float));
// 5. 拷贝数据到 GPU
cudaMemcpy(d_A, h_A, M*K*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, K*N*sizeof(float), cudaMemcpyHostToDevice);
// 6. 调用 cublasSgemm(使用调换技巧)
float alpha = 1.0f, beta = 0.0f;
cublasSgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N,
N, M, K, // 注意:调换了 M 和 N
&alpha,
d_B, N, // 注意:先传 B
d_A, K, // 注意:后传 A
&beta,
d_C, N);
// 7. 拷贝结果回主机
cudaMemcpy(h_C_gpu, d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
// 8. 打印 GPU 结果
printf("\nGPU Result (CUBLAS):\n");
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
printf("%8.0f ", h_C_gpu[i*N+j]);
}
printf("\n");
}
// 9. 验证结果
bool pass = true;
for (int i = 0; i < M*N; i++) {
if (abs(h_C_cpu[i] - h_C_gpu[i]) > 1e-5) {
pass = false;
break;
}
}
printf("\nResult: %s\n", pass ? "PASS" : "FAIL");
// 10. 清理资源
cublasDestroy(handle);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}预期输出:
Expected Result (CPU):
70 80 90
158 184 210
GPU Result (CUBLAS):
70 80 90
158 184 210
Result: PASS总结与最佳实践
关键要点
-
cublasSgemm 完全在 GPU 上执行,是高度优化的单精度矩阵乘法实现
-
核心难点:cuBLAS 的列主序存储与 C/C++ 的行主序差异
-
解决方案:使用"调换技巧"
- 调换 m 和 n 参数
- 调换 A 和 B 的传入顺序
-
性能测量:使用 CUDA Events 而非 CPU 计时器
-
错误检查 :始终使用
checkCudaErrors()宏检查 CUDA 调用
常见错误避免
| 错误 | 后果 | 正确做法 |
|---|---|---|
| 直接使用 M,N,K 原值 | 结果矩阵维度错误 | 调换 m 和 n |
| 按 A,B 顺序传入 | 结果数值错误 | 调换 A 和 B |
| 传递 alpha, beta 值而非指针 | 编译错误或未定义行为 | 传递地址 |
| 使用 CPU 计时器 | 计时包含 CPU-GPU 同步开销 | 使用 CUDA Events |
进阶提示
- 转置支持 :可通过
transa/transb参数让 CUBLAS 自动转置输入矩阵 - 批量乘法 :使用
cublasSgemmBatched可高效计算大批量小矩阵乘法 - 混合精度 :cuBLAS 还提供
cublasHgemm(半精度)、cublasDgemm(双精度)等变体
这个示例展示了如何在实际应用中正确使用 CUBLAS 库进行高性能矩阵乘法,是学习 GPU 科学计算的良好起点。