这张图片展示了关于**可解释性人工智能(XAI, Explainable Artificial Intelligence)**方法的分类体系。
从三个维度对XAI方法进行了划分,并重点讲解了基于"模型复杂度"这一维度的具体含义。
以下是对这些知识点的详细解释:
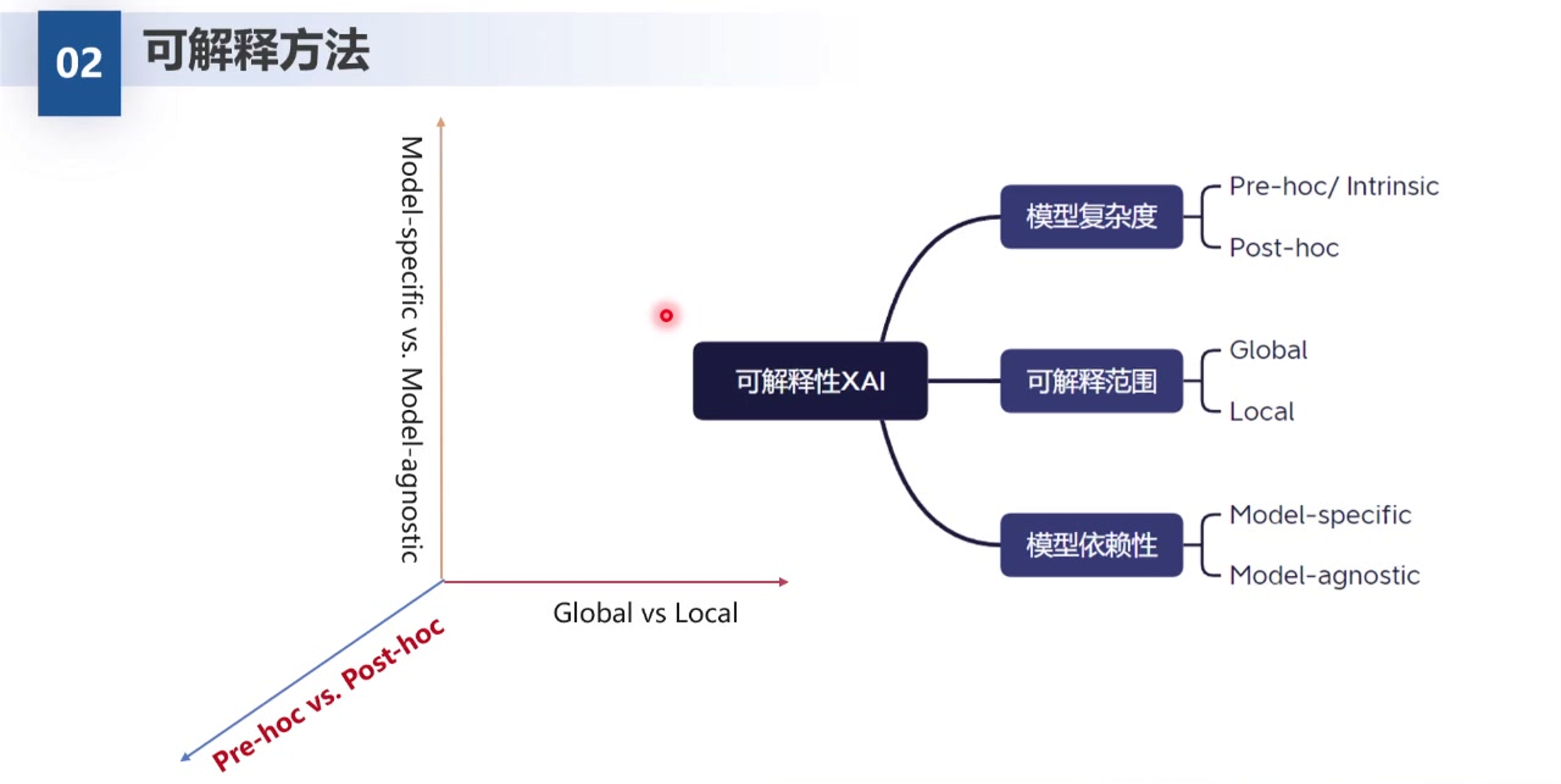
1. 可解释性方法的三维分类体系
第一张图展示了一个三维坐标系,用来定位不同的可解释性方法。这三个维度分别是:
-
模型复杂度 (Model Complexity):
- Pre-hoc / Intrinsic (事前/内在可解释性): 指模型本身就是透明的、简单的,不需要额外的工具就能理解。例如线性回归或决策树。
- Post-hoc (事后解释性): 指模型训练完成后,通过外部工具来分析其决策过程。通常用于复杂的黑盒模型(如深度神经网络)。
-
可解释范围 (Scope of Explanation):
- Global (全局解释): 试图解释整个模型的运作机制,即模型在所有数据上的总体行为逻辑。
- Local (局部解释): 只针对单个样本或特定区域的预测结果进行解释,说明为什么模型对这一个特定的输入做出了这样的判断。
-
模型依赖性 (Model Dependency):
- Model-specific (特定于模型): 这种解释方法只能用于特定类型的模型(例如,专门用于分析卷积神经网络的方法不能用于随机森林)。
- Model-agnostic (模型无关/通用): 这种方法不关心模型内部结构,把模型当作一个黑盒,只看输入和输出,因此可以应用于任何机器学习模型。

2. 重点解析:模型复杂度 (Model Complexity)
第二张图详细展开了"模型复杂度"这个维度,将其分为两类:
Pre-hoc / Intrinsic (事前/内在可解释性)
- 定义: 在执行任务之前,就设计一个本来就可以直接解释的模型。这意味着可解释性是模型自带的属性。
- 典型例子:
- 决策树: 你可以清晰地看到从根节点到叶节点的判断路径(例如:如果年龄>30且收入>5000,则批准贷款)。
- 线性模型: 可以通过查看权重系数的大小和正负来直接理解特征的重要性。
- 优缺点:
- 优点: 简单直观,完全透明。
- 缺点: 以牺牲准确性为代价。这类模型通常结构简单,难以捕捉复杂数据中的非线性关系,因此在处理图像、自然语言等复杂任务时,性能往往不如深度学习模型。
Post-hoc (事后解释性) ------ 图中红框重点
- 定义: 先设计一个高复杂、高性能但不可解释的模型(即"黑盒"模型),然后在模型训练好之后,利用逆向工程的方法来挖掘解释。
- 核心逻辑: "先追求高性能,再回头找解释"。
- 典型技术:
- LIME: 一种局部代理模型方法,通过在待解释样本附近采样,训练一个简单的局部模型来近似复杂模型的行为。
- Saliency Map (显著性图): 常用于计算机视觉,通过计算梯度等方式,高亮显示图像中对模型决策贡献最大的像素区域。
- 应用场景:
- 理解模型: 了解模型学到了什么特征。
- 理解决策: 明白模型为什么做出某个具体的预测。
- 理解样例: 分析特定输入数据的特殊性。
- 优缺点:
- 优点: 可以使用目前最先进、准确率最高的复杂模型(如Transformer, CNN),同时又能获得一定程度的解释。
- 缺点: 解释本身可能只是对原模型的一种近似,不一定能100%忠实反映原模型的内部逻辑(即存在"保真度"问题)。
总结
在构建AI系统时,我们需要在准确性 和可解释性之间做权衡。
- 如果我们选择Pre-hoc,我们选择了简单的逻辑,放弃了部分精度。
- 如果我们选择Post-hoc,我们保留了高精度的黑盒模型,但需要额外的步骤来"翻译"它的决策过程。
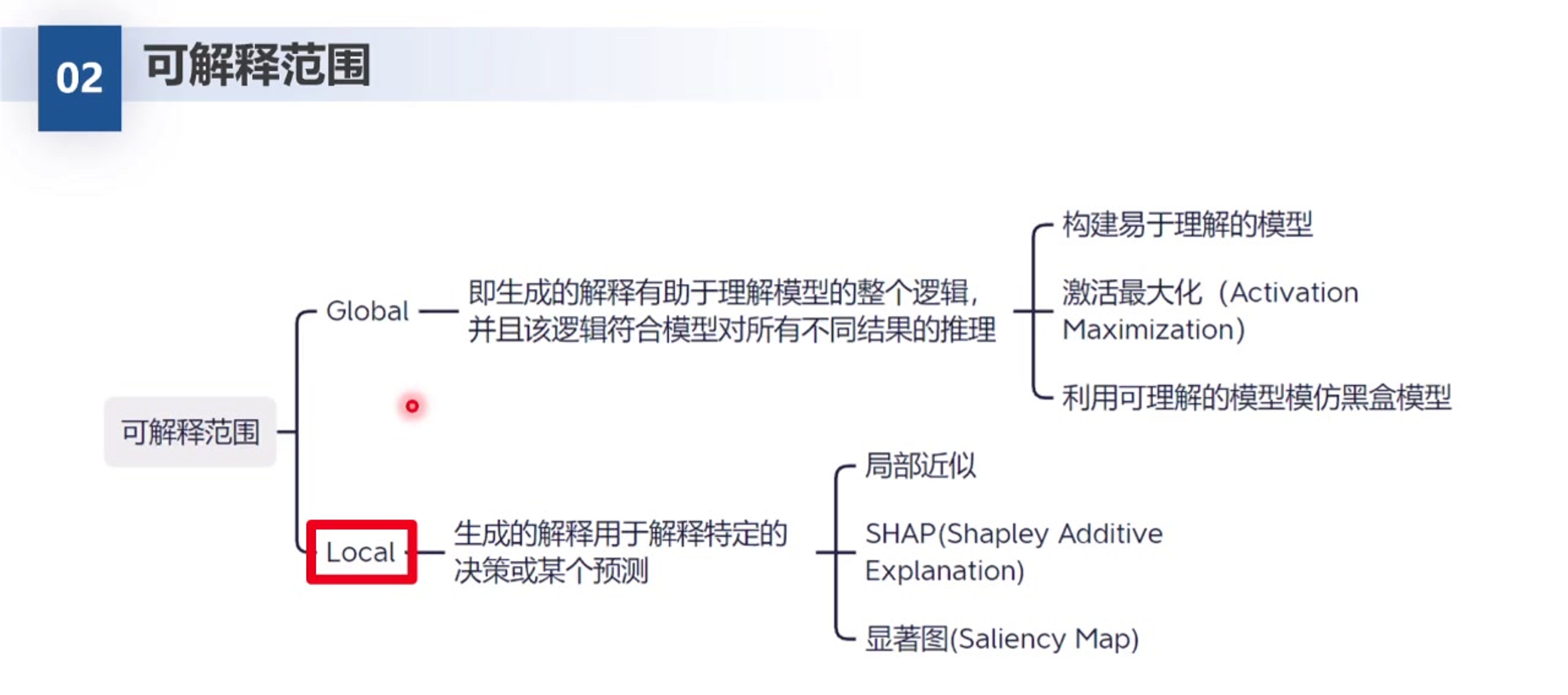
3. 可解释范围 (Scope of Explanation)
这一维度关注的是解释的覆盖面:是针对整个模型的宏观逻辑,还是针对单个预测的微观原因。
Global (全局解释)
- 定义: 生成的解释旨在帮助理解模型的整体逻辑。它试图回答"这个模型总体上是如何工作的?"以及"哪些特征对模型的整体决策最重要?"。这种解释必须符合模型对所有不同结果的推理过程。
- 典型方法:
- 构建易于理解的模型: 直接使用简单的模型(如线性回归、浅层决策树)来代替复杂模型,从而获得全局的可解释性。
- 激活最大化 (Activation Maximization): 主要用于深度学习(特别是图像识别)。通过生成能够最大程度激活某个神经元的输入图像,来理解该神经元究竟在"看"什么特征(例如,某个神经元专门识别"圆形的边缘")。
- 利用可理解的模型模仿黑盒模型: 这通常指代理模型技术。训练一个简单的白盒模型(如决策树)去拟合复杂黑盒模型的输入输出关系,然后用这个简单模型来近似解释黑盒的全局行为。
Local (局部解释)
- 定义: 生成的解释仅用于解释特定的决策或某个具体的预测结果。它不关心模型在其他数据上表现如何,只回答"为什么模型对这一个特定的样本做出了这样的判断?"。
- 典型方法:
- 局部近似: 在待解释样本的周围邻域内,用一个简单的线性模型来近似复杂的非线性模型。最著名的代表是 LIME。
- SHAP (Shapley Additive Explanations): 基于博弈论中的Shapley值。它将预测结果分配给各个特征,计算出每个特征对当前这次预测的贡献值(正贡献或负贡献)。这是目前最流行且理论完备的局部解释方法。
- 显著图 (Saliency Map): 主要用于计算机视觉。通过计算输出相对于输入的梯度,高亮显示图像中对分类结果影响最大的像素区域(例如,识别猫的图片中,猫脸部分的像素会被高亮)。
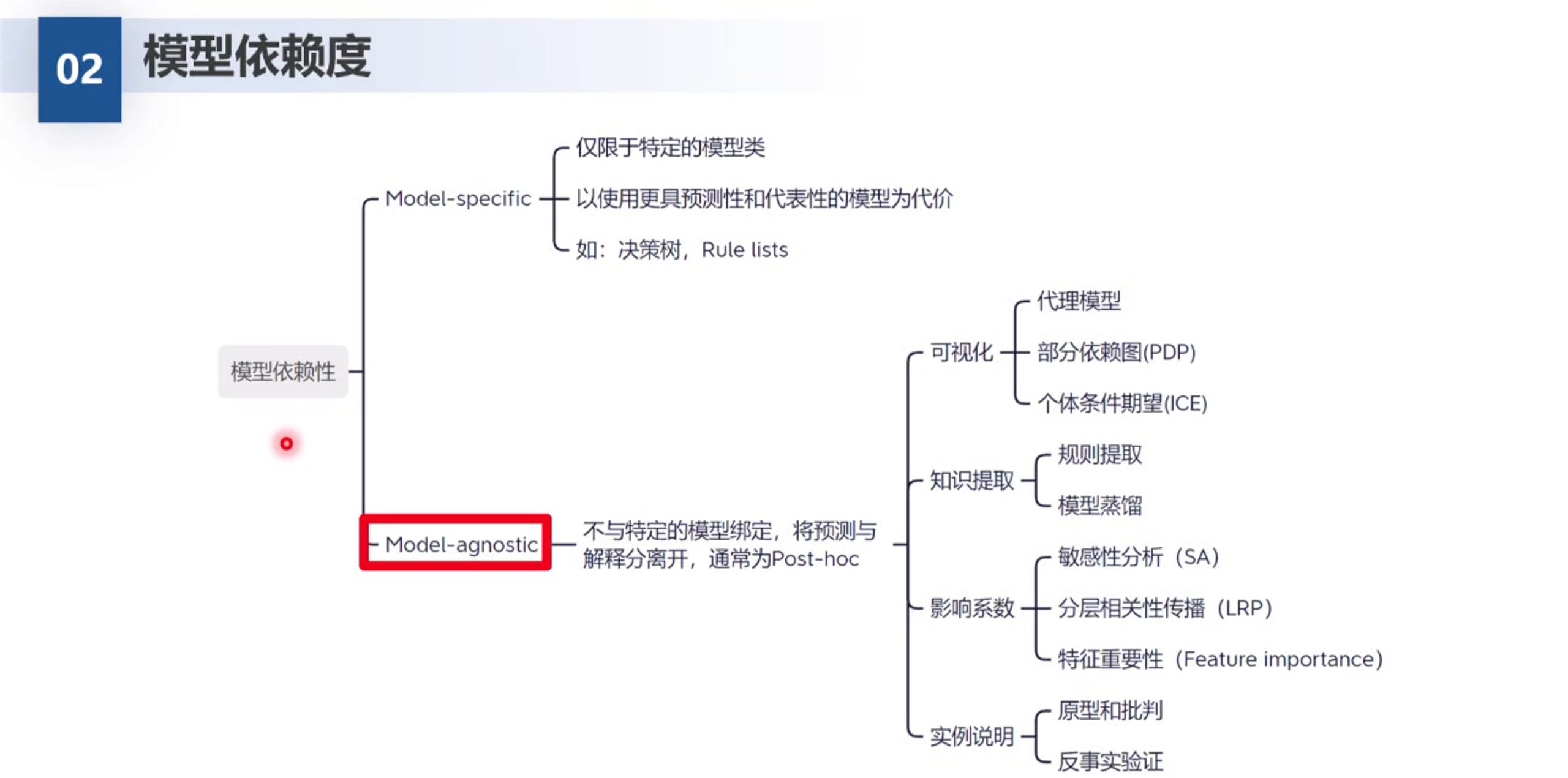
4. 模型依赖度 (Model Dependency)
这一维度关注的是解释方法与模型内部结构的耦合程度:是必须懂模型内部原理才能用,还是把模型当黑盒就能用。
Model-specific (特定于模型)
- 定义: 这种方法仅限于特定的模型类。它利用了模型内部的特定结构或参数来进行解释。
- 代价: 往往以牺牲模型的预测性能为代价,因为为了可解释性,我们可能被迫使用结构简单但预测能力较弱的模型。
- 典型例子:
- 决策树: 只能用于树模型的解释(查看分裂节点)。
- Rule lists (规则列表): 提取出的 "If-Then" 规则通常直接对应于模型内部的逻辑结构。
Model-agnostic (模型无关/通用)
- 定义: 这种方法不与特定的模型绑定 。它将模型的预测功能与解释过程分离开来。通常把模型视为一个黑盒,只关注输入数据和输出结果之间的关系。这类方法通常是 Post-hoc(事后) 的。
- 优势: 灵活性极高,可以应用于任何机器学习算法(从线性回归到深度神经网络)。
- 主要分类及方法:
- 可视化:
- 代理模型: 用一个简单的模型(如线性模型)去模拟复杂模型的行为并进行可视化。
- 部分依赖图 (PDP): 展示一个或两个特征对模型预测结果的边际效应(即:保持其他特征不变,改变该特征时,预测值如何变化)。
- 个体条件期望 (ICE): PDP的变体,展示单个样本在特征变化时的预测路径,比PDP更能揭示个体差异。
- 知识提取:
- 规则提取: 从复杂的黑盒模型中提取出人类可读的 "If-Then" 规则集。
- 模型蒸馏: 将大模型(Teacher)的知识转移到一个小的、可解释的模型(Student)中。
- 影响系数:
- 敏感性分析 (SA): 扰动输入特征,观察输出的变化幅度,以此衡量特征的重要性。
- 分层相关性传播 (LRP): 一种专门用于深度学习的归因方法,将预测分数从输出层逐层反向传播回输入层,确定每个像素的贡献。
- 特征重要性 (Feature Importance): 许多树模型(如Random Forest, XGBoost)自带的功能,衡量特征在分裂节点时带来的纯度提升总和。
- 实例说明:
- 原型和批判: 寻找最具代表性的样本(原型)和最能体现模型边界的异常样本(批判),通过举例来解释模型学到了什么。
- 反事实验证: 寻找最小的输入变化,使得模型的预测结果发生翻转(例如:"如果他的年收入增加5000元,贷款就会被批准")。
- 可视化:
总结
这两张图完善了XAI的方法论框架:
- 如果你想知道为什么这个具体的病人被诊断为患病 ,你需要 Local 方法(如SHAP)。
- 如果你想知道模型总体上是否利用了性别歧视来进行招聘筛选 ,你需要 Global 方法(如PDP)。
- 如果你使用的是一个现成的、无法修改内部代码的API模型,你必须使用 Model-agnostic 方法。
- 如果你正在设计一个新的医疗诊断系统,且医生要求完全透明,你可能会选择 Model-specific 的内在可解释模型(如决策树)。