ROS2,作为目前最热门的机器人控制库与程序,主要用于机器人控制,高效开发机器人。其具备多平台的特性,可以在linux,windows,macOS甚至裸机上开发使用。但是在实际应用中,主要还是在Linux上进行开发学习。因此,本文章主要为讲述如何在Linux(Server)版本上开发使用Linux。
ROS2安装
ROS2稳定更新的版本主要依于ubantu 22.04的版本。ROS2主要有几个版本,但是我们一般使用humble即可。humble中两个大一点的分类,一个是服务器版(base),很小,很符合实际工作的需求,但是没有相关例程以及gui;另外一个是桌面版(desktop),很大,有很多例程,也可以三维仿真,但是实际上如果真的部署在机器人上,还是推荐base版,边缘设备资源紧张,能省则省。
linux虚拟机的安装与使用,我便不再赘述。如果是完全的小白的话,可以参考下面古月居的视频,因为我是基于服务器直接开发,因此linux系统我是选择Server版+ssh连接vscode的方法进行开发。至于ROS2的安装,推荐直接输入下面那行命令,那是一个大佬做的,可以全自动安装ROS2,并且选择你需要的版本。ssh的连接方向也是如下。具体的vscode连接方法,也可以csdn或者b站看看。https://www.bilibili.com/video/BV16B4y1Q7jQ/?spm_id_from=333.788.videopod.episodes&vd_source=b2dfaa7240df89acf5bf3293ca9945eb
wget http://fishros.com/install -O fishros && . fishros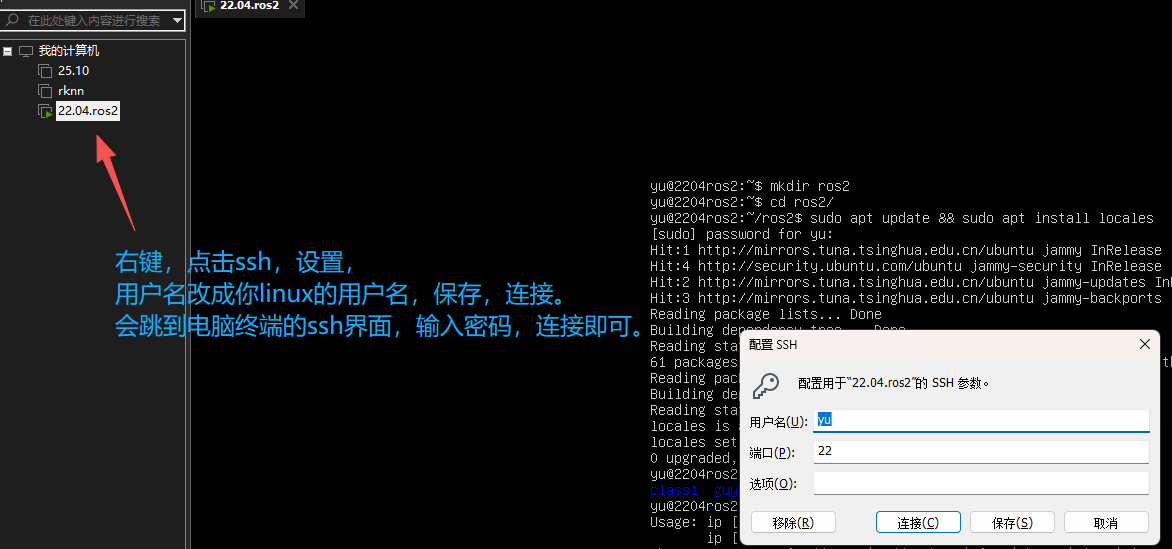
ROS2基础指令
在安装好ROS2以后,我们就可以开始初步的学习ROS2了。ROS2最大的优点就是高效的封装以及规则化。他的使用很有章法。我们直接以2个命令作为起手式。如果是desktop版本可以直接输入命令,但是如果是base,请先输入以下命令,安装例程包
sudo apt update && sudo apt install ros-humble-demo-nodes-cpp ros-humble-demo-nodes-py -yros2运行的命令格式如下。我们首先开一个终端,用于发送数据(publish),为了观察结果,我们再开一个终端,用于收取数据(subscribe)。当我们两个程序同时开始运行的时候,可以看到终端1一直在发送数据,终端2一直在接收终端1发送而来的数据。这,就是ros2最基础的两个运行程序。主要是为了表现ros2的DDS机制。如果两个同存在于一个主机上,那他便使用共享内存进行通信;如果不在一个主机上,那便使用socket进行通信。
ros2 run <功能包名> <可执行文件名>
ros2 run demo_nodes_cpp talker
# 注意:每个新开的终端窗口,第一步一定要先刷新 ROS 2 环境变量
source /opt/ros/humble/setup.bash
# 运行听众
ros2 run demo_nodes_py listener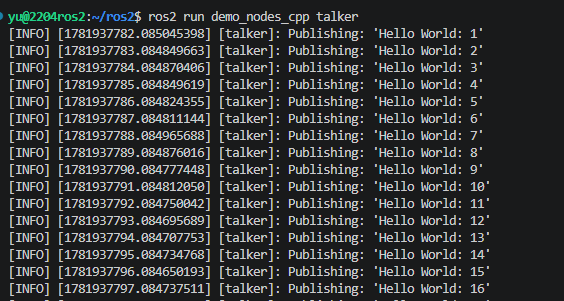
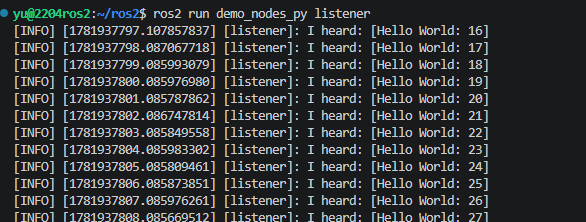
基础通道监测,工作空间与编译
大部分视频教学者此时应该要开始玩小乌龟了,但是由于我的linux是纯服务器,没有桌面,因此qt(qt是小乌龟的实现方法,主要也是由cpp编写)也无法显示在桌面上。因此接下来我们先简单介绍一下通道检测,接着直接进入工作空间的设计。
通道监测
我们在上面运行talker和listener的时候,谈到了他们进行通信。其实他们更本质的,是使用话题(topic)进行通信。DDS会对所有的节点进行监控,比如现在有个节点1加入了话题a,并且往外抛数据,那么DDS就会监视,系统中还有没有其他的节点也加入了这个通道,并且想接受数据。如果有,就会把节点1的数据传感那个需要数据的节点。然后,接下来的三条指令就是对话题的监控,是重要的debug手段。当我们运行这三条指令后,就可以监视到一些topic的信息。
ros2 topic list # 查看当前系统有哪些硬件/算法通道
ros2 topic info /chatter # 看看这个通道是谁在发,谁在收
ros2 topic echo /chatter # 核心!亲眼看着终端里裸数据高频刷新的样子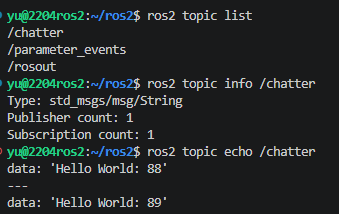
工作空间与编译
工作空间是ROS2的重要概念(其实也是任何编码项目的工作概念),我们不能把所有的项目全部在一个文件夹里面写完, 这样项目即混乱,也不高效。因此,我们需要分区治理。
工作空间就是为了解决这个问题而存在,一个高效合理的工作空间应该包含以下几个文件夹:
我们倒也没必要一个一个文件夹的去mkdir,最主要的还是src这个文件夹。我们创建好src文件夹后,可以直接自动生成一个C++的功能包。接下来,我先解析一下这个功能包的几个参数
自动生成一个 C++ 的功能包 (指定依赖库为 rclcpp 和 std_msgs)
ros2 pkg create --build-type ament_cmake --dependencies rclcpp std_msgs my_robot_sdkros2 pkg create:该命令意为:帮我创造(create)一个全新的 ROS 2 功能包(pkg)。
my_robot_sdk:这就是你给这个项目起的名字(项目文件夹的名字)。
--build-type ament_cmake :制定这个项目的"构建技术路线",ament_cmake翻译过来就是:"这是一个正儿八经的 C++ 项目,底层请用 CMake 编译器来管我。" (如果是 Python 项目,这里就会变成build-type ament_python)。
--dependencies rclcpp std_msgs: 这是整行命令最爽的地方------自动抱大腿(指定依赖库)。 它告诉系统:"我的项目接下来要用到 ROS 2 的 C++ 核心库(rclcpp)和标准机器人消息库(std_msgs)。
当我们运行好那条命令以后,系统便会自动帮我们生成CMakeList.txt,并且帮我们写好前几十行,其中还包含了两个库在 Linux 系统里的绝对路径了。第二个是include,里面存放该项目需要的一些头文件。第三个是一个.xml文件,是项目说明书(记录作者、许可证和依赖)。最后一个是src,放源代码,我们在这个地方放cpp/cc文件即可。
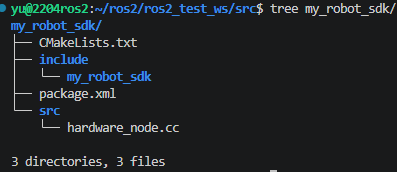
编译部分,我们需要回到上一个目录,即理应放着4个文件夹的那个目录。此时,我们在这个目录输入以下的命令,便会快速的编译项目,创建我们需要的四个文件夹,并且根据src的需求与结果(即CMake中的规定内容),往四个文件夹里面写入要求的文件。
colcon build第一个节点程序
光说不练假把式,纯讲节点话题这些知识没意思,我们来一段真代码学习一下。
这是一个比较初步的程序,主要目的是每个20豪秒往通道里面扔一个Motor_1 Position: 1.57 rad的字符串,用于测试。我们从上往下讲起,
首先,引入一众ros2的头文件,这些都是ros2比较常用的头文件。
第二,我们在私有空间里面写了两个参数,我就只解释publisher_前面那串类型的含义了。首先,rclcpp::是命名空间,Publisher<std_msgs::msg::String>是一个类模板,里面放着的是通信中流淌着什么类型的数据,::SharedPtr是经过ROS2封装过的智能指针。
第三,创建我们自己的类,继承库里面Node节点,根据cpp的语法,我们需要在初始化列表里面实例化基类,因为ROS2规定,每一个独立运行的节点,都有自己的唯一名,因此我们传一个名字给他。
第四,创建了一个通信通道,这个通道叫"/motor_states",使用基类的一个函数进行创建,10代表10 代表底层通信的队列深度即缓冲区大小。
第五,写了一个计时器,每隔 20ms,系统内核会自动回调一次 timer_callback 函数。这里还有一个特殊的用法,如果我们把this改为另外一个节点(甚至不需要是节点,是个对象就行)的指针,那么每隔20秒,系统就会去调用那个节点的时间回调函数,这种属于跨对象绑定,实现了解耦。
第六,实现了一个时间回调函数,每隔20ms,把message往通道里面发布,需要注意的是,这里的string不是原生C++的string类,他是经过封装以后的。
第七,就是main函数了,首先进行初始化,把命令行的参数数量和参数列表给他,spin函数就是要一个死循环,当主函数执行到spin时,主线程就会在这里"卡住"死循环。它在底层会源源不断地检查:时间有没有到 20ms?有没有收到别的进程传过来的网络数据包?如果发现时间到了,它就会立刻在内核里回调(Callback)你写的时间回调 函数。如果没有它,主函数main瞬间就会从上往下执行完return 0退出,程序就直接结束了。接着,shutdown函数,全系统级析构和清理扫干净屋子。
#include "rclcpp/rclcpp.hpp"
#include "std_msgs/msg/string.hpp"
#include <chrono>
class RobotHardwareNode : public rclcpp::Node {
public:
RobotHardwareNode() : Node("hardware_node") {
// 1. 创建通信通道
publisher_ = this->create_publisher<std_msgs::msg::String>("/motor_states", 10);
timer_ = this->create_wall_timer(
std::chrono::milliseconds(20),
[this]() { this->timer_callback(); }
);
}
private:
void timer_callback() {
auto message = std_msgs::msg::String();
message.data = "Motor_1 Position: 1.57 rad";
publisher_->publish(message);
}
rclcpp::Publisher<std_msgs::msg::String>::SharedPtr publisher_;
rclcpp::TimerBase::SharedPtr timer_;
};
int main(int argc, char * argv[]) {
rclcpp::init(argc, argv);
// 确保类名大小写严格匹配:RobotHardwareNode
rclcpp::spin(std::make_shared<RobotHardwareNode>());
rclcpp::shutdown();
return 0;
}多线程+互斥锁程序
写完了上面那个略微初级的,现在我们来写一个plus版本的。在真正的开发中,基本上不可能是单线程工作,并且在机器人sdk开发中,假设我们是想做到下面图片中红色的部分,我们就有有可能要实现上位机的AI低频率数据处理+机器人的超高频率电机数据。因此,我们这次就来写一个类似的demo。

头文件
这次的头文件主要是加入了两个新的,一个是互斥锁的头文件,一个是线程头文件。
#include "rclcpp/rclcpp.hpp"
#include "std_msgs/msg/string.hpp"
#include <chrono>
#include <mutex> // 引入 Linux 互斥锁
#include <thread>类的定义
首先,和之前一样,继承ROS2官方基类。然后我们先来看一下这个对象声明。前面两个,是回调组智能指针声明,主要是用于保证两个任务被拆分到两个不同的cpu上进行工作。如果我们不设置这个回调组声明,他们会被默认分到同一个组。那么由于ros2的铁律要求:属于同一个回调组内部的各个回调函数,在同一时刻绝对不允许被两个不同的线程并发执行。就会导致任务A(1000HZ)会被任务B(20HZ)无限卡住。假设任务A是电机信息的读取,那就是完全的延迟。因此,我们需要进行划分。然后后面的这个时间基类也说一下,反正就是记住,ROS2中,不管你是想定分钟级别,还是毫秒级别,都得用这个,这是铁律。
class MultiThreadedSdkNode : public rclcpp::Node {
private:
// 临界资源变量与锁
double shared_motor_position_ = 0.0;
std::mutex data_mutex_;
// ROS 2 高级控制对象声明
rclcpp::CallbackGroup::SharedPtr hardware_group_;
rclcpp::CallbackGroup::SharedPtr pub_group_;
rclcpp::TimerBase::SharedPtr hardware_timer_;
rclcpp::TimerBase::SharedPtr pub_timer_;
rclcpp::Publisher<std_msgs::msg::String>::SharedPtr publisher_;
};构造函数
该构造函数也是开局先继承基类,然后命名一下。接着就是创建互斥回调组,其形象比喻就是创建两个完全的房间,随后我们把定时器A绑定回调组A,定时器B绑定回调组B,那么当Executor在观察线程池的时候,当1ms 和 20ms 的时间同时到了,线程 1 准备去执行硬件循环。大管家一看,它绑了hardware_group_,另外一个线程绑了另外一个,就认为他们不互冲,就让他们同时开始干活。其他的就与初版程序无异了。
MultiThreadedSdkNode() : Node("multi_threaded_sdk_node") {
// 1. 创建两个独立的互斥回调组
hardware_group_ = this->create_callback_group(rclcpp::CallbackGroupType::MutuallyExclusive);
pub_group_ = this->create_callback_group(rclcpp::CallbackGroupType::MutuallyExclusive);
// 指定发布通道
publisher_ = this->create_publisher<std_msgs::msg::String>("/motor_states", 10);
// 2. 跨版本黄金写法:直接在第 4 个参数位把包厢(callback_group)强行灌进去
hardware_timer_ = this->create_wall_timer(
std::chrono::milliseconds(1),
[this]() { this->hardware_io_loop(); },
hardware_group_
);
// 3. 同理,低频发布定时器也直接灌入对应的包厢
pub_timer_ = this->create_wall_timer(
std::chrono::milliseconds(20),
[this]() { this->ros_publish_loop(); },
pub_group_
);
}并发线程程序
里面包含两个线程的程序,其实和上面的时间回调函数差不多。其中比较特色的就是lock_guard了。有人会问,既然我们都把两个线程塞到两个核心里面去工作了,又何必使用cpp的线程互斥呢?非也,虽然他们在不同核心工作了,但他们有可能访问同一片内存呀?同时访问那可不行,那可就竞争了。lock_guard这是一个线程智能锁,具有RAII特性,主要是就是防止竞争。他会在离开碰到的第一个闭合性大括号时自动析构。由此我们还可以引出,如果我们需要,我们可以在某个时候,快速读取某个传感器的信息,获得内容以后,快速析构。主打一个资源节约,毕竟嵌入式工控机的内存线程资源非常宝贵。
// 【并发线程 A】:1000Hz 疯狂读取真机硬件数据,并修改全局共享资源
void hardware_io_loop() {
// 模拟从物理总线读回来的编码器关节数据
static double mock_encoder_val = 0.0;
mock_encoder_val += 0.01;
// 【标志位 Plus 现场上锁】罩住临界区,防止高低频数据撕裂
{
std::lock_guard<std::mutex> lock(data_mutex_);
shared_motor_position_ = mock_encoder_val;
} // 离开这个大括号,lock 自动析构解锁,极为安全
}
// 【并发线程 B】:50Hz 慢速把最新的硬件数据打包,通过 ROS 2 通道泵送给上层 AI 策略
void ros_publish_loop() {
double safe_position = 0.0;
// 快速上锁拷贝,拷贝完立刻解锁,绝对不耽误 1ms 极其敏感的硬件总线
{
std::lock_guard<std::mutex> lock(data_mutex_);
safe_position = shared_motor_position_;
}
// 把安全拿出来的局部变量打包发布
auto message = std_msgs::msg::String();
message.data = "Secured Position: " + std::to_string(safe_position) + " rad";
publisher_->publish(message);
}
{
// 用大括号开辟一个"临时局部沙盒"
std::shared_ptr<BigDataPacket> temp_packet = std::make_shared<BigDataPacket>();
temp_packet->load_from_sensor();
process_data(temp_packet);
} // 👈 碰到了右大括号!temp_packet 在这里瞬间被系统强行析构,内存立刻释放!主函数
老样子,先初始化。然后设置一个多线程执行器,类似于做个了线程池管家。然后实例化一个MultiThreadedSdkNode对象,使用std::make_shared赋予这个节点RAII的特性,使它在底层把对象的创建和 C++ 标准库的引用计数智能指针死死绑定在一起。然后把这个node加入executor管理的进程池里面,启动进程池,开始干活,因为特殊原因终止以后,就全局析构和处理。
int main(int argc, char * argv[]) {
rclcpp::init(argc, argv);
// 【核心操作 4】:创建多线程执行器(线程池大管家)
rclcpp::executors::MultiThreadedExecutor executor;
auto node = std::make_shared<MultiThreadedSdkNode>();
executor.add_node(node);
// 启动线程池,开始真正的并发轮询
executor.spin();
rclcpp::shutdown();
return 0;
}