原文
https://www.zhihu.com/people/fffar/answers
这个问题前两年比较困扰我。那个时候经常调用大模型来生成训练数据,经常出现模型前面多一句"好的,以下是JSON 结果",或者后面少一个引号,程序解析不了。现在已经有一些非常漂亮的解决方法了。最优雅的方法之一是,很多大模型厂商,比如 DeepSeek 的 API,自己有专门的 JSON 模式,可以保证输出的是合法 JSON。
但是合法 JSON 只能保证格式对了,不代表字段也对。我把几个最主流的方法都分享一下吧。
下面是我从《一个大模型算法工程师的诞生》书稿里抽出来的一个样章小节。这本书我已经交稿,将会在不久之后由清华大学出版社出版。
你以后天天要用的东西
这一节的内容,可能看起来不像Transformer、不像注意力机制那样高大上。它不涉及什么精妙的数学推导,也不会出现在顶会论文的标题里。但我可以非常负责任地告诉你:在你真正坐到工位上干活的头三个月里,这一节讲的东西,你用到的频率可能比前面学的所有理论知识加起来还高。
为什么这么说?因为在真实的项目里,大模型的输出几乎从来不是给人直接看的。它的输出是要接到一条流水线里------被程序解析、被数据库存储、被下游系统消费。而程序不会理解自然语言。程序需要的是严格的、可预期的、结构化的数据格式。JSON是目前最通用的那种格式。
你会在各种各样的场景里碰到这个需求。做智能客服的时候,用户发来一条消息,模型要从里面提取意图和关键信息,输出一个JSON,传给后台系统自动处理。用大模型批量生成训练数据的时候,每一条数据都必须是严格的JSONL格式,差一个逗号都喂不进训练脚本。用大模型做数据清洗和标注的时候,模型输出的分类标签、置信度、标注理由必须是结构化的,才能批量写进数据库供后续分析。后面如果接触到Agent(智能体)的开发,模型需要判断"该调用哪个工具、传什么参数",这个判断结果也是一个JSON。
而且不仅仅是JSON。XML、YAML、CSV、自定义的模板格式,凡是结构化的输出,面临的问题和解决思路都是万变不离其宗的。这一节用JSON做主角,但你学到的方法论可以平移到任何结构化格式上。
我之所以纠结了很久最终决定把这一节加上,就是因为这个话题太实战了。它不会出现在任何教科书的目录里,但你第一天上班就会碰到,而且你碰到之后会发现,网上搜到的零碎经验帖根本帮不了你建立系统性的认知。我希望你读完这一节之后,面对结构化输出的问题,脑子里有一张清晰的地图,知道有哪些方案、每个方案保证了什么、没保证什么、什么时候该用哪个。
先看一个场景
想象你在一家做智能客服的公司,产品上线一周了,老板让你加一个新功能:用户发来一条退货请求,模型自动从里面提取关键信息,也就是商品名称、订单号、退货原因,然后输出一个JSON,传给后台系统生成退货工单。
你觉得这不难。模型理解能力挺强的,提取几个字段嘛,写个好点的prompt就行了。你花了半小时调好prompt,模型的回答看起来很完美:
商品名称:蓝色运动外套订单号:20250415123退货原因:尺码偏大你把这个结果拿给后端同事看,他问你一个问题:"这个输出我怎么解析?"
当然,真要硬来,也可以按冒号和换行写规则去拆。但这种规则很脆:字段顺序一变、模型多说一句话、用户原因里自己带了换行,解析就可能出错。工程里更稳的做法,是让模型输出一种大家都认的固定格式,比如JSON。它长这样:
{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏大"}程序拿到这个JSON之后,能精确地知道 product 对应什么、order_id 对应什么,然后把它们分别填进数据库的不同字段里。整个过程是自动的,中间没有人。
但如果模型的输出不是这个格式,哪怕只是少了一个引号、多了一个逗号、或者在JSON前面多说了一句废话,后端的Python代码在做 json.loads() 的时候就会直接报错。报了错,退货工单就生成不了。用户等半天没回音,投诉就来了。
好,你意识到了问题的严肃性。那就改prompt,明确要求模型输出JSON格式。这是所有人的第一反应,也确实是实战中的起点。
在prompt里说清楚
你在prompt里写得很详细:告诉模型"你只能输出一个JSON对象,不要输出任何其他文字",列出每个字段的名称和类型,还给了一个完整的JSON示例。一个典型的prompt可能长这样:
你是一个信息提取助手。用户会发来一段退货请求,你需要从中提取关键信息,以JSON格式输出。输出格式要求:- 只输出一个JSON对象,不要输出任何其他文字- JSON必须包含以下字段: product: 商品名称(字符串) order_id: 订单号(字符串) reason: 退货原因(字符串)输出示例:{"product": "黑色羽绒服", "order_id": "20250101456", "reason": "拉链损坏"}你拿这个prompt跑了几条测试数据,模型表现得很乖,每次都老老实实地输出一个漂亮的JSON。你觉得问题解决了。
然后你自信满满地跑了500条真实的用户退货消息。翻车了。
翻车的六种姿势
打开日志一条一条看,发现翻车的姿势五花八门。
翻车一:模型忍不住说废话
这是出现频率最高的一种。你明明说了"不要输出任何其他文字",但模型有时候就是忍不住:
好的,以下是提取结果:{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏大"}或者在JSON后面加一句:
{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏大"}希望对你有帮助!如果还有其他问题请随时告诉我。不管是前面多了一句话还是后面多了一句话,你的Python代码拿整段文本去做 json.loads(),都会直接报错。JSON解析器期望的输入是一个纯粹的JSON字符串,前面那句"好的,以下是提取结果:"在它眼里是非法字符。
为什么模型会这样?因为它在指令微调阶段被大量教导"要礼貌、要有帮助、要解释自己在做什么"。这些行为在对话场景里是优点,但在结构化输出场景里就成了捣乱:模型的礼貌本能和你的"只输出JSON"指令在互相拉扯,偶尔礼貌会赢。
还有一种更隐蔽的废话:模型用Markdown的代码栅栏把JSON包了起来:
```json{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏大"}```肉眼看上去挺规整的,但那三个反引号加上 json 这个标记,对JSON解析器来说都是非法字符。如果你没有针对这种情况做预处理,一样会报错。那简单啊,解析前先把代码栅栏剥掉不就行了?确实,很多项目最后都会写这类预处理。但这种翻车真正阴险的地方不在这里:模型版本更新之后可能突然开始偏好用代码栅栏包裹输出,你在旧版本上测的好好的prompt,换了新版本突然一大片报错,你去查日志才发现罪魁祸首是三个反引号。
锁定模型版本,否则你的线上系统会被"静默升级"搞崩
你用某家API跑通了结构化输出,上了线,稳定运行了一个月。某天早上你打开监控,发现格式报错率突然从0.5%飙到了8%。你的代码没改过,prompt没动过,数据也没变。查了两个小时才发现:API提供商在后台更新了模型版本,新版本的输出风格变了,比如开始偏好用Markdown代码栅栏包裹JSON。在调用API时,永远指定具体的模型版本号(比如用 gpt-4o-2024-08-06 而不是 gpt-4o),不要用会自动升级的别名。模型更新是好事,但应该由你主动测试后再切换,而不是被动地被"惊喜"。
翻车二:字段名乱跑
你要求的字段叫 product,但模型不一定每次都用这个名字。有时候它会这样:
第一条输出:{"product": "蓝色运动外套", ...}
第二条输出:{"product_name": "红色连衣裙", ...}
第三条输出:{"商品名称": "黑色皮鞋", ...}
三种写法,每种单独看都说得通。但你的下游程序只认 product 这一个名字,代码里写的是 data["product"],模型输出 product_name 的时候,程序找不到 product 这个key,直接抛 KeyError。
这种问题在输入内容比较复杂的时候尤其容易出现。模型看到用户的原文里写了"商品名称"四个字,就好心地把字段名也改成了中文,完全没理会你在prompt里定义的英文字段名。
翻车三:值的类型漂移
你期望价格字段是一个数字 99.5,模型给你输出了一个字符串 "99.5元",还带单位。或者你期望一个布尔值 true,模型输出了 "是"。
期望的:{"product": "蓝色外套", "price": 99.5, "in_stock": true}实际的:{"product": "蓝色外套", "price": "99.5元", "in_stock": "是"}你的下游代码拿到 price 之后要做数值计算,"99.5元" 这个字符串参与加减乘除会直接报类型错误。如果某个字段只能从几个固定值里选,比如 positive、negative、neutral,解析之后还要检查它是不是这三个值之一,不在名单里的就算格式对了也不能放行。
翻车四:JSON语法错误
这一类翻车肉眼很难看出来。你盯着模型输出看了半天觉得没问题啊,但解析器就是报错。典型的:
末尾多了一个逗号:
{"product": "蓝色外套", "order_id": "20250415123", "reason": "尺码偏大",}最后一个字段后面那个逗号,在JavaScript里是合法的(叫trailing comma),但在JSON标准里是非法的。如果你写过JavaScript,你可能觉得这完全没问题,但JSON解析器不这么想。
用了单引号:
{'product': '蓝色外套', 'order_id': '20250415123'}Python的字典用单引号没问题,但JSON标准要求必须用双引号。模型在训练数据里见过大量Python代码,偶尔会把Python字典的写法带到JSON输出里来。
还有一种更折磨人的情况,是JSON里面套JSON。比如你在做数据生成,让模型造一条SFT训练样本,外层格式是 {"instruction": "...", "output": "..."},而 output 的值恰好又是一段JSON字符串。这个时候,内层JSON的双引号必须转义成 \",否则外层解析器会在内层双引号那里提前断句。模型很容易在这里翻车:有时漏转义,有时多转义,有时把 \" 写成 \\"。遇到这种需求,别硬让模型一次性写对所有转义。更稳的做法是分两步:先让模型输出内层内容,再由你的代码把它塞进外层JSON,并负责转义。转义这种机械活,交给代码比交给模型可靠得多。
翻车五:截断
这种特别坑,因为报错信息不直观。模型输出的内容太长,撞上了你设置的 max_tokens 上限,被从中间硬生生切断了:
{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏后面的引号、花括号全没了。你拿到的是一个残缺的JSON片段,根本无法解析。
翻车六:幻觉字段
你只要求三个字段,模型自作主张加了第四个:
{"product": "蓝色运动外套", "order_id": "20250415123", "reason": "尺码偏大", "confidence": 0.95}confidence 是哪来的?你没要求这个字段,模型自己觉得加一个置信度挺合理的,就给你加上了。
另一种失败方向也要单独记住:模型可能觉得某个字段在这条数据里"不适用",干脆跳过不输出。你的代码去取这个字段的时候,同样会遇到 KeyError;前一种是多了不该有的字段,后一种是缺了应该有的字段。
你可能会问:这些翻车是因为模型太笨吗?
不是。哪怕你用目前最强的模型,把prompt打磨到极致,只要跑的量够大,这些问题都会出现。原因在于模型生成文本的根本工作方式:它在生成每一个token的时候,你的prompt只是它参考的众多上下文信号之一。prompt说"只输出JSON",这个信号确实能把模型推向正确的方向,但它不能保证每一步、每一次都占据绝对主导。一旦某一步生成偏了,比如多输出了一个"好"字,后续的生成就会顺着这个偏差继续走。模型不会在生成过程中突然"醒过来"说"哎不对我刚才不该说那个字"。错误会被放大,而不是被纠正。
本质上,prompt约束是一种软约束:它提高了正确格式出现的概率,但无法提供确定性的保证。
那怎么办?再写得更长一点、更凶一点,prompt里强调三遍"只输出JSON"?你已经试过了,真的不行。更稳的方向,是尽量把格式约束前移到生成过程里:不是在模型生成完之后去检查、去修补,而是在它生成每一步的时候,就不让它走错路。
从源头堵死:受限解码
前面所有的方案都是同一个思路:让模型自由发挥,出了问题再去擦屁股。现在要讲的方案彻底换了一个方向:在模型生成的过程中,从每一步就限制它只能走合法的路。
回忆一下前面讲解码策略时说过的流程:模型在每一步,会为词表里的所有token打分(这些分数就是logits),然后经过Softmax变成概率分布,最后从这个概率分布中采样出一个token。
受限解码插手的位置,就在Softmax之前。这里一定要分清楚:模型只负责给所有候选token打分;判断哪些token合法的,是外面的解码器、API或推理框架。它手里拿着一套JSON语法规则,会根据已经生成的前缀判断当前处在什么状态:是在等key,等冒号,等value,还是正在字符串中间。状态一确定,下一步哪些token合法也就确定了。
所以,受限解码做的事情是:在Softmax之前,把那些一选就会破坏JSON语法的 token 的分数强制设成负无穷大。
负无穷经过Softmax之后变成0。那些不合法的token被彻底从候选名单上移除了,模型不可能选到它们。
假设模型已经生成了 {"age": 这几个token,现在要决定下一个token是什么。简化一下,假设词表里只有5个候选token:
注意一个关键细节:hello 的原始分数最高,是4.0。模型最"想"输出的就是它。但 {"age": hello 不是合法的JSON。JSON的值要么是数字,要么是用双引号包裹的字符串,要么是 true/false/null,裸单词 hello 不在合法选项里。} 不合法的原因不同:age 的值还没给,对象不能就这么结束。, 也一样,值还没给,不能跳到下一个字段。
如果不做任何干预,直接对这5个分数做Softmax:
e3.0≈20.1e^{3.0}\approx20.1e3.0≈20.1
e2.5≈12.2e^{2.5}\approx12.2e2.5≈12.2
e4.0≈54.6e^{4.0}\approx54.6e4.0≈54.6
e1.0≈2.7e^{1.0}\approx2.7e1.0≈2.7
e0.5≈1.6e^{0.5}\approx1.6e0.5≈1.6
总和约91.2。
算出的概率分布:2 占22%," 占13.4%,hello 占59.9%,} 占3%,, 占1.8%。
hello 有将近60%的概率被选中。一旦选了它,JSON就坏了。
加上受限解码之后 ,先把不合法的token的分数设为 −∞-\infty−∞:
修改后的分数:3.0, 2.5, −∞, −∞, −∞3.0,\\ 2.5,\\ -\\infty,\\ -\\infty,\\ -\\infty3.0, 2.5, −∞, −∞, −∞
e−∞=0e^{-\infty} = 0e−∞=0,所以Softmax的计算只剩两个有效的数字:e3.0+e2.5≈20.1+12.2=32.3e^{3.0} + e^{2.5} \approx 20.1 + 12.2 = 32.3e3.0+e2.5≈20.1+12.2=32.3。
新的概率分布:2 占62.2%," 占37.8%,其余三个都是0%。
模型现在只能在输出一个数字和开始一个字符串之间选择。不管选哪个,JSON的语法都不会被破坏。
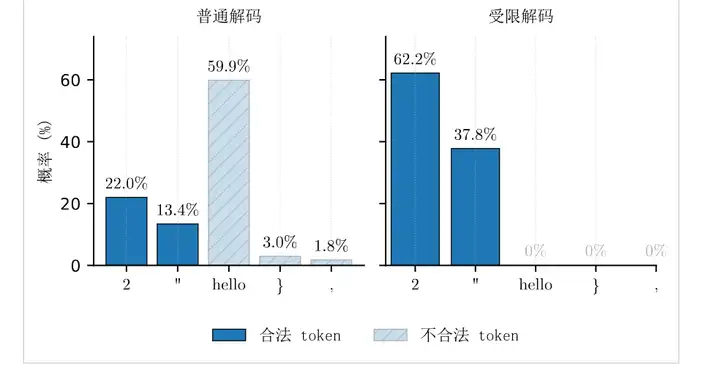
上图直观地展示了这个变化。左右两张图的对比,就是受限解码做的全部事情。
这就是受限解码做的全部事情:把不合法的选项从菜单上划掉。模型原本想输出什么没有变(原始logit不变),只是犯错的自由被拿走了。就像把一道填空题变成了选择题:填空题里你什么都能填,填错了就是语法错误;选择题里每个选项都是合法的,你随便选都不会出格。
在计算机科学里,这个负责记住当前语法状态的东西叫做"状态机"。JSON的语法规则是固定的,所以这个状态机可以提前写好,在模型生成每一步时查一下就行,额外的计算开销很小。
但有一个至关重要的点必须说清楚:受限解码只保证语法正确,不保证内容正确。
在刚才的例子里,模型被限制在 2 和 " 之间选了 ",然后继续生成了 "二十五岁"。最终输出是 {"age": "二十五岁"},语法完全合法,json.loads() 解析毫无问题。但如果你的下游系统期望 age 是一个整数25而不是字符串二十五岁,这个值就是错的。受限解码管得了括号有没有闭合,管不了模型填的内容对不对。
这个区分非常重要,后面还会专门讲。先继续往下走。
受限解码会不会降低生成质量
常见问法:"你说受限解码把不合法token的概率设为零,那这样不就干预了模型本来的概率分布吗?会不会导致模型输出的内容变差?"
典型错误:要么一口咬定"不会有任何影响",要么夸大影响说会严重降低质量。
正确思路:影响确实存在,但在结构化提取场景下通常可以忽略。关键要分两种情况。第一种,模型正在输出JSON的"骨架"部分(花括号、冒号、引号、字段名),这些位置合法的token本来就很少,受限解码基本不会改变模型的选择。第二种,模型正在输出字段的"值"部分(比如在 "name": " 后面填内容),这时候大部分词表token都是合法的(因为它们都可以作为字符串的一部分),受限解码几乎不做任何干预。真正可能出问题的是极端情况:Schema非常复杂,模型被迫生成一个它"不想"生成的嵌套结构,这时它在结构骨架上被迫选了低概率token,可能影响后续内容的连贯性。但对于典型的信息提取任务(字段不多、嵌套不深),这个影响微乎其微。
API帮你做好了
受限解码是底层原理。你可能在想:我需要自己写一个JSON状态机吗?
好消息是,如果你用的是主流API,不需要。API提供商已经把这件事封装好了,暴露成简单的参数让你一键开启。目前主流的封装分成两个层级,很多人容易搞混,这里要仔细区分。
第一个层级:JSON Mode
你在调用API的时候,加一个参数告诉它"我要JSON格式的输出"。API保证返回的一定是语法合法的JSON,不会多废话、不会少括号、不会有尾逗号。
但注意:它只保证"是合法的JSON",不保证"是你想要的那种JSON"。
什么意思?你的prompt要求提取商品名称、订单号和退货原因,你开了JSON Mode,模型返回了这个:
{"result": "用户想退一件蓝色运动外套,订单号20250415123,原因是尺码偏大"}这是合法的JSON吗?完全合法。一个对象,一个字段 result,值是一个字符串。json.loads() 解析毫无问题。
但这是你想要的结构吗?完全不是。你要的是 product、order_id、reason 三个独立字段,模型把所有信息糊成了一句话塞进了一个字段里。你的下游程序去取 data["product"] 的时候,KeyError,字段不存在。
很多人第一次用JSON Mode的时候就在这里栽跟头:"不是说保证JSON了吗?为什么我的程序还是报错?"程序报的是"找不到product这个字段",并不是JSON解析错误。JSON Mode保证了语法,没保证结构。
第二个层级:JSON Schema模式
这个层级比JSON Mode更进一步。你不仅告诉API"我要JSON",还传入一份完整的JSON Schema。
JSON Schema是什么?它本身也是一段JSON,只不过它描述的是"数据应该长什么样"的规则:哪些字段必须有、每个字段的名字叫什么、值是什么类型(字符串、数字、布尔值还是数组)、嵌套结构是什么样的。你可以把它理解成一份验收标准:模型的输出必须完全符合这份标准,否则API不会放行。
API拿到你传入的Schema之后,会在底层构建一个状态机,和前面讲的受限解码思路一致。在模型生成的每一步,它只让模型选那些既符合JSON语法、又符合你Schema定义的token。只要你在Schema里把必填字段、类型和额外字段规则写清楚,模型就不能少字段、不能乱加字段、不能搞错类型。
这才是真正意义上的想要什么格式就得到什么格式。
两个层级的区别用一句话概括:JSON Mode保证"这是一个合法的JSON",JSON Schema模式保证"这是一个符合你定义的那种合法JSON"。 前者管语法,后者管语法加结构。
不同API提供商对这两个层级的命名和参数写法各不相同,变化也快,查文档就能找到,不值得死记。重要的是理解这两个层级各自保证了什么、没保证什么,这个认知不会过时。
Function Calling:模型不只是输出JSON,还帮你决定该做什么
到目前为止,所有方案的目标都是一样的:让模型输出一个格式正确的JSON。但想一想:你要这个JSON干什么?在实际工程中,拿到JSON之后的用途一般是:查数据库、调用某个API、在后台系统里创建一条记录、发一封邮件。
function calling(也叫tool use,工具调用)把这个意图直接摆到了台面上。用退货客服的例子来走一遍。
先从你的代码开始。你在代码里定义一组"工具"。每个工具有三样东西:名字、描述、参数的JSON Schema。比如你定义了一个工具叫 create_return_order,描述是"创建退货工单",参数Schema要求有 product(字符串)、order_id(字符串)、reason(字符串)。
你可能还定义了另一个工具叫 query_order_status,描述是"查询订单状态",参数只需要一个 order_id。
你在调用API的时候,把这些工具定义和用户的消息一起发给模型。
这一步很关键:模型之所以知道有哪些工具可用,是因为你在这次请求里把工具清单也交给了它。
接着,用户说:"我三天前买的蓝色外套想退货,订单号20250415123,太大了。"模型看了用户的消息和你定义的工具列表,判断出"这个用户想退货,我应该调用 create_return_order 这个工具"。
然后,模型不会直接给用户写一段自然语言回复,而是输出一个结构化的工具调用请求。内容大致长这样:
{ "tool": "create_return_order", "arguments": { "product": "蓝色外套", "order_id": "20250415123", "reason": "尺码偏大" }}这里的 arguments 部分由工具的参数Schema严格约束。API在底层通常会使用前面讲的受限解码或类似机制来保证参数格式正确。
到这里,模型的任务就结束了一半。真正执行动作的是你的代码。你的程序解析出工具名 create_return_order 和参数,然后调用你写好的退货工单创建函数,把参数传进去。函数在后台系统里创建了一条退货记录,返回了结果:"退货工单已创建,工单号RT20250419001"。
有些场景还会多走一步:你把函数的执行结果再发回给模型。模型看到了"退货工单已创建"的结果,再基于这个结果生成一句自然语言回复给用户:"您的退货申请已提交,工单号是RT20250419001,预计3个工作日内处理。"
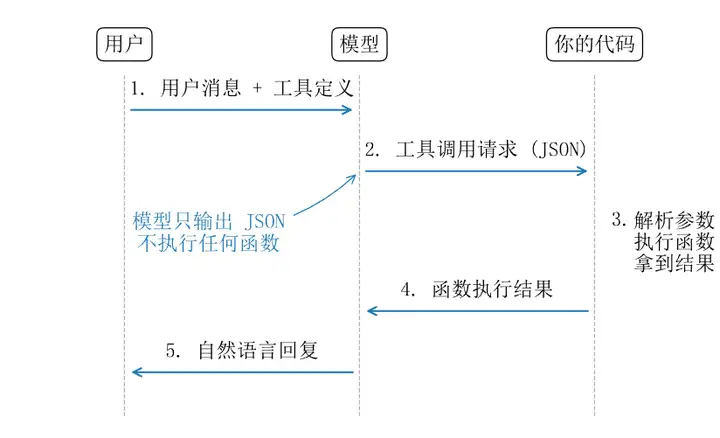
上图清晰地展示了这条边界:模型的箭头只到你的代码就停了,从不直接通向任何外部系统。模型本身没有调用任何函数。 function calling 这个名字容易让人误以为模型自己去执行了什么操作。实际上模型做的事情只有一件:输出一段JSON,表达"我认为应该调用这个函数,参数是这些"。真正的函数调用发生在你的代码里。模型负责决策,程序负责执行。这个区分在后面接触Agent开发的时候会变得非常重要。
从结构化输出的角度看,function calling其实就是两件事的组合:结构化输出 + 意图路由。 结构化输出保证了参数的格式正确(受限解码那一套),意图路由让模型判断应该调用哪个工具(从你定义的工具列表里选)。里面没有一个全新的解码原理。扒开皮看,你可以把它理解成:结构化输出那套格式约束,加上工具选择这一步。
function calling的价值不在于发明了什么新技术,而在于它把模型输出结构化数据和数据驱动下游操作天然地绑在了一起。你不需要先让模型输出JSON,再自己写代码解析JSON,再根据解析结果决定调哪个函数,function calling把中间的胶水层省掉了。如果你的场景是模型做决策、程序做执行,function calling几乎就是首选方案。
不过,function calling还有一个细节很容易被新人漏掉:模型不一定每次都会调用工具。如果用户问的是"今天天气怎么样",而你定义的工具只有退货和查单,模型可能判断没有合适的工具可用,直接返回普通文本。这意味着你的代码不能默认返回结果里一定有 tool_calls,而是要同时处理两种情况:一种是工具调用请求,另一种是普通文本回复。很多线上小事故就出在这里:代码直接去取 tool_calls,没做空值判断,一遇到普通回复就报 NoneType 错误。
有些API还允许你强制模型必须调用某个工具,这个功能要谨慎用。强制调用意味着即使用户的问题和工具无关,模型也会硬凑一个调用出来,参数很可能是瞎编的。除非业务上真的要求"每次请求都必须落到某个工具",否则一般让模型自己判断更稳。
最后一道安全网:解析、校验、重试
到这里,你已经看到了几种更硬的方案:受限解码、JSON Mode、JSON Schema、function calling。它们能把格式成功率拉得很高,但线上系统里仍然要留一层安全网。原因很简单:输出可能被截断,API可能返回空内容,模型可能拒答,网络可能超时,字段的值也可能不符合业务约束。
这层安全网不用写得很玄,核心就是四步:先解析,再校验,失败就重试,最后记录日志。解析负责判断这段文本能不能作为合法JSON读取;校验负责判断字段齐不齐、类型对不对、枚举值有没有越界;重试负责把具体错误告诉模型,让它重新输出;日志负责把救不回来的样本留下来,别让一条坏数据拖垮整个批次。
以前那种"找第一个左花括号和最后一个右花括号"的方法,只适合低成本原型。它能救一点模型多说废话的情况,但遇到多个JSON对象、字符串里有花括号、输出被截断,就很容易误切。真正上线时,更可靠的做法是优先用API提供的JSON Schema或function calling;不支持这些能力时,再把"提取、解析、校验、重试"作为兜底流程。
校验最好交给代码来做。Python里可以用Pydantic这类工具定义字段和类型:缺字段、类型错、枚举值不在范围里,直接报出具体位置。转义、尾逗号、字段类型这些机械活,也尽量交给代码,不要让模型硬背规则。
重试也要有边界。一次失败后,把错误信息带回去让模型重来,通常很有效;连续两三次仍然失败,就不要继续烧钱了。记录原始输入、模型输出、报错信息和使用的prompt版本,后面才能分析到底是输入太脏、Schema太复杂、模型太弱,还是你的格式要求写得不清楚。
拿到一个"要JSON"的需求,先问三个问题
你在工位上会反复遇到一类需求,表现形式各不相同。有时候是"帮我从这批文本里提取关键字段",有时候是"模型的回答要能被下游系统解析",有时候是"我要用模型批量生成训练数据",但本质上都是同一件事:让模型的输出变成程序可以直接消费的结构化数据。
前面把prompt约束、受限解码、JSON Mode、JSON Schema和function calling都拆开讲了一遍。真正坐到工位上接需求的时候,你不需要把这些方案重新背一遍。每次拿到这种需求,先问三个问题,答案会把你直接导向最合适的方案。
第一个问题:你用的是什么模型,怎么部署的?
如果你用的是主流闭源API(比如通过API调用大模型),先去翻一下文档,看它支持到哪一层:JSON Mode、JSON Schema模式,还是function calling。只支持JSON Mode,至少能保证输出是合法JSON;支持JSON Schema模式,结构就能被卡住;支持function calling,模型还能顺手帮你做工具选择。先把平台能给你的硬约束摸清楚,再往下判断需求。
如果你用的是本地部署的开源模型,看一下你的推理框架(比如 vLLM)有没有guided decoding(也就是前面讲的受限解码)功能。有的话,效果和闭源API的JSON Schema模式基本等价。没有的话,你的起点只能是"prompt约束 + 后处理"。别灰心,很多线上项目就是这么跑的。
第二个问题:你的输出结构是固定的,还是动态变化的?
如果每条数据的输出结构都一样,也就是同样的字段名、同样的类型、同样的嵌套,这是最适合JSON Schema模式的场景。定义一次Schema,所有数据复用。
如果你的API只支持JSON Mode,没有JSON Schema模式,也不是不能用。它至少能帮你挡掉尾逗号、少括号、多废话这些语法问题。只是字段缺失、字段名漂移、类型不对这些结构问题,仍然要靠后处理校验来兜底。
如果输出结构会根据输入变化,比如不同类型的商品需要提取不同的字段,你就需要在代码里维护多套Schema定义和对应的解析逻辑,工程复杂度会上升。这种情况下,prompt约束 + 后处理反而更灵活。你可以在prompt里根据输入类型动态拼接不同的格式要求和示例。
第三个问题:你的需求是"得到一个JSON",还是"让模型驱动下游操作"?
如果你只是需要把模型的输出解析成结构化数据存起来、做分析、或者喂给另一个模型,优先考虑JSON Schema模式。如果平台只支持JSON Mode,就用JSON Mode配后处理校验;再退一步,才是prompt约束 + 后处理。
如果你需要模型根据用户的请求,判断应该执行什么操作、传什么参数,比如用户说"帮我查一下订单状态",模型要判断"应该调用查询订单的函数,参数是订单号",这是function calling的典型场景。它比单纯的结构化输出多了一层"意图路由"的能力。
三个问题回答完,你的方案基本就定了。但不管选了哪个方案,有一件事永远要做:在后处理中加一层校验。 哪怕你用了JSON Schema模式、理论上格式不可能出错,也在代码里加一个 try-except 包住 json.loads(),加一个Pydantic模型做字段校验。这么做的理由很朴素:线上系统需要对所有异常情况都有兜底,网络超时、API返回格式变化、模型版本静默更新,这些事随时可能发生。防御性编程的成本极低,但它能在关键时刻救你一命。
还有一条贯穿所有方案的原则:先试成本最低的,不行再升级。 如果你的场景是每天跑几十条、容忍偶尔出错,prompt约束就够了。如果prompt约束的成功率不够、或者你的量级上来了,先看平台有没有JSON Mode;JSON Mode够用就先用它,再配后处理校验。还不够,或者你需要确定性的字段结构,再升到JSON Schema模式。需要让模型决定调用哪个工具,再用function calling。不要一上来就用最重的方案。工程中的好决策,关键是用刚好够用的工具。
实战中几个隐蔽的坑
最后聊几个教科书里很少写、但实际项目里很容易碰到的坑。
- 结构化输出本身也会吃token。
字段名、冒号、逗号、双引号、示例里的完整JSON骨架,都会被算进输入或输出成本里。字段很多、调用量很大时,字段名尽量简短,极少出现的字段可以考虑设为可选,不要让模型每次都输出一堆 null。
- 温度参数和结构化输出的关系。
前面讲解码策略的时候说过,温度越高,模型输出越随机、越有创造力。但在结构化输出的场景里,创造力恰恰是你不想要的。你希望模型老老实实地按格式输出,不要搞创新。所以做结构化提取的时候,通常把temperature设得很低,接近0。如果你用了受限解码或JSON Schema模式,温度的影响会小很多(因为不合法的token已经被屏蔽了),但如果你只靠prompt约束,温度拧高是在给自己找麻烦。
- Schema太复杂,模型会分心。
当你的JSON结构有三四层嵌套、十几个字段、每个字段还有各种条件约束的时候,你会发现一个奇怪的现象:格式倒是对了,但字段里填的内容质量明显下降。模型并没有变笨,它只是把太多注意力分给了"搞清楚该输出什么结构",留给认真理解输入内容的注意力就少了。实战中的应对策略是:把一个复杂的提取任务拆成多次调用,每次只提取一部分信息,每次的Schema保持简单。
- 截断是最常被忽视的隐患。
前面在翻车案例里提过,这里再强调一次防御方式:根据你的Schema估算最长可能的输出长度,给 max_tokens 留出足够余量。在后处理中加一个简单的检查:如果输出的最后一个非空字符不是 } 或 ],大概率是被截断了,直接走重试,不要浪费时间去修复一个残缺的JSON。
- 小模型的格式遵从能力弱得多。
如果你只用过大的闭源模型,可能对这个问题完全没有感知。但当你尝试在7B甚至更小的开源模型上用prompt约束来获取JSON输出时,你会发现成功率断崖式下降。同样的prompt,在大模型上90%的成功率,在小模型上可能只有50%。这通常不是prompt写得差,问题更多出在小模型对指令的遵从能力本身就弱。它的参数量不够支撑它同时理解输入内容和遵守格式约束。在本地部署小模型的场景里,受限解码经常是上线门槛。
- 流式输出和结构化输出有冲突。
很多API默认是流式返回的。模型生成一个token就发一个token回来,让用户看到"正在打字"的效果。但流式返回意味着你在收到完整输出之前没法做JSON解析。如果你的场景需要结构化输出,要么关掉流式、等模型全部生成完再一次性拿到结果去解析;要么在流式接收的过程中先把token拼起来,前端可以展示"正在生成"的状态,让用户知道系统没卡住,但JSON解析要等全部收完之后再做。这不是什么大坑,但第一次碰到的时候容易困惑。
- 字段名用中文还是英文。
一句话的建议:字段名永远用英文,值里面该中文就中文。字段名是给程序读的,英文不会有编码问题,也和绝大多数编程语言的命名习惯一致。值是给业务用的,中文数据就用中文,不需要翻译。
把两个问题分清楚
这一节讲了很多方案和技巧,但在结束之前,有一个贯穿始终的认知值得单独拎出来强调,它能帮你在面对结构化输出问题时少走弯路:
格式正确和内容正确是两个完全独立的问题。
受限解码、JSON Schema、function calling,这些方案解决的全部是格式问题。它们保证输出的JSON语法合法、结构符合预期。但JSON里填的内容对不对,提取的名称是不是原文里的、数字是不是准确的、分类是不是正确的,这些,它们一概管不了。
打个比方:这些方案保证的是信封的形状和尺寸完全符合邮局的规格要求。但信封里装的那封信写了什么、写得对不对,和信封的形状没有半点关系。
内容质量取决于模型本身的能力、prompt的质量、以及输入数据的清晰程度。这些是前面prompt engineering讲的东西,以及后面微调相关章节要解决的问题。
把这两件事分清楚,你在排查问题的时候就不会走弯路。下游系统报错了,先判断是格式问题还是内容问题。格式问题用这一节讲的方案解决。内容问题回去优化prompt、改进数据、或者换一个更强的模型。两类问题的解法完全不同,混在一起只会越修越乱。
Q&A
文章在「受限解码原理」和「API 帮你做好了」之间确实跳了一大步。我把中间这层补全,分三部分讲:先看生成循环到底长什么样,然后看你自己拿 qwen3-1.7b 怎么做,最后看 OpenAI 在它的服务器里做了什么。你会发现这两件事本质上是同一件事,只是一个在你的机器上、一个在它的机器上。
第一部分:先把「生成」这个循环拆开
文章里说受限解码插手在 Softmax 之前。但要理解 API 怎么做,得先看清楚「生成一段话」其实是一个循环,不是一次性的:
html
prompt = '{"age":'
循环开始:
第 1 步: 模型吃进 prompt → 输出整个词表的 logits → 选一个 token(比如 2)→ 拼到后面
第 2 步: 模型吃进 '{"age":2' → 输出 logits → 选一个 token(比如 5)→ 拼到后面
第 3 步: 模型吃进 '{"age":25' → 输出 logits → 选一个 token(比如 })→ ...
...
直到选出「结束符」(EOS)→ 循环结束每一步,模型干的事完全一样:给当前已有的文本,吐出下一个 token 的 logits。模型本身没有「记忆」这个状态机,它每一步只是纯打分。
所以「受限解码」要插手,插手的就是这个循环的每一圈 :在「拿到 logits」和「采样」之间,加一道工序,把非法 token 的 logit 改成 -inf。
关键点:谁来跑这个循环,谁就能插手。 这就是你自己跑小模型 和 用 OpenAI 的唯一区别------循环在谁手里。
第二部分:你用 qwen3-1.7b 自己做,完整步骤
你本地跑 qwen3-1.7b(比如用 HuggingFace transformers),这个循环在你手里,所以你能亲手插手。下面是从零到能用的完整链条。
步骤 0:理解一个钩子------LogitsProcessor
HuggingFace 的 model.generate() 内部就是上面那个循环。它留了一个官方钩子叫 LogitsProcessor。它的约定是:
每生成一步,框架会在采样之前 调用你的函数,把「目前已生成的 token 序列」和「这一步的 logits」交给你,你返回修改后的 logits 。
签名长这样:
html
class MyProcessor(LogitsProcessor):
def __call__(self, input_ids, scores):
# input_ids: 目前已经生成的所有 token (就是上面的前缀)
# scores: 这一步整个词表的 logits, 形状 [vocab_size]
# 返回: 改过的 scores
...
return scores你要做的,就是在这里把非法 token 的 scores 设成 -inf。文章里那个「把 hello 设成 -∞」的操作,落到代码就是这一行。问题只剩一个:怎么知道哪些 token 非法? 这就是下面三步要解决的。
步骤 1:把 JSON Schema 编译成一个「状态机」
你不能手写「等 key、等冒号、等 value」这套逻辑(能写,但很痛苦)。标准做法是把你的 Schema 转成一个正则/语法 ,再编译成有限状态自动机(FSM)。
举个最小例子,Schema 要求 {"age": <整数>},它能被等价表达成一个正则:
html
\{"age":[0-9]+\}把它编译成状态机,就是一串「状态」加「箭头」。箭头上写的是「读到什么字符」:
html
状态0 --读到 {--> 状态1 --读到 "--> 状态2 --读到 a--> ... --读到 :--> 状态C
状态C --读到 0~9 任一数字--> 状态D
状态D --读到 0~9 任一数字--> 状态D (停在原地,数字可以一直接)
状态D --读到 }--> 状态E(结束,合法)我们就盯着 状态 C 看(刚生成完 {"age":,正等着第一个数字)。从状态 C 出发,状态机只认两种情况:
- 读到一个数字(0~9)→ 走到状态 D
- 读到别的任何字符 → 没有这条箭头,死路
这张「在某状态读某字符,跳到哪 / 还是死路」的表,就是状态机的全部。它是固定的,Schema 一确定就编译好了。
步骤 2:解决最关键的难点------「字符」和「token」对不上
关键认知:状态机的箭头是按「字符」画的,但模型吐的是「token」,一个 token 常常是好几个字符。 所以判断一个 token 合不合法,做法是:把这个 token 拆成字符,一个一个喂进状态机,从当前状态开始走,看会不会撞到死路。
我们现在在 状态 C,挨个验证词表里的 token:
**token **"25"(两个字符 2、5):
html
从状态C出发
读 '2' → 状态C有「读数字」这条箭头 → 走到状态D ✅ 没死
读 '5' → 状态D有「读数字」这条箭头 → 留在状态D ✅ 没死
走完了,没撞死路 → "25" 合法**token **"hello"(字符 h、e...):
html
从状态C出发
读 'h' → 状态C只有「读数字」的箭头,没有「读h」的箭头 → 死路 ❌
还没走完就撞死了 → "hello" 非法**token **"}"(一个字符 }):
html
从状态C出发
读 '}' → 状态C没有「读 }」的箭头(必须先有数字) → 死路 ❌
→ "}" 在状态C非法(注意:} 在状态 D 就是合法的,因为状态 D 有「读 } → 状态E」这条箭头。同一个 token,在不同状态下合不合法是不一样的------这点请记住,问题二就靠它。)
token " "(空格加引号):
html
从状态C出发
读 ' '(空格)→ 状态C没有这条箭头 → 死路 ❌
→ 非法这就是「逐字符走状态机」的全部,你描述得没错。
官方开源代码在哪: 这套「把 token 拆成字符、从某状态逐字符走 FSM、撞死路就判非法」的算法,对应的就是 Outlines 库(论文 Efficient Guided Generation for LLMs , arXiv:2307.09702 的参考实现)里的函数,函数名叫 walk_fsm** / **find_sub_sequences。现在性能核心抽到了 Rust 库 outlines-core(GitHub: dottxt-ai/outlines-core)。同类还有 XGrammar (mlc-ai/xgrammar,vLLM 默认用它)、lm-format-enforcer。
现在问题来了:词表有 15 万个 token。如果每生成一步,都把这 15 万个 token 全部拿出来「逐字符走一遍状态机」,那太慢了------每走一步就 15 万次模拟。
预计算的思路:这 15 万个 token 在每个状态下合不合法,是 Schema 一定下来就固定的、跟模型当时想说什么无关。那我何必每步现算?生成开始前,我把它一次性全算完、存成一张表。
这张表长什么样?key 是「状态」,value 是「这个状态下所有合法的 token」。 沿用我们的例子,预计算产出的表是这样的:
html
表 = {
状态C : { "2","5","25","100","7",... 所有数字开头且全程是数字的token }, ← } 不在里面
状态D : { "2","5","25",... 所有数字token, 还有 "}" }, ← } 在里面!
状态1 : { "\"" }, ← 这个状态只等一个引号
... 每个状态都预先算好一行
}注意对比 状态C 和 状态D 那两行:"}" 只出现在状态D 的集合里,不在状态C 里。这正是问题一最后那个细节------同一个 token 在不同状态合法性不同,所以必须对每个状态各算一份。
怎么算出这张表: 就是把问题一的「逐字符走状态机」这件事,对每个状态 × 每个 token 全跑一遍,把走得通的 token 登记进对应状态那一行。这个活儿干一次,在生成开始前。
算好之后,运行时变成什么样
没有这张表时,每生成一步:
html
出 logits → 现场把 15 万个 token 逐字符走状态机 → 找出合法的 → 设 -inf ❌ 慢有了这张表时,每生成一步:
html
出 logits → 查表:我现在在状态C → 表[状态C] 直接给我合法token集合 → 不在集合里的设 -inf ✅ 一次查表搞定「逐字符模拟」这件昂贵的事,被从「运行时每步都做」挪到了「开机前做一次」。运行时只剩查字典,这就是为什么开销小。
而运行时怎么知道「我现在在哪个状态」?靠状态机的箭头更新:每采样一个 token,就顺着箭头走一步。比如在状态C 采到了 "25",就沿 2→D、5→D 走到状态D,下一步就去查 表[状态D](这时候 } 就合法了,模型可以结束了)。
步骤 3:把状态机塞进 LogitsProcessor,跑起来
把前两步合起来,LogitsProcessor 的逻辑就完整了:
html
class JSONConstraint(LogitsProcessor):
def __init__(self, fsm, tokenizer):
self.fsm = fsm # 步骤1编译好的状态机
self.state = fsm.start # 当前状态
def __call__(self, input_ids, scores):
# 1. 根据「上一步实际选了哪个 token」更新当前状态
last_token = input_ids[0, -1]
self.state = self.fsm.advance(self.state, last_token)
# 2. 查预计算的表, 拿到当前状态允许的 token 集合
allowed = self.fsm.allowed_tokens(self.state)
# 3. 把不允许的 token 全设成 -inf
mask = torch.full_like(scores, float("-inf"))
mask[0, allowed] = 0
return scores + mask # 合法的 +0 不变, 非法的 +(-inf) → -inf返回的 scores 再走 Softmax、采样,模型就只能在合法 token 里选。这就是文章那张「左图变右图」的图,落到代码里的样子。
步骤 4:别自己写,用现成的库
上面三步全有成熟库封装,你只管喂 Schema:
- Outlines ------ 最主流,直接
outlines.generate.json(model, schema),底层就是上面整套(它的招牌是把 Schema 转成正则再建 FSM,预计算 token 索引)。 - lm-format-enforcer ------ 同类,支持 JSON Schema 和正则。
- XGrammar ------ 新一些,主打把 mask 计算做得极快(压缩位掩码 + 并行),vLLM 现在默认用它。
- llama.cpp 的 GBNF grammar ------ 如果你用 llama.cpp 跑 qwen,直接写一段 grammar 文件喂进去。
- 如果你用 vLLM 部署 qwen3-1.7b,根本不用碰 LogitsProcessor,直接传
guided_json=your_schema参数,vLLM 内部就是上面这套(后端可选 outlines/xgrammar)。
所以对 qwen3-1.7b,你的真实工作量是:
html
from vllm import LLM, SamplingParams
llm = LLM("Qwen/Qwen3-1.7B")
out = llm.generate(prompt, SamplingParams(guided_decoding=GuidedDecodingParams(json=my_schema)))
# 完事, 输出保证符合 my_schema注意一个重要现实 :小模型(1.7B)在结构化任务上,受限解码的价值反而比大模型更大。因为小模型「自由发挥」时更容易吐错格式、漏字段;加上受限解码后,格式 100% 正确 这件事和模型大小无关------状态机锁死了语法。但文章那句也要记住:它只保证格式对,不保证内容对 。1.7B 模型可能乖乖填了 {"age": ...},但把年龄填错。这点小模型比大模型更明显。
第三部分:OpenAI 在它的服务器里做了什么
理解了上面,OpenAI 就没什么神秘了------它做的是一模一样的事,只是循环在它的机器上跑。你看不到 LogitsProcessor,是因为整个推理栈是它的,它把这道工序焊死在了自己的采样代码里。
具体到它的 Structured Outputs 功能(strict: true),步骤是:
1. 你传 Schema 过去
html
response_format={
"type": "json_schema",
"json_schema": {
"name": "extract",
"strict": True, # 关键, 开启受限解码
"schema": { ... 你的字段定义 ... }
}
}strict: true 是开关。不加它就只是「JSON Mode」(只保证是合法 JSON,不保证符合你的 Schema------就是文章里那个把所有信息糊进一个 result 字段的翻车例子)。加了 strict: true 才进入「JSON Schema 模式」,才真正受限。
2. 它把你的 Schema 编译成语法,并缓存
OpenAI 官方说过:它把 Schema 转成一个上下文无关文法(CFG),再编译成约束推理用的 artifact(本质和你本地的 FSM/预计算表是一类东西,CFG 比纯正则能表达更复杂的嵌套结构)。
这里有个你能直接观测到的现象 ,正好印证它在做预计算:第一次用某个新 Schema 请求时,会有额外延迟 (官方文档明说了,通常几秒,可能到十几秒,复杂 Schema 更久)。这段时间就是它在编译语法、算 token mask。算完它会缓存 这个 artifact,之后用同一个 Schema 的请求就快了------这跟你本地「步骤 2 预计算那张表」是同一个道理,只是它帮你缓存复用。
3. 生成时,在它的采样器里逐 token mask
模型在它的 GPU 上跑那个生成循环,每一步出 logits 后,它的采样代码查编译好的语法 + mask,把非法 token 压成 -inf,再采样。和你本地 LogitsProcessor 干的事逐字对应。
4. 它对 Schema 加了限制,正是因为这套机制
你会发现 OpenAI 的 Structured Outputs 不支持完整的 JSON Schema ,只支持一个子集:必须 additionalProperties: false、所有字段必须 required、不支持某些 minLength/正则约束、嵌套深度有上限等等。
为什么?正是因为底层是「Schema → 语法 → 状态机」这条路。有些 JSON Schema 特性(比如复杂的数值范围、某些条件依赖)很难甚至无法编译成一个高效的有限状态机/CFG。所以它把不好编译的特性禁掉了。你理解了底层机制,就能预测「为什么这个 Schema 特性它不支持」------不是它偷懒,是状态机表达不了。
Function calling 同理
文章后面讲的 function calling,它的 arguments 那段 JSON,在 OpenAI 这边也是用同一套受限解码保证格式(工具定义里 strict: true 时)。所以文章说「function calling = 结构化输出 + 意图路由」是对的,这里的「结构化输出」用的就是上面这套。
例子
好,沿用我们一直在用的两个例子:简单的 {"age": 整数},和退货客服的 product / order_id / reason。我直接给你能跑的 schema,然后逐行讲为什么要这么写。
先看最小例子:只要一个整数年龄
你想要的效果是:返回 {"age": 25},age 必须是整数,不能多字段、不能少字段、不能变成字符串 "二十五岁"。
html
response_format={
"type": "json_schema",
"json_schema": {
"name": "extract_age",
"strict": True,
"schema": {
"type": "object",
"properties": {
"age": {"type": "integer"}
},
"required": ["age"],
"additionalProperties": False
}
}
}这里面真正干活的是 schema 那一块,它就是我们之前讲的「Schema → 状态机」里被编译的那个东西。逐行对应到机制:
"type": "object"------ 告诉状态机:最外层一定以{开头、}结尾。"properties": {"age": {"type": "integer"}}------ 定义了 key 叫age,而且它的 value 类型是integer。integer** 这个词直接决定了状态机:在"age":后面,只允许数字 token,引号"、字母全被 mask 掉。** 这就是为什么模型不可能填出"二十五岁"------状态机里根本没有「读引号」那条边。"required": ["age"]------ age 必须出现,不能漏。"additionalProperties": False------ 不准模型自己加别的字段。
退货例子:三个字段都要
html
"schema": {
"type": "object",
"properties": {
"product": {"type": "string"},
"order_id": {"type": "string"},
"reason": {"type": "string"}
},
"required": ["product", "order_id", "reason"],
"additionalProperties": False
}这就根治了文章里那个翻车例子(模型把所有信息糊进一个 result 字段)。因为现在状态机被锁死成:必须先吐 {"product": ,然后 "order_id": ,然后 "reason":,一个都不能少、不能改名、不能多加。 模型没有自由把它们合并成一句话。
三个「不写就达不到效果」的关键点
这是新手最容易栽的地方,直接决定你能不能拿到「想要什么格式就得到什么格式」:
1. strict: True 必须加。 不加它,就只是 JSON Mode------只保证「是合法 JSON」,不保证「符合你的 schema」。加了它才真正进入受限解码,状态机才会按你的字段去 mask。
2. OpenAI 的 strict 模式下, required** 必须列出所有字段,additionalProperties 必须是 False。** 这不是可选项。如果你想表达「某字段可有可无」,OpenAI 不让你靠「不放进 required」来实现,你得把它的类型写成联合类型、允许为 null:
html
"properties": {
"product": {"type": "string"},
"order_id": {"type": "string"},
"reason": {"type": ["string", "null"]} # reason 允许没有 → 用 null 表达
},
"required": ["product", "order_id", "reason"] # 但它仍然必须出现在 required 里模型若判断没有退货原因,就会填 "reason": null,而不是省掉这个字段。这正是上一部分讲的「机制决定限制」的体现------状态机要预先知道每个位置可能出现什么,「字段时有时无」对它来说不好编译,所以 OpenAI 强制你用 null 这种「位置固定、值可空」的方式表达可选。
3. 想约束「枚举值」也写进 schema,而不是靠 prompt 求模型。 比如退货原因只允许几种:
html
"reason": {
"type": "string",
"enum": ["尺码不合", "质量问题", "不想要了", "其他"]
}写了 enum,状态机会把候选 token 锁死在这 4 个字符串上,模型连第一个字都只能从这 4 个的开头里选,根本吐不出第五种。这比在 prompt 里写「请从以下四类中选择」可靠得多------prompt 是请求,enum 是物理上做不到别的。
嵌套也一样,层层都要写全
如果要一个订单里带多个商品:
html
"schema": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"price": {"type": "number"}
},
"required": ["name", "price"],
"additionalProperties": False
}
}
},
"required": ["order_id", "items"],
"additionalProperties": False
}注意:**每一层 object 都得自己写 required + **additionalProperties: False,内层不会自动继承外层的。漏写内层的,内层就退化成不受约束。
qwen3-1.7b 也能像 OpenAI 那样,传一个参数就开启受限解码。
先纠正一个根本认知:受限解码是「推理引擎」的功能,不是模型的功能
qwen3-1.7b 本身不是一个 API,它只是一堆模型权重文件 (几个 .safetensors)。它自己不会解码、不懂什么 JSON Mode、也没有 response_format 这个概念。它必须被某个推理引擎装起来跑。
所以「受限解码」这个能力,从来不属于模型,而属于你用什么引擎去跑这个模型 。OpenAI 之所以方便,不是因为它的模型特殊,而是因为它把「模型 + 推理引擎 + API」整套打包好了。你跑 qwen,只要也给它配一个带受限解码的引擎,体验可以和 OpenAI 一模一样。
所以真正的区别不是「自己写 vs 不写」,而是:
OpenAI 的引擎是它替你跑的;qwen 的引擎是你(或别人)替自己跑的。机制完全一样,连 API 长相都能做到一样。
qwen 有几条路,从「最像 OpenAI」到「最底层」
路线一:用 vLLM / SGLang 起一个服务(最推荐,和 OpenAI 体验几乎零差别)
这些引擎起来后,直接给你一个 OpenAI 兼容的接口 。你甚至可以用 OpenAI 的官方 SDK,只改一个 base_url 指向你自己的服务器,然后传的 response_format 跟 OpenAI 那部分讲的一字不差:
html
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="不校验")
resp = client.chat.completions.create(
model="Qwen/Qwen3-1.7B",
messages=[...],
response_format={ # ← 跟 OpenAI 那段完全一样
"type": "json_schema",
"json_schema": {
"name": "extract_age",
"schema": {
"type": "object",
"properties": {"age": {"type": "integer"}},
"required": ["age"],
"additionalProperties": False
}
}
}
)vLLM 内部就用 Outlines / XGrammar 帮你把 schema 编译成状态机、预计算那张表(就是前两部分讲的全套)。你一行 LogitsProcessor 都不用碰。
路线二:Ollama(本地最省事)
ollama run qwen3:1.7b 之后,它也支持传 schema:
html
ollama.chat(model="qwen3:1.7b", messages=[...],
format=my_schema) # 传 JSON Schema,效果同上路线三:llama.cpp
如果你用 llama.cpp 跑 gguf 量化版的 qwen,它有 json_schema / grammar 参数,一样传进去就行。
路线四:裸 HuggingFace transformers + 自己写 LogitsProcessor(几乎没人这么干)
这才是「自己写」的那条路。它存在,但只在两种情况下用:① 你在做教学 demo,想亲眼看到 -inf 被设上去的那一刻;② 你的约束特别诡异,现成库表达不了。正常做业务绝不会走这条路。