1. RAG
1.1 RAG概念
对于【AI 大模型】来说,它最擅长的是语义理解和文本总结,最不擅长的就是获取实时的信息。因为大模型的训练数据是有截止日期的!
对于【搜索引擎】来说,它最擅长的就是获取实时的信息,缺点是信息分散,每次都需要人为进行总结。
大模型与搜索引擎的结合,就是给 AI 配备了一个活字典,让 AI 可以随时进行查阅。
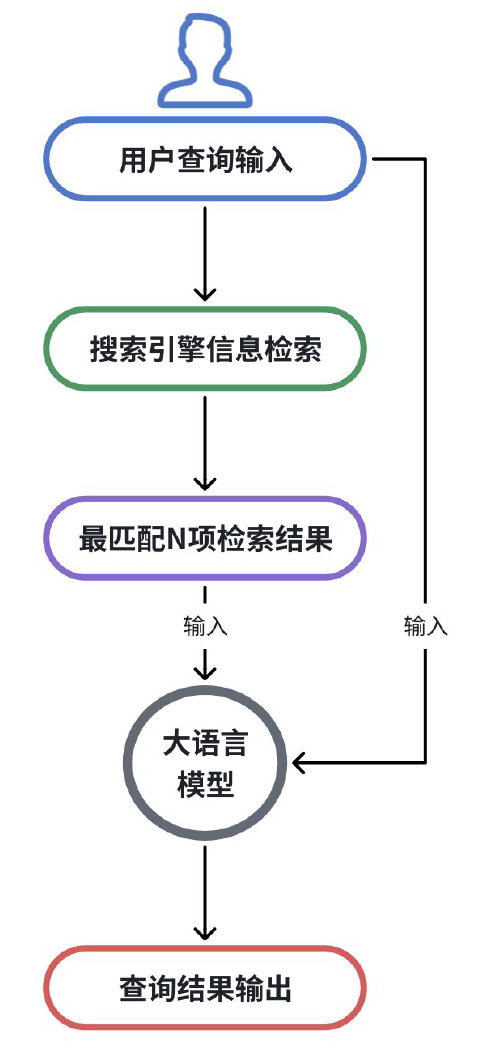
搜索引擎可以帮我们解决实时数据的获取,但获取到的数据也是受限的。它只能获取到公开在网络中的数据,而无法获取到一些本地数据,或企业内部的私有数据等,此时该如何?
答案是使用 RAG(检索增强生成)技术!当用户向 LLM 提问时,系统首先在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。与 AI 搜索类比,本质是知识库改变了,从搜索引擎线上搜索改为了本地或私有知识库中搜索。
1.2 RAG 流程
RAG 的流程分为【离线数据处理】和【在线检索】两个过程。
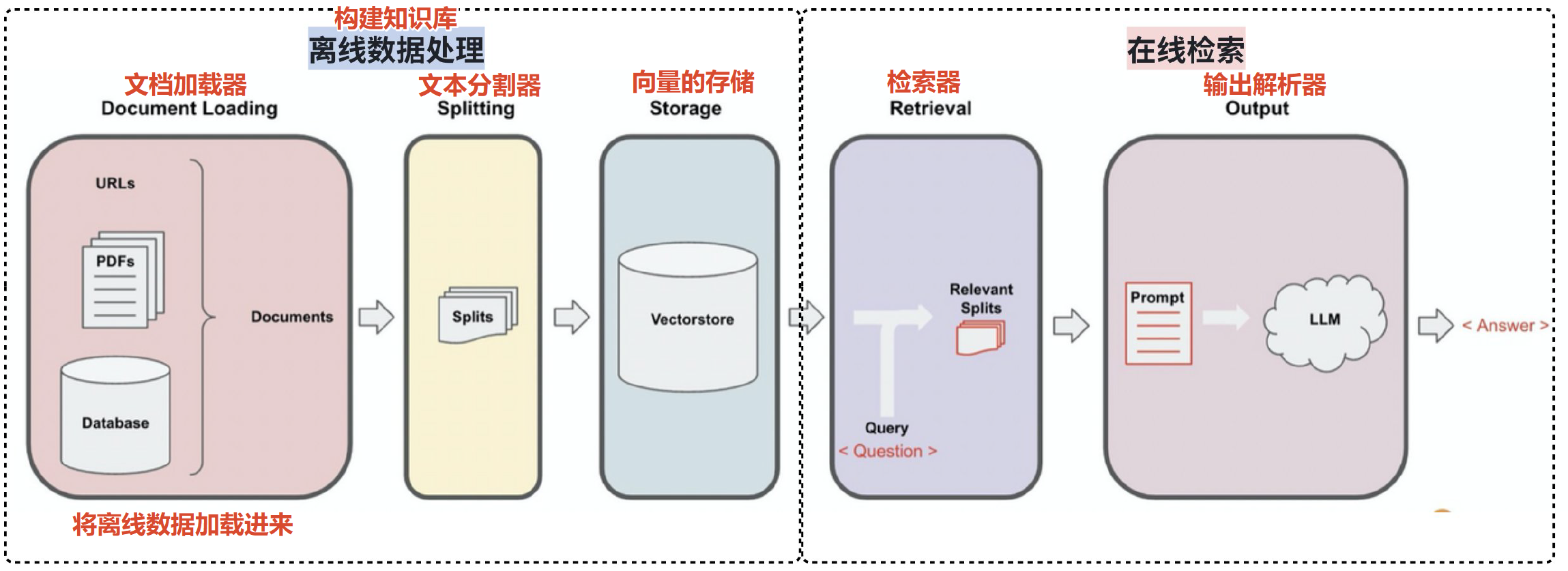
- 文档加载 (Document Loading):加载多种不同来源加载文档。LangChain 提供了 100 多种不同的文档加载器,包括 PDF 在内的非结构化的数据、SQL 在内的结构化的数据,以及 Python、Java之类的代码等。
- 文本分割 (Splitting):文本分割器把 Documents 切分为指定大小的块。
- 存储 (Storage):存储涉及到两个环节,分别是:
将切分好的文档块进行嵌入(Embedding),即将文档块转换成向量的形式。
将 Embedding 后的向量数据,存储到向量数据库中。 - 检索 (Retrieval):数据存入向量数据库后。当我们需要进行数据检索时,会通过某种检索算法找到与输入问题相似的文档块。
- 输出 (Output):把问题以及检索出来的文档块一起提交给 LLM,LLM 会通过问题和检索出来的提示一起来生成更加合理的答案。
2. Document文档类
要想实现 RAG,首先就需要从源中获取数据,即加载数据或文档。这是通过 LangChain 的文档加载器完成的。LangChain 文档加载器可以将各种数据源加载成一系列的文档对象Document 。
class langchain_core.documents.base.Document 用于存储一段文本和相关元数据的类,我们可以直接定义LangChain 文档列表:
python
from langchain_core.documents import Document
# 手动定义文档列表
documents = [
Document(
# 内容--字符串文本
page_content="狗是忠实的伴侣",
# 元数据字典--元数据属性(文档源、与其他文档的关系以及其他属性信息)
metadata={"source": "pets-doc"},
),
Document(
# 内容
page_content="猫是很好的宠物",
# 元数据字典--元数据属性(文档源、与其他文档的关系以及其他属性信息)
metadata={"source": "pets-doc"},
)
]对于单个Document类,它一般表示较大的文档的某个块或者某一页,而不是表示一整个文档。
3. 加载PDF文档
将本地的 PDF 文档加载到 LangChain 中,其实就是将 PDF 文档转换为一个个Document 对象。这时就需要我们使用 PyPDFLoader 文档加载器完成这一功能。
python
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.documents import Document
# 文档加载器(PDF)--默认将文档按照分页进行拆分
loader = PyPDFLoader(file_path="../Docs/pdf/AI 八股文.pdf")
# 加载--生成文档列表
docs = loader.load()
print(f"PDF文档总页数:{len(docs)}")
print(f"第二页文本的内容(前200)是:\n{docs[1].page_content[:200]}\n")输出结果:
python
PDF文档总页数:19
第二页文本的内容(前200)是:
是指通过计算机系统模拟⼈类智能的技术。通过这种技术,可以实现⼈类的认知和思维活动,从⽽
可以完成许多复杂的任务,⽐如学习,推理决策等。本质就是通过算法和数据,让机器具备类⼈能⼒。
刷短视频,短视频平台知道你喜欢看什么,⼀直给你推荐→这就是⼈⼯智能在"学习"和"预测"
你的喜好。(⽐如抖⾳、⼩红书等都有这样的能⼒)
跟语⾳助⼿说话,它能听懂你在讲啥,还会回答你→这是⼈⼯智能PDF加载器只是将文本加载进来了,图片并没有加载进来。
现在许多 LLM 支持对多模态输入(例如图像)进行推理。在某些应用程序中,例如对具有复杂布局、图表或扫描的 PDF 进行问答,可以跳过 PDF 解析,直接将 PDF 页面转换为图像并将其直接传递给模型可能是更准确的。
4. 加载 Markdown 文件
将本地的Markdown 文档加载到 LangChain 中,需要我们使用UnstructuredMarkdownLoader 文档加载器完成这一功能。
python
from langchain_community.document_loaders import PyPDFLoader, UnstructuredMarkdownLoader
from langchain_core.documents import Document
# 文档加载器(MD)
md_loader = UnstructuredMarkdownLoader("../Docs/markdown/【LangChain-AI】核心组件 -- 输出解析器.md")
# load()方法将本地文件加载成document列表
docs = md_loader.load()
print(f"MD文档总页数:{len(docs)}")输出结果:
python
MD文档总页数:1可以看到文档的总页数是1,这是因为MD加载器默认将文档加载成一个,但是我们可以通过设置参数mode来改变加载模式。
UnstructuredMarkdownLoader有以下关键函数:
- init() 初始化函数,所需参数:
file_path:表示要加载的Markdown 文件的路径。
mode:加载文件时要使用的模式。可以是single或elements。默认为single。(single:文档将作为单个Document对象返回;elements:会将文档拆分为Title和NarrativeText等不同类型的元素。)load() → list[Document]:将数据加载到文档对象中。返回文档对象列表。
elements模式代码:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 文档加载器(MD)
md_loader = UnstructuredMarkdownLoader(
"../Docs/markdown/【LangChain-AI】核心组件 -- 输出解析器.md",
# mode="single", # MD 加载器默认将文档加载为一个
mode="elements", # 拆分成不同类型的子块
)
# load()方法将本地文件加载成document列表
docs = md_loader.load()
print(f"MD文档总数:{len(docs)}")
print(f"第一个文档的内容是:\n{docs[0].page_content}\n")
print(f"第一个文档的元数据字典是:\n{docs[0].metadata}\n")
print(f"第二个文档的内容是:\n{docs[1].page_content}\n")
print(f"第二个文档的元数据字典是:\n{docs[1].metadata}\n")输出结果:
python
MD文档总数:30
第一个文档的内容是:
1. 概念
第一个文档的元数据字典是:
{'source': '../Docs/markdown/【LangChain-AI】核心组件 -- 输出解析器.md', 'category_depth': 0, 'languages': ['eng'], 'file_directory': '../Docs/markdown', 'filename': '【LangChain-AI】核心组件 -- 输出解析器.md', 'filetype': 'text/markdown', 'last_modified': '2026-06-22T16:27:49', 'category': 'Title', 'element_id': '6bcffefc7122f399d559fa6659eba47c'}
第二个文档的内容是:
输出解析器负责获取模型的输出,并将输出转换为更结构化的格式。
第二个文档的元数据字典是:
{'source': '../Docs/markdown/【LangChain-AI】核心组件 -- 输出解析器.md', 'languages': ['eng'], 'file_directory': '../Docs/markdown', 'filename': '【LangChain-AI】核心组件 -- 输出解析器.md', 'filetype': 'text/markdown', 'last_modified': '2026-06-22T16:27:49', 'parent_id': '6bcffefc7122f399d559fa6659eba47c', 'category': 'UncategorizedText', 'element_id': 'adb5b1f5af96a1cb56b5683833e4b9bc'}
获取当前文档包含的所有类型:
python
print(f"当前MD文档的所有分类:{set(document.metadata["category"] for document in docs)}")输出结果:
python
当前MD文档的所有分类:{'Image', 'Title', 'ListItem', 'Table', 'NarrativeText', 'UncategorizedText'}
Image:图像。使用语法插入的图片。Title:标题。这里包含了一级、二级、三级等标题。ListItem:列表项。以-,*,+开头的无序列表项,或以1.,2.等开头的有序列表项。Table:表格。使用|和-语法创建的表格。NarrativeText:叙述性文本。一个或多个连续的段落。UncategorizedText:未分类文本。通常是:表格中的脚注或注释、图片下方的简短说明、项目符号中非常简短的词组、文档页眉/页脚中的日期或页码等元数据。
对于 LangChain 来说,能加载的文档类型远不止这些,它还能加载网页、一些云提供商文件、社交媒体平台文档等,更多文档加载器见这里。