一.为什么需要向量嵌入?
传统关系型数据库依托关键词匹配、字符比对实现数据检索,擅长完成字面精准匹配 与模糊字符检索,日常通过WHERE title='气候变化'等值精准查询、LIKE "%气候%"通配模糊查询等语句,能够快速匹配到文本中含有相同字词、句式高度一致的数据内容。
但在实际业务与智能检索场景中,用户日常提出的自然语言问题大多脱离字面词汇束缚,偏向语义意图层面的理解与匹配,不再局限于文字表面是否重合,即便查询语句和目标文档用词不同、句式相异、表达方式存在差异,只要核心含义、表达主旨相近,就应当被精准检索出来,这也是传统关键词检索模式难以高效满足的核心痛点。如下表所示:
| 用户查询 | 期望匹配文档(标题) | 传统关键词能否命中 |
|---|---|---|
| 什么是健康饮食与生活习惯 | 健康饮食与生活习惯建议 | 部分命中(需包含相同词) |
| 向量数据库怎么用 | Milvus 向量数据库使用教程 | 难以命中(词面不同) |
| 全球变暖对生态的影响 | 气候变化对生态环境的影响 | 难以命中(同义表达) |
向量嵌入是将文本映射到高维连续向量空间,使语义相近的文本在空间中的距离更近。配合向量数据库即可实现语义检索。整体流程如下图所示:

二.文本向量化的核心原理
(1)从字符到向量的流水线
文本向量化不是简单的查表,而是一条深度学习的流水线,如下图所示:
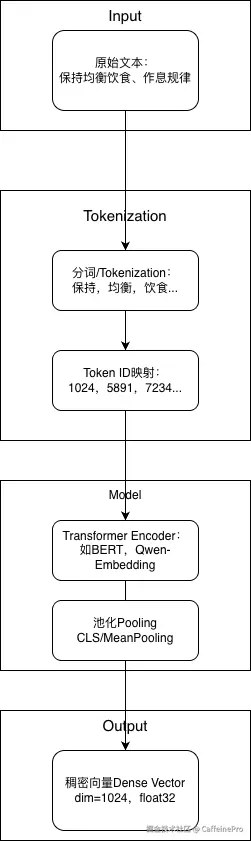
如图所示,首先对原始文本执行分词处理,把完整语句拆解为模型可识别的子词单元,再将分词结果映射为对应的数字标识。随后依托Transformer类预训练嵌入模型,为每一个子词生成初始向量表征,并结合上下文语境完成语义信息建模,挖掘词句之间的语义关联。
完成深层特征编码后,通过CLS池化、均值池化等方式,把不定长的序列向量压缩整合为固定维度的全局文本向量,得到标准稠密向量结果。最后可根据检索需求选择进行L2归一化处理,统一向量模长,让向量能够适配余弦相似度、内积等主流相似度计算方式,为后续向量库存储与语义匹配检索做准备。
(2)稠密向量与稀疏向量
这里用表格来进行对比:
| 类型 | 维度特点 | 典型来源 | 语义能力 | 关键词能力 |
|---|---|---|---|---|
| 稠密向量 Dense | 固定低维(128~4096),几乎全部维度非零 | Transformer Embedding 模型 | 强(同义、泛化) | 弱 |
| 稀疏向量 Sparse | 超高维(词汇表大小),仅少量维度非零 | TF-IDF、BM25 | 弱 | 强(精确词匹配) |
在文本向量表征体系中,稠密向量与稀疏向量是两类应用场景截然不同的向量形式,二者在维度结构、生成方式、语义表达能力上存在明显差异。
其中稠密向量维度数量固定,取值范围集中,绝大多数维度均具备有效数值,主要依靠大语言类嵌入模型训练生成,擅长挖掘文本深层语义,能够精准识别语句同义替换、语义引申等抽象表达,但对精准关键词的匹配把控能力较弱。
稀疏向量整体维度规模庞大,与语料词汇表量级保持一致,仅极少数维度存在有效权重数值,多由传统统计检索算法生成,在关键词精准命中、字词匹配场景中表现优异,却难以完成深层次语义理解与泛化推理。
在实际RAG检索系统搭建过程中,通常将两种向量形式结合使用,兼顾语义理解能力与关键词检索优势,补齐单一向量检索存在的功能短板。
(3)嵌入空间的直觉
训练良好的嵌入模型满足:
1.语义相近,例如:"国王"与"皇帝"向量夹角小。
2.语义对立,例如:"健康"与"疾病"向量夹角大。
3.类比管理,例如:vec("国王")-vec("男人")+vec("女人")≈vec("女王")(经典 Word2Vec现象,现代模型仍保留类似结构)。
维度选择存在权衡:
| 维度 | 优点 | 缺点 |
|---|---|---|
| 256~512 | 存储小、检索快 | 语义表达能力有限 |
| 1024(常用) | 平衡精度与性能 | 主流选择 |
| 2048~4096 | 细粒度语义区分 | 存储与计算成本高 |
三.相似度度量与向量空间
向量入库与检索前,必须约定距离/相似度度量方式。
(1)常用度量公式与适应场景表
| 度量名称 | 公式 | Milvus metric_type | 适用场景 | ||||
|---|---|---|---|---|---|---|---|
| 欧氏距离L2 | ( d = \sqrt{\sum_i (a_i - b_i)^2} ) | L2 |
未归一化向量 | ||||
| 内积IP | ( s = \sum_i a_i \cdot b_i ) | IP |
L2 归一化后等价于余弦 | ||||
| 余弦相似度 | (\cos = \frac{a \cdot b}{ | a | b | } ) | COSINE |
文本Embedding最常用 | |
| BM25 | 基于词频的稀疏打分 | BM25 |
稀疏向量/全文检索 |
需要注意的是Milvus中distance字段的含义因metric而异,L2越小越相似,IP/COSINE/BM25越大越相似。后处理阈值需与metric对齐。
(2)余弦相似度的几何直觉
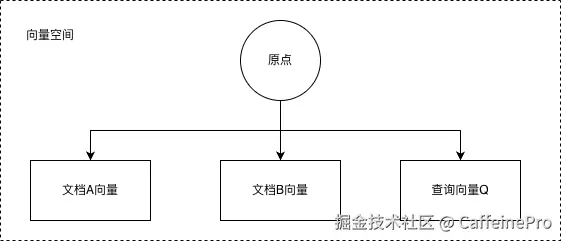
在高维向量空间内,所有文本向量均以原点作为起始点进行分布排布,查询向量与各类文档向量形成不同夹角。
向量之间的夹角大小直接决定语义相似度高低,夹角越小代表余弦相似度数值越高,对应文本语义契合度也就越高。
将所有向量完成L2归一化处理后,内积计算结果和余弦相似度的排序逻辑完全统一,在实际项目开发中,开发人员大多直接采用内积运算完成相似度判定,以此简化运算流程、降低检索计算开销。
如下图所示:
四.文本向量化的工程实践
(1)单文本向量化与批量向量化
实际工程中需处理API限流、批量大小、异常重试等问题。embedding_demo.py演示完整流程:
python
from embedding_utils import get_embedding, get_embeddings
# 单条文本向量化
query = "什么是健康饮食与生活习惯"
query_vector = get_embedding(query)
print(f"向量维度: {len(query_vector)}") # 1024
# 批量向量化自动按BATCH_MAX_SIZE分批
texts = [
"人工智能技术正在改变医疗行业",
"Python 是一门简洁易懂的编程语言",
"全球气候变暖导致极端天气增多",
]
vectors = get_embeddings(texts)
print(f"批量数量: {len(vectors)}, 单条维度: {len(vectors[0])}")(2)向量化工具函数设计要点
文本批量向量化工具函数在开发设计时,充分结合接口调用规范与项目安全规范制定多项优化策略。采用批量调用接口的方式,能够有效减少接口请求频次,大幅降低接口响应延迟与调用成本。
同时按照接口单次最大请求数量对文本数据进行分批切片处理,严格遵循平台接口传入条数限制,避免请求报错。
函数统一设置向量维度入参,保障存入向量数据库同一集合内的所有向量维度保持统一,满足数据库存储与检索的基础要求。在密钥管理层面,将接口密钥存放于环境变量中调用,摒弃代码硬编码写法,从源头规避密钥泄露风险,提升项目整体安全性与可维护性。
可以参考下表:
| 设计要点 | 原因 |
|---|---|
| 批量接口 | 减少API调用次数,降低延迟与费用 |
| 分批切片 | 遵守APIbatch_size上限 |
| 统一维度参数 | 同一Collection内所有向量维度必须一致 |
| 环境变量存API Key | 避免密钥硬编码泄露 |
(3)文档入库前的数据装配
将业务字段与向量字段组装为Milvus可接受的记录结构,示例代码:
python
import json
with open("sample_data.json") as f:
data = json.load(f)
texts = [item["content"] for item in data]
embeddings = get_embeddings(texts)
for item, vector in zip(data, embeddings):
item["vector"] = vector # 装配稠密向量字段
client.insert(collection_name="demo_collection", data=data)其中sample_data.json记录结构举例:
json
[ { "id": 1, "title": "健康饮食与生活习惯指南", "content": "日常保持均衡饮食,多食用蔬菜水果,减少高油高盐食物摄入,同时坚持规律作息与适度运动,养成良好生活方式。", "source": "生活健康科普文库", "vector":[0.021, 0.135, -0.087, 0.204, 0.056, -0.112, 0.093, -0.037] },五.Milvus数据库架构概览
Milvus是专为海量高维向量设计的开源分布式数据库,核心解决存储、索引、近似最近邻(ANN)检索。
(1)整体架构
这里不进行配图了,简单描述一下,想具体了解可以看看官方文档。
Milvus是面向海量高维向量数据研发的开源分布式向量数据库,核心聚焦向量数据持久化存储、高效索引构建以及近似最近邻检索三大核心能力。
整体采用分层式架构设计,自上而下依次为客户端层、接入层、协调层、工作节点层与底层存储层。
客户端可通过官方SDK或REST接口发起各类业务请求,请求统一经由Proxy接入层完成路由转发与身份校验;再由各类协调器统一统筹管理元数据、数据分片、查询任务与索引任务,合理分发调度;最终交由数据节点、查询节点、索引节点完成数据写入、向量检索、索引生成等实际业务操作,所有数据、元数据与增量日志则分别依托对象存储、etcd与消息队列完成持久化,保障集群稳定运行与数据可靠存储。
(2)单机模式与分布式模式
Milvus主要分为单机部署与集群部署两种运行模式,适配不同使用场景。
单机模式可通过Docker Compose快速搭建,适合日常学习调试、项目开发测试以及小规模业务上线使用 ,本地默认通过http://localhost:19530完成连接访问。
集群模式依托Kubernetes 实现多节点分布式部署,具备强大的扩容能力与并发处理能力,能够承载亿级海量向量数据存储,支撑高并发检索业务场景,客户端通过集群代理地址建立连接。
学习阶段使用Milvus Lite 或Docker Standalone 即可,API与集群版一致。
(3)核心概念关系
在Milvus向量数据库中,数据库作为顶层逻辑容器,内部包含多个集合。
集合是存储数据的核心单元,既定义各类字段结构,也可创建检索索引,同时用于存储一条条实体数据记录。
字段是构成实体的基本单元,可针对性建立索引来加速查询,实体则对应实际存入的业务数据行,包含主键、文本字段与向量字段等核心内容,整体架构逻辑与传统关系型数据库表结构高度相似,上手学习难度较低。核心表如下图所示:
| 概念 | 类比关系型数据库 | 说明 |
|---|---|---|
| Database | Database | 逻辑命名空间隔离 |
| Collection | Table | 一组同Schema的实体 |
| Field | Column | 标量字段或向量字段 |
| Entity | Row | 一条记录 |
| Index | Index | 加速向量/标量检索 |
| Partition | Partition | Collection内逻辑分片(可选) |
六.Collection与Schema设计
(1)简单Schema
稠密向量检索,如下代码所示:
python
# 快速创建隐式Schema
client.create_collection(
collection_name="demo_collection",
dimension=1024, # 向量维度
)(2)完整Schema包括多字段与混合检索
示例代码:
python
from pymilvus import MilvusClient, DataType, Function, FunctionType
schema = MilvusClient.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=True)
schema.add_field("title", DataType.VARCHAR, max_length=512)
schema.add_field("content", DataType.VARCHAR, max_length=65535,
enable_analyzer=True, enable_match=True,
analyzer_params={"tokenizer": "standard", "filter": ["lowercase"]})
schema.add_field("sparse_vector", DataType.SPARSE_FLOAT_VECTOR)
schema.add_field("dense_vector", DataType.FLOAT_VECTOR, dim=1024)
# BM25函数:content到sparse_vector入库时自动计算
bm25_fn = Function(
name="bm25",
function_type=FunctionType.BM25,
input_field_names="content",
output_field_names="sparse_vector",
)
schema.add_function(bm25_fn)Schema字段设计参考表:
| 字段名 | 数据类型 | 索引 | 用途 |
|---|---|---|---|
id |
INT64, PK | --- | 主键,支持精确查询 |
title |
VARCHAR | --- | 展示、标量过滤 |
content |
VARCHAR + Analyzer | --- | 正文、BM25输入 |
metadata |
JSON | --- | 灵活扩展元信息 |
dense_vector |
FLOAT_VECTOR1024 | HNSW + IP | 语义检索 |
sparse_vector |
SPARSE_FLOAT_VECTOR | SPARSE_INVERTED_INDEX | 关键词检索 |
七.索引类型与检索算法
向量全量暴力扫描Flat在百万级以上不可接受,Milvus通过ANN 索引牺牲少量精度换取百倍加速。
(1)稠密向量检索对比表
| 索引类型 | 原理 | 构建速度 | 查询速度 | 内存占用 | 适用场景 |
|---|---|---|---|---|---|
| FLAT | 暴力扫描 | 无需构建 | 慢 | 低 | 小数据集、基准测试 |
| IVF_FLAT | 聚类 + 倒排 | 中 | 中 | 中 | 中等规模 |
| IVF_PQ | 聚类 + 乘积量化 | 中 | 快 | 低 | 大规模、内存敏感 |
| HNSW | 分层导航小世界图 | 慢 | 很快 | 高 | 生产首选 |
| DISKANN | 磁盘友好图索引 | 慢 | 快 | 低磁盘 | 超大规模 |
(2)稀疏向量索引
| 索引类型 | metric_type | 说明 |
|---|---|---|
| SPARSE_INVERTED_INDEX | BM25 | 倒排索引,经典全文检索 |
(3)创建索引示例
这里直接给出代码示例,这段代码用于批量配置Milvus集合索引并完成集合创建,分别为稠密向量与稀疏向量配置专属索引规则。
针对dense_vector 稠密向量字段选用主流的HNSW索引,搭配内积IP作为相似度计算方式;针对sparse_vector稀疏向量字段采用稀疏倒排索引,适配 BM25 关键词检索模式,最后结合预设数据表结构与索引参数完成向量集合一键创建,适配语义+关键词双路检索场景:
python
index_params = MilvusClient.prepare_index_params()
# 稠密向量:HNSW与内积
index_params.add_index(
field_name="dense_vector",
index_type="HNSW",
metric_type="IP",
params={"M": 16, "efConstruction": 200},
)
# 稀疏向量:倒排与BM25
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
)
client.create_collection(COLLECTION_NAME, schema=schema, index_params=index_params)HNSW索引拥有三个核心可调参数,其中M 代表图结构每层节点最大连接数量,数值越大检索精度越高,但内存占用随之上升,日常取值范围为8至64;
efConstruction 是索引构建阶段的候选检索数量,调大该参数能够提升索引整体质量,同时会拉长索引构建耗时;
ef为检索阶段候选集数量,提升该值可有效提高内容召回率,也会增加查询响应延迟,可根据业务对速度与精度的需求灵活调配。
八.检索流程:从查询到结果
(1)三种检索模式
精确查询通过指定主键ID直接定位数据,能够快速精准获取指定记录。
Milvus标量过滤依托文本字段完成关键词模糊筛选,沿用传统数据库检索逻辑,实现字面内容匹配。
Milvus语义检索则传入向量化后的查询向量,借助 ANN 近似最近邻算法完成相似度比对,突破文字表层限制,实现基于语义含义的智能检索。
(2)语义检索完整代码
导入向量化工具函数,将用户输入的自然语言查询语句转为对应的语义向量。接着调用Milvus检索接口,指定目标向量集合、传入查询向量,设置返回结果数量并声明需要展示的文本字段。接口执行ANN近似近邻检索后返回匹配结果,结果为双层列表结构,内层每条结果包含数据主键、相似度分值与完整实体信息。最后遍历检索结果,格式化输出相似度数值与文档标题,直观展示语义匹配度最高的相关内容。实现代码示例如下:
python
from embedding_utils import get_embedding
query = "什么是健康饮食与生活习惯"
query_vector = get_embedding(query)
hits = client.search(
collection_name="demo_collection",
data=[query_vector],
limit=5,
output_fields=["title", "content"],
)
# hits结构: List[List[Hit]],每个Hit含id, distance, entity
for hit in hits[0]:
print(f"距离={hit['distance']:.4f} | {hit['entity']['title']}")(3)后处理,阈值过滤与Top-K截断
模型返回的Top-K未必都足够相关,工程上常加阈值,例如:
python
TOP_K = 3
THRESHOLD = 0.3 # IP/COSINE越大越相似
final_results = []
for item in hits[0]:
if item["distance"] >= THRESHOLD and len(final_results) < TOP_K:
final_results.append(item)
else:
break # 假设结果按distance降序,低分直接终止后处理策略与作用如下表所示:
| 后处理策略 | 作用 |
|---|---|
| 距离阈值 | 过滤低相关结果,减少噪声 |
| Top-K 截断 | 控制上下文长度(RAG 场景) |
| 重排序 Rerank | 用 Cross-Encoder 二次精排(可选) |
(4)检索链路时序
用户向业务应用发起自然语言提问,应用先调用嵌入服务接口,将文本内容转换为固定维度的查询向量。
随后携带向量数据向Milvus向量数据库发起检索请求,数据库调用底层HNSW索引执行近似最近邻遍历搜索,快速筛选出相似度靠前的候选数据并计算匹配分值。
数据库将携带业务字段的检索结果回传给应用端,应用再通过相似度阈值筛选、结果重排序等方式完成二次优化,剔除低质量无关内容,最后整理规整后将精准的最终结果反馈给用户。
整体时序图如下图所示:
九.混合检索,稠密与稀疏
单一稠密检索可能漏掉精确关键词 ;
单一BM25无法理解同义表达。混合检索(Hybrid Search)融合两者优势。
(1)混合架构与代码示意
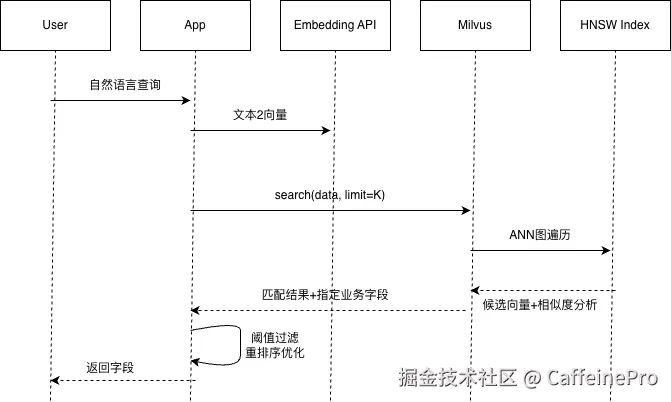
混合检索同时开启两条检索链路,用户查询文本一方面通过嵌入模型生成稠密向量,依靠 HNSW 索引完成语义层面检索。
另一方面借助BM25算法生成稀疏向量,利用倒排索引实现关键词精准匹配。两路检索结果汇总后,通过RRF倒数排名融合或加权打分的方式统一排序,综合语义相似度与关键词匹配度,筛选出相关性最优的Top-K结果输出,兼顾语义理解与精准词条匹配能力,示意图如下图所示。
 下面是一段混合检索到示例代码:
下面是一段混合检索到示例代码:
python
from pymilvus import AnnSearchRequest, RRFRanker
query = "什么是健康饮食与生活习惯?"
sparse_request = AnnSearchRequest(
data=[query],
anns_field="sparse_vector",
param={"metric_type": "BM25"},
limit=5,
)
dense_request = AnnSearchRequest(
data=[get_embedding(query)],
anns_field="dense_vector",
param={"metric_type": "IP"},
limit=5,
)
results = client.hybrid_search(
collection_name="demo_hybrid_collection",
reqs=[sparse_request, dense_request],
ranker=RRFRanker(), # Reciprocal Rank Fusion
limit=5,
output_fields=["title", "content"],
)(2)融合策略对比
常用的融合策略与对应的优劣分析如下表所示:
| 融合算法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| RRF | 按排名倒数加权求和 | 无需调参、鲁棒 | 无法强调某一路 |
| Weighted | 加权合并两路分数 | 可自定义权重 | 需调参 |
| Rerank | Cross-Encoder重排 | 精度最高 | 延迟大、成本高 |
十.总结
本文梳理了向量嵌入技术与Milvus向量数据库的完整知识体系,从传统检索方式存在的语义匹配短板出发,逐层讲解文本向量化的底层流程、向量分类差异与空间分布逻辑,清晰阐明各类相似度计算方式的适用场景与使用规范。同时结合实际开发场景,落地讲解文本批量向量化、数据入库装配等工程化实操方案,打通从原始文本到标准向量数据的全流程处理流程。
剖析Milvus分层架构、部署模式与核心数据概念,详细介绍集合结构设计、主流向量索引选型规则与参数调优思路,完整演示单一路径语义检索与稠密稀疏混合检索的实现方式,并对比多种结果融合策略的优劣。整体内容兼顾理论原理与项目实战,既理清了向量语义检索的核心逻辑,也提供了可直接复用的代码方案与落地规范,能够为RAG知识库搭建、智能语义检索系统开发提供完整的技术参考与实践指导。