一、文本索引核心原理概述
MongoDB 的文本索引(Text Index)是专为自然语言搜索设计的特殊索引类型。与传统的 B-Tree 索引不同,文本索引通过语言感知的分词、停用词过滤和词干提取,在后台构建倒排索引(Inverted Index)结构,从而实现对字符串内容的高效全文搜索。
1. 文本索引与普通索引的本质区别
| 特性维度 | 普通索引 (B-Tree) | 文本索引 (Text Index) |
|---|---|---|
| 匹配方式 | 精确匹配、前缀匹配或正则表达式 | 语义分词匹配、词干提取、短语匹配 |
| 排序能力 | 支持多字段复合排序 | 仅支持基于 textScore 的相关性排序 |
| 语言处理 | 无(区分大小写和重音) | 支持多语言、自动过滤停用词 |
| 架构限制 | 单集合可创建多个普通索引 | 单集合最多只能创建一个文本索引 |
| 适用场景 | 状态码、ID、时间戳等结构化数据过滤 | 博客正文、商品描述、评论等非结构化文本搜索 |
二、端到端生命周期:从写入到查询
1. 文本索引与查询执行流程图
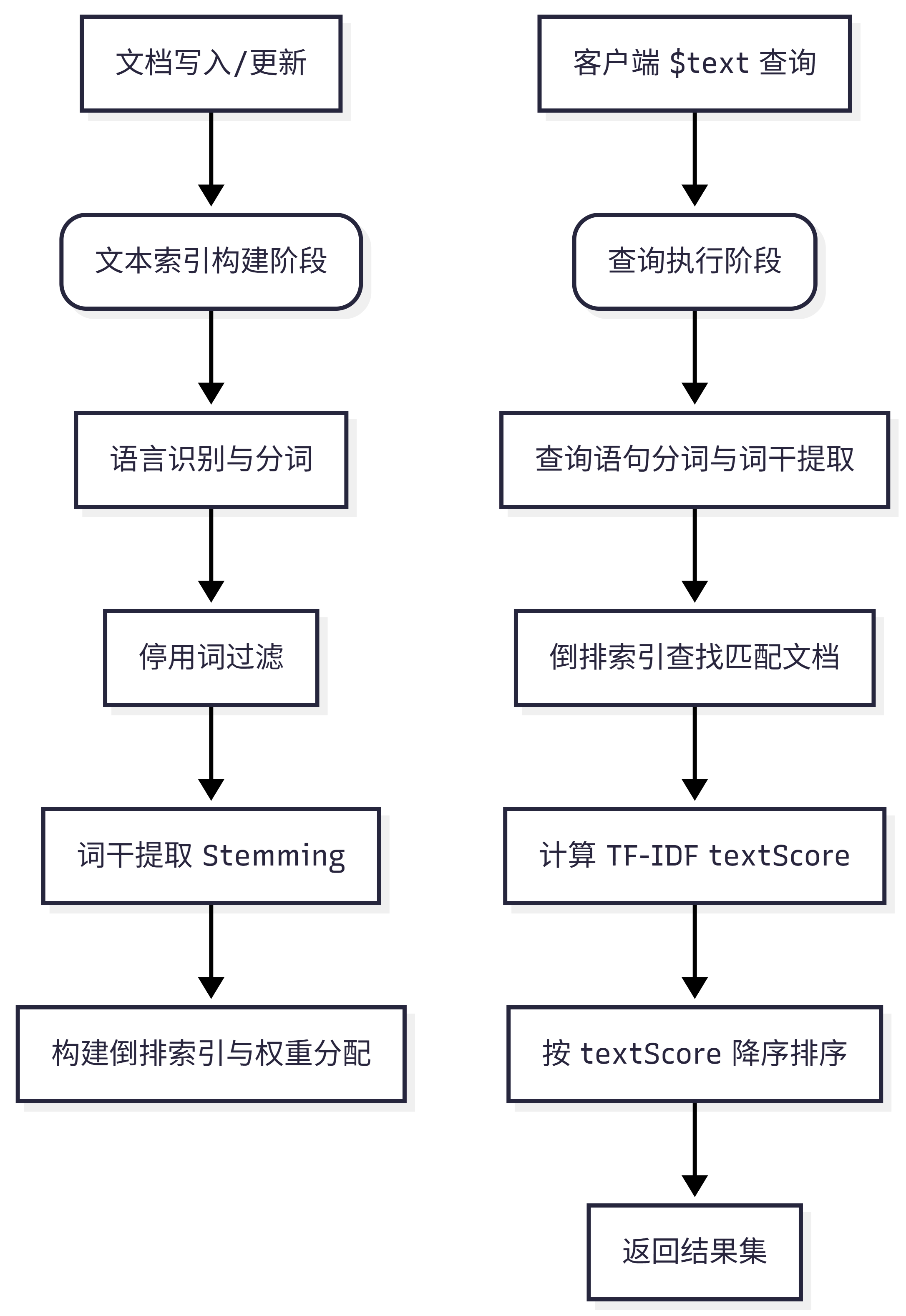
2. 写入阶段:倒排索引的构建
当向集合中插入或更新文档时,MongoDB 会对配置了文本索引的字段执行以下操作:
- 分词(Tokenization):将文本按空格和标点拆分为词元(Tokens)。
- 停用词过滤(Stop Words):自动剔除如 "the"、"a"、"is" 等对搜索无意义的常见词汇。
- 词干提取(Stemming):将词汇还原为词根形式(例如 "running" 和 "runs" 均被提取为 "run")。
- 倒排存储:记录每个词元对应的文档 ID 列表(Posting List),并根据配置的权重(Weights)记录词元在标题或正文中的出现频次。
3. 查询阶段:$text 与 textScore
执行 $text 查询时,MongoDB 会对用户的搜索词执行相同的分词和词干提取,然后在倒排索引中快速定位文档。相关性评分(textScore)基于简化的 TF-IDF 算法计算:
- TF(词频):词在文档中出现的次数越多,得分越高。
- IDF(逆文档频率):词在整个集合中越罕见,得分越高。
- 权重乘数:如果词元出现在高权重字段(如标题)中,得分会按配置的权重倍数放大。
三、核心架构限制与进阶解决方案
1. "单集合单文本索引"的设计哲学
MongoDB 严格限制每个集合只能拥有一个文本索引。这一设计的根本原因在于:
- 性能开销:文本索引的构建和更新极其消耗 CPU 和 I/O 资源。多个文本索引会导致写入性能急剧下降。
- 排序冲突 :
$text查询强依赖于textScore进行排序。如果存在多个文本索引,数据库将无法确定应以哪个维度的评分作为主排序依据。
2. 架构演进:突破原生限制的替代方案
对于系统架构师而言,当原生文本索引无法满足业务需求时,应考虑以下架构演进路线:
- 应用层预分词 + 数组索引(轻量级替代)
在数据写入 MongoDB 之前,使用外部 NLP 库(如 jieba、IKAnalyzer)进行分词,将结果存入数组字段(如keywords: ["mongodb", "性能", "优化"])。随后为该数组字段建立普通 B-Tree 索引,查询时使用$in操作符。此方案将查询复杂度从 O(N) 降至 O(log N),且完美支持多字段复合排序。 - 引入专业搜索引擎(重量级替代)
当数据量突破数十万级,或业务要求高亮显示、模糊搜索、同义词扩展时,应果断引入 Elasticsearch 或 Meilisearch。MongoDB 仅作为持久化存储层,通过 CDC(变更数据捕获)或双写机制将数据同步至搜索引擎。 - 复合文本索引优化(原生性能调优)
若必须使用原生文本索引,可通过创建复合索引(如{ status: 1, content: "text" })来限制扫描范围。查询时结合等值过滤条件(如status: "PUBLISHED"),可大幅减少倒排索引的扫描条目数。
四、高频面试题与深度解析
Q1:为什么在 MongoDB 中搜索中文时,即使建立了文本索引也常常返回空结果?
答 :这是因为 MongoDB 文本索引的默认语言是英语(default_language: "english")。在英语分词规则下,中文字符会被视为一个完整的词元 ,且极易被当作停用词过滤掉。解决方案是在创建索引时显式指定中文:createIndex({ content: "text" }, { default_language: "zh" }),或者将 default_language 设为 "none" 以禁用停用词过滤和词干提取。
Q2:如何在一个集合中实现"标题"比"正文"更重要的搜索排序?
答 :虽然一个集合只能有一个文本索引,但该索引可以覆盖多个字段。在创建索引时,可以通过 weights 参数为不同字段分配权重。例如:createIndex({ title: "text", body: "text" }, { weights: { title: 10, body: 1 } })。在查询时投影并排序 { score: { $meta: "textScore" } },标题中命中关键词的文档将获得 10 倍于正文的评分加成。
Q3:我的文本搜索在数据量超过 10 万后变得极慢,甚至超时,如何排查和优化?
答 :首先使用 .explain("executionStats") 检查 totalKeysExamined,如果该值接近集合总文档数,说明发生了全索引扫描。优化策略包括:(1) 创建复合文本索引,将高频等值过滤字段(如 category、status)放在文本字段之前;(2) 避免在 $text 查询中嵌套复杂的 $and 或聚合管道;(3) 如果业务强依赖非相关性排序(如按时间排序),应放弃原生 $text,改用应用层预分词方案或引入 Elasticsearch。
Q4:$text 查询支持哪些高级搜索语法?
答 :MongoDB 的 $search 字符串支持三种高级语法:(1) 使用双引号进行精确短语匹配,如 "\"error handling\"";(2) 使用前置连字符排除特定词汇,如 "mongodb -deprecated";(3) 未加引号的词汇默认使用 OR 逻辑连接。需要注意的是,原生文本索引不支持跨词项的 AND 运算符,也不支持模糊搜索(Fuzzy Search)。