前言
最近我又肝了一个新项目:CodeGuardian AI 智能代码审查系统。
这是一个真正把 AI Agent 架构落地到代码审查场景的项目。
不是调个 ChatGPT API 就完事的"套壳"。
它能自己调用静态分析工具、能从历史问题中学习、能作为质量门禁接入 CI/CD 流水线。
非常适合写到简历里,很加分。
更多项目实战在我的技术网站:susan.net.cn/project
一、项目介绍
这个项目是干什么的?
简单说:让代码审查这件事,从「靠人」变成「靠系统」。
你是不是经常遇到这些情况:
- 凌晨提交了 PR,三个同事都睡了,merge 倒计时还剩 4 小时,没人帮你 review。
- 团队定了代码规范,但全靠人工盯着,久而久之形同虚设。
- 核心模块要上线,心里没底,想找个"第三方"帮你全面扫一遍。
- CI/CD 流水线只跑编译和单测,代码质量问题根本拦不住。
- 想用 AI 做代码审查,但市面上的工具要么是 ChatGPT 套壳,要么不支持本地模型、数据安全过不了关。
CodeGuardian AI 就是为解决这些问题而生的。
它覆盖了从代码片段审查、单文件分析、目录/项目批量扫描、Git 仓库克隆分析,到 AI + 规则双引擎审查、RAG 知识增强、CI/CD 质量门禁、Webhook 自动触发、专业报告生成的全链路。
项目规模有多大?
| 维度 | 数据 |
|---|---|
| Java 源文件 | 160个 |
| REST API 端点 | 43个 |
| 数据库表 | 13张(PostgreSQL 17 + pgvector) |
| 中间件集成 | 3种(Redis、MinIO、PostgreSQL pgvector) |
| 服务类 | 37个 |
| 控制器 | 16个 |
| 前端页面 | 12个 Thymeleaf 模板 |
| AI 模型提供商 | 3家(通义千问 / DeepSeek / OpenAI),共 9+ 模型 |
| Function Calling 工具 | 2个(JavaParser AST分析 + Semgrep 安全扫描) |
| 规则文件 | 4套(阿里巴巴 Java / Google Java / Airbnb JS / PEP8 Python) |
它是按照企业级架构标准设计的、可以直接部署到生产环境的系统,不是教学 demo。
系统架构一览
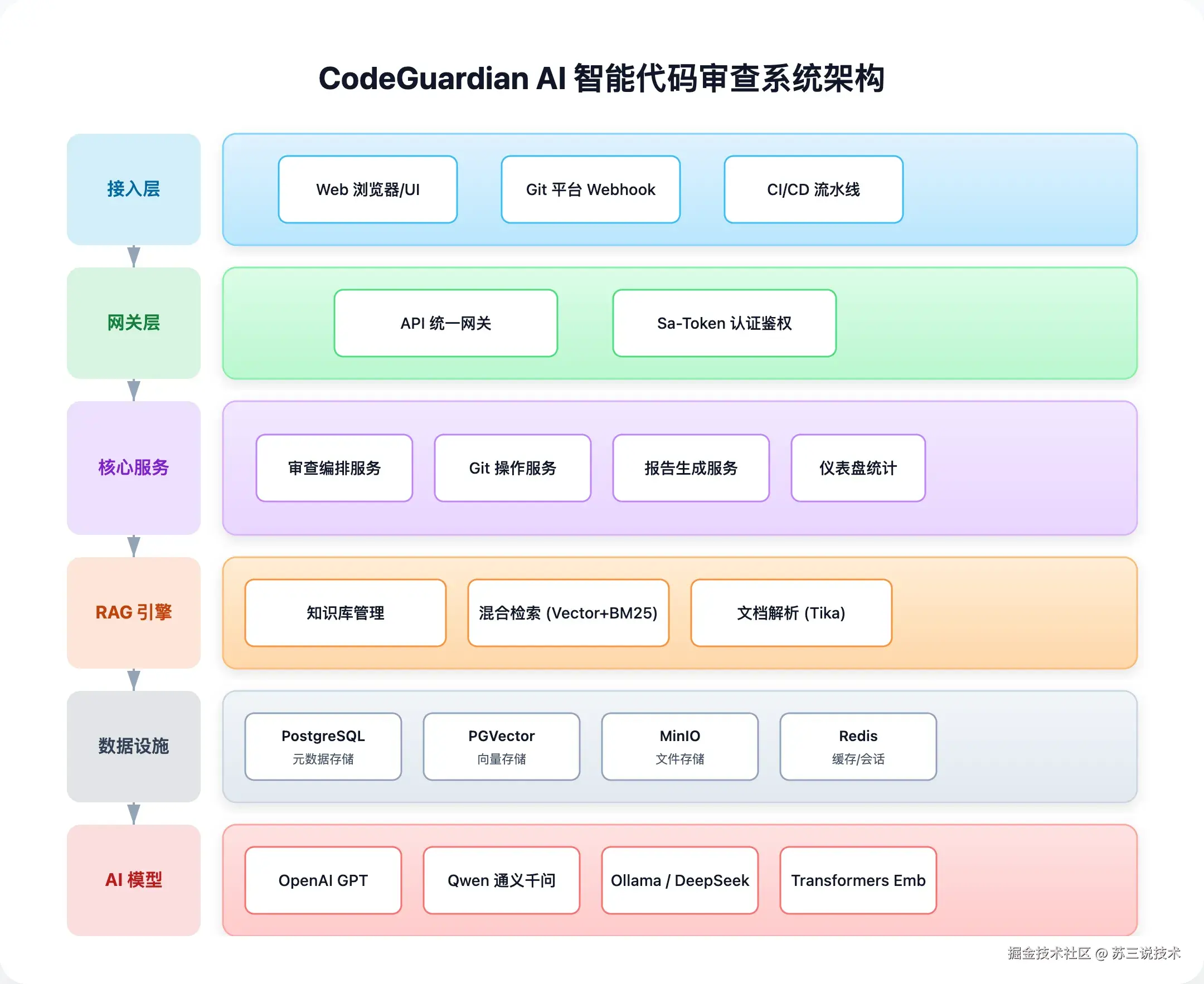
二、使用技术
后端技术栈
| 技术 | 版本 | 在项目里的实际用途 |
|---|---|---|
| Java | 21 LTS | 主语言,虚拟线程、Record 类、模式匹配 |
| Spring Boot | 3.4.1 | 应用基础框架 |
| Spring AI | 1.0.0-M4 | LLM 集成框架,统一多模型调用、向量存储、文档解析 |
| Spring Data JPA | - | 数据库 ORM 操作 |
| PostgreSQL | 17 + pgvector | 主数据库 + 384维向量检索 |
| Redis | 7.x | 语义指纹缓存、Session 管理、数据缓存 |
| MinIO | 8.5.7 | S3 兼容对象存储,知识库文件管理 |
| Sa-Token | 1.39.0 | 权限认证框架,Redis 会话管理 |
| Thymeleaf | - | 服务端模板引擎,页面渲染 |
| JavaParser | 3.26.0 | Java AST 语法解析,Function Calling 工具 |
| Semgrep | CLI | 静态安全扫描,Function Calling 工具 |
| OkHttp | 4.12.0 | HTTP 客户端,AI API 调用 |
| OpenHTMLToPDF | 1.0.10 | HTML/Markdown → PDF 报告导出 |
| Apache Tika | - | 多文档格式解析(RAG 知识库文档导入) |
| Jackson | 2.18.2 | JSON 序列化、AI 响应解析 |
| HikariCP | - | 数据库连接池 |
AI 模型支持
| 提供商 | 默认模型 | 部署方式 | 适用场景 |
|---|---|---|---|
| 通义千问 | qwen | 阿里云 DashScope API | 深度分析,复杂逻辑审查 |
| DeepSeek | deepseek | 本地 Ollama + 云端 API 双模式 | 日常审查(本地免费),高敏感代码 |
| OpenAI | gpt | OpenAI API | 国际化场景,高质量审查 |
嵌入模型 :all-MiniLM-L6-v2(本地 Transformers),384维向量。
中间件 & 基础设施
| 组件 | 版本 | 用途 |
|---|---|---|
| PostgreSQL + pgvector | 17 | 业务数据 + 向量存储(HNSW索引 + 余弦距离) |
| Redis | 7 | 语义指纹缓存(SimHash + LSH)、Session 共享 |
| MinIO | 最新 | 知识库文档对象存储 |
| Docker Compose | - | 一键部署 PostgreSQL + Redis |
三、功能介绍
我把最核心的功能一个一个拆开来说。
3.1 五种审查模式,覆盖全场景
不只是"把代码丢给 AI 看看"。
| 模式 | 触发方式 | 适用场景 |
|---|---|---|
| 代码片段 | 直接在页面粘贴代码 | 快速检查几行核心逻辑 |
| 单文件 | 上传或指定文件路径 | 新写了一个类,单独检查 |
| 目录 | 指定目录,递归扫描 | 一个模块开发完,批量检查 |
| 项目 | 全项目扫描 + include/exclude 过滤 | 提测前全量代码审查 |
| Git 仓库 | 输入 Git URL,自动克隆后分析 | 第三方代码审查或流水线集成 |
目录和项目级别的审查使用 20 线程并发处理,多文件并行分析,不会因为文件多就卡死。
3.2 AI + 规则双引擎审查
市面上 99% 的 AI 代码审查工具,做的事情都一样:把代码拼进 prompt,发给 GPT,把返回贴出来。
CodeGuardian 完全不同。
它有两套并行的分析引擎:
引擎一:LLM 深度分析
- AI 理解代码的业务逻辑、数据流、架构依赖
- 发现安全漏洞、性能瓶颈、逻辑缺陷、可维护性问题
- 输出精确到行号的问题描述、修复建议、代码 diff
引擎二:规则引擎精准匹配
- 内置 4 套规则库:阿里巴巴 Java 开发手册、Google Java Style、Airbnb JS/TS 规范、PEP8 Python 规范
- 正则模式精准匹配,零幻觉
- 规则可自定义扩展
两套引擎的结果做交叉验证,取长补短。

你得到的不是「AI 觉得有问题」,而是有两个证据来源互相印证的分析结果。
3.3 Function Calling --- AI 自己调用工具
这是架构上最亮眼的地方。
CodeGuardian 实现了完整的 Function Calling 架构。
AI 在审查代码时,不是被动地只看代码文本,而是可以自己决定调用专业工具来辅助分析。
目前注册了两个工具:
工具一:javaSyntaxAnalysis(JavaParser AST 分析)
AI 发现 Java 代码需要做语法级别的深度检查时,会主动调用这个工具。底层使用 JavaParser 进行三级智能解析:
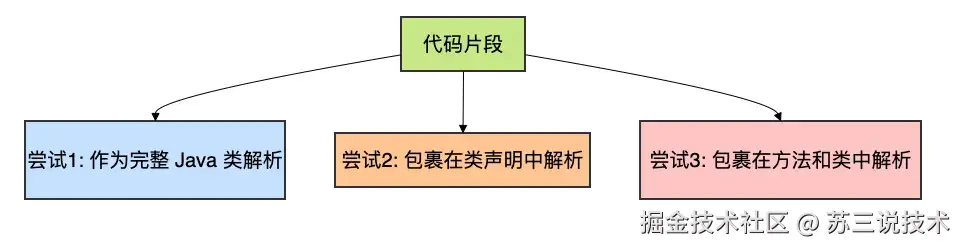
自动适应你贴进去的是完整类、方法片段、还是零散代码。
工具二:semgrepAnalysis(Semgrep 安全扫描)
AI 发现代码可能存在安全风险时,会主动调用 Semgrep CLI 进行静态安全分析。底层自动处理代码包裹、临时文件管理、超时控制、JSON 结果解析和严重性映射。
关键设计的巧妙之处:
Semgrep 分析结果会自动注入回 AI 的审查上下文。AI 拿到静态分析的发现后,不是简单转发,而是基于这些实证做深度复查 --- 确认是否有误报、判断真实影响范围、补充修复建议。
如果 AI 已经拿到了静态分析结果,Semgrep 工具会被自动禁用,避免重复分析浪费 token。
这是真正的 AI Agent,不是脚本。
3.4 RAG 知识增强 --- 越用越聪明
每完成一次代码审查,发现的问题和解决方案都会被知识库吸收。
整个 RAG pipeline 是这样的:
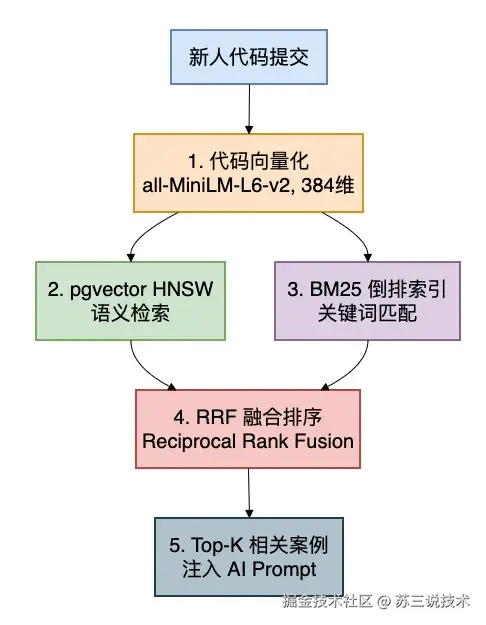
不是简单的"搜索关键词然后拼到 prompt 里"。
它实现的是混合检索:
- 向量语义搜索:搜"数据库连接没关"能命中"Connection leak"相关文档
- BM25 关键词匹配:精确命中"NullPointerException"等术语
- RRF 融合排序:两路结果加权合并,取最相关的前 K 条
底层存储:
- PostgreSQL
vector_store表:384 维向量,HNSW 索引,余弦距离 - PostgreSQL
knowledge_documents表:文档元数据、内容、解决方案、分类 - MinIO 对象存储:原始文件(PDF/Word/Markdown/TXT 等)
- Apache Tika 文档解析:自动提取多种格式文件的文本内容
这意味着什么?你的 CodeGuardian 用得越久,它见过的代码问题越多,审查就越准。
3.5 语义指纹缓存 --- 不花钱重复审查
同一个文件、同一段代码,你已经审查过了,过两天又触发一次?
大部分工具会傻傻地再调一次 AI API,再花一次钱。
CodeGuardian 做了两件事:
精确匹配:对代码做归一化(去掉注释、字符串、标识符,保留语法结构),计算 SHA-256 哈希。相同归一化结果的代码直接返回缓存结果。
模糊匹配:用 FNV-1a 64 位 SimHash 算法生成语义指纹,分 4 段存入 Redis LSH 桶索引。汉明距离 ≤ 3 的相似代码也会命中缓存。
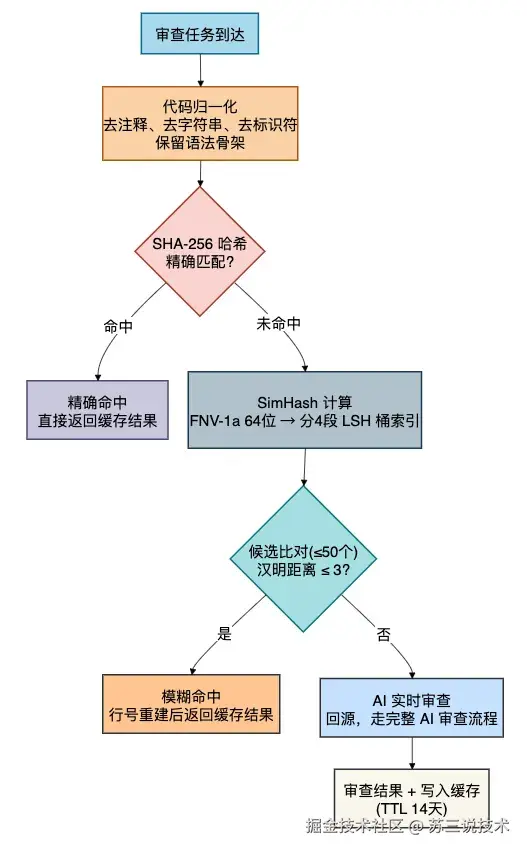
缓存配置:TTL 14 天,Python 版本跟随命名空间隔离。
Redis 不可用时优雅降级,不会影响主流程。
3.6 CI/CD 质量门禁
把代码审查变成硬约束。
大多数团队的 CI 流水线只跑编译和单测,代码质量完全是"凭自觉"。
CodeGuardian 把代码审查嵌入了 CI/CD 流程:
触发审查(在你的 CI 脚本里加一步):
bash
curl -X POST http://codeguardian:7003/api/v1/cicd/trigger \
-H "Content-Type: application/json" \
-d '{
"gitUrl": "https://gitlab.com/your-project.git",
"projectPath": ".",
"triggerBy": "CI-Pipeline"
}'轮询结果 + 质量门禁:
bash
# blockOn 参数:CRITICAL / HIGH / MEDIUM / LOW
curl http://codeguardian:7003/api/v1/cicd/status/TASK_ID?blockOn=HIGH当 blockOn=HIGH 时,只要代码中存在 CRITICAL 或 HIGH 级别的问题,Pipeline 直接失败。
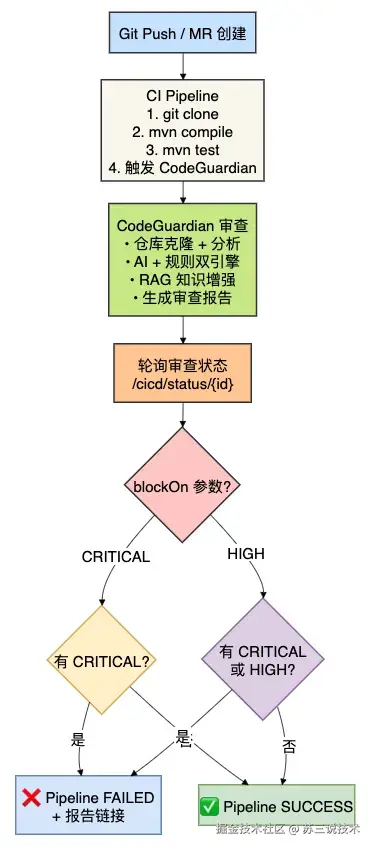
这是真正的「铁门」,不是「建议」。
返回结果包含:
passed:是否通过(布尔值)summary:critical/high/medium/low 各级别问题数量reportUrl:完整报告的访问链接
3.7 Webhook 自动触发 --- 创建 MR 就自动审查
支持 GitCode(兼容 GitLab API)的 Merge Request Webhook。
流程:
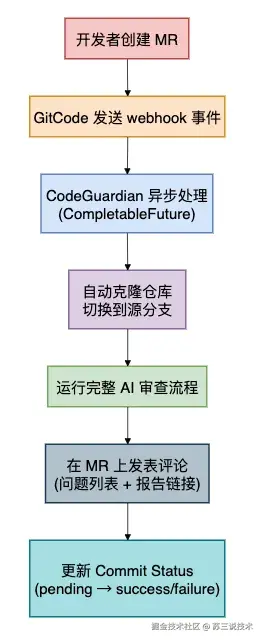
整个过程不需要人工介入,MR 创建后自动完成。
3.8 专业报告生成
不只是返回一个 JSON 数组。
| 格式 | 用途 |
|---|---|
| HTML 报告 | 带图表、颜色标识、代码 diff 高亮,可以发给老板 |
| Markdown 报告 | 可以直接 commit 到项目文档 |
| PDF 报告 | 适合归档和审计 |
每份报告包含:
- 问题分布概览(按严重性 + 按类别)
- 每个问题的详细信息(标题、位置、行号、描述、修复建议、代码 diff)
- 统计摘要(critical/high/medium/low 计数)
3.9 RBAC 权限管理
基于 Sa-Token + Redis 的完整权限体系:
| 角色 | 权限 |
|---|---|
| ADMIN | 所有权限(查询 + 审查 + 配置 + 管理) |
| REVIEWER | 创建审查任务 + 查看审查结果 |
| VIEWER | 仅查看审查结果 |
4 个独立权限:QUERY、REVIEW、CONFIG、ADMIN
支持:用户管理、角色管理、权限分配、操作日志审计(记录谁在什么时候做了什么)。
3.10 Dashboard 数据看板
- 代码健康评分:0-100 分,根据发现问题严重程度加权扣分
- 问题分布图表:critical/high/medium/low 各占多少
- 项目趋势图:最近 5 个项目的质量变化曲线
- 定时刷新:每 5 分钟自动更新 Dashboard 缓存
四、系统展示
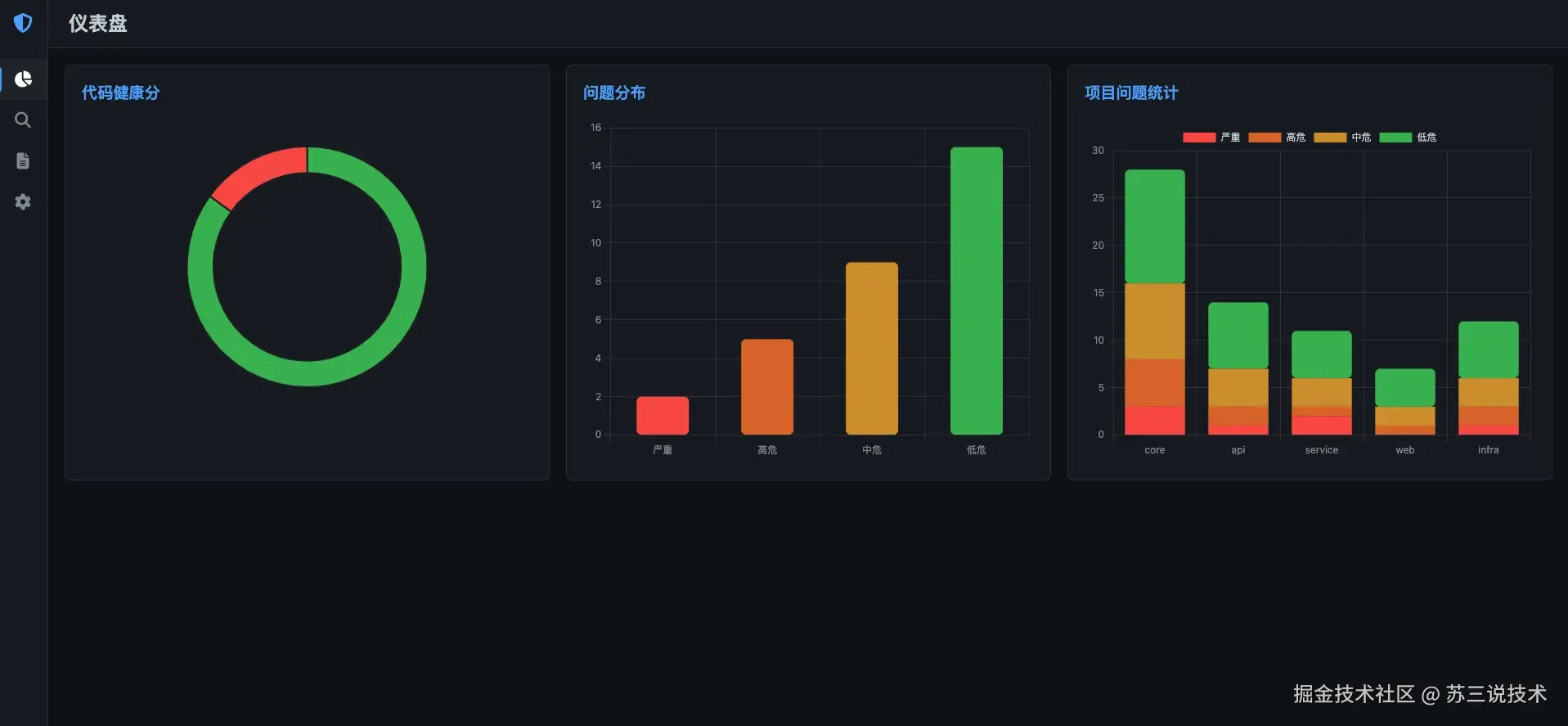
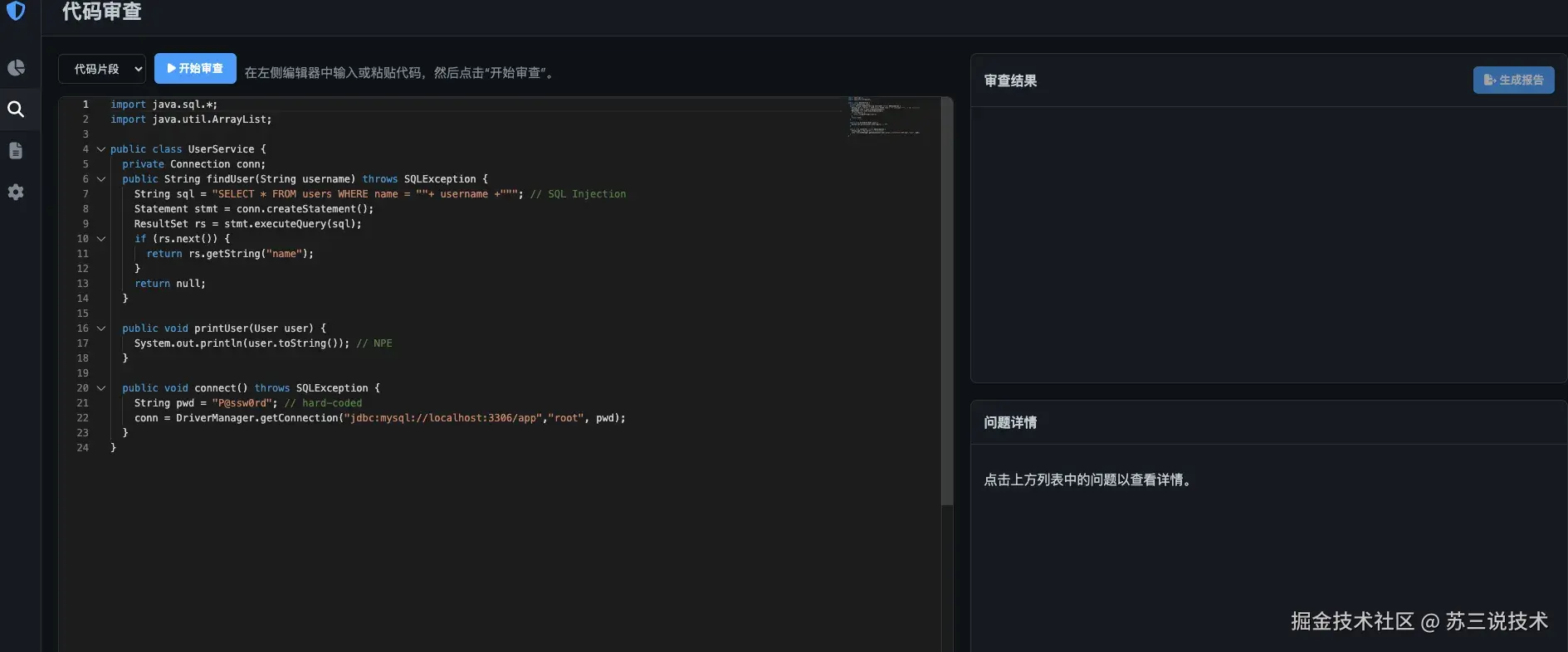
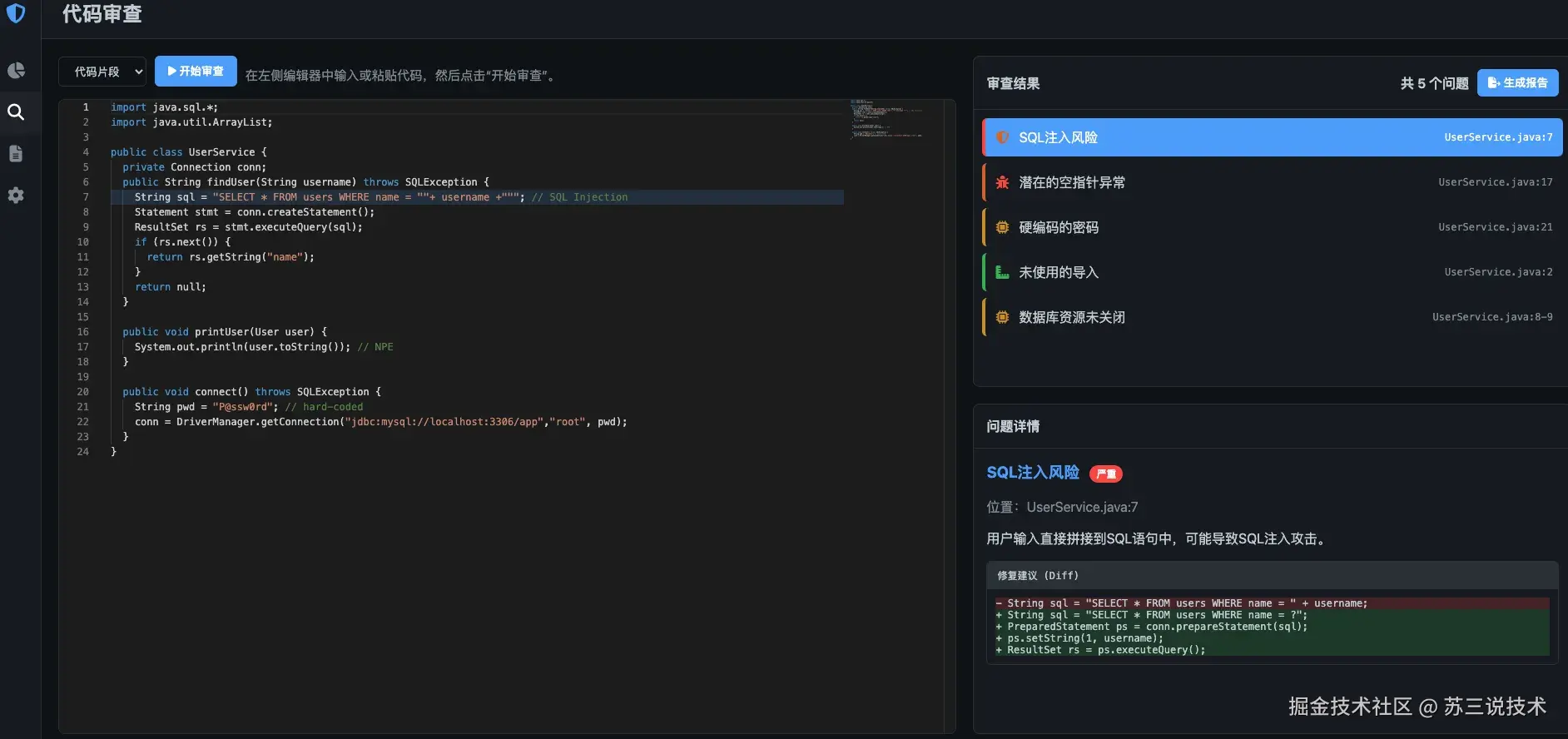
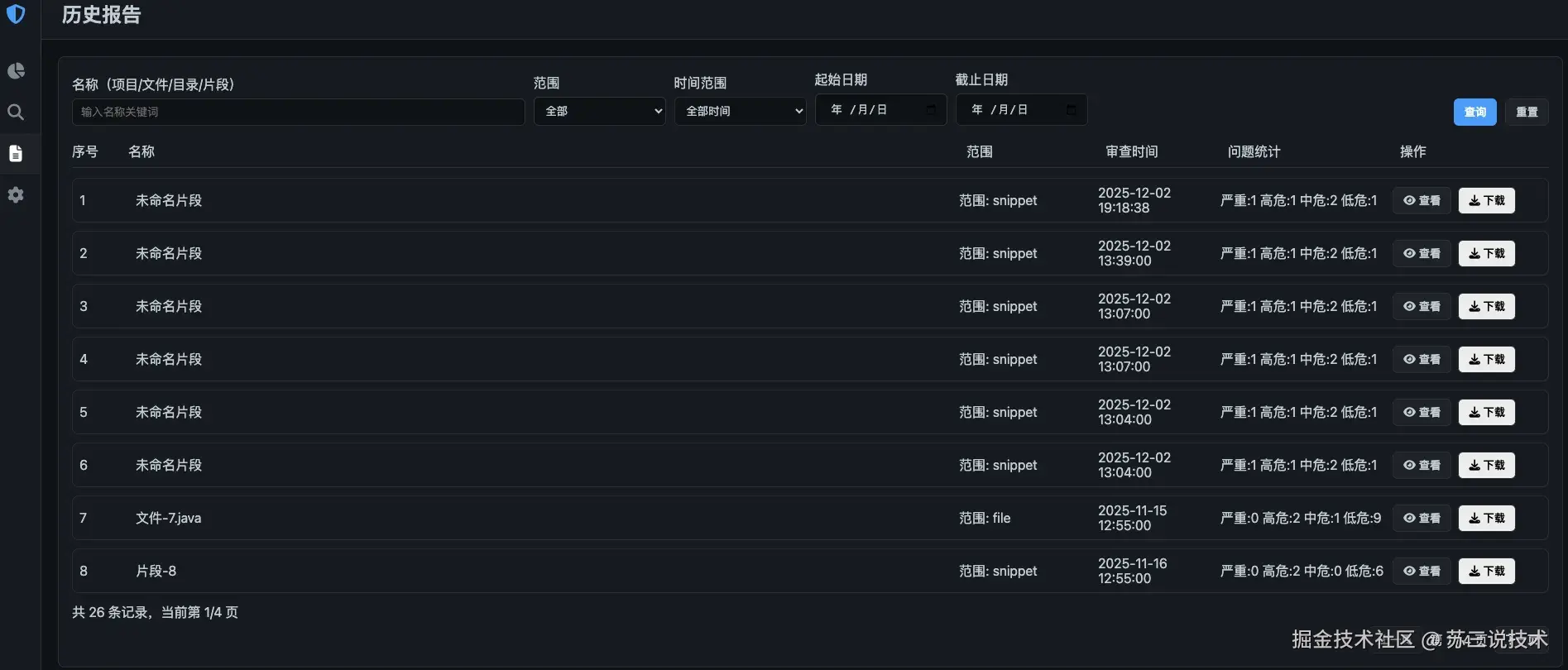
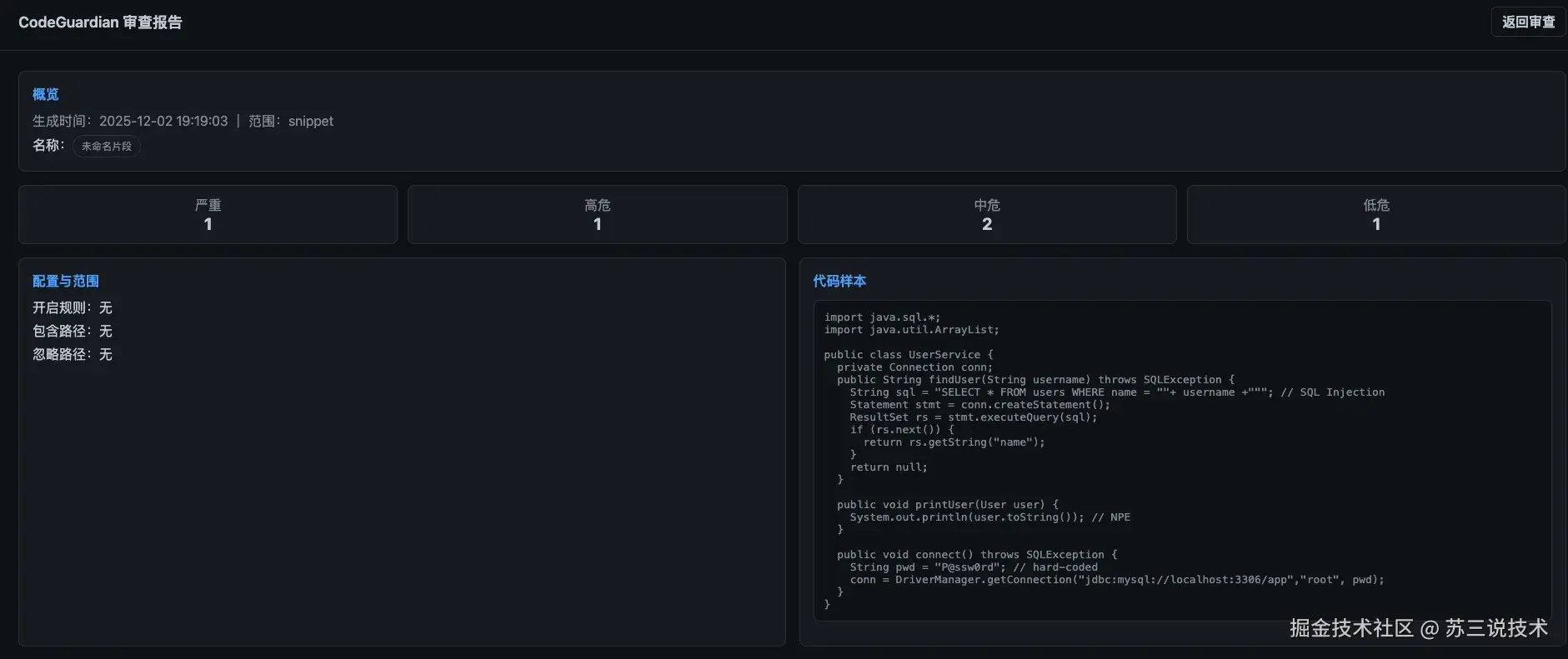
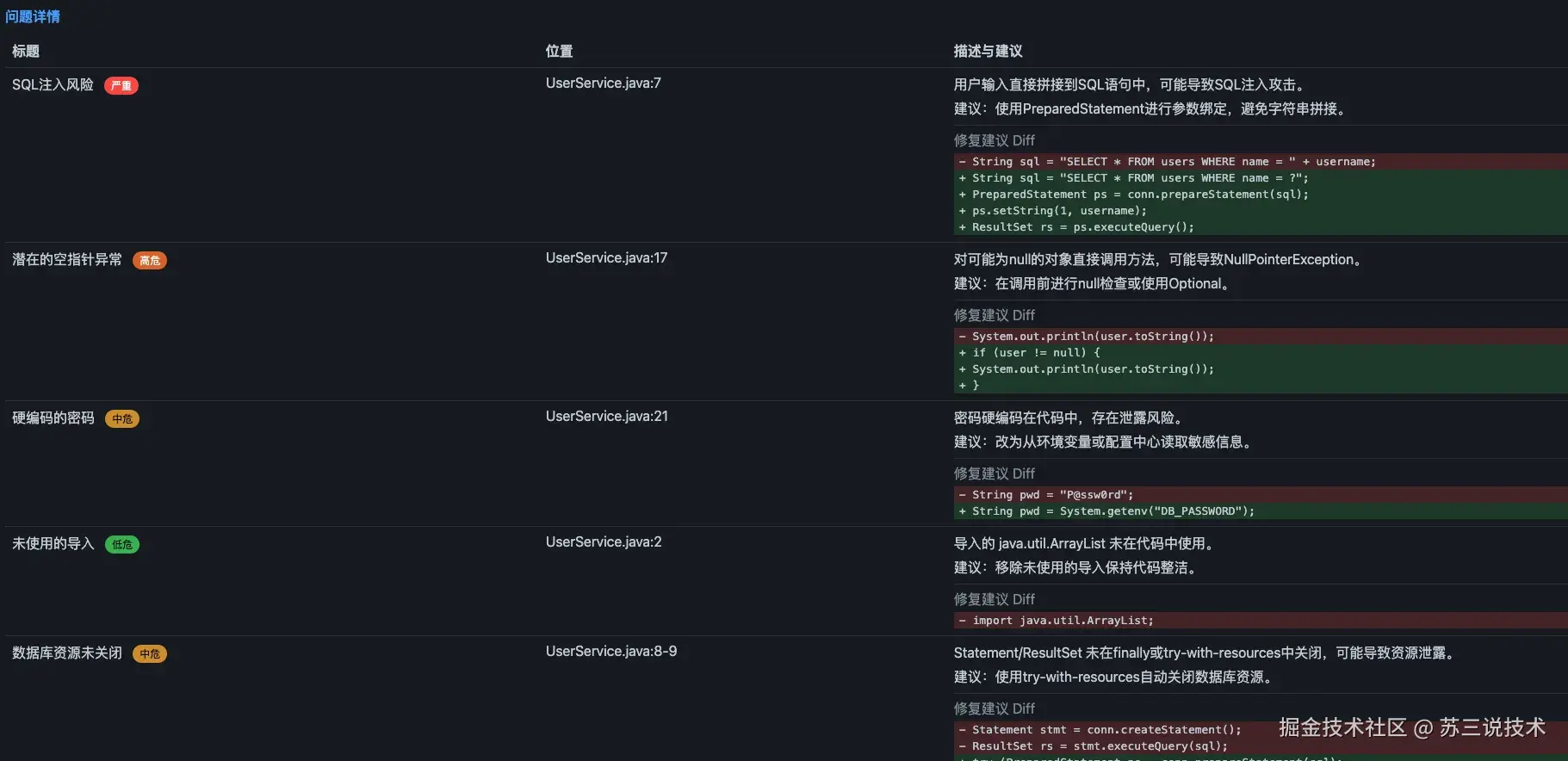
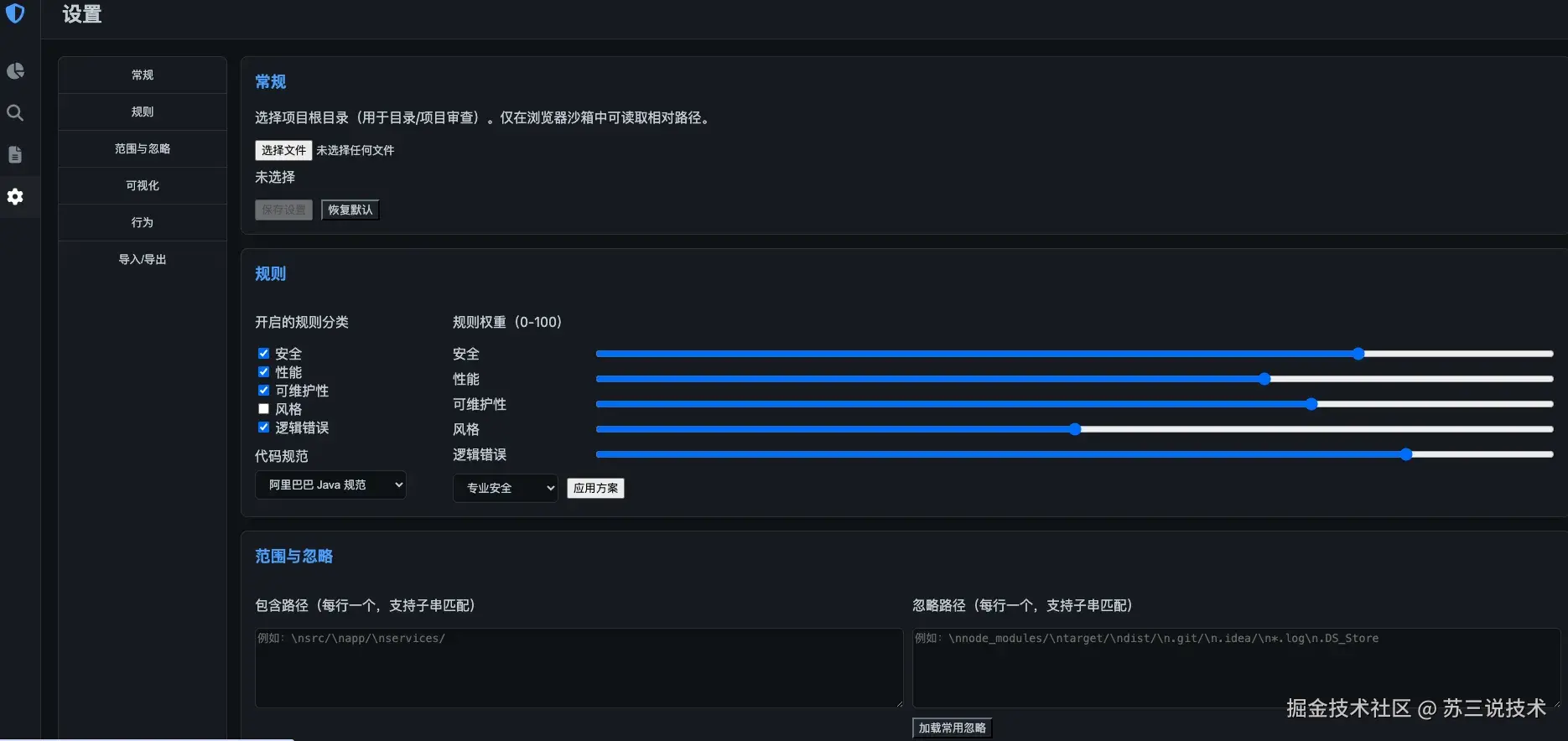
代码结构如下:
五、项目亮点
5.1 架构亮点
1. 真正的 AI Agent 架构,不是调 API
项目实现了一整套 AI Agent 的核心能力:
| 维度 | 实现方式 |
|---|---|
| Function Calling | AI 自行决定调用 JavaParser AST 分析 / Semgrep 安全扫描 |
| RAG 检索增强 | 混合检索(向量 + BM25)→ RRF 融合 → 上下文注入 |
| 语义缓存 | SimHash + LSH 桶索引 + 精确 SHA-256 匹配 |
| 多模型切换 | 策略模式,运行时切换 OpenAI / DeepSeek / Qwen |
| AI 自我纠错 | AI 拿到静态分析结果后复查确认,降低幻觉 |
ToolRegistry 在启动时自动扫描所有标注了 @Description 的 Function<?,?> Bean,自动注册为 AI 可调用工具。新增一个分析工具只要写一个实现类加上注解。
AIModelService 的审查流程可以拆解为独立步骤:
javascript
代码输入 → 语义缓存查询 → 知识库混合检索
→ Prompt 构建(含 RAG 上下文 + 工具指引)
→ AI 审查(可调用 Function Calling 工具)
→ 响应解析 → 发现问题持久化 → 缓存更新每一步都有独立的 Service 实现,方便替换或升级。
2. 混合检索(pgvector + BM25)
不是简单的数据库 LIKE 模糊查询。
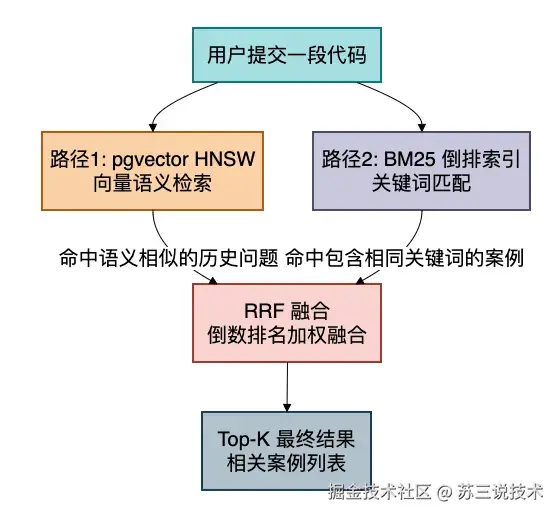
BM25 参数可调(k1=1.5, b=0.75),支持中文分词。
3. 代码归一化语义指纹
SemanticFingerprintCacheService(622行)实现了一套完整的代码去重缓存:
- 代码归一化:移除注释、字符串字面量、数字、标识符名称,保留语法结构
- 精确匹配:归一化后的 SHA-256 哈希
- 模糊匹配:FNV-1a 64 位 SimHash,分 4 段 LSH 桶索引,汉明距离 ≤ 3
- 候选限制:最多 50 个候选,避免全量比对
- 行号重建:缓存发现中的相对行号在返回时重建为绝对行号
4. GitCode 集成 --- 完整的 PR 自动审查闭环
sql
GitCode Webhook → 异步审查 → 评论回写 → Commit Status 更新不只是触发审查,而是把审查结果写回 MR,形成完整闭环。
5. Java 21 虚拟线程 --- 轻量级高并发审查
项目基于 Java 21 LTS,充分利用了虚拟线程(Virtual Threads)特性。
在目录和项目级别的批量审查中,使用虚拟线程并发处理:
java
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
files.forEach(file -> executor.submit(() -> reviewFile(file)));
}虚拟线程的核心优势:
- 每个虚拟线程只占用 KB 级别的内存(传统平台线程是 MB 级)
- 可以轻松创建数千个虚拟线程而不会 OOM
- I/O 密集型任务(调用 AI API、读文件、查数据库)是虚拟线程的最佳场景
- 没有线程池调参的烦恼,也不用担心上下文切换开销
这意味着系统在审查 50+ 文件的 Java 项目时,可以同时发起 20 个并发 AI 调用,而内存只增加不到 1MB。
用传统的线程池实现同样效果,需要 20 个核心线程常驻,光线程栈就要吃掉 20MB+。
6. SSE 流式输出 --- AI 思考过程实时可见
市面上一大半的 AI 代码审查工具,交互体验都是「提交 → 白屏等待 → 一次性吐结果」。等了好几十秒,用户根本不知道系统在干嘛。
CodeGuardian 基于 SSE(Server-Sent Events)协议实现全流程流式推送:
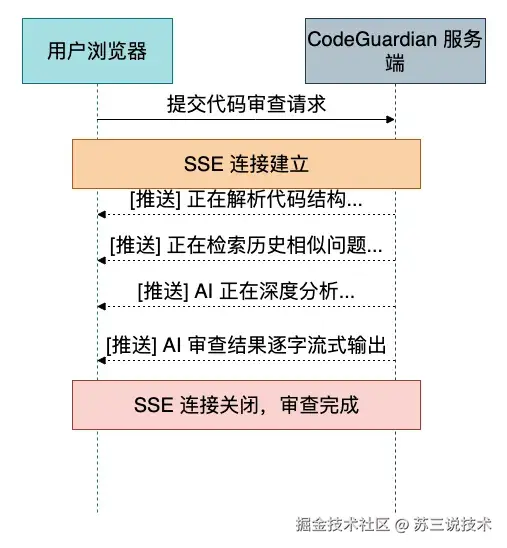
前端通过 Thymeleaf + EventSource API 接收 SSE 事件流,问题列表逐条渲染到页面。用户不只是看到最终结果,而是能看到 AI 的思考过程------这一点对 UX 的提升是降维打击。
后端基于 Spring AI 的 Flux<String> 响应式流 + Spring Web MVC 的 SseEmitter 实现,兼容性好,不需要 WebFlux 全家桶。
7. Prompt 工程体系 --- 70+ 行结构化模板
好的 AI 审查效果,70% 取决于 Prompt 的设计。
CodeGuardian 的 Prompt 不是随手写的一段话,而是一套工程化的模板体系:
| 模板组件 | 作用 |
|---|---|
| 角色设定 | 明确 AI 是「资深 Java 代码审查专家」,限定技术栈和分析视角 |
| 审查规则注入 | 自动载入选中的规则文件(阿里巴巴/Google/Airbnb/PEP8) |
| RAG 上下文注入 | 将 Top-K 历史相似问题及解决方案嵌入 Prompt |
| 工具使用指引 | 告知 AI 在什么场景下调用 javaSyntaxAnalysis / semgrepAnalysis |
| JSON Schema 约束 | 严格的输出格式定义,确保返回结果可被机器解析 |
| Few-shot 示例 | 内置 2-3 个高质量审查示例,引导 AI 按预期的精度和风格输出 |
| 严重级别定义 | CRITICAL / HIGH / MEDIUM / LOW 的判定标准和示例 |
模板总长度超过 70 行 ,每一个字段、每一条指令都是反复调优的结果。而且 Prompt 不是写死的------通过 PromptTemplateService 根据目标语言、选中的规则集、可用工具、严重级别阈值动态组装。
8. 多级降级与容错
AI 系统最大的问题就是不稳定:API 超时、返回格式抽风、token 超限、第三方依赖挂了......任何一个环节崩了,整个审查流程就跪了。
CodeGuardian 在每个关键路径上都做了降级处理:
| 故障场景 | 降级策略 |
|---|---|
| Redis 不可用 | 自动跳过语义缓存,直接走 AI 实时审查,不影响主流程 |
| AI API 超时/报错 | 自动重试(指数退避),仍失败则降级到纯规则引擎审查 |
| Semgrep CLI 未安装 | AI 独立完成审查,工具不可用不阻塞 |
| 向量检索无结果 | 返回空上下文,Prompt 中不注入 RAG 内容,正常构建和调用 |
| AI 返回 JSON 解析失败 | 正则兜底提取 + 默认值填充,尽可能挽救有效信息 |
这套设计背后的思想是熔断器模式(Circuit Breaker)和优雅降级(Graceful Degradation)------系统在任何一个组件出问题的情况下,都能给出有意义的审查结果,而不是直接抛 500。
「不能因为 AI 不稳定,就让审查功能不可用。」 这是从一开始就定下的设计原则。
9. 插件化工具自注册 --- 零侵入扩展
想让 AI 调用新的分析工具?
不需要改核心流程代码,不需要改 XML 配置。
写一个实现类,加一个 @Description 注解就行:
java
@Component
@Description("计算代码的圈复杂度和认知复杂度指标")
public class ComplexityAnalysisFunction
implements Function<ComplexityRequest, ComplexityResponse> {
@Override
public ComplexityResponse apply(ComplexityRequest request) {
// 你的分析逻辑 → 直接返回结果,框架自动处理
}
}ToolRegistry 在 Spring 容器启动时自动扫描所有标注了 @Description 的 Function<?, ?> Bean:
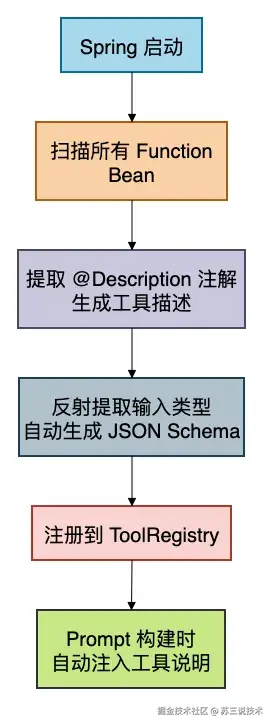
这是真正的插件架构。 你想接入 ESLint?写一个 Function。想接 SonarQube?写一个 Function。想加代码复杂度分析?还是写一个 Function。核心审查流程完全不用动,新工具即插即用。
5.2 工程亮点
| 分类 | 亮点数 | 核心关键词 |
|---|---|---|
| AI Agent 架构 | 5 | Function Calling 工具自注册、双工具协同、AI 自纠错、多提供商策略模式、SSE 流式输出 |
| RAG 知识库 | 4 | 向量+BM25 混合检索+RRF融合、pgvector HNSW索引、Tika多格式文档解析、MinIO对象存储 |
| 审查引擎 | 3 | AI+规则双引擎、20线程并发、5种审查模式全覆盖 |
| 语义缓存 | 3 | SimHash+LSH模糊匹配、SHA-256精确匹配、优雅降级 |
| CI/CD 集成 | 3 | 质量门禁可配置、Webhook异步审查、提交状态回写 |
| 权限安全 | 3 | RBAC三角色四权限、Sa-Token Redis会话、AOP操作审计 |
| 报告导出 | 3 | HTML/Markdown/PDF 三格式、代码diff高亮、统计分析图表 |
| 运维工程 | 3 | Docker Compose 一键部署、全局异常处理、环境变量全覆盖配置 |
更多项目实战在我的技术网站:susan.net.cn/project
5.3 这套源码能带给你什么?
如果你是一个初中级后端开发:
- AI Agent 的 Function Calling 怎么实现?怎么让 AI 自己调用工具?这个项目有完整的可运行代码
- RAG 检索增强生成怎么落地?从文档分块到向量化到混合检索到 LLM 生成,每一步都有独立的 Service 实现
- 多 AI 模型切换(OpenAI + DeepSeek + Qwen)的策略模式怎么设计?
- Spring AI 框架在实际项目中怎么用?ChatClient 怎么封装?
- CI/CD 质量门禁怎么设计和实现?
- Sa-Token + RBAC 权限模型怎么落地?
如果你关注 AI / LLM:
- Function Calling 的完整代码实现:ToolRegistry 扫描注册 → ToolDefinition JSON Schema 自动生成 → ChatClient 工具回调 → 结果注入上下文
- RAG 完整 Pipeline:Tika 文档解析 → TokenTextSplitter 分块 → Transformers Embedding → pgvector 向量存储 → 混合检索(向量 + BM25) → RRF 融合 → Prompt 注入
- 语义缓存:代码归一化 → SHA-256 精确匹配 → SimHash + LSH 模糊匹配 → Redis 存储
- Prompt 工程:70+ 行的提示模板,包含角色设定、RAG 上下文注入、工具使用指引、严格 JSON 输出格式约束、Few-shot 示例
- 多种模型提供商集成:OpenAI 原生 / 阿里云 DashScope / Ollama 本地部署
如果你是一个架构师或技术 Leader:
- 单体可演进架构怎么设计,为未来拆微服务预留接口
- AI 审查系统的核心流程怎么编排(缓存 → RAG → Prompt → AI → 工具调用 → 解析 → 持久化)
- 质量门禁的阈值体系怎么设计(CRITICAL > HIGH > MEDIUM > LOW 级联阻断)
- 语义缓存的降级策略(Redis 不可用时优雅降级,不影响主流程)