智能客服 RAG 搭建:技术要点、选型与常见问题
一、为什么很多 RAG 项目 Demo 效果不错,落地后却很难稳定
过去两年,RAG 几乎已经成为企业建设 AI 知识库、智能问答和智能客服系统的标准方案。常见的实现路径通常并不复杂:文档导入、文本切分、向量化、写入向量库,再结合检索结果调用大模型生成答案。
这条路径足以快速完成一个 Demo,但在进入实际业务场景后,问题往往会迅速暴露出来:
- 用户问题并不复杂,但回答不稳定
- 文档已经入库,检索结果仍然不理想
- 回答表面相关,实际偏离业务语境
- 多轮追问一旦出现,命中率明显下降
- 涉及退款、权限、订单、投诉等场景时,系统很难直接上线
这类问题通常不会首先出现在模型能力层面,而更多出现在更靠前的工程环节,例如:
- 文档解析质量不足
- Chunk 切分方式不合理
- 缺少关键词检索能力
- 检索结果未做有效重排
- 权限过滤未下沉到检索层
- 多轮对话没有做问题改写
- 缺乏拒答与人工兜底策略
智能客服 RAG 的难点,往往不在于是否已经接入大模型,而在于整条知识服务链路是否足够完整、稳定和可控。
二、为什么智能客服场景比普通知识问答更复杂
智能客服并不是一个单纯的知识问答系统。与通用问答相比,它至少同时涉及以下几类问题。
1. 知识问答
典型问题包括:
- 功能使用说明
- 套餐和价格差异
- 开票与售后政策
- 产品配置与报错处理
- 接口与集成说明
2. 多轮对话理解
真实用户的提问往往并不完整,常见形式包括:
- "退款多久到账?"
- "国际卡呢?"
- "企业版也是吗?"
如果系统不能根据上下文进行补全和改写,后续轮次的检索质量通常会显著下降。
3. 多渠道接入
客服场景通常不会只存在于一个网页聊天窗口,还可能分布在:
- 官网在线客服
- 企业微信
- 飞书
- Telegram
- 邮件
- 工单系统
渠道增多后,消息结构、用户身份、会话归档、人工接管等问题都会随之复杂化。
4. 业务动作执行
用户请求并不总是停留在咨询层面,很多场景还会直接涉及业务动作,例如:
- 查询订单
- 查询物流
- 创建工单
- 申请退款
- 转人工
- 下载资料
这意味着系统不能只做知识检索与回答,还需要接入工具调用、业务接口和权限校验。
5. 风险控制
客服系统与普通聊天机器人的一个重要区别在于,错误回答的代价更高。一次错误回复,可能直接带来:
- 用户投诉
- 售后争议
- 销售承诺偏差
- 内部 SOP 暴露
- 企业客户关系受损
因此,智能客服系统的目标并不是尽可能提高回答覆盖率,而是保证回答质量、控制回答边界,并在必要时能够稳定地转交人工处理。
三、从高 Star 项目中可以看到哪些共识
参考 Dify、MaxKB、RAGFlow、Rasa、Chatwoot、Rocket.Chat、LangChain、n8n、ChatterBot 等开源项目的 README、FAQ、部署文档及 issue,可以看到一个比较清晰的趋势:这些项目的差异主要体现在产品定位上,但它们最终都在解决同一个问题,即如何将模型能力转化为可上线、可维护的系统能力。
1. Dify、MaxKB、RAGFlow:RAG 的重点已经转向平台化能力
这类项目关注的重点已经不再是单一的向量检索,而是完整的知识处理与检索工程,包括:
- 文档导入与解析
- 数据清洗与结构恢复
- 多路召回与结果融合
- 检索重排
- 工作流编排
- 引用追踪
- 模型接入与观测能力
这说明生产环境中的 RAG 体系,核心竞争力更多体现为上下文工程,而不仅仅是模型接入数量。
2. Chatwoot、Rocket.Chat、Rasa:客服系统的难点不只在模型层
这类项目并不都以 RAG 为核心,但对于智能客服场景很有参考价值。它们长期解决的是以下问题:
- 多渠道消息统一接入
- 会话分配与人工协同
- 标签、路由与权限控制
- fallback 与 human handoff
- 运营与反馈闭环
这类能力提醒我们,智能客服系统本质上是服务系统,而不仅是检索系统。
3. LangChain、n8n:适合作为编排与集成层
LangChain 和 n8n 在工具接入、外部系统集成、工作流自动化和 PoC 搭建方面都很高效,适合承担连接器和编排层的角色。但这类框架并不能替代底层检索质量建设。如果文档解析、切分、混合检索和重排没有做好,再完整的工作流也很难弥补结果质量问题。
四、智能客服 RAG 更适合从哪些层面理解
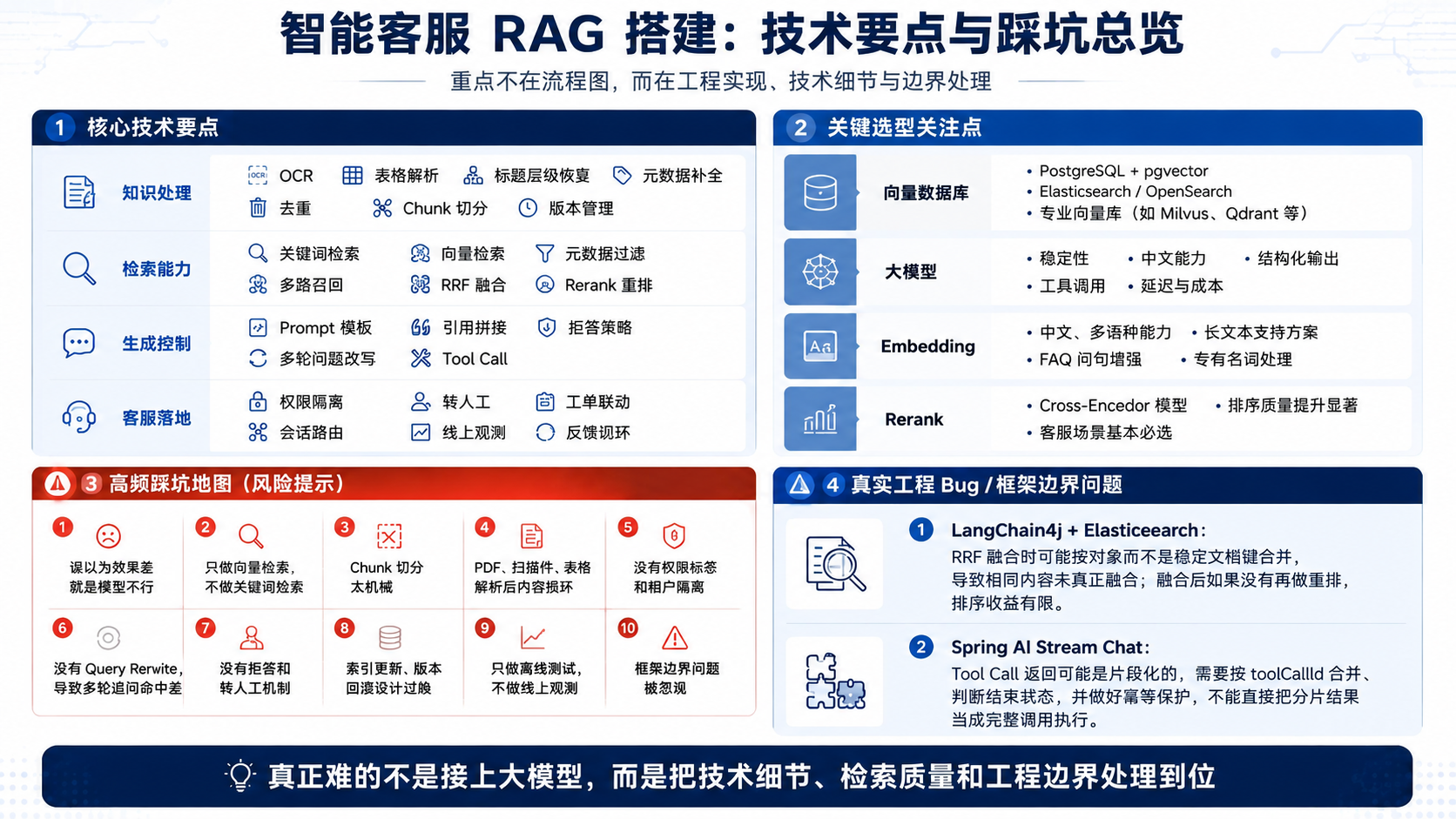
从工程实现角度看,一个可落地的智能客服 RAG 系统,至少应拆解为以下几个层面。
1. 数据接入层
负责接入各类知识与业务数据:
- FAQ
- 帮助中心内容
- 产品手册
- PDF / Word / PPT
- API 文档
- 工单历史
- CRM / 订单 / 物流数据
- 内部 SOP
2. 知识处理层
这一层直接决定检索质量下限,通常包括:
- OCR
- 表格解析
- 标题层级恢复
- 元数据补全
- 去重
- Chunk 切分
- 版本管理
- 权限标签
如果知识处理链路质量不足,后续的向量检索和大模型生成很难得到稳定结果。
3. 检索层
面向生产场景的客服 RAG,通常至少需要同时具备:
- 全文或关键词检索
- 向量检索
- 元数据过滤
- 多路召回
- 融合排序
- Rerank 重排
4. 生成控制层
这一层不仅负责调用大模型,还需要承担以下工作:
- Prompt 模板管理
- 引用片段拼接
- 风险控制
- 拒答策略
- 多轮上下文压缩
- 工具调用编排
5. 客服业务层
这一层决定系统是否真正具备上线能力,通常包括:
- 会话路由
- 用户身份识别
- 转人工
- 工单创建
- SLA 管理
- 满意度反馈
- 质检
- 反馈回流
五、搭建过程中最常见的问题
坑一:将效果问题简单归因于模型能力
这是最常见的误判之一。很多系统在效果不理想时,第一反应是更换模型,但实际原因往往来自以下环节:
- 文档解析错误
- Chunk 切分不合理
- FAQ 没有做结构化处理
- 只做了向量检索
- 没有加入重排
- 没有进行 query rewrite
很多表面上的"模型问题",本质上仍然属于检索工程问题。
坑二:只有向量检索,没有关键词检索
客服场景中,大量问题依赖精确命中,例如:
- 错误码
- 订单号
- 套餐名称
- 接口路径
- 型号
- 版本号
如果系统只依赖 dense retrieval,这类问题很容易发生偏召回。因此,混合检索通常不是增强项,而是客服场景中的基础能力。
坑三:Chunk 切分方式过于机械
固定 token 长度切分虽然实现简单,但与真实知识结构常常不匹配,常见问题包括:
- FAQ 被拆散
- 标题与正文断开
- 表格上下文丢失
- 操作步骤跨块分裂
- 条款边界不清晰
更合理的方式通常是按内容类型设计切分策略,例如 FAQ 按问答对切分,帮助文档按标题层级切分,接口文档按 endpoint 切分,规则文档按条款切分。
坑四:解析成功并不代表内容可用
PDF、扫描件和表格型文档是知识入库中最容易被低估的风险来源。常见问题包括:
- 表格列错位
- OCR 错字
- 标题丢失
- 多栏顺序错乱
- 图片中的关键信息未被提取
因此,知识入库后的抽检机制非常必要,不能仅根据索引条数判断处理结果是否可用。
坑五:权限标签缺失,后期返工成本高
客服知识通常具有明显的访问边界,例如:
- 公开 FAQ
- 登录用户专属内容
- 企业客户专属规则
- 渠道商资料
- 内部客服 SOP
如果权限控制没有下沉到 chunk 级或检索级,后续补齐的成本通常很高,而且容易带来知识泄露风险。
坑六:缺少拒答与转人工机制
成熟的客服系统需要明确哪些问题可以回答,哪些问题应当拒答,哪些问题必须转人工。尤其在以下场景中,这一步不可省略:
- 退款承诺
- 订单与个人信息
- 投诉升级
- 检索证据不足
- 多轮上下文不清晰
在这类场景下,继续生成答案并不一定是正确选择,稳定的兜底策略往往更重要。
坑七:框架实现细节带来的边界问题
项目推进到一定阶段后,很多问题并不来自整体方案,而是来自框架在边界场景下的实现细节。这类问题容易被误判为模型问题、召回问题或业务问题,因此排查成本往往较高。
1. langchain4j-elasticsearch 中 RRF 融合的对象合并问题
在 multi-query retrieval 场景中,系统通常会将一个用户问题改写为多个 query,再通过 RRF 做融合。按常规预期,几路 query 如果命中了同一段内容,融合阶段应当识别并合并这些结果,再利用多路命中提升排序表现。
但实际问题在于:如果融合逻辑依赖对象等价性,而不是稳定的文档键,即使返回结果的文本字段相同,不同 query 返回的对象也可能不会被真正合并。这样会带来两个直接后果:
- 融合阶段累积了重复候选
- 融合结束后如果没有再做显式重排,排序收益会非常有限
这类问题说明,很多框架虽然已经支持 RRF 或 recall fusion,但仍然需要重点验证以下几点:
- 去重依据是什么
- 是否基于稳定文档 ID 合并
- 融合后是否进行了有效重排
- 多路召回是否真正提升了 Top-K 质量
更稳妥的做法通常包括:
- 自定义稳定文档键,例如
doc_id + chunk_id - 在缺少稳定 ID 时,对正文归一化后再计算 hash
- RRF 融合结束后再补一次显式 rerank
- 为检索链路增加回归测试,持续跟踪重复率、Top-K 命中率和最终引用质量
2. Spring AI 中 streamChat 的 tool-call 分片问题
在流式输出场景下,tool-call 返回内容可能并不是一次性完整给出,而是以分片形式逐段返回。工具名、参数 JSON、调用 ID 都可能被拆分在不同事件中。
如果业务代码直接将单个分片视为完整的工具调用对象,常见后果包括:
- 参数 JSON 解析失败
- 参数未收全即开始执行
- 同一个工具被重复触发
- 调用记录无法完整落库
因此,在 streaming 模式下,业务侧面对的并不是一个完整的函数调用对象,而是一组需要自行聚合的事件流。更稳妥的做法包括:
- 按
toolCallId维度维护累加器 - 持续拼装工具名、参数片段和状态信息
- 仅在确认 tool-call 完整结束后再触发执行
- 对工具调用增加幂等保护,避免重复执行
- 完整记录 streaming 日志,便于后续排查
如果系统已经接入下单、查订单、提工单、改状态、调用 CRM 等外部动作,这一层的稳定性尤为关键,因为此时错误后果已不再只是回答偏差,而可能直接变为业务执行错误。
3. 为什么 issue 区比 README 更值得反复阅读
框架 README 往往告诉使用者"支持什么",而 issue 区更能反映"在什么场景下会出问题、问题表现是什么、是否存在稳定 workaround,以及功能本身的成熟度"。
因此,在选型阶段,不宜只看 star 数量和功能清单,还应重点检索以下关键词:
streamtool callduplicatererankhybrid searchelasticsearchtimeouttenantpermissionmemory
如果一个框架在这些关键词下长期存在较多问题,且缺少稳定修复,就意味着该能力仍需要业务侧补齐较多边界处理。
六、几个关键选型问题
1. 向量数据库如何选择
从 0 到 1 的项目阶段,通常优先考虑以下两类方案:
PostgreSQL + pgvectorElasticsearch / OpenSearch
前者的优势在于:
- 架构简单
- 运维成本低
- 容易与业务数据联动
MaxKB 在公开技术栈中采用 PostgreSQL + pgvector,也说明这一路线对于企业级起步阶段具有较高现实性。
后者更适合以下场景:
- 关键词检索需求强
- 过滤条件较多
- 搜索能力要求较高
- 文本检索与分析一体化需求明显
RAGFlow 默认采用 Elasticsearch,也说明在复杂检索场景下,全文检索能力仍然具有很强的工程价值。
2. 大模型如何选择
客服场景中的模型选型,不宜只看榜单或单轮效果,更应重点评估:
- 指令遵循稳定性
- 长上下文支持能力
- 中文客服表达质量
- 结构化输出能力
- 工具调用能力
- 成本与延迟
对于客服系统而言,稳定性、可控性和系统集成能力,通常比单纯的主观"聪明程度"更重要。
3. Embedding 模型如何选择
Embedding 选型应结合自身数据特征进行验证,而不是只参考公开 benchmark。重点关注:
- 中文表现是否稳定
- 是否支持多语种
- 长文本表现如何
- 专有名词和数字类内容是否稳定
- FAQ 场景下是否需要问句增强
一个常见误区是只对答案文本做 embedding,而没有将"用户如何提问"的表达方式纳入向量化策略。
4. 是否需要 Rerank
在客服场景中,Rerank 通常不是可有可无的增强项,而是决定排序质量的关键能力。很多问题并不是"召不回来",而是"召回结果排序不准"。
对于这类场景,Cross-Encoder 类 rerank 往往能显著提升最终命中质量。因此,在延迟预算允许的前提下,Rerank 基本应视为生产配置的一部分。
七、一套更务实的落地思路
1. MVP 阶段
项目初期更适合先验证高频、低风险问题能否稳定覆盖,而不是一开始就追求完整能力闭环。一个更务实的组合通常包括:
- 使用 Dify 或 MaxKB 快速搭建平台能力
- 使用 Chatwoot 或现有客服工作台承接会话
- 以
PostgreSQL + pgvector或Elasticsearch / OpenSearch作为检索底座 - 选择一套中文效果稳定的 embedding 模型
- 补齐可用的 rerank 能力
- 选择支持结构化输出和工具调用的稳定 LLM
- 通过 n8n 或 LangChain 对接外部系统
这一阶段的目标应当聚焦在少量高频问题的准确覆盖,而不是过早扩展能力边界。
2. 生产阶段
当系统进入生产后,再逐步补齐以下能力:
- 多租户隔离
- 多路召回
- 版本管理
- 引用追踪
- Query Rewrite
- 在线观测
- 工单联动
- 人工反馈闭环
这种推进方式通常比一开始追求"大而全"更容易获得稳定结果。
八、结语
智能客服 RAG 的落地,表面上看是在建设"知识库 + 大模型"的能力组合,实质上更接近一套完整的知识服务系统。决定最终效果的,通常不是某个单点模型名称,而是以下链路是否足够扎实:
数据接入 -> 文档处理 -> 元数据治理 -> 混合召回 -> 重排 -> 引用生成 -> 权限过滤 -> 多轮改写 -> 工具执行 -> 转人工 -> 反馈闭环
在这一过程中,常见误区主要有三类:
- 将系统理解为一个会查资料的聊天框
- 将所有效果问题归结为模型能力不足
- 将注意力集中在模型接入,而忽略知识链路建设
对于智能客服场景来说,更重要的判断标准始终是:
- 是否能够稳定命中正确知识
- 是否能够控制回答边界
- 是否能够在不确定时可靠兜底
- 是否能够将回答能力与业务动作安全衔接
只有在这些问题得到系统化处理之后,RAG 项目才有可能从演示系统进入可上线、可运维、可持续优化的生产阶段。