文章首发 猩猩程序员 公众号,欢迎关注
原文地址 docs.litellm.ai/blog/litell...
2026 年 6 月 22 日
Ishaan Jaffer(LiteLLM CTO)
在过去一年里,我们从用户和社区听到同一个反馈:他们想要一个更快、更轻、更容易部署的 AI Gateway。
我们听到了这个需求,并正在通过一个重大改变来解决它:
将 LiteLLM 的核心迁移到 Rust。
为什么要做这件事
随着 LiteLLM 在生产环境中的使用越来越广泛,我们越来越清楚地看到一些瓶颈:
- 高负载下的延迟波动(latency spikes)
- Python 运行时带来的性能限制
- 内存泄漏与 OOM(Out of Memory)导致的服务崩溃风险
- 在大规模 AI 请求下难以保证稳定性
这些问题在 AI Gateway 这种基础设施级别的系统中尤为关键。
我们希望解决的是一个核心问题:
如何让 AI 请求路由层在高并发下仍然保持稳定、低延迟、可预测的性能表现?
为什么选择 Rust
Rust 提供了我们需要的三个关键能力:
1. 更低延迟(Low Latency)
Rust 编译型执行路径可以显著减少 Python runtime 的额外开销。
2. 更小内存占用(Memory Efficiency)
Rust 的内存模型更可控,可以避免 GC 或 Python 对象管理带来的不可预测内存增长。
3. 更高稳定性(Reliability)
在高并发场景下,可以避免 Python GIL 带来的瓶颈以及运行时抖动问题。
架构方式:渐进式迁移(Non-breaking Migration)
这次迁移不会破坏现有 API 或使用方式。
我们采用的是逐步替换核心组件的方式:
- LiteLLM 的 Python SDK 保持不变
- LiteLLM 的 Proxy Server 仍然兼容现有配置
- Rust 组件作为"底层执行引擎"逐步接管核心逻辑
通过 PyO3(Python ↔ Rust 绑定):
Python 仍然作为用户接口层存在,而 Rust 负责性能关键路径
迁移目标
我们最终希望实现:
- Python SDK 完全兼容(无需修改现有代码)
- Proxy Server 保持 API 不变
- Rust 成为执行核心(hot path)
- 提供更低延迟、更高吞吐、更稳定的 AI gateway
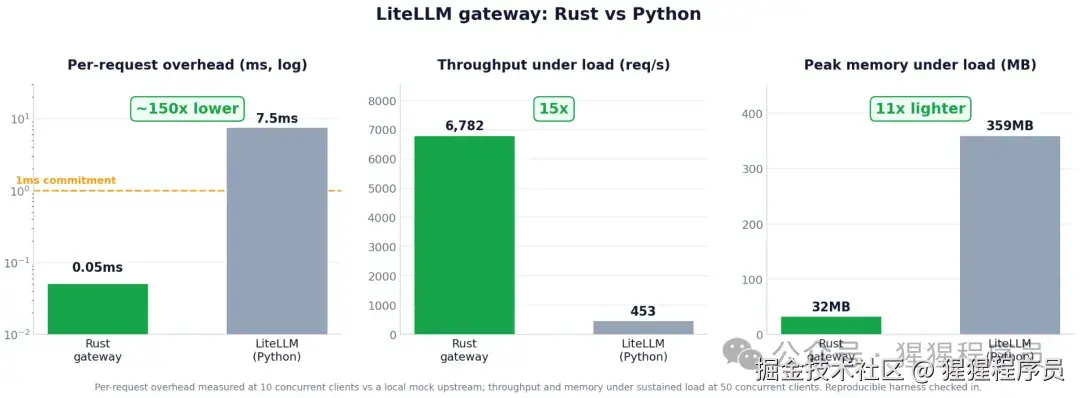
性能目标与初步结果
在早期测试中,我们已经看到了显著提升:
- 吞吐量提升约 15 倍
- 内存使用减少约 11 倍
- 每请求延迟从约 7.5ms 降低到约 0.05ms
- Rust 路径已实现 亚毫秒级(sub-1ms)开销
这些结果表明:
Rust 可以显著提升 AI gateway 在生产环境中的稳定性与性能上限。
迁移路线图
我们计划分阶段完成整个系统迁移:
阶段 1:核心路由层 Rust 化
- 请求调度
- provider 路由
- 基础转换逻辑
阶段 2:增强能力迁移
- retry / fallback 逻辑
- 负载均衡
- caching 层优化
阶段 3:完整 Gateway Rust 化
- Proxy Server 完全 Rust 化
- Python SDK 仅作为客户端封装层
预计在 2026 年 12 月 1 日前完成整体迁移。
对现有用户意味着什么?
最重要的一点是:
不会有任何破坏性变化
你现有的使用方式保持不变:
- Python SDK 仍然可用
- API 不变
- 配置不需要修改
- 只是底层变得更快、更稳定
我们的长期愿景
LiteLLM 的目标一直很简单:
让所有 AI 模型都可以通过一个统一、可靠、高性能的接口来访问。
迁移到 Rust 并不是为了"换语言",而是为了:
- 支撑更大规模 AI 应用
- 降低基础设施成本
- 提高系统稳定性
- 为 agent 时代的高并发推理做好准备
总结
这次 Rust 迁移的核心不是"重写",而是:
- 保持兼容性
- 提升性能上限
- 消除 Python 在高负载场景下的结构性瓶颈
我们相信:
Rust 将让 LiteLLM 成为更快、更轻、更可靠的 AI Gateway。
文章首发 猩猩程序员 公众号,欢迎关注