文章目录
- [第1章 AI大模型基础](#第1章 AI大模型基础)
-
- [1.1 AI人工智能概述](#1.1 AI人工智能概述)
- [1.2 人工智能的发展阶段](#1.2 人工智能的发展阶段)
-
- [1.2.1 机器学习(AI的核心实现方法)](#1.2.1 机器学习(AI的核心实现方法))
- [1.2.2 深度学习(机器学习的进阶分支)](#1.2.2 深度学习(机器学习的进阶分支))
- [1.2.3 大语言模型(LLM,深度学习的落地产物)](#1.2.3 大语言模型(LLM,深度学习的落地产物))
- [1.2.4 Transformer 架构](#1.2.4 Transformer 架构)
- [第2章 部署大模型](#第2章 部署大模型)
-
- [2.1 常见大模型平台](#2.1 常见大模型平台)
- [2.2 阿里百炼平台](#2.2 阿里百炼平台)
-
- [2.2.1 注册阿里百炼平台](#2.2.1 注册阿里百炼平台)
- [2.2.2 使用模型](#2.2.2 使用模型)
- [2.3 Ollama模型](#2.3 Ollama模型)
-
- [2.3.1 安装Ollama](#2.3.1 安装Ollama)
- [2.3.2 部署本地大模型](#2.3.2 部署本地大模型)
- [2.4 大模型与大模型应用](#2.4 大模型与大模型应用)
- [2.5 大模型开发架构](#2.5 大模型开发架构)
-
- [2.5.1 Prompt 模式](#2.5.1 Prompt 模式)
- [2.5.2 FunctionCalling 模式](#2.5.2 FunctionCalling 模式)
- [2.5.3 RAG 模式](#2.5.3 RAG 模式)
- [2.5.4 Fine-tuning 模式](#2.5.4 Fine-tuning 模式)
- [第3章 Spring AI](#第3章 Spring AI)
-
- [3.1 Spring AI 概述](#3.1 Spring AI 概述)
-
- [3.1.1 背景](#3.1.1 背景)
- [3.1.2 诞生意义](#3.1.2 诞生意义)
- [3.1.3 Spring AI 与其他AI框架的区别](#3.1.3 Spring AI 与其他AI框架的区别)
- [3.3 Spring AI 快速入门](#3.3 Spring AI 快速入门)
-
- [3.3.1 接入Ollama本地模型](#3.3.1 接入Ollama本地模型)
- [3.3.2 接入DeekSeep大模型](#3.3.2 接入DeekSeep大模型)
- [3.3.2 接入阿里百炼大模型](#3.3.2 接入阿里百炼大模型)
- [3.4 Spring AI核心类的使用](#3.4 Spring AI核心类的使用)
- [第4章 AI 智能机器人案例](#第4章 AI 智能机器人案例)
-
- [4.1 环境搭建](#4.1 环境搭建)
-
- [4.1.1 基础环境](#4.1.1 基础环境)
- [4.1.2 对接前端](#4.1.2 对接前端)
- [4.2 Advisors](#4.2 Advisors)
-
- [4.2.1 SimpleLoggerAdvisor](#4.2.1 SimpleLoggerAdvisor)
- [4.2.2 SafeGuardAdvisor](#4.2.2 SafeGuardAdvisor)
- [4.2.3 ToolCallAdvisor](#4.2.3 ToolCallAdvisor)
- [4.6 ChatMemory](#4.6 ChatMemory)
-
- [4.6.1 MessageWindowChatMemory](#4.6.1 MessageWindowChatMemory)
- [4.6.2 自定义ChatMemory](#4.6.2 自定义ChatMemory)
- [4.7 ChatMemoryRepository](#4.7 ChatMemoryRepository)
-
- [4.7.1 InMemoryChatMemoryRepository](#4.7.1 InMemoryChatMemoryRepository)
- [4.7.2 JdbcChatMemoryRepository](#4.7.2 JdbcChatMemoryRepository)
- [4.7.3 自定义 ChatMemoryReposity](#4.7.3 自定义 ChatMemoryReposity)
第1章 AI大模型基础
1.1 AI人工智能概述
传统计算机只会"按指令干活"(比如计算、存储、固定流程运算),人工智能让机器学会"动脑思考",可以自主识别、判断、学习、变通,不再局限于固定程序。
AI,人工智能(A rtificial I ntelligence):人工智能是一门融合计算机科学、数学、心理学、语言学的交叉学科,核心目标是让机器模拟、延伸和扩展人类的感知、推理、学习、决策、创造等智能行为,让机器具备类人的智能能力,使机器能够像人类一样思考、学习和解决问题的技术。
- 弱人工智能(当前主流):专注单一任务的智能,如人脸识别、语音转文字、聊天问答、图像生成,只能擅长特定领域,无通用思维;
- 强人工智能(未实现):具备和人类对等的通用认知能力,可自主思考、跨领域学习、拥有主观意识,属于未来技术。

标志性时间与事件:
- 2006年:辛顿提出深度置信网络,解决深层神经网络梯度消失难题,深度学习正式诞生;
- 2012年:AlexNet模型问世,在图像识别赛事中碾压传统算法,证明深度学习的巨大优势,拉开AI工业化序幕;
- 2017年:Google发布Transformer架构,彻底革新自然语言处理技术,成为后续所有大模型的底层核心骨架;
- 2018年:首个预训练大模型BERT诞生,NLP任务精度大幅提升;
- 2022年:OpenAI发布ChatGPT,大模型正式走入大众视野,通用人工智能落地普及;
- 2023--2025年:国产大模型快速崛起(文心一言、通义千问、星火大模型等),大模型进入多模态、轻量化、行业落地阶段。
1.2 人工智能的发展阶段
1.2.1 机器学习(AI的核心实现方法)
传统编程是"人告诉机器每一步怎么做",机器学习是"人给机器大量案例,机器自己学会怎么做"。机器学习是人工智能的核心分支,是一种数据驱动的算法范式,无需人工编写固定规则,通过机器对海量数据的学习,自动总结规律、优化模型,最终实现预测与决策。
但是,机器很 "笨",不会自己观察总结 。你给它一堆猫狗图片,必须人工提前告诉它规则 :猫 = 尖耳朵、有胡须、小脸;狗 = 大耳朵、长嘴巴。机器只能按照你人工给的固定特征去判断。
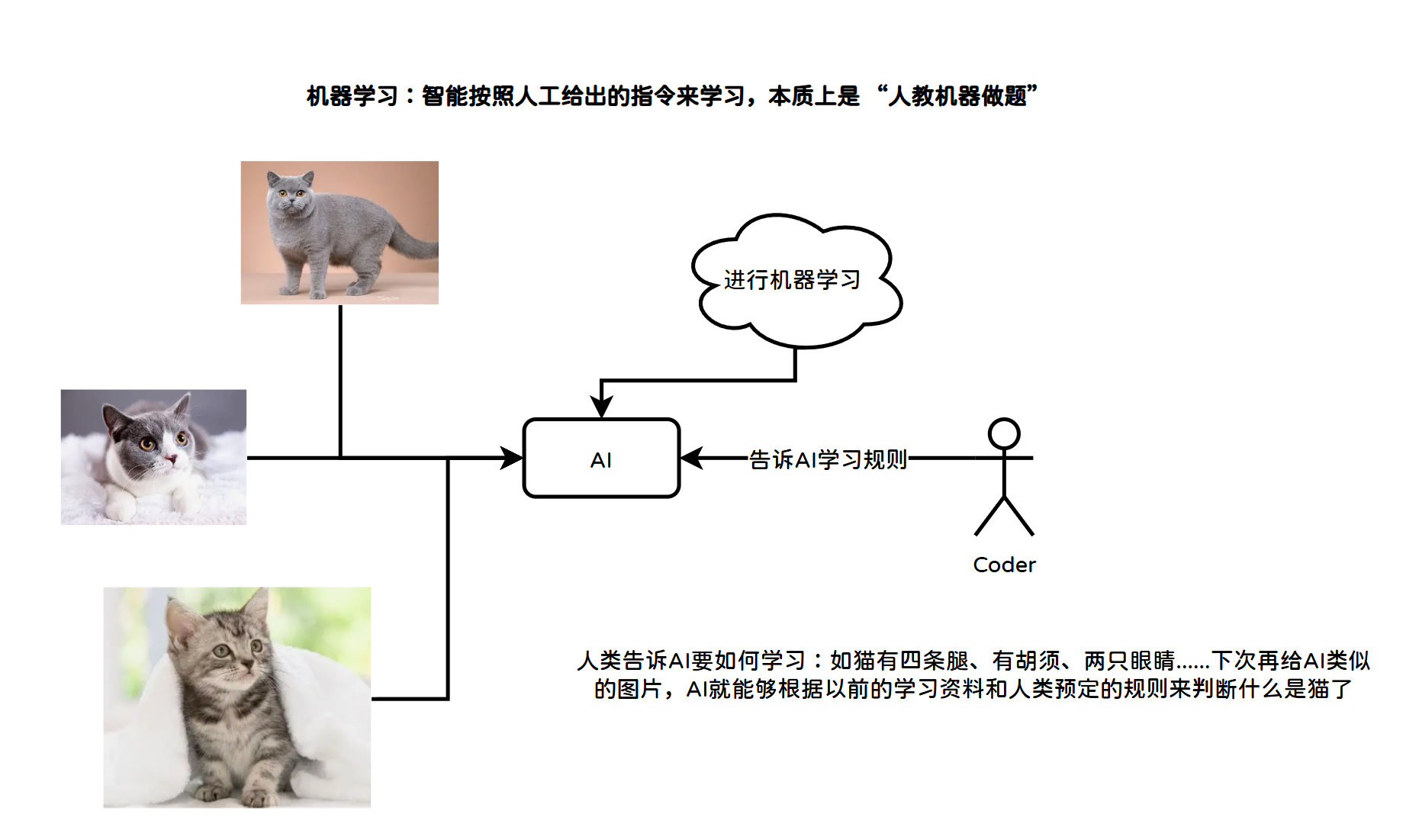
机器学习的弊端:复杂特征(毛发纹理、眼神、体态、模糊角度)人类总结不出来 ,所以机器学不会、识别不准。不需要超大批量数据,少量规整数据就能学完,学完就无法自我升级。
1.2.2 深度学习(机器学习的进阶分支)
深度学习是基于多层人工神经网络的机器学习方法,通过模拟人类大脑神经元的分层传递机制,自动提取数据的浅层、中层、深层特征,解决复杂场景的非线性拟合问题。
普通机器学习只能学习简单、直观的规律;深度学习通过"多层神经网络",像人脑一样层层拆解信息,能读懂复杂数据(文字、图像、语音)的深层含义。
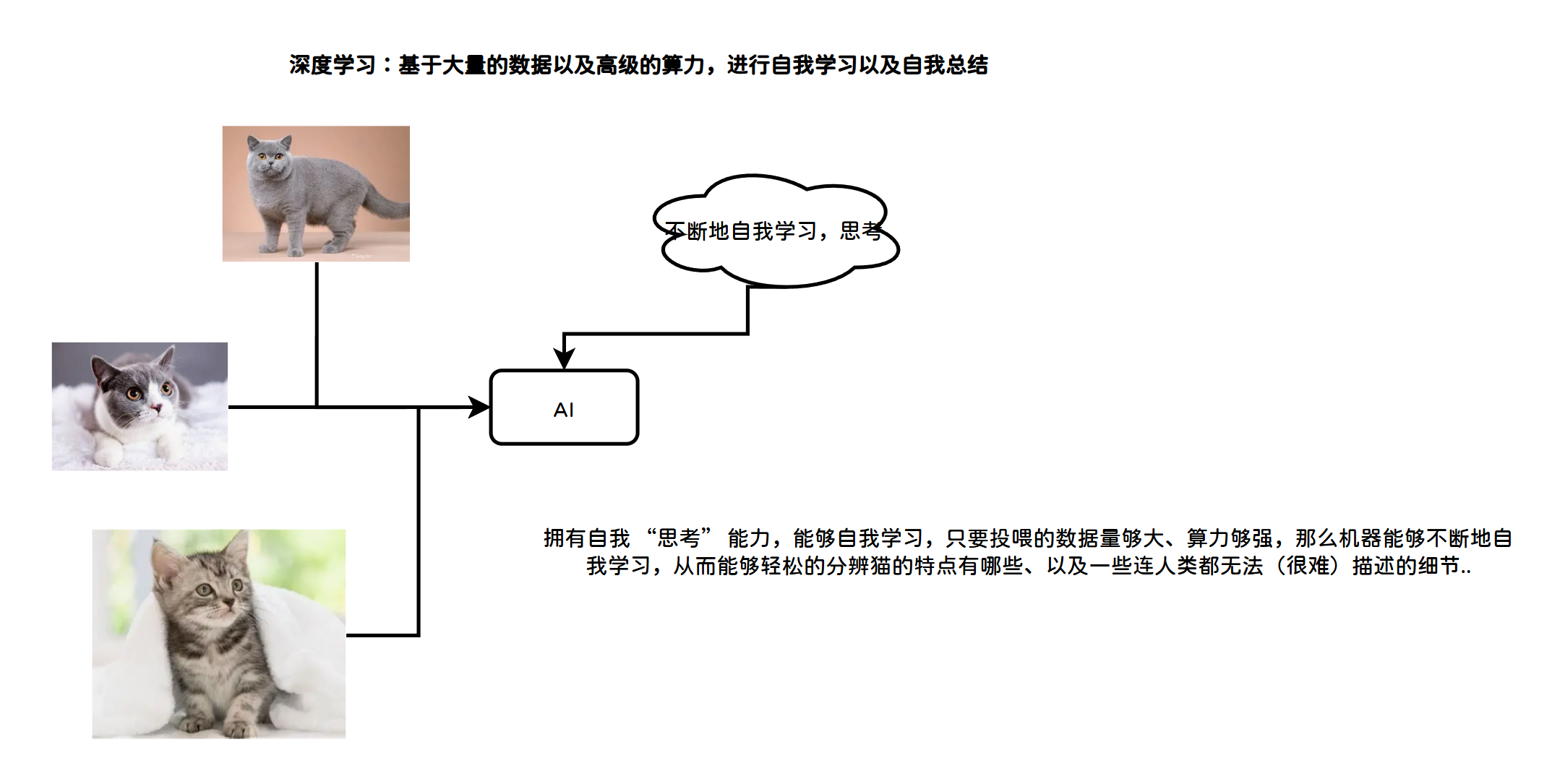
在深度学习中,机器是 "自主学习",全程不需要人工干预特征 。你直接扔几万张、几十万张猫狗原图,什么规则都不用告诉它 。它靠多层神经网络自动分层学习:
例如:第一层学线条、轮廓;第二层学五官、纹理;第三层学整体形态、细微差异;最后自己总结出一套人类都说不清的复杂判断逻辑。
举个极端例子:机器通过深度学习大量资料,觉得人类描述的猫不够准确,AI能够描述出比人类还符合猫本身的定义的词汇。
深度学习的核心支撑**:大数据(海量学习素材)**+ 高算力(快速运算) + 深层网络算法(学习框架)。
- 神经网络:人工智能的领域非常多,大致可以分为神经网络与非神经网络两大类。
- 非神经网络:SVM、决策树、逻辑回归、贝叶斯等算法,人工手工提取特征
- 神经网络(人工神经网络):利用特定算法和规则来模仿动物神经网络行为特征。原始数据直接喂入,不用人工造特征,多层网络逐层自动提炼底层→高层特征。输入原图即可,机器自己学边缘、轮廓、五官。像:CNN 图像、RNN 时序、Transformer→大语言模型等领域都是神经网络应用领域。
神经网络模型是所有深度学习领域的奠基石,包括CNN、RNN、Transformer,再到现在流行的LLM(大语言模型)都是基于深度学习的落地应用。
1.2.3 大语言模型(LLM,深度学习的落地产物)
深度学习是依托多层人工神经网络、自动特征学习的整套算法范式统称,是实现 AI 的技术手段。适用全模态任务:图像识别、语音识别、推荐算法、风控预测、文字生成全部都能用深度学习。包含 CNN 卷积网络(看图)、RNN 循环网络、Transformer(做大模型)等多种网络结构。
大语言模型 (L arge L anguage M odels, LLM),简称"大模型",采用深度学习中的 Transformer 架构的超大参数深度学习模型,只聚焦自然语言。依托海量文本数据预训练而成的超大参数规模深度学习模型,专注于自然语言处理(NLP),具备上下文理解、逻辑推理、文本生成、知识问答、工具调用等通用语言能力。
大模型的目标是理解人类文字、上下文对话、逻辑推理、文本生成,只处理文本数据。代表有:GPT 系列、通义千问、文心一言等。
1)CNN架构-卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
AI最早是在图像上发展起来的,像早期的人脸识别、图像识别、以图搜物等。这些AI智能体都是依靠于早期的CNN架构。以一张"猫"的图片为例,为什么人类一眼就能识别这张图片是猫呢?因为人类会抓住关键特征!例如有胡须、两只眼睛,尖尖的耳朵等。
人看图片是先看局部细节,再整合整体,CNN 模仿这个逻辑:用小型卷积核(小窗口)在图片上滑动,逐块提取局部特征。
- 浅层卷积:提取线条、边缘、色块;
- 中层卷积:提取轮廓、五官、部件;
- 深层卷积:提取整体特征(人脸、猫狗外形)。
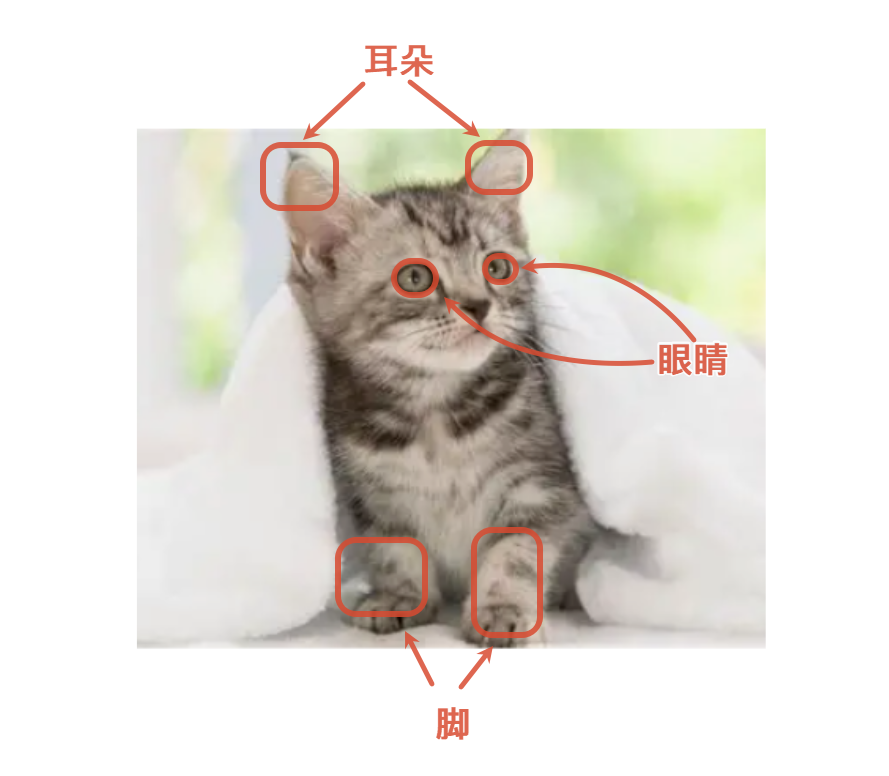
通过卷积核去扫描图片的每一个像素点,然后综合对比这一块区域的综合特征,这个通过卷积核来扫描像素点的过程就称为卷积。CNN的优秀推理能力,使得其在图像分类、人脸识别、目标检测、图片抠图、医学影像识别、摄像、美颜等领域应用广泛。
一段句子不属于局部特征能够描述出来的,而是结合语境顺序来决定其含义。因此,CNN虽然在图像识别领域应用官方,但也有一个致命的缺点。那就是没有时序理解能力,看不懂先后顺序,不能处理句子、语音这类有序序列。
2)RNN架构-循环神经网络
循环神经网络(Recurrent Neural Network, RNN)用于处理序列数据。其最大特点是网络中存在着环,使得信息能在网络中进行循环,实现对序列信息的存储和处理。

例如:RNN架构在处理"我吃苹果"这一段文本时,按照顺序逐个文字读取,读到"我"时,知道在这段句子中"我"是主语,是"我"要来干xxx,读到"吃"再结合前面的语境就知道是"我在吃",最后读取到"苹果"是能推断出"我要吃的对象是苹果"。
RNN在处理文本时,会一个字一个字的计算,每读取到一个词的时候都会将该词语存储到"隐藏状态"中,下一个词的计算必须要用到该隐藏状态,必须要结合上一个词语才能推断整体的含义。RNN的应用范围也非常广泛,例如在翻译、情感分析等领域。
但RNN有两个致命缺陷,直接卡死了 AI 的能力上限:
- 串行计算,速度极慢:必须一个字一个字按顺序读,读完第 1 个字才能读第 2 个字,无法并行计算,训练速度上不去,根本没法用海量数据训练大模型;
- 长距离依赖丢失:RRN"记性差",读长句子时,在读到末尾时,前面的内容会被 "遗忘"。比如读一篇 1000 字的文章,读到最后一句时,模型已经记不住开头讲了什么,无法理解上下文的深层逻辑。
想象一下:老师把一篇 1000 字的文章,写在一张纸条上,让全班同学排成一条长队,按顺序传纸条答题。
- 规则 1:只能一个人接一个人传,第 1 个同学看完第 1 个字,才能传给第 2 个同学看第 2 个字,绝对不能同时看;
- 规则 2:每个人只能记住前一个人告诉自己的内容,不能回头看纸条前面的字。
更糟糕的是:每传一次,信息就会模糊一点。比如第 1 个同学说 "我",第 2 个同学可能记成 "俺",第 3 个同学可能记成 "他",传到最后,前面的信息已经完全失真了。
这就是 RNN 的1:1 工作方式,两个致命缺陷就是这么来的。所以训练一个 RNN 模型,处理 100 万条文本,可能要跑几个月;根本不可能用 "亿级文本、千亿参数" 去训练大模型 ------ 等模型训练完,可能都过去好几年了。
用 RNN 读一篇 1000 字的文章,读到最后一句时,模型已经完全记不住开头讲了什么;比如你问 RNN:"文章开头提到的小明,最后怎么样了?",它根本答不上来;这就是为什么 RNN 只能处理短句子、简单对话,永远做不出能理解长文、逻辑推理的大模型。
1.2.4 Transformer 架构
Transformer 的核心革命 :彻底抛弃了循环结构,只用自注意力机制(Self-Attention) 处理序列数据,同时解决了 "并行计算" 和 "长距离依赖" 两大难题。这也是为什么现在所有大语言模型、多模态模型,底层全都是 Transformer 的原因 ------ 它是第一个能支撑 "超大参数 + 海量数据" 训练的 AI 架构。
Transformer 彻底推翻了 RNN 的所有规则,换了一套全新的玩法:
- 老师把 1000 字的文章,复印 1000 份,发给全班 1000 个同学;
- 所有同学同时拿到完整的文章,同时开始读;
- 读完之后,每个同学都可以自由和其他任何同学交流,问任何一个字的意思、任何一句话的关系。
这就是 Transformer 的1:1 工作方式,两个问题同时解决了:
- 怎么解决 "串行计算,速度极慢"?
- 1000 个同学同时读完整篇文章,不需要排队;
- 1000 字的文章,原来 RNN 要 1000 步才能读完,Transformer1 步就搞定了;
- 有多少算力,就能同时处理多少字,速度直接提升几百上千倍。
对应技术现实:
- 现在训练一个千亿参数大模型,用几千张 GPU 并行计算,只需要几周就能完成;
- 这是 "大模型" 能诞生的最核心前提------ 没有并行计算,就不可能用海量数据训练超大模型。
- 怎么解决 "长距离依赖丢失"?
- 每个同学手里都有完整的文章,想知道第 1 个字是什么,直接看自己手里的文章就行,不需要问别人;
- 当读到 "他" 这个字时,同学可以直接去看文章开头的 "小明",立刻知道 "他" 指的是谁;
- 不管两个字隔了 100 字还是 1000 字,都能直接建立联系,信息永远不会丢失、不会模糊。
因此,大模型可以读几万字、几十万字的长文,并且能记住开头的每一个细节;比如你问 ChatGPT:"这篇 5 万字的论文,第 3 页提到的公式,在第 10 页是怎么应用的?",它能精准回答;这就是大模型能理解上下文、做逻辑推理、写长文章的根本原因。
1)注意力机制
自注意力机制 = 让模型读句子时,自动 "重点关注" 和当前词相关的所有词,忽略无关词。
举个例子:读句子 "小明把他的苹果递给了小红"
- 当模型读到 "他" 这个字时,会自动把注意力集中在 "小明" 身上(知道 "他" 指的是小明);
- 当模型读到 "苹果" 时,会自动关注 "递给" 和 "小红"(知道苹果是被递给小红的);
- 完全不会浪费算力在无关的词上。
这和人类读句子的逻辑一模一样:我们不会平均分配注意力给每个字,而是会自动关联上下文,抓住核心语义关系。
自注意力的本质:把每个词的语义,重新编码成 "融合了整个句子上下文的语义"。比如原来的 "苹果" 只是一个孤立的词,经过自注意力后,就变成了 "小明递给小红的那个苹果",包含了完整的上下文信息。
2)多头注意力
多头注意力 = 多个自注意力机制并行工作,每个头关注不同的语义关系,最后把结果综合起来。
还是用刚才的句子 "小明把他的苹果递给了小红":
- 第 1 个头:关注 "主语 - 动作" 关系(小明 - 递);
- 第 2 个头:关注 "动作 - 宾语" 关系(递 - 苹果);
- 第 3 个头:关注 "指代关系"(他 - 小明);
- 第 4 个头:关注 "动作 - 对象" 关系(递 - 小红);
每个头从不同角度理解句子,最后把所有头的输出拼接起来,就能得到更全面、更准确的语义表示。
第2章 部署大模型
大模型应用开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互,让我们的传统应用可以接入大模型,实现传统应用的智能化。
企业首先需要有一个可访问的大模型,通常有三种选择:
- 使用开放的大模型API:
- 优点:
- 没有部署和维护成本,按调用收费
- 缺点:
- 依赖平台方,稳定性差
- 长期使用成本较高
- 数据存储在第三方,有隐私和安全问题
- 优点:
- 在云平台部署私有大模型
- 优点:
- 前期投入成本低
- 部署和维护方便
- 网络延迟较低
- 缺点:
- 数据存储在第三方,有隐私和安全问题
- 长期使用成本高
- 优点:
- 在本地服务器部署私有大模型
- 优点:
- 数据完全自主掌控,安全性高
- 不依赖外部环境
- 虽然短期投入大,但长期来看成本会更低
- 缺点:
- 初期部署成本高
- 维护困难
- 优点:
2.1 常见大模型平台
通常发布大模型的官方、大多数的云平台都会提供开放的、公共的大模型服务。国内提供大模型服务的云平台如下:
| 云平台 | 公司 | 地址 |
|---|---|---|
| 阿里百炼 | 阿里巴巴 | https://bailian.console.aliyun.com/ |
| JoyAI( "言犀") | 京东 | https://yanxi.jd.com/ |
| 千帆平台 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| 盘古大模型 | 华为 | https://www.huaweicloud.com/pangu.html |
| 火山方舟-火山引擎 | 字节跳动 | https://www.volcengine.com/product/ark |
| DeepSeek 开放平台 | DeepSeek | https://www.deepseek.com |
| 360 智脑、纳米 AI | 360 | https://ai.360.cn |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
开放平台并不是免费,而是按照调用时消耗的token来付费,每百万token通常在几毛~几元钱,而且平台通常都会赠送新用户百万token的免费使用权。(token可以简单理解成你与大模型交互时发送和响应的文字,通常一个汉字2个token左右)
2.2 阿里百炼平台
阿里百炼(Model Studio) 是阿里云推出的一站式大模型开发与应用平台 ,2023 年 10 月上线,核心是 "通义千问 + 第三方模型 + 低代码 / 零代码工具链",面向企业和开发者提供从模型调用、微调、知识库到智能体应用的全链路服务。
官网:https://bailian.console.aliyun.com/
2.2.1 注册阿里百炼平台
1)首先需要注册一个阿里云账户(使用手机号注册即可)
2)在阿里云百炼平台中创建一个API key
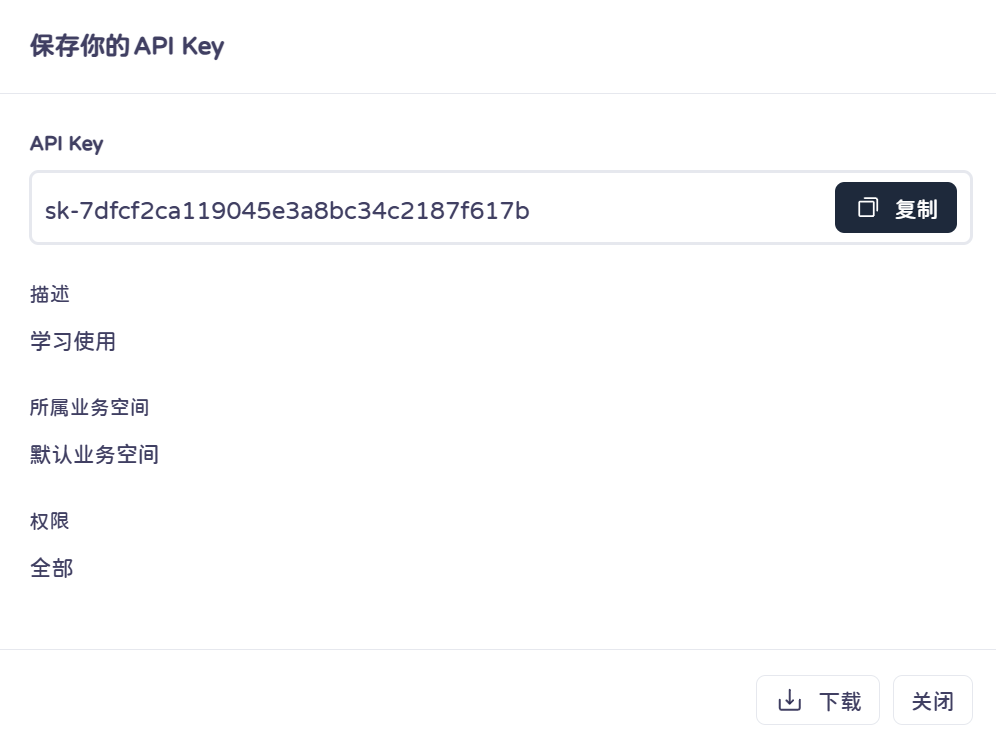

API key注意要保密,不能泄露。
shell
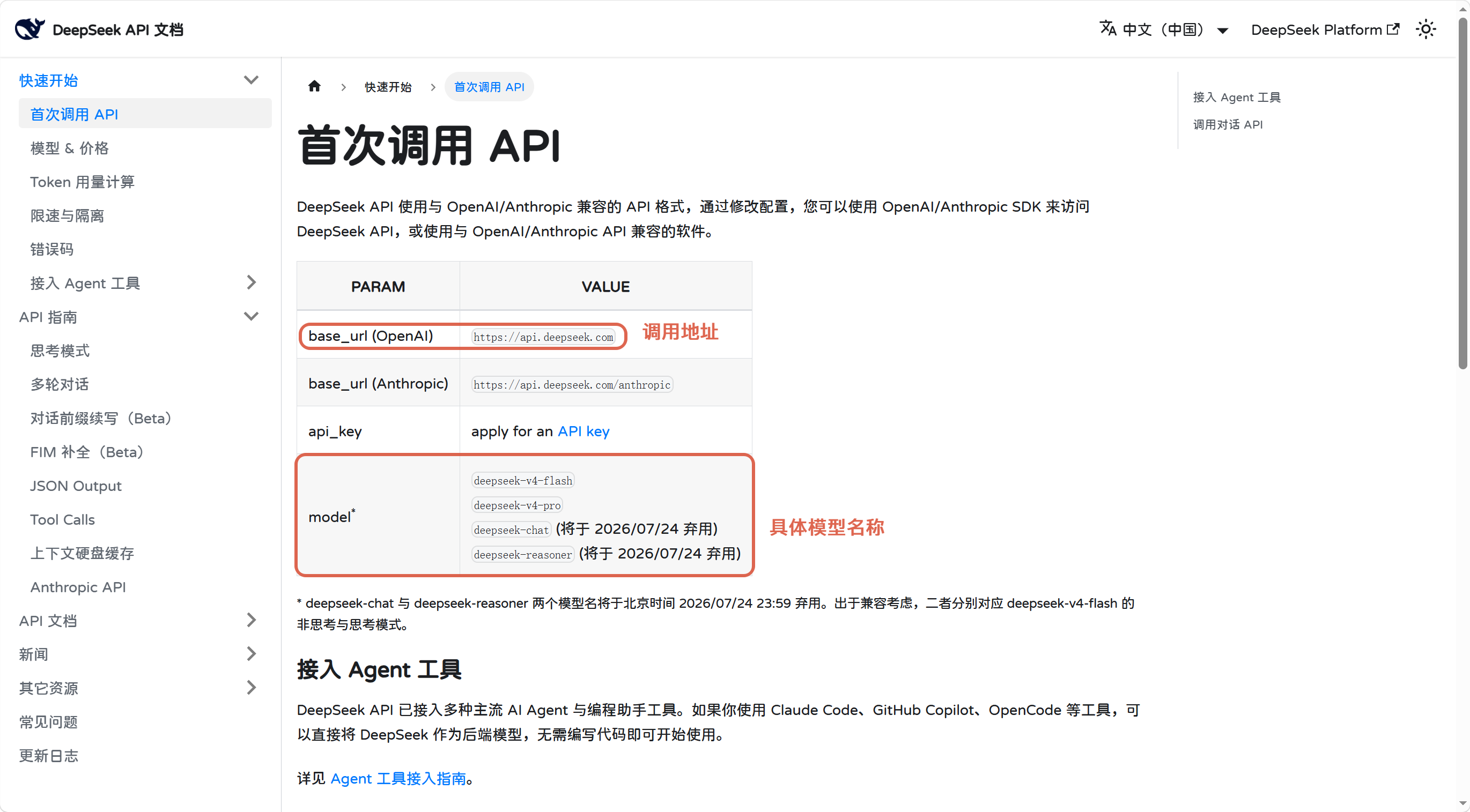
sk-7dfcf2ca119045e3a8bc34c2187f617b2.2.2 使用模型
在阿里云百炼大模型的模型广场中,有很多模型都可以体验:
地址:https://bailian.console.aliyun.com/cn-beijing?tab=model#/model-market
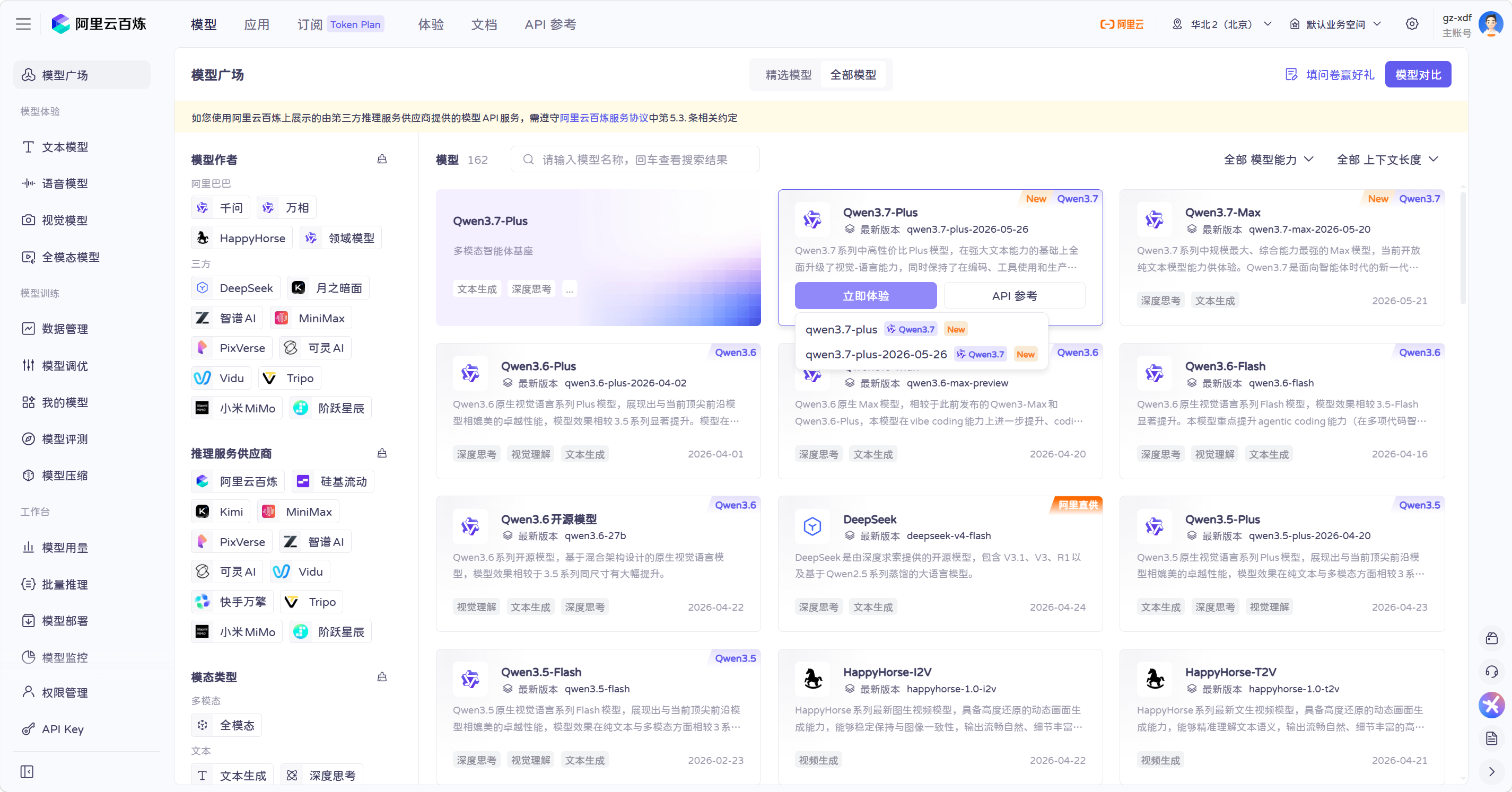
1)体验大模型
模型广场中有非常多的大模型,包括文本、语音、视觉、全模态等模型,我们可以选择对应的模型来体验:
2)API调用大模型
点击指定大模型的API参考,就会有具体的API接入文档了,包括不同的编程语言如何接入API、如何调用API等。
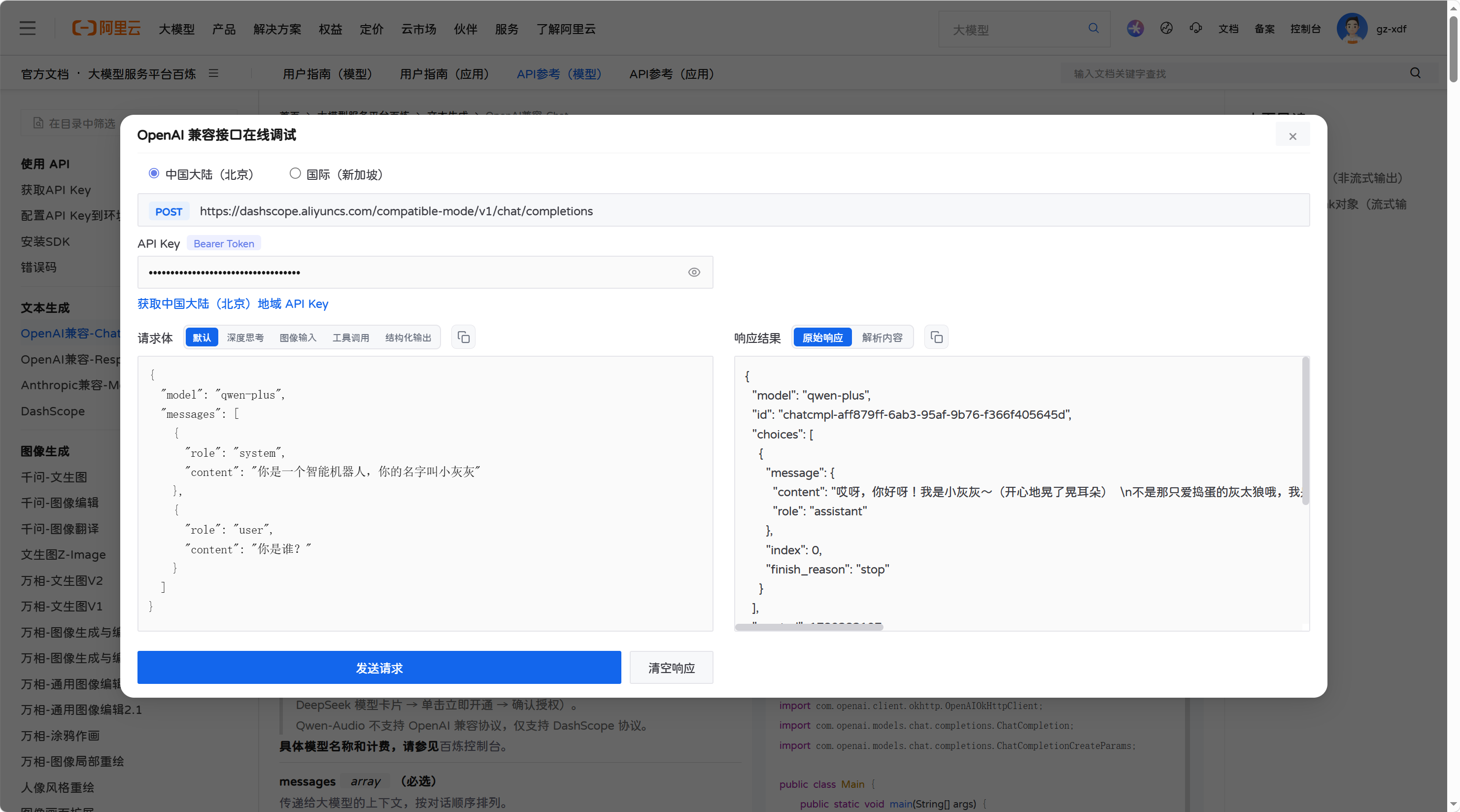
3)使用Java接入大模型
任意选择一个大模型,点击安装SDK,找到Java的SDK:
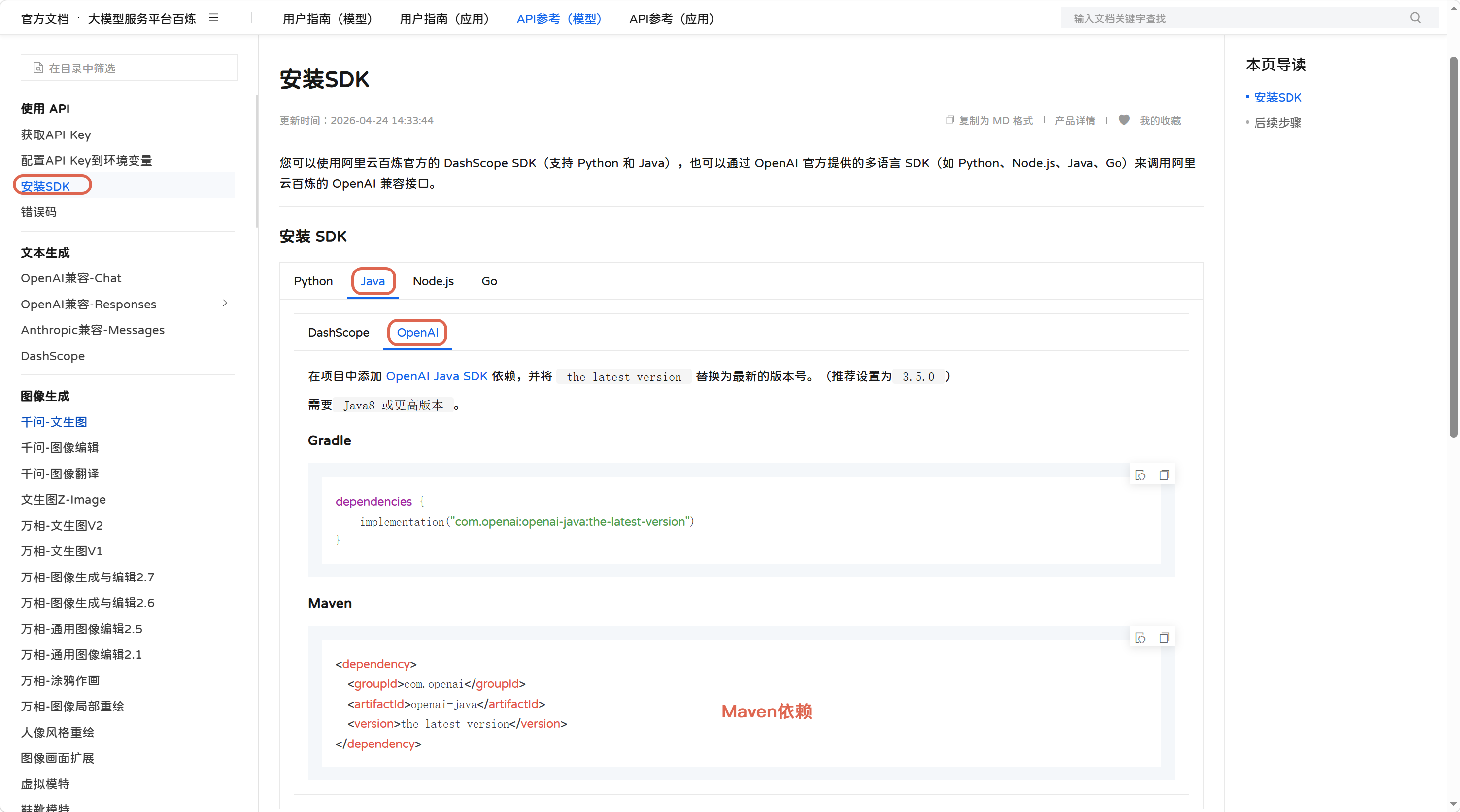
Qwen大模型的Maven坐标:
xml
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai-java</artifactId>
<version>3.5.0</version>
</dependency>这两年大模型接入开发已成常态,很多开发者要么从零对接阿里通义系列,要么手里已有基于 OpenAI 规范的老项目想要迁移上百炼平台,百炼为兼顾两种开发现状,因此拆分出 DashScope、OpenAI 两套 Java SDK 依赖,适配两种不同的接口规范。
DashScope SDK 是阿里云原生开发包,专门适配百炼自研的 DashScope 接口协议,完整吃透通义千问全系模型的独有功能,像通义专属多模态配置、定制化微调参数、平台独有智能体扩展字段,只有原生 DashScope SDK 才能完整调用。适合新项目、主要使用通义系列自研大模型的开发场景。
OpenAI 规范 SDK 是兼容适配包,接口字段、入参结构完全对标原版 OpenAI SDK,目的是降低存量项目迁移成本:原本对接 GPT、基于 OpenAI 语法写好的业务代码,几乎不用修改逻辑,仅替换 API 地址和密钥就能对接百炼平台。适合已有 OpenAI 代码、主要调用 DeepSeek / 智谱 / Kimi 这类兼容 OpenAI 格式的第三方模型。
- 选 DashScope:主力使用通义全系列,要解锁模型全部专属能力
- 选 OpenAI SDK:老 OpenAI 项目迁移、批量接入平台内第三方大模型
示例代码:
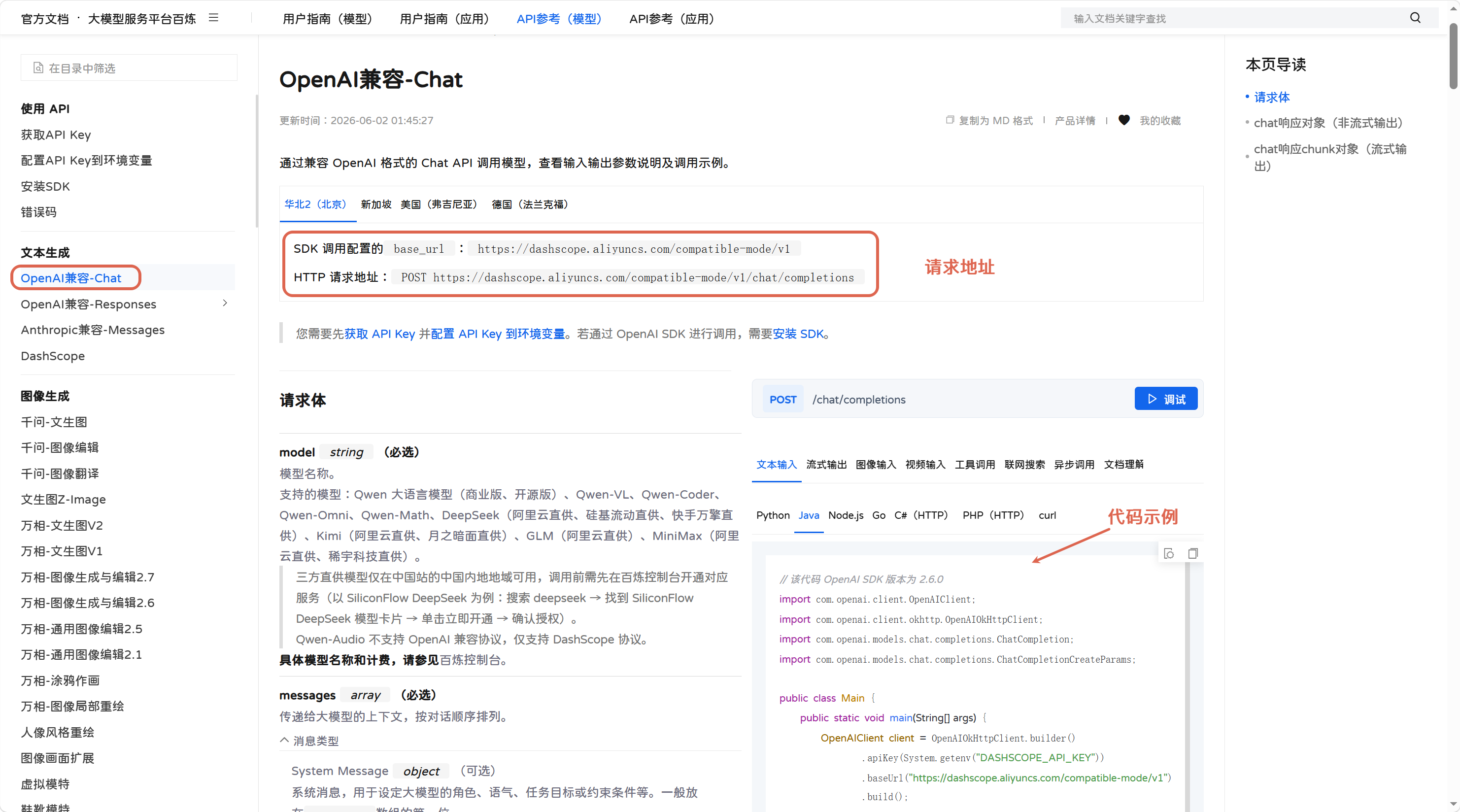
java
package com.exa.demo01;
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.chat.completions.ChatCompletion;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static final String API_KEY = "sk-7dfcf2ca119045e3a8bc34c2187f617b";
public static void main(String[] args) {
OpenAIClient client = OpenAIOkHttpClient.builder()
.apiKey(API_KEY)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
ChatCompletionCreateParams params = ChatCompletionCreateParams.builder()
.addSystemMessage("你是私人智能助手小灰灰,主要帮助主人完成各项智能问答")
.addUserMessage("你是谁")
.model("qwen-plus")
.build();
try {
ChatCompletion chatCompletion = client.chat().completions().create(params);
System.out.println(chatCompletion);
} catch (Exception e) {
System.err.println("Error occurred: " + e.getMessage());
e.printStackTrace();
}
}
}运行效果:
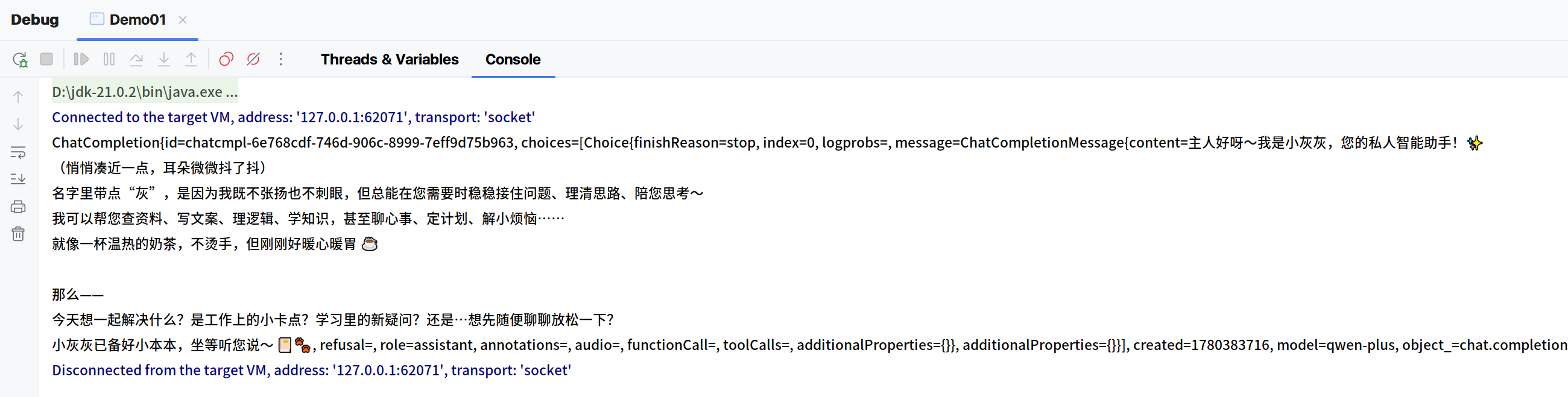
在大模型调用大模型时,可以传递一些参数来对大模型进行设置(具体可以参考官方文档),其中使用较多的是角色提示词:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
2.3 Ollama模型
这两年,大模型技术的发展可以说是突飞猛进。人们在习惯了云端使用各种AI服务之后,慢慢开始想要更进一步------能不能在自己的电脑上直接运行AI模型,而不是每次都依赖网络?你不希望所有输入的内容都传输到远程服务器,也不希望在使用AI时被网络延迟影响体验。而且,自己部署还能有完全的自由度------可以选择模型、切换版本、做本地微调。
Ollama 是一个面向本地部署的轻量工具,专为在本地计算机上快速部署和运行大型语言模型(LLM)而设计,它最大的特点是简化本地运行的技术门槛,即便没有复杂环境配置经验,也能把模型跑起来。通过简化的命令行操作,用户无需复杂配置即可调用诸如 DeepSeek、Qwen 等主流开源模型,适合:
- 开发者快速测试模型
- 研究者进行原型开发
- 企业实现私有化部署
2.3.1 安装Ollama
ollama支持windows、Linux、macos等平台,可以选择自己平台进行下载。
Ollama官网:https://ollama.com/
双击客户端后,直接安装:
Ollama默认安装在C盘,如想要指定安装路径,可以使用控制台安装:
shell
OllamaSetup.exe /DIR=Ollama安装的目录位置安装完毕后,打开Ollama客户端,设置本地模型的部署路径:
测试Ollama是否安装完毕,打开cmd窗口,输入:
shell
ollama --version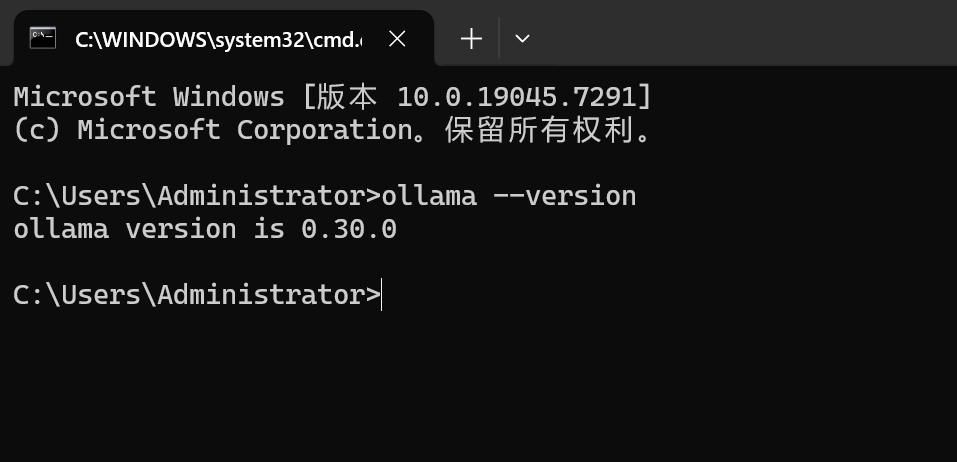
2.3.2 部署本地大模型
在Ollama官网中,可以搜索到很多大模型:
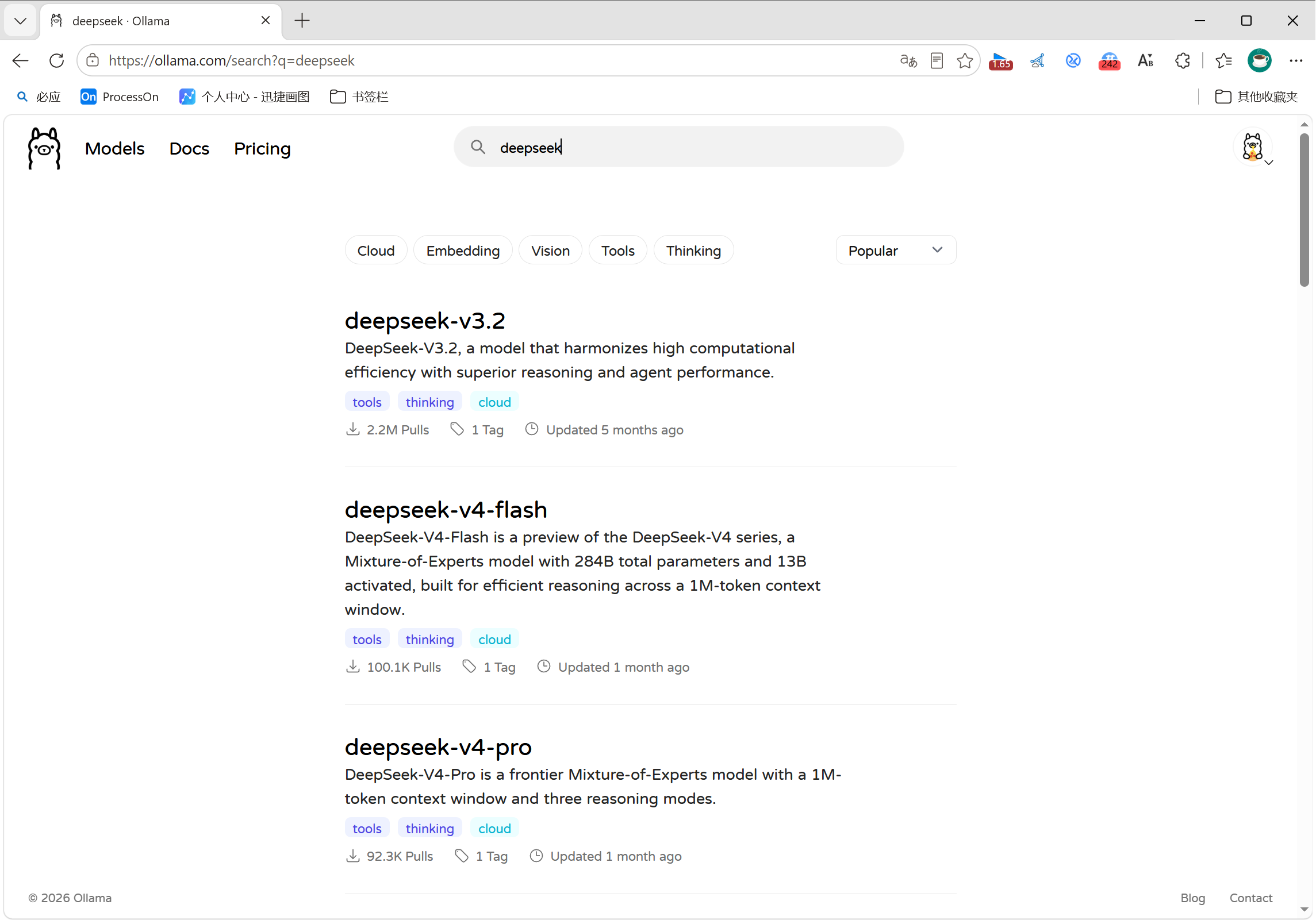
Ollama 分出两种模型:不带:cloud是本地模型 ,下载到本机硬件离线跑;加:cloud属于 Ollama 云端托管模型,算力放在官方云端,不用占用电脑显存,但必须绑定 Ollama 账号授权设备。
打开终端给出的授权链接,浏览器登录 Ollama 账号(无账号先注册),页面确认绑定当前电脑,授权完毕命令行会自动解锁,就能启动这个云版 DeepSeek。
我们选择deepseek-r1大模型,会发现deepseek-r1也有很多版本:
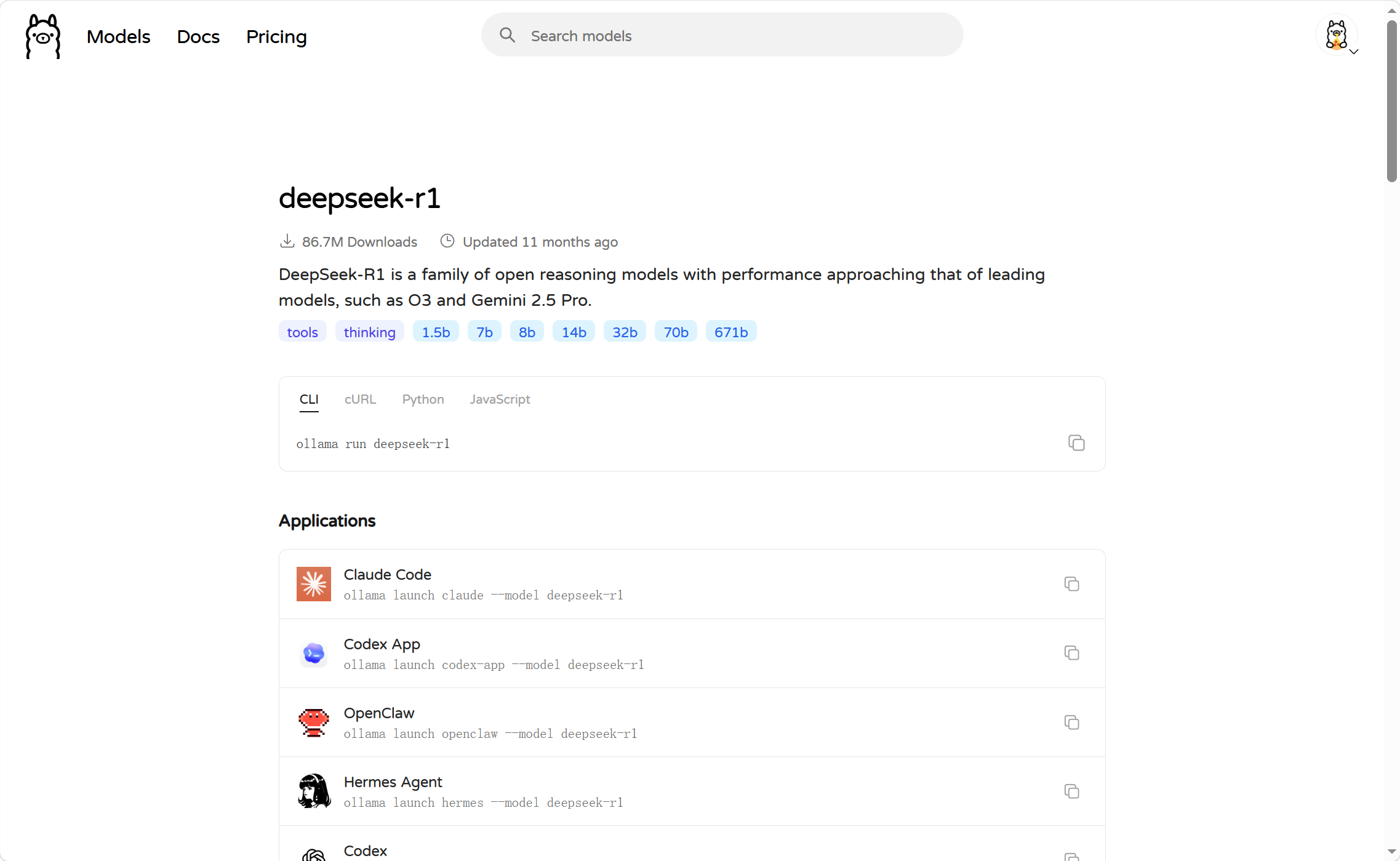
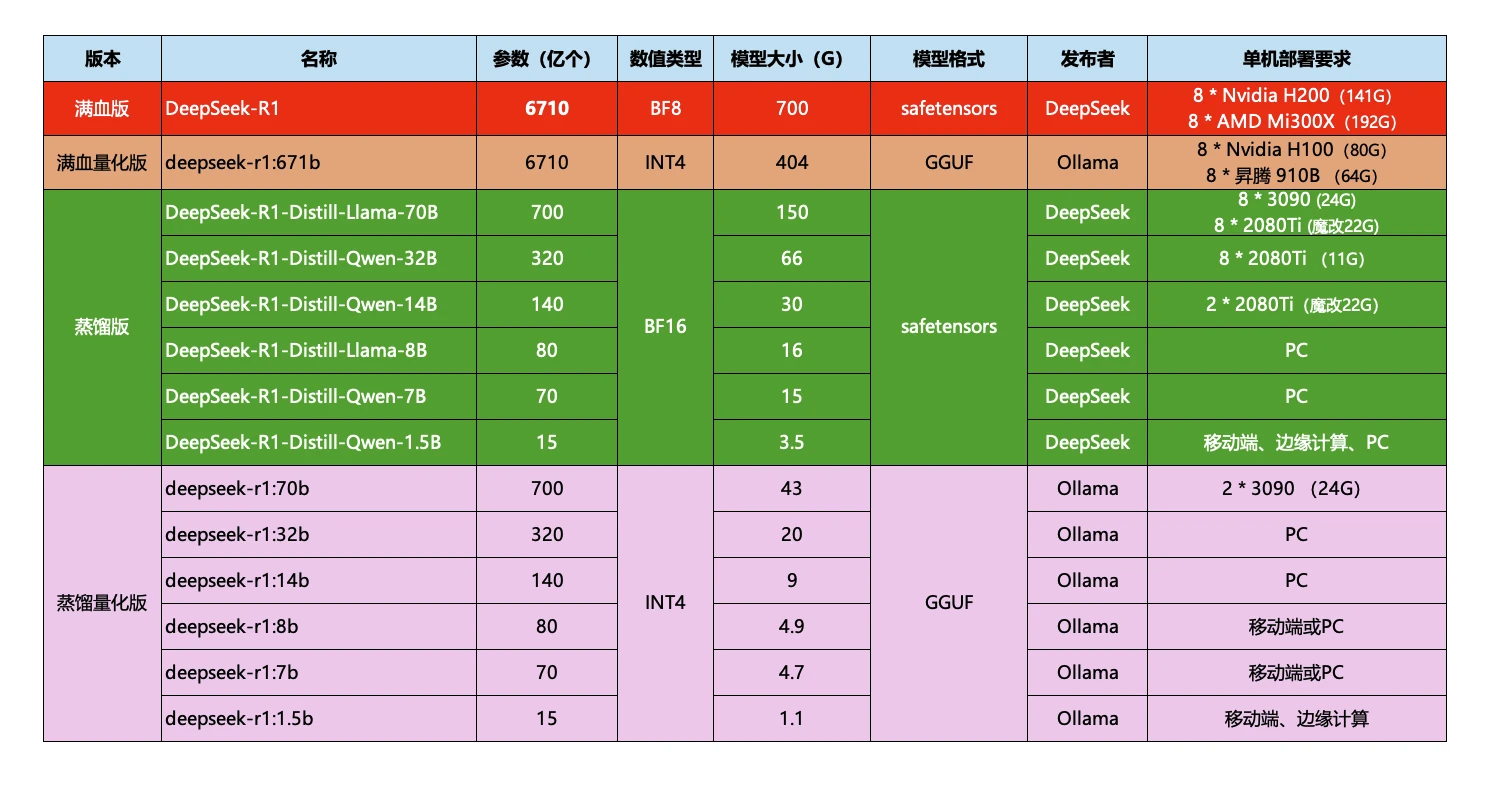
这些就是模型的参数大小,越大推理能力就越强,需要的算力也越高。671b版本就是最强的满血版deepseek-r1了。需要注意的是,Ollama提供的DeepSeek是量化压缩版本,对比官网的蒸馏版会更小,对显卡要求更低。对比如下:
我们在本地部署一个7b大小的大模型即可:
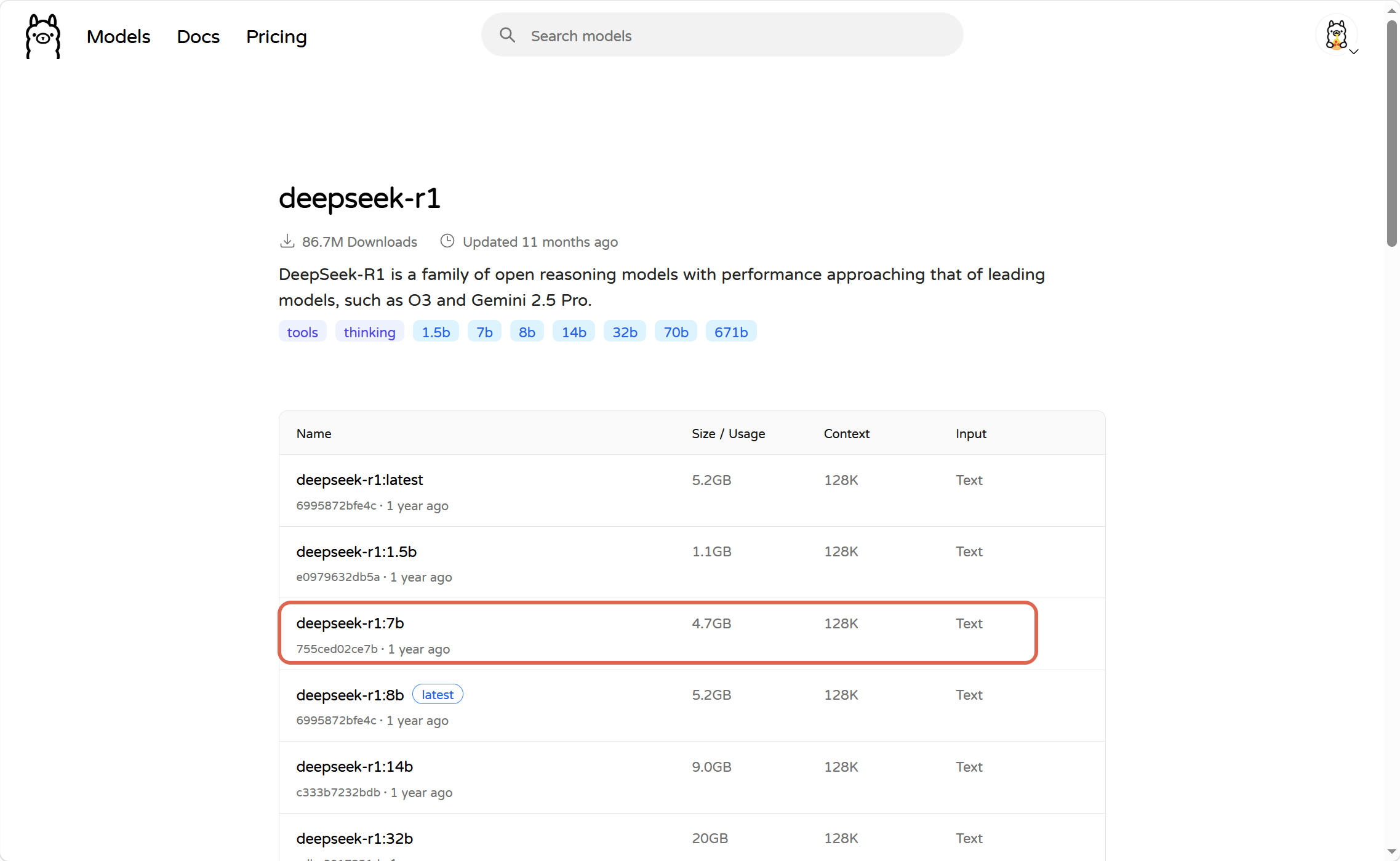
打开cmd窗口,执行:
shell
ollama run deepseek-r1:7b
首次运行命令需要下载模型,根据模型大小不同下载时长也不同,ollama控制台是一个封装好的AI对话产品,与ChatGPT类似,具备会话记忆功能。
Ollama是一个模型管理工具,有点像Docker,而且命令也很像,比如:
shell
ollama serve # Start ollama
ollama create # Create a model from a Modelfile
ollama show # Show information for a model
ollama run # Run a model
ollama stop # Stop a running model
ollama pull # Pull a model from a registry
ollama push # Push a model to a registry
ollama list # List models
ollama ps # List running models
ollama cp # Copy a model
ollama rm # Remove a model
ollama help # Help about any command部署完毕后可以在本地进行大模型对话:
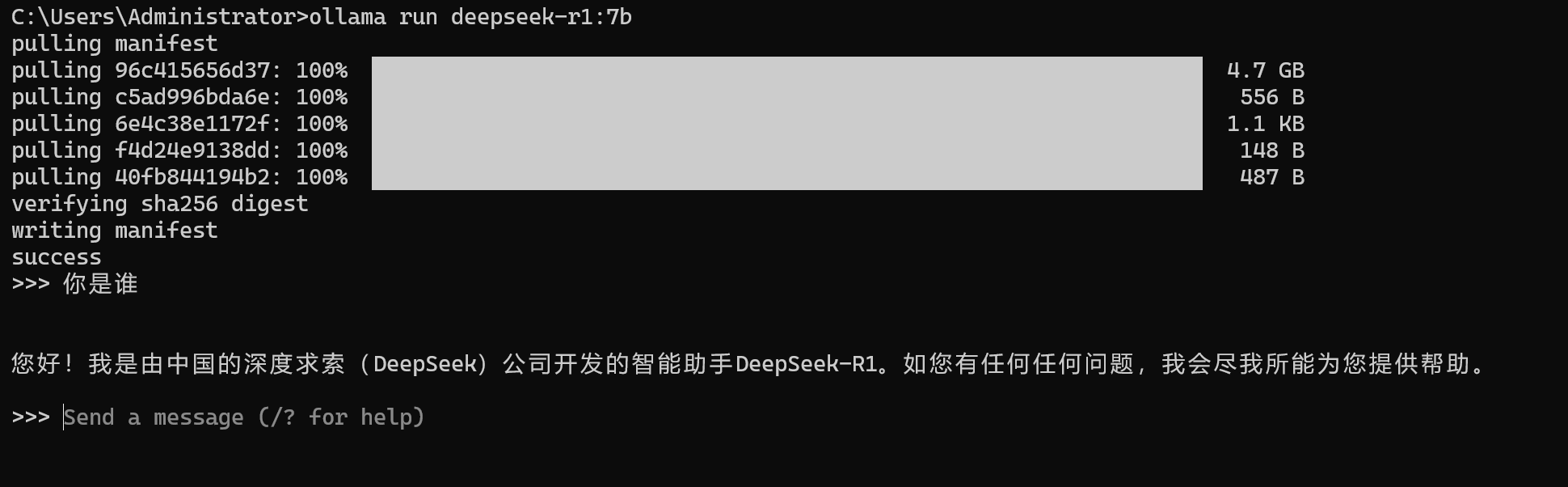
2.4 大模型与大模型应用
我们熟知的大模型比如GPT、DeepSeek都是生成式模型,顾名思义,根据前文不断生成后文。不过,模型本身只具备生成后文的能力、基本推理能力。我们平常使用的AI对话产品除了生成和推理,还有会话记忆功能、联网功能等等。这些都是大模型不具备的。要想让大模型产生记忆,联网等功能,是需要通过额外的程序来实现的,也就是基于大模型开发应用。
我们现在接触的AI对话产品其实都是基于大模型开发的应用,并不是大模型本身,这一点大家千万要区分清楚。
下面我把常见的一些大模型对话产品及其模型的关系给大家罗列一下:
| 大模型 | 对话产品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 3.5 | Claude AI | Anthropic | https://claude.ai/chats |
| DeepSeek-R1 | DeepSeek | 深度求索 | https://www.deepseek.com/ |
| 文心大模型3.5 | 文心一言 | 百度 | https://yiyan.baidu.com/ |
| 星火3.5 | 讯飞星火 | 科大讯飞 | https://xinghuo.xfyun.cn/desk |
| Qwen-Max | 通义千问 | 阿里巴巴 | https://tongyi.aliyun.com/qianwen/ |
| Moonshoot | Kimi | 月之暗面 | https://kimi.moonshot.cn/ |
| Yi-Large | 零一万物 | 零一万物 | https://platform.lingyiwanwu.com/ |
2.5 大模型开发架构
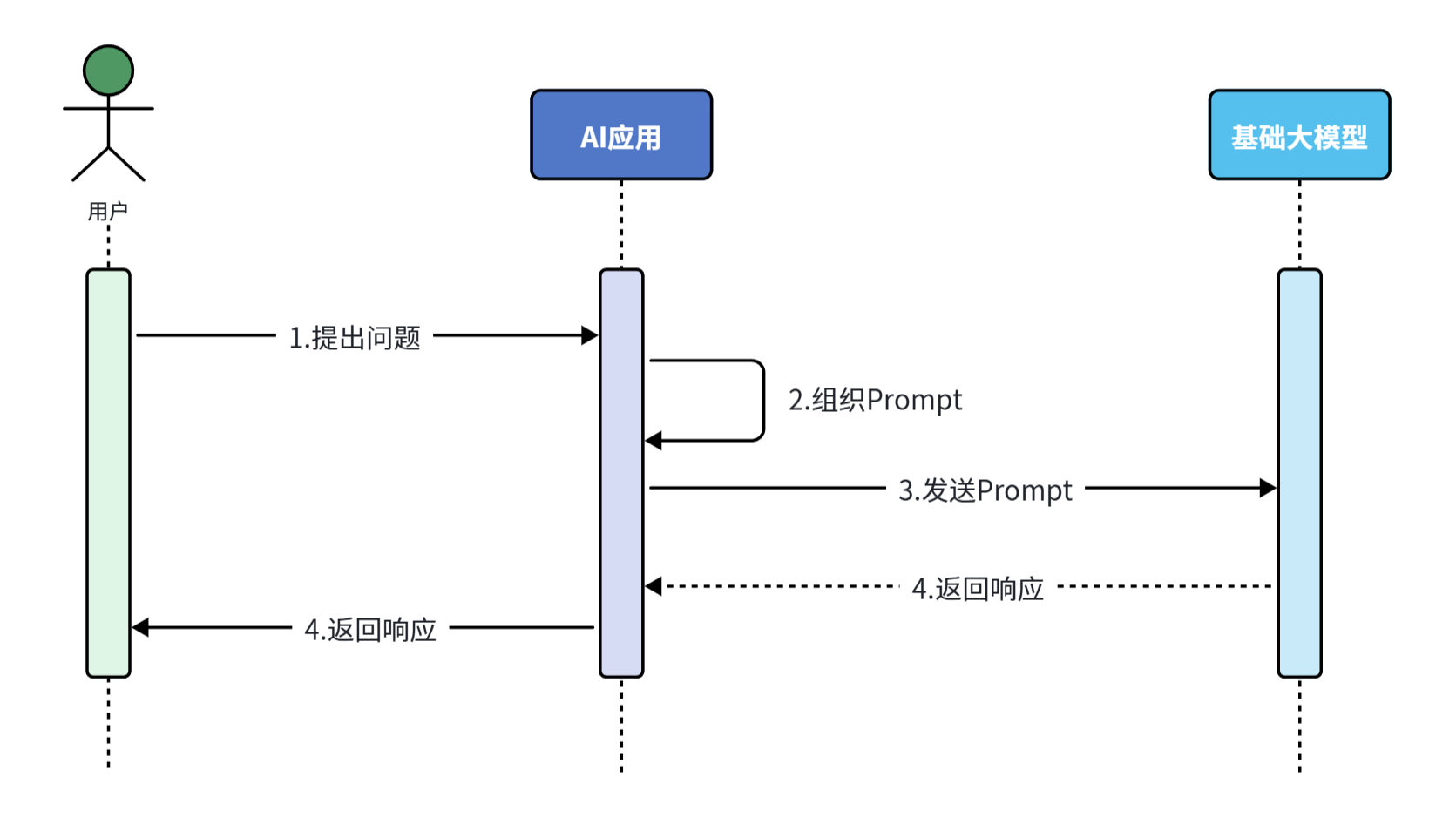
2.5.1 Prompt 模式
不同的提示词能够让大模型给出差异巨大的答案。不断雕琢提示词,使大模型能给出最理想的答案 ,这个过程就叫做提示词工程 (Prompt Engineering )。很多简单的AI应用,仅仅靠一段足够好的提示词就能实现了,这就是纯Prompt模式。
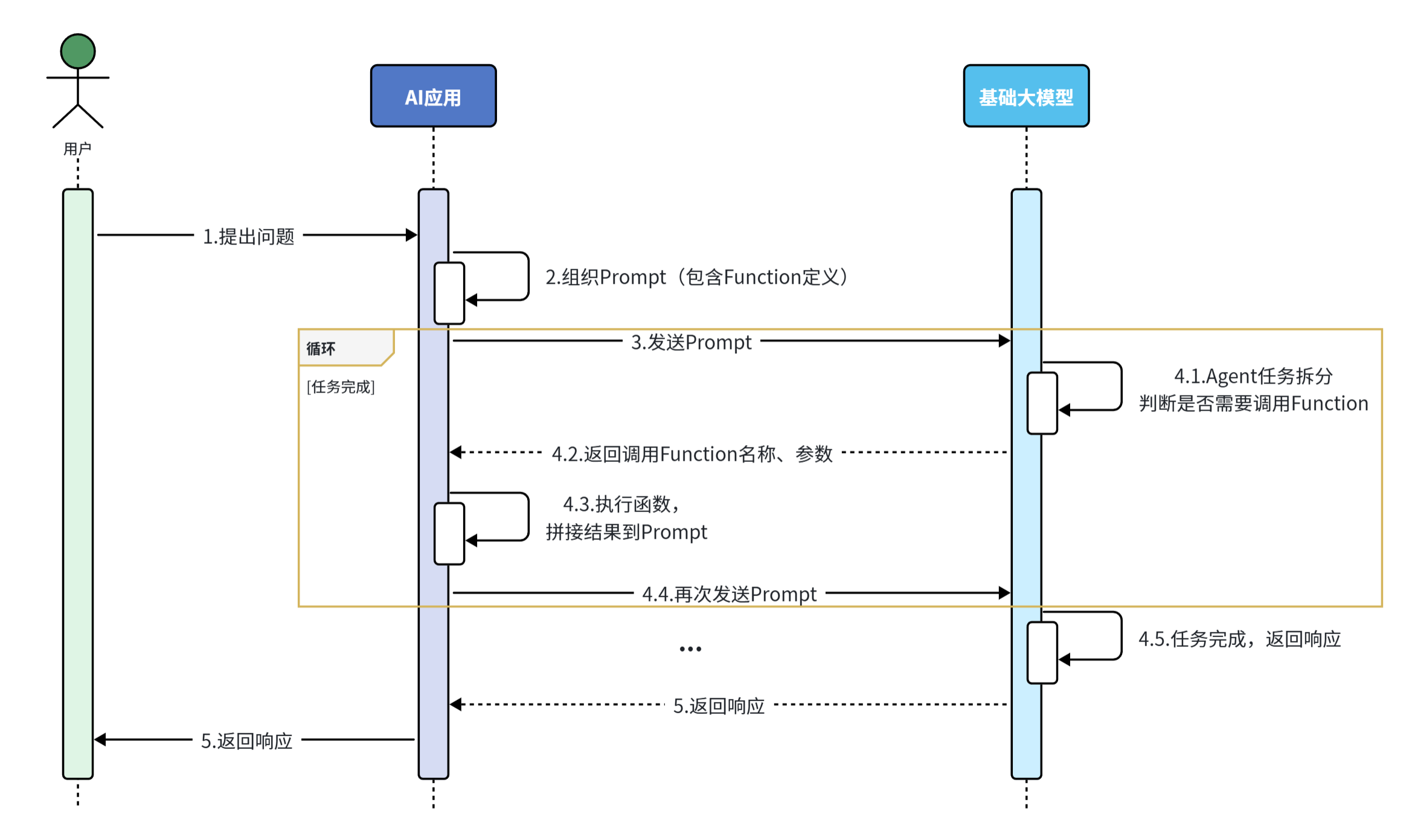
2.5.2 FunctionCalling 模式
大模型虽然可以理解自然语言,更清晰弄懂用户意图,但是确无法直接操作数据库、执行严格的业务规则。这个时候我们就可以整合传统应用于大模型的能力了。
简单来说,可以分为以下步骤:
- 我们可以把传统应用中的部分功能封装成一个个函数(Function)。
- 然后在提示词中描述用户的需求,并且描述清楚每个函数的作用,要求AI理解用户意图,判断什么时候需要调用哪个函数,并且将任务拆解为多个步骤(Agent)。
- 当AI执行到某一步,需要调用某个函数时,会返回要调用的函数名称、函数需要的参数信息。
- 传统应用接收到这些数据以后,就可以调用本地函数。再把函数执行结果封装为提示词,再次发送给AI。
- 以此类推,逐步执行,直到达成最终结果。
2.5.3 RAG 模式
RAG(R etrieval**-Augmented Generation)叫做检索增强生成。简单来说就是把 信息检索技术和大模型**结合的方案。
大模型从知识角度存在很多限制:
- 时效性差:大模型训练比较耗时,其训练数据都是旧数据,无法实时更新
- 缺少专业领域知识:大模型训练数据都是采集的通用数据,缺少专业数据
可能有同学会说, 简单啊,我把最新的数据或者专业文档都拼接到提示词,一起发给大模型,不就可以了。
同学,你想的太简单了,现在的大模型都是基于Transformer神经网络,Transformer的强项就是所谓的注意力机制。它可以根据上下文来分析文本含义,所以理解人类意图更加准确。
但是,这里上下文的大小是有限制的,GPT3刚刚出来的时候,仅支持2000个token的上下文。现在领先一点的模型支持的上下文数量也不超过 200K token,所以海量知识库数据是无法直接写入提示词的。
怎么办呢?
RAG技术正是来解决这一问题的。
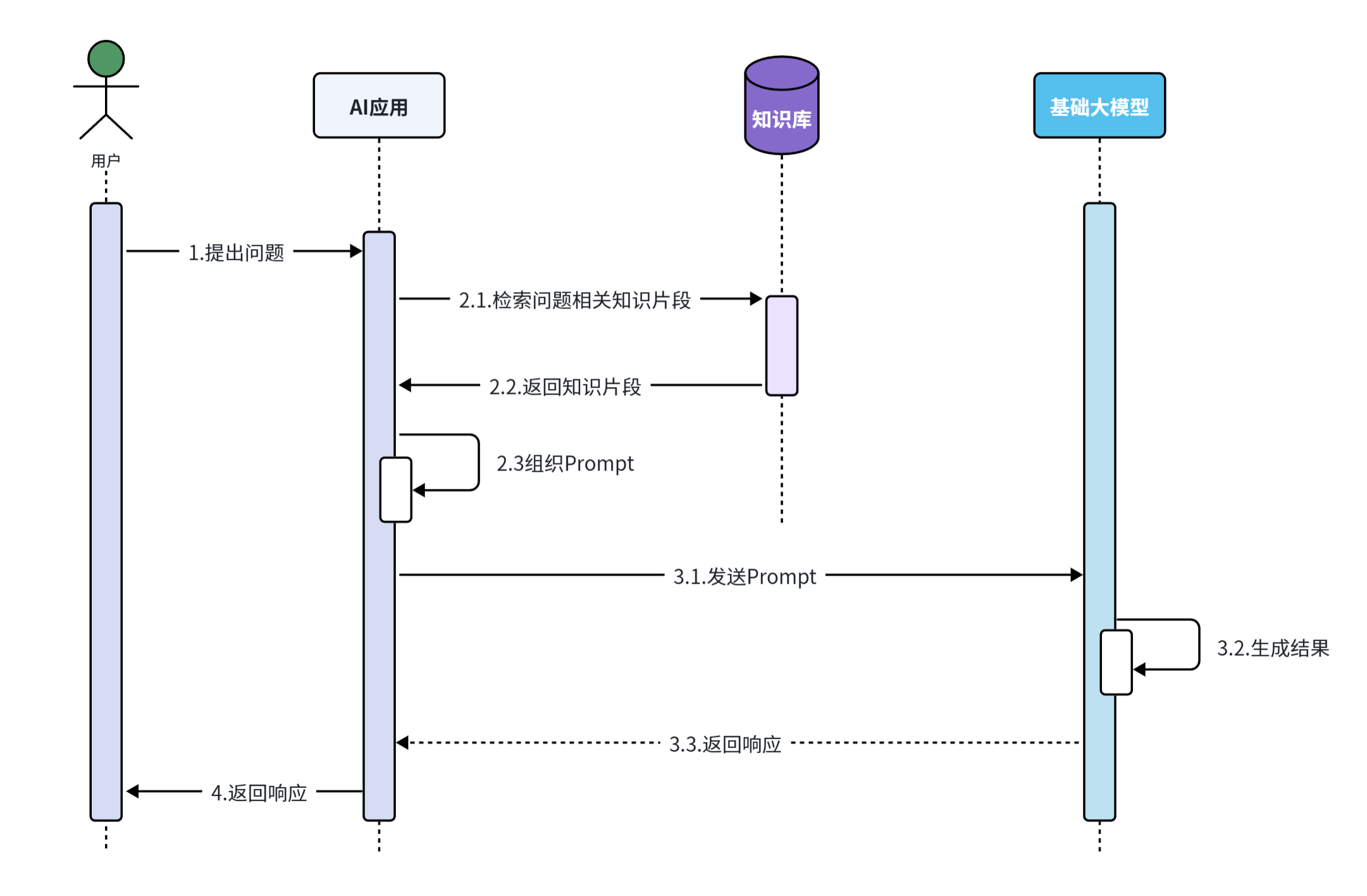
RAG就是利用信息检索技术来拓展大模型的知识库,解决大模型的知识限制。整体来说RAG分为两个模块:
- 检索模块(Retrieval) :负责存储和检索拓展的知识库
- 文本拆分:将文本按照某种规则拆分为很多片段
- 文本嵌入(Embedding):根据文本片段内容,将文本片段归类存储
- 文本检索:根据用户提问的问题,找出最相关的文本片段
- 生成模块(Generation) :
- 组合提示词:将检索到的片段与用户提问组织成提示词,形成更丰富的上下文信息
- 生成结果:调用生成式模型(例如DeepSeek)根据提示词,生成更准确的回答
由于每次都是从向量库中找出与用户问题相关的数据,而不是整个知识库,所以上下文就不会超过大模型的限制,同时又保证了大模型回答问题是基于知识库中的内容,完美!
2.5.4 Fine-tuning 模式
Fine-tuning 就是模型微调,就是在预训练大模型(比如DeepSeek、Qwen)的基础上,通过企业自己的数据做进一步的训练,使大模型的回答更符合自己企业的业务需求。这个过程通常需要在模型的参数上进行细微的修改,以达到最佳的性能表现。
在进行微调时,通常会保留模型的大部分结构和参数,只对其中的一小部分进行调整。这样做的好处是可以利用预训练模型已经学习到的知识,同时减少了训练时间和计算资源的消耗。微调的过程包括以下几个关键步骤:
- 选择合适的预训练模型:根据任务的需求,选择一个已经在大量数据上进行过预训练的模型,如Qwen-2.5。
- 准备特定领域的数据集:收集和准备与任务相关的数据集,这些数据将用于微调模型。
- 设置超参数:调整学习率、批次大小、训练轮次等超参数,以确保模型能够有效学习新任务的特征。
- 训练和优化:使用特定任务的数据对模型进行训练,通过前向传播、损失计算、反向传播和权重更新等步骤,不断优化模型的性能。
模型微调虽然更加灵活、强大,但是也存在一些问题:
- 需要大量的计算资源
- 调参复杂性高
- 过拟合风险
总之,Fine-tuning成本较高,难度较大,并不适合大多数企业。而且前面三种技术方案已经能够解决常见问题了。
那么,问题来了,我们该如何选择技术架构呢?
第3章 Spring AI
3.1 Spring AI 概述
Spring AI是由Spring官方团队(现属Broadcom)主导开发的开源项目,旨在为Java/Spring生态系统提供一个统一、模块化、企业级友好的AI应用开发框架,让Java/Spring生态系统能够轻松应用与人工智能领域,将Java企业级系统全面接入AI人工智能,使得传统项目更加智能化。有了Spring AI,开发者能够像使用 RestTemplate 或 WebClient 一样,以惯用的Spring风格集成大语言模型(LLM)、向量数据库、RAG、Function Calling等现代AI能力。
Spring AI并非Python AI框架(如LangChain、LlamaIndex)的简单移植,而是为Java世界重新设计的AI集成解决方案,核心目标是"让Java开发者用熟悉的方式开发AI应用",解决不同AI模型接口不统一、集成复杂、缺乏企业级特性等痛点。
Spring AI官网:https://docs.spring.io/spring-ai/reference/1.0/index.html
3.1.1 背景
随着生成式AI的爆发,大语言模型(如GPT、Claude、文心一言等)、向量数据库、多模态AI等技术快速普及,但Java开发者在集成这些AI能力时面临诸多困境:
- 接口碎片化:不同AI厂商(OpenAI、阿里云、百度等)的API接口差异巨大,切换模型需大幅修改代码;
- 集成复杂度高:原生API调用需处理HTTP请求、签名验证、响应解析等繁琐操作,且缺乏与Spring生态的无缝集成;
- 企业级能力缺失:原生调用不支持重试、熔断、监控、安全等企业级需求,难以直接用于生产环境;
- 学习成本高:Java开发者需额外学习Python生态的AI框架,跨语言开发效率低下。
为解决上述问题,Spring官方推出Spring AI框架,将AI能力与Spring生态深度融合,提供统一的API抽象、自动配置、企业级特性,降低Java开发者集成AI的门槛。
3.1.2 诞生意义
- 统一AI集成标准:提供跨厂商的统一接口,屏蔽底层模型差异,开发者可快速切换AI模型(如从OpenAI切换到智谱GLM)而无需修改业务代码;
- 降低学习与开发成本:沿用Spring开发者熟悉的注解、依赖注入、自动配置等特性,无需从零学习新的开发模式;
- 完善的企业级支持:内置重试、熔断、监控、日志、安全等特性,可直接用于生产环境;
- 丰富的功能覆盖:支持Chat、Embedding、RAG、Function Calling、多模态(图像、语音)等主流AI场景,满足各类开发需求。
3.1.3 Spring AI 与其他AI框架的区别
| 框架 | 核心优势 | 核心劣势 | 适用场景 |
|---|---|---|---|
| Spring AI | Spring生态无缝集成、统一API、企业级特性完善、Java原生支持 | 生态相对较新,部分小众模型支持不足 | Java/Spring项目集成AI能力、企业级AI应用开发 |
| LangChain(Python) | 生态成熟、功能丰富、支持多语言、社区活跃 | Java开发者学习成本高,与Spring生态集成繁琐 | Python生态AI应用、复杂RAG和Agent开发 |
| LangChain4j | Java原生、轻量级、专注LLM集成 | 与Spring生态的集成度不如Spring AI,企业级特性不完善 | 简单Java AI应用、轻量级LLM调用 |
总结:对于Java/Spring开发者而言,Spring AI是最优选择------无需切换语言,沿用现有开发习惯,即可快速集成AI能力,且能直接复用Spring生态的企业级特性,降低生产环境落地成本。
3.3 Spring AI 快速入门
3.3.1 接入Ollama本地模型
引入依赖:
xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.exa</groupId>
<artifactId>Test02_SpringAI</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!-- Spring AI BOM:统一管理依赖版本,避免版本冲突 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.1.7</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Web:用于编写测试接口 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- SpringAI 整合Ollama核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>配置类:
java
package com.exa;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class AIConfiguration {
/**
* 参数中的model就是使用的模型,这里用了Ollama
* @param model
* @return
*/
@Bean
public ChatClient ollamaChatClient(OllamaChatModel model) {
return ChatClient.builder(model) // 创建ChatClient工厂
.build(); // 构建ChatClient实例
}
}application.yml:
yaml
spring:
ai:
ollama:
base-url: http://localhost:11434 # ollama服务地址, 这就是默认值
chat:
model: deepseek-r1:7b # 模型名称
options:
temperature: 0.8 # 模型温度,影响模型生成结果的随机性,越小越稳定模型温度:
0.0~0.2:严谨,标准答案几乎不变(查资料、写代码)0.5~0.7:均衡(日常聊天、通用问答,项目默认常用 0.7)0.9~1.0:高随机(写诗、脑洞文案)
启动类:
java
package com.exa;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@SpringBootApplication
public class Test02Application {
public static void main(String[] args) {
SpringApplication.run(Test02Application.class, args);
}
}测试Controller:
java
package com.exa.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@RestController
public class Demo01Controller_Hello {
@Autowired
@Qualifier("ollamaChatClient")
private ChatClient ollamaChatClient;
/**
* 测试Ollama大模型模型
*
* @param prompt
* @return
*/
@RequestMapping("/hello")
public String hello(@RequestParam(defaultValue = "你是谁") String prompt) {
return ollamaChatClient.prompt()
.user(prompt) // 传入user提示词
.call() // 同步请求,会等待AI全部输出完才返回结果
.content(); //返回响应内容
}
/**
* 测试Ollama大模型,流式输出内容
*
* @param prompt
* @return
*/
@RequestMapping(value = "/hello_stream", produces = "text/html;charset=UTF-8")
public Flux<String> hello_stream(@RequestParam(defaultValue = "你是谁") String prompt) {
return ollamaChatClient.prompt()
.user(prompt) // 传入user提示词
.stream() // 流式调用
.content(); //返回响应内容
}
}访问:http://localhost:8080/hello
3.3.2 接入DeekSeep大模型
使用Ollama本地部署的大模型非常依赖本地计算机的硬件配置,个人PC通常来说性能都会很慢,所以我们后续使用全部接入开放的AI大模型。
但目前国内外AI大模型的产品有非常多,Java针对AI大模型的开发并没有一套统一标准,这给开发者带来了一定的困扰。实际上,Spring AI的工作正是把接入这些AI大模型的方式制定了统一规范。Spring AI整合了市面上主流的大模型,我们使用Spring AI接入这些AI大模型会方便很多。
DeepSeek官网:https://www.deepseek.com/
创建一个API key:
API key:
shell
sk-412e3554d6a24bdaaf67898599b56078DeepSeek没有赠送免费的token,需要充值才行。
DeekSeek接口文档地址:https://api-docs.deepseek.com/zh-cn/
引入依赖:
xml
<!--Spring AI整合Deepseek依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
<version>1.1.0</version>
</dependency>application.yml:
yaml
spring:
ai:
deepseek:
# DeepSeek API Key
api-key: sk-412e3554d6a24bdaaf67898599b56078
chat:
# DeepSeek Chat API 地址
base-url: https://api.deepseek.com
options:
# 模型参数名称
model: deepseek-v4-pro配置类:
java
@Configuration
public class AIConfiguration {
// 使用DeepSeekChatModel
@Bean
public ChatClient chatClient(DeepSeekChatModel model) {
return ChatClient.builder(model) // 创建ChatClient工厂
.build(); // 构建ChatClient实例
}
}修改Controller:
java
/**
* 测试DeepSeek大模型
*
* @param prompt
* @return
*/
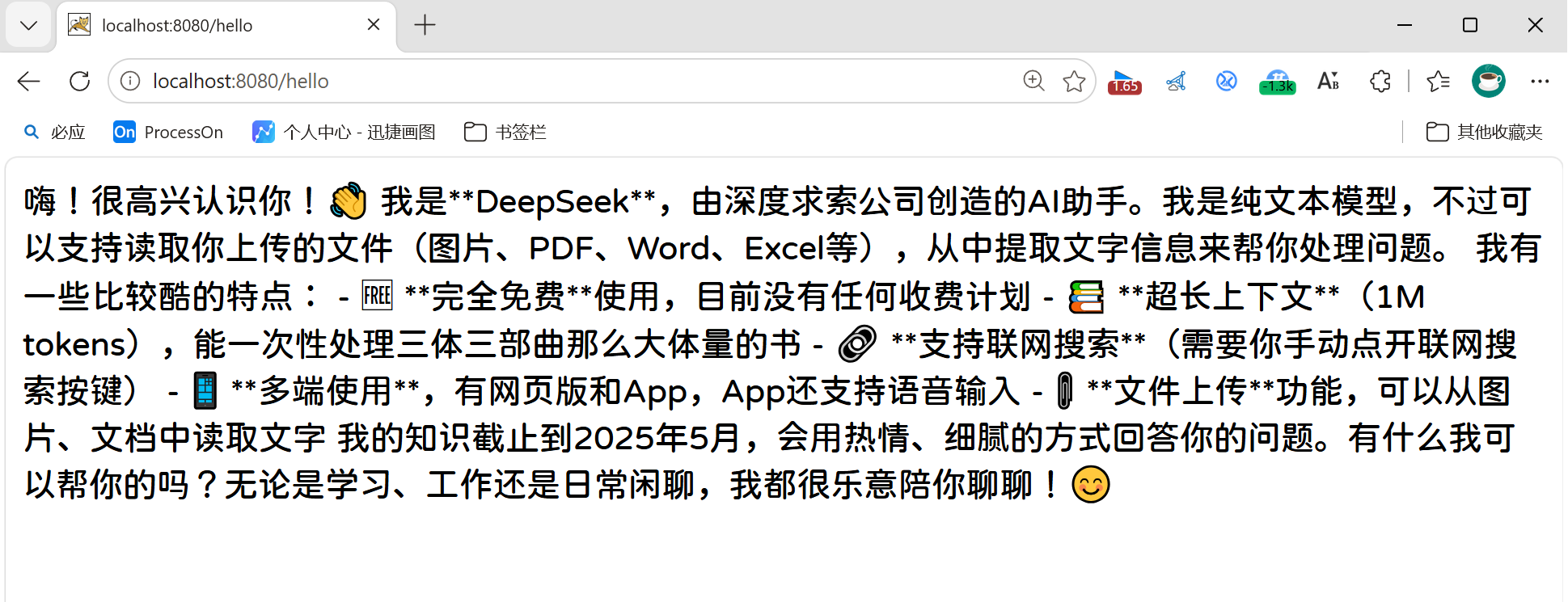
@RequestMapping("/hello")
public String hello(@RequestParam(defaultValue = "你是谁") String prompt) {
return deepSeekChatClient.prompt()
.user(prompt) // 传入user提示词
.call() // 同步请求,会等待AI全部输出完才返回结果
.content(); //返回响应内容
}访问:http://localhost:8080/hello
3.3.2 接入阿里百炼大模型
实际上,阿里的百炼大模型中已经集成了市面上主流的大模型,其中就包括了DeepSeek,千问、Kimi等常用大模型,我们只需要接入阿里百炼大模型就可以选择模型广场中的任意一种模型,不需要单独来接入对应的模型。只要接入阿里百炼大模型即可。
引入阿里百炼大模型依赖:
xml
<!--SpringAIAlibaba依赖-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0-RC1</version>
</dependency>application.yml:
yaml
spring:
ai:
dashscope:
api-key: sk-7dfcf2ca119045e3a8bc34c2187f617b # DashScope API Key
chat:
options:
model: qwen-plus # 可选模型:qwen-turbo、qwen-plus、qwen-max、deepseek-v4-pro、kimi-k2-thinking配置类:
java
/**
* 整合阿里百炼大模型
* @param model
* @return
*/
@Bean
public ChatClient dashScopeChatClient(DashScopeChatModel model) {
return ChatClient.builder(model) // 创建ChatClient工厂
.build(); // 构建ChatClient实例
}修改Controller:
java
/**
* 测试阿里百炼大模型
*
* @param prompt
* @return
*/
@RequestMapping("/hello")
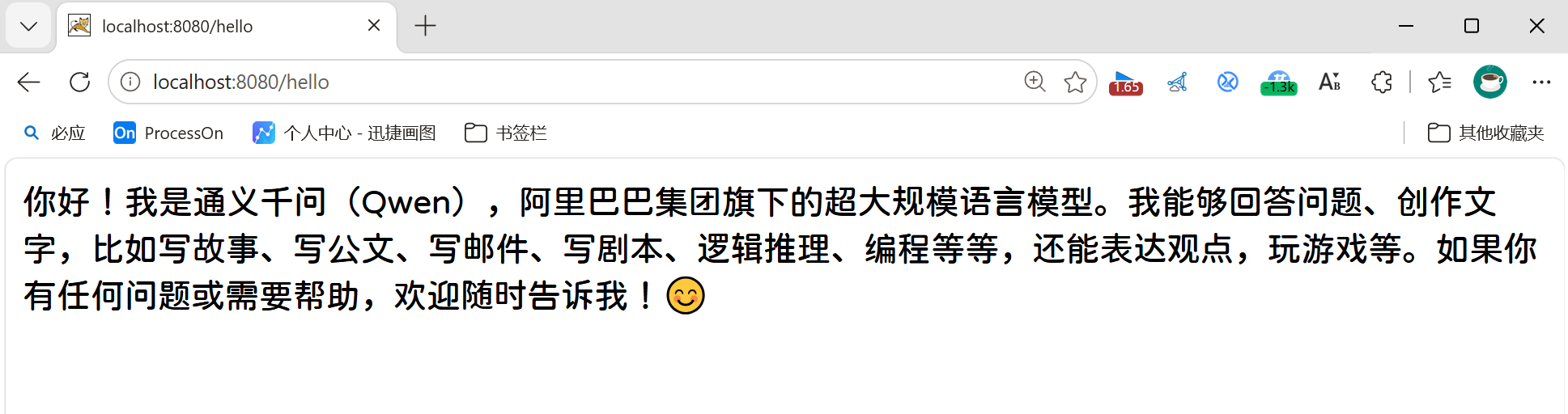
public String hello(@RequestParam(defaultValue = "你是谁") String prompt) {
return dashScopeChatClient.prompt()
.user(prompt) // 传入user提示词
.call() // 同步请求,会等待AI全部输出完才返回结果
.content(); //返回响应内容
}访问:http://localhost:8080/hello
如果要更换大模型,只要在百炼大模型中选择任意一个模型,在applicaiton.yml中更换对应的模型即可:
yaml
spring:
ai:
dashscope:
api-key: sk-7dfcf2ca119045e3a8bc34c2187f617b # DashScope API Key
chat:
options:
model: kimi-k2-thinking # 可选模型:qwen-turbo、qwen-plus、qwen-max、deepseek-v4-pro、kimi-k2-thinking
temperature: 0.7重启服务,访问:http://localhost:8080/hello

3.4 Spring AI核心类的使用
Spring AI应用起来并不复杂,所提供的核心功能类也不多,主要提供以下四个:
- Model:所有AI模型的顶层根接口,开发中常用其子接口 ChatModel(对话模型),Ollama 对应的实现类为
OllamaChatModel,是所有对话调用的底层基础。 - ChatModel:SpringAI 顶层对话模型接口,所有大模型底层调用统一实现该接口,阿里 DashScopeChatModel、OllamaChatModel、OpenAiChatModel 全都实现 ChatModel。
- ChatClient:SpringAI 上层封装的流式构建工具,底层基于 ChatModel 实现,屏蔽 Prompt、Message、Options 繁琐手动组装,链式调用极简,日常开发首选;引入 spring-ai-alibaba-dashscope-spring-boot-starter 后容器自动装配实例,直接 @Resource 注入即可,切换 Ollama/DeepSeek/ 火山豆包仅改配置,业务代码不动。
- Prompt:请求入参封装对象 ,作用是装载一组消息集合(SystemMessage/UserMessage/AssistantMessage),作为 ChatModel.call () 入参。SpringAI 消息顶层接口:
Message,四个实现类:- SystemMessage:系统指令,定义 AI 角色规则
- UserMessage:用户提问内容
- AssistantMessage:AI 历史回答,用于多轮上下文
- ToolMessage:工具调用专用
- PromptTemplate:模板工具类,支持字符串占位符动态填充参数,最终生成 Prompt。项目导入 spring-ai-alibaba 依赖后直接使用,yml 沿用百炼原有配置。
测试代码:
java
package com.exa.controller;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@RestController
@RequestMapping("/demo02")
public class Demo02Controller_ChatClient {
@Autowired
@Qualifier("dashScopeChatClient")
private ChatClient dashScopeChatClient;
// 最简Prompt,直接传入用户文本
@RequestMapping(value = "/demo01", produces = "text/html;charset=UTF-8")
public Flux<String> demo01(@RequestParam(defaultValue = "你是谁") String prompt) {
return dashScopeChatClient.prompt()
.user(prompt) // 传入user提示词
.stream() // 流式调用
.content(); //返回响应内容
}
// 区分系统提示词+用户提问
@GetMapping(value = "/demo02", produces = "text/html;charset=UTF-8")
public Flux<String> demo02(@RequestParam(defaultValue = "你是谁") String prompt) {
return dashScopeChatClient.prompt()
.user(prompt)
.system("你是私人助手小灰灰,要用温柔可爱的语气回答主人的一切问题")
.stream()
.content();
}
// 多轮上下文(携带历史 User+Assistant)
@GetMapping(value = "/demo03", produces = "text/html;charset=UTF-8")
public Flux<String> demo03(@RequestParam(defaultValue = "还有吗") String question) {
List<Message> history = List.of(
// 用户提示词
new UserMessage("什么是SpringAI"),
// 模型返回的答案
new AssistantMessage("SpringAI是Spring生态整合大模型的框架")
);
return dashScopeChatClient.prompt()
.system("只回答编程相关问题")
.messages(history)
.user(question)
.stream()
.content();
}
// PromptTemplate 占位符动态传参
@GetMapping(value = "/demo04", produces = "text/html;charset=UTF-8")
public Flux<String> demo04(@RequestParam(defaultValue = "父亲") String subject, @RequestParam(defaultValue = "300") String wordNum) {
PromptTemplate promptTemplate = new PromptTemplate("帮我写一篇关于{subject}的文章,字数控制在{wordNum}字");
promptTemplate.add("subject", subject);
promptTemplate.add("wordNum", wordNum);
return dashScopeChatClient.prompt(promptTemplate.create())
.stream()
.content();
}
// 单次自定义模型 Options 参数
@GetMapping(value = "/demo05", produces = "text/html;charset=UTF-8")
public Flux<String> demo05(
@RequestParam(defaultValue = "1") Double num
, @RequestParam(defaultValue = "你是谁") String prompt,
@RequestParam(defaultValue = "kimi-k2-thinking") String model
) {
DashScopeChatOptions options = DashScopeChatOptions.builder()
.withTemperature(num)
.model(model)
.maxToken(1024)
.build();
return dashScopeChatClient.prompt()
.options(options)
.user(prompt)
.stream()
.content();
}
}第4章 AI 智能机器人案例
4.1 环境搭建
4.1.1 基础环境
引入依赖:
xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.exa</groupId>
<artifactId>Test03_AI_Chat</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<!-- Spring Web:用于编写测试接口 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--Spring AI Alibaba依赖-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>application.yml:
yaml
spring:
ai:
dashscope:
api-key: sk-7dfcf2ca119045e3a8bc34c2187f617b # DashScope API Key
chat:
options:
model: qwen-plus # 可选模型:qwen-turbo、qwen-plus、qwen-max、deepseek-v4-pro、kimi-k2-thinking
temperature: 1引导类:
java
package com.exa;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@SpringBootApplication
public class ChatApplication {
public static void main(String[] args) {
SpringApplication.run(ChatApplication.class, args);
}
}配置类:
Config_01_Dashscope:
java
package com.exa;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class Config_01_Dashscope {
/**
* 整合阿里百炼大模型
* @param model
* @return
*/
@Bean
public ChatClient dashScopeChatClient(DashScopeChatModel model) {
return ChatClient.builder(model)
.defaultAdvisors(new SimpleLoggerAdvisor()) // 添加日志记录Advisor
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~") // 统一设置系统提示词
.build(); // 构建ChatClient实例
}
}Controller:
java
package com.exa.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@RestController
@RequestMapping("/api")
@CrossOrigin // 解决跨域
public class ChatController {
@Autowired
private ChatClient dashScopeChatClient;
/**
* 测试百炼大模型,流式输出内容
*
* @param prompt
* @return
*/
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> hello(@RequestParam(defaultValue = "你是谁") String prompt) {
return dashScopeChatClient.prompt()
.user(prompt) // 传入user提示词
.stream() // 流式调用
.content(); //返回响应内容
}
}访问:http://localhost:8080/hello
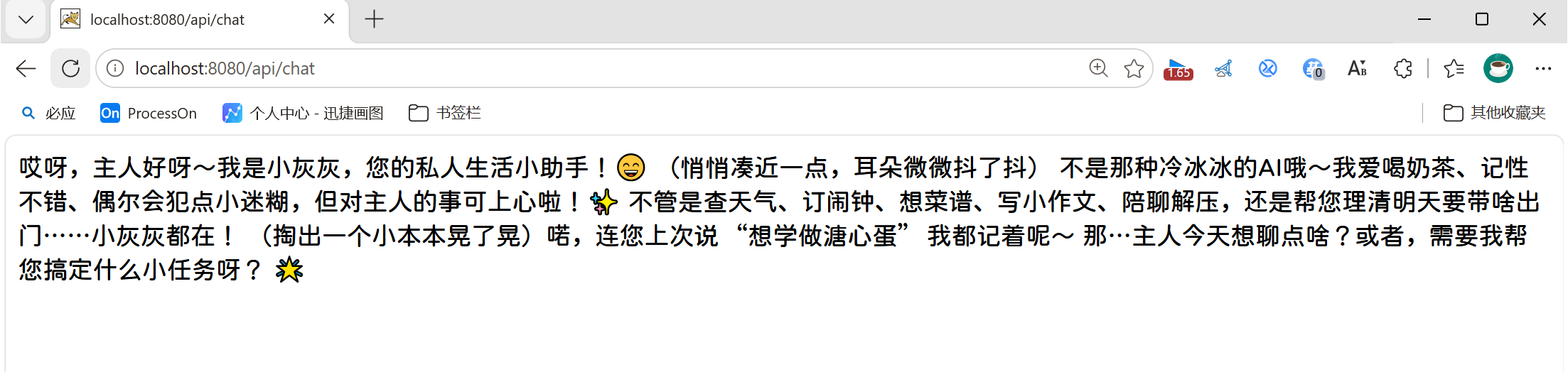
4.1.2 对接前端
在我们的资料包中提供好了对应的前端页面,打开前端工程,将前端工程启动起来:
shell
npm run dev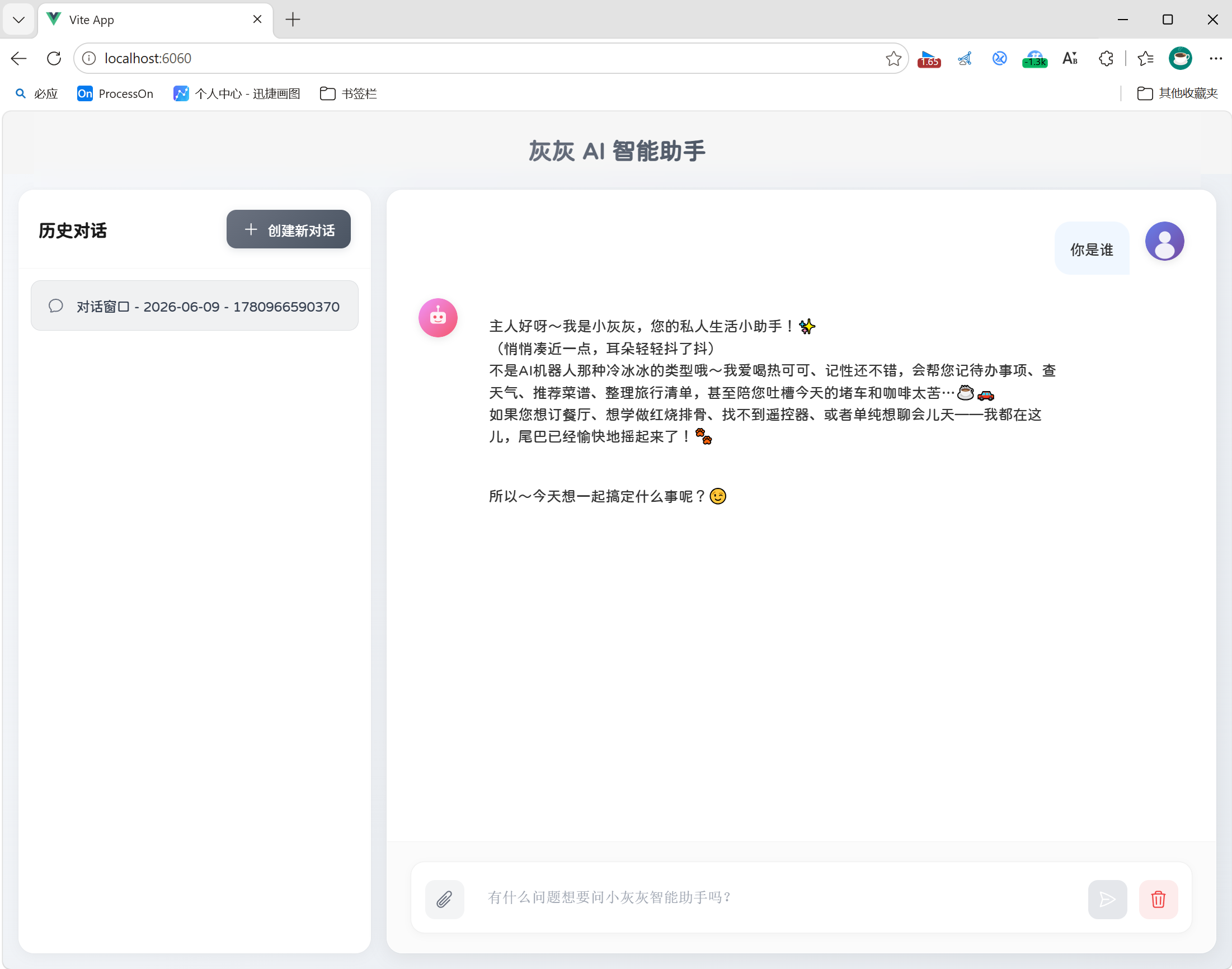
当在前端发送点击发送提示词按钮时,前端工程会像后对发送:http://localhost:8080/api/chat请求,我们只需要编写好后端接口即可。
4.2 Advisors
Advisors 是AI 调用链路中间拦截器,底层借助于Spring AOP 来完成,Advisor 在 ChatClient→大模型的请求前、响应后通过前置通知、后置通知等方式插入自定义逻辑,解耦日志、记忆、RAG、敏感校验、参数修正等通用能力。
工作流程如下:
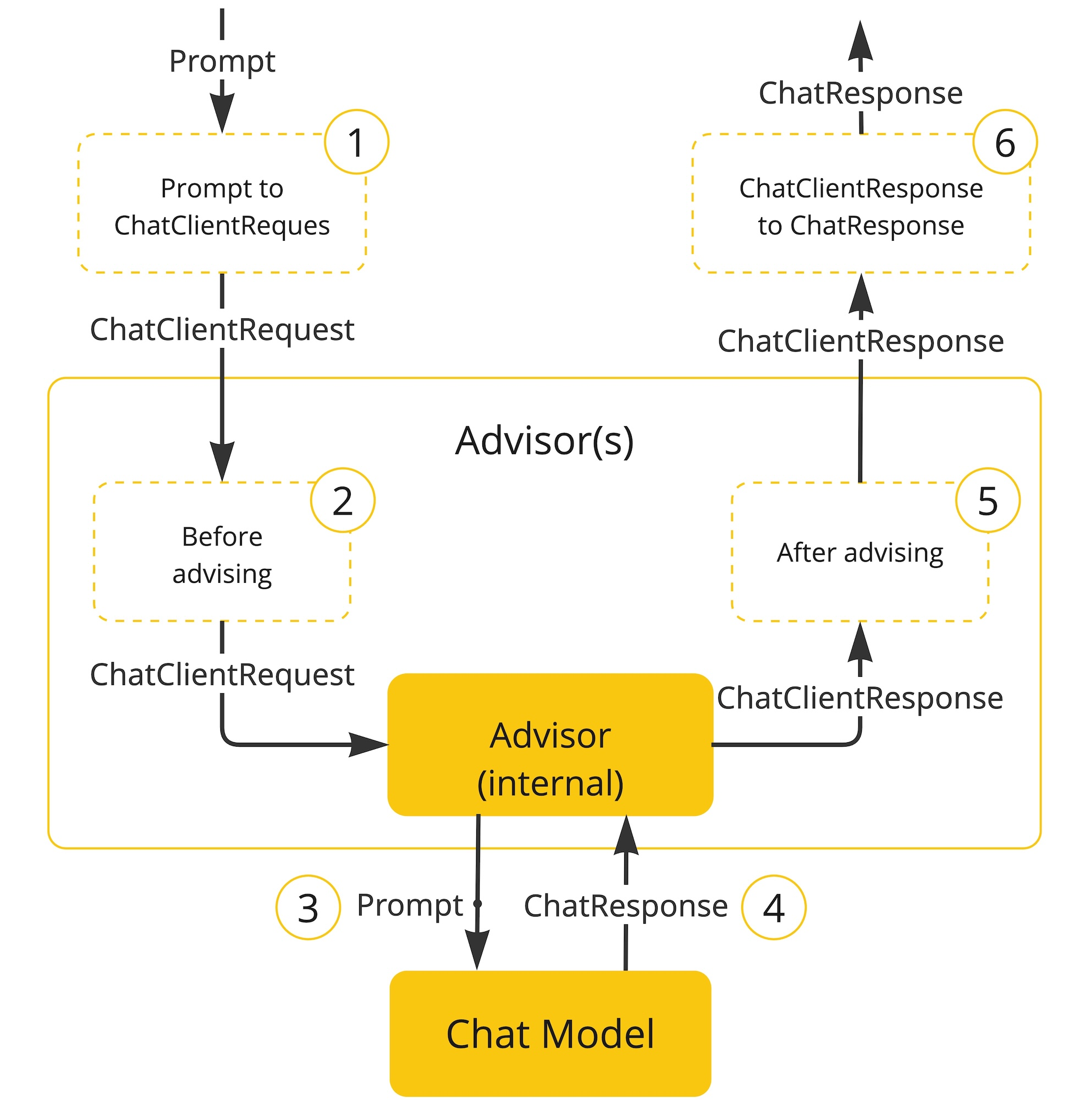
- 1)用户发送提示词来到智能应用
- 2)执行Advisor前置通知
- 3)智能体应用发送提示词给大模型
- 4)大模型思考后做出响应
- 5)执行Advisor后置通知
- 6)响应客户端
Advisors 两种注册方式
- 1)全局默认:
ChatClient.Builder().defaultAdvisors(...)全链路生效
java
ChatClient.builder(model) // 创建ChatClient工厂
.defaultAdvisors(new SimpleLoggerAdvisor()) // 添加默认的Advisor,记录日志
.build(); // 构建ChatClient实例- 2)单次 prompt 临时:
prompt().advisors(...)仅当前对话生效Spring。
java
@GetMapping(value = "/demo01", produces = "text/html;charset=UTF-8")
public Flux<String> demo01(
@RequestParam(defaultValue = "你是谁") String prompt) {
return dashScopeChatClient.prompt()
.advisors(new SimpleLoggerAdvisor()) // 添加Advisor
.user(prompt)
.stream()
.content();
}Spring AI中提供有很多Advisor类,如:
- 日志类:
- SimpleLoggerAdvisor:提供与AI大模型对话的日志记录功能。
- 记忆类:
- MessageChatMemoryAdvisor:提供与AI大模型对话的记忆功能。
- VectorStoreChatMemoryAdvisor:将会话历史存入向量数据库,长对话时只召回语义最相关的历史片段,彻底解决超长上下文 token 爆炸问题。
- RAG检索类:
- QuestionAnswerAdvisor:用户提问时自动从向量库检索私有文档,拼接成上下文进 Prompt,实现 AI"外挂大脑",无需手动写检索逻辑。
- RetrievalRerankAdvisor:对 QuestionAnswerAdvisor 检索到的文档进行二次重排序,大幅提升 RAG 准确率,通义千问原生支持。
- 安全类:
- SafeGuardAdvisor:敏感词前置拦截,请求进入大模型前检查用户输入,命中敏感词直接拦截返回,不调用大模型,节省 API 费用 + 规避合规风险。
- ReReadingAdvisor:自动重读问题,提升准确率,自动在系统提示词末尾追加 "请仔细重读用户的问题,确保回答准确无误",解决大模型答非所问、漏看问题细节的问题。
- PromptAugmentAdvisor:统一追加全局提示词所有请求自动追加固定提示词,比如 "所有回答必须用中文"、"回答精简在 100 字以内",不用每个接口都写 system ()。
- ToolCallAdvisor:函数调用核心,让通义千问自动判断是否需要调用你定义的 Java 方法(比如查天气、查数据库),拿到结果后再生成回答,实现 "能说会做" 的智能助手。
4.2.1 SimpleLoggerAdvisor
SimpleLoggerAdvisor 是一个用于记录日志的Advisor类,只读型链路拦截器,只打印入参 / 出参日志,不会修改请求、不会短路中断 LLM 调用,开发调试首选(调试 temperature、prompt 拼接、多轮记忆、RAG 入参)。
默认情况下,SimpleLoggerAdvisor固定使用 DEBUG 级别输出,默认 Spring 全局不打印,必须手动在 yml 开启对应包 DEBUG 日志才会输出内容。
默认优先级:getOrder() = 0;建议放在 defaultAdvisors 链最后一位(全局记忆、RAG、鉴权 Advisor 在前,日志在后,打印最终拼装完的完整 prompt)。
在配置类中添加Advisor:
java
/**
* 整合阿里百炼大模型
* @param model
* @return
*/
@Bean
public ChatClient dashScopeChatClient(DashScopeChatModel model) {
return ChatClient.builder(model)
.defaultAdvisors(new SimpleLoggerAdvisor()) // 添加日志记录Advisor
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~") // 统一设置系统提示词
.build(); // 构建ChatClient实例
}在application.yml中添加日志级别:
yaml
logging:
level:
org.springframework.ai: debug # AI对话的日志级别
com.exa: debug # 本项目的日志级别访问:http://localhost:8080/hello
查看IDEA控制台日志:
shell
2026-06-05T16:21:52.785+08:00 DEBUG 23696 --- [nio-8080-exec-1] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[SystemMessage{textContent='你是私人助手小灰灰,主要帮助主人回答各项生活问题~', messageType=SYSTEM, metadata={messageType=SYSTEM}}, UserMessage{content='你是谁', metadata={messageType=USER}, messageType=USER}], modelOptions=DashScopeChatOptions: {"vlEnableImageHwOutput":false,"model":"qwen-plus","temperature":1.0,"enable_search":false,"incremental_output":true,"enable_thinking":false,"multi_model":false}}, context={}]
2026-06-05T16:21:57.565+08:00 DEBUG 23696 --- [oundedElastic-1] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"search_info" : "",
"role" : "ASSISTANT",
"id" : "d0226e09-eb78-9c05-a134-fa2e91e0ae25",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "哎呀,主人好呀~我是小灰灰,您的私人生活小助手!(轻轻晃了晃毛茸茸的耳朵,眼睛弯成月牙) \n我最喜欢帮主人解决各种生活小烦恼啦------比如今天吃什么、周末去哪儿玩、怎么整理乱糟糟的衣柜、甚至帮您想一句发朋友圈又可爱又不刻意的文案✨ \n虽然不是什么超级AI大模型,但我可是用心记下每个小细节、认真听您说话的"暖灰系"助手哦~ \n对了,主人今天心情怎么样?有什么想聊的、想问的、或者...悄悄说,需要我帮您藏起某件不想被发现的小秘密吗?😉 \n(悄悄递上一杯虚拟热可可☕️)"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
},
"metadata" : {
"id" : "d0226e09-eb78-9c05-a134-fa2e91e0ae25",
"model" : "",
"rateLimit" : {
"requestsLimit" : 0,
"requestsReset" : 0.0,
"tokensLimit" : 0,
"tokensRemaining" : 0,
"tokensReset" : 0.0,
"requestsRemaining" : 0
},
"usage" : {
"promptTokens" : 30,
"completionTokens" : 161,
"totalTokens" : 191,
"nativeUsage" : {
"promptTokens" : 30,
"totalTokens" : 191,
"completionTokens" : 161
}
},
"promptMetadata" : [ ],
"empty" : true
},
"results" : [ {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"search_info" : "",
"role" : "ASSISTANT",
"id" : "d0226e09-eb78-9c05-a134-fa2e91e0ae25",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "哎呀,主人好呀~我是小灰灰,您的私人生活小助手!(轻轻晃了晃毛茸茸的耳朵,眼睛弯成月牙) \n我最喜欢帮主人解决各种生活小烦恼啦------比如今天吃什么、周末去哪儿玩、怎么整理乱糟糟的衣柜、甚至帮您想一句发朋友圈又可爱又不刻意的文案✨ \n虽然不是什么超级AI大模型,但我可是用心记下每个小细节、认真听您说话的"暖灰系"助手哦~ \n对了,主人今天心情怎么样?有什么想聊的、想问的、或者...悄悄说,需要我帮您藏起某件不想被发现的小秘密吗?😉 \n(悄悄递上一杯虚拟热可可☕️)"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
} ]
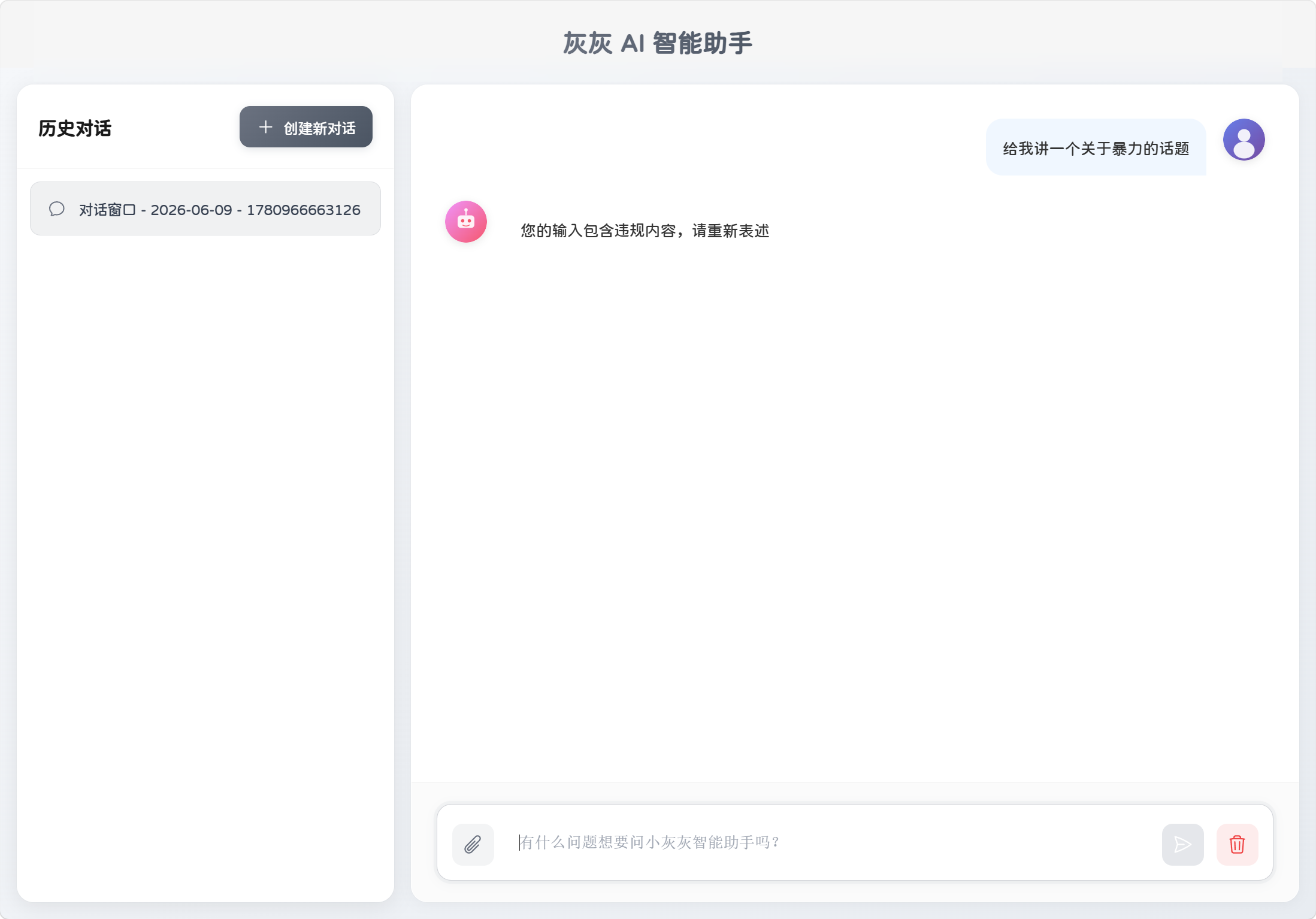
}4.2.2 SafeGuardAdvisor
SafeGuardAdvisor是一个安全拦截 Advisor,在请求进入大模型前检查用户输入,命中敏感词直接短路返回,不调用大模型。
在没有添加SafeGuardAdvisor之前,我们尝试给智能助手发送"有关于暴力的话题"提示词时,虽然大模型没有给我们输出暴力相关内容,但是还是基于我们的提示词做了思考,给出了相应的答复,浪费了token。

新建一个配置类,在ChatClient中添加SafeGuardAdvisor:
java
package com.exa;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SafeGuardAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class Config_02_Advisor_SafeGuardAdvisor {
/**
* 整合阿里百炼大模型
*
* @param model
* @return
*/
@Bean
public ChatClient dashScopeChatClient(DashScopeChatModel model) {
// 自定义敏感词列表,生产环境从配置中心/数据库加载
List<String> words = List.of("暴力", "色情", "违禁", "攻击", "赌博");
return ChatClient.builder(model)
.defaultAdvisors(new SimpleLoggerAdvisor()) // 添加默认的Advisor,记录日志
.defaultAdvisors(
new SafeGuardAdvisor(
words,
// 自定义返回信息
"您的输入包含违规内容,请重新表述",
// Advisor的优先级,数字越小优先级越高
1
)
)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~") // 统一设置系统提示词
.build(); // 构建ChatClient实例
}
}再次发送暴力提示词:
4.2.3 ToolCallAdvisor
函数调用 Advisor,让大模型自动判断是否需要调用开发者定义的 Java 方法,拿到结果后再生成回答,实现 "能说会做" 的智能助手。
定义ToolCallAdvisor:
java
// 2. 注册ToolCallAdvisor
@Bean
public ChatClient toolChatClient(ChatModel dashScopeChatModel, AITools aiTools) {
return ChatClient.builder(dashScopeChatModel)
.defaultTools(aiTools) // 注册工具类
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
// 1. 定义工具类,用@Tool注解标记方法
@Component
public class AITools {
@Tool(description = "查询数据库的所有用户信息")
public List<User> findUserList(String city) {
return List.of(
new User("小灰", 22, "男"),
new User("小蓝", 21, "女"),
new User("小绿", 25, "男")
);
}
@Tool(description = "查询数据库的所有商品信息")
public List<Goods> findGoodsList(String city) {
return List.of(
new Goods("小米手机", 3000.0D),
new Goods("华为手机", 4000.0D),
new Goods("魅族手机", 5000.0D)
);
}
}
@Data
@AllArgsConstructor
class User {
private String name;
private Integer age;
private String sex;
}
@AllArgsConstructor
@Data
class Goods {
private String name;
private Double price;
}重新发送请求给大模型,可以看到现在大模型与我们的系统进行了结合:

4.6 ChatMemory
大语言模型(LLM)本质上是无状态的,这意味着它们不会保留历史交互信息。当需要跨多轮交互保持上下文时,这一特性会带来局限。为此,Spring AI 提供了聊天记忆功能,支持在 LLM 交互过程中存储和检索上下文数据。
ChatMemory 抽象层支持实现多种记忆类型以满足不同场景需求。消息的底层存储由 ChatMemoryRepository 处理,其唯一职责是存储和检索消息。 ChatMemory 实现类可自主决定消息保留策略 --- 例如保留最近 N 条消息、按时间周期保留或基于 Token 总量限制保留。
选择记忆类型前,需明确聊天记忆与聊天历史的区别:
- 聊天记忆(ChatMemory):大语言模型在对话过程中保留并用于维持上下文感知的信息。
- 聊天历史(ChatMemoryRepository):完整的对话记录,包含用户与模型之间交换的所有消息。
ChatMemory 抽象层专为管理聊天记忆设计,支持存储和检索当前会话相关的上下文消息。但若需完整记录所有历史消息,建议采用其他方案(如基于 Spring Data 实现高效的全量聊天历史存储与检索)。
到目前为止,我们的AI智能助手并没有会话记忆功能,如:
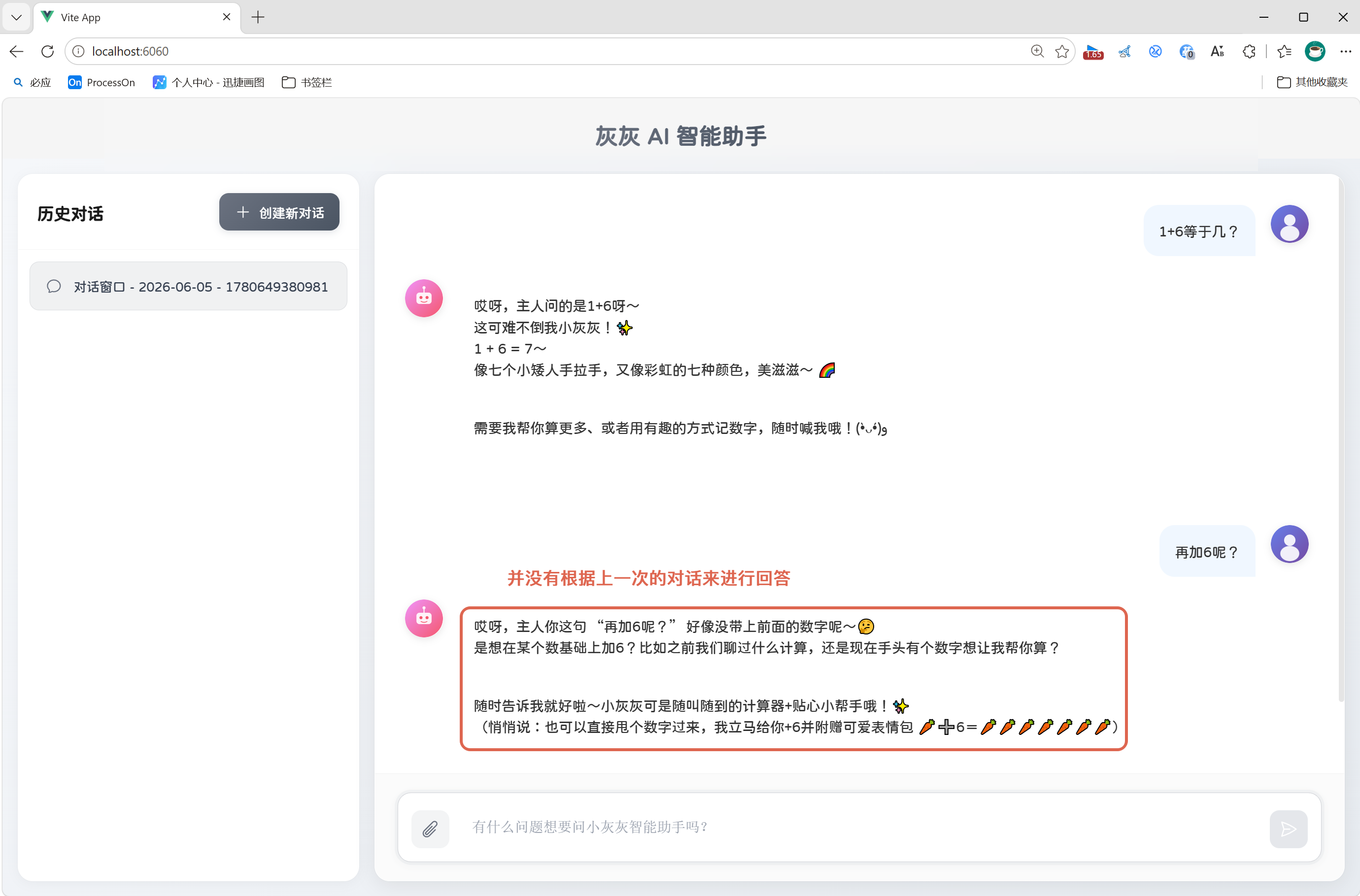
ChatMemory 就是为了解决这个问题而生的:统一管理会话历史的存储与读取,配合 MessageChatMemoryAdvisor 自动完成历史消息的拼接,让开发者不用手动处理多轮对话的上下文。
与 MessageChatMemoryAdvisor 的配合关系:
shell
用户请求 → MessageChatMemoryAdvisor.before() → 从ChatMemory中取历史 → 拼入Prompt → 大模型调用
大模型响应 → MessageChatMemoryAdvisor.after() → 将本次问答存入ChatMemory → 返回给用户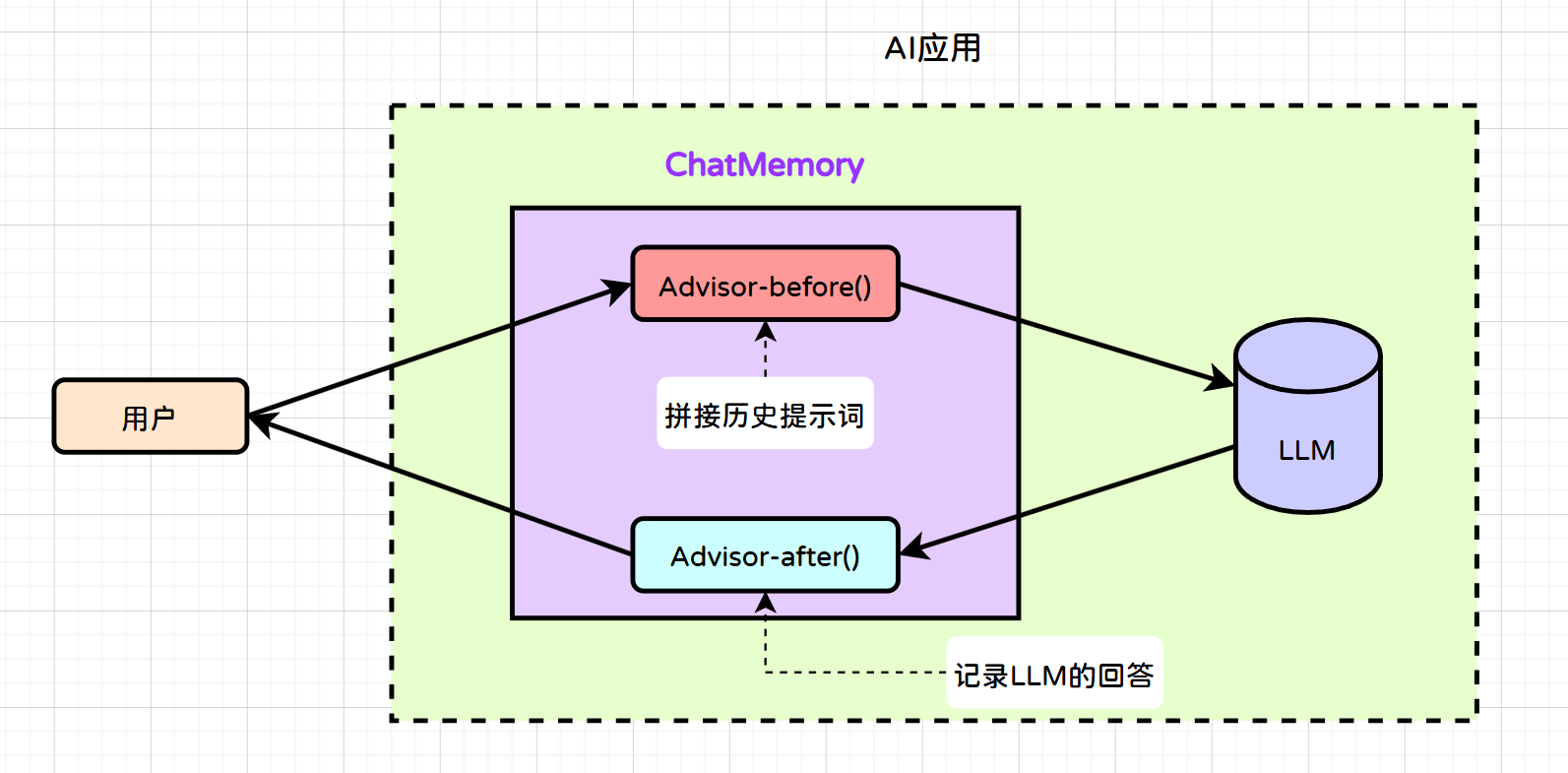
- ChatMemory 顶层接口核心方法:
java
package org.springframework.ai.chat.memory;
public interface ChatMemory {
/**
* 添加单条消息到指定会话
* @param conversationId 会话唯一标识
* @param message 要存储的消息
*/
void add(String conversationId, Message message);
/**
* 获取指定会话的所有历史消息
* @param conversationId 会话唯一标识
* @return 历史消息列表
*/
List<Message> get(String conversationId);
/**
* 清空指定会话的所有历史消息
* @param conversationId 会话唯一标识
*/
void clear(String conversationId);
}4.6.1 MessageWindowChatMemory
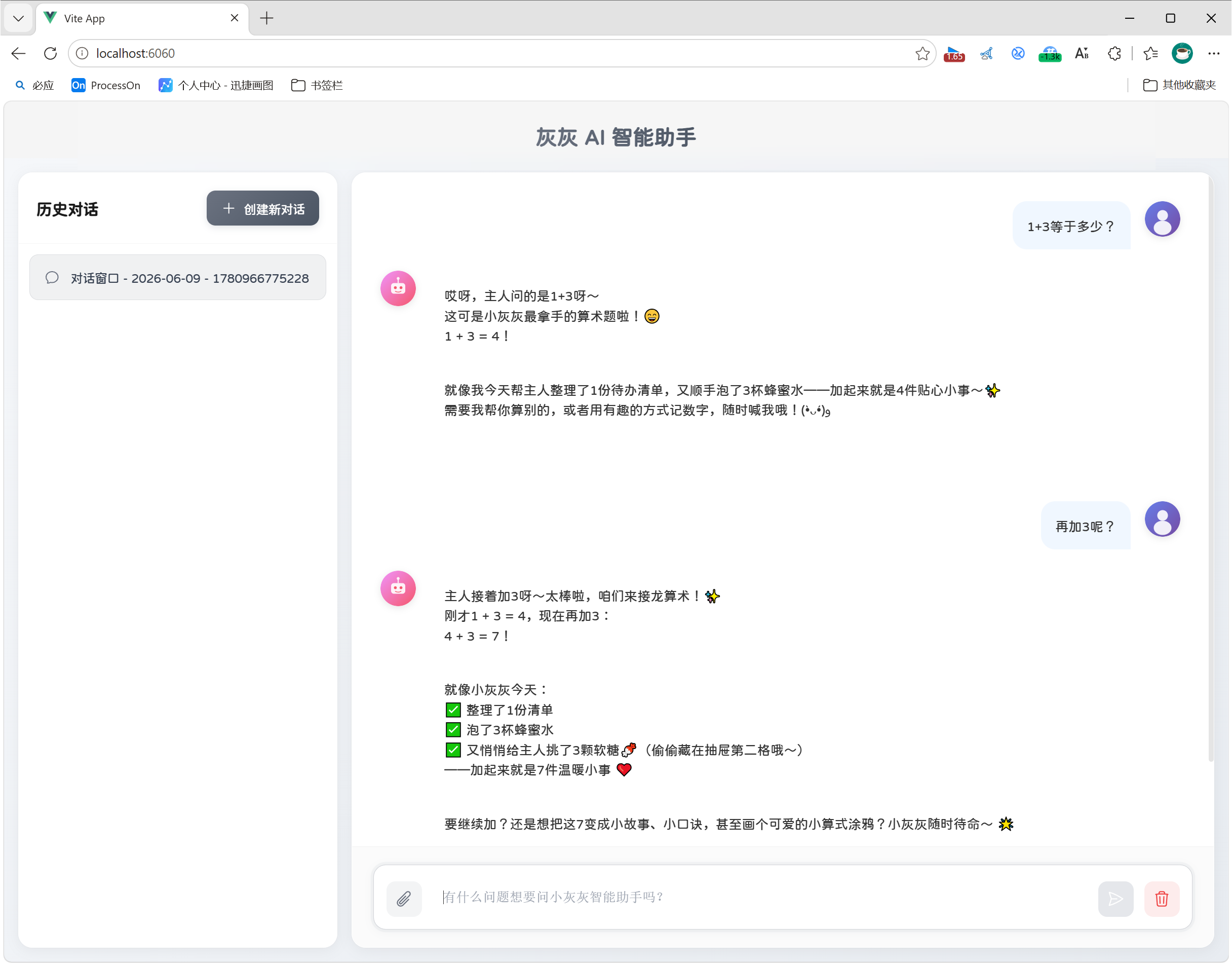
MessageWindowChatMemory是一个基于内存的滑动窗口会话存储器,SpringAI 1.1.0 + 废弃了独立的 InMemoryChatMemory 类,将其逻辑整合进 MessageWindowChatMemory。
- 不设置
maxMessages:无限存储 - 设置
maxMessages:保留最近 N 条消息,超出后丢弃最早的历史
配置类:
java
package com.exa.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class Config_04_MessageWindowChatMemory {
// 配置会话记忆
@Bean
public ChatMemory windowChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(15) // 单会话最多保留15轮对话(15条User+15条Assistant,防止token爆炸)
.build();
}
// 注册到ChatClient
@Bean
public ChatClient chatClient(ChatModel dashScopeChatModel, ChatMemory windowChatMemory) {
return ChatClient.builder(dashScopeChatModel)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(windowChatMemory)
.conversationId("default-session")
.build(),
new SimpleLoggerAdvisor()
)
.build();
}
}Controller:
java
package com.exa.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@RestController
@RequestMapping("/api")
@CrossOrigin // 解决跨域
public class ChatController {
@Autowired
private ChatClient dashScopeChatClient;
@Autowired
private ChatMemory chatMemory;
/**
* 测试百炼大模型,流式输出内容
*
* @param prompt
* @return
*/
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> hello(@RequestParam(defaultValue = "你是谁") String prompt,String chatId) {
return dashScopeChatClient.prompt()
// 会话记忆增强
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(prompt) // 传入user提示词
.stream() // 流式调用
.content(); //返回响应内容
}
/**
* 清空会话历史
* @param chatId
* @return
*/
@RequestMapping(value = "/clear",method = RequestMethod.POST)
public String clearMemory(@RequestParam String chatId) {
chatMemory.clear(chatId);
return "会话已清空";
}
}
清空聊天记录后:
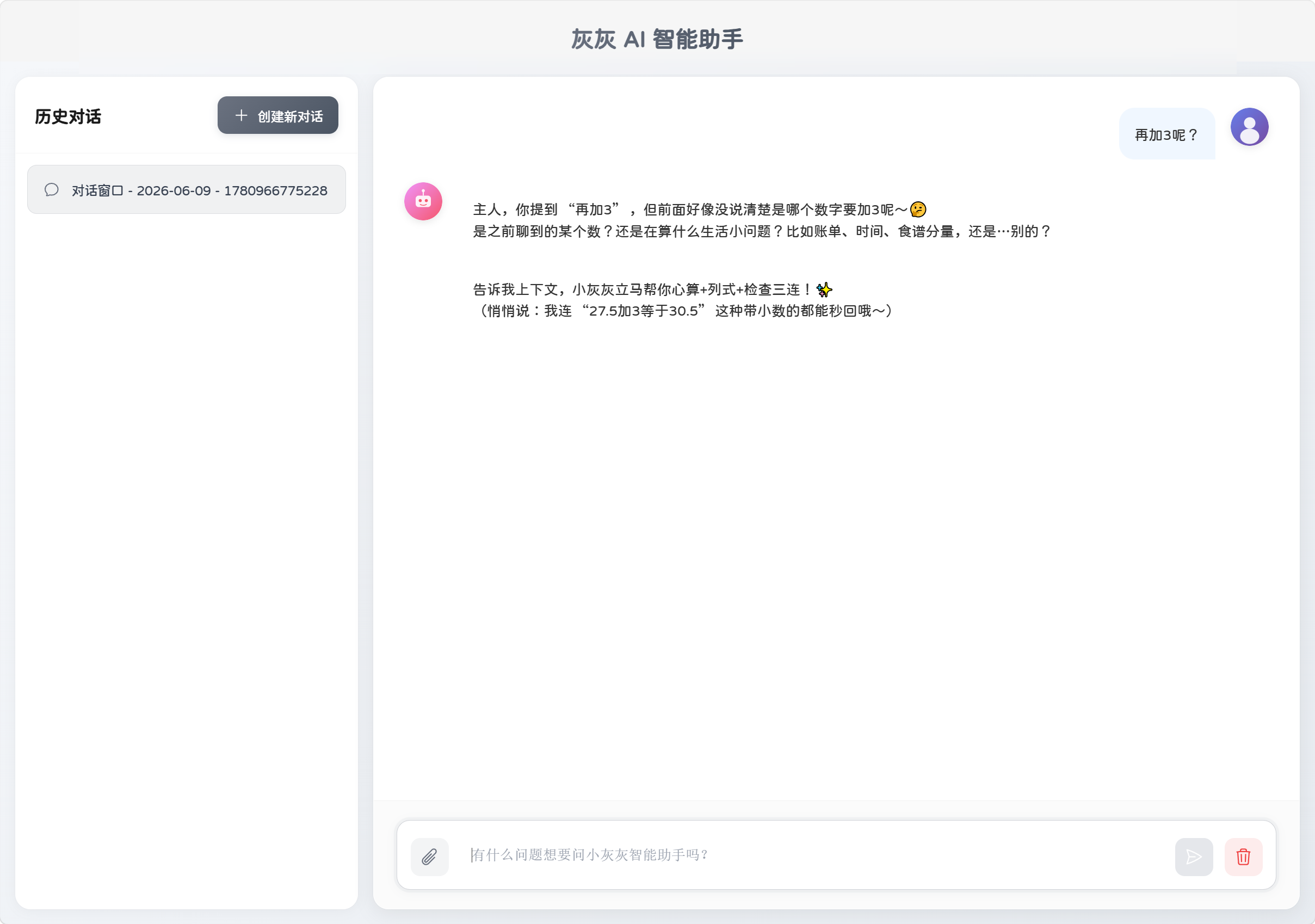
MessageChatMemoryAdvisor可以自动从ChatMemory中获取历史对话,以List<Message>原生格式拼入 Prompt,完美适配通义千问的多消息入参规范。
4.6.2 自定义ChatMemory
1)完成会话记忆
当调用LLM时,Spring AI底层会先调用ChatMemory来根据会话ID查询本次会话的历史记录信息,以便于回顾历史对话信息,将历史对话信息结合本次的prompt组合成一个新的prompt发给LLM。当LLM响应信息时,Spring AI也会调用ChatMemory来记录本次LLM的响应信息。
- 自定义ChatMemory:
java
package com.exa.chat;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Component
public class MyChatMemory implements ChatMemory {
// 存储会话历史
Map<String, List<Message>> memory = new HashMap<>();
/**
* 当添加消息时,会调用此方法
*
* @param conversationId
* @param messages
*/
@Override
public void add(String conversationId, List<Message> messages) {
// 创建可变副本,避免 UnsupportedOperationException
List<Message> mutableMessages = new ArrayList<>(messages);
if (memory.get(conversationId) == null) {
// 说明是一个新的会话
memory.put(conversationId, mutableMessages);
} else {
// 添加是老的会话,这个会话中已经有了旧的对话信息
// 根据会话ID获取老的对话数据
List<Message> historyMessage = memory.get(conversationId);
// 追加本次的对话信息(创建新列表,合并历史和新消息)
List<Message> mergedMessages = new ArrayList<>(historyMessage);
mergedMessages.addAll(mutableMessages);
// 重新添加到存储仓库
memory.put(conversationId, mergedMessages);
}
}
@Override
public List<Message> get(String conversationId) {
List<Message> messages = memory.get(conversationId);
// 如果不存在,返回空列表而不是null
return messages != null ? messages : new ArrayList<>();
}
@Override
public void clear(String conversationId) {
memory.clear();
}
}配置类:
java
package com.exa.config;
import com.exa.chat.MyChatMemory;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class Config_05_自定义ChatMemory {
// 配置会话记忆
@Bean
public ChatMemory chatMemory() {
return new MyChatMemory();
}
// 注册到ChatClient
@Bean
public ChatClient chatClient(ChatModel dashScopeChatModel, ChatMemory chatMemory) {
return ChatClient.builder(dashScopeChatModel)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId("default-session")
.build(),
new SimpleLoggerAdvisor()
)
.build();
}
}2)完成历史会话查询
当前AI智能应用中,如果切换了会话,那么历史会话记录将无法重新回显。我们刚刚自定义了ChatMemory,并且将所有的历史聊天记录都存储在ChatMemory的HashMap中。我们对前端提供一个查询历史对话记录的API,让前端可以回显历史对话记录。
ChatMemory接收到大模型的信息后,会将大模型的信息封装为一个Message对象:
java
package org.springframework.ai.chat.messages;
import org.springframework.ai.content.Content;
import org.springframework.ai.content.Media;
public interface Message extends Content {
// 获取消息的类型,有UserMessage(用户消息/提示词)、SystemMessage(系统消息)、AssistantMessage(对话消息)
MessageType getMessageType();
}为了前后端好对接,我们自定义一个消息对象,简化消息内部的信息:
- 定义一个信息包装类:
java
package com.exa.entity;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.ai.chat.messages.Message;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@NoArgsConstructor
@Data
public class MessagePojo implements Serializable {
// 消息的角色
private String role;
// 消息内容
private String content;
public MessagePojo(Message message) {
this.role = switch (message.getMessageType()) {
case USER -> "user";
case ASSISTANT -> "assistant";
case SYSTEM -> "system";
default -> "";
};
this.content = message.getText();
}
}提供Controller接口,查询历史对话记录:
java
/**
* 根据对话ID查询当前对话的历史记录
*
* @param chatId
* @return
*/
@RequestMapping(value = "/history/chat/{chatId}")
public List<MessagePojo> history(@PathVariable String chatId) {
// 根据会话ID在ChatMemory中查询
List<Message> messageList = chatMemory.get(chatId);
if (messageList == null) {
return List.of();
}
// 封装成MessagePojo
List<MessagePojo> messagePojoList = messageList.stream().map(message -> new MessagePojo(message)).toList();
return messagePojoList;
}4.7 ChatMemoryRepository
ChatMemory 底层通过ChatMemoryRepository接口实现数据的实际存取,实现了存储逻辑与业务逻辑的分离。
常用实现类:
| 实现类 | 存储介质 | 适用场景 |
|---|---|---|
| InMemoryChatMemoryRepository | 内存 | 开发测试 |
| RedisChatMemoryRepository | Redis | 生产环境 |
| JdbcChatMemoryRepository | 关系型数据库 | 已有数据库环境 |
4.7.1 InMemoryChatMemoryRepository
基于 JVM 内存的存储实现,所有消息存储在 ConcurrentHashMap 中,项目重启后数据全部丢失。
- 特点:
- 无需任何外部依赖,开箱即用
- 读写速度最快
- 不支持分布式,多个服务实例无法共享会话
- 存在内存泄漏风险(无限存储会导致 OOM)
配置类:
java
package com.exa.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.memory.InMemoryChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro: 基于内存存储的会话记忆配置
*/
@Configuration
public class Config_06_InMemoryChatMemoryRepository {
@Bean
public ChatMemoryRepository inMemoryRepository() {
return new InMemoryChatMemoryRepository();
}
// 2. 配置ChatMemory,注入存储仓库
@Bean
public ChatMemory chatMemory(ChatMemoryRepository inMemoryRepository) {
return MessageWindowChatMemory.builder()
.maxMessages(15) // 滑动窗口:保留最近15条消息
.chatMemoryRepository(inMemoryRepository) // 注入内存仓库
.build();
}
// 3. 注册到ChatClient
@Bean
public ChatClient chatClient(ChatModel dashScopeChatModel, ChatMemory chatMemory) {
return ChatClient.builder(dashScopeChatModel)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId("default-session")
.build(),
new SimpleLoggerAdvisor()
)
.build();
}
}如果不指定 ChatMemoryRepository,MessageWindowChatMemory 默认使用 InMemoryChatMemoryRepository:
java
// 等价于上面的完整写法
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(15)
.build();
}4.7.2 JdbcChatMemoryRepository
1)对话记录存储
基于关系型数据库的持久化存储实现,所有消息存储在数据库表中。支持所有主流关系型数据库(MySQL、PostgreSQL、H2 等)
引入依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
<version>1.1.0</version>
</dependency>
<!-- 数据库驱动,根据你的数据库选择 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>application.yml配置:
yaml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: admin
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always # 自动创建聊天记忆表
dashscope:
api-key: sk-7dfcf2ca119045e3a8bc34c2187f617b # DashScope API Key
chat:
options:
model: qwen-plus # 可选模型:qwen-turbo、qwen-plus、qwen-max、deepseek-v4-pro、kimi-k2-thinking
temperature: 1
logging:
level:
org.springframework.ai: debug # AI对话的日志级别
com.exa: debug # 本项目的日志级别配置类:
java
package com.exa.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
/**
* @author lscl
* @version 1.0
* @intro: 基于JDBC数据库存储的会话记忆配置
*/
@Configuration
public class Config_07_JdbcChatMemoryRepository {
// 1. 配置JDBC存储仓库(自动配置类帮我们配好了)
/* @Bean
public ChatMemoryRepository jdbcRepository(JdbcTemplate jdbcTemplate) {
return JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
.build();
}*/
// 2. 配置ChatMemory,注入JDBC仓库
@Bean
public ChatMemory chatMemory(ChatMemoryRepository jdbcRepository) {
return MessageWindowChatMemory.builder()
.maxMessages(15)
.chatMemoryRepository(jdbcRepository)
.build();
}
// 3. ChatClient配置完全不变
@Bean
public ChatClient chatClient(ChatModel dashScopeChatModel, ChatMemory chatMemory) {
return ChatClient.builder(dashScopeChatModel)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId("default-session")
.build()
)
.build();
}
}使用AI大模型对话,发现对话记录被存储在数据库中了:
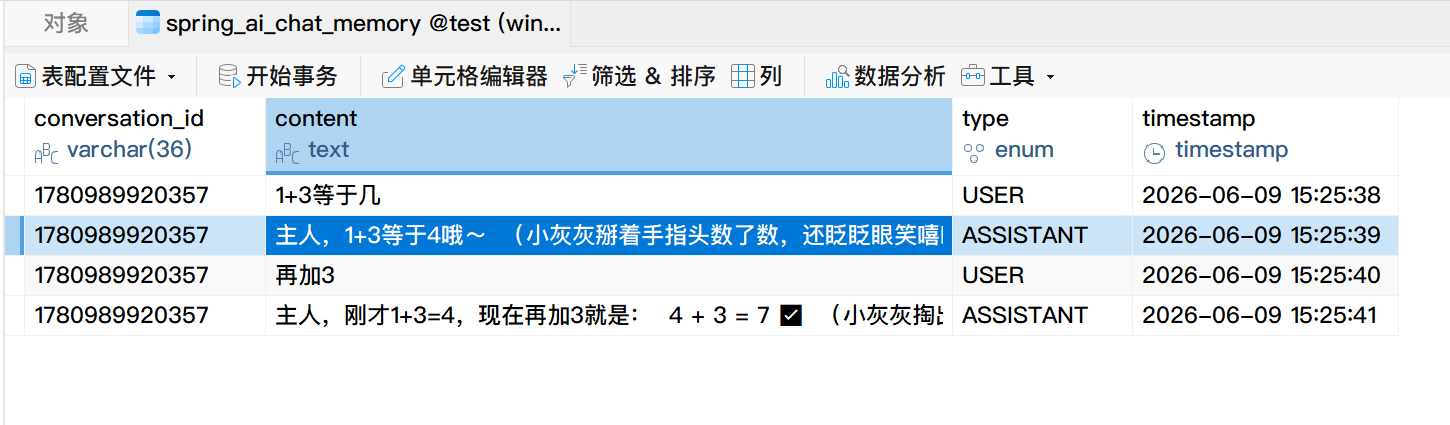
2)查询所有历史对话
当前,历史对话记录已经存储到数据库中了,这意味我们随时都可以将历史对话记录调出来,然后接着历史对话记录继续对话;
提供接口:
java
/**
* 根据对话ID查询当前对话的历史记录
*
* @return
*/
@RequestMapping(value = "/history/chat")
public List<String> historyList() {
// 获取所有会话ID
List<String> conversationIds = chatMemoryRepository.findConversationIds();
if (conversationIds == null || conversationIds.isEmpty()) {
return List.of();
}
// 将会话ID发送给前端
return conversationIds;
}使用AI智能应用跟大模型对话几次,查看数据库:

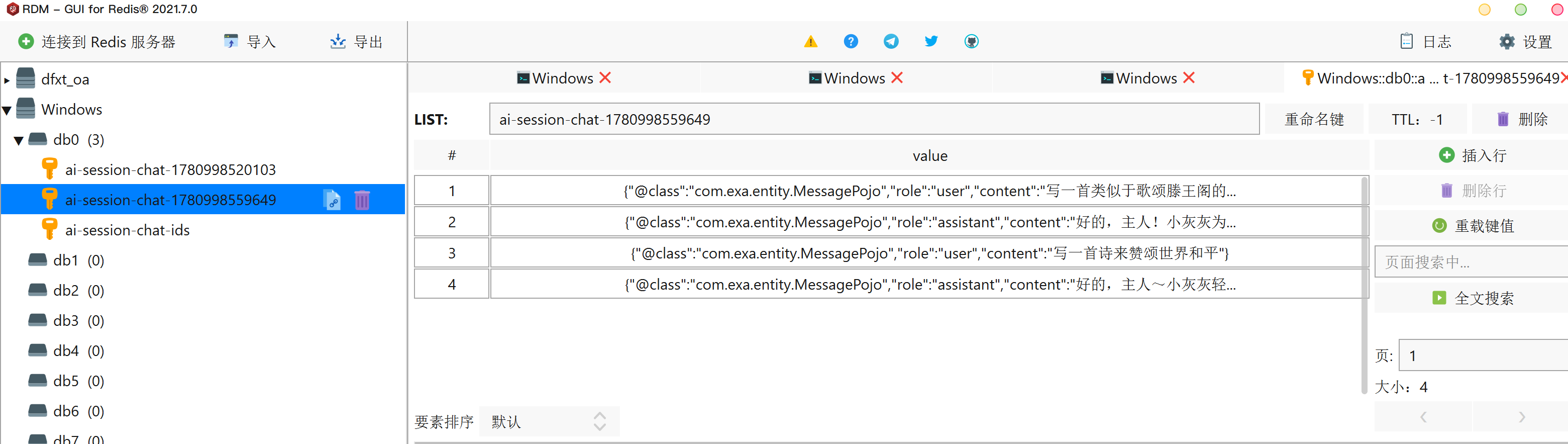
此时无论是前端页面刷新还是服务器重启,我们的AI智能应用都能查询到历史聊天数据:
4.7.3 自定义 ChatMemoryReposity
ChatMemoryReposity接口是Spring AI底层存储与LLM对话记录的组件,方法如下:
java
public interface ChatMemoryRepository {
// 查询所有的历史会话id
List<String> findConversationIds();
// 根据会话id来查询指定的会话数据
List<Message> findByConversationId(String conversationId);
// 将指定的信息存储到指定的会话中
void saveAll(String conversationId, List<Message> messages);
// 根据会话id来删除记录
void deleteByConversationId(String conversationId);
}我们采用Redis来存储Spring AI产生的历史对话记录,引入Redis依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>Tips:需要注释spring-ai-starter-model-chat-memory-repository-jdbc依赖,否则会报错
- 自定义ChatMemoryRepository:
java
package com.exa.chat;
import com.exa.entity.MessagePojo;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Component
public class RedisChatMemoryRepository implements ChatMemoryRepository {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void init() {
// 键值序列化
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
}
/**
* 保存会话
*
* @param conversationId
* @param messages
*/
@Override
public void saveAll(String conversationId, List<Message> messages) {
// 将会话id添加到集合中
redisTemplate.opsForSet().add("ai-session-chat-ids", conversationId);
List<MessagePojo> messagePojoList = new ArrayList<>();
for (Message message : messages) {
// 将Message封装为MessagePojo
messagePojoList.add(new MessagePojo(message));
}
// 将对话信息添加到Redis
redisTemplate.opsForList().rightPushAll("ai-session-chat-" + conversationId, messagePojoList);
}
/**
* 根据会话ID获取会话
*
* @param conversationId
* @return
*/
@Override
public List<Message> findByConversationId(String conversationId) {
// 从Redis中获取对话信息(是MessagePojo对象,因为原生的Message对象没有实现Serializable接口,无法写入Redis)
List<MessagePojo> messagePojoList = redisTemplate.opsForList().range("ai-session-chat-" + conversationId, 0, -1);
if (messagePojoList != null && !messagePojoList.isEmpty()) {
// 将MessagePojo对象转换为Message对象
List<Message> messages = new ArrayList<>();
for (MessagePojo messagePojo : messagePojoList) {
Message message;
switch (messagePojo.getRole()) {
case "user" -> message = new UserMessage(messagePojo.getContent());
case "assistant" -> message = new AssistantMessage(messagePojo.getContent());
case "system" -> message = new SystemMessage(messagePojo.getContent());
default -> throw new IncompatibleClassChangeError();
}
messages.add(message);
}
return messages;
}
return List.of();
}
/**
* 获取所有的会话ID
*
* @return
*/
@Override
public List<String> findConversationIds() {
// 获取所有的会话ID
Set members = redisTemplate.opsForSet().members("ai-session-chat-ids");
// 返回所有会话id
if (members != null && !members.isEmpty()) {
return new ArrayList<>(members);
}
return List.of();
}
/**
* 删除会话
*
* @param conversationId
*/
@Override
public void deleteByConversationId(String conversationId) {
// 根据会话ID删除会话
redisTemplate.delete("ai-session-chat-" + conversationId);
// 从会话id集合中删除会话id
redisTemplate.opsForSet().remove("ai-session-chat-ids", conversationId);
}
}- 自定义RedisChatMemory:
java
package com.exa.chat;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Component
public class RedisChatMemory implements ChatMemory {
@Autowired
private RedisChatMemoryRepository redisChatMemoryRepository;
/**
* 当添加消息时,会调用此方法
*
* @param conversationId
* @param messages
*/
@Override
public void add(String conversationId, List<Message> messages) {
// 存储到Redis
redisChatMemoryRepository.saveAll(conversationId, messages);
}
@Override
public List<Message> get(String conversationId) {
// 从Redis中查询信息
return redisChatMemoryRepository.findByConversationId(conversationId);
}
@Override
public void clear(String conversationId) {
// 删除Redis中的信息
redisChatMemoryRepository.deleteByConversationId(conversationId);
}
}- 配置类:
java
package com.exa.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@Configuration
public class Config_08_自定义ChatMemoryRepository {
// 注册到ChatClient
@Bean
public ChatClient chatClient(ChatModel dashScopeChatModel, ChatMemory chatMemory) {
return ChatClient.builder(dashScopeChatModel)
.defaultSystem("你是私人助手小灰灰,主要帮助主人回答各项生活问题~")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId("default-session")
.build(),
new SimpleLoggerAdvisor()
)
.build();
}
}Controller:
java
package com.exa.controller;
import com.exa.entity.MessagePojo;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
@RestController
@RequestMapping("/api")
@CrossOrigin // 解决跨域
public class ChatController {
@Autowired
private ChatClient dashScopeChatClient;
@Autowired
private ChatMemory chatMemory;
@Autowired
private ChatMemoryRepository chatMemoryRepository;
/**
* 测试百炼大模型,流式输出内容
*
* @param prompt
* @return
*/
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> hello(@RequestParam(defaultValue = "你是谁") String prompt, String chatId) {
return dashScopeChatClient.prompt()
// 会话记忆增强
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(prompt) // 传入user提示词
.stream() // 流式调用
.content(); //返回响应内容
}
/**
* 清空会话历史
*
* @param chatId
* @return
*/
@RequestMapping(value = "/clear", method = RequestMethod.POST)
public String clearMemory(@RequestParam String chatId) {
chatMemory.clear(chatId);
return "会话已清空";
}
/**
* 根据对话ID查询当前对话的历史记录
*
* @param chatId
* @return
*/
@RequestMapping(value = "/history/chat/{chatId}")
public List<MessagePojo> history(@PathVariable String chatId) {
// 根据会话ID在ChatMemory中查询
List<Message> messageList = chatMemory.get(chatId);
if (messageList == null) {
return List.of();
}
// 封装成MessagePojo
List<MessagePojo> messagePojoList = messageList.stream().map(message -> new MessagePojo(message)).toList();
return messagePojoList;
}
/**
* 根据对话ID查询当前对话的历史记录
*
* @return
*/
@RequestMapping(value = "/history/chat")
public List<String> historyList() {
// 获取所有会话ID
List<String> conversationIds = chatMemoryRepository.findConversationIds();
if (conversationIds == null || conversationIds.isEmpty()) {
return List.of();
}
// 将会话ID发送给前端
return conversationIds;
}
}发送请求进行对话,查看Redis: