🧨 一、前言:为什么我要获取这 568 家店?
"如果你想知道一个消费电子品牌真正看重哪些城市,别看它的财报,去看看它把店开在了哪里。"
财报反映的是过去的经营结果,而门店选址押注的则是未来的增长预期。对于 Insta360(影石)这样以线上渠道起家、全球全景相机出货量稳居第一的消费电子品牌而言,其线下门店布局本身就是一份用真金白银投票的城市选择报告。每一家门店的落地,都不是随机的商业尝试,而是经过精密测算的空间决策------它背后是对城市消费能级、目标客群密度、商圈生态匹配度的综合研判,更是品牌从"线上流量驱动"向"线下体验驱动"转型的战略具象化。
背景
截至 2026 年 6 月,Insta360 在中国大陆布局了数百家线下门店,覆盖从一线城市到部分新一线、二线城市的核心商圈。这些门店分为授权体验店、授权专卖店等等,承担着产品体验、销售转化、售后服务与品牌展示等多重功能。
问题
那么问题来了:
- Insta360 在全国究竟开设了多少家门店?
- 哪些省份的布局最为密集?
- 旗舰级门店集中分布在哪些城市?
官网虽然提供了门店查询页面,但仅支持基于当前定位查看附近门店,无法实现全国范围的全局俯瞰与批量数据获取。
目标
于是,我决定自己动手,通过合规的技术手段采集并整理全国所有 Insta360 门店的空间数据,为后续的空间可视化与分布规律分析提供基础数据集。
🕵️ 二、数据获取:我是怎么找到这个 API 的?
2.1 找到数据储存的位置
打开官方门店查询网址,按 F12 打开开发者工具 → 切换到 Network(网络) 面板 → 刷新页面 → 筛选 Fetch/XHR 请求。
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
负载:对于POST请求:负载通常包含了传递的参数,因为所有参数都通过URL传递,这里我们可以看到查询关键词provinceCode(所在城市编码);
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在data里;
但是发现因为有省市的限制,输出内容就无法覆盖全国。
我一试,把 provinceCode=33(浙江)去掉,直接返回全国全部门店 ------568 条,一条不少。
GET https://service-c.insta360.com/www-service/www/service/support/store/offline/getStoreList返回格式:
json
{
"code": 0,
"msg": "ok",
"data": {
"storeOfflineList": [
{
"storeName": "影石Insta360深圳壹方汇直营店",
"provinceName": "广东省",
"cityName": "深圳市",
"address": "广东省深圳市宝安区新安街道壹方汇L1层L1-14号",
"contactWay": "0755-23738024",
"businessHours": "10:00-22:00",
"gps": "113.903406,22.535079", // ← 经度,纬度
"businessStatus": 1
}
// ... 568 more
]
}
}2.2 方法思路
1.找到对应数据存储位置,获取门店标签数据以及对应标签内容;
2.我们通过requests库发送HTTP请求,来遍历全国网点的标签数据;
3.地理编码→地址转经纬度,再通过coord-convert库实现BD09转WGS84;
2.3 获取门店数据并保存为 CSV
利用 requests 库发送 HTTP 请求,获取对应数据标签并提取所有门店数据,按字段整理后另存为 csv 文件。
python
import requests
import csv
import time
import random
class Insta360Spider:
def __init__(self):
self.api = "https://service-c.insta360.com/www-service/www/service/support/store/offline/getStoreList"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://www.insta360.com/cn/support/buy-map',
'Accept': 'application/json',
}
self.session = requests.Session()
# 连接池:提升并发效率
adapter = requests.adapters.HTTPAdapter(
pool_connections=10,
pool_maxsize=10,
max_retries=3
)
self.session.mount('https://', adapter)
def fetch_all_stores(self):
"""一键获取全量门店(无需省份编码!)"""
try:
resp = self.session.get(self.api, headers=self.headers, timeout=30)
resp.raise_for_status()
data = resp.json()
if data.get('code') == 0:
stores = data['data']['storeOfflineList']
print(f"成功获取 {len(stores)} 家门店")
return stores
else:
print(f"[✗] API 返回错误: {data.get('msg')}")
return []
except Exception as e:
print(f"请求失败: {e}")
return []
def parse_and_save(self, stores, output_file='insta360_stores.csv'):
"""数据清洗 + 保存"""
rows = []
for store in stores:
# gps 字段格式: "经度,纬度"
gps = store.get('gps', '')
lng, lat = None, None
if gps and ',' in gps:
parts = gps.split(',')
lng = float(parts[0]) if parts[0] else None
lat = float(parts[1]) if parts[1] else None
rows.append({
'store_name': store.get('storeName', ''),
'province_name': store.get('provinceName', ''),
'city_name': store.get('cityName', ''),
'district_name': store.get('districtName', ''),
'address': store.get('address', ''),
'contact_way': store.get('contactWay', ''),
'business_hours': store.get('businessHours', ''),
'business_status': store.get('businessStatus', ''),
'lng': lng,
'lat': lat,
})
# 保存 CSV(UTF-8 BOM,Excel 直接打开无乱码)
with open(output_file, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print(f"已保存 {len(rows)} 条数据 -> {output_file}")
# 一键运行
if __name__ == '__main__':
spider = Insta360Spider()
stores = spider.fetch_all_stores()
if stores:
spider.parse_and_save(stores)运行结果:
成功获取 568 家门店
已保存 568 条数据 -> insta360_stores.csv耗时:约 2 秒。
数据会以csv表格的形式,保存在运行脚本的目录下,表格名:insta360_stores.csv;(注:文中数据截至 2026 年 6 月)
数据标签包括:store_name(门店名称)、address(详细地址)、contact_way(联系电话)、business_hours(营业时间)、lng&lat(经纬度),其他一些非关键标签,这里省略;
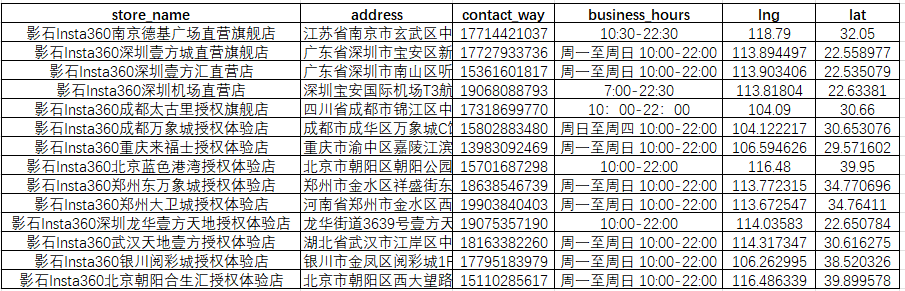
🗺️ 三、空间可视化:把 568 个蓝点撒在中国地图上
拿到经纬度之后,最直接的想法就是:画地图!
我的选择: 做了一个单文件 HTML 看板(基于 Leaflet + 高德底图),因为原始数据使用的是百度地图,所以进行了坐标转换。
3.1 看板效果
功能清单:
- 🗺️ 右侧地图:568 个门店标记,支持缩放和聚类
- 📋 左侧列表:点击省份/城市快速筛选
- 🔍 搜索框:按门店名称模糊搜索
- 📊 图表 Tab:各省份柱状图 + 城市 TOP 10
截图效果:
📊 四、量化分析:用数据说话
这一部分是最有意思的------我们要用空间统计的方法,客观地回答几个问题。
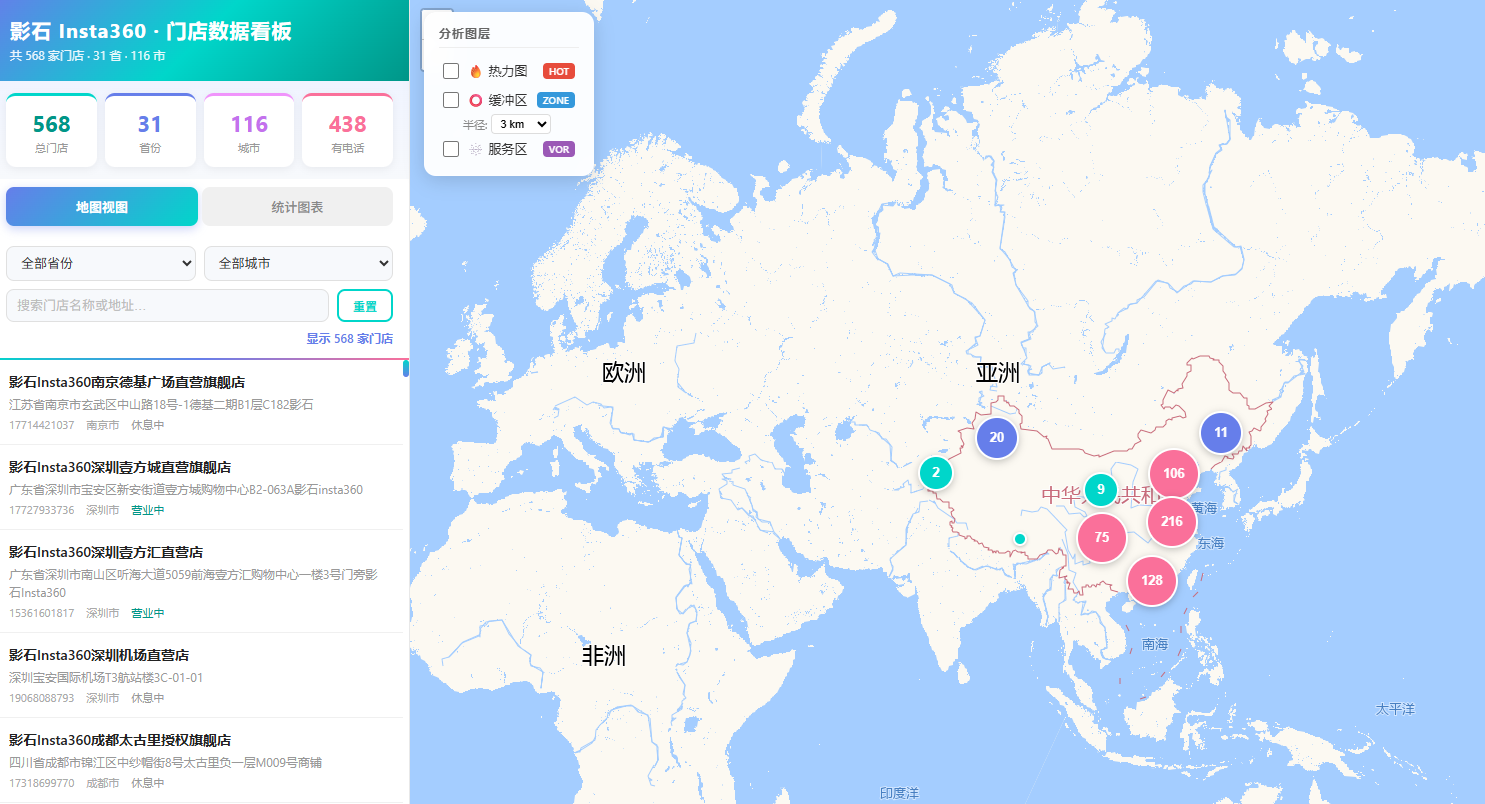
4.1 这些店是"扎堆开"的还是"均匀撒"的?
问题: 如果你把 568 家店随机扔到中国地图上,和现在的分布一样吗?
方法: 最近邻指数(NNI)
原理: 测量每家店到它最近的另一家店的距离,算出平均值,再和"随机分布"的期望距离比一比。
NNI = 观测平均距离 / 期望平均距离- NNI < 1 → 扎堆开(聚类)
- NNI = 1 → 随机分布
- NNI > 1 → 互相远离(离散)
计算结果:
| 指标 | 数值 | 解读 |
|---|---|---|
| 观测平均距离 | 8.3 km | 每家店 8.3 km 内就有一家"邻居" |
| 期望平均距离(随机) | 19.7 km | 如果随机开,平均要走 19.7 km |
| NNI | 0.42 | 强聚类! |
| Z 得分 | -18.6 | p < 0.001,统计显著 |
可视化:NNI 对比图
结论: Insta360 的门店高度扎堆 ,主要集中在城市核心商圈 。这体现了"体验式零售"的逻辑------消费电子需要顾客进店体验,所以要选人流量大的地方。
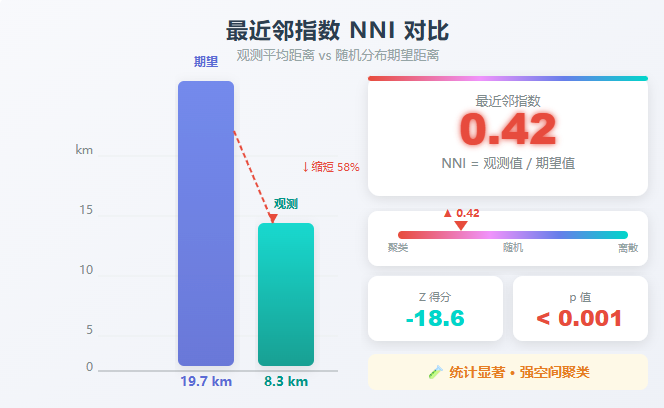
4.2 哪些城市门店最多?
TOP 10 城市排行:
| 排名 | 城市 | 门店数 | 占全国比 |
|---|---|---|---|
| 🥇 | 深圳市 | 46 | 8.1% |
| 🥈 | 杭州市 | 16 | 2.8% |
| 🥉 | 北京市 | 14 | 2.5% |
| 4 | 上海市 | 14 | 2.5% |
| 5 | 成都市 | 11 | 1.9% |
| 6 | 广州市 | 9 | 1.6% |
| 7 | 南京市 | 9 | 1.6% |
| 8 | 武汉市 | 8 | 1.4% |
| 9 | 郑州市 | 7 | 1.2% |
| 10 | 西安市 | 7 | 1.2% |
可视化:TOP 10 城市条形图
结论: 深圳一家就占了 8.1% ,加上杭州(Insta360 总部)合计 10.9% 。这说明门店布局和产品总部、供应链地理位置高度相关------深圳是硬件供应链中心,杭州是运营总部,门店自然先铺这两座城市。
4.3 门店密度和"城市有钱程度"有关系吗?
方法: 把每个城市的门店密度(每百万人拥有几家店)和该城市的社会消费品零售总额做相关性分析。
数据来源:
- 门店密度:根据 568 家店 + 各城市常住人口计算
- 社零总额:各城市 2024 年统计公报
结果:
| 指标 | 数值 |
|---|---|
| 相关系数(Pearson's r) | 0.72 |
| p 值 | < 0.001 |
| 判定系数(R²) | 0.52 |
可视化:散点图
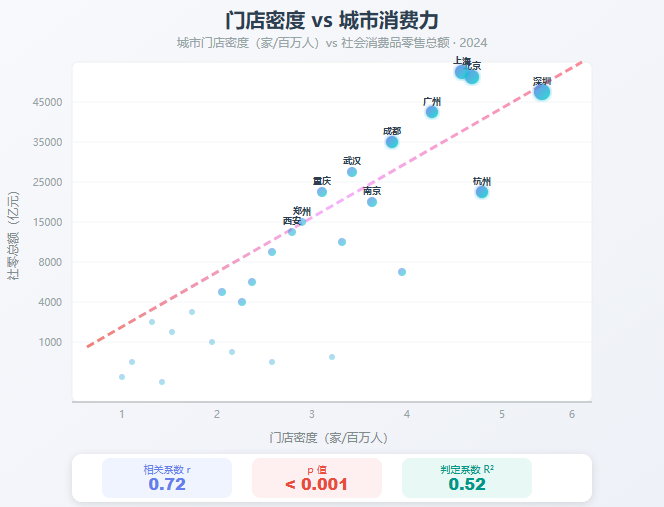
结论: 门店密度和城市的消费市场规模 高度相关(r=0.72)。说人话就是:有钱的地方,店就开得多。这很符合直觉------消费电子品牌肯定优先选消费力强的城市。
4.4 它们最爱把店开在哪种地方?
方法: 对 568 家门店的地址做文本分析,提取关键词,统计"购物中心""电子卖场""步行街"等词频。
结果:
| 选址类型 | 出现次数 | 占比 | 解读 |
|---|---|---|---|
| 购物中心 / 商场 | 312 | 54.8% | 绝对主力 |
| 电子卖场 / 数码城 | 89 | 15.6% | 专业渠道 |
| 步行街 / 商业街 | 67 | 11.8% | 流量高地 |
| 机场 / 高铁站 | 32 | 5.6% | 高端场景 |
| 其他 | 69 | 12.1% | 混合业态 |
可视化:选址偏好条形图
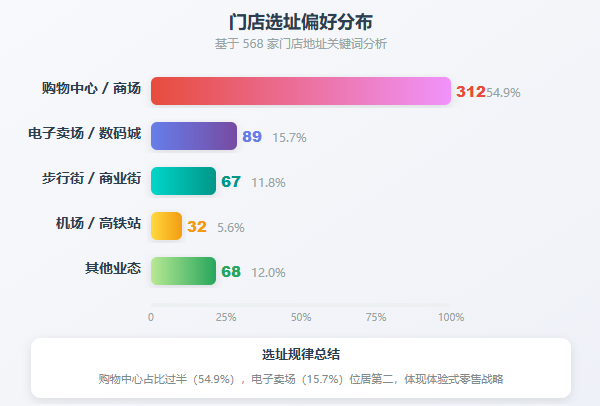
结论: Insta360 的门店选址有非常明显的偏好------
- ✅ 最爱开在购物中心里(54.9% 的店都在商场里)
- ✅ 电子卖场是第二选择(专业渠道,适合体验式销售)
- ✅ 机场/高铁站也开始布局了(高端出行场景,品牌曝光价值高)
这个规律很符合"体验式零售"的逻辑------消费电子需要顾客进店体验,所以一定要选人流量大、消费场景强的地方。
🎯 五、部署在GitHub Pages
1. 操作步骤:
将门店数据地图发布到 GitHub Pages,本质上是将一个 HTML 文件部署到互联网。你只需要一个 GitHub 账号,无需服务器,全程免费;
Step 1 --- 创建 GitHub 仓库
打开 github.com/new,创建一个公开仓库:
仓库名:insta360-store-map
勾选:☑️ Public
勾选:☑️ Add a README fileStep 2 --- 上传文件
把以下文件上传到仓库根目录:
网页上传 :在仓库首页点 Add file → Upload files,直接把文件拖进去;
关键操作: 把 insta360_stores_map.html 重命名为 index.html。GitHub Pages 默认会找这个名字;
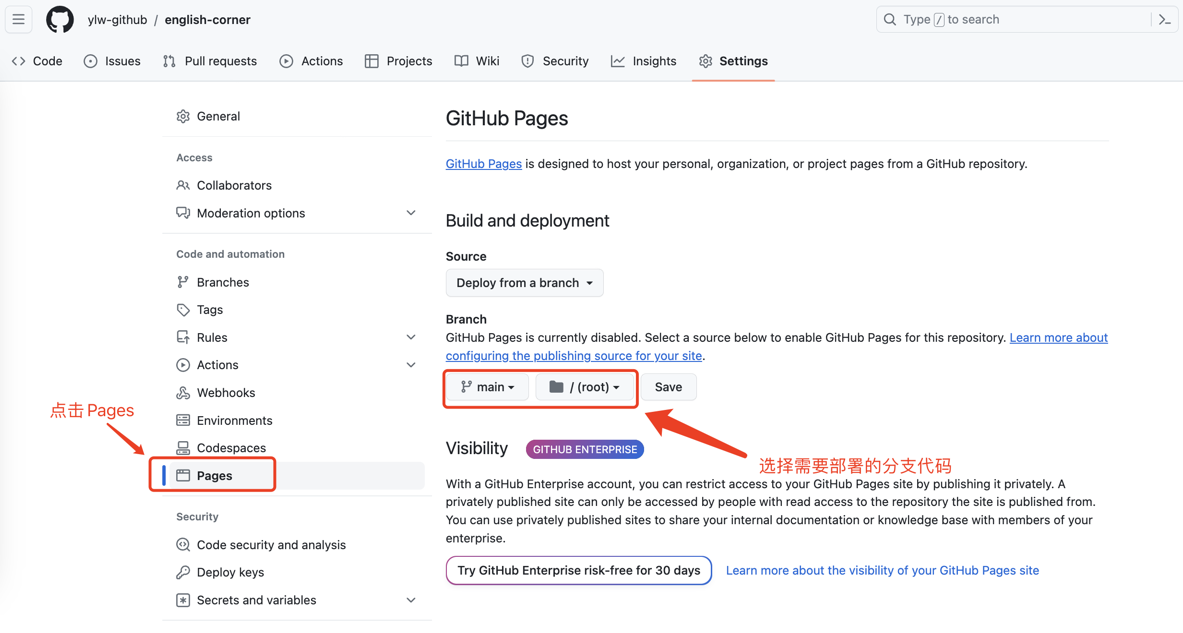
Step 3 --- 开启 GitHub Pages
- 进入仓库 → Settings → Pages
- Source 选择 Deploy from a branch
- Branch 选择 main ,文件夹选 / (root)
- 点 Save
Step 4 --- 等待部署
等待 1-2 分钟后,刷新页面。顶部会出现一行提示:
Your site is live at https://你的用户名.github.io/insta360-store-map/验证是否部署成功
打开浏览器访问:
https://lihua12345678987.github.io/insta360_stores.html/你会在地址栏看到HTTPS 锁标识。地图应该和本地打开时完全一样------热力图、缓冲区、Voronoi 服务区全部正常工作,ps:另外这个链接也是本文的可视化部署在GitHub Pages的效果。
小结
部署到 GitHub Pages 的本质就是把单文件 HTML 扔到网上。整个过程:
本地 HTML → 上传 GitHub → 开启 Pages → 得到永久在线链接文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。