理解重定向的本质
由上一篇基础IO之后,我们知道文件描述符的本质就是数组下标。那文件描述符的分配规则是什么样子的呢?直接说结论,分配文件操作符表数组中,值最小的并且没有被使用过的fd。以这个结论为基础,我们去探讨关于重定向的本质。
cpp
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
close(1);
int fd = open("test.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
printf("fd: %d\n", fd);
printf("fd: %d\n", fd);
printf("fd: %d\n", fd);
printf("fd: %d\n", fd);
return 0;
}
请看上文的代码和运行结果,首先,test.txt的文件描述符为1,根据上文的结论,我把1给关掉了,又012就是进程启动的时候自动打开的3个文件,所以1就是分配文件操作符表数组中,值最小的并且没有被使用过的fd,因此text.txt的文件描述符为1。
接下来来看有疑惑的地方,printf不是往屏幕上打印东西吗,怎么现在屏幕上没有,跑到test.txt里了?我在打开test.txt之前先把1给关了,1是对应着上层的stdout,stdout封装了1,没关掉1对应的文件之前,1里边对应得文件应为显示器,然后现在1关掉了的意思就是把显示器文件给关了(Linux下一切皆文件),现在的1数组下标地址里存着的是test.txt的地址,也就是说对于内核来说,对于底层来说,1不再对应着显示器文件,而是对应着text.txt文件。但是上层的printf还是没变呀,什么意思,就是printf对应着stdout,它是要往stdout里输入东西的,stdout封装了1,这些都没有变,变的是1对应的文件,上层C语言又不知道底层变化了,反正就是我printf规定了就是要往stdout打印的,因此就打印到了test.txt里。
再复述一遍,OS在底层改变了1的指向,语言层不知道,语言层只知道stdout封装了1,就要往1指向的文件里写入数据,它只认数字1。重定向的本质就是更改数组特定下标内的内容。暗度陈仓。(上文只拿输出重定向举了例子,其他的重定向其实都一样,无非就是更改的数组下标不一样,比如说输入重定向那就得先close(0),要么就是文件的打开方式不一样,比如说追加重定向的打开方式就需要变成O_APPEND)。
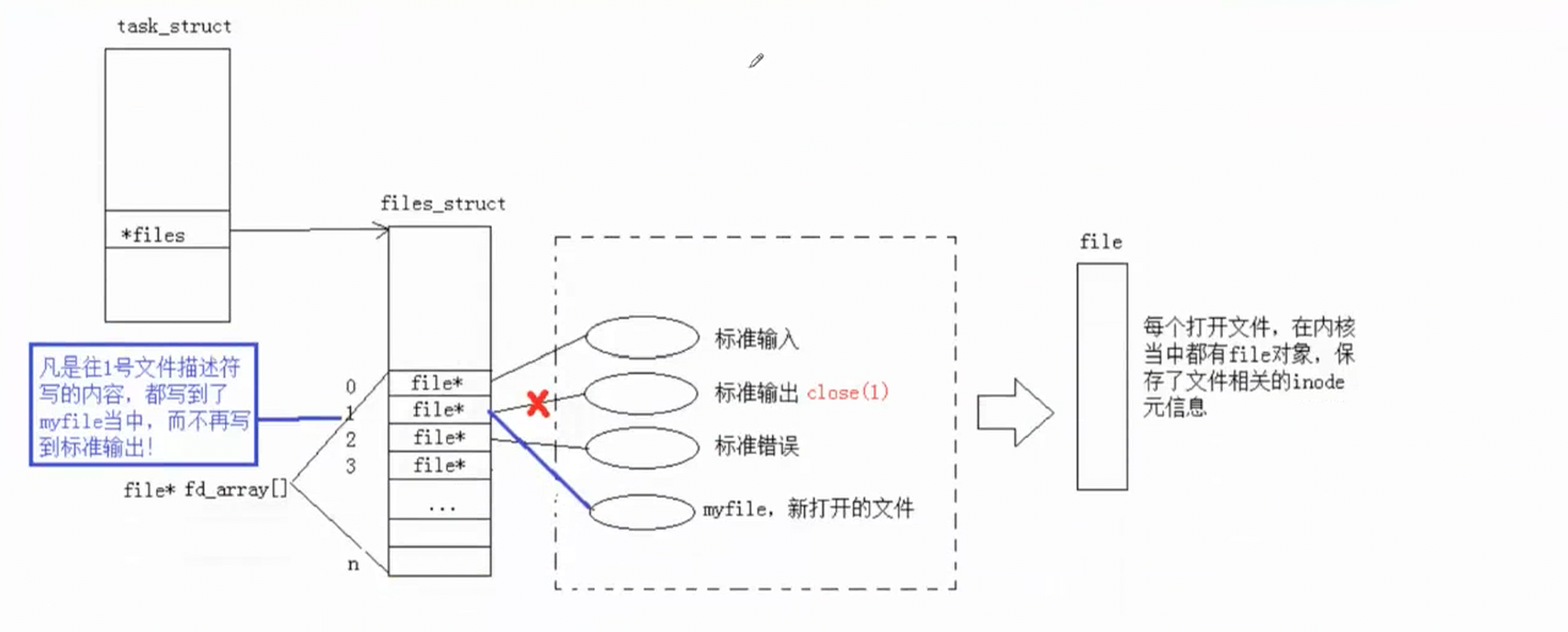
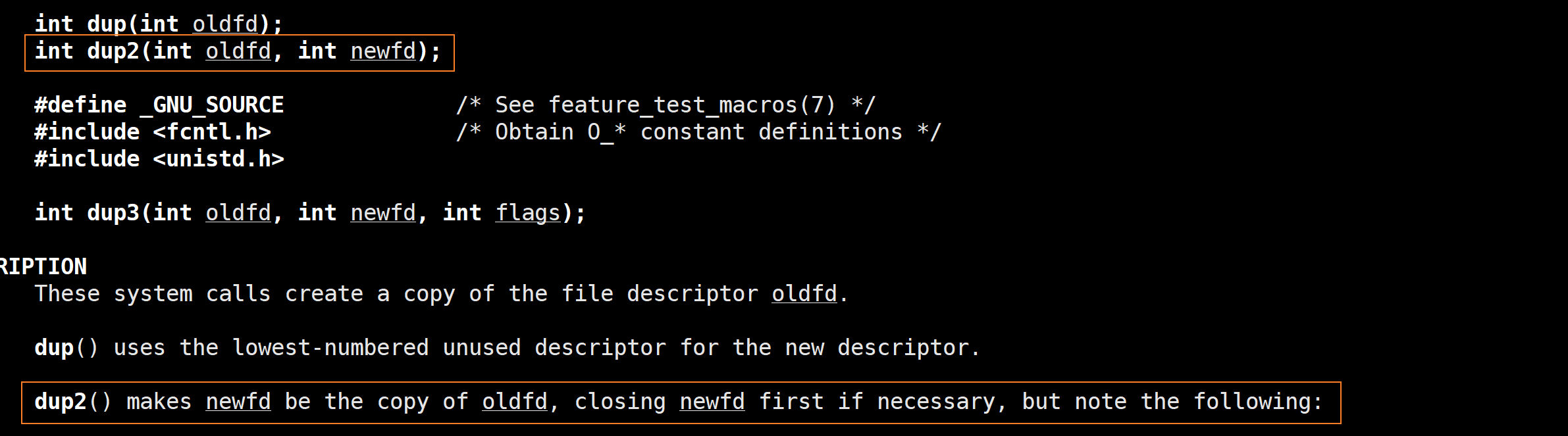
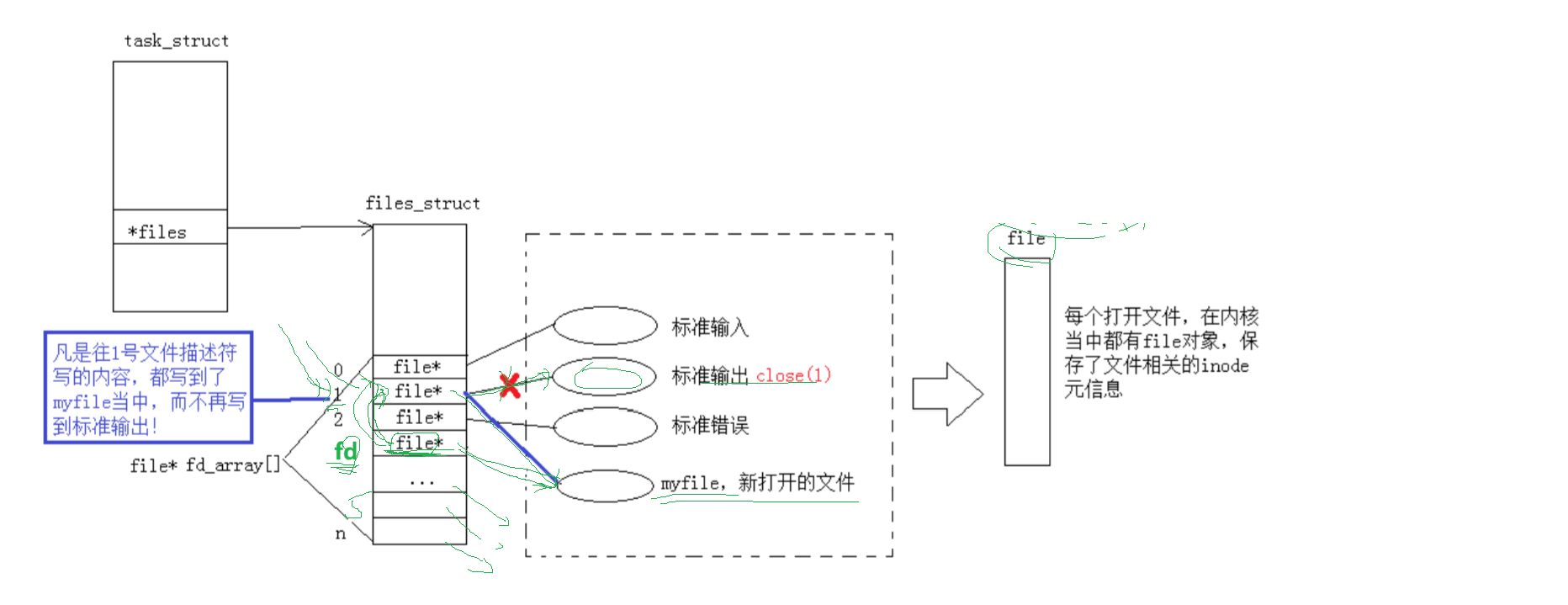
上述是我用比较淳朴简陋的方式去说明了重定向的本质,OS是有相关的系统调用的,有3个,我们只需要知道dup2就可以了。它的具体使用的意思就是将新的fd变成老的fd的拷贝(剩下的是oldfd),这里拷贝的是fd数组下标里对应的内容,而不是两个int整数。再具体看看下图你就懂了,假设我现在打开了myfile,它的文件描述符为3,然后我现在想输出重定向,我就要将该文件的地址拷贝给1号下标,实现内容覆盖,然后往1对应文件里边写入就变成了往3对应文件里边写,就实现了输出重定向。与上文那种先close(1)再打开文件,利用文件描述符的分配规则来实现输出重定向的方式相比,利用系统调用更加的灵活,我不用自己去关闭文件并且我可以在除了012这3个下标之外的其他下标之前做重定向,比如说34之间做重定向(将往4文件的输出也重定向成往3文件的输出)。最后再强调一下谁是oldfd谁是newfd,dup2之后剩下的是oldfd,你想向哪个文件做重定向,oldfd就是它的fd。
cpp
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
int fd = open("test.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
dup2(fd, 1);
const char* str = "hello world\n";
fputs(str, stdout);
fputs(str, stdout);
fputs(str, stdout);
fputs(str, stdout);
fputs(str, stdout);
fputs(str, stdout);
return 0;
}
修改自定义Shell
之前博客里写过一个自主Shell,现在我想把控制台实现重定向的方式加入进去。之前的主逻辑是打印命令行->读取用户输入->解析字符串->判断是否是内建命令并执行->不是内建交给子进程执行。而现在应该在解析字符串之前先判断一下是否支持重定向。由于篇幅限制就不搞内建命令的重定向了。
cpp
//表明重定向的信息
#define NoneRedir 0
#define OutputRedir 1
#define AppendRedir 2
#define InputRedir 3
int redir_type = NoneRedir;//存重定向的方式
char* filename = NULL;//存重定向的文件
//编程技巧---将完整的代码放在循环里,循环只会循环一次,目的不是循环而是将代码放在代码块({})里规整好
#define TramSpace(start) do{\
while(isspace(*start))\
++start;\
}while(0)
//Eg: "ls -l -a > filename.txt","ls -l -a >> filename.txt","ls -l -a < filename.txt"
void ParseRedir(char commandline[])
{
redir_type = NoneRedir;
filename = NULL;
char* start = commandline;
char* end = commandline + strlen(commandline) - 1;
//便利字符串,找到重定向的标志符,> < >>,并设置成'\0',因为strtok遇到'\0'就会结束
//"ls -l -a > filename.txt" -> "ls -l -a \0 filename.txt"
while(start <= end)
{
if((*start) == '>')
{
if((*(start+1)) == '>')
{
//>>追加重定向
*start = '\0';
++start;
*start = '\0';
++start;
TramSpace(start);//将start开始一直到文件名前的空格清掉
redir_type = AppendRedir;
filename = start;
break;
}
//输出重定向
*start = '\0';
++start;
TramSpace(start);
redir_type = OutputRedir;
filename = start;
break;
}
else if((*start) == '<')
{
//输入重定向
*start = '\0';
++start;
TramSpace(start);
redir_type = InputRedir;
filename = start;
break;
}
else
{
//继续找,或者找完了就说明是普通指令
++start;
}
}
}
int ExecuteCommand()
{
pid_t id = fork();
if(id < 0)
{
//失败
return -1;
}
else if(id == 0)
{
int fd = -1;
//child
//程序替换前先打开文件,程序替换并不影响文件的打开
if(redir_type == NoneRedir)
{
//do nothing
}
else if(redir_type == OutputRedir)
{
fd = open(filename, O_WRONLY|O_CREAT|O_TRUNC, 0666);
dup2(fd, 1);
}
else if(redir_type == InputRedir)
{
fd = open(filename, O_RDONLY);
dup2(fd, 0);
}
else if(redir_type == AppendRedir)
{
fd = open(filename, O_WRONLY|O_CREAT|O_APPEND, 0666);
dup2(fd, 1);
}
else
{
//bug?
}
execvp(gargv[0], gargv);
exit(3);
}
else
{
//parent---就干一件事情就是等待回收子进程
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid == id)
{
//成功
lastcode = WEXITSTATUS(status);
}
}
return 0;
}
int main()
{
while(1)
{
//1.打印命令行, [用户名@主机名字 路径]
PrintCommandLine();
//2.获取用户输入的字符串
char commandline[MAXSIZE] = {0};
if(0 == GetCommand(commandline, sizeof(commandline)))
continue;
//printf("%s\n", commandline);
//3.判断是否支持重定向
ParseRedir(commandline);
//4.解析字符串
ParseCommandline(commandline);
//5.子进程执行还是父进程执行
if(CheckBuiltinExecute())
{
//如果是内建命令就不要交给子进程
continue;
}
//6.让子进程执行命令
ExecuteCommand();
}
return 0;
}由上述代码也可得知,重定向就是将你输入的指令拆分成指令和文件名,然后根据符号(>,<,>>)转化成open打开文件的不同方式,整个打开文件的过程跟子进程的程序替换之间没有任何关系,程序替换改变的是内存,文件操作是进程的文件描述符表和文件结构体之间的事情,为什么不在父进程里做重定向是因为一旦做了重定向,后续创建的子进程不都是重定向了,子进程会拷贝父进程的内核数据结构,文件描述符表也属于内核数据结构,这其实也说明了为什么交给子进程执行的指令在控制台也能被父进程看到是因为他俩对应的外设是一个外设(都是显示器),而子进程做完一次重定向工作并退出后就会被父进程回收,不影响其他指令的执行。(还有其他原因更详细的可以问问AI)。
如何理解一切皆文件
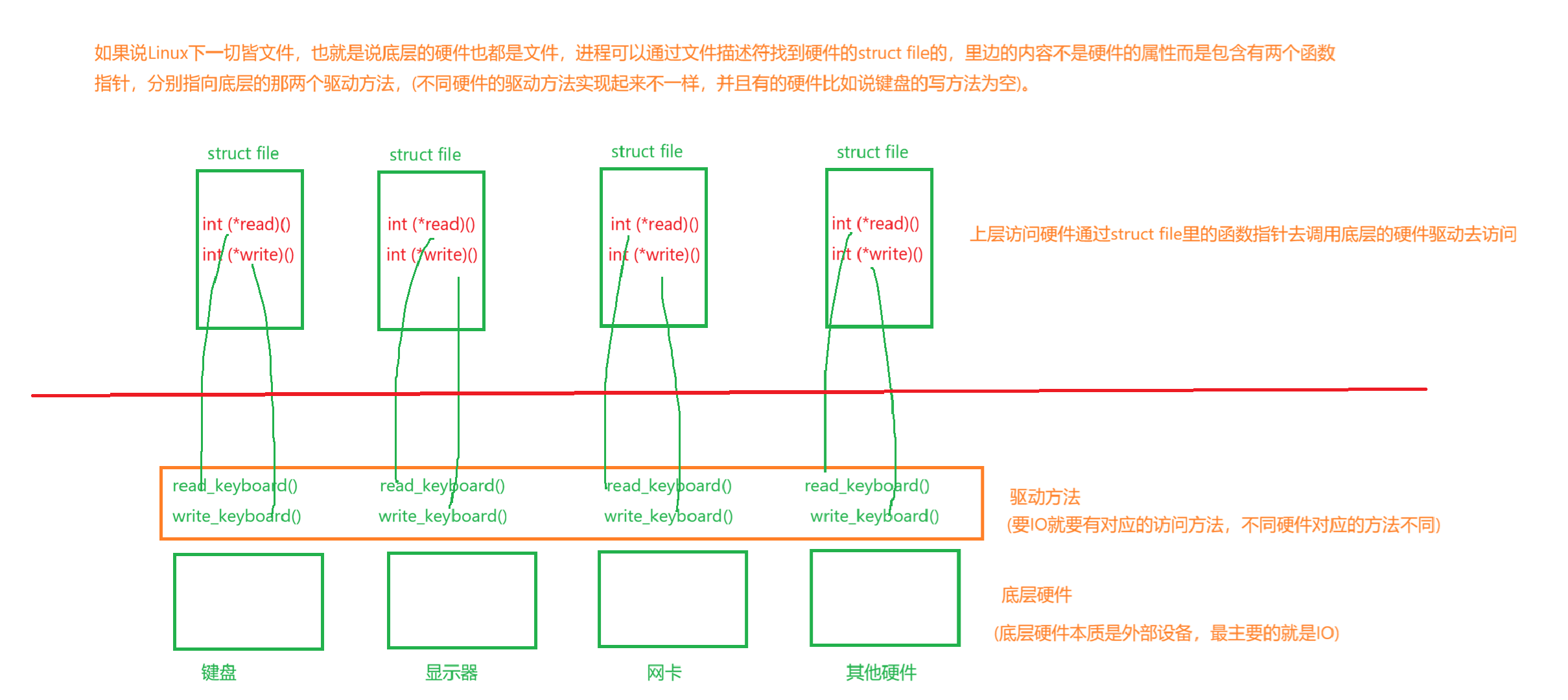
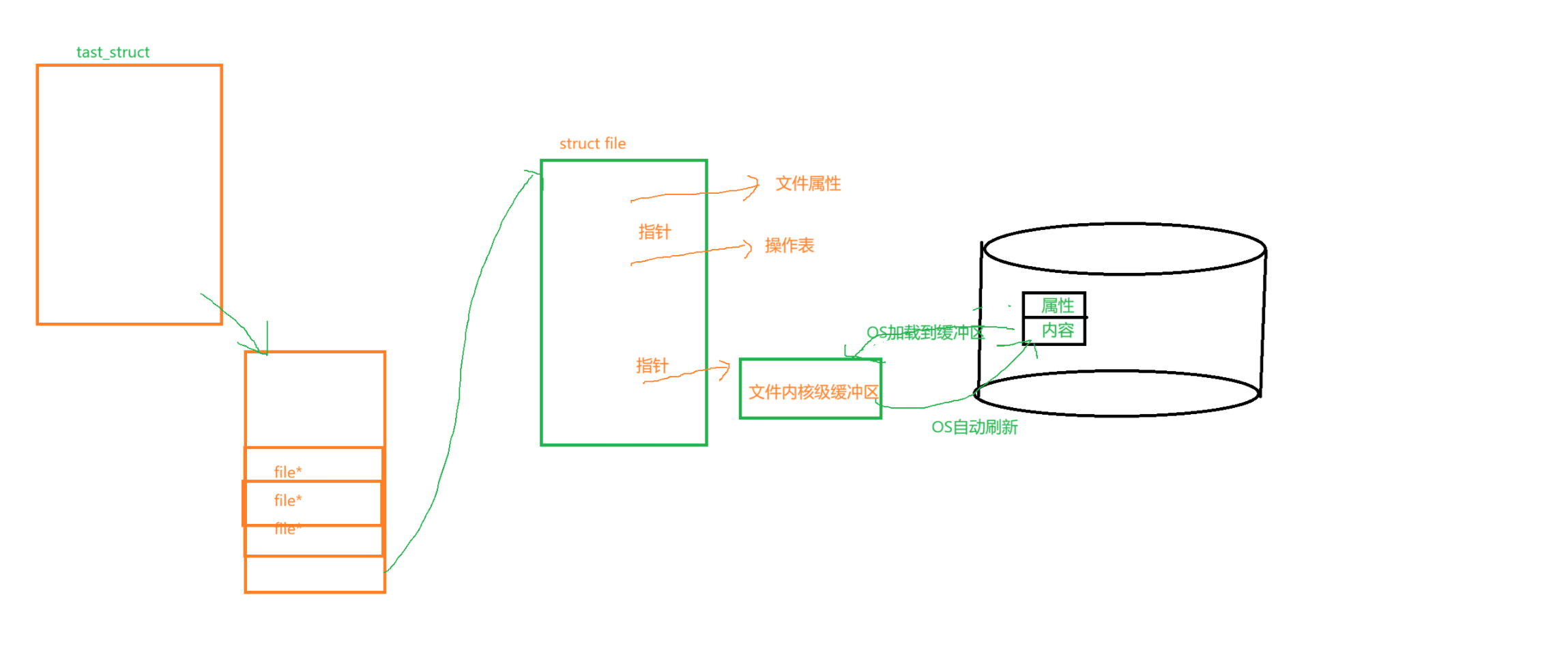
拿硬件举例。上层的那些struct file叫做虚拟文件系统,每一个struct file叫做虚拟文件,虚拟文件系统将底层每种硬件不同的驱动访问方式变成一样的了,都是通过函数指针去调用,而函数指针是一样的。这个struct file里的函数指针表(read和write只是一个缩影)就是实现一切皆文件的底层原理,上层的struct file就像是基类,底层的不同硬件就像是子类,整套系统就构成了多态,从系统角度,也就是用户角度,一切皆文件(一切皆struct file),但是底层其实很多元化,不同的硬件干的活都是不一样的。
缓冲区(处理文件内容)
文件打开和读写的基本过程
在没被打开之前,文件是存在物理磁盘里的,文件==文件属性+文件内容。启动一个进程之后,该进程会有task_struct和文件描述符表....进程里有函数或者系统调用去打开文件,那么此时在内存里OS会创建该文件的struct file,里边包含了文件的属性,文件的操作表(上文说的函数指针表),包括指向文件内核级缓冲区的指针。
万事具备,现在进程需要读取文件内容,使用read系统调用,进程会根据read的参数fd去通过文件描述符表找到struct file的文件内核级缓冲区,跟scanf一样,如果缓冲区里没有内容,进程会先阻塞(对于磁盘里的文件加载的这个过程很快,一般看不到现象,因为文件里本来就有内容,而scanf的时候,底层也是调用的read,但是此时是键盘里获取用户输入加载到内存里的键盘文件缓冲区里,必须要等用户从键盘输入数据才能进一步将数据加载到缓冲区里,这个等待的过程就相对来说时间长一些,可被观察),此时OS会将文件的内容从磁盘加载到文件内核级缓冲区里,所谓的read(就是拷贝函数),就是将内容从缓冲区拷贝到read参数的buff里,同理向文件写的时候(write也是拷贝函数)也是先找到缓冲区,然后将内容从buff拷贝到缓冲区里,OS会自动对缓冲区做刷新,刷新到磁盘里。除了打开和写入,我们还有可能要修改文件内容,同样的,大部分文件IO的情况下,OS会先将文件内容拷贝到缓冲区里,再修改,最后刷新回去,修改的方式可能不同,但本质上只是光标的位置不同而已,特殊的,当我们open的时候加了O_TRUNC,表示清空文件,此时直接将文件大小置为0了,也不会加载了,直接就写入缓冲区然后刷新的时候改一下属性和内容就可以了。
那操作系统是怎么将文件的内容加载到缓冲区和刷新到磁盘的呢?上文说了,struct file里有文件操作表,里边有许多的函数指针指向底层的硬件驱动,操作表里的read和write函数指针会帮OS完成内存和硬件(磁盘)交互的过程,因此操作表其实是给OS用的。
补充:read的简单使用
下边代码里的buffer叫用户缓冲区,目前阶段简单理解成存数据的一个数组就可以了。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
const char* filename = "log.txt";
int fd = open(filename, O_RDONLY);
char buffer[1024];
//读取字符串的时候最后一个位置留给'\0'
//文件里不考虑'\0'的问题
//但是读取出来到了语言层就需要'\0'作为结束标志了
ssize_t n = read(fd, buffer, sizeof(buffer) - 1);
//读取成功
if(n > 0)
{
buffer[n] = 0; //0就相当于'\0'
printf("buffer: %s\n", buffer);
}
close(fd);
return 0;
}引入缓冲区(意义)
结论:调用系统调用是需要成本的。说白了就是比较慢一点,从理解的角度,我们在C语言里调用malloc/new的时候底层是要去调用系统调用的,因为它们本质上是在修改虚拟内存mm_struct里堆空间的大小,是要修改mm_struct的属性的,这个工作肯定是由OS来做,所以必须调用系统调用,在stl里,比如说在使用vector的时候,当它空间满了,它不是会去1.5/2倍扩容嘛?它虽然一下子可能用不到这么多内存,依旧是用多少拿多少,但是当它下一次满了的时候就只需要到已经开辟好的空间里去拿就可以了,就不用再去调用malloc了,这本质上就是有效的减少了系统调用的次数,因此也就得出了,解决系统效用成本问题的核心思想就是尽量减少系统调用的次数。
回到打开读取文件这里,其实这里主要的成本就出现在read和write的次数上(它们都是系统调用),那我们要提高成本,肯定是要减少read和write的次数,先举个例子,菜鸟驿站的包裹,从来不会说你今天去寄快递了,当天就把你的那份快递单独的去运,永远是先存进仓库,当仓库里的快递积累到一定程度的时候才会一起寄出去。这里也同理,在上层的C语言/C++(下边拿C语言举例,都一样)里不是有针对文件IO的库函数嘛,里边封装了系统调用,就拿fputs举例,其参数有个const char* s,这个就是上文说的用户缓冲区,对于C语言来说会有两个语言级缓冲区,输入缓冲区和输出缓冲区,每一次调用fputs都会将用户缓冲区里的内容拷贝到输入缓冲区里,会有规律的调用系统调用将数据刷新到相应文件的内存内核级缓冲区里,这样一来就大大减少了调用系统调用的次数,提高了C语言的IO函数的运行效率。
那语言级缓冲区在哪里呢?答案就在FILE结构体里,注意这个FILE结构体不是struct file,两个都不是一个东西,一个是用语言IO函数打开文件的时候,IO函数会在虚拟内存堆区malloc一块空间并且返回一个FILE*地址,所以在调用fopen这种库函数打开文件的时候必然要调用fclose,fclose就是在回收FILE结构体,刷新语言级缓冲区,关闭文件描述符。一个是系统调用打开文件的时候文件从磁盘加载到内存被真正打开之后OS为管理它创建的struct file。FILE结构体里到底有什么?首先肯定是有文件描述符的,方便底层调用系统调用的时候当做参数传过去,此外,FILE里还会有char* inbuffer\[\]和char* outbuffer\[\],这两个数组就是语言级缓冲区(之前说的stdin,stdout,stderr也是FILE结构体),每一个文件打开时候都会有各自的FILE结构体,就会有各自的缓冲区。
语言级缓冲区vs内核级缓冲区
语言级缓冲区
补充:语言级缓冲区的刷新问题。语言级缓冲区刷新的本质:IO函数底层调用系统调用write,将缓冲区里的内容拷贝到内核级文件缓冲区里。就是把你的数据交给OS,不一定是写到磁盘的,只是刷新到内核级缓冲区里,具体之后说。
以下3种情况语言级缓冲区会刷新:
1.进程结束的时候会自动刷新。(库层退出,exit()/return,系统调用_exit是直接内核层面杀死了进程,并不会涉及到刷新上层语言级缓冲区的效果,库函数底层封装系统调用,但你直接用系统调用可能就会少了一些功能)
2.如果目标文件是显示器,行刷新->行缓冲,我们用的\n就是行刷新。行刷新的作用就是方便用户去读。
3.如果是普通文件,一般是全缓冲,缓冲区写满了才会刷新。
注意对于计算机语言来说,我不知道重定向的事情,反正在我心目中的目标文件就是fd下标里的指针所指向的那个文件。fflush和fclose都有强制刷新的效果。
现象1:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
printf("hehe\n");
close(fd);
return 0;
}上边的代码是将printf重定向成了往log.txt里边打印,运行之后会发现无论是显示器还是log.txt都是空的。这是为什么呢?printf本质是往stdout(FILE结构体对象)的缓冲区里打印的hehe,FILE内部会记录文件类型来知道fd对应的到底是终端还是文件,此时是文件,\n不会去刷新,然而缓冲区又没有被写满,它就会等进程结束之后才刷新,但我们在进程结束前先调用了close系统调用,直接就把文件关了,等进程结束想刷新的时候文件都关了,printf底层调用write的时候会报错就此终止,所以啥也看不到,解决方案就是主动调用fflush或者fclose,在进程结束前强制刷新。(注意:IO函数是不知道我最后到底往哪种类型的文件里写入或者读取的,但是FILE里会记录下来,底层是知道的)。
现象2:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
//C库函数
printf("hello world\n");
fprintf(stdout, "hello fprintf\n");
const char* s = "hello fputs\n";
fputs(s, stdout);
//系统调用
const char* ss = "hello write\n";
write(1, ss, strlen(ss));//不用加1,因为字符串末尾加\0是C语言的事情,Linux下一切皆文件,它不会管这些
fork();
return 0;
}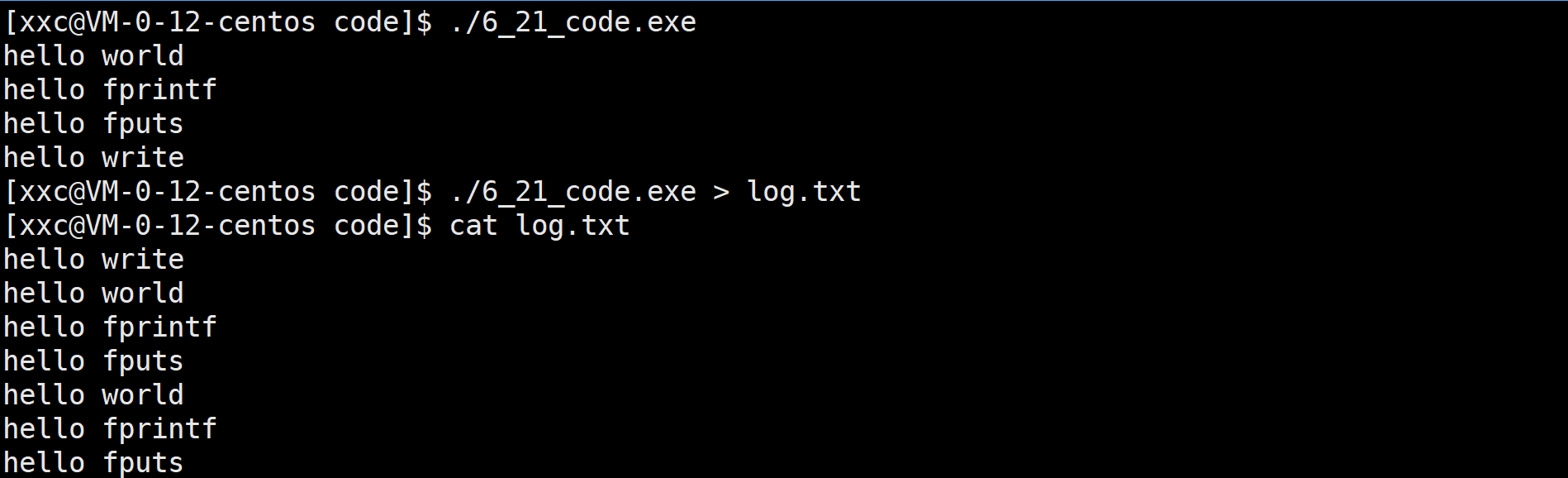
./6_21_code.exe的时候没有重定向,目标文件是显示器,会行刷新,因此前三行(库函数打印的那3行)就直接从语言级缓冲区刷新到了内核级文件缓冲区里,最后一行是由系统调用打印的,直接就写入了内核级缓冲区里。./6_21_code.exe > log.txt是重定向到普通文件里,会全刷新,\n没用了,很显然语言级缓冲区目前是没写满的,所以它不会刷新,会待在语言级缓冲区里一直等到进程结束才会刷新,fork之后创建子进程,子进程会和父进程会共享数据(stdout的输入缓冲区里的内容肯定也共享了),进程结束后(return 0后父子都结束了),需要刷新缓冲区,缓冲区里都是数据,本质就是要更改数据,因为刷新过后缓冲区就空了,因此会发生一定程度的写时拷贝,所以就会看到两份,而系统调用跟它们都没关系,write在fork之前就直接写入了内核级缓冲区里,所以log.txt里就一份。
内核级缓冲区
细节1:只要把数据从用户缓冲区拷贝到了内核文件缓冲区,就相当于交给了硬件。
细节2:OS会自动刷新内核级缓冲区,它有自己定的一套刷新策略(笼统理解)
1.立即刷新
2.等OS不忙了再自主刷新
同样的,如果想要OS立即刷新,就需要用系统调用,具体之后说。另外,数据从系统到硬件也是需要成本的,内核级缓冲区的作用和语言级缓冲区的一样,就是节约成本。