文章目录
-
- 配套仓库(中文学习与复现)
- [RAG 全流程概览(离线索引 / 在线查询)](#RAG 全流程概览(离线索引 / 在线查询))
- 离线索引:决定"我们能检索到什么"
-
- 1) 数据采集 数据采集)
- 2) 文档解析与清洗 文档解析与清洗)
- 3) 文本切块(chunking) 文本切块(chunking))
- 4) 向量化(Embedding) 向量化(Embedding))
- 5) 向量库 / 索引 向量库 / 索引)
- 在线查询:决定"怎么回答、能不能稳定回答对"
-
- 1) Query 改写/扩展(步骤级可选) Query 改写/扩展(步骤级可选))
- 2) 检索:向量 top-k +(实现细节可选)BM25 检索:向量 top-k +(实现细节可选)BM25)
- 3) 重排序(步骤级可选) 重排序(步骤级可选))
- 4) 上下文增强(步骤级可选) 上下文增强(步骤级可选))
- 5) Prompt 组装:把证据"喂对方式" Prompt 组装:把证据“喂对方式”)
- 6) LLM 生成 LLM 生成)
- 7) 后处理(步骤级可选) 后处理(步骤级可选))
- 常见问题与对策
- [评估闭环:让 RAG 从"能跑"到"可迭代"](#评估闭环:让 RAG 从“能跑”到“可迭代”)
配套仓库(中文学习与复现)
我把关键技术点整理成一套循序渐进的学习步骤,全部以 Jupyter Notebook 形式呈现,便于你边跑边调试;LangChain 采用较新的 1.3.9 版本:
仓库学什么
- 基础 RAG 闭环:加载/切块/向量化/入库/检索/生成(含 CSV/JSON 等数据形态)
- 查询与检索增强:Query 改写、混合检索、融合检索、重排序等
- 上下文增强:header、扩窗、压缩/过滤,把证据包整理成更适合模型的上下文
- 可靠性与评估:groundedness、相关性过滤、LLM-as-judge 指标与端到端评测
- 高级架构:GraphRAG、RAPTOR、Self-RAG、CRAG、MemoRAG 等
RAG 全流程概览(离线索引 / 在线查询)
我们可以把 RAG 拆成两条链路:
- 离线索引(Indexing):把知识变成"可检索的向量索引"
- 在线查询(Retrieve → Generate):把问题变成"带证据的答案"
离线阶段通常包含:数据采集 → 解析清洗 → 文本切块 → 向量化 → 入库
在线阶段通常包含:Query →Query 改写(可选) → 检索(向量 + 可选 BM25)→重排序(可选) →上下文增强(可选) → Prompt 组装 → LLM 生成 →后处理(可选)
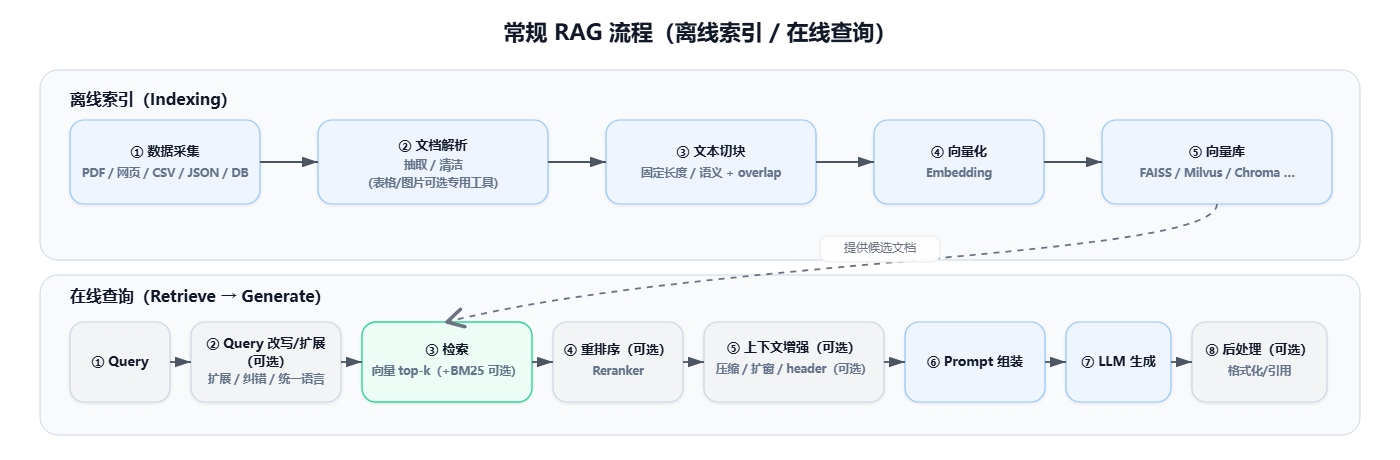
离线索引:决定"我们能检索到什么"
离线索引的质量,直接决定在线回答的上限。
1) 数据采集
来源可能是 PDF/网页/数据库/CSV/JSON/内部 Wiki 等。关键点是:数据要"可更新",并且能追踪到来源(后面做引用与评估会用到)。
2) 文档解析与清洗
- PDF:页眉页脚、分栏、表格、图片 OCR/解析都可能影响后续 chunk 质量
- 网页:广告、导航、脚本等噪声要清理
- 结构化数据(CSV/JSON):要考虑"按行/按对象"还是"按字段拼接"入库
经验:解析质量不行,后面再强的检索/重排都很难救回来。
3) 文本切块(chunking)
切块是 RAG 的"地基工程"。你需要权衡:
- chunk 太小:语义不完整、召回碎片化
- chunk 太大:噪声多、token 成本高、容易稀释关键信息
常见策略:固定长度 + overlap、语义切块、命题切块、带 header 的 chunk 等。
4) 向量化(Embedding)
Embedding 模型决定"语义相似度空间"的质量。要注意:
- 语言(中英混合/中文为主)
- 文本长度与截断策略
5) 向量库 / 索引
FAISS/Milvus/Chroma/Weaviate 等本质差异在:规模、过滤、混合检索、运维成本、索引更新策略。学习阶段用本地轻量方案即可,关键是把流程跑通并能迭代。
在线查询:决定"怎么回答、能不能稳定回答对"
在线链路可以视为"证据检索 + 证据整理 + 约束生成"。
1) Query 改写/扩展(步骤级可选)
当用户问题太短、含糊、口语化、或中英混杂时,Query 改写能显著提升召回:
- 扩展:补全同义词、别名、上下位词
- 纠错:拼写/实体纠错
- 统一语言:中文问题检英文资料(或反过来)
但它也可能引入偏差,所以通常作为"可选增强",在检索差时启用。
2) 检索:向量 top-k +(实现细节可选)BM25
- 向量检索:擅长语义相似、同义改写
- BM25(可选):擅长关键词精确匹配、实体/编号/术语
工程里常见组合:向量召回 + BM25 召回 → 融合(例如 union/加权) → 进入重排序。
3) 重排序(步骤级可选)
"检索"解决的是"找回来候选",重排序解决的是"候选里谁最相关"。
Reranker 常见是 cross-encoder 类模型:对 query 与文档对做更精细的相关性判断。
什么时候需要重排序?
- top-k 里混入了看似相似但无关的段落
- 你的向量召回质量不稳定
- 你追求更高 precision(更少噪声喂给 LLM)
4) 上下文增强(步骤级可选)
这是很多人最容易忽略、但对效果很关键的一步:检索到了文档之后,如何把"证据包"整理成最适合 LLM 使用的上下文。常见手段:
- 压缩:抽取关键句、去冗余、删噪声
- 扩窗:命中某个 chunk 后补上前后 chunk,保证语义完整
- header(实现细节可选):把章节标题/表头/字段名等结构信息带上,减少"孤立 chunk"误读
一句话总结:检索负责"找回来",上下文增强负责"把找回来的证据整理好"。
5) Prompt 组装:把证据"喂对方式"
常见实践:
- system prompt 明确约束:只能基于 context 回答,不足就说不知道
- 规范输出:要点式/结构化字段/带引用
- 控制上下文长度:避免 token 爆炸
6) LLM 生成
模型选择、温度、最大输出长度都会影响稳定性。
如果你希望更"可控",可以引入结构化输出(JSON schema / Pydantic)或分步生成。
7) 后处理(步骤级可选)
后处理并不改变"推理能力",但能显著提升"可用性":
- 格式化(标题、列表、表格)
- 引用标注(来源、chunk id、页码)
- 安全过滤(敏感信息脱敏)
- 结果去重、断句、语气统一
常见问题与对策
- 答非所问:先看 Query 是否需要改写;再看检索 top-k 是否相关;必要时加 rerank
- "看起来像引用但其实胡说":prompt 里强约束 + 上下文增强(压缩/过滤)+ groundedness 检查
- 上下文太长成本高:上下文压缩、减少 top-k、chunk 策略优化、扩窗替代大 chunk
- 指标没法量化:引入评估闭环(correctness/faithfulness/retrieval relevance)
评估闭环:让 RAG 从"能跑"到"可迭代"
没有评估,你很难判断"是检索的问题还是生成的问题"。一套最小闭环通常包括:
- Correctness:答案是否正确(相对参考答案)
- Faithfulness / Groundedness:是否严格基于检索证据
- Retrieval relevance:检索结果是否与问题相关