在语法上,内连接有专门的 inner join 写法,格式为 select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件,其中 on 关键字用来指定两张表的连接条件,and 后面可以追加额外的业务筛选条件。这种写法和我们之前用 where 条件实现的内连接是等价的,只是语法结构更清晰,把连接条件和筛选条件分开了,也更符合现代 SQL 的书写规范。
需要注意的是,我们之前学习的笛卡尔积也属于内连接的一种特殊情况,当不写任何 on 或 where 条件时,两张表会直接生成完整的笛卡尔积,此时的连接条件相当于恒成立,所有记录都会被保留。而我们实际使用的内连接,都是在笛卡尔积的基础上,通过条件过滤出有业务意义的记录,这也是内连接最核心的作用。
之前的写法就是用 where 条件实现的内连接。执行 select * from emp, dept where emp.deptno=dept.deptno; 时,数据库会先对两张表做笛卡尔积,再通过 where 条件筛选出部门号匹配的记录,最终得到 14 条数据,每条记录都同时包含员工信息和对应的部门信息。
因为我们只需要员工姓名和部门名称,可以把语句改成 select emp.ename, dept.dname from emp, dept where emp.deptno=dept.deptno;,结果中就会只显示员工姓名和对应的部门名称,比如 SMITH 对应 RESEARCH,ALLEN 对应 SALES,这和我们的需求匹配。
现在我们可以换种写法:
我们切换到 inner join 的标准写法,执行 select * fromemp inner join depton emp.deptno=dept.deptno;。和之前的写法一样,数据库会先做笛卡尔积,再通过 on 子句的连接条件筛选有效记录,结果和 where 条件写法完全一致,同样是 14 条包含员工和部门信息的记录。
因为我们只需要目标字段,所以执行 select ename, dname from emp inner join dept on emp.deptno=dept.deptno;,结果也和之前的字段筛选结果完全相同,说明两种写法在功能上是等价的,只是语法结构不同。
我们也可以在内连接中添加额外筛选条件。第一种是在 on 子句后用 and 追加条件,执行 select ename,dname from emp inner join dept on emp.deptno=dept.deptno and ename='SMITH';,结果只会返回 SMITH 的姓名和部门名称;第二种是在 inner join 语句后用 where 子句追加条件,执行 select ename,dname from emp inner join dept on emp.deptno=dept.deptno where ename='SMITH';,结果和第一种方式一致。这说明在内连接中,and 和 where 都可以用来添加业务筛选条件,只是 on 子句主要用于指定连接条件,而 where 子句更适合添加后续的过滤条件,实际使用中可以根据习惯选择,两种方式的执行结果没有区别。
在语法上,左外连接的格式是 select 字段名 from 表1 left join 表2 on 连接条件,其中 表1 就是我们所说的 "左侧表",它的所有记录都会被保留,而 表2 是右侧表,只保留和左侧表匹配的记录。这种写法的关键在于 left join 关键字,它明确指定了以左侧表为基准进行连接,这也是它和内连接最本质的区别 ------ 内连接只保留两张表都匹配的记录,而左外连接会优先保留左侧表的全部数据,再去匹配右侧表的数据。
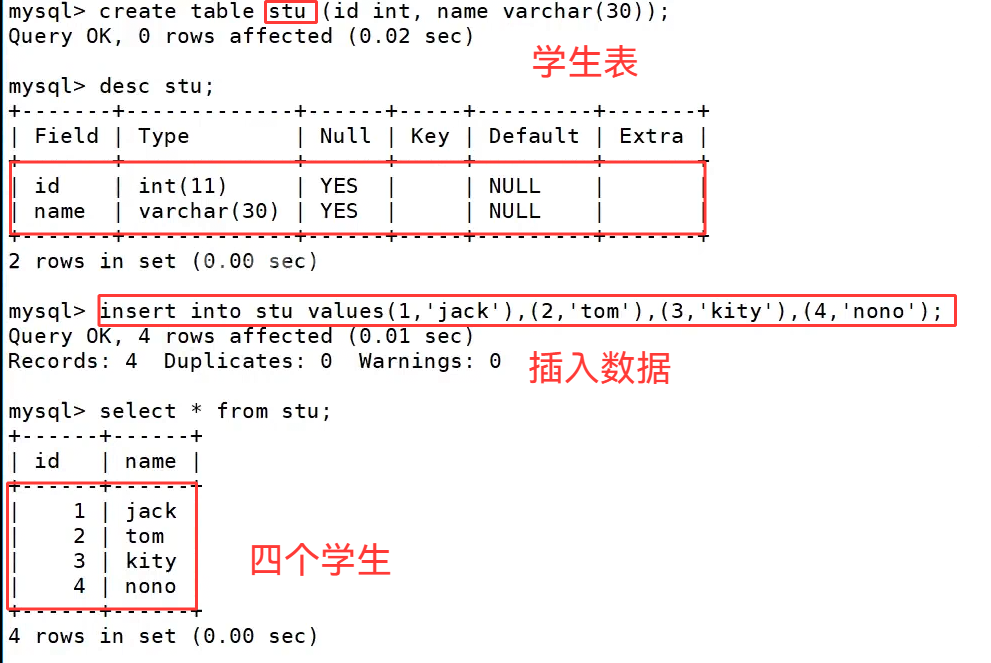
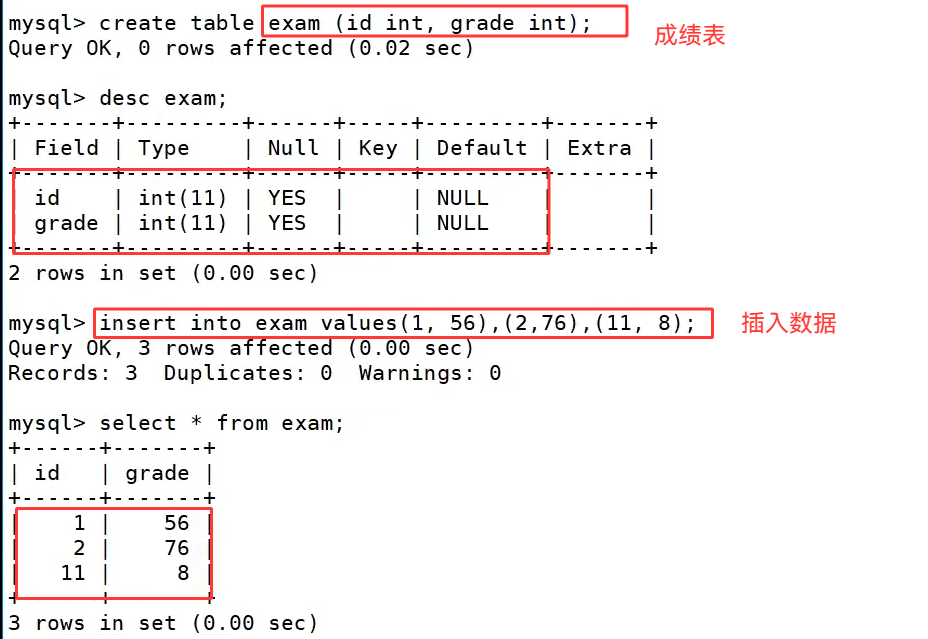
我们重新建两张表: 学生表和成绩表
这两张表分别是学生表 stu 和成绩表 exam,它们通过 id 字段建立关联关系。创建学生表时,我们用 create table stu(id int, name varchar(30)); 定义了表结构,包含学生编号 id 和姓名 name 两个字段,随后插入了 4 条学生数据,执行 select * from stu; 后可以看到,表中共有 4 名学生,编号分别为 1、2、3、4。接着创建成绩表 exam,使用 create table exam(id int, grade int); 定义了学生编号 id 和成绩 grade 字段并插入数据,执行 select * from exam; 后能看到,成绩表中只有编号 1、2 的学生有成绩记录,还有一条编号 11 的无效成绩数据,和学生表的数据并不完全匹配,这种数据差异正是用来演示内连接和左外连接区别的关键。
示例: 查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
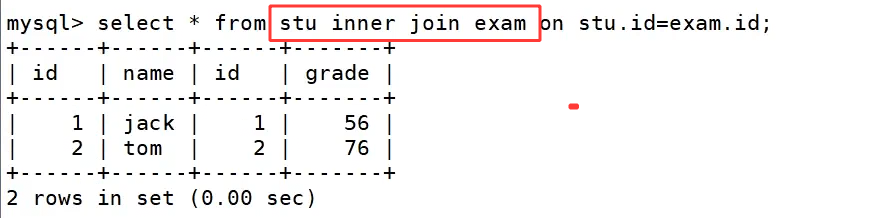
如果是内连接的话:
执行 select * from stu inner join exam on stu.id=exam.id;,内连接只会保留两张表中 id 字段匹配的记录,所以只有编号 1 的 jack 和编号 2 的 tom 被查询出来,共 2 条结果。编号 3 和 4 的学生因为在成绩表中没有匹配的记录,被直接过滤掉了,这显然不符合 "查询所有学生成绩,无成绩也要显示学生信息" 的需求,也体现了内连接 "只保留匹配数据" 的局限性。
如果是左外连接:
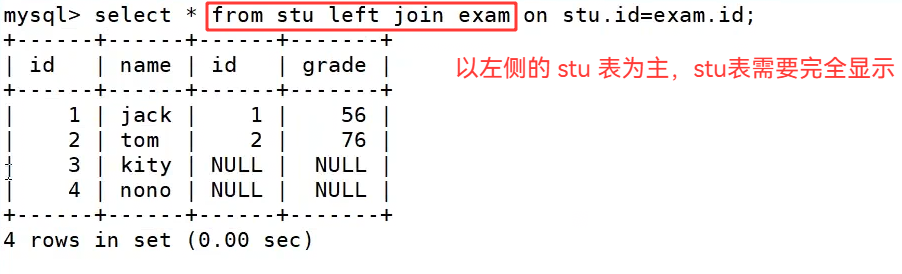
执行 select * from stu left join exam on stu.id=exam.id;,这里以左侧的学生表 stu 为主表,它的所有记录都会被完整保留,再去匹配右侧成绩表 exam 中的数据。执行结果中,4 名学生全部被显示出来,编号 1 和 2 的学生因为有匹配的成绩,正常显示了对应的 grade 字段;而编号 3 的 kity 和编号 4 的 nono 因为没有匹配的成绩,exam 表对应的 id 和 grade 字段都显示为 NULL,既保留了所有学生信息,也体现了他们无成绩的状态。这也清晰展示了左外连接的核心特点:左侧主表的数据全部保留,右侧表的数据根据连接条件匹配,不匹配的字段以 NULL 填充,这也是它和内连接最本质的区别。
右外连接
我们现在来看和左外连接对应的右外连接,它的逻辑和左外连接刚好相反。
什么是右外连接?
右外连接的定义是,在联合查询中,右侧的表会被完全显示,不管它在左侧表中有没有匹配的记录。
语法:
它的语法格式是 select 字段 from 表1 right join 表2 on 连接条件,其中 表2 就是右侧的主表,它的所有记录都会被完整保留,而 表1 是左侧表,只保留和右侧表匹配的记录,不匹配的字段会显示为 NULL。 示例1 : 对stu表和exam表联合查询,把所有的成绩都显示出来,即使这个成绩没有学生与它对应,也要显示出来
也就是以右侧表为主:
当我们执行 select * from stu right join exam on stu.id=exam.id; 时,以右侧的成绩表 exam 为主表,它的所有记录都会被保留。执行结果里,成绩表中的 3 条记录全部显示了出来:id 为 1 和 2 的成绩在学生表中有匹配的记录,正常显示了学生的 id 和 name;而 id 为 11 的成绩在学生表中没有对应的学生,所以左侧学生表的 id 和 name 字段都显示为 NULL,但这条成绩记录依然被保留了下来,实现了 "显示所有成绩,即使没有对应学生" 的需求。 我们也可以使用左外连接交换位置也能达到同样的效果,只需要交换两张表的位置。比如上面的右外连接语句,等价于 select * from exam left join stu on stu.id=exam.id;,此时以 exam 作为左侧主表,同样会保留所有成绩记录,不匹配的学生字段显示为 NULL,结果和右外连接完全一致。这也说明,在实际开发中,大多数场景用左外连接就能覆盖需求,右外连接更多是作为一种对称的写法存在,理解它的核心逻辑,就能和左外连接互相转换使用。
接着我们用左外连接来实现需求,执行 select * from dept left join emp on dept.deptno=emp.deptno;。这里我们把 dept 部门表作为左侧主表,所以所有部门记录都会被完整保留,再去匹配右侧 emp 员工表中的数据。执行结果中,10、20、30 号部门因为有员工,正常显示了对应的员工信息;而 40 号部门因为没有员工,员工表对应的字段全部显示为 NULL,但部门本身的信息依然被保留了下来,实现了 "同时列出没有员工的部门" 的需求。
为了让结果更直观,我们可以加上 order by dept.deptno asc; 对部门号进行排序,执行 select * from dept left join emp on dept.deptno=emp.deptno order by dept.deptno asc; 后,结果会按部门号从小到大排列,40 号部门会出现在最后一行,所有员工字段都为 NULL,一眼就能看出它是没有员工的部门。这也再次验证了左外连接的核心逻辑:以左侧主表为基准,保留所有记录,右侧表匹配不到的字段用 NULL 填充,完美解决了内连接无法处理的 "主表数据全部保留" 场景。
在语法上,内连接有专门的 inner join 写法,格式为 select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件,其中 on 关键字用来指定两张表的连接条件,and 后面可以追加额外的业务筛选条件。这种写法和我们之前用 where 条件实现的内连接是等价的,只是语法结构更清晰,把连接条件和筛选条件分开了,也更符合现代 SQL 的书写规范。
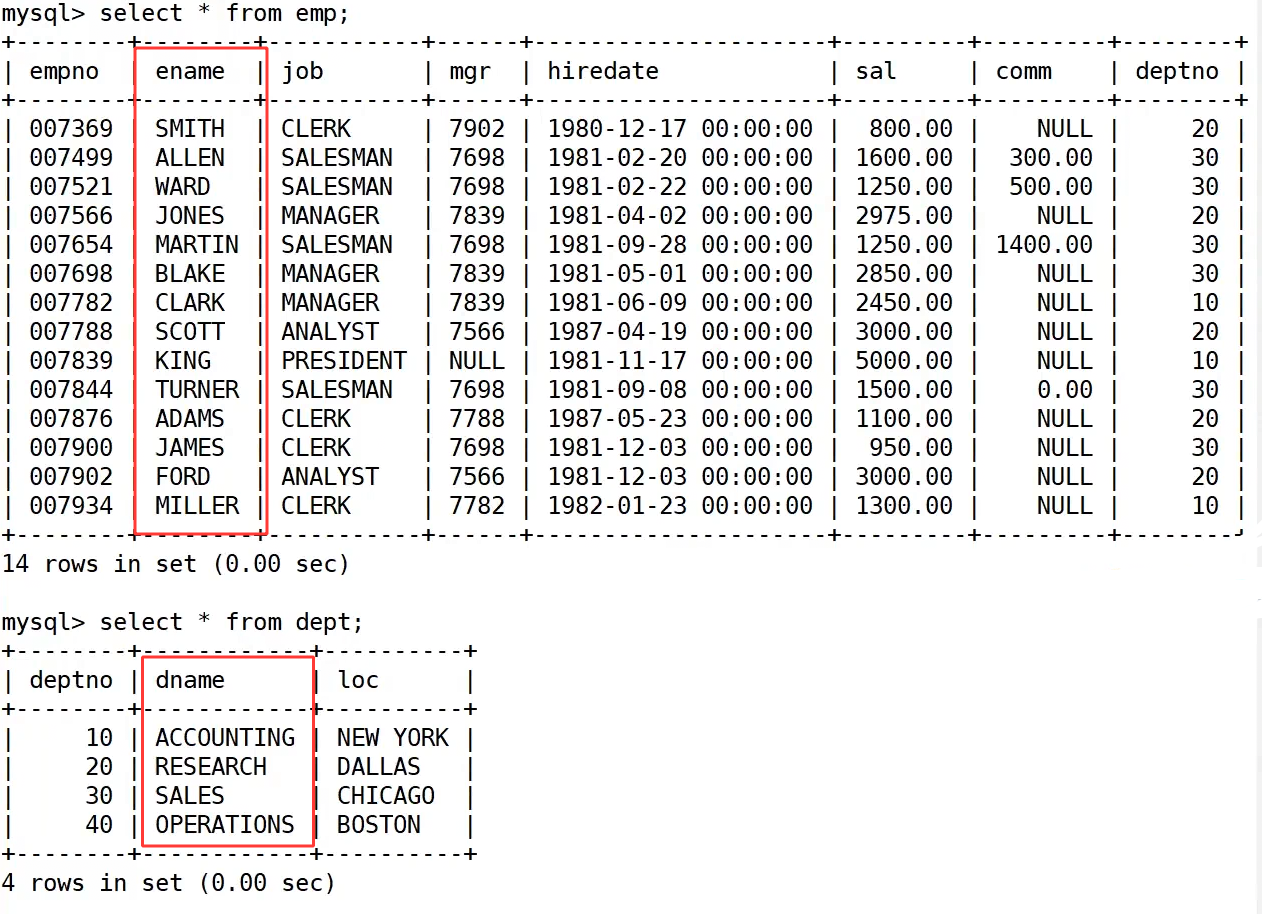
之前的写法就是用 where 条件实现的内连接。执行 select * from emp, dept where emp.deptno=dept.deptno; 时,数据库会先对两张表做笛卡尔积,再通过 where 条件筛选出部门号匹配的记录,最终得到 14 条数据,每条记录都同时包含员工信息和对应的部门信息。
因为我们只需要员工姓名和部门名称,可以把语句改成 select emp.ename, dept.dname from emp, dept where emp.deptno=dept.deptno;,结果中就会只显示员工姓名和对应的部门名称,比如 SMITH 对应 RESEARCH,ALLEN 对应 SALES,这和我们的需求匹配。
我们切换到 inner join 的标准写法,执行 select * fromemp inner join depton emp.deptno=dept.deptno;。和之前的写法一样,数据库会先做笛卡尔积,再通过 on 子句的连接条件筛选有效记录,结果和 where 条件写法完全一致,同样是 14 条包含员工和部门信息的记录。
因为我们只需要目标字段,所以执行 select ename, dname from emp inner join dept on emp.deptno=dept.deptno;,结果也和之前的字段筛选结果完全相同,说明两种写法在功能上是等价的,只是语法结构不同。
我们也可以在内连接中添加额外筛选条件。第一种是在 on 子句后用 and 追加条件,执行 select ename,dname from emp inner join dept on emp.deptno=dept.deptno and ename='SMITH';,结果只会返回 SMITH 的姓名和部门名称;第二种是在 inner join 语句后用 where 子句追加条件,执行 select ename,dname from emp inner join dept on emp.deptno=dept.deptno where ename='SMITH';,结果和第一种方式一致。这说明在内连接中,and 和 where 都可以用来添加业务筛选条件,只是 on 子句主要用于指定连接条件,而 where 子句更适合添加后续的过滤条件,实际使用中可以根据习惯选择,两种方式的执行结果没有区别。
在语法上,左外连接的格式是 select 字段名 from 表1 left join 表2 on 连接条件,其中 表1 就是我们所说的 "左侧表",它的所有记录都会被保留,而 表2 是右侧表,只保留和左侧表匹配的记录。这种写法的关键在于 left join 关键字,它明确指定了以左侧表为基准进行连接,这也是它和内连接最本质的区别 ------ 内连接只保留两张表都匹配的记录,而左外连接会优先保留左侧表的全部数据,再去匹配右侧表的数据。

当我们执行 select * from stu right join exam on stu.id=exam.id; 时,以右侧的成绩表 exam 为主表,它的所有记录都会被保留。执行结果里,成绩表中的 3 条记录全部显示了出来:id 为 1 和 2 的成绩在学生表中有匹配的记录,正常显示了学生的 id 和 name;而 id 为 11 的成绩在学生表中没有对应的学生,所以左侧学生表的 id 和 name 字段都显示为 NULL,但这条成绩记录依然被保留了下来,实现了 "显示所有成绩,即使没有对应学生" 的需求。
我们也可以使用左外连接交换位置也能达到同样的效果,只需要交换两张表的位置。比如上面的右外连接语句,等价于 select * from exam left join stu on stu.id=exam.id;,此时以 exam 作为左侧主表,同样会保留所有成绩记录,不匹配的学生字段显示为 NULL,结果和右外连接完全一致。这也说明,在实际开发中,大多数场景用左外连接就能覆盖需求,右外连接更多是作为一种对称的写法存在,理解它的核心逻辑,就能和左外连接互相转换使用。


接着我们用左外连接来实现需求,执行 select * from dept left join emp on dept.deptno=emp.deptno;。这里我们把 dept 部门表作为左侧主表,所以所有部门记录都会被完整保留,再去匹配右侧 emp 员工表中的数据。执行结果中,10、20、30 号部门因为有员工,正常显示了对应的员工信息;而 40 号部门因为没有员工,员工表对应的字段全部显示为 NULL,但部门本身的信息依然被保留了下来,实现了 "同时列出没有员工的部门" 的需求。
