大家好,我是孟健。GLM-5.2 是我最近用下来最意外的国产模型:它已经很接近 GPT、Claude 的第一梯队,但我不会建议你今天就把 Agent 全切过去。
01 先说结论:国内第一,但不是默认主力
我接触国产模型的时间不短了,大多数时候的结论都是"还行,但差一截"。GLM-5.2 是第一次让我觉得,这句话得改一改。
整体表现上,它已经是我用过的国内模型里最强的。跟 GPT、Claude 的顶级梯队比,差距已经不算特别大。但"不算特别大"和"可以替代"是两件事,后面我会细说。
在 AI 编程和 Agent 长任务这两个方向,国内模型之前很少能进入选型讨论------通常是"没有预算才用"或者排在最末位的备选。GLM-5.2 是第一次让我觉得,它有资格参与主力候选的对比,放进同一张选型表里认真看。
但今天你如果问我,要不要把所有 Agent 都切过去------不要。
衡量"能用"和"适合当主力",标准不同。能用,看能力上限。适合当主力,看稳定性、额度、生态接入成本。GLM-5.2 在能力上已经过了门槛,在后三项上还没到位。这三个问题,往下说。
02 真正变强的是长任务和 Agent 感
GLM-5.2 的官方定位是面向长任务的旗舰文本模型,支持 1M 上下文、最大输出 128K tokens。
这两个数字放在一起,意味着它可以一口气吃下一个中等规模的代码仓库,然后给你输出一份完整的重构方案。整个仓库丢进去,省掉分段喂或者靠外部向量检索补漏的步骤。对于需要跨文件理解的工程任务,这个上下文窗口是实打实的优势。
官方强调的场景是:项目级工程接管、长程重构、生产规范压力测试、移动端真机调试,以及微信小程序、小游戏、科研复刻这类有具体工程语境的任务。跟以往国产模型主打"通用能力"的定位不同,GLM-5.2 在往垂直工程方向走。
我自己用下来,印象最深的是复杂任务里的稳定性。以前用国产模型跑长流程 Agent,经常在中途出现上下文理解断层------前面定义过的变量命名规范,跑了几步之后就忘了,或者指令跟踪能力突然变差,前后不一致。GLM-5.2 在这方面好一些。推进一个多步骤的工程任务,它能跟下去的概率比之前明显高。跑完一个完整流程再出错,总比中途乱掉容易处理。
官方给出的基准数据:FrontierSWE 上仅落后 Opus 4.8 约 1%,超过 GPT-5.5 约 1%,超过 Opus 4.7 约 11%;SWE-Marathon 上与 Opus 4.8 仍有约 13% 的差距。
这组数字不是绝对真理,基准测试跟实际工程场景永远有出入。但趋势方向值得参考------在 SWE 这类编程任务基准上,国内模型第一次进入了可以和 Opus、GPT 并列放在一张表里讨论的位置,这本身就是信号。
03 问题也很现实:限流、倍数、额度消耗
能力强归能力强,用起来的摩擦感是真实存在的。
Coding Plan 有两层限额:每 5 小时一个额度上限,每周一个总额度。Lite 套餐大约 80 prompts / 5h,Pro 约 400/5h,Max 约 1600/5h------对应周额度分别约 400、2000、8000 prompts。
然后是倍数消耗。GLM-5.2 是高阶模型,对标 Claude Opus。高峰期(北京时间 14:00--18:00)按 3 倍额度消耗,非高峰期 2 倍。有个限时福利是非高峰 1 倍抵扣,持续到 9 月底。
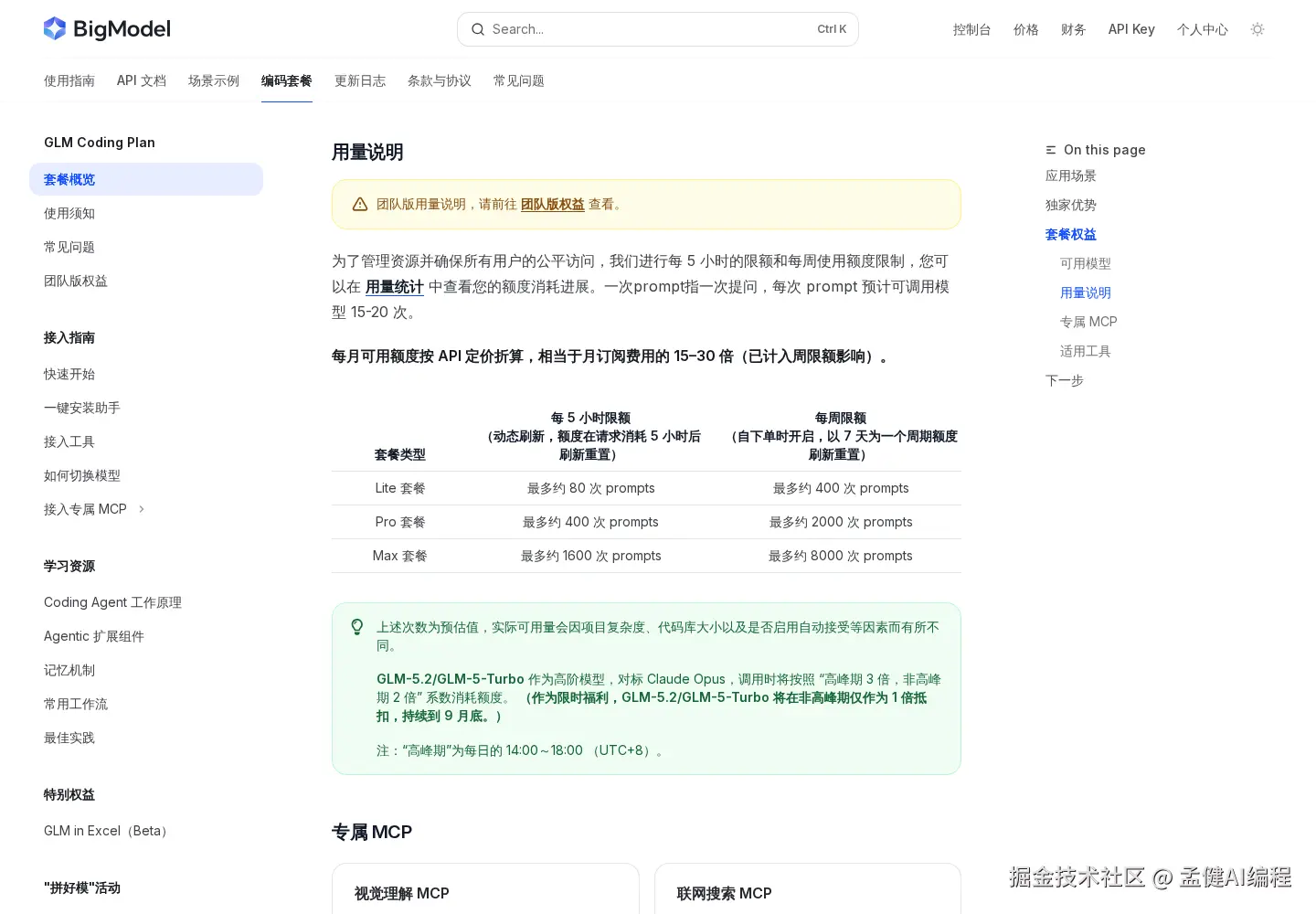
换算下来,一个跑得起来的 Agent 任务,在高峰期的消耗量非常可观。你以为在用 1 个 prompt,实际计费是 3 个。高强度工作流下,一天的额度在两三个小时里就能烧完。
我之前把三个 Agent 切到了 GPT,一周额度就耗光了。拿这个例子不是说 GPT 贵------高强度 Agent 使用下,任何模型的额度消耗都快。GLM 这边情况类似,高峰期 3 倍的乘数会把这个过程压缩得更短。
Pro 套餐每周 2000 prompts 听起来够,但高峰期全 3 倍消耗,实际能跑的 Agent 轮数打个折扣。想无限制地跑,基本得上千元的团队版。对比 200 美元的 GPT Pro,各有各的账本,很难简单比高下。
额度之外还有时间窗口的问题。高峰期限制明显,实际上会逼着你养成"大任务留到非高峰跑"的习惯。对有时间灵活性的工作流来说这可以接受,但如果你的 Agent 需要在工作时间全天候响应,这个限制会很快变成瓶颈。
04 接入不是无痛:工具链这里卡了很久
这一节是我觉得对高级用户最关键、但官方最不会主动说清楚的部分。
官方说法是 Coding Plan 套餐仅限在官方支持的工具/产品环境中使用。OpenClaw 被列为支持工具之一,但实际是采用次级调度与尽力交付策略,高负载下会动态排队、限流。
我这边实际接入时,遇到的问题更直接。Hermes 和 OpenClaw 的接入过程里,有明显的定向拦截------不改源码基本绕不过去。具体表现是请求能发出去,但返回要么超时,要么是拒绝类响应,跟普通限流的报错格式不一样,更像是识别到客户端特征之后的处理。
周围几个用同类工具的人也碰到了类似情况,大概率是系统行为,不是偶发。
这意味着什么?如果你的工作流依赖非官方渠道、或者自定义工具链,接入 GLM-5.2 的成本远比"换一下 API endpoint"高。要么改源码,要么换工具,要么接受次级调度带来的不稳定。
模型能力追上来之后,真正决定能不能落地的,往往是额度、生态和限制这三项现实问题。
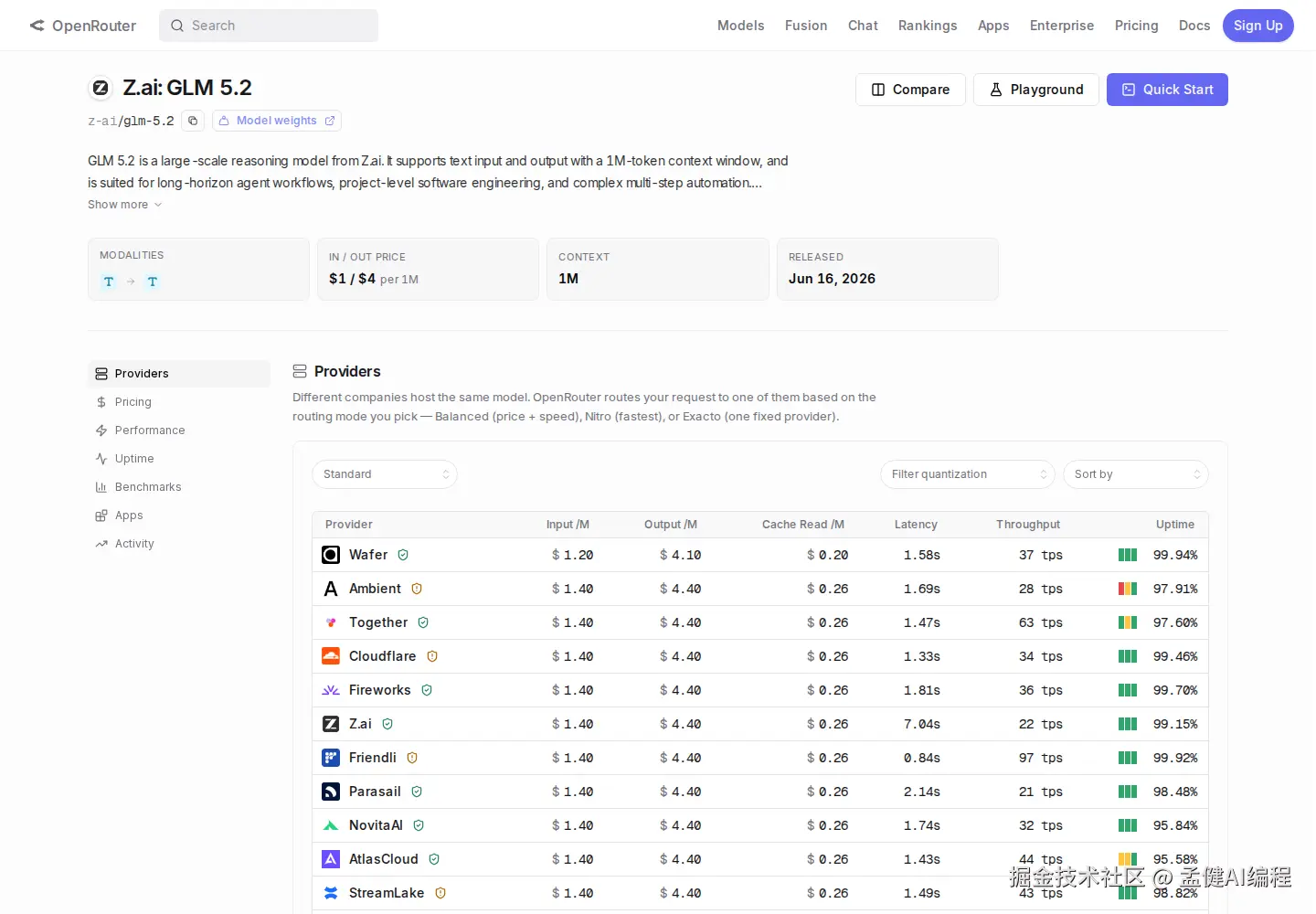
OpenRouter 上 GLM-5.2 目前的标价是 1.20input/4.10 output per 1M tokens,2026 年 6 月 16 日发布,HuggingFace 上有开放权重。如果你有自己的推理环境,这条路绕过 Coding Plan 的额度限制会更灵活。但自建推理的接入成本是另一个故事------GPU 资源、运维、延迟,每一项都要另算。
05 我的建议:别替代 GPT,把它放进模型组合
我现在的用法是把 GLM-5.2 当补位武器,不是主力。
GPT 安全限制太强的任务。 有些任务 GPT 的安全策略会拦截,或者拒绝走到底。GLM-5.2 在这方面限制相对宽松,可以接手 GPT 不愿意碰的部分。这是最直接的补位价值,不用改工作流,直接拿来填空。
长上下文仓库理解。 1M context 在这里是实打实的优势,尤其是需要一次性读完大量代码再做判断的场景------读取、分析、输出方案一次完成,比多轮分段喂效率高不少。适合用在"全量扫一遍再说"的分析类任务上。
国产环境和中文工程场景。 微信小程序、小游戏、国内特有技术栈,这些场景里 GLM 的工程上下文更贴近实际,值得单独测试,对比一下输出质量再决定要不要替换。
非高峰期的大任务。 凌晨或者早上跑,1 倍抵扣(限时福利到 9 月底)、非高峰期 2 倍消耗,是成本最优的时间窗口。跑时间长、对延迟不敏感的任务,排到这段时间最合适。
作为第二意见模型。 一个复杂决策让两个模型分别给出方案,再对比。GLM-5.2 有时候能从不同角度给出 GPT 没覆盖到的判断。互补的价值大于直接替代,用在最终决策前的校验环节效果不错。
不适合用在这几个场景:全天候高强度 Agent 群、需要无限制自动化、对稳定额度有要求的生产主链路。这些场景下,GLM-5.2 目前的限流和接入摩擦都会成为瓶颈,容易出现跑到一半卡住又得切回来的情况。
今天的国产模型,第一次让我觉得可以认真讨论"放在哪个位置用"这个问题,不只是追问"能不能用"。你不用再问国产模型能不能写代码了,这条已经过线了。现在该问的是:它适不适合进你的 Agent 预算表,放哪个位置,跟哪个主力模型搭配。
最危险的用法,是因为它能力强了,就把所有 Agent 一把切过去,然后在高峰期被限流卡死,再重新换回来。这个切换成本不低,来回折腾很容易浪费掉原本可以生产的时间。
GLM-5.2 的限制主要体现在额度能不能撑住你的用量,能力这边已经过线了。用对了位置,它是真实的增量。用错了位置,它的限制会比你想象的更快显现出来。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏